 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Online Automatic Speech Recognition with Listen, Attend and Spell Model
Aug 12, 2020
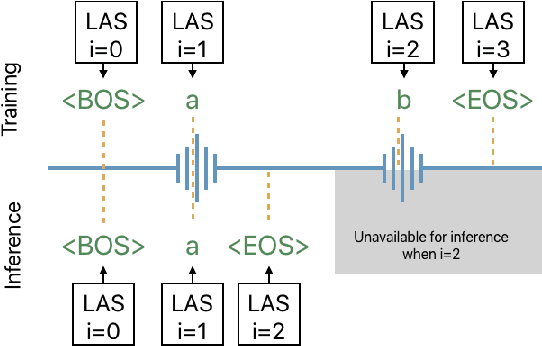
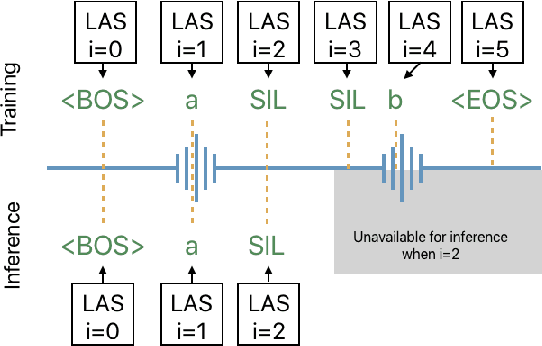
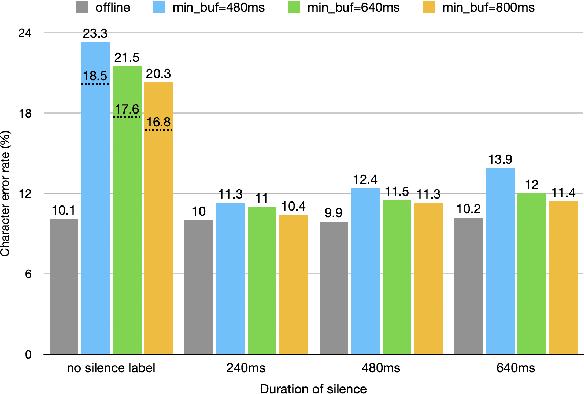
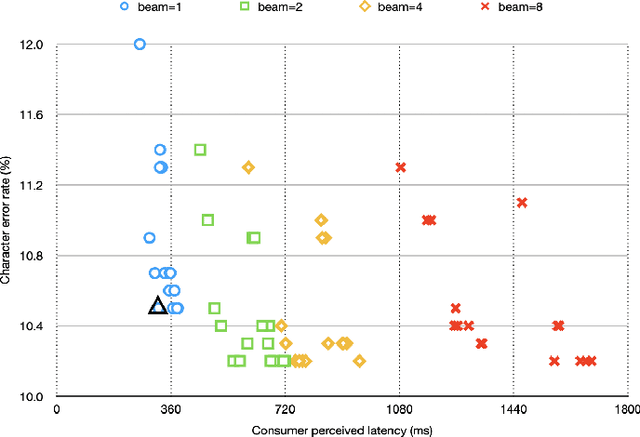
The Listen, Attend and Spell (LAS) model and other attention-based automatic speech recognition (ASR) models have known limitations when operated in a fully online mode. In this paper, we analyze the online operation of LAS models to demonstrate that these limitations stem from the handling of silence regions and the reliability of online attention mechanism at the edge of input buffers. We propose a novel and simple technique that can achieve fully online recognition while meeting accuracy and latency targets. For the Mandarin dictation task, our proposed approach can achieve a character error rate in online operation that is within 4% relative to an offline LAS model. The proposed online LAS model operates at 12% lower latency relative to a conventional neural network hidden Markov model hybrid of comparable accuracy. We have validated the proposed method through a production scale deployment, which, to the best of our knowledge, is the first such deployment of a fully online LAS model.
End-to-End Automatic Speech Translation of Audiobooks
Feb 12, 2018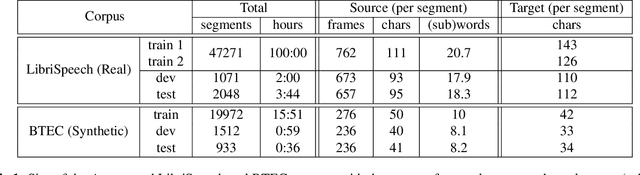
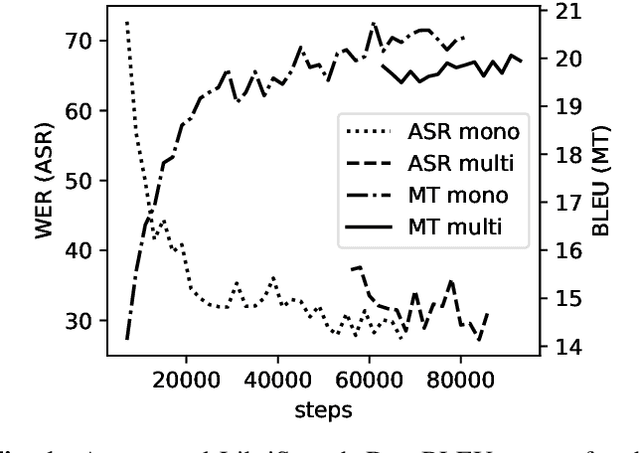
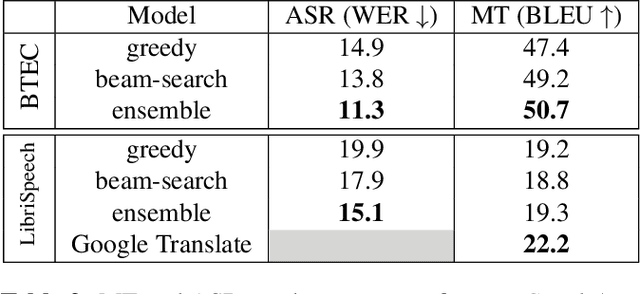
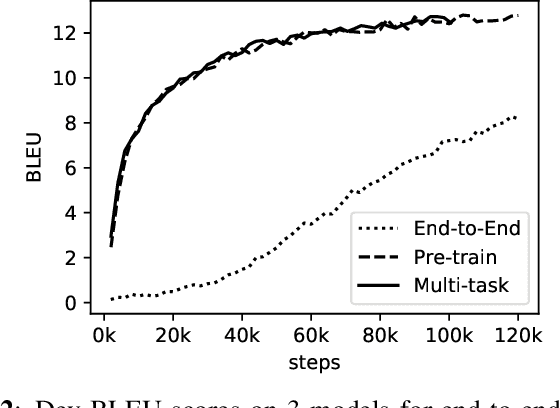
We investigate end-to-end speech-to-text translation on a corpus of audiobooks specifically augmented for this task. Previous works investigated the extreme case where source language transcription is not available during learning nor decoding, but we also study a midway case where source language transcription is available at training time only. In this case, a single model is trained to decode source speech into target text in a single pass. Experimental results show that it is possible to train compact and efficient end-to-end speech translation models in this setup. We also distribute the corpus and hope that our speech translation baseline on this corpus will be challenged in the future.
Improving Unsupervised Subword Modeling via Disentangled Speech Representation Learning and Transformation
Jul 03, 2019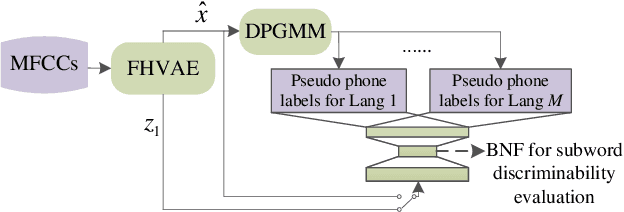
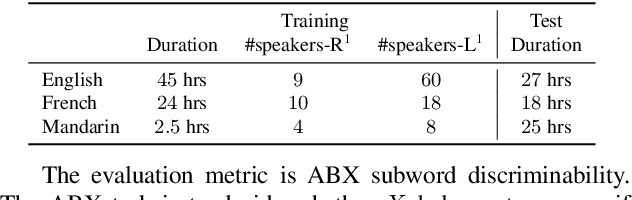
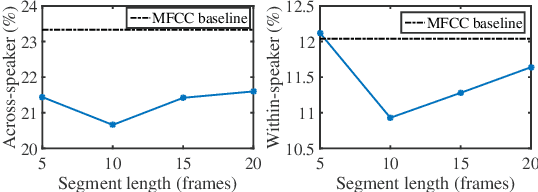
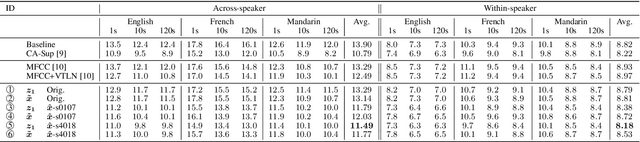
This study tackles unsupervised subword modeling in the zero-resource scenario, learning frame-level speech representation that is phonetically discriminative and speaker-invariant, using only untranscribed speech for target languages. Frame label acquisition is an essential step in solving this problem. High quality frame labels should be in good consistency with golden transcriptions and robust to speaker variation. We propose to improve frame label acquisition in our previously adopted deep neural network-bottleneck feature (DNN-BNF) architecture by applying the factorized hierarchical variational autoencoder (FHVAE). FHVAEs learn to disentangle linguistic content and speaker identity information encoded in speech. By discarding or unifying speaker information, speaker-invariant features are learned and fed as inputs to DPGMM frame clustering and DNN-BNF training. Experiments conducted on ZeroSpeech 2017 show that our proposed approaches achieve $2.4\%$ and $0.6\%$ absolute ABX error rate reductions in across- and within-speaker conditions, comparing to the baseline DNN-BNF system without applying FHVAEs. Our proposed approaches significantly outperform vocal tract length normalization in improving frame labeling and subword modeling.
STC speaker recognition systems for the NIST SRE 2021
Nov 03, 2021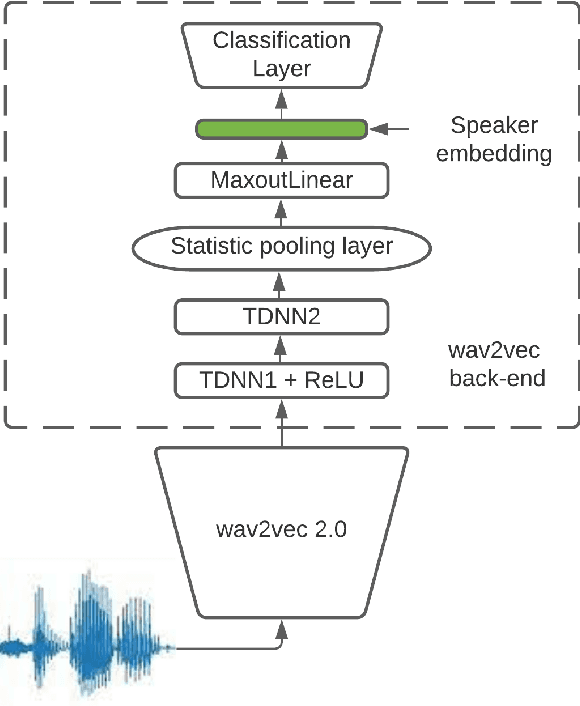
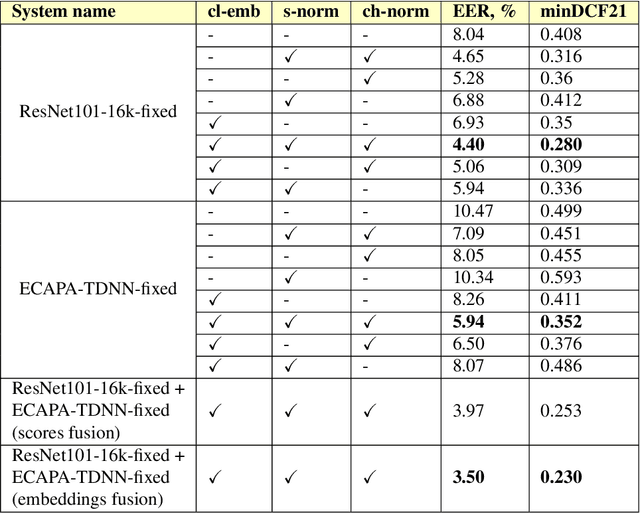
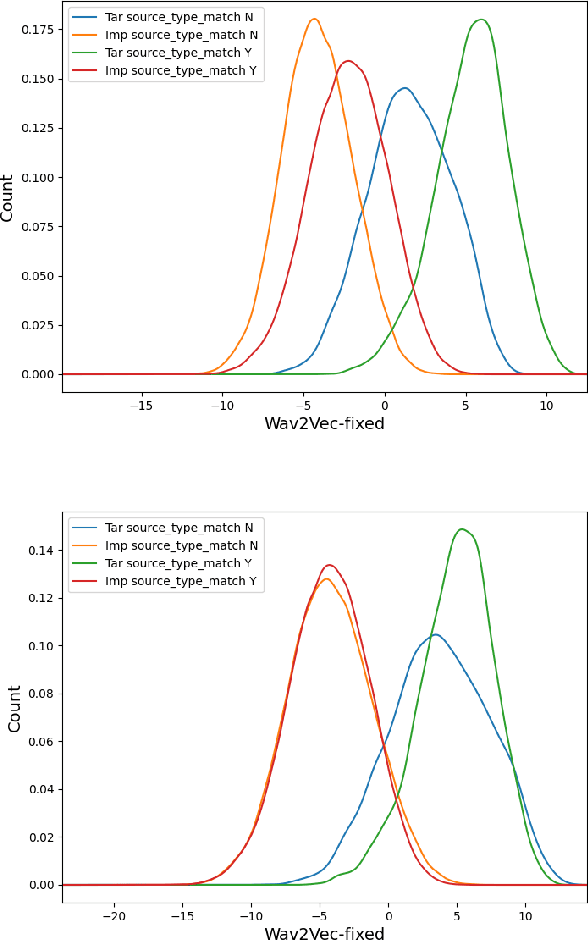
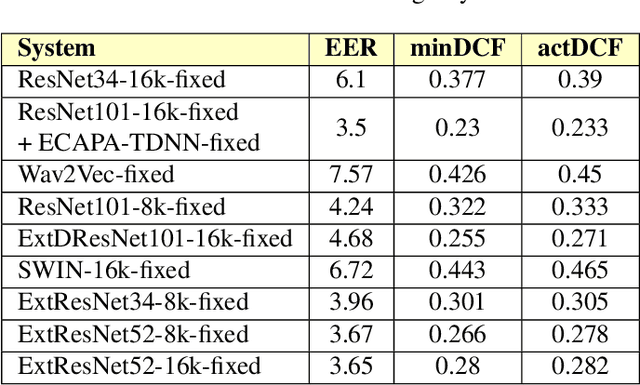
This paper presents a description of STC Ltd. systems submitted to the NIST 2021 Speaker Recognition Evaluation for both fixed and open training conditions. These systems consists of a number of diverse subsystems based on using deep neural networks as feature extractors. During the NIST 2021 SRE challenge we focused on the training of the state-of-the-art deep speaker embeddings extractors like ResNets and ECAPA networks by using additive angular margin based loss functions. Additionally, inspired by the recent success of the wav2vec 2.0 features in automatic speech recognition we explored the effectiveness of this approach for the speaker verification filed. According to our observation the fine-tuning of the pretrained large wav2vec 2.0 model provides our best performing systems for open track condition. Our experiments with wav2vec 2.0 based extractors for the fixed condition showed that unsupervised autoregressive pretraining with Contrastive Predictive Coding loss opens the door to training powerful transformer-based extractors from raw speech signals. For video modality we developed our best solution with RetinaFace face detector and deep ResNet face embeddings extractor trained on large face image datasets. The final results for primary systems were obtained by different configurations of subsystems fusion on the score level followed by score calibration.
Towards a Real-time Measure of the Perception of Anthropomorphism in Human-robot Interaction
Jan 24, 2022
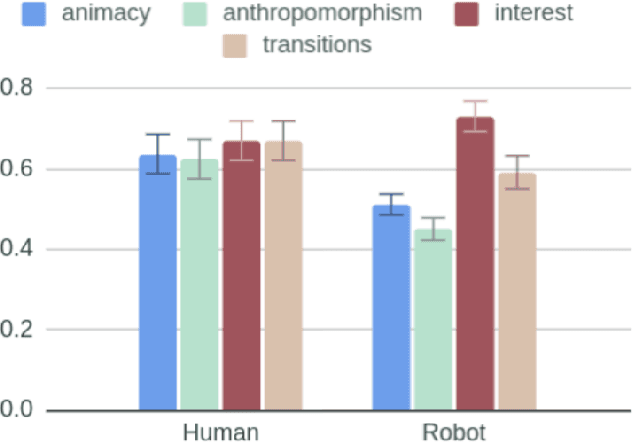
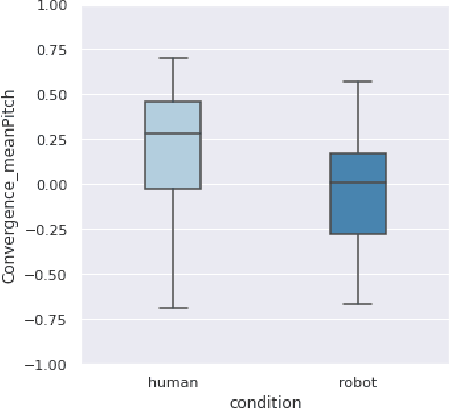
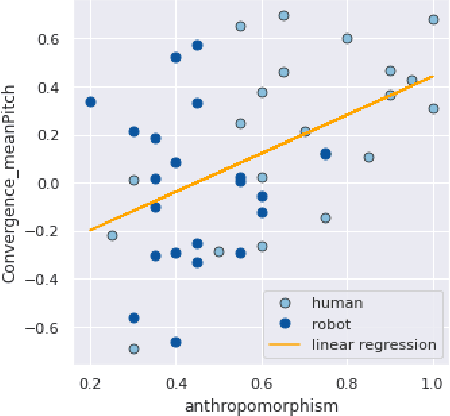
How human-like do conversational robots need to look to enable long-term human-robot conversation? One essential aspect of long-term interaction is a human's ability to adapt to the varying degrees of a conversational partner's engagement and emotions. Prosodically, this can be achieved through (dis)entrainment. While speech-synthesis has been a limiting factor for many years, restrictions in this regard are increasingly mitigated. These advancements now emphasise the importance of studying the effect of robot embodiment on human entrainment. In this study, we conducted a between-subjects online human-robot interaction experiment in an educational use-case scenario where a tutor was either embodied through a human or a robot face. 43 English-speaking participants took part in the study for whom we analysed the degree of acoustic-prosodic entrainment to the human or robot face, respectively. We found that the degree of subjective and objective perception of anthropomorphism positively correlates with acoustic-prosodic entrainment.
Unified Multimodal Punctuation Restoration Framework for Mixed-Modality Corpus
Jan 24, 2022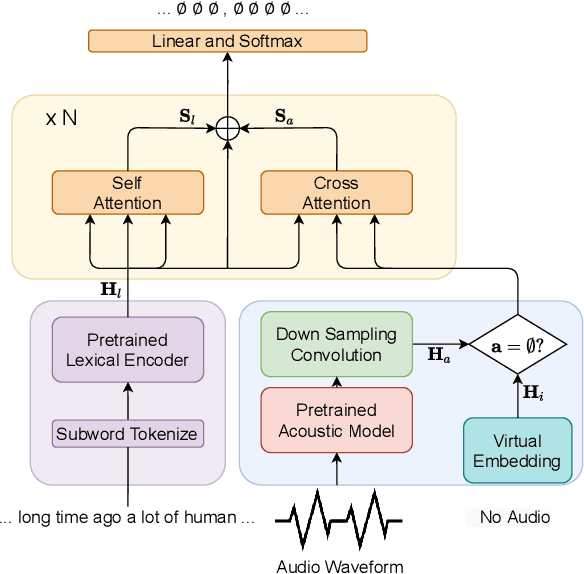
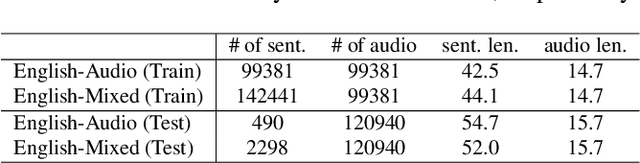
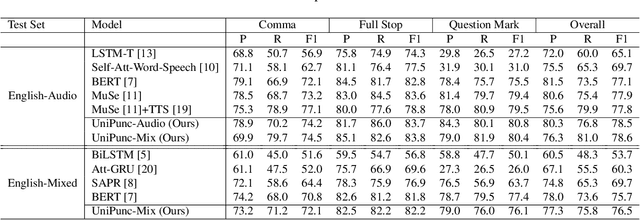
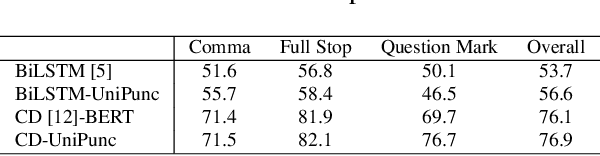
The punctuation restoration task aims to correctly punctuate the output transcriptions of automatic speech recognition systems. Previous punctuation models, either using text only or demanding the corresponding audio, tend to be constrained by real scenes, where unpunctuated sentences are a mixture of those with and without audio. This paper proposes a unified multimodal punctuation restoration framework, named UniPunc, to punctuate the mixed sentences with a single model. UniPunc jointly represents audio and non-audio samples in a shared latent space, based on which the model learns a hybrid representation and punctuates both kinds of samples. We validate the effectiveness of the UniPunc on real-world datasets, which outperforms various strong baselines (e.g. BERT, MuSe) by at least 0.8 overall F1 scores, making a new state-of-the-art. Extensive experiments show that UniPunc's design is a pervasive solution: by grafting onto previous models, UniPunc enables them to punctuate on the mixed corpus. Our code is available at github.com/Yaoming95/UniPunc
End-to-End Text-to-Speech using Latent Duration based on VQ-VAE
Oct 20, 2020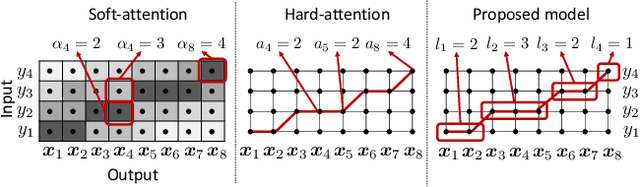
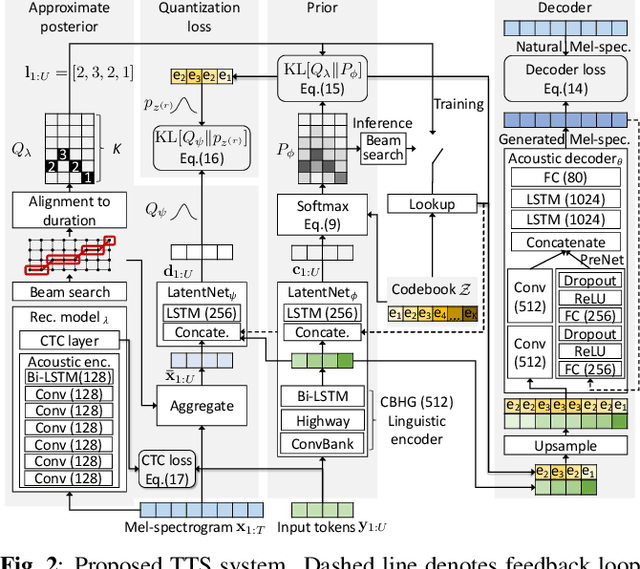
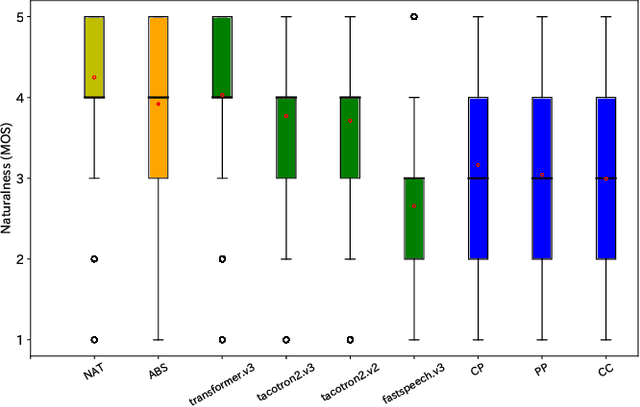
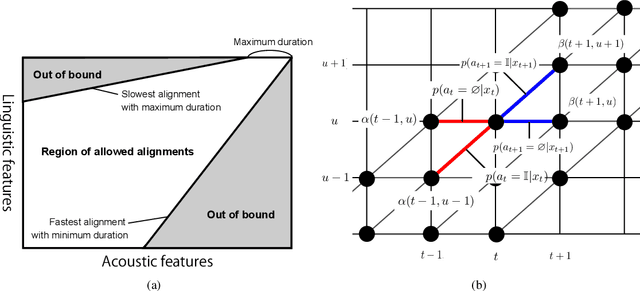
Explicit duration modeling is a key to achieving robust and efficient alignment in text-to-speech synthesis (TTS). We propose a new TTS framework using explicit duration modeling that incorporates duration as a discrete latent variable to TTS and enables joint optimization of whole modules from scratch. We formulate our method based on conditional VQ-VAE to handle discrete duration in a variational autoencoder and provide a theoretical explanation to justify our method. In our framework, a connectionist temporal classification (CTC) -based force aligner acts as the approximate posterior, and text-to-duration works as the prior in the variational autoencoder. We evaluated our proposed method with a listening test and compared it with other TTS methods based on soft-attention or explicit duration modeling. The results showed that our systems rated between soft-attention-based methods (Transformer-TTS, Tacotron2) and explicit duration modeling-based methods (Fastspeech).
TEET! Tunisian Dataset for Toxic Speech Detection
Oct 11, 2021
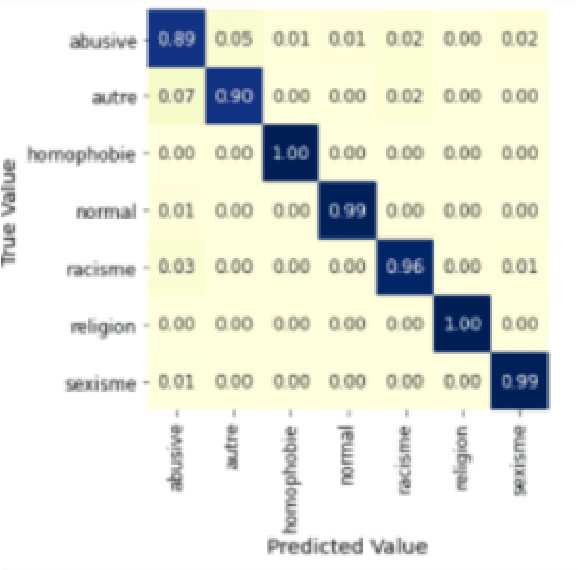
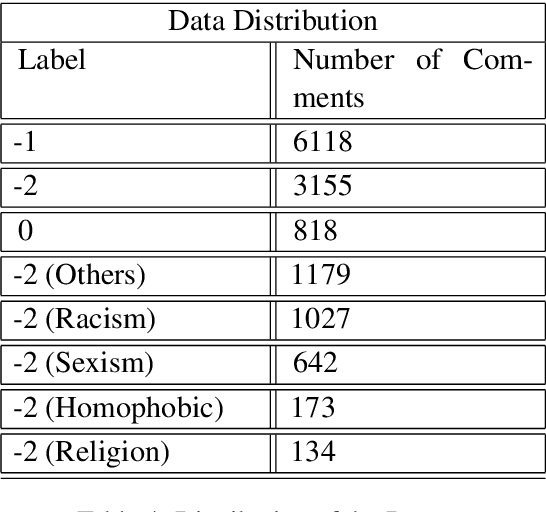
The complete freedom of expression in social media has its costs especially in spreading harmful and abusive content that may induce people to act accordingly. Therefore, the need of detecting automatically such a content becomes an urgent task that will help and enhance the efficiency in limiting this toxic spread. Compared to other Arabic dialects which are mostly based on MSA, the Tunisian dialect is a combination of many other languages like MSA, Tamazight, Italian and French. Because of its rich language, dealing with NLP problems can be challenging due to the lack of large annotated datasets. In this paper we are introducing a new annotated dataset composed of approximately 10k of comments. We provide an in-depth exploration of its vocabulary through feature engineering approaches as well as the results of the classification performance of machine learning classifiers like NB and SVM and deep learning models such as ARBERT, MARBERT and XLM-R.
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
Nov 05, 2018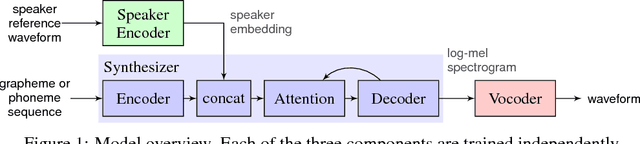

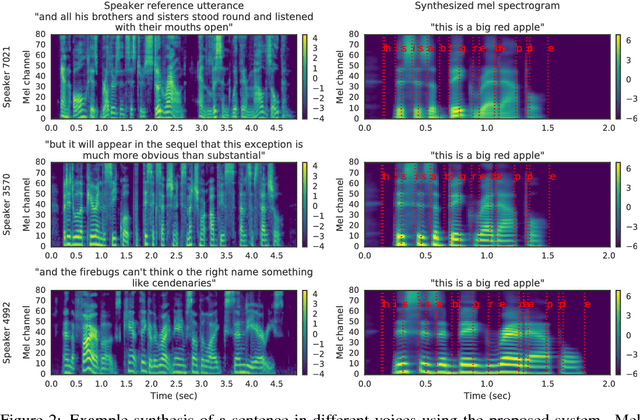
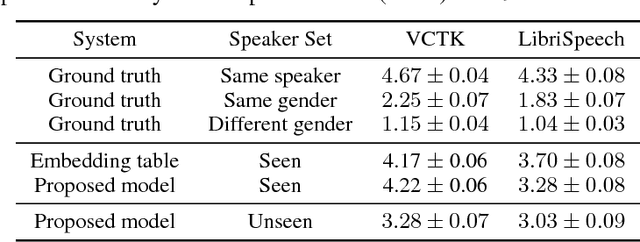
We describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of many different speakers, including those unseen during training. Our system consists of three independently trained components: (1) a speaker encoder network, trained on a speaker verification task using an independent dataset of noisy speech from thousands of speakers without transcripts, to generate a fixed-dimensional embedding vector from seconds of reference speech from a target speaker; (2) a sequence-to-sequence synthesis network based on Tacotron 2, which generates a mel spectrogram from text, conditioned on the speaker embedding; (3) an auto-regressive WaveNet-based vocoder that converts the mel spectrogram into a sequence of time domain waveform samples. We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the new task, and is able to synthesize natural speech from speakers that were not seen during training. We quantify the importance of training the speaker encoder on a large and diverse speaker set in order to obtain the best generalization performance. Finally, we show that randomly sampled speaker embeddings can be used to synthesize speech in the voice of novel speakers dissimilar from those used in training, indicating that the model has learned a high quality speaker representation.
Transformer in action: a comparative study of transformer-based acoustic models for large scale speech recognition applications
Oct 29, 2020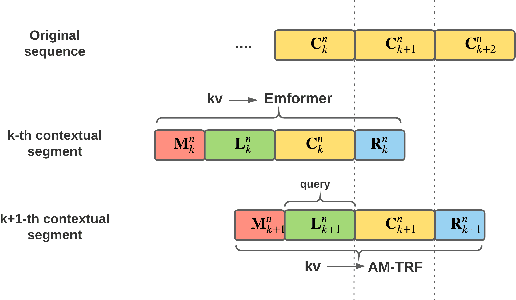
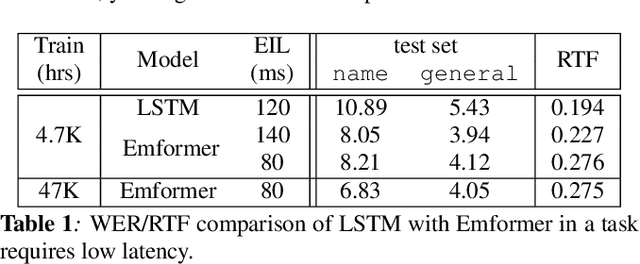
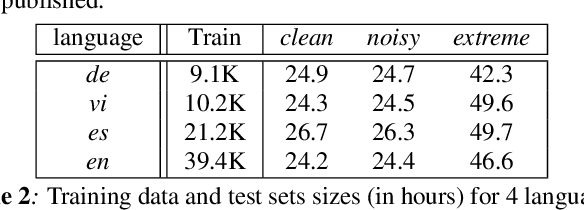
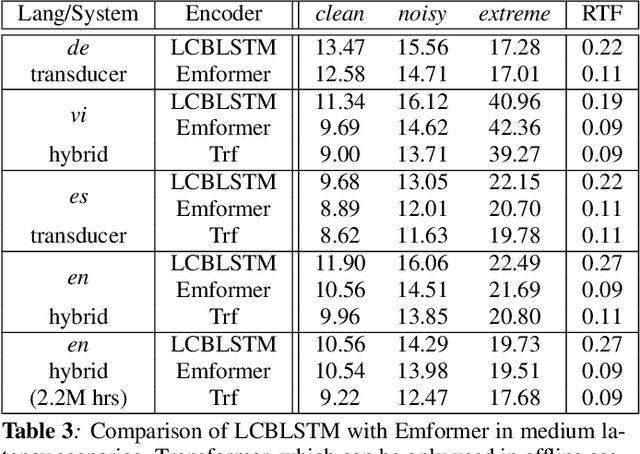
In this paper, we summarize the application of transformer and its streamable variant, Emformer based acoustic model for large scale speech recognition applications. We compare the transformer based acoustic models with their LSTM counterparts on industrial scale tasks. Specifically, we compare Emformer with latency-controlled BLSTM (LCBLSTM) on medium latency tasks and LSTM on low latency tasks. On a low latency voice assistant task, Emformer gets 24% to 26% relative word error rate reductions (WERRs). For medium latency scenarios, comparing with LCBLSTM with similar model size and latency, Emformer gets significant WERR across four languages in video captioning datasets with 2-3 times inference real-time factors reduction.