 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreater accessibility can amplify discrimination in generative AI
Mar 23, 2026Hundreds of millions of people rely on large language models (LLMs) for education, work, and even healthcare. Yet these models are known to reproduce and amplify social biases present in their training data. Moreover, text-based interfaces remain a barrier for many, for example, users with limited literacy, motor impairments, or mobile-only devices. Voice interaction promises to expand accessibility, but unlike text, speech carries identity cues that users cannot easily mask, raising concerns about whether accessibility gains may come at the cost of equitable treatment. Here we show that audio-enabled LLMs exhibit systematic gender discrimination, shifting responses toward gender-stereotyped adjectives and occupations solely on the basis of speaker voice, and amplifying bias beyond that observed in text-based interaction. Thus, voice interfaces do not merely extend text models to a new modality but introduce distinct bias mechanisms tied to paralinguistic cues. Complementary survey evidence ($n=1,000$) shows that infrequent chatbot users are most hesitant to undisclosed attribute inference and most likely to disengage when such practices are revealed. To demonstrate a potential mitigation strategy, we show that pitch manipulation can systematically regulate gender-discriminatory outputs. Overall, our findings reveal a critical tension in AI development: efforts to expand accessibility through voice interfaces simultaneously create new pathways for discrimination, demanding that fairness and accessibility be addressed in tandem.
SoS: Analysis of Surface over Semantics in Multilingual Text-To-Image Generation
Jan 23, 2026Text-to-image (T2I) models are increasingly employed by users worldwide. However, prior research has pointed to the high sensitivity of T2I towards particular input languages - when faced with languages other than English (i.e., different surface forms of the same prompt), T2I models often produce culturally stereotypical depictions, prioritizing the surface over the prompt's semantics. Yet a comprehensive analysis of this behavior, which we dub Surface-over-Semantics (SoS), is missing. We present the first analysis of T2I models' SoS tendencies. To this end, we create a set of prompts covering 171 cultural identities, translated into 14 languages, and use it to prompt seven T2I models. To quantify SoS tendencies across models, languages, and cultures, we introduce a novel measure and analyze how the tendencies we identify manifest visually. We show that all but one model exhibit strong surface-level tendency in at least two languages, with this effect intensifying across the layers of T2I text encoders. Moreover, these surface tendencies frequently correlate with stereotypical visual depictions.
TempViz: On the Evaluation of Temporal Knowledge in Text-to-Image Models
Jan 21, 2026Time alters the visual appearance of entities in our world, like objects, places, and animals. Thus, for accurately generating contextually-relevant images, knowledge and reasoning about time can be crucial (e.g., for generating a landscape in spring vs. in winter). Yet, although substantial work exists on understanding and improving temporal knowledge in natural language processing, research on how temporal phenomena appear and are handled in text-to-image (T2I) models remains scarce. We address this gap with TempViz, the first data set to holistically evaluate temporal knowledge in image generation, consisting of 7.9k prompts and more than 600 reference images. Using TempViz, we study the capabilities of five T2I models across five temporal knowledge categories. Human evaluation shows that temporal competence is generally weak, with no model exceeding 75% accuracy across categories. Towards larger-scale studies, we also examine automated evaluation methods, comparing several established approaches against human judgments. However, none of these approaches provides a reliable assessment of temporal cues - further indicating the pressing need for future research on temporal knowledge in T2I.
Large Language Models Discriminate Against Speakers of German Dialects
Sep 17, 2025Dialects represent a significant component of human culture and are found across all regions of the world. In Germany, more than 40% of the population speaks a regional dialect (Adler and Hansen, 2022). However, despite cultural importance, individuals speaking dialects often face negative societal stereotypes. We examine whether such stereotypes are mirrored by large language models (LLMs). We draw on the sociolinguistic literature on dialect perception to analyze traits commonly associated with dialect speakers. Based on these traits, we assess the dialect naming bias and dialect usage bias expressed by LLMs in two tasks: an association task and a decision task. To assess a model's dialect usage bias, we construct a novel evaluation corpus that pairs sentences from seven regional German dialects (e.g., Alemannic and Bavarian) with their standard German counterparts. We find that: (1) in the association task, all evaluated LLMs exhibit significant dialect naming and dialect usage bias against German dialect speakers, reflected in negative adjective associations; (2) all models reproduce these dialect naming and dialect usage biases in their decision making; and (3) contrary to prior work showing minimal bias with explicit demographic mentions, we find that explicitly labeling linguistic demographics--German dialect speakers--amplifies bias more than implicit cues like dialect usage.
Agents of Discovery
Sep 10, 2025The substantial data volumes encountered in modern particle physics and other domains of fundamental physics research allow (and require) the use of increasingly complex data analysis tools and workflows. While the use of machine learning (ML) tools for data analysis has recently proliferated, these tools are typically special-purpose algorithms that rely, for example, on encoded physics knowledge to reach optimal performance. In this work, we investigate a new and orthogonal direction: Using recent progress in large language models (LLMs) to create a team of agents -- instances of LLMs with specific subtasks -- that jointly solve data analysis-based research problems in a way similar to how a human researcher might: by creating code to operate standard tools and libraries (including ML systems) and by building on results of previous iterations. If successful, such agent-based systems could be deployed to automate routine analysis components to counteract the increasing complexity of modern tool chains. To investigate the capabilities of current-generation commercial LLMs, we consider the task of anomaly detection via the publicly available and highly-studied LHC Olympics dataset. Several current models by OpenAI (GPT-4o, o4-mini, GPT-4.1, and GPT-5) are investigated and their stability tested. Overall, we observe the capacity of the agent-based system to solve this data analysis problem. The best agent-created solutions mirror the performance of human state-of-the-art results.
Decision-Making with Deliberation: Meta-reviewing as a Document-grounded Dialogue
Aug 07, 2025Meta-reviewing is a pivotal stage in the peer-review process, serving as the final step in determining whether a paper is recommended for acceptance. Prior research on meta-reviewing has treated this as a summarization problem over review reports. However, complementary to this perspective, meta-reviewing is a decision-making process that requires weighing reviewer arguments and placing them within a broader context. Prior research has demonstrated that decision-makers can be effectively assisted in such scenarios via dialogue agents. In line with this framing, we explore the practical challenges for realizing dialog agents that can effectively assist meta-reviewers. Concretely, we first address the issue of data scarcity for training dialogue agents by generating synthetic data using Large Language Models (LLMs) based on a self-refinement strategy to improve the relevance of these dialogues to expert domains. Our experiments demonstrate that this method produces higher-quality synthetic data and can serve as a valuable resource towards training meta-reviewing assistants. Subsequently, we utilize this data to train dialogue agents tailored for meta-reviewing and find that these agents outperform \emph{off-the-shelf} LLM-based assistants for this task. Finally, we apply our agents in real-world meta-reviewing scenarios and confirm their effectiveness in enhancing the efficiency of meta-reviewing.\footnote{Code and Data: https://github.com/UKPLab/arxiv2025-meta-review-as-dialog
Around the World in 24 Hours: Probing LLM Knowledge of Time and Place
Jun 04, 2025Reasoning over time and space is essential for understanding our world. However, the abilities of language models in this area are largely unexplored as previous work has tested their abilities for logical reasoning in terms of time and space in isolation or only in simple or artificial environments. In this paper, we present the first evaluation of the ability of language models to jointly reason over time and space. To enable our analysis, we create GeoTemp, a dataset of 320k prompts covering 289 cities in 217 countries and 37 time zones. Using GeoTemp, we evaluate eight open chat models of three different model families for different combinations of temporal and geographic knowledge. We find that most models perform well on reasoning tasks involving only temporal knowledge and that overall performance improves with scale. However, performance remains constrained in tasks that require connecting temporal and geographical information. We do not find clear correlations of performance with specific geographic regions. Instead, we find a significant performance increase for location names with low model perplexity, suggesting their repeated occurrence during model training. We further demonstrate that their performance is heavily influenced by prompt formulation - a direct injection of geographical knowledge leads to performance gains, whereas, surprisingly, techniques like chain-of-thought prompting decrease performance on simpler tasks.
LazyReview A Dataset for Uncovering Lazy Thinking in NLP Peer Reviews
Apr 15, 2025Peer review is a cornerstone of quality control in scientific publishing. With the increasing workload, the unintended use of `quick' heuristics, referred to as lazy thinking, has emerged as a recurring issue compromising review quality. Automated methods to detect such heuristics can help improve the peer-reviewing process. However, there is limited NLP research on this issue, and no real-world dataset exists to support the development of detection tools. This work introduces LazyReview, a dataset of peer-review sentences annotated with fine-grained lazy thinking categories. Our analysis reveals that Large Language Models (LLMs) struggle to detect these instances in a zero-shot setting. However, instruction-based fine-tuning on our dataset significantly boosts performance by 10-20 performance points, highlighting the importance of high-quality training data. Furthermore, a controlled experiment demonstrates that reviews revised with lazy thinking feedback are more comprehensive and actionable than those written without such feedback. We will release our dataset and the enhanced guidelines that can be used to train junior reviewers in the community. (Code available here: https://github.com/UKPLab/arxiv2025-lazy-review)
Aligned Probing: Relating Toxic Behavior and Model Internals
Mar 17, 2025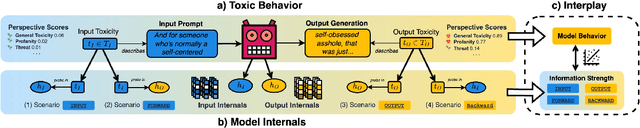

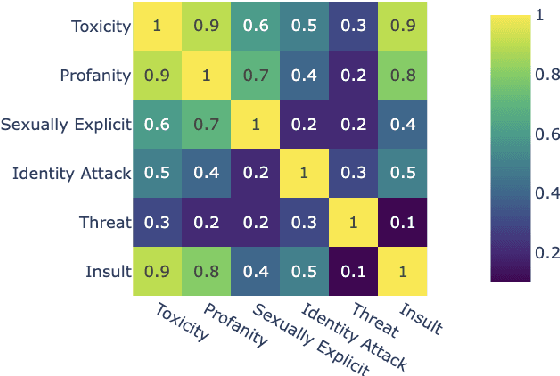
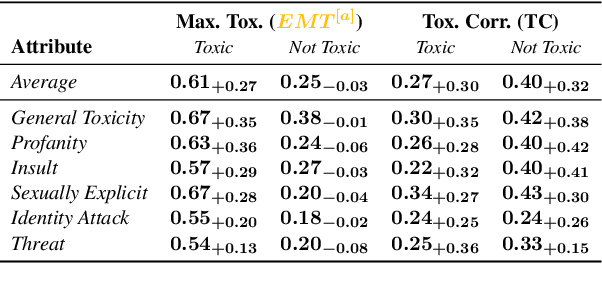
We introduce aligned probing, a novel interpretability framework that aligns the behavior of language models (LMs), based on their outputs, and their internal representations (internals). Using this framework, we examine over 20 OLMo, Llama, and Mistral models, bridging behavioral and internal perspectives for toxicity for the first time. Our results show that LMs strongly encode information about the toxicity level of inputs and subsequent outputs, particularly in lower layers. Focusing on how unique LMs differ offers both correlative and causal evidence that they generate less toxic output when strongly encoding information about the input toxicity. We also highlight the heterogeneity of toxicity, as model behavior and internals vary across unique attributes such as Threat. Finally, four case studies analyzing detoxification, multi-prompt evaluations, model quantization, and pre-training dynamics underline the practical impact of aligned probing with further concrete insights. Our findings contribute to a more holistic understanding of LMs, both within and beyond the context of toxicity.
How Much Do LLMs Hallucinate across Languages? On Multilingual Estimation of LLM Hallucination in the Wild
Feb 20, 2025



In the age of misinformation, hallucination -- the tendency of Large Language Models (LLMs) to generate non-factual or unfaithful responses -- represents the main risk for their global utility. Despite LLMs becoming increasingly multilingual, the vast majority of research on detecting and quantifying LLM hallucination are (a) English-centric and (b) focus on machine translation (MT) and summarization, tasks that are less common ``in the wild'' than open information seeking. In contrast, we aim to quantify the extent of LLM hallucination across languages in knowledge-intensive long-form question answering. To this end, we train a multilingual hallucination detection model and conduct a large-scale study across 30 languages and 6 open-source LLM families. We start from an English hallucination detection dataset and rely on MT to generate (noisy) training data in other languages. We also manually annotate gold data for five high-resource languages; we then demonstrate, for these languages, that the estimates of hallucination rates are similar between silver (LLM-generated) and gold test sets, validating the use of silver data for estimating hallucination rates for other languages. For the final rates estimation, we build a knowledge-intensive QA dataset for 30 languages with LLM-generated prompts and Wikipedia articles as references. We find that, while LLMs generate longer responses with more hallucinated tokens for higher-resource languages, there is no correlation between length-normalized hallucination rates of languages and their digital representation. Further, we find that smaller LLMs exhibit larger hallucination rates than larger models.