 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improved Speech Reconstruction from Silent Video
Aug 29, 2017
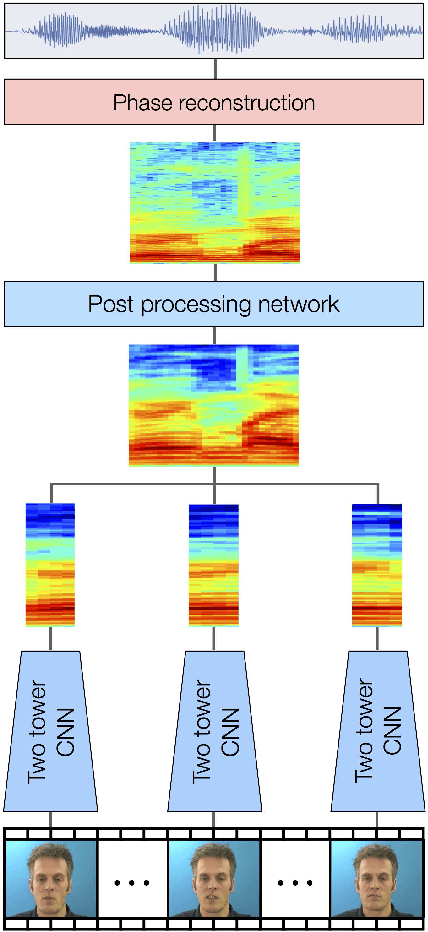

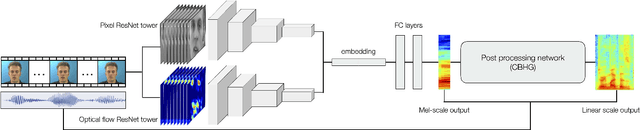
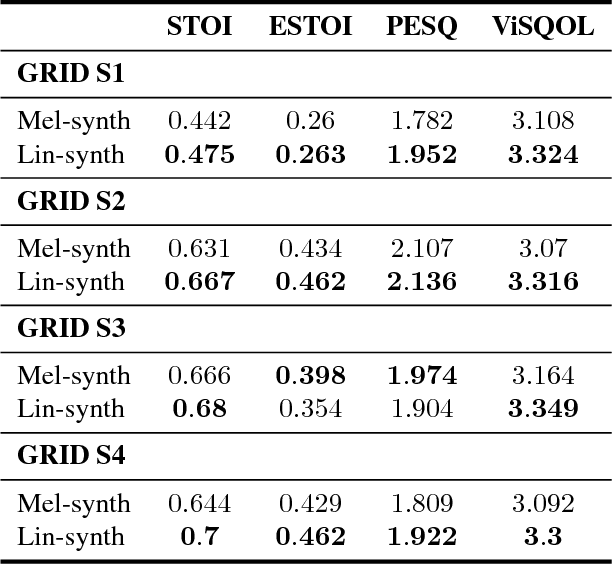
Speechreading is the task of inferring phonetic information from visually observed articulatory facial movements, and is a notoriously difficult task for humans to perform. In this paper we present an end-to-end model based on a convolutional neural network (CNN) for generating an intelligible and natural-sounding acoustic speech signal from silent video frames of a speaking person. We train our model on speakers from the GRID and TCD-TIMIT datasets, and evaluate the quality and intelligibility of reconstructed speech using common objective measurements. We show that speech predictions from the proposed model attain scores which indicate significantly improved quality over existing models. In addition, we show promising results towards reconstructing speech from an unconstrained dictionary.
A Machine Learning Approach to Detect Suicidal Ideation in US Veterans Based on Acoustic and Linguistic Features of Speech
Sep 14, 2020
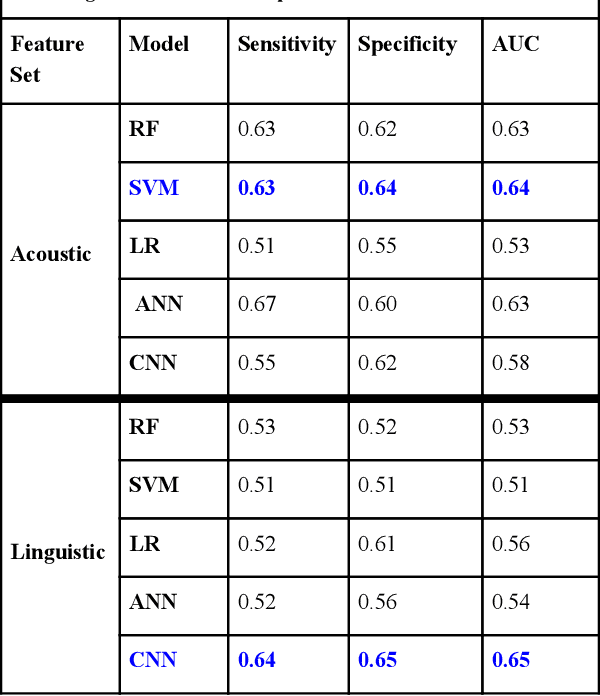

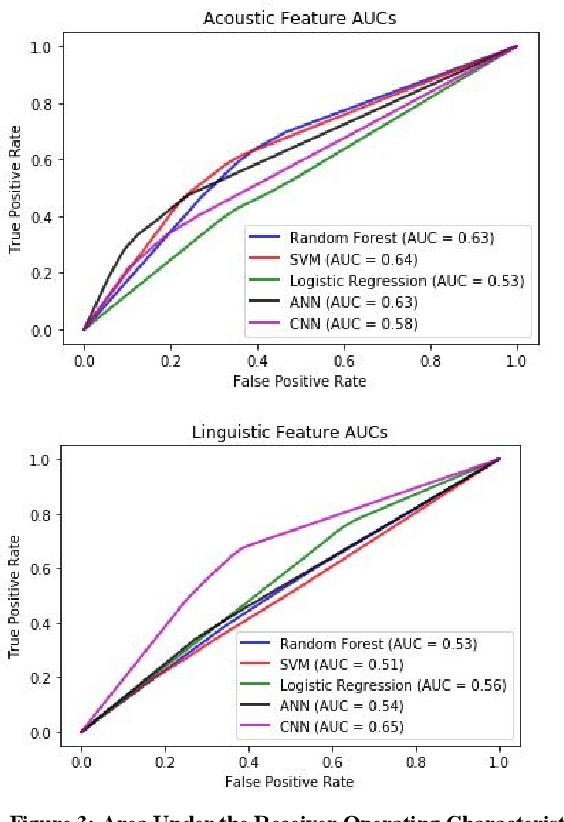
Preventing Veteran suicide is a national priority. The US Department of Veterans Affairs (VA) collects, analyzes, and publishes data to inform suicide prevention strategies. Current approaches for detecting suicidal ideation mostly rely on patient self report which are inadequate and time consuming. In this research study, our goal was to automate suicidal ideation detection from acoustic and linguistic features of an individual's speech using machine learning (ML) algorithms. Using voice data collected from Veterans enrolled in a large interventional study on Gulf War Illness at the Washington DC VA Medical Center, we conducted an evaluation of the performance of different ML approaches in achieving our objective. By fitting both classical ML and deep learning models to the dataset, we identified the algorithms that were most effective for each feature set. Among classical machine learning algorithms, the Support Vector Machine (SVM) trained on acoustic features performed best in classifying suicidal Veterans. Among deep learning methods, the Convolutional Neural Network (CNN) trained on the linguistic features performed best. Our study shows that speech analysis in a machine learning pipeline is a promising approach for detecting suicidality among Veterans.
FBWave: Efficient and Scalable Neural Vocoders for Streaming Text-To-Speech on the Edge
Nov 25, 2020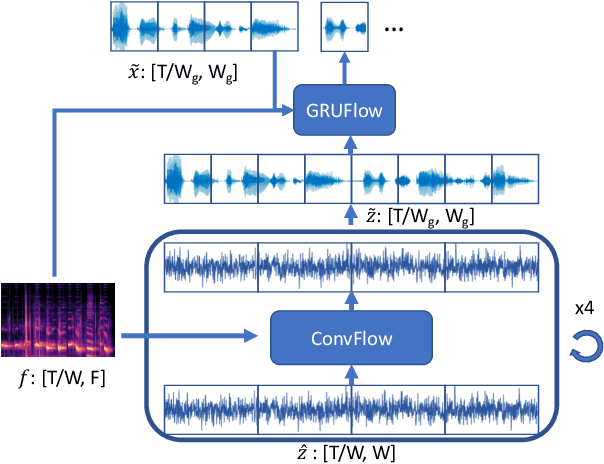
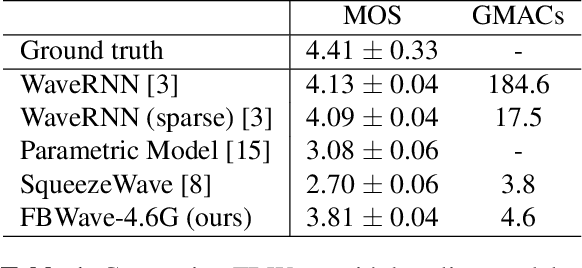
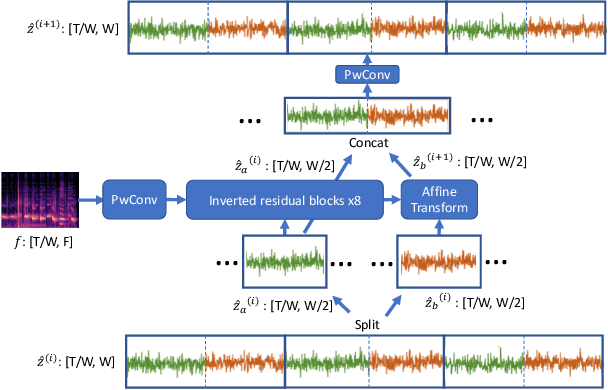

Nowadays more and more applications can benefit from edge-based text-to-speech (TTS). However, most existing TTS models are too computationally expensive and are not flexible enough to be deployed on the diverse variety of edge devices with their equally diverse computational capacities. To address this, we propose FBWave, a family of efficient and scalable neural vocoders that can achieve optimal performance-efficiency trade-offs for different edge devices. FBWave is a hybrid flow-based generative model that combines the advantages of autoregressive and non-autoregressive models. It produces high quality audio and supports streaming during inference while remaining highly computationally efficient. Our experiments show that FBWave can achieve similar audio quality to WaveRNN while reducing MACs by 40x. More efficient variants of FBWave can achieve up to 109x fewer MACs while still delivering acceptable audio quality. Audio demos are available at https://bichenwu09.github.io/vocoder_demos.
Improving the fusion of acoustic and text representations in RNN-T
Jan 25, 2022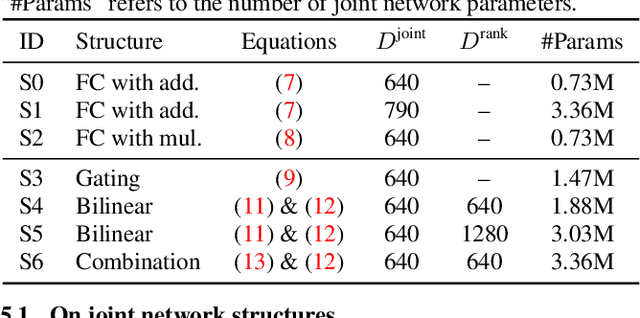

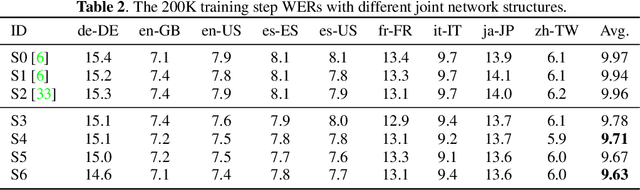
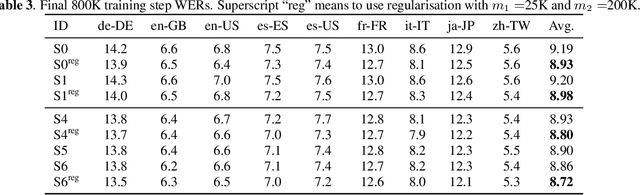
The recurrent neural network transducer (RNN-T) has recently become the mainstream end-to-end approach for streaming automatic speech recognition (ASR). To estimate the output distributions over subword units, RNN-T uses a fully connected layer as the joint network to fuse the acoustic representations extracted using the acoustic encoder with the text representations obtained using the prediction network based on the previous subword units. In this paper, we propose to use gating, bilinear pooling, and a combination of them in the joint network to produce more expressive representations to feed into the output layer. A regularisation method is also proposed to enable better acoustic encoder training by reducing the gradients back-propagated into the prediction network at the beginning of RNN-T training. Experimental results on a multilingual ASR setting for voice search over nine languages show that the joint use of the proposed methods can result in 4%--5% relative word error rate reductions with only a few million extra parameters.
Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
Jul 24, 2019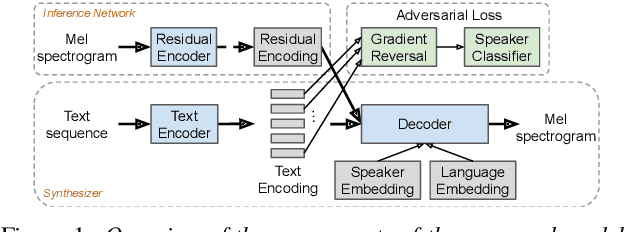
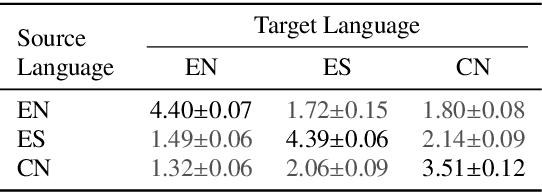
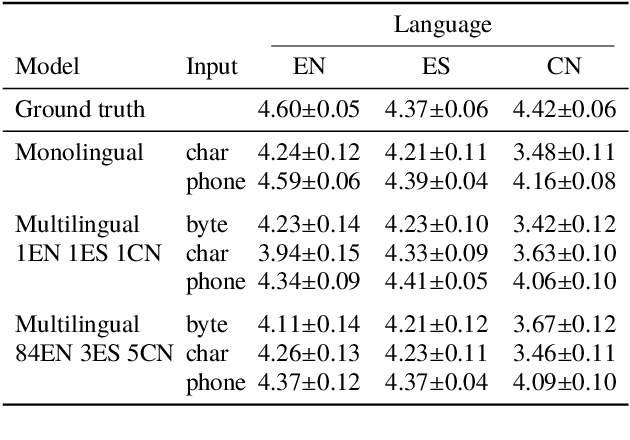
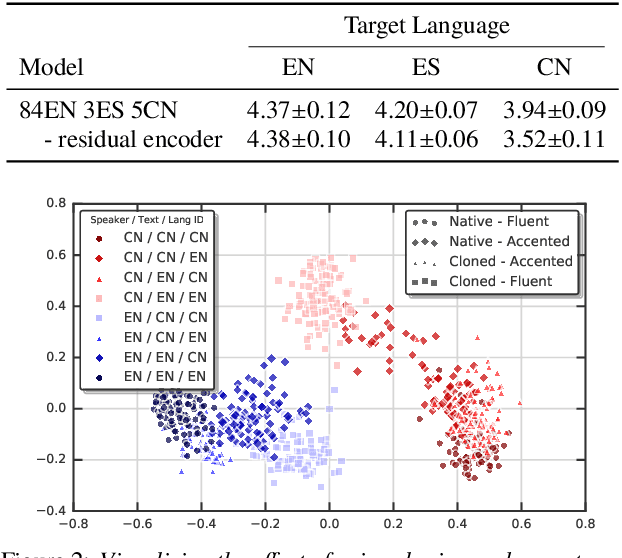
We present a multispeaker, multilingual text-to-speech (TTS) synthesis model based on Tacotron that is able to produce high quality speech in multiple languages. Moreover, the model is able to transfer voices across languages, e.g. synthesize fluent Spanish speech using an English speaker's voice, without training on any bilingual or parallel examples. Such transfer works across distantly related languages, e.g. English and Mandarin. Critical to achieving this result are: 1. using a phonemic input representation to encourage sharing of model capacity across languages, and 2. incorporating an adversarial loss term to encourage the model to disentangle its representation of speaker identity (which is perfectly correlated with language in the training data) from the speech content. Further scaling up the model by training on multiple speakers of each language, and incorporating an autoencoding input to help stabilize attention during training, results in a model which can be used to consistently synthesize intelligible speech for training speakers in all languages seen during training, and in native or foreign accents.
Pretraining Strategies, Waveform Model Choice, and Acoustic Configurations for Multi-Speaker End-to-End Speech Synthesis
Nov 10, 2020
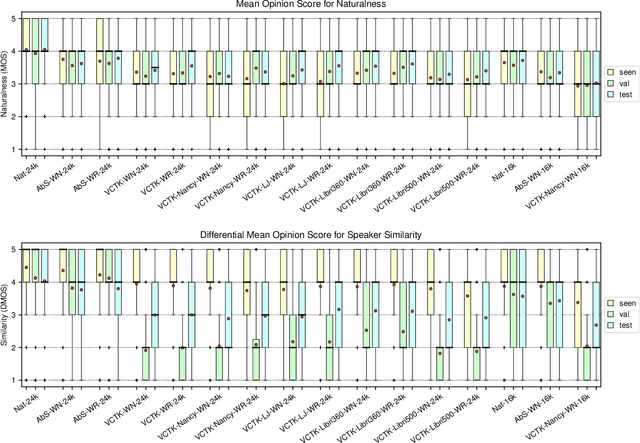
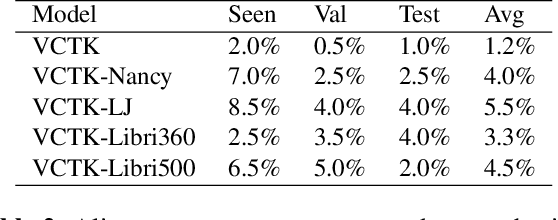
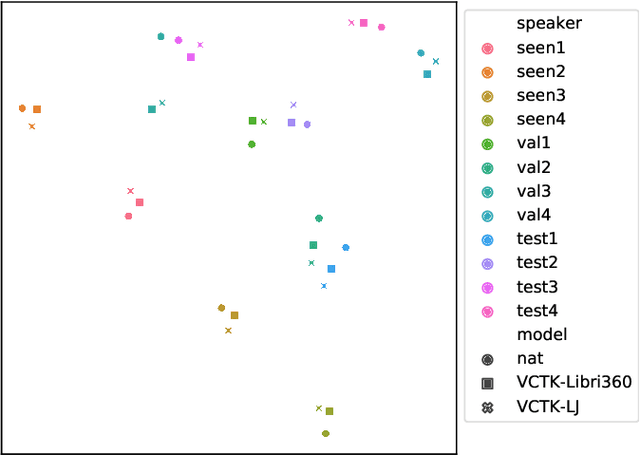
We explore pretraining strategies including choice of base corpus with the aim of choosing the best strategy for zero-shot multi-speaker end-to-end synthesis. We also examine choice of neural vocoder for waveform synthesis, as well as acoustic configurations used for mel spectrograms and final audio output. We find that fine-tuning a multi-speaker model from found audiobook data that has passed a simple quality threshold can improve naturalness and similarity to unseen target speakers of synthetic speech. Additionally, we find that listeners can discern between a 16kHz and 24kHz sampling rate, and that WaveRNN produces output waveforms of a comparable quality to WaveNet, with a faster inference time.
GC-TTS: Few-shot Speaker Adaptation with Geometric Constraints
Aug 16, 2021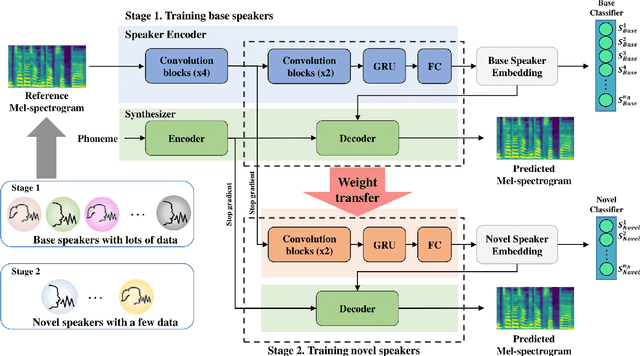
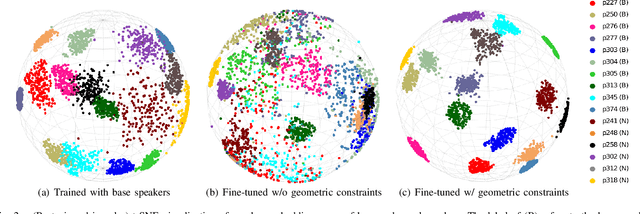
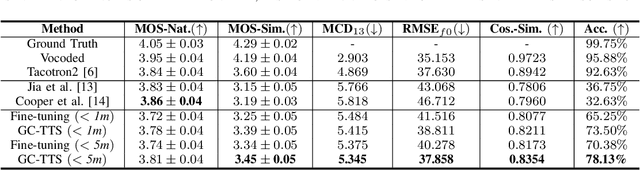

Few-shot speaker adaptation is a specific Text-to-Speech (TTS) system that aims to reproduce a novel speaker's voice with a few training data. While numerous attempts have been made to the few-shot speaker adaptation system, there is still a gap in terms of speaker similarity to the target speaker depending on the amount of data. To bridge the gap, we propose GC-TTS which achieves high-quality speaker adaptation with significantly improved speaker similarity. Specifically, we leverage two geometric constraints to learn discriminative speaker representations. Here, a TTS model is pre-trained for base speakers with a sufficient amount of data, and then fine-tuned for novel speakers on a few minutes of data with two geometric constraints. Two geometric constraints enable the model to extract discriminative speaker embeddings from limited data, which leads to the synthesis of intelligible speech. We discuss and verify the effectiveness of GC-TTS by comparing it with popular and essential methods. The experimental results demonstrate that GC-TTS generates high-quality speech from only a few minutes of training data, outperforming standard techniques in terms of speaker similarity to the target speaker.
Beyond $L_p$ clipping: Equalization-based Psychoacoustic Attacks against ASRs
Oct 25, 2021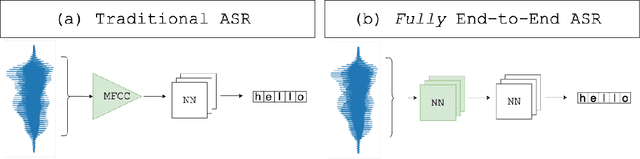

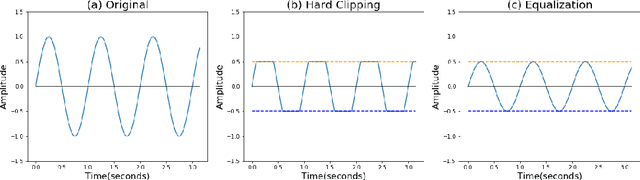
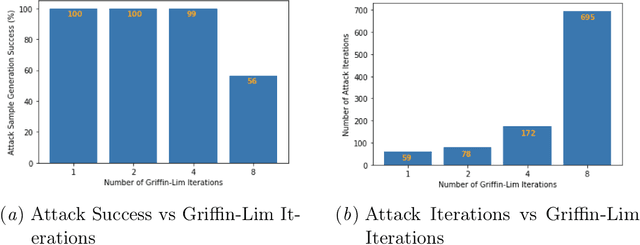
Automatic Speech Recognition (ASR) systems convert speech into text and can be placed into two broad categories: traditional and fully end-to-end. Both types have been shown to be vulnerable to adversarial audio examples that sound benign to the human ear but force the ASR to produce malicious transcriptions. Of these attacks, only the "psychoacoustic" attacks can create examples with relatively imperceptible perturbations, as they leverage the knowledge of the human auditory system. Unfortunately, existing psychoacoustic attacks can only be applied against traditional models, and are obsolete against the newer, fully end-to-end ASRs. In this paper, we propose an equalization-based psychoacoustic attack that can exploit both traditional and fully end-to-end ASRs. We successfully demonstrate our attack against real-world ASRs that include DeepSpeech and Wav2Letter. Moreover, we employ a user study to verify that our method creates low audible distortion. Specifically, 80 of the 100 participants voted in favor of all our attack audio samples as less noisier than the existing state-of-the-art attack. Through this, we demonstrate both types of existing ASR pipelines can be exploited with minimum degradation to attack audio quality.
The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes
Jun 08, 2020
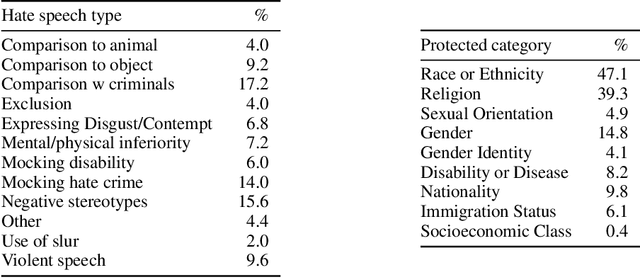
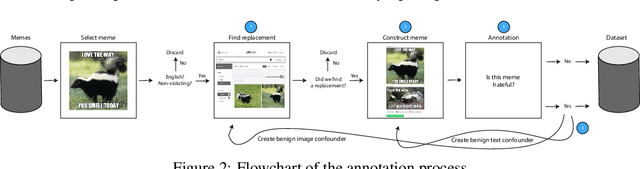

This work proposes a new challenge set for multimodal classification, focusing on detecting hate speech in multimodal memes. It is constructed such that unimodal models struggle and only multimodal models can succeed: difficult examples ("benign confounders") are added to the dataset to make it hard to rely on unimodal signals. The task requires subtle reasoning, yet is straightforward to evaluate as a binary classification problem. We provide baseline performance numbers for unimodal models, as well as for multimodal models with various degrees of sophistication. We find that state-of-the-art methods perform poorly compared to humans (64.73% vs. 84.7% accuracy), illustrating the difficulty of the task and highlighting the challenge that this important problem poses to the community.
Neural Simultaneous Speech Translation Using Alignment-Based Chunking
May 29, 2020
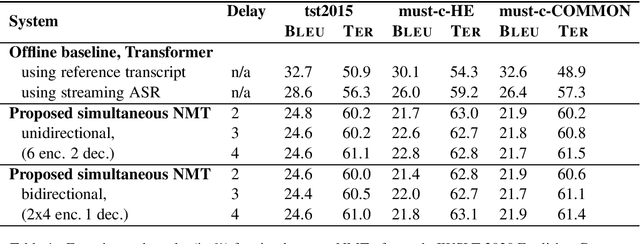
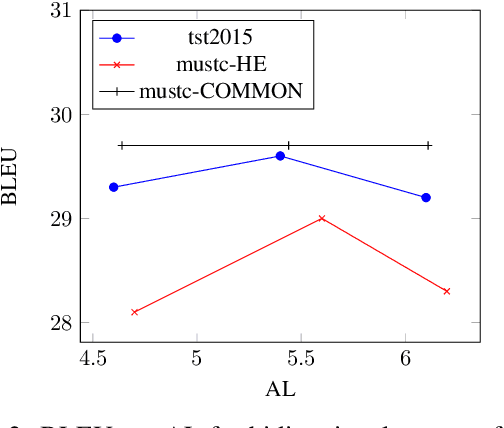
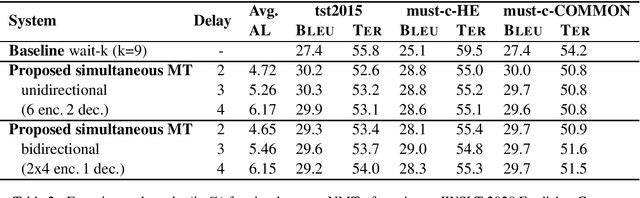
In simultaneous machine translation, the objective is to determine when to produce a partial translation given a continuous stream of source words, with a trade-off between latency and quality. We propose a neural machine translation (NMT) model that makes dynamic decisions when to continue feeding on input or generate output words. The model is composed of two main components: one to dynamically decide on ending a source chunk, and another that translates the consumed chunk. We train the components jointly and in a manner consistent with the inference conditions. To generate chunked training data, we propose a method that utilizes word alignment while also preserving enough context. We compare models with bidirectional and unidirectional encoders of different depths, both on real speech and text input. Our results on the IWSLT 2020 English-to-German task outperform a wait-k baseline by 2.6 to 3.7% BLEU absolute.