 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Singer Identity Representation Learning using Self-Supervised Techniques
Jan 10, 2024
Significant strides have been made in creating voice identity representations using speech data. However, the same level of progress has not been achieved for singing voices. To bridge this gap, we suggest a framework for training singer identity encoders to extract representations suitable for various singing-related tasks, such as singing voice similarity and synthesis. We explore different self-supervised learning techniques on a large collection of isolated vocal tracks and apply data augmentations during training to ensure that the representations are invariant to pitch and content variations. We evaluate the quality of the resulting representations on singer similarity and identification tasks across multiple datasets, with a particular emphasis on out-of-domain generalization. Our proposed framework produces high-quality embeddings that outperform both speaker verification and wav2vec 2.0 pre-trained baselines on singing voice while operating at 44.1 kHz. We release our code and trained models to facilitate further research on singing voice and related areas.
* Accepted at the ISMIR conference, Milan, Italy, 2023
MuTox: Universal MUltilingual Audio-based TOXicity Dataset and Zero-shot Detector
Jan 10, 2024Research in toxicity detection in natural language processing for the speech modality (audio-based) is quite limited, particularly for languages other than English. To address these limitations and lay the groundwork for truly multilingual audio-based toxicity detection, we introduce MuTox, the first highly multilingual audio-based dataset with toxicity labels. The dataset comprises 20,000 audio utterances for English and Spanish, and 4,000 for the other 19 languages. To demonstrate the quality of this dataset, we trained the MuTox audio-based toxicity classifier, which enables zero-shot toxicity detection across a wide range of languages. This classifier outperforms existing text-based trainable classifiers by more than 1% AUC, while expanding the language coverage more than tenfold. When compared to a wordlist-based classifier that covers a similar number of languages, MuTox improves precision and recall by approximately 2.5 times. This significant improvement underscores the potential of MuTox in advancing the field of audio-based toxicity detection.
Efficient speech detection in environmental audio using acoustic recognition and knowledge distillation
Dec 14, 2023The ongoing biodiversity crisis, driven by factors such as land-use change and global warming, emphasizes the need for effective ecological monitoring methods. Acoustic monitoring of biodiversity has emerged as an important monitoring tool. Detecting human voices in soundscape monitoring projects is useful both for analysing human disturbance and for privacy filtering. Despite significant strides in deep learning in recent years, the deployment of large neural networks on compact devices poses challenges due to memory and latency constraints. Our approach focuses on leveraging knowledge distillation techniques to design efficient, lightweight student models for speech detection in bioacoustics. In particular, we employed the MobileNetV3-Small-Pi model to create compact yet effective student architectures to compare against the larger EcoVAD teacher model, a well-regarded voice detection architecture in eco-acoustic monitoring. The comparative analysis included examining various configurations of the MobileNetV3-Small-Pi derived student models to identify optimal performance. Additionally, a thorough evaluation of different distillation techniques was conducted to ascertain the most effective method for model selection. Our findings revealed that the distilled models exhibited comparable performance to the EcoVAD teacher model, indicating a promising approach to overcoming computational barriers for real-time ecological monitoring.
Low-latency Speech Enhancement via Speech Token Generation
Oct 20, 2023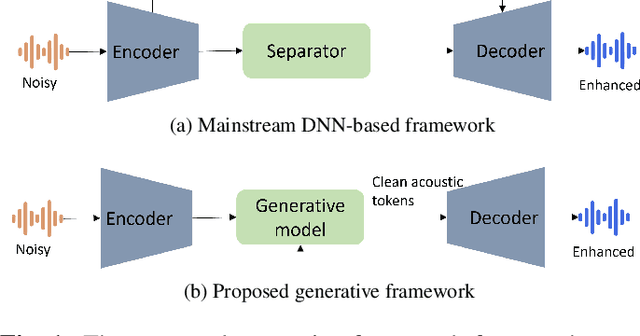
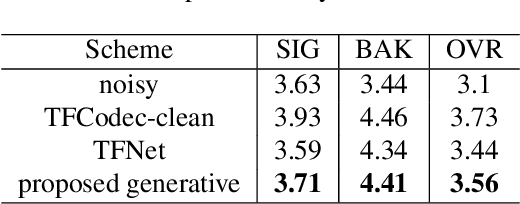
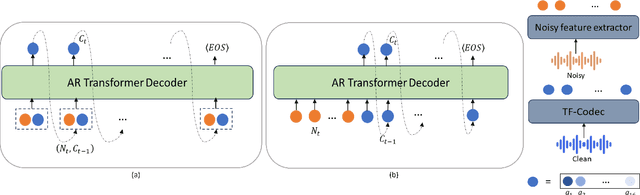
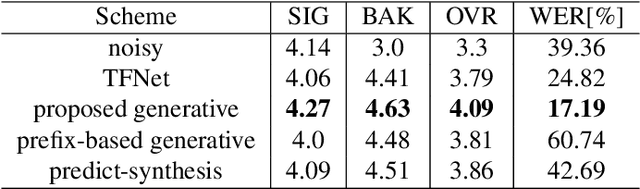
Existing deep learning based speech enhancement mainly employ a data-driven approach, which leverage large amounts of data with a variety of noise types to achieve noise removal from noisy signal. However, the high dependence on the data limits its generalization on the unseen complex noises in real-life environment. In this paper, we focus on the low-latency scenario and regard speech enhancement as a speech generation problem conditioned on the noisy signal, where we generate clean speech instead of identifying and removing noises. Specifically, we propose a conditional generative framework for speech enhancement, which models clean speech by acoustic codes of a neural speech codec and generates the speech codes conditioned on past noisy frames in an auto-regressive way. Moreover, we propose an explicit-alignment approach to align noisy frames with the generated speech tokens to improve the robustness and scalability to different input lengths. Different from other methods that leverage multiple stages to generate speech codes, we leverage a single-stage speech generation approach based on the TF-Codec neural codec to achieve high speech quality with low latency. Extensive results on both synthetic and real-recorded test set show its superiority over data-driven approaches in terms of noise robustness and temporal speech coherence.
Geodesic interpolation of frame-wise speaker embeddings for the diarization of meeting scenarios
Jan 08, 2024We propose a modified teacher-student training for the extraction of frame-wise speaker embeddings that allows for an effective diarization of meeting scenarios containing partially overlapping speech. To this end, a geodesic distance loss is used that enforces the embeddings computed from regions with two active speakers to lie on the shortest path on a sphere between the points given by the d-vectors of each of the active speakers. Using those frame-wise speaker embeddings in clustering-based diarization outperforms segment-level clustering-based diarization systems such as VBx and Spectral Clustering. By extending our approach to a mixture-model-based diarization, the performance can be further improved, approaching the diarization error rates of diarization systems that use a dedicated overlap detection, and outperforming these systems when also employing an additional overlap detection.
The NUS-HLT System for ICASSP2024 ICMC-ASR Grand Challenge
Dec 26, 2023This paper summarizes our team's efforts in both tracks of the ICMC-ASR Challenge for in-car multi-channel automatic speech recognition. Our submitted systems for ICMC-ASR Challenge include the multi-channel front-end enhancement and diarization, training data augmentation, speech recognition modeling with multi-channel branches. Tested on the offical Eval1 and Eval2 set, our best system achieves a relative 34.3% improvement in CER and 56.5% improvement in cpCER, compared to the offical baseline system.
Audiobox: Unified Audio Generation with Natural Language Prompts
Dec 25, 2023Audio is an essential part of our life, but creating it often requires expertise and is time-consuming. Research communities have made great progress over the past year advancing the performance of large scale audio generative models for a single modality (speech, sound, or music) through adopting more powerful generative models and scaling data. However, these models lack controllability in several aspects: speech generation models cannot synthesize novel styles based on text description and are limited on domain coverage such as outdoor environments; sound generation models only provide coarse-grained control based on descriptions like "a person speaking" and would only generate mumbling human voices. This paper presents Audiobox, a unified model based on flow-matching that is capable of generating various audio modalities. We design description-based and example-based prompting to enhance controllability and unify speech and sound generation paradigms. We allow transcript, vocal, and other audio styles to be controlled independently when generating speech. To improve model generalization with limited labels, we adapt a self-supervised infilling objective to pre-train on large quantities of unlabeled audio. Audiobox sets new benchmarks on speech and sound generation (0.745 similarity on Librispeech for zero-shot TTS; 0.77 FAD on AudioCaps for text-to-sound) and unlocks new methods for generating audio with novel vocal and acoustic styles. We further integrate Bespoke Solvers, which speeds up generation by over 25 times compared to the default ODE solver for flow-matching, without loss of performance on several tasks. Our demo is available at https://audiobox.metademolab.com/
FADI-AEC: Fast Score Based Diffusion Model Guided by Far-end Signal for Acoustic Echo Cancellation
Jan 08, 2024Despite the potential of diffusion models in speech enhancement, their deployment in Acoustic Echo Cancellation (AEC) has been restricted. In this paper, we propose DI-AEC, pioneering a diffusion-based stochastic regeneration approach dedicated to AEC. Further, we propose FADI-AEC, fast score-based diffusion AEC framework to save computational demands, making it favorable for edge devices. It stands out by running the score model once per frame, achieving a significant surge in processing efficiency. Apart from that, we introduce a novel noise generation technique where far-end signals are utilized, incorporating both far-end and near-end signals to refine the score model's accuracy. We test our proposed method on the ICASSP2023 Microsoft deep echo cancellation challenge evaluation dataset, where our method outperforms some of the end-to-end methods and other diffusion based echo cancellation methods.
Vec-Tok Speech: speech vectorization and tokenization for neural speech generation
Oct 12, 2023Language models (LMs) have recently flourished in natural language processing and computer vision, generating high-fidelity texts or images in various tasks. In contrast, the current speech generative models are still struggling regarding speech quality and task generalization. This paper presents Vec-Tok Speech, an extensible framework that resembles multiple speech generation tasks, generating expressive and high-fidelity speech. Specifically, we propose a novel speech codec based on speech vectors and semantic tokens. Speech vectors contain acoustic details contributing to high-fidelity speech reconstruction, while semantic tokens focus on the linguistic content of speech, facilitating language modeling. Based on the proposed speech codec, Vec-Tok Speech leverages an LM to undertake the core of speech generation. Moreover, Byte-Pair Encoding (BPE) is introduced to reduce the token length and bit rate for lower exposure bias and longer context coverage, improving the performance of LMs. Vec-Tok Speech can be used for intra- and cross-lingual zero-shot voice conversion (VC), zero-shot speaking style transfer text-to-speech (TTS), speech-to-speech translation (S2ST), speech denoising, and speaker de-identification and anonymization. Experiments show that Vec-Tok Speech, built on 50k hours of speech, performs better than other SOTA models. Code will be available at https://github.com/BakerBunker/VecTok .
1SPU: 1-step Speech Processing Unit
Nov 10, 2023Recent studies have made some progress in refining end-to-end (E2E) speech recognition encoders by applying Connectionist Temporal Classification (CTC) loss to enhance named entity recognition within transcriptions. However, these methods have been constrained by their exclusive use of the ASCII character set, allowing only a limited array of semantic labels. We propose 1SPU, a 1-step Speech Processing Unit which can recognize speech events (e.g: speaker change) or an NL event (Intent, Emotion) while also transcribing vocal content. It extends the E2E automatic speech recognition (ASR) system's vocabulary by adding a set of unused placeholder symbols, conceptually akin to the <pad> tokens used in sequence modeling. These placeholders are then assigned to represent semantic events (in form of tags) and are integrated into the transcription process as distinct tokens. We demonstrate notable improvements on the SLUE benchmark and yields results that are on par with those for the SLURP dataset. Additionally, we provide a visual analysis of the system's proficiency in accurately pinpointing meaningful tokens over time, illustrating the enhancement in transcription quality through the utilization of supplementary semantic tags.