 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Hypergraph based semi-supervised learning algorithms applied to speech recognition problem: a novel approach
Oct 28, 2018

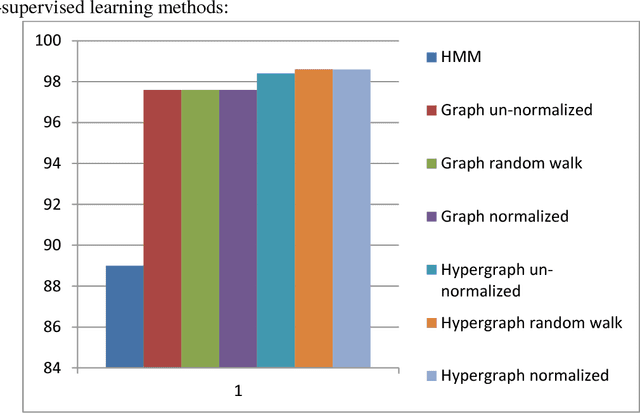
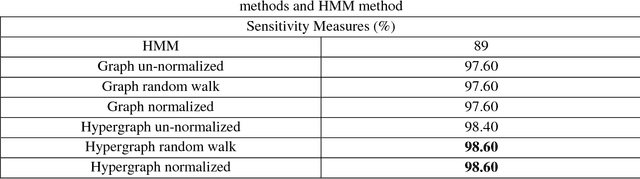
Most network-based speech recognition methods are based on the assumption that the labels of two adjacent speech samples in the network are likely to be the same. However, assuming the pairwise relationship between speech samples is not complete. The information a group of speech samples that show very similar patterns and tend to have similar labels is missed. The natural way overcoming the information loss of the above assumption is to represent the feature data of speech samples as the hypergraph. Thus, in this paper, the three un-normalized, random walk, and symmetric normalized hypergraph Laplacian based semi-supervised learning methods applied to hypergraph constructed from the feature data of speech samples in order to predict the labels of speech samples are introduced. Experiment results show that the sensitivity performance measures of these three hypergraph Laplacian based semi-supervised learning methods are greater than the sensitivity performance measures of the Hidden Markov Model method (the current state of the art method applied to speech recognition problem) and graph based semi-supervised learning methods (i.e. the current state of the art network-based method for classification problems) applied to network created from the feature data of speech samples.
A variance modeling framework based on variational autoencoders for speech enhancement
Feb 05, 2019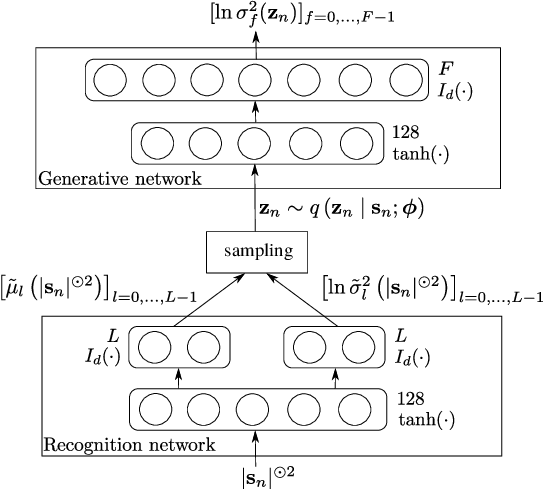
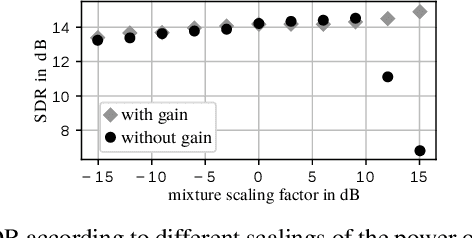
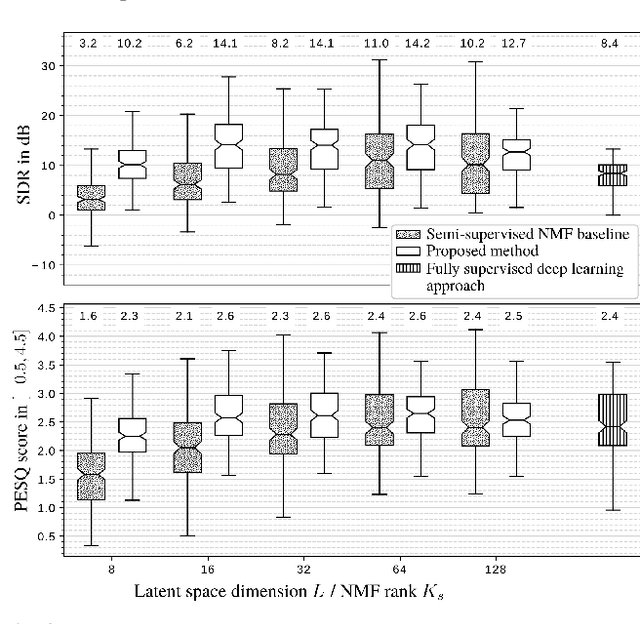
In this paper we address the problem of enhancing speech signals in noisy mixtures using a source separation approach. We explore the use of neural networks as an alternative to a popular speech variance model based on supervised non-negative matrix factorization (NMF). More precisely, we use a variational autoencoder as a speaker-independent supervised generative speech model, highlighting the conceptual similarities that this approach shares with its NMF-based counterpart. In order to be free of generalization issues regarding the noisy recording environments, we follow the approach of having a supervised model only for the target speech signal, the noise model being based on unsupervised NMF. We develop a Monte Carlo expectation-maximization algorithm for inferring the latent variables in the variational autoencoder and estimating the unsupervised model parameters. Experiments show that the proposed method outperforms a semi-supervised NMF baseline and a state-of-the-art fully supervised deep learning approach.
* 6 pages, 3 figures
UltraSuite: A Repository of Ultrasound and Acoustic Data from Child Speech Therapy Sessions
Jul 01, 2019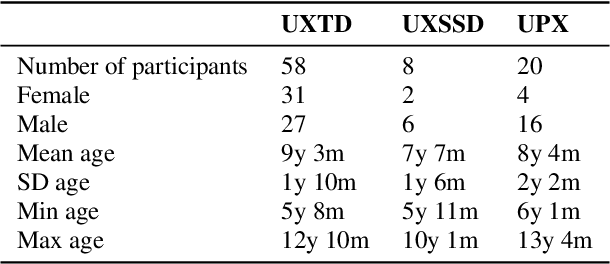

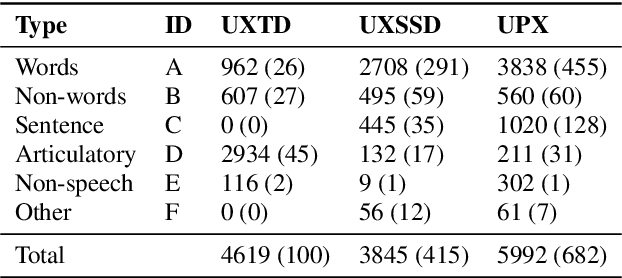
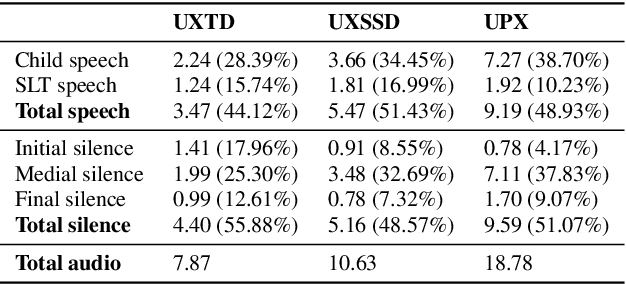
We introduce UltraSuite, a curated repository of ultrasound and acoustic data, collected from recordings of child speech therapy sessions. This release includes three data collections, one from typically developing children and two from children with speech sound disorders. In addition, it includes a set of annotations, some manual and some automatically produced, and software tools to process, transform and visualise the data.
Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
Jul 09, 2019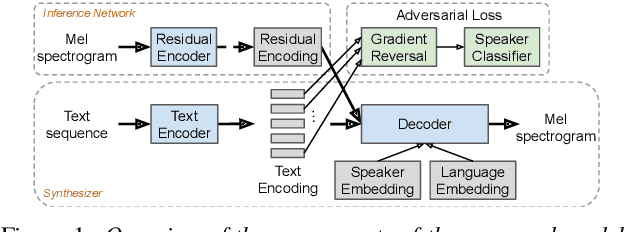
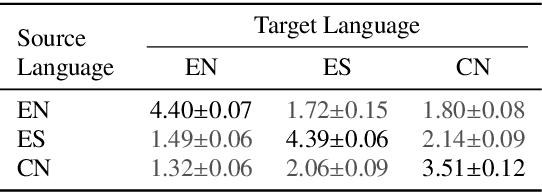
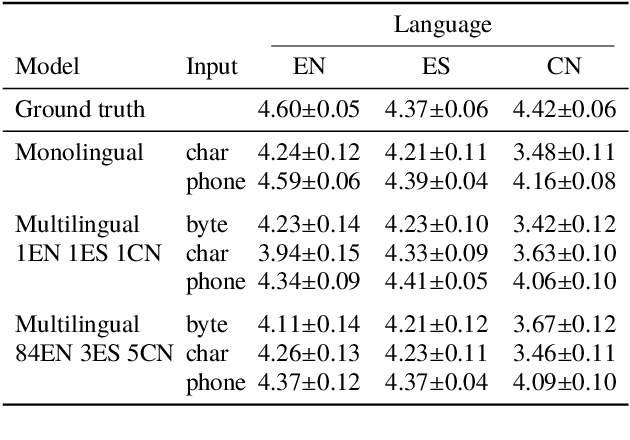
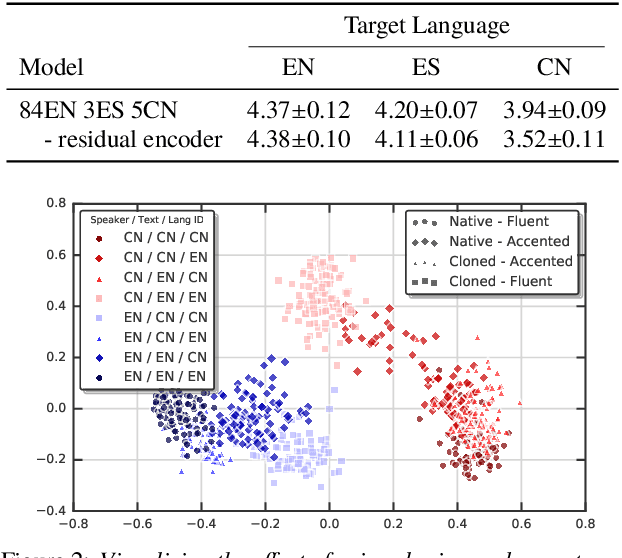
We present a multispeaker, multilingual text-to-speech (TTS) synthesis model based on Tacotron that is able to produce high quality speech in multiple languages. Moreover, the model is able to transfer voices across languages, e.g. synthesize fluent Spanish speech using an English speaker's voice, without training on any bilingual or parallel examples. Such transfer works across distantly related languages, e.g. English and Mandarin. Critical to achieving this result are: 1. using a phonemic input representation to encourage sharing of model capacity across languages, and 2. incorporating an adversarial loss term to encourage the model to disentangle its representation of speaker identity (which is perfectly correlated with language in the training data) from the speech content. Further scaling up the model by training on multiple speakers of each language, and incorporating an autoencoding input to help stabilize attention during training, results in a model which can be used to consistently synthesize intelligible speech for training speakers in all languages seen during training, and in native or foreign accents.
SD-QA: Spoken Dialectal Question Answering for the Real World
Sep 24, 2021

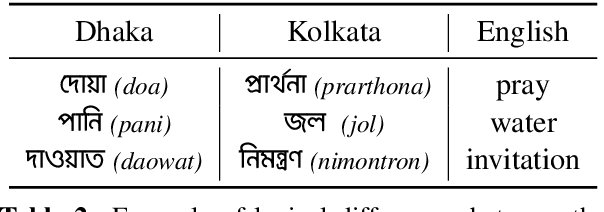
Question answering (QA) systems are now available through numerous commercial applications for a wide variety of domains, serving millions of users that interact with them via speech interfaces. However, current benchmarks in QA research do not account for the errors that speech recognition models might introduce, nor do they consider the language variations (dialects) of the users. To address this gap, we augment an existing QA dataset to construct a multi-dialect, spoken QA benchmark on five languages (Arabic, Bengali, English, Kiswahili, Korean) with more than 68k audio prompts in 24 dialects from 255 speakers. We provide baseline results showcasing the real-world performance of QA systems and analyze the effect of language variety and other sensitive speaker attributes on downstream performance. Last, we study the fairness of the ASR and QA models with respect to the underlying user populations. The dataset, model outputs, and code for reproducing all our experiments are available: https://github.com/ffaisal93/SD-QA.
Multi-scale Octave Convolutions for Robust Speech Recognition
Oct 31, 2019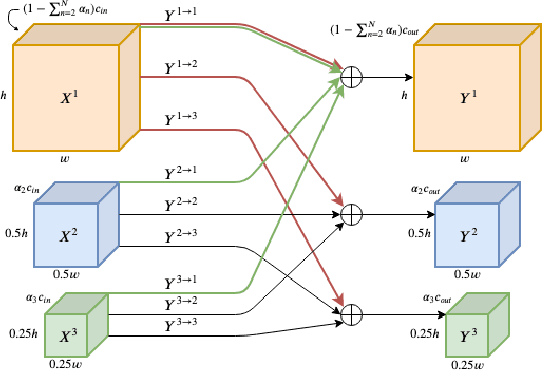
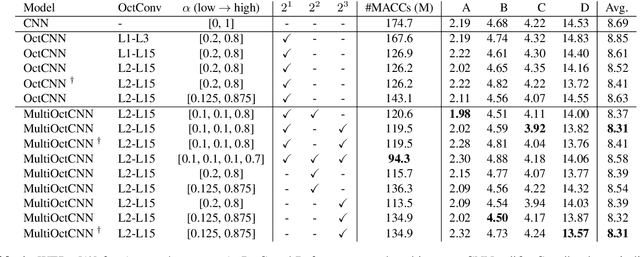
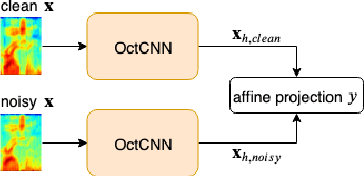
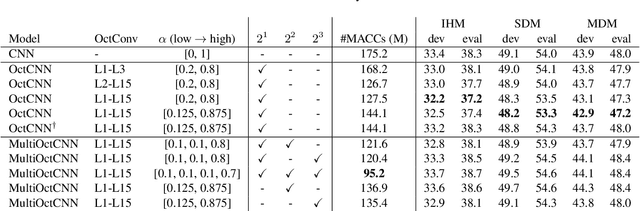
We propose a multi-scale octave convolution layer to learn robust speech representations efficiently. Octave convolutions were introduced by Chen et al [1] in the computer vision field to reduce the spatial redundancy of the feature maps by decomposing the output of a convolutional layer into feature maps at two different spatial resolutions, one octave apart. This approach improved the efficiency as well as the accuracy of the CNN models. The accuracy gain was attributed to the enlargement of the receptive field in the original input space. We argue that octave convolutions likewise improve the robustness of learned representations due to the use of average pooling in the lower resolution group, acting as a low-pass filter. We test this hypothesis by evaluating on two noisy speech corpora - Aurora-4 and AMI. We extend the octave convolution concept to multiple resolution groups and multiple octaves. To evaluate the robustness of the inferred representations, we report the similarity between clean and noisy encodings using an affine projection loss as a proxy robustness measure. The results show that proposed method reduces the WER by up to 6.6% relative for Aurora-4 and 3.6% for AMI, while improving the computational efficiency of the CNN acoustic models.
On the Contributions of Visual and Textual Supervision in Low-resource Semantic Speech Retrieval
Apr 24, 2019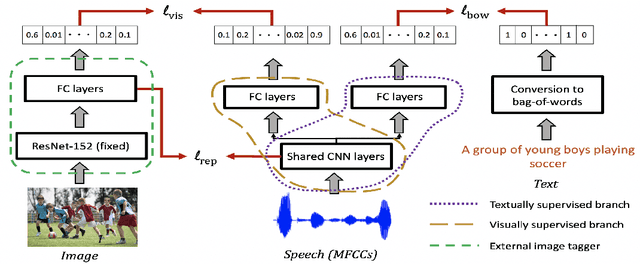
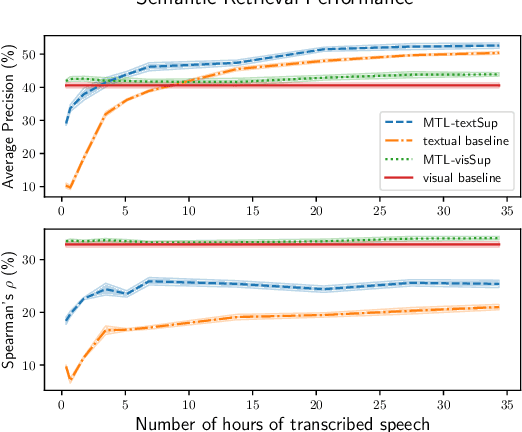
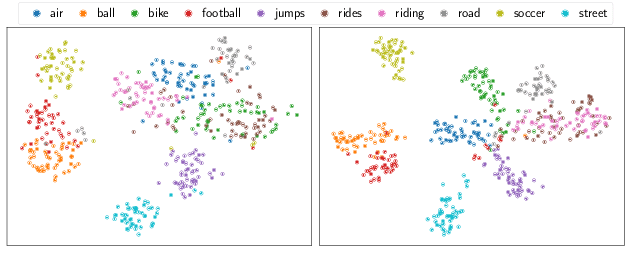
Recent work has shown that speech paired with images can be used to learn semantically meaningful speech representations even without any textual supervision. In real-world low-resource settings, however, we often have access to some transcribed speech. We study whether and how visual grounding is useful in the presence of varying amounts of textual supervision. In particular, we consider the task of semantic speech retrieval in a low-resource setting. We use a previously studied data set and task, where models are trained on images with spoken captions and evaluated on human judgments of semantic relevance. We propose a multitask learning approach to leverage both visual and textual modalities, with visual supervision in the form of keyword probabilities from an external tagger. We find that visual grounding is helpful even in the presence of textual supervision, and we analyze this effect over a range of sizes of transcribed data sets. With ~5 hours of transcribed speech, we obtain 23% higher average precision when also using visual supervision.
Fully Quantizing a Simplified Transformer for End-to-end Speech Recognition
Nov 09, 2019
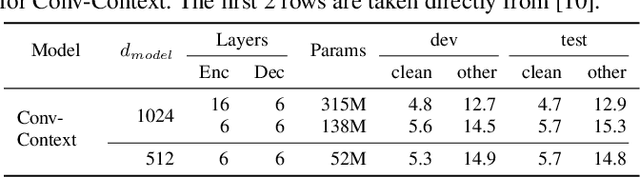
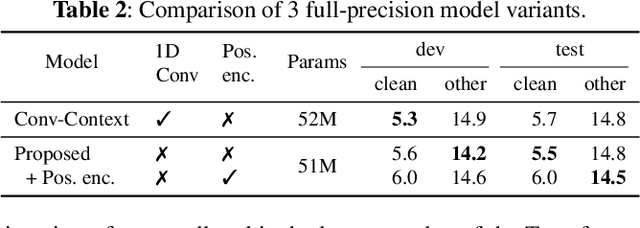
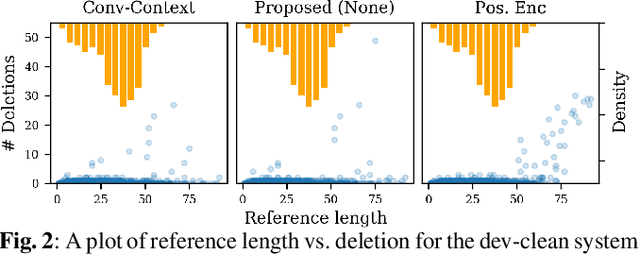
While significant improvements have been made in recent years in terms of end-to-end automatic speech recognition (ASR) performance, such improvements were obtained through the use of very large neural networks, unfit for embedded use on edge devices. That being said, in this paper, we work on simplifying and compressing Transformer-based encoder-decoder architectures for the end-to-end ASR task. We empirically introduce a more compact Speech-Transformer by investigating the impact of discarding particular modules on the performance of the model. Moreover, we evaluate reducing the numerical precision of our network's weights and activations while maintaining the performance of the full-precision model. Our experiments show that we can reduce the number of parameters of the full-precision model and then further compress the model 4x by fully quantizing to 8-bit fixed point precision.
Constructing interval variables via faceted Rasch measurement and multitask deep learning: a hate speech application
Sep 22, 2020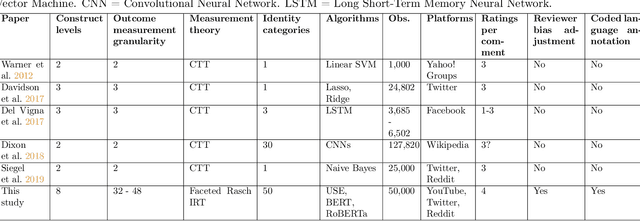



We propose a general method for measuring complex variables on a continuous, interval spectrum by combining supervised deep learning with the Constructing Measures approach to faceted Rasch item response theory (IRT). We decompose the target construct, hate speech in our case, into multiple constituent components that are labeled as ordinal survey items. Those survey responses are transformed via IRT into a debiased, continuous outcome measure. Our method estimates the survey interpretation bias of the human labelers and eliminates that influence on the generated continuous measure. We further estimate the response quality of each labeler using faceted IRT, allowing responses from low-quality labelers to be removed. Our faceted Rasch scaling procedure integrates naturally with a multitask deep learning architecture for automated prediction on new data. The ratings on the theorized components of the target outcome are used as supervised, ordinal variables for the neural networks' internal concept learning. We test the use of an activation function (ordinal softmax) and loss function (ordinal cross-entropy) designed to exploit the structure of ordinal outcome variables. Our multitask architecture leads to a new form of model interpretation because each continuous prediction can be directly explained by the constituent components in the penultimate layer. We demonstrate this new method on a dataset of 50,000 social media comments sourced from YouTube, Twitter, and Reddit and labeled by 11,000 U.S.-based Amazon Mechanical Turk workers to measure a continuous spectrum from hate speech to counterspeech. We evaluate Universal Sentence Encoders, BERT, and RoBERTa as language representation models for the comment text, and compare our predictive accuracy to Google Jigsaw's Perspective API models, showing significant improvement over this standard benchmark.
Prosody-Aware Neural Machine Translation for Dubbing
Dec 16, 2021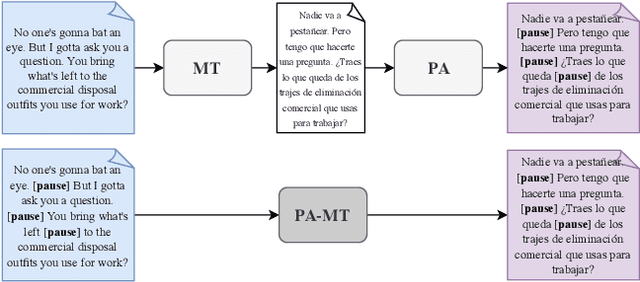
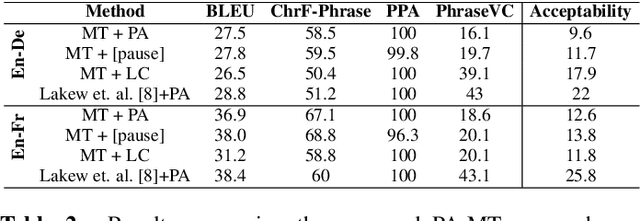
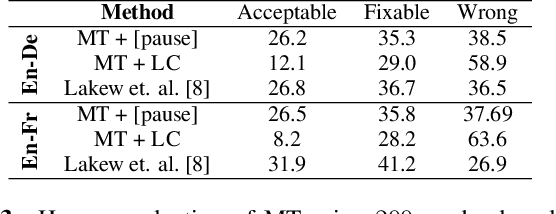

We introduce the task of prosody-aware machine translation which aims at generating translations suitable for dubbing. Dubbing of a spoken sentence requires transferring the content as well as the prosodic structure of the source into the target language to preserve timing information. Practically, this implies correctly projecting pauses from the source to the target and ensuring that target speech segments have roughly the same duration of the corresponding source segments. In this work, we propose an implicit and explicit modeling approaches to integrate prosody information into neural machine translation. Experiments on English-German/French with automatic metrics show that the simplest of the considered approaches works best. Results are confirmed by human evaluations of translations and dubbed videos.