 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Make BERT-based Chinese Spelling Check Model Enhanced by Layerwise Attention and Gaussian Mixture Model
Dec 27, 2023
BERT-based models have shown a remarkable ability in the Chinese Spelling Check (CSC) task recently. However, traditional BERT-based methods still suffer from two limitations. First, although previous works have identified that explicit prior knowledge like Part-Of-Speech (POS) tagging can benefit in the CSC task, they neglected the fact that spelling errors inherent in CSC data can lead to incorrect tags and therefore mislead models. Additionally, they ignored the correlation between the implicit hierarchical information encoded by BERT's intermediate layers and different linguistic phenomena. This results in sub-optimal accuracy. To alleviate the above two issues, we design a heterogeneous knowledge-infused framework to strengthen BERT-based CSC models. To incorporate explicit POS knowledge, we utilize an auxiliary task strategy driven by Gaussian mixture model. Meanwhile, to incorporate implicit hierarchical linguistic knowledge within the encoder, we propose a novel form of n-gram-based layerwise self-attention to generate a multilayer representation. Experimental results show that our proposed framework yields a stable performance boost over four strong baseline models and outperforms the previous state-of-the-art methods on two datasets.
* 10 pages, 4 figures, 2023 International Joint Conference on Neural Networks (IJCNN)
Extending Whisper with prompt tuning to target-speaker ASR
Dec 13, 2023Target-speaker automatic speech recognition (ASR) aims to transcribe the desired speech of a target speaker from multi-talker overlapped utterances. Most of the existing target-speaker ASR (TS-ASR) methods involve either training from scratch or fully fine-tuning a pre-trained model, leading to significant training costs and becoming inapplicable to large foundation models. This work leverages prompt tuning, a parameter-efficient fine-tuning approach, to extend Whisper, a large-scale single-talker ASR model, to TS-ASR. Experimental results show that prompt tuning can achieve performance comparable to state-of-the-art full fine-tuning approaches while only requiring about 1% of task-specific model parameters. Notably, the original Whisper's features, such as inverse text normalization and timestamp prediction, are retained in target-speaker ASR, keeping the generated transcriptions natural and informative.
Enhancing Consistency in Multimodal Dialogue System Using LLM with Dialogue Scenario
Dec 20, 2023This paper describes our dialogue system submitted to Dialogue Robot Competition 2023. The system's task is to help a user at a travel agency decide on a plan for visiting two sightseeing spots in Kyoto City that satisfy the user. Our dialogue system is flexible and stable and responds to user requirements by controlling dialogue flow according to dialogue scenarios. We also improved user satisfaction by introducing motion and speech control based on system utterances and user situations. In the preliminary round, our system was ranked fifth in the impression evaluation and sixth in the plan evaluation among all 12 teams.
Acoustic BPE for Speech Generation with Discrete Tokens
Oct 23, 2023Discrete audio tokens derived from self-supervised learning models have gained widespread usage in speech generation. However, current practice of directly utilizing audio tokens poses challenges for sequence modeling due to the length of the token sequence. Additionally, this approach places the burden on the model to establish correlations between tokens, further complicating the modeling process. To address this issue, we propose acoustic BPE which encodes frequent audio token patterns by utilizing byte-pair encoding. Acoustic BPE effectively reduces the sequence length and leverages the prior morphological information present in token sequence, which alleviates the modeling challenges of token correlation. Through comprehensive investigations on a speech language model trained with acoustic BPE, we confirm the notable advantages it offers, including faster inference and improved syntax capturing capabilities. In addition, we propose a novel rescore method to select the optimal synthetic speech among multiple candidates generated by rich-diversity TTS system. Experiments prove that rescore selection aligns closely with human preference, which highlights acoustic BPE's potential to other speech generation tasks.
Audio-visual fine-tuning of audio-only ASR models
Dec 14, 2023Audio-visual automatic speech recognition (AV-ASR) models are very effective at reducing word error rates on noisy speech, but require large amounts of transcribed AV training data. Recently, audio-visual self-supervised learning (SSL) approaches have been developed to reduce this dependence on transcribed AV data, but these methods are quite complex and computationally expensive. In this work, we propose replacing these expensive AV-SSL methods with a simple and fast \textit{audio-only} SSL method, and then performing AV supervised fine-tuning. We show that this approach is competitive with state-of-the-art (SOTA) AV-SSL methods on the LRS3-TED benchmark task (within 0.5% absolute WER), while being dramatically simpler and more efficient (12-30x faster to pre-train). Furthermore, we show we can extend this approach to convert a SOTA audio-only ASR model into an AV model. By doing so, we match SOTA AV-SSL results, even though no AV data was used during pre-training.
AE-Flow: AutoEncoder Normalizing Flow
Dec 27, 2023Recently normalizing flows have been gaining traction in text-to-speech (TTS) and voice conversion (VC) due to their state-of-the-art (SOTA) performance. Normalizing flows are unsupervised generative models. In this paper, we introduce supervision to the training process of normalizing flows, without the need for parallel data. We call this training paradigm AutoEncoder Normalizing Flow (AE-Flow). It adds a reconstruction loss forcing the model to use information from the conditioning to reconstruct an audio sample. Our goal is to understand the impact of each component and find the right combination of the negative log-likelihood (NLL) and the reconstruction loss in training normalizing flows with coupling blocks. For that reason we will compare flow-based mapping model trained with: (i) NLL loss, (ii) NLL and reconstruction losses, as well as (iii) reconstruction loss only. Additionally, we compare our model with SOTA VC baseline. The models are evaluated in terms of naturalness, speaker similarity, intelligibility in many-to-many and many-to-any VC settings. The results show that the proposed training paradigm systematically improves speaker similarity and naturalness when compared to regular training methods of normalizing flows. Furthermore, we show that our method improves speaker similarity and intelligibility over the state-of-the-art.
HCDIR: End-to-end Hate Context Detection, and Intensity Reduction model for online comments
Dec 20, 2023Warning: This paper contains examples of the language that some people may find offensive. Detecting and reducing hateful, abusive, offensive comments is a critical and challenging task on social media. Moreover, few studies aim to mitigate the intensity of hate speech. While studies have shown that context-level semantics are crucial for detecting hateful comments, most of this research focuses on English due to the ample datasets available. In contrast, low-resource languages, like Indian languages, remain under-researched because of limited datasets. Contrary to hate speech detection, hate intensity reduction remains unexplored in high-resource and low-resource languages. In this paper, we propose a novel end-to-end model, HCDIR, for Hate Context Detection, and Hate Intensity Reduction in social media posts. First, we fine-tuned several pre-trained language models to detect hateful comments to ascertain the best-performing hateful comments detection model. Then, we identified the contextual hateful words. Identification of such hateful words is justified through the state-of-the-art explainable learning model, i.e., Integrated Gradient (IG). Lastly, the Masked Language Modeling (MLM) model has been employed to capture domain-specific nuances to reduce hate intensity. We masked the 50\% hateful words of the comments identified as hateful and predicted the alternative words for these masked terms to generate convincing sentences. An optimal replacement for the original hate comments from the feasible sentences is preferred. Extensive experiments have been conducted on several recent datasets using automatic metric-based evaluation (BERTScore) and thorough human evaluation. To enhance the faithfulness in human evaluation, we arranged a group of three human annotators with varied expertise.
DASpeech: Directed Acyclic Transformer for Fast and High-quality Speech-to-Speech Translation
Oct 11, 2023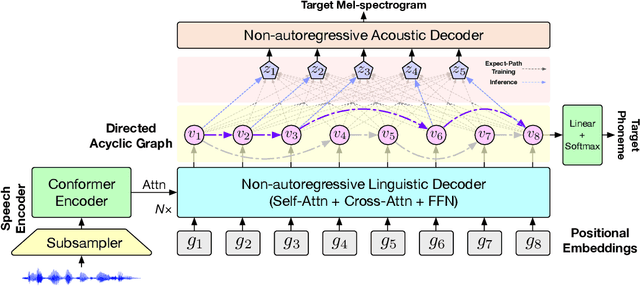
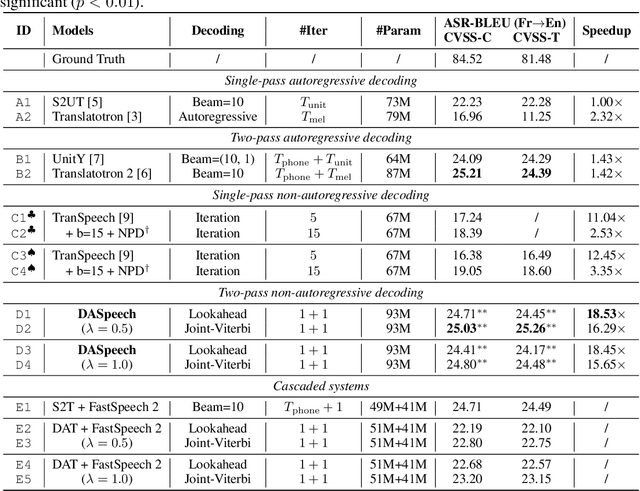
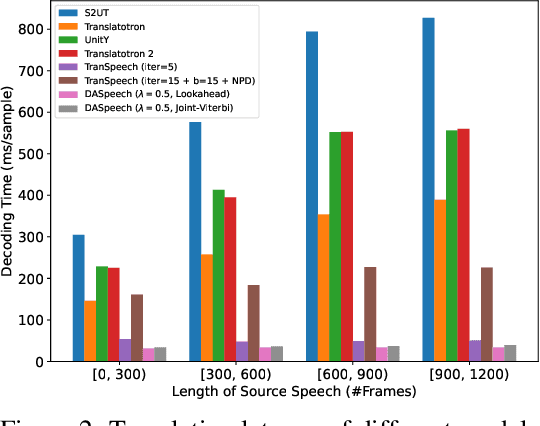
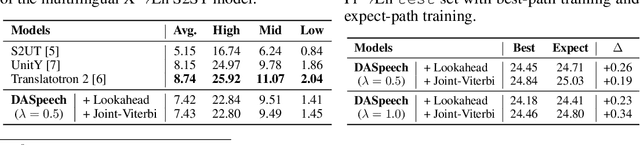
Direct speech-to-speech translation (S2ST) translates speech from one language into another using a single model. However, due to the presence of linguistic and acoustic diversity, the target speech follows a complex multimodal distribution, posing challenges to achieving both high-quality translations and fast decoding speeds for S2ST models. In this paper, we propose DASpeech, a non-autoregressive direct S2ST model which realizes both fast and high-quality S2ST. To better capture the complex distribution of the target speech, DASpeech adopts the two-pass architecture to decompose the generation process into two steps, where a linguistic decoder first generates the target text, and an acoustic decoder then generates the target speech based on the hidden states of the linguistic decoder. Specifically, we use the decoder of DA-Transformer as the linguistic decoder, and use FastSpeech 2 as the acoustic decoder. DA-Transformer models translations with a directed acyclic graph (DAG). To consider all potential paths in the DAG during training, we calculate the expected hidden states for each target token via dynamic programming, and feed them into the acoustic decoder to predict the target mel-spectrogram. During inference, we select the most probable path and take hidden states on that path as input to the acoustic decoder. Experiments on the CVSS Fr-En benchmark demonstrate that DASpeech can achieve comparable or even better performance than the state-of-the-art S2ST model Translatotron 2, while preserving up to 18.53x speedup compared to the autoregressive baseline. Compared with the previous non-autoregressive S2ST model, DASpeech does not rely on knowledge distillation and iterative decoding, achieving significant improvements in both translation quality and decoding speed. Furthermore, DASpeech shows the ability to preserve the speaker's voice of the source speech during translation.
An Exploration of In-Context Learning for Speech Language Model
Oct 19, 2023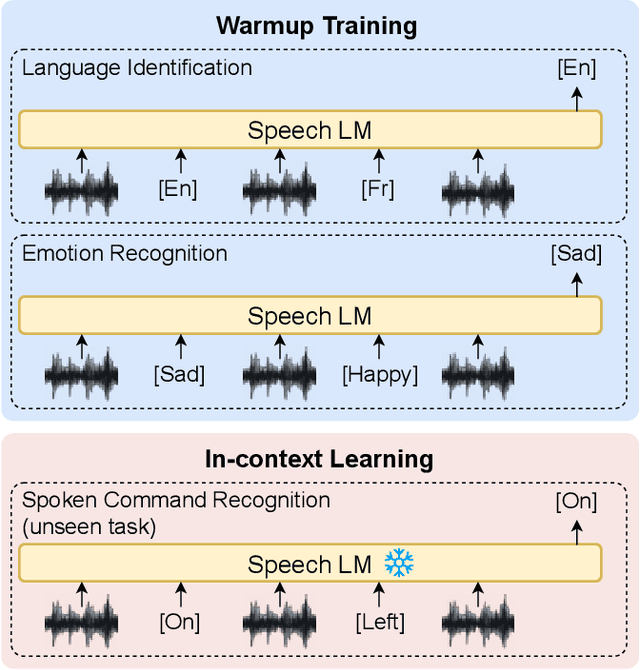
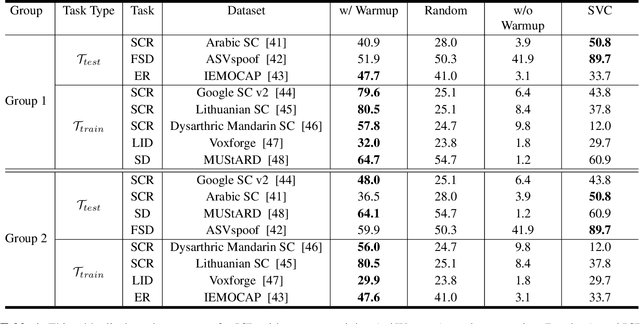
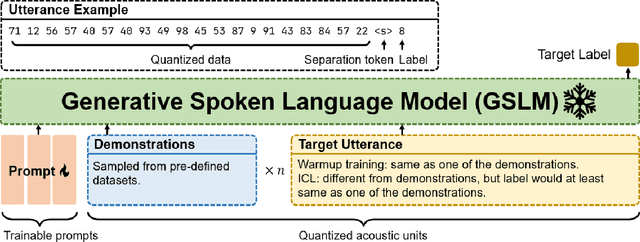
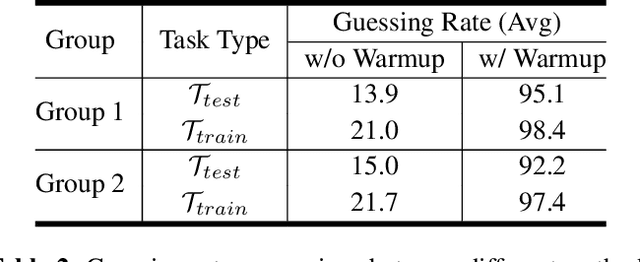
Ever since the development of GPT-3 in the natural language processing (NLP) field, in-context learning (ICL) has played an important role in utilizing large language models (LLMs). By presenting the LM utterance-label demonstrations at the input, the LM can accomplish few-shot learning without relying on gradient descent or requiring explicit modification of its parameters. This enables the LM to learn and adapt in a black-box manner. Despite the success of ICL in NLP, little work is exploring the possibility of ICL in speech processing. This study proposes the first exploration of ICL with a speech LM without text supervision. We first show that the current speech LM does not have the ICL capability. With the proposed warmup training, the speech LM can, therefore, perform ICL on unseen tasks. In this work, we verify the feasibility of ICL for speech LM on speech classification tasks.
TorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023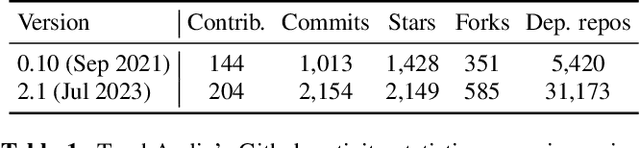


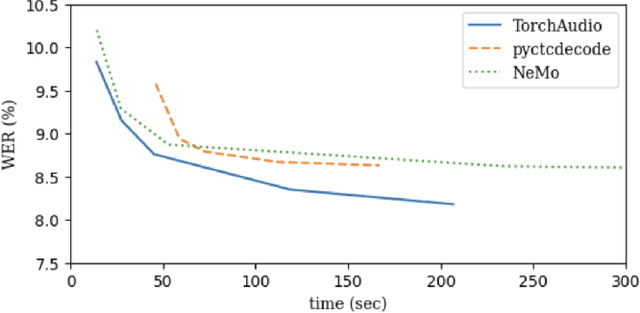
TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.