 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Flavored Tacotron: Conditional Learning for Prosodic-linguistic Features
Apr 08, 2021
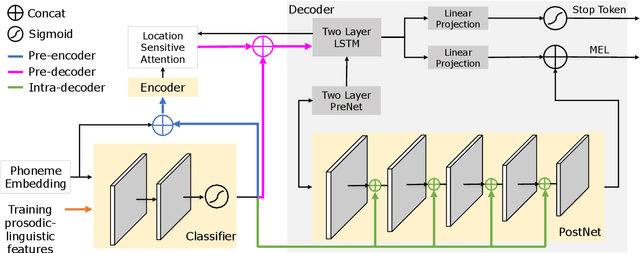
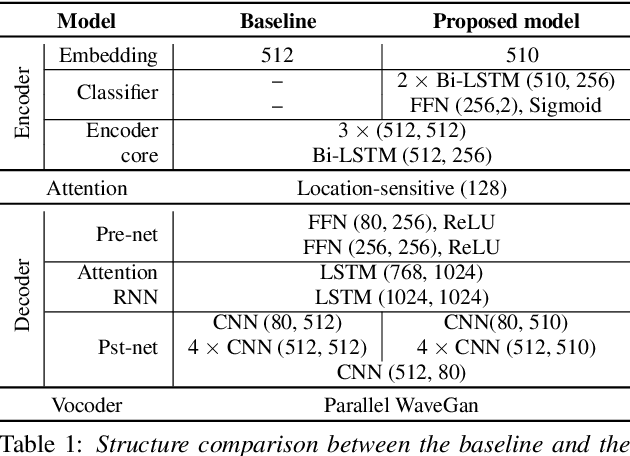
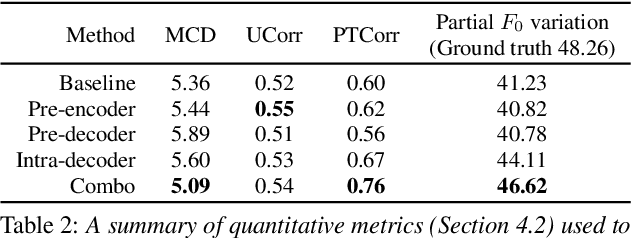
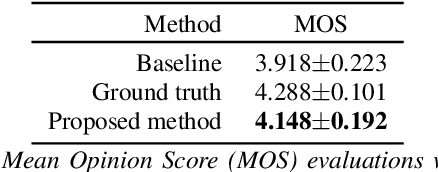
Neural sequence-to-sequence text-to-speech synthesis (TTS), such as Tacotron-2, transforms text into high-quality speech. However, generating speech with natural prosody still remains a challenge. Yasuda et. al. show that unlike natural speech, Tacotron-2's encoder doesn't fully represent prosodic features (e.g. syllable stress in English) from characters, and result in flat fundamental frequency variations. In this work, we propose a novel carefully designed strategy for conditioning Tacotron-2 on two fundamental prosodic features in English -- stress syllable and pitch accent, that help achieve more natural prosody. To this end, we use of a classifier to learn these features in an end-to-end fashion, and apply feature conditioning at three parts of Tacotron-2's Text-To-Mel Spectrogram: pre-encoder, post-encoder, and intra-decoder. Further, we show that jointly conditioned features at pre-encoder and intra-decoder stages result in prosodically natural synthesized speech (vs. Tacotron-2), and allows the model to produce speech with more accurate pitch accent and stress patterns. Quantitative evaluations show that our formulation achieves higher fundamental frequency contour correlation, and lower Mel Cepstral Distortion measure between synthesized and natural speech. And subjective evaluation shows that the proposed method's Mean Opinion Score of 4.14 fairs higher than baseline Tacotron-2, 3.91, when compared against natural speech (LJSpeech corpus), 4.28.
VENOMAVE: Clean-Label Poisoning Against Speech Recognition
Oct 21, 2020

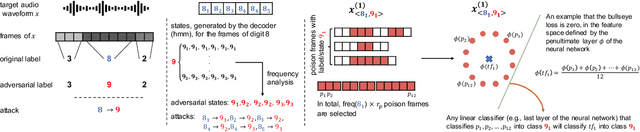
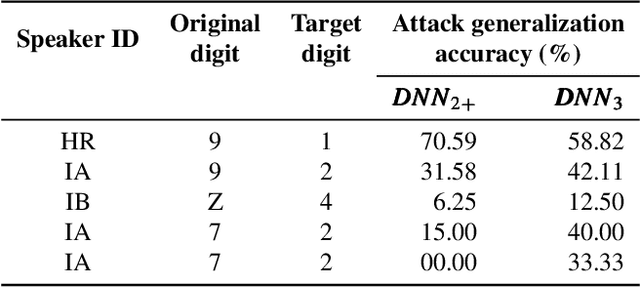
In the past few years, we observed a wide adoption of practical systems that use Automatic Speech Recognition (ASR) systems to improve human-machine interaction. Modern ASR systems are based on neural networks and prior research demonstrated that these systems are susceptible to adversarial examples, i.e., malicious audio inputs that lead to misclassification by the victim's network during the system's run time. The research question if ASR systems are also vulnerable to data poisoning attacks is still unanswered. In such an attack, a manipulation happens during the training phase of the neural network: an adversary injects malicious inputs into the training set such that the neural network's integrity and performance are compromised. In this paper, we present the first data poisoning attack in the audio domain, called VENOMAVE. Prior work in the image domain demonstrated several types of data poisoning attacks, but they cannot be applied to the audio domain. The main challenge is that we need to attack a time series of inputs. To enforce a targeted misclassification in an ASR system, we need to carefully generate a specific sequence of disturbed inputs for the target utterance, which will eventually be decoded to the desired sequence of words. More specifically, the adversarial goal is to produce a series of misclassification tasks and in each of them, we need to poison the system to misrecognize each frame of the target file. To demonstrate the practical feasibility of our attack, we evaluate VENOMAVE on an ASR system that detects sequences of digits from 0 to 9. When poisoning only 0.94% of the dataset on average, we achieve an attack success rate of 83.33%. We conclude that data poisoning attacks against ASR systems represent a real threat that needs to be considered.
Reconstructing Speech Stimuli From Human Auditory Cortex Activity Using a WaveNet Approach
Nov 08, 2018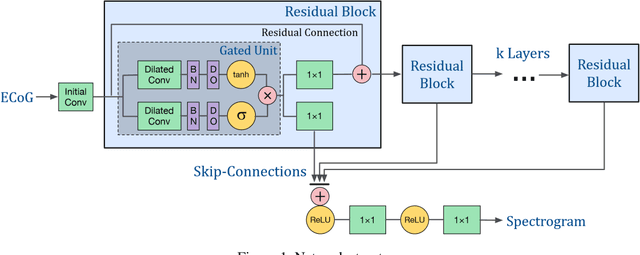
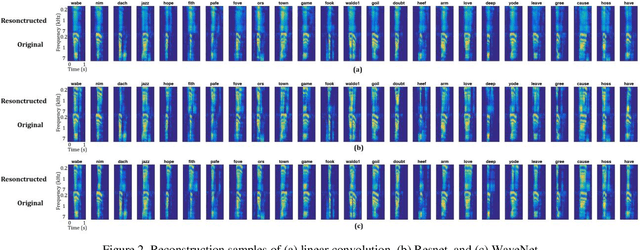
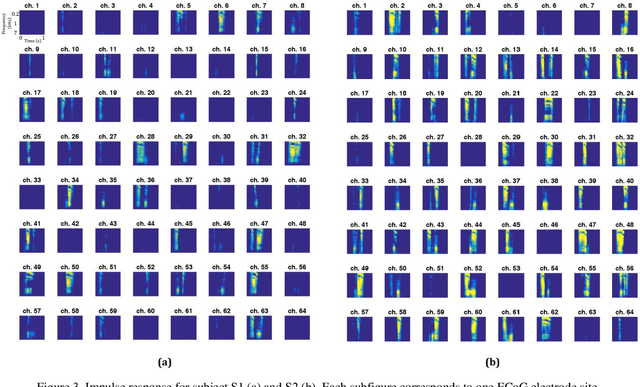

The superior temporal gyrus (STG) region of cortex critically contributes to speech recognition. In this work, we show that a proposed WaveNet, with limited available data, is able to reconstruct speech stimuli from STG intracranial recordings. We further investigate the impulse response of the fitted model for each recording electrode and observe phoneme level temporospectral tuning properties for the recorded area of cortex. This discovery is consistent with previous studies implicating the posterior STG (pSTG) in a phonetic representation of speech and provides detailed acoustic features that certain electrode sites possibly extract during speech recognition.
Author Profiling for Hate Speech Detection
Feb 14, 2019
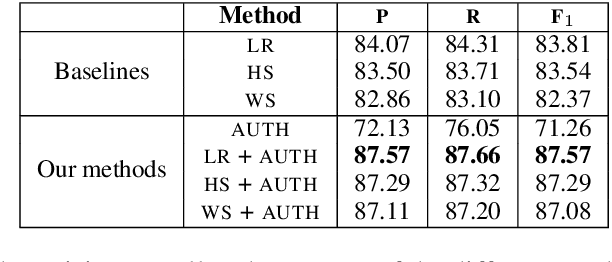
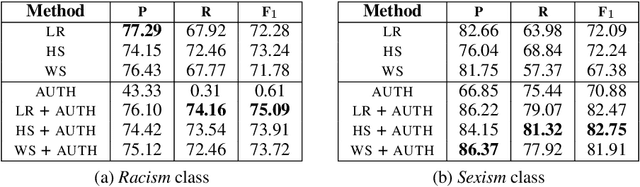

The rapid growth of social media in recent years has fed into some highly undesirable phenomena such as proliferation of abusive and offensive language on the Internet. Previous research suggests that such hateful content tends to come from users who share a set of common stereotypes and form communities around them. The current state-of-the-art approaches to hate speech detection are oblivious to user and community information and rely entirely on textual (i.e., lexical and semantic) cues. In this paper, we propose a novel approach to this problem that incorporates community-based profiling features of Twitter users. Experimenting with a dataset of 16k tweets, we show that our methods significantly outperform the current state of the art in hate speech detection. Further, we conduct a qualitative analysis of model characteristics. We release our code, pre-trained models and all the resources used in the public domain.
Knowledge Engineering in the Long Game of Artificial Intelligence: The Case of Speech Acts
Feb 02, 2022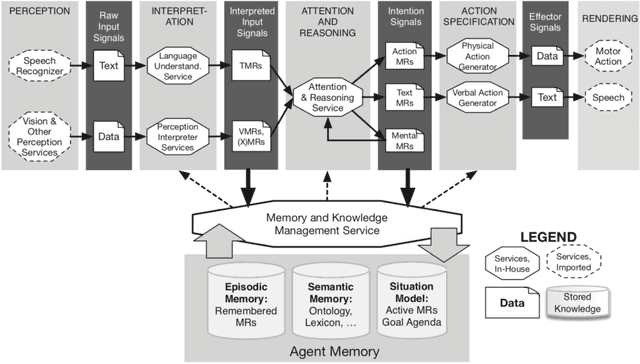



This paper describes principles and practices of knowledge engineering that enable the development of holistic language-endowed intelligent agents that can function across domains and applications, as well as expand their ontological and lexical knowledge through lifelong learning. For illustration, we focus on dialog act modeling, a task that has been widely pursued in linguistics, cognitive modeling, and statistical natural language processing. We describe an integrative approach grounded in the OntoAgent knowledge-centric cognitive architecture and highlight the limitations of past approaches that isolate dialog from other agent functionalities.
Adaptive Discounting of Implicit Language Models in RNN-Transducers
Feb 21, 2022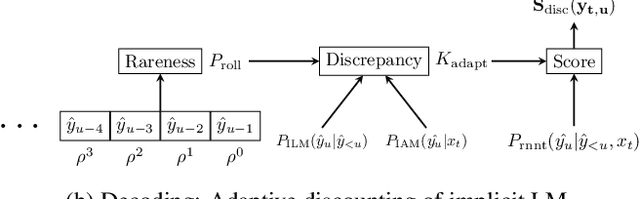
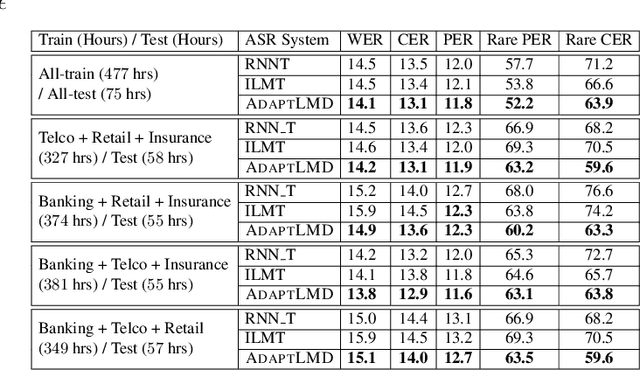
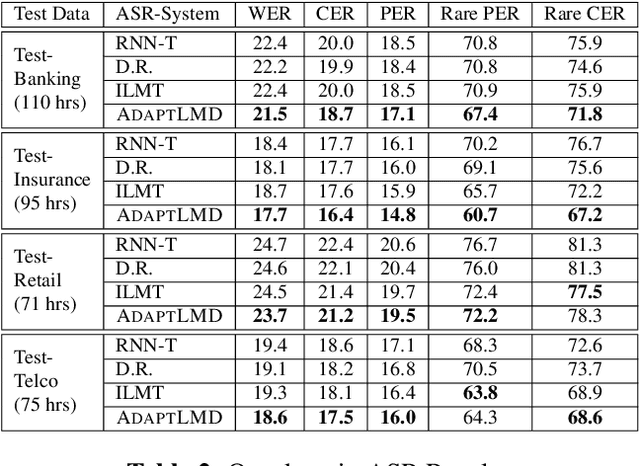
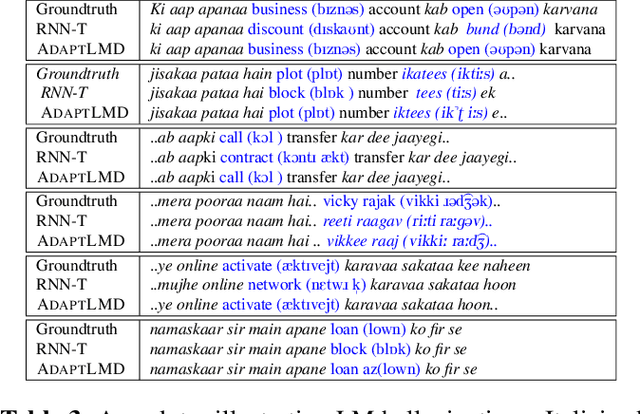
RNN-Transducer (RNN-T) models have become synonymous with streaming end-to-end ASR systems. While they perform competitively on a number of evaluation categories, rare words pose a serious challenge to RNN-T models. One main reason for the degradation in performance on rare words is that the language model (LM) internal to RNN-Ts can become overconfident and lead to hallucinated predictions that are acoustically inconsistent with the underlying speech. To address this issue, we propose a lightweight adaptive LM discounting technique AdaptLMD, that can be used with any RNN-T architecture without requiring any external resources or additional parameters. AdaptLMD uses a two-pronged approach: 1) Randomly mask the prediction network output to encourage the RNN-T to not be overly reliant on it's outputs. 2) Dynamically choose when to discount the implicit LM (ILM) based on rarity of recently predicted tokens and divergence between ILM and implicit acoustic model (IAM) scores. Comparing AdaptLMD to a competitive RNN-T baseline, we obtain up to 4% and 14% relative reductions in overall WER and rare word PER, respectively, on a conversational, code-mixed Hindi-English ASR task.
The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes
Jun 08, 2020
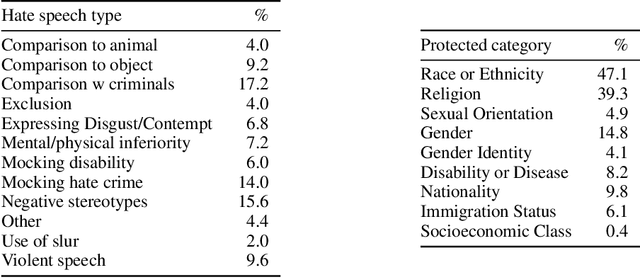
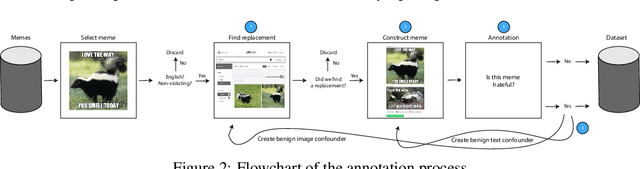

This work proposes a new challenge set for multimodal classification, focusing on detecting hate speech in multimodal memes. It is constructed such that unimodal models struggle and only multimodal models can succeed: difficult examples ("benign confounders") are added to the dataset to make it hard to rely on unimodal signals. The task requires subtle reasoning, yet is straightforward to evaluate as a binary classification problem. We provide baseline performance numbers for unimodal models, as well as for multimodal models with various degrees of sophistication. We find that state-of-the-art methods perform poorly compared to humans (64.73% vs. 84.7% accuracy), illustrating the difficulty of the task and highlighting the challenge that this important problem poses to the community.
Gesture based Arabic Sign Language Recognition for Impaired People based on Convolution Neural Network
Mar 10, 2022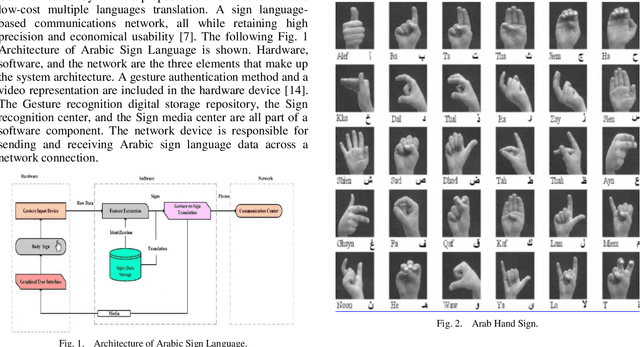
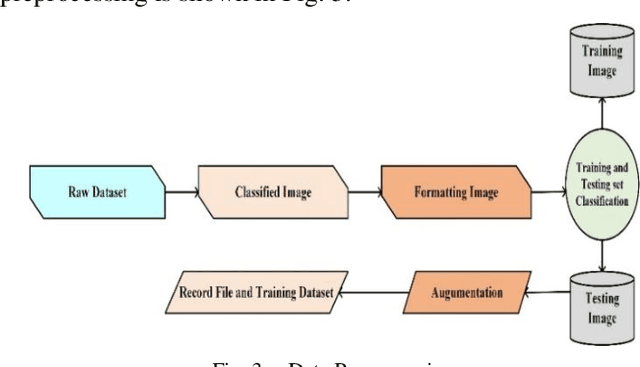
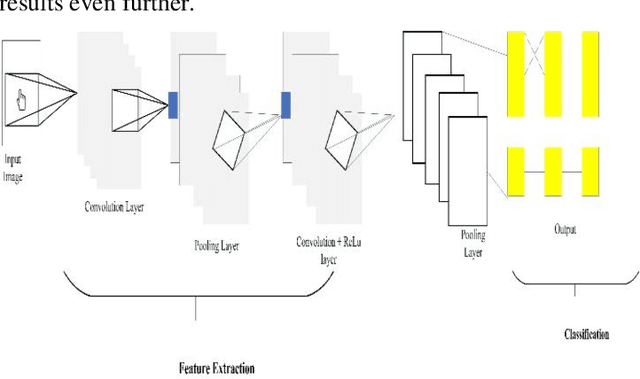
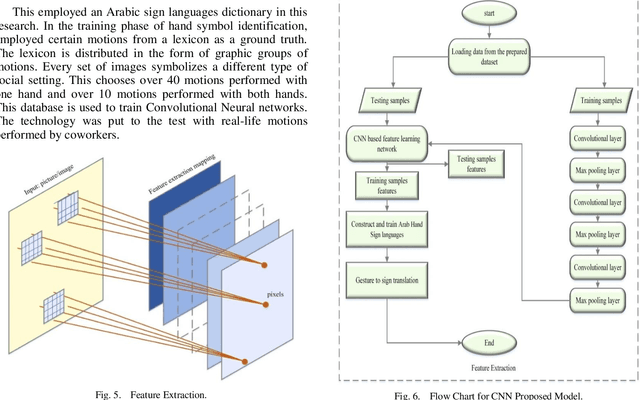
The Arabic Sign Language has endorsed outstanding research achievements for identifying gestures and hand signs using the deep learning methodology. The term "forms of communication" refers to the actions used by hearing-impaired people to communicate. These actions are difficult for ordinary people to comprehend. The recognition of Arabic Sign Language (ArSL) has become a difficult study subject due to variations in Arabic Sign Language (ArSL) from one territory to another and then within states. The Convolution Neural Network has been encapsulated in the proposed system which is based on the machine learning technique. For the recognition of the Arabic Sign Language, the wearable sensor is utilized. This approach has been used a different system that could suit all Arabic gestures. This could be used by the impaired people of the local Arabic community. The research method has been used with reasonable and moderate accuracy. A deep Convolutional network is initially developed for feature extraction from the data gathered by the sensing devices. These sensors can reliably recognize the Arabic sign language's 30 hand sign letters. The hand movements in the dataset were captured using DG5-V hand gloves with wearable sensors. For categorization purposes, the CNN technique is used. The suggested system takes Arabic sign language hand gestures as input and outputs vocalized speech as output. The results were recognized by 90% of the people.
Transformer-based language modeling and decoding for conversational speech recognition
Jan 04, 2020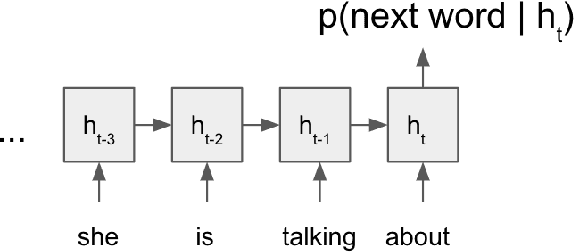
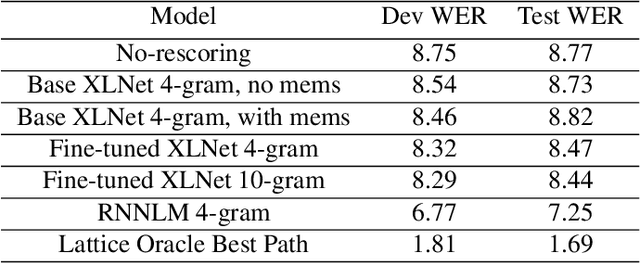
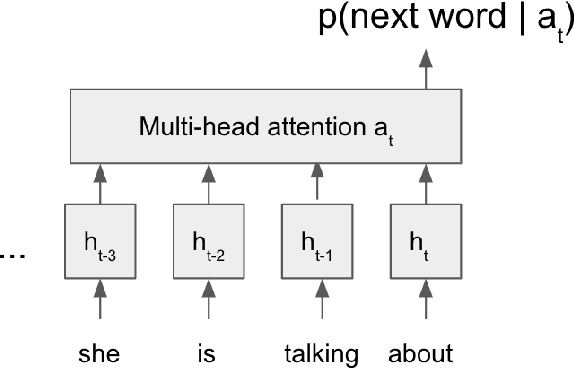
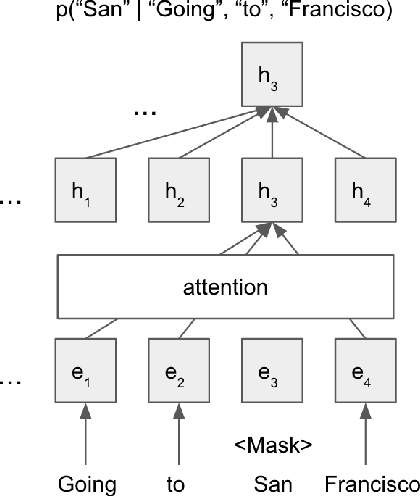
We propose a way to use a transformer-based language model in conversational speech recognition. Specifically, we focus on decoding efficiently in a weighted finite-state transducer framework. We showcase an approach to lattice re-scoring that allows for longer range history captured by a transfomer-based language model and takes advantage of a transformer's ability to avoid computing sequentially.
A Machine Learning Approach to Detect Suicidal Ideation in US Veterans Based on Acoustic and Linguistic Features of Speech
Sep 14, 2020
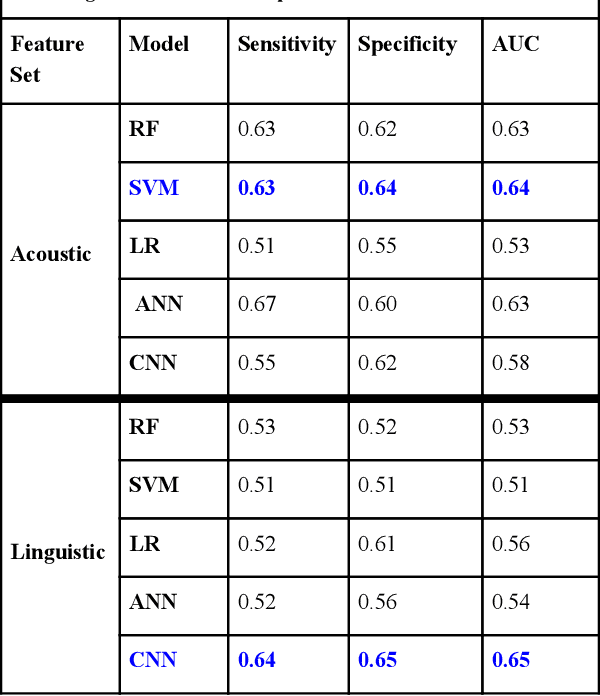

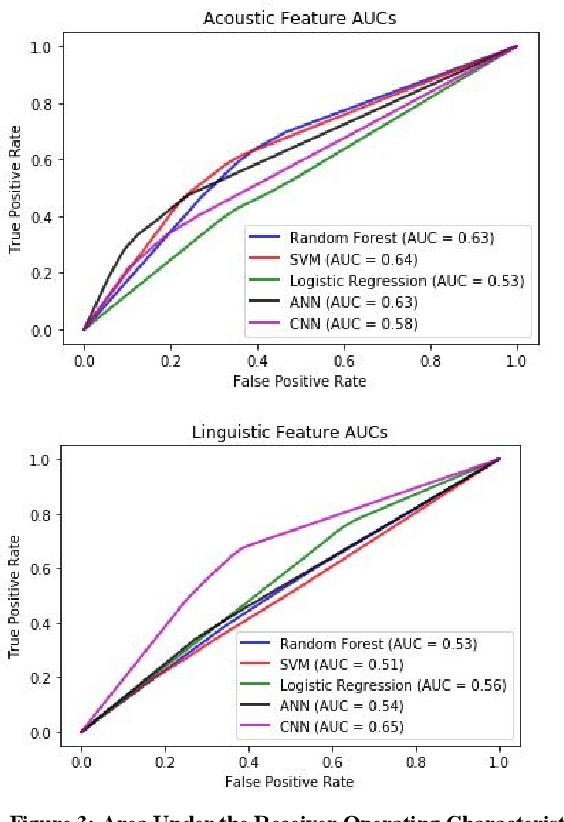
Preventing Veteran suicide is a national priority. The US Department of Veterans Affairs (VA) collects, analyzes, and publishes data to inform suicide prevention strategies. Current approaches for detecting suicidal ideation mostly rely on patient self report which are inadequate and time consuming. In this research study, our goal was to automate suicidal ideation detection from acoustic and linguistic features of an individual's speech using machine learning (ML) algorithms. Using voice data collected from Veterans enrolled in a large interventional study on Gulf War Illness at the Washington DC VA Medical Center, we conducted an evaluation of the performance of different ML approaches in achieving our objective. By fitting both classical ML and deep learning models to the dataset, we identified the algorithms that were most effective for each feature set. Among classical machine learning algorithms, the Support Vector Machine (SVM) trained on acoustic features performed best in classifying suicidal Veterans. Among deep learning methods, the Convolutional Neural Network (CNN) trained on the linguistic features performed best. Our study shows that speech analysis in a machine learning pipeline is a promising approach for detecting suicidality among Veterans.