 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiang Bai
Dataset and Benchmark for Urdu Natural Scenes Text Detection, Recognition and Visual Question Answering
May 21, 2024
The development of Urdu scene text detection, recognition, and Visual Question Answering (VQA) technologies is crucial for advancing accessibility, information retrieval, and linguistic diversity in digital content, facilitating better understanding and interaction with Urdu-language visual data. This initiative seeks to bridge the gap between textual and visual comprehension. We propose a new multi-task Urdu scene text dataset comprising over 1000 natural scene images, which can be used for text detection, recognition, and VQA tasks. We provide fine-grained annotations for text instances, addressing the limitations of previous datasets for facing arbitrary-shaped texts. By incorporating additional annotation points, this dataset facilitates the development and assessment of methods that can handle diverse text layouts, intricate shapes, and non-standard orientations commonly encountered in real-world scenarios. Besides, the VQA annotations make it the first benchmark for the Urdu Text VQA method, which can prompt the development of Urdu scene text understanding. The proposed dataset is available at: https://github.com/Hiba-MeiRuan/Urdu-VQA-Dataset-/tree/main
MTVQA: Benchmarking Multilingual Text-Centric Visual Question Answering
May 20, 2024Text-Centric Visual Question Answering (TEC-VQA) in its proper format not only facilitates human-machine interaction in text-centric visual environments but also serves as a de facto gold proxy to evaluate AI models in the domain of text-centric scene understanding. However, most TEC-VQA benchmarks have focused on high-resource languages like English and Chinese. Despite pioneering works to expand multilingual QA pairs in non-text-centric VQA datasets using translation engines, the translation-based protocol encounters a substantial ``Visual-textual misalignment'' problem when applied to TEC-VQA. Specifically, it prioritizes the text in question-answer pairs while disregarding the visual text present in images. Furthermore, it does not adequately tackle challenges related to nuanced meaning, contextual distortion, language bias, and question-type diversity. In this work, we address the task of multilingual TEC-VQA and provide a benchmark with high-quality human expert annotations in 9 diverse languages, called MTVQA. To our knowledge, MTVQA is the first multilingual TEC-VQA benchmark to provide human expert annotations for text-centric scenarios. Further, by evaluating several state-of-the-art Multimodal Large Language Models (MLLMs), including GPT-4V, on our MTVQA dataset, it is evident that there is still room for performance improvement, underscoring the value of our dataset. We hope this dataset will provide researchers with fresh perspectives and inspiration within the community. The MTVQA dataset will be available at https://huggingface.co/datasets/ByteDance/MTVQA.
The First Swahili Language Scene Text Detection and Recognition Dataset
May 19, 2024Scene text recognition is essential in many applications, including automated translation, information retrieval, driving assistance, and enhancing accessibility for individuals with visual impairments. Much research has been done to improve the accuracy and performance of scene text detection and recognition models. However, most of this research has been conducted in the most common languages, English and Chinese. There is a significant gap in low-resource languages, especially the Swahili Language. Swahili is widely spoken in East African countries but is still an under-explored language in scene text recognition. No studies have been focused explicitly on Swahili natural scene text detection and recognition, and no dataset for Swahili language scene text detection and recognition is publicly available. We propose a comprehensive dataset of Swahili scene text images and evaluate the dataset on different scene text detection and recognition models. The dataset contains 976 images collected in different places and under various circumstances. Each image has its annotation at the word level. The proposed dataset can also serve as a benchmark dataset specific to the Swahili language for evaluating and comparing different approaches and fostering future research endeavors. The dataset is available on GitHub via this link: https://github.com/FadilaW/Swahili-STR-Dataset
Exploring the Capabilities of Large Multimodal Models on Dense Text
May 09, 2024While large multi-modal models (LMM) have shown notable progress in multi-modal tasks, their capabilities in tasks involving dense textual content remains to be fully explored. Dense text, which carries important information, is often found in documents, tables, and product descriptions. Understanding dense text enables us to obtain more accurate information, assisting in making better decisions. To further explore the capabilities of LMM in complex text tasks, we propose the DT-VQA dataset, with 170k question-answer pairs. In this paper, we conduct a comprehensive evaluation of GPT4V, Gemini, and various open-source LMMs on our dataset, revealing their strengths and weaknesses. Furthermore, we evaluate the effectiveness of two strategies for LMM: prompt engineering and downstream fine-tuning. We find that even with automatically labeled training datasets, significant improvements in model performance can be achieved. We hope that this research will promote the study of LMM in dense text tasks. Code will be released at https://github.com/Yuliang-Liu/MultimodalOCR.
VimTS: A Unified Video and Image Text Spotter for Enhancing the Cross-domain Generalization
Apr 30, 2024Text spotting, a task involving the extraction of textual information from image or video sequences, faces challenges in cross-domain adaption, such as image-to-image and image-to-video generalization. In this paper, we introduce a new method, termed VimTS, which enhances the generalization ability of the model by achieving better synergy among different tasks. Typically, we propose a Prompt Queries Generation Module and a Tasks-aware Adapter to effectively convert the original single-task model into a multi-task model suitable for both image and video scenarios with minimal additional parameters. The Prompt Queries Generation Module facilitates explicit interaction between different tasks, while the Tasks-aware Adapter helps the model dynamically learn suitable features for each task. Additionally, to further enable the model to learn temporal information at a lower cost, we propose a synthetic video text dataset (VTD-368k) by leveraging the Content Deformation Fields (CoDeF) algorithm. Notably, our method outperforms the state-of-the-art method by an average of 2.6% in six cross-domain benchmarks such as TT-to-IC15, CTW1500-to-TT, and TT-to-CTW1500. For video-level cross-domain adaption, our method even surpasses the previous end-to-end video spotting method in ICDAR2015 video and DSText v2 by an average of 5.5% on the MOTA metric, using only image-level data. We further demonstrate that existing Large Multimodal Models exhibit limitations in generating cross-domain scene text spotting, in contrast to our VimTS model which requires significantly fewer parameters and data. The code and datasets will be made available at the https://VimTextSpotter.github.io.
TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Apr 19, 2024



Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT4V and Gemini, partly due to a lack of extensive, high-quality instruction tuning data. To this end, we introduce a new approach for creating a massive, high-quality instruction-tuning dataset, Square-10M, which is generated using closed-source MLLMs. The data construction process, termed Square, consists of four steps: Self-Questioning, Answering, Reasoning, and Evaluation. Our experiments with Square-10M led to three key findings: 1) Our model, TextSquare, considerably surpasses open-source previous state-of-the-art Text-centric MLLMs and sets a new standard on OCRBench(62.2%). It even outperforms top-tier models like GPT4V and Gemini in 6 of 10 text-centric benchmarks. 2) Additionally, we demonstrate the critical role of VQA reasoning data in offering comprehensive contextual insights for specific questions. This not only improves accuracy but also significantly mitigates hallucinations. Specifically, TextSquare scores an average of 75.1% across four general VQA and hallucination evaluation datasets, outperforming previous state-of-the-art models. 3) Notably, the phenomenon observed in scaling text-centric VQA datasets reveals a vivid pattern: the exponential increase of instruction tuning data volume is directly proportional to the improvement in model performance, thereby validating the necessity of the dataset scale and the high quality of Square-10M.
Bridging the Gap Between End-to-End and Two-Step Text Spotting
Apr 06, 2024Modularity plays a crucial role in the development and maintenance of complex systems. While end-to-end text spotting efficiently mitigates the issues of error accumulation and sub-optimal performance seen in traditional two-step methodologies, the two-step methods continue to be favored in many competitions and practical settings due to their superior modularity. In this paper, we introduce Bridging Text Spotting, a novel approach that resolves the error accumulation and suboptimal performance issues in two-step methods while retaining modularity. To achieve this, we adopt a well-trained detector and recognizer that are developed and trained independently and then lock their parameters to preserve their already acquired capabilities. Subsequently, we introduce a Bridge that connects the locked detector and recognizer through a zero-initialized neural network. This zero-initialized neural network, initialized with weights set to zeros, ensures seamless integration of the large receptive field features in detection into the locked recognizer. Furthermore, since the fixed detector and recognizer cannot naturally acquire end-to-end optimization features, we adopt the Adapter to facilitate their efficient learning of these features. We demonstrate the effectiveness of the proposed method through extensive experiments: Connecting the latest detector and recognizer through Bridging Text Spotting, we achieved an accuracy of 83.3% on Total-Text, 69.8% on CTW1500, and 89.5% on ICDAR 2015. The code is available at https://github.com/mxin262/Bridging-Text-Spotting.
SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
Apr 04, 2024Recent advances in 2D/3D generative models enable the generation of dynamic 3D objects from a single-view video. Existing approaches utilize score distillation sampling to form the dynamic scene as dynamic NeRF or dense 3D Gaussians. However, these methods struggle to strike a balance among reference view alignment, spatio-temporal consistency, and motion fidelity under single-view conditions due to the implicit nature of NeRF or the intricate dense Gaussian motion prediction. To address these issues, this paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. Moreover, we introduce Adaptive Gaussian (AG) initialization and Gaussian Alignment (GA) loss to mitigate shape degeneration issue, ensuring the fidelity of the learned motion and shape. Comprehensive experimental results demonstrate that our method surpasses existing methods in both quality and efficiency. In addition, facilitated by the disentangled modeling of motion and appearance of SC4D, we devise a novel application that seamlessly transfers the learned motion onto a diverse array of 4D entities according to textual descriptions.
OmniParser: A Unified Framework for Text Spotting, Key Information Extraction and Table Recognition
Mar 28, 2024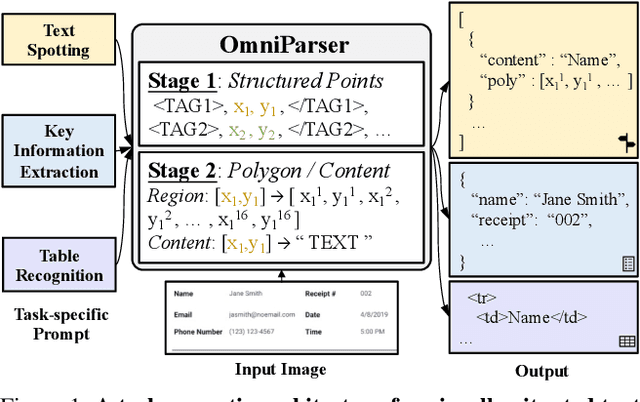
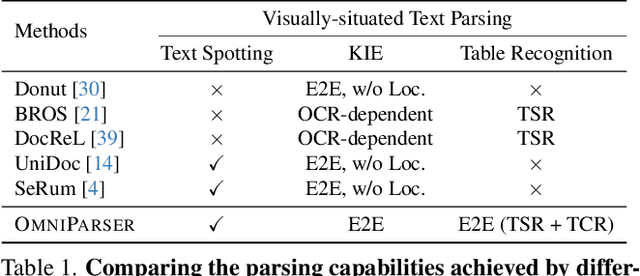
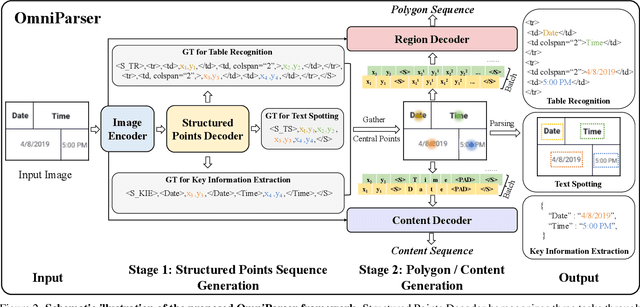
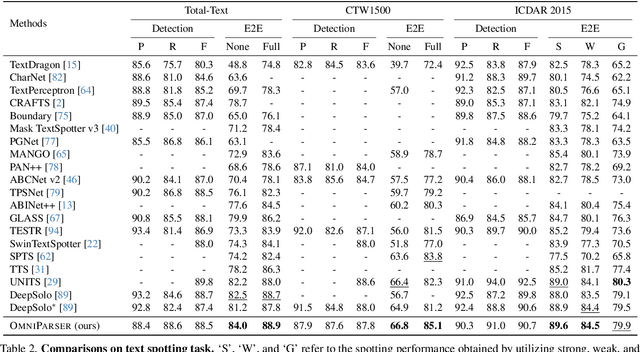
Recently, visually-situated text parsing (VsTP) has experienced notable advancements, driven by the increasing demand for automated document understanding and the emergence of Generative Large Language Models (LLMs) capable of processing document-based questions. Various methods have been proposed to address the challenging problem of VsTP. However, due to the diversified targets and heterogeneous schemas, previous works usually design task-specific architectures and objectives for individual tasks, which inadvertently leads to modal isolation and complex workflow. In this paper, we propose a unified paradigm for parsing visually-situated text across diverse scenarios. Specifically, we devise a universal model, called OmniParser, which can simultaneously handle three typical visually-situated text parsing tasks: text spotting, key information extraction, and table recognition. In OmniParser, all tasks share the unified encoder-decoder architecture, the unified objective: point-conditioned text generation, and the unified input & output representation: prompt & structured sequences. Extensive experiments demonstrate that the proposed OmniParser achieves state-of-the-art (SOTA) or highly competitive performances on 7 datasets for the three visually-situated text parsing tasks, despite its unified, concise design. The code is available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery.
PSALM: Pixelwise SegmentAtion with Large Multi-Modal Model
Mar 21, 2024



PSALM is a powerful extension of the Large Multi-modal Model (LMM) to address the segmentation task challenges. To overcome the limitation of the LMM being limited to textual output, PSALM incorporates a mask decoder and a well-designed input schema to handle a variety of segmentation tasks. This schema includes images, task instructions, conditional prompts, and mask tokens, which enable the model to generate and classify segmentation masks effectively. The flexible design of PSALM supports joint training across multiple datasets and tasks, leading to improved performance and task generalization. PSALM achieves superior results on several benchmarks, such as RefCOCO/RefCOCO+/RefCOCOg, COCO Panoptic Segmentation, and COCO-Interactive, and further exhibits zero-shot capabilities on unseen tasks, such as open-vocabulary segmentation, generalized referring expression segmentation and video object segmentation, making a significant step towards a GPT moment in computer vision. Through extensive experiments, PSALM demonstrates its potential to transform the domain of image segmentation, leveraging the robust visual understanding capabilities of LMMs as seen in natural language processing. Code and models are available at https://github.com/zamling/PSALM.