 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
DPP-TTS: Diversifying prosodic features of speech via determinantal point processes
Oct 23, 2023
With the rapid advancement in deep generative models, recent neural Text-To-Speech(TTS) models have succeeded in synthesizing human-like speech. There have been some efforts to generate speech with various prosody beyond monotonous prosody patterns. However, previous works have several limitations. First, typical TTS models depend on the scaled sampling temperature for boosting the diversity of prosody. Speech samples generated at high sampling temperatures often lack perceptual prosodic diversity, which can adversely affect the naturalness of the speech. Second, the diversity among samples is neglected since the sampling procedure often focuses on a single speech sample rather than multiple ones. In this paper, we propose DPP-TTS: a text-to-speech model based on Determinantal Point Processes (DPPs) with a prosody diversifying module. Our TTS model is capable of generating speech samples that simultaneously consider perceptual diversity in each sample and among multiple samples. We demonstrate that DPP-TTS generates speech samples with more diversified prosody than baselines in the side-by-side comparison test considering the naturalness of speech at the same time.
Scenario-Aware Audio-Visual TF-GridNet for Target Speech Extraction
Oct 30, 2023Target speech extraction aims to extract, based on a given conditioning cue, a target speech signal that is corrupted by interfering sources, such as noise or competing speakers. Building upon the achievements of the state-of-the-art (SOTA) time-frequency speaker separation model TF-GridNet, we propose AV-GridNet, a visual-grounded variant that incorporates the face recording of a target speaker as a conditioning factor during the extraction process. Recognizing the inherent dissimilarities between speech and noise signals as interfering sources, we also propose SAV-GridNet, a scenario-aware model that identifies the type of interfering scenario first and then applies a dedicated expert model trained specifically for that scenario. Our proposed model achieves SOTA results on the second COG-MHEAR Audio-Visual Speech Enhancement Challenge, outperforming other models by a significant margin, objectively and in a listening test. We also perform an extensive analysis of the results under the two scenarios.
Seeing Through the Conversation: Audio-Visual Speech Separation based on Diffusion Model
Oct 30, 2023The objective of this work is to extract target speaker's voice from a mixture of voices using visual cues. Existing works on audio-visual speech separation have demonstrated their performance with promising intelligibility, but maintaining naturalness remains a challenge. To address this issue, we propose AVDiffuSS, an audio-visual speech separation model based on a diffusion mechanism known for its capability in generating natural samples. For an effective fusion of the two modalities for diffusion, we also propose a cross-attention-based feature fusion mechanism. This mechanism is specifically tailored for the speech domain to integrate the phonetic information from audio-visual correspondence in speech generation. In this way, the fusion process maintains the high temporal resolution of the features, without excessive computational requirements. We demonstrate that the proposed framework achieves state-of-the-art results on two benchmarks, including VoxCeleb2 and LRS3, producing speech with notably better naturalness.
Cross-Linguistic Offensive Language Detection: BERT-Based Analysis of Bengali, Assamese, & Bodo Conversational Hateful Content from Social Media
Dec 16, 2023In today's age, social media reigns as the paramount communication platform, providing individuals with the avenue to express their conjectures, intellectual propositions, and reflections. Unfortunately, this freedom often comes with a downside as it facilitates the widespread proliferation of hate speech and offensive content, leaving a deleterious impact on our world. Thus, it becomes essential to discern and eradicate such offensive material from the realm of social media. This article delves into the comprehensive results and key revelations from the HASOC-2023 offensive language identification result. The primary emphasis is placed on the meticulous detection of hate speech within the linguistic domains of Bengali, Assamese, and Bodo, forming the framework for Task 4: Annihilate Hates. In this work, we used BERT models, including XML-Roberta, L3-cube, IndicBERT, BenglaBERT, and BanglaHateBERT. The research outcomes were promising and showed that XML-Roberta-lagre performed better than monolingual models in most cases. Our team 'TeamBD' achieved rank 3rd for Task 4 - Assamese, & 5th for Bengali.
Privacy-preserving Representation Learning for Speech Understanding
Oct 26, 2023Existing privacy-preserving speech representation learning methods target a single application domain. In this paper, we present a novel framework to anonymize utterance-level speech embeddings generated by pre-trained encoders and show its effectiveness for a range of speech classification tasks. Specifically, given the representations from a pre-trained encoder, we train a Transformer to estimate the representations for the same utterances spoken by other speakers. During inference, the extracted representations can be converted into different identities to preserve privacy. We compare the results with the voice anonymization baselines from the VoicePrivacy 2022 challenge. We evaluate our framework on speaker identification for privacy and emotion recognition, depression classification, and intent classification for utility. Our method outperforms the baselines on privacy and utility in paralinguistic tasks and achieves comparable performance for intent classification.
Rapid Speaker Adaptation in Low Resource Text to Speech Systems using Synthetic Data and Transfer learning
Dec 02, 2023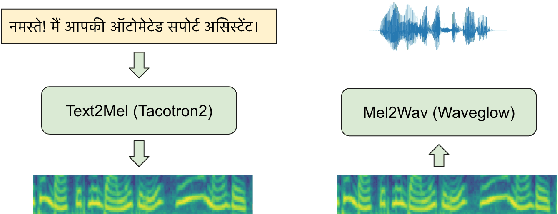

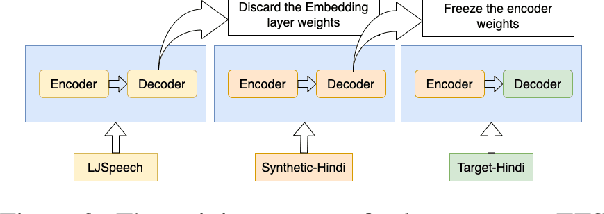
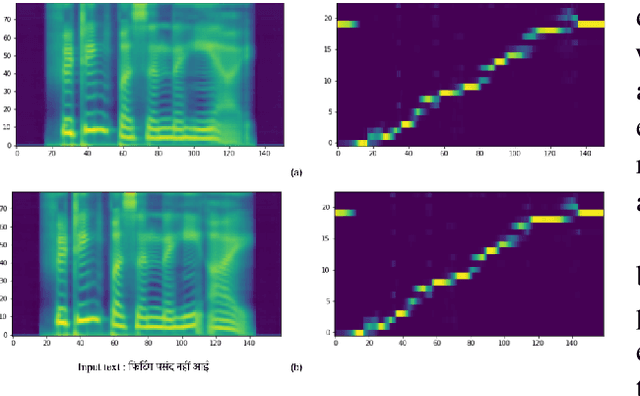
Text-to-speech (TTS) systems are being built using end-to-end deep learning approaches. However, these systems require huge amounts of training data. We present our approach to built production quality TTS and perform speaker adaptation in extremely low resource settings. We propose a transfer learning approach using high-resource language data and synthetically generated data. We transfer the learnings from the out-domain high-resource English language. Further, we make use of out-of-the-box single-speaker TTS in the target language to generate in-domain synthetic data. We employ a three-step approach to train a high-quality single-speaker TTS system in a low-resource Indian language Hindi. We use a Tacotron2 like setup with a spectrogram prediction network and a waveglow vocoder. The Tacotron2 acoustic model is trained on English data, followed by synthetic Hindi data from the existing TTS system. Finally, the decoder of this model is fine-tuned on only 3 hours of target Hindi speaker data to enable rapid speaker adaptation. We show the importance of this dual pre-training and decoder-only fine-tuning using subjective MOS evaluation. Using transfer learning from high-resource language and synthetic corpus we present a low-cost solution to train a custom TTS model.
Personalized Speech-driven Expressive 3D Facial Animation Synthesis with Style Control
Oct 25, 2023Different people have different facial expressions while speaking emotionally. A realistic facial animation system should consider such identity-specific speaking styles and facial idiosyncrasies to achieve high-degree of naturalness and plausibility. Existing approaches to personalized speech-driven 3D facial animation either use one-hot identity labels or rely-on person specific models which limit their scalability. We present a personalized speech-driven expressive 3D facial animation synthesis framework that models identity specific facial motion as latent representations (called as styles), and synthesizes novel animations given a speech input with the target style for various emotion categories. Our framework is trained in an end-to-end fashion and has a non-autoregressive encoder-decoder architecture with three main components: expression encoder, speech encoder and expression decoder. Since, expressive facial motion includes both identity-specific style and speech-related content information; expression encoder first disentangles facial motion sequences into style and content representations, respectively. Then, both of the speech encoder and the expression decoders input the extracted style information to update transformer layer weights during training phase. Our speech encoder also extracts speech phoneme label and duration information to achieve better synchrony within the non-autoregressive synthesis mechanism more effectively. Through detailed experiments, we demonstrate that our approach produces temporally coherent facial expressions from input speech while preserving the speaking styles of the target identities.
Causal Understanding of Why Users Share Hate Speech on Social Media
Oct 24, 2023Hate speech on social media threatens the mental and physical well-being of individuals and is further responsible for real-world violence. An important driver behind the spread of hate speech and thus why hateful posts can go viral are reshares, yet little is known about why users reshare hate speech. In this paper, we present a comprehensive, causal analysis of the user attributes that make users reshare hate speech. However, causal inference from observational social media data is challenging, because such data likely suffer from selection bias, and there is further confounding due to differences in the vulnerability of users to hate speech. We develop a novel, three-step causal framework: (1) We debias the observational social media data by applying inverse propensity scoring. (2) We use the debiased propensity scores to model the latent vulnerability of users to hate speech as a latent embedding. (3) We model the causal effects of user attributes on users' probability of sharing hate speech, while controlling for the latent vulnerability of users to hate speech. Compared to existing baselines, a particular strength of our framework is that it models causal effects that are non-linear, yet still explainable. We find that users with fewer followers, fewer friends, and fewer posts share more hate speech. Younger accounts, in return, share less hate speech. Overall, understanding the factors that drive users to share hate speech is crucial for detecting individuals at risk of engaging in harmful behavior and for designing effective mitigation strategies.
VOT: Revolutionizing Speaker Verification with Memory and Attention Mechanisms
Dec 28, 2023Speaker verification is essentially the process of identifying unknown speakers within an 'open set'. Our objective is to create optimal embeddings that condense information into concise speech-level representations, ensuring short distances within the same speaker and long distances between different speakers. Despite the prevalence of self-attention and convolution methods in speaker verification, they grapple with the challenge of high computational complexity.In order to surmount the limitations posed by the Transformer in extracting local features and the computational intricacies of multilayer convolution, we introduce the Memory-Attention framework. This framework incorporates a deep feed-forward temporal memory network (DFSMN) into the self-attention mechanism, capturing long-term context by stacking multiple layers and enhancing the modeling of local dependencies. Building upon this, we design a novel model called VOT, utilizing a parallel variable weight summation structure and introducing an attention-based statistical pooling layer.To address the hard sample mining problem, we enhance the AM-Softmax loss function and propose a new loss function named AM-Softmax-Focal. Experimental results on the VoxCeleb1 dataset not only showcase a significant improvement in system performance but also surpass the majority of mainstream models, validating the importance of local information in the speaker verification task. The code will be available on GitHub.
Path Signature Representation of Patient-Clinician Interactions as a Predictor for Neuropsychological Tests Outcomes in Children: A Proof of Concept
Dec 12, 2023This research report presents a proof-of-concept study on the application of machine learning techniques to video and speech data collected during diagnostic cognitive assessments of children with a neurodevelopmental disorder. The study utilised a dataset of 39 video recordings, capturing extensive sessions where clinicians administered, among other things, four cognitive assessment tests. From the first 40 minutes of each clinical session, covering the administration of the Wechsler Intelligence Scale for Children (WISC-V), we extracted head positions and speech turns of both clinician and child. Despite the limited sample size and heterogeneous recording styles, the analysis successfully extracted path signatures as features from the recorded data, focusing on patient-clinician interactions. Importantly, these features quantify the interpersonal dynamics of the assessment process (dialogue and movement patterns). Results suggest that these features exhibit promising potential for predicting all cognitive tests scores of the entire session length and for prototyping a predictive model as a clinical decision support tool. Overall, this proof of concept demonstrates the feasibility of leveraging machine learning techniques for clinical video and speech data analysis in order to potentially enhance the efficiency of cognitive assessments for neurodevelopmental disorders in children.