 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Open-vocabulary keyword spotting in any language through multilingual contrastive speech-phoneme pretraining
Nov 14, 2023

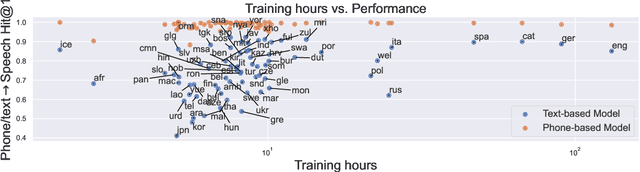
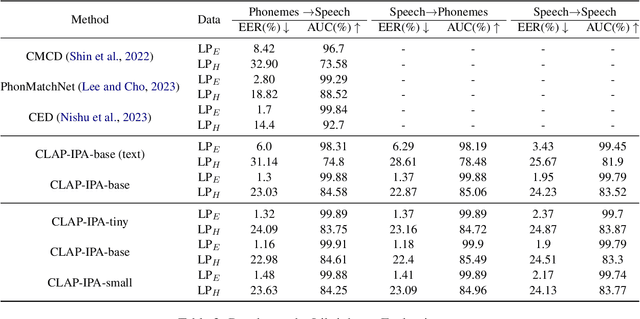
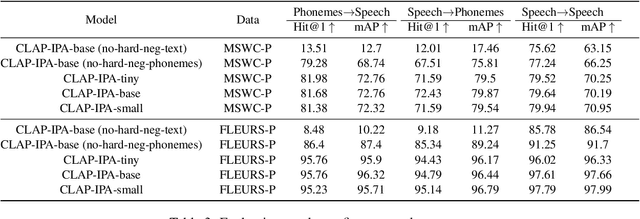
In this paper, we introduce a massively multilingual speech corpora with fine-grained phonemic transcriptions, encompassing more than 115 languages from diverse language families. Based on this multilingual dataset, we propose CLAP-IPA, a multilingual phoneme-speech contrastive embedding model capable of open-vocabulary matching between speech signals and phonemically transcribed keywords or arbitrary phrases. The proposed model has been tested on two fieldwork speech corpora in 97 unseen languages, exhibiting strong generalizability across languages. Comparison with a text-based model shows that using phonemes as modeling units enables much better crosslinguistic generalization than orthographic texts.
Towards Online Sign Language Recognition and Translation
Jan 10, 2024The objective of sign language recognition is to bridge the communication gap between the deaf and the hearing. Numerous previous works train their models using the well-established connectionist temporal classification (CTC) loss. During the inference stage, the CTC-based models typically take the entire sign video as input to make predictions. This type of inference scheme is referred to as offline recognition. In contrast, while mature speech recognition systems can efficiently recognize spoken words on the fly, sign language recognition still falls short due to the lack of practical online solutions. In this work, we take the first step towards filling this gap. Our approach comprises three phases: 1) developing a sign language dictionary encompassing all glosses present in a target sign language dataset; 2) training an isolated sign language recognition model on augmented signs using both conventional classification loss and our novel saliency loss; 3) employing a sliding window approach on the input sign sequence and feeding each sign clip to the well-optimized model for online recognition. Furthermore, our online recognition model can be extended to boost the performance of any offline model, and to support online translation by appending a gloss-to-text network onto the recognition model. By integrating our online framework with the previously best-performing offline model, TwoStream-SLR, we achieve new state-of-the-art performance on three benchmarks: Phoenix-2014, Phoenix-2014T, and CSL-Daily. Code and models will be available at https://github.com/FangyunWei/SLRT
Reading Between the Frames: Multi-Modal Depression Detection in Videos from Non-Verbal Cues
Jan 05, 2024Depression, a prominent contributor to global disability, affects a substantial portion of the population. Efforts to detect depression from social media texts have been prevalent, yet only a few works explored depression detection from user-generated video content. In this work, we address this research gap by proposing a simple and flexible multi-modal temporal model capable of discerning non-verbal depression cues from diverse modalities in noisy, real-world videos. We show that, for in-the-wild videos, using additional high-level non-verbal cues is crucial to achieving good performance, and we extracted and processed audio speech embeddings, face emotion embeddings, face, body and hand landmarks, and gaze and blinking information. Through extensive experiments, we show that our model achieves state-of-the-art results on three key benchmark datasets for depression detection from video by a substantial margin. Our code is publicly available on GitHub.
Low-latency Speech Enhancement via Speech Token Generation
Oct 13, 2023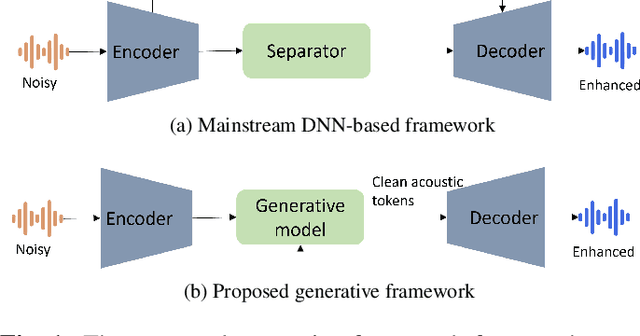
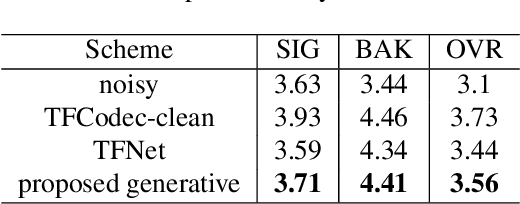
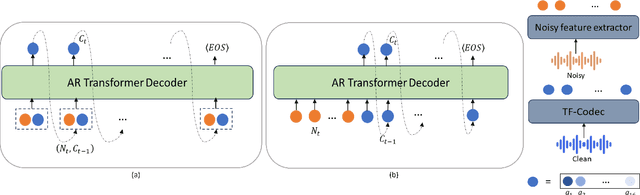
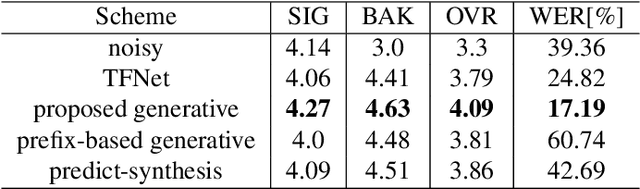
Existing deep learning based speech enhancement mainly employ a data-driven approach, which leverage large amounts of data with a variety of noise types to achieve noise removal from noisy signal. However, the high dependence on the data limits its generalization on the unseen complex noises in real-life environment. In this paper, we focus on the low-latency scenario and regard speech enhancement as a speech generation problem conditioned on the noisy signal, where we generate clean speech instead of identifying and removing noises. Specifically, we propose a conditional generative framework for speech enhancement, which models clean speech by acoustic codes of a neural speech codec and generates the speech codes conditioned on past noisy frames in an auto-regressive way. Moreover, we propose an explicit-alignment approach to align noisy frames with the generated speech tokens to improve the robustness and scalability to different input lengths. Different from other methods that leverage multiple stages to generate speech codes, we leverage a single-stage speech generation approach based on the TF-Codec neural codec to achieve high speech quality with low latency. Extensive results on both synthetic and real-recorded test set show its superiority over data-driven approaches in terms of noise robustness and temporal speech coherence.
On the Effectiveness of ASR Representations in Real-world Noisy Speech Emotion Recognition
Nov 14, 2023This paper proposes an efficient attempt to noisy speech emotion recognition (NSER). Conventional NSER approaches have proven effective in mitigating the impact of artificial noise sources, such as white Gaussian noise, but are limited to non-stationary noises in real-world environments due to their complexity and uncertainty. To overcome this limitation, we introduce a new method for NSER by adopting the automatic speech recognition (ASR) model as a noise-robust feature extractor to eliminate non-vocal information in noisy speech. We first obtain intermediate layer information from the ASR model as a feature representation for emotional speech and then apply this representation for the downstream NSER task. Our experimental results show that 1) the proposed method achieves better NSER performance compared with the conventional noise reduction method, 2) outperforms self-supervised learning approaches, and 3) even outperforms text-based approaches using ASR transcription or the ground truth transcription of noisy speech.
SpeechAgents: Human-Communication Simulation with Multi-Modal Multi-Agent Systems
Jan 08, 2024Human communication is a complex and diverse process that not only involves multiple factors such as language, commonsense, and cultural backgrounds but also requires the participation of multimodal information, such as speech. Large Language Model (LLM)-based multi-agent systems have demonstrated promising performance in simulating human society. Can we leverage LLM-based multi-agent systems to simulate human communication? However, current LLM-based multi-agent systems mainly rely on text as the primary medium. In this paper, we propose SpeechAgents, a multi-modal LLM based multi-agent system designed for simulating human communication. SpeechAgents utilizes multi-modal LLM as the control center for individual agent and employes multi-modal signals as the medium for exchanged messages among agents. Additionally, we propose Multi-Agent Tuning to enhance the multi-agent capabilities of LLM without compromising general abilities. To strengthen and evaluate the effectiveness of human communication simulation, we build the Human-Communication Simulation Benchmark. Experimental results demonstrate that SpeechAgents can simulate human communication dialogues with consistent content, authentic rhythm, and rich emotions and demonstrate excellent scalability even with up to 25 agents, which can apply to tasks such as drama creation and audio novels generation. Code and models will be open-sourced at https://github. com/0nutation/SpeechAgents
On the compression of shallow non-causal ASR models using knowledge distillation and tied-and-reduced decoder for low-latency on-device speech recognition
Dec 15, 2023Recently, the cascaded two-pass architecture has emerged as a strong contender for on-device automatic speech recognition (ASR). A cascade of causal and shallow non-causal encoders coupled with a shared decoder enables operation in both streaming and look-ahead modes. In this paper, we propose shallow cascaded model by combining various model compression techniques such as knowledge distillation, shared decoder, and tied-and-reduced transducer network in order to reduce the model footprint. The shared decoder is changed into a tied-and-reduced network. The cascaded two-pass model is further compressed using knowledge distillation using a Kullback-Leibler divergence loss on the model posteriors. We demonstrate a 50% reduction in the size of a 41 M parameter cascaded teacher model with no noticeable degradation in ASR accuracy and a 30% reduction in latency
Towards General-Purpose Speech Abilities for Large Language Models Using Unpaired Data
Nov 12, 2023In this work, we extend the instruction-tuned Llama-2 model with end-to-end general-purpose speech processing and reasoning abilities while maintaining the wide range of LLM capabilities, without using any carefully curated paired data. The proposed model can utilize audio prompts as a replacement for text and sustain a conversation. Such a model also has extended cross-modal capabilities such as being able to perform speech question answering, speech translation, and audio summarization amongst many other closed and open-domain tasks. This is unlike prior approaches in speech, in which LLMs are extended to handle audio for a limited number of pre-designated tasks. Experiments show that our end-to-end approach is on par with or outperforms a cascaded system (speech recognizer + LLM) in terms of modeling the response to a prompt. Furthermore, unlike a cascade, our approach shows the ability to interchange text and audio modalities and utilize the prior context in a conversation to provide better results.
CDSD: Chinese Dysarthria Speech Database
Oct 24, 2023We present the Chinese Dysarthria Speech Database (CDSD) as a valuable resource for dysarthria research. This database comprises speech data from 24 participants with dysarthria. Among these participants, one recorded an additional 10 hours of speech data, while each recorded one hour, resulting in 34 hours of speech material. To accommodate participants with varying cognitive levels, our text pool primarily consists of content from the AISHELL-1 dataset and speeches by primary and secondary school students. When participants read these texts, they must use a mobile device or the ZOOM F8n multi-track field recorder to record their speeches. In this paper, we elucidate the data collection and annotation processes and present an approach for establishing a baseline for dysarthric speech recognition. Furthermore, we conducted a speaker-dependent dysarthric speech recognition experiment using an additional 10 hours of speech data from one of our participants. Our research findings indicate that, through extensive data-driven model training, fine-tuning limited quantities of specific individual data yields commendable results in speaker-dependent dysarthric speech recognition. However, we observe significant variations in recognition results among different dysarthric speakers. These insights provide valuable reference points for speaker-dependent dysarthric speech recognition.
Generative De-Quantization for Neural Speech Codec via Latent Diffusion
Nov 15, 2023In low-bitrate speech coding, end-to-end speech coding networks aim to learn compact yet expressive features and a powerful decoder in a single network. A challenging problem as such results in unwelcome complexity increase and inferior speech quality. In this paper, we propose to separate the representation learning and information reconstruction tasks. We leverage an end-to-end codec for learning low-dimensional discrete tokens and employ a latent diffusion model to de-quantize coded features into a high-dimensional continuous space, relieving the decoder's burden of de-quantizing and upsampling. To mitigate the issue of over-smooth generation, we introduce midway-infilling with less noise reduction and stronger conditioning. In ablation studies, we investigate the hyperparameters for midway-infilling and latent diffusion space with different dimensions. Subjective listening tests show that our model outperforms the state-of-the-art at two low bitrates, 1.5 and 3 kbps. Codes and samples of this work are available on our webpage.