 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGloria: Consistent Character Video Generation via Content Anchors
Mar 31, 2026Digital characters are central to modern media, yet generating character videos with long-duration, consistent multi-view appearance and expressive identity remains challenging. Existing approaches either provide insufficient context to preserve identity or leverage non-character-centric information as the memory, leading to suboptimal consistency. Recognizing that character video generation inherently resembles an outside-looking-in scenario. In this work, we propose representing the character visual attributes through a compact set of anchor frames. This design provides stable references for consistency, while reference-based video generation inherently faces challenges of copy-pasting and multi-reference conflicts. To address these, we introduce two mechanisms: Superset Content Anchoring, providing intra- and extra-training clip cues to prevent duplication, and RoPE as Weak Condition, encoding positional offsets to distinguish multiple anchors. Furthermore, we construct a scalable pipeline to extract these anchors from massive videos. Experiments show our method generates high-quality character videos exceeding 10 minutes, and achieves expressive identity and appearance consistency across views, surpassing existing methods.
End-to-End Spatial-Temporal Transformer for Real-time 4D HOI Reconstruction
Mar 15, 2026Monocular 4D human-object interaction (HOI) reconstruction - recovering a moving human and a manipulated object from a single RGB video - remains challenging due to depth ambiguity and frequent occlusions. Existing methods often rely on multi-stage pipelines or iterative optimization, leading to high inference latency, failing to meet real-time requirements, and susceptibility to error accumulation. To address these limitations, we propose THO, an end-to-end Spatial-Temporal Transformer that predicts human motion and coordinated object motion in a forward fashion from the given video and 3D template. THO achieves this by leveraging spatial-temporal HOI tuple priors. Spatial priors exploit contact-region proximity to infer occluded object features from human cues, while temporal priors capture cross-frame kinematic correlations to refine object representations and enforce physical coherence. Extensive experiments demonstrate that THO operates at an inference speed of 31.5 FPS on a single RTX 4090 GPU, achieving a >600x speedup over prior optimization-based methods while simultaneously improving reconstruction accuracy and temporal consistency. The project page is available at: https://nianheng.github.io/THO-project/
EXPLORE-Bench: Egocentric Scene Prediction with Long-Horizon Reasoning
Mar 12, 2026Multimodal large language models (MLLMs) are increasingly considered as a foundation for embodied agents, yet it remains unclear whether they can reliably reason about the long-term physical consequences of actions from an egocentric viewpoint. We study this gap through a new task, Egocentric Scene Prediction with LOng-horizon REasoning: given an initial-scene image and a sequence of atomic action descriptions, a model is asked to predict the final scene after all actions are executed. To enable systematic evaluation, we introduce EXPLORE-Bench, a benchmark curated from real first-person videos spanning diverse scenarios. Each instance pairs long action sequences with structured final-scene annotations, including object categories, visual attributes, and inter-object relations, which supports fine-grained, quantitative assessment. Experiments on a range of proprietary and open-source MLLMs reveal a significant performance gap to humans, indicating that long-horizon egocentric reasoning remains a major challenge. We further analyze test-time scaling via stepwise reasoning and show that decomposing long action sequences can improve performance to some extent, while incurring non-trivial computational overhead. Overall, EXPLORE-Bench provides a principled testbed for measuring and advancing long-horizon reasoning for egocentric embodied perception.
Event-based Visual Deformation Measurement
Feb 16, 2026Visual Deformation Measurement (VDM) aims to recover dense deformation fields by tracking surface motion from camera observations. Traditional image-based methods rely on minimal inter-frame motion to constrain the correspondence search space, which limits their applicability to highly dynamic scenes or necessitates high-speed cameras at the cost of prohibitive storage and computational overhead. We propose an event-frame fusion framework that exploits events for temporally dense motion cues and frames for spatially dense precise estimation. Revisiting the solid elastic modeling prior, we propose an Affine Invariant Simplicial (AIS) framework. It partitions the deformation field into linearized sub-regions with low-parametric representation, effectively mitigating motion ambiguities arising from sparse and noisy events. To speed up parameter searching and reduce error accumulation, a neighborhood-greedy optimization strategy is introduced, enabling well-converged sub-regions to guide their poorly-converged neighbors, effectively suppress local error accumulation in long-term dense tracking. To evaluate the proposed method, a benchmark dataset with temporally aligned event streams and frames is established, encompassing over 120 sequences spanning diverse deformation scenarios. Experimental results show that our method outperforms the state-of-the-art baseline by 1.6% in survival rate. Remarkably, it achieves this using only 18.9% of the data storage and processing resources of high-speed video methods.
Unbiased Gradient Estimation for Event Binning via Functional Backpropagation
Feb 13, 2026Event-based vision encodes dynamic scenes as asynchronous spatio-temporal spikes called events. To leverage conventional image processing pipelines, events are typically binned into frames. However, binning functions are discontinuous, which truncates gradients at the frame level and forces most event-based algorithms to rely solely on frame-based features. Attempts to directly learn from raw events avoid this restriction but instead suffer from biased gradient estimation due to the discontinuities of the binning operation, ultimately limiting their learning efficiency. To address this challenge, we propose a novel framework for unbiased gradient estimation of arbitrary binning functions by synthesizing weak derivatives during backpropagation while keeping the forward output unchanged. The key idea is to exploit integration by parts: lifting the target functions to functionals yields an integral form of the derivative of the binning function during backpropagation, where the cotangent function naturally arises. By reconstructing this cotangent function from the sampled cotangent vector, we compute weak derivatives that provably match long-range finite differences of both smooth and non-smooth targets. Experimentally, our method improves simple optimization-based egomotion estimation with 3.2\% lower RMS error and 1.57$\times$ faster convergence. On complex downstream tasks, we achieve 9.4\% lower EPE in self-supervised optical flow, and 5.1\% lower RMS error in SLAM, demonstrating broad benefits for event-based visual perception. Source code can be found at https://github.com/chjz1024/EventFBP.
TrackTeller: Temporal Multimodal 3D Grounding for Behavior-Dependent Object References
Dec 25, 2025Understanding natural-language references to objects in dynamic 3D driving scenes is essential for interactive autonomous systems. In practice, many referring expressions describe targets through recent motion or short-term interactions, which cannot be resolved from static appearance or geometry alone. We study temporal language-based 3D grounding, where the objective is to identify the referred object in the current frame by leveraging multi-frame observations. We propose TrackTeller, a temporal multimodal grounding framework that integrates LiDAR-image fusion, language-conditioned decoding, and temporal reasoning in a unified architecture. TrackTeller constructs a shared UniScene representation aligned with textual semantics, generates language-aware 3D proposals, and refines grounding decisions using motion history and short-term dynamics. Experiments on the NuPrompt benchmark demonstrate that TrackTeller consistently improves language-grounded tracking performance, outperforming strong baselines with a 70% relative improvement in Average Multi-Object Tracking Accuracy and a 3.15-3.4 times reduction in False Alarm Frequency.
MatE: Material Extraction from Single-Image via Geometric Prior
Dec 20, 2025The creation of high-fidelity, physically-based rendering (PBR) materials remains a bottleneck in many graphics pipelines, typically requiring specialized equipment and expert-driven post-processing. To democratize this process, we present MatE, a novel method for generating tileable PBR materials from a single image taken under unconstrained, real-world conditions. Given an image and a user-provided mask, MatE first performs coarse rectification using an estimated depth map as a geometric prior, and then employs a dual-branch diffusion model. Leveraging a learned consistency from rotation-aligned and scale-aligned training data, this model further rectify residual distortions from the coarse result and translate it into a complete set of material maps, including albedo, normal, roughness and height. Our framework achieves invariance to the unknown illumination and perspective of the input image, allowing for the recovery of intrinsic material properties from casual captures. Through comprehensive experiments on both synthetic and real-world data, we demonstrate the efficacy and robustness of our approach, enabling users to create realistic materials from real-world image.
Anchoring Values in Temporal and Group Dimensions for Flow Matching Model Alignment
Dec 13, 2025Group Relative Policy Optimization (GRPO) has proven highly effective in enhancing the alignment capabilities of Large Language Models (LLMs). However, current adaptations of GRPO for the flow matching-based image generation neglect a foundational conflict between its core principles and the distinct dynamics of the visual synthesis process. This mismatch leads to two key limitations: (i) Uniformly applying a sparse terminal reward across all timesteps impairs temporal credit assignment, ignoring the differing criticality of generation phases from early structure formation to late-stage tuning. (ii) Exclusive reliance on relative, intra-group rewards causes the optimization signal to fade as training converges, leading to the optimization stagnation when reward diversity is entirely depleted. To address these limitations, we propose Value-Anchored Group Policy Optimization (VGPO), a framework that redefines value estimation across both temporal and group dimensions. Specifically, VGPO transforms the sparse terminal reward into dense, process-aware value estimates, enabling precise credit assignment by modeling the expected cumulative reward at each generative stage. Furthermore, VGPO replaces standard group normalization with a novel process enhanced by absolute values to maintain a stable optimization signal even as reward diversity declines. Extensive experiments on three benchmarks demonstrate that VGPO achieves state-of-the-art image quality while simultaneously improving task-specific accuracy, effectively mitigating reward hacking. Project webpage: https://yawen-shao.github.io/VGPO/.
Beyond Randomness: Understand the Order of the Noise in Diffusion
Nov 11, 2025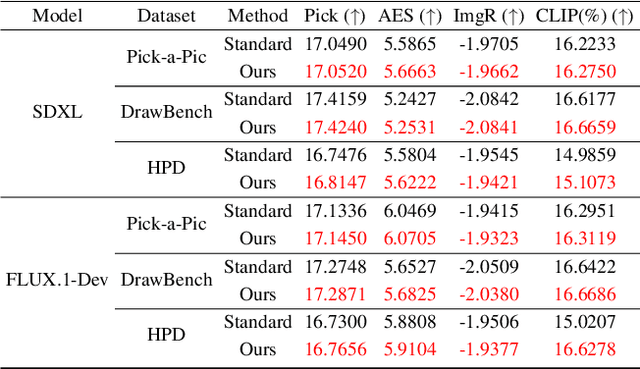
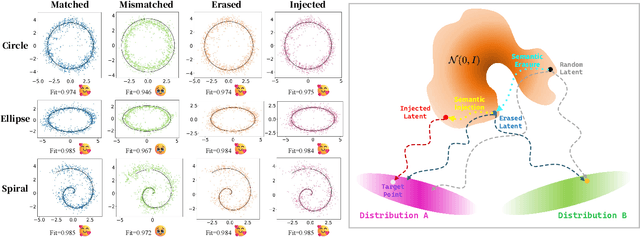


In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.
AliTok: Towards Sequence Modeling Alignment between Tokenizer and Autoregressive Model
Jun 05, 2025Autoregressive image generation aims to predict the next token based on previous ones. However, existing image tokenizers encode tokens with bidirectional dependencies during the compression process, which hinders the effective modeling by autoregressive models. In this paper, we propose a novel Aligned Tokenizer (AliTok), which utilizes a causal decoder to establish unidirectional dependencies among encoded tokens, thereby aligning the token modeling approach between the tokenizer and autoregressive model. Furthermore, by incorporating prefix tokens and employing two-stage tokenizer training to enhance reconstruction consistency, AliTok achieves great reconstruction performance while being generation-friendly. On ImageNet-256 benchmark, using a standard decoder-only autoregressive model as the generator with only 177M parameters, AliTok achieves a gFID score of 1.50 and an IS of 305.9. When the parameter count is increased to 662M, AliTok achieves a gFID score of 1.35, surpassing the state-of-the-art diffusion method with 10x faster sampling speed. The code and weights are available at https://github.com/ali-vilab/alitok.