 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Confidence Estimation for Black Box Automatic Speech Recognition Systems Using Lattice Recurrent Neural Networks
Oct 25, 2019
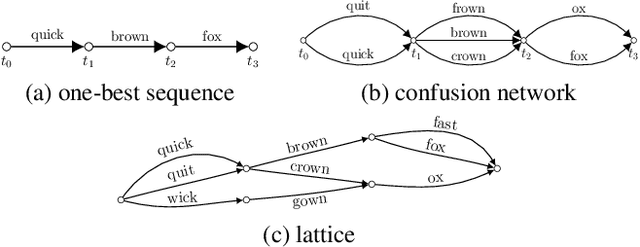
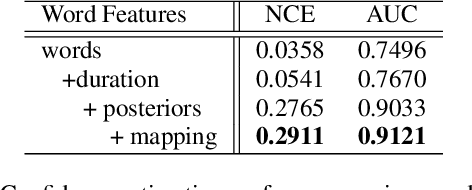
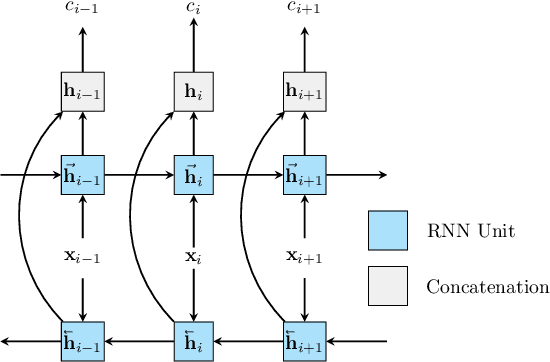
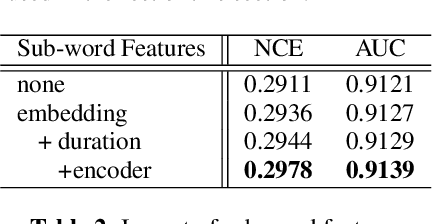
Recently, there has been growth in providers of speech transcription services enabling others to leverage technology they would not normally be able to use. As a result, speech-enabled solutions have become commonplace. Their success critically relies on the quality, accuracy, and reliability of the underlying speech transcription systems. Those black box systems, however, offer limited means for quality control as only word sequences are typically available. This paper examines this limited resource scenario for confidence estimation, a measure commonly used to assess transcription reliability. In particular, it explores what other sources of word and sub-word level information available in the transcription process could be used to improve confidence scores. To encode all such information this paper extends lattice recurrent neural networks to handle sub-words. Experimental results using the IARPA OpenKWS 2016 evaluation system show that the use of additional information yields significant gains in confidence estimation accuracy.
Emotion Recognition in Speech using Cross-Modal Transfer in the Wild
Aug 16, 2018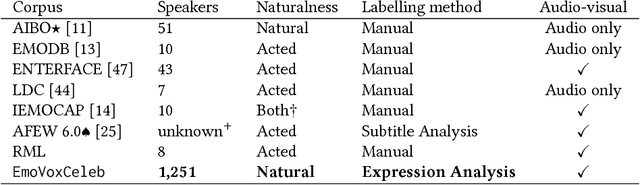



Obtaining large, human labelled speech datasets to train models for emotion recognition is a notoriously challenging task, hindered by annotation cost and label ambiguity. In this work, we consider the task of learning embeddings for speech classification without access to any form of labelled audio. We base our approach on a simple hypothesis: that the emotional content of speech correlates with the facial expression of the speaker. By exploiting this relationship, we show that annotations of expression can be transferred from the visual domain (faces) to the speech domain (voices) through cross-modal distillation. We make the following contributions: (i) we develop a strong teacher network for facial emotion recognition that achieves the state of the art on a standard benchmark; (ii) we use the teacher to train a student, tabula rasa, to learn representations (embeddings) for speech emotion recognition without access to labelled audio data; and (iii) we show that the speech emotion embedding can be used for speech emotion recognition on external benchmark datasets. Code, models and data are available.
Acoustic and Textual Data Augmentation for Improved ASR of Code-Switching Speech
Jul 28, 2018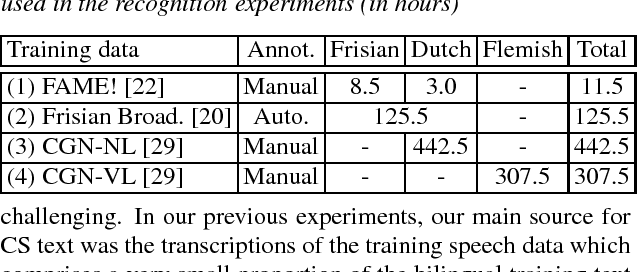
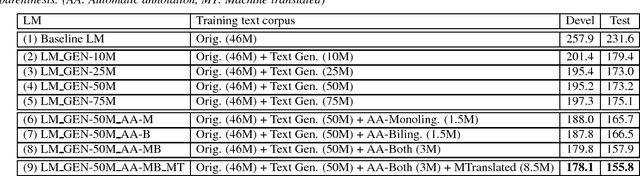
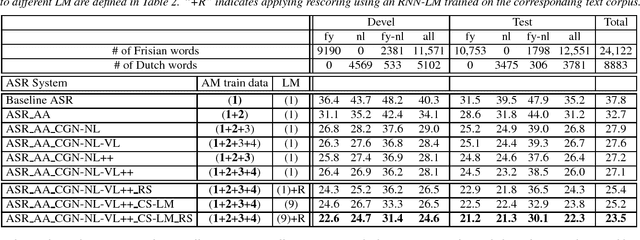
In this paper, we describe several techniques for improving the acoustic and language model of an automatic speech recognition (ASR) system operating on code-switching (CS) speech. We focus on the recognition of Frisian-Dutch radio broadcasts where one of the mixed languages, namely Frisian, is an under-resourced language. In previous work, we have proposed several automatic transcription strategies for CS speech to increase the amount of available training speech data. In this work, we explore how the acoustic modeling (AM) can benefit from monolingual speech data belonging to the high-resourced mixed language. For this purpose, we train state-of-the-art AMs, which were ineffective due to lack of training data, on a significantly increased amount of CS speech and monolingual Dutch speech. Moreover, we improve the language model (LM) by creating code-switching text, which is in practice almost non-existent, by (1) generating text using recurrent LMs trained on the transcriptions of the training CS speech data, (2) adding the transcriptions of the automatically transcribed CS speech data and (3) translating Dutch text extracted from the transcriptions of a large Dutch speech corpora. We report significantly improved CS ASR performance due to the increase in the acoustic and textual training data.
Generating Rich Product Descriptions for Conversational E-commerce Systems
Nov 30, 2021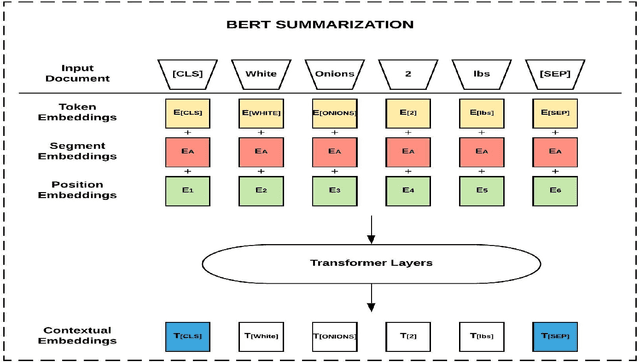

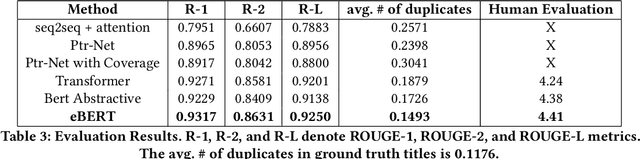
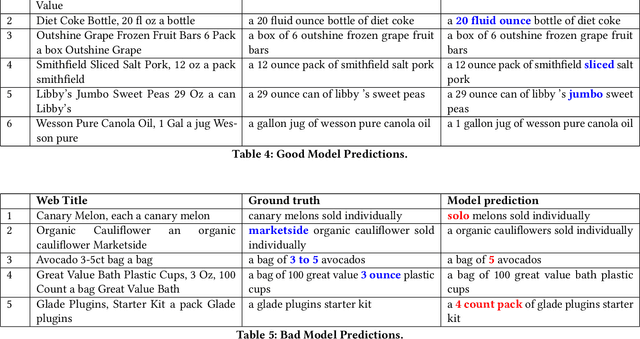
Through recent advancements in speech technologies and introduction of smart assistants, such as Amazon Alexa, Apple Siri and Google Home, increasing number of users are interacting with various applications through voice commands. E-commerce companies typically display short product titles on their webpages, either human-curated or algorithmically generated, when brevity is required. However, these titles are dissimilar from natural spoken language. For example, "Lucky Charms Gluten Free Break-fast Cereal, 20.5 oz a box Lucky Charms Gluten Free" is acceptable to display on a webpage, while a similar title cannot be used in a voice based text-to-speech application. In such conversational systems, an easy to comprehend sentence, such as "a 20.5 ounce box of lucky charms gluten free cereal" is preferred. Compared to display devices, where images and detailed product information can be presented to users, short titles for products which convey the most important information, are necessary when interfacing with voice assistants. We propose eBERT, a sequence-to-sequence approach by further pre-training the BERT embeddings on an e-commerce product description corpus, and then fine-tuning the resulting model to generate short, natural, spoken language titles from input web titles. Our extensive experiments on a real-world industry dataset, as well as human evaluation of model output, demonstrate that eBERT summarization outperforms comparable baseline models. Owing to the efficacy of the model, a version of this model has been deployed in real-world setting.
* 8 pages, 1 figure. arXiv admin note: substantial text overlap with arXiv:2007.11768
Local and non-local dependency learning and emergence of rule-like representations in speech data by Deep Convolutional Generative Adversarial Networks
Sep 27, 2020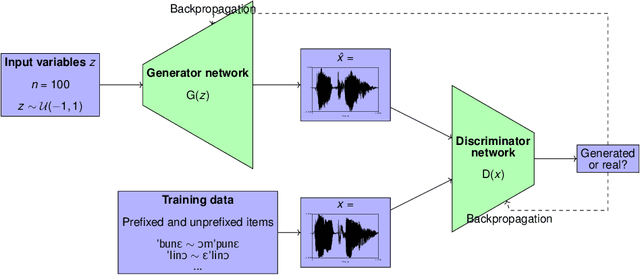
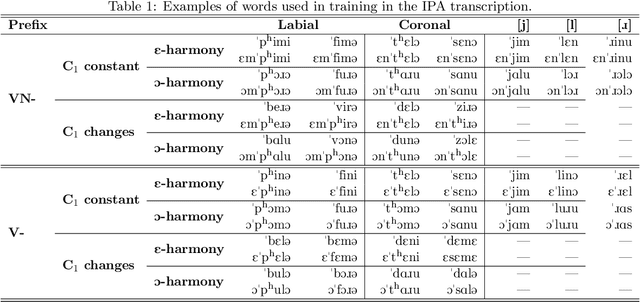
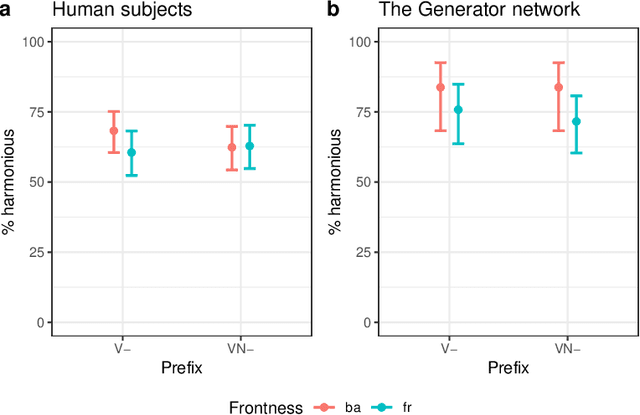
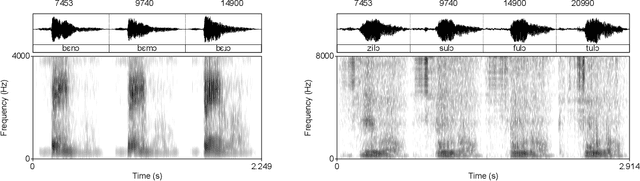
This paper argues that training GANs on local and non-local dependencies in speech data offers insights into how deep neural networks discretize continuous data and how symbolic-like rule-based morphophonological processes emerge in a deep convolutional architecture. Acquisition of speech has recently been modeled as a dependency between latent space and data generated by GANs in Begu\v{s} (arXiv:2006.03965), who models learning of a simple local allophonic distribution. We extend this approach to test learning of local and non-local phonological processes that include approximations of morphological processes. We further parallel outputs of the model to results of a behavioral experiment where human subjects are trained on the data used for training the GAN network. Four main conclusions emerge: (i) the networks provide useful information for computational models of language acquisition even if trained on a comparatively small dataset of an artificial grammar learning experiment; (ii) local processes are easier to learn than non-local processes, which matches both behavioral data in human subjects and typology in the world's languages. This paper also proposes (iii) how we can actively observe the network's progress in learning and explore the effect of training steps on learning representations by keeping latent space constant across different training steps. Finally, this paper shows that (iv) the network learns to encode the presence of a prefix with a single latent variable; by interpolating this variable, we can actively observe the operation of a non-local phonological process. The proposed technique for retrieving learning representations has general implications for our understanding of how GANs discretize continuous speech data and suggests that rule-like generalizations in the training data are represented as an interaction between variables in the network's latent space.
Effectiveness of self-supervised pre-training for speech recognition
Nov 10, 2019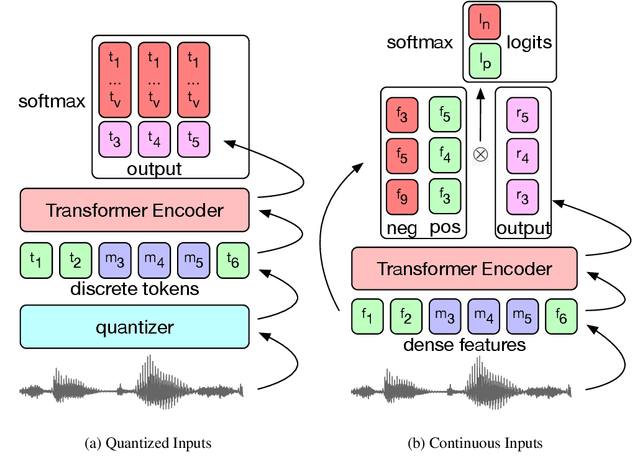
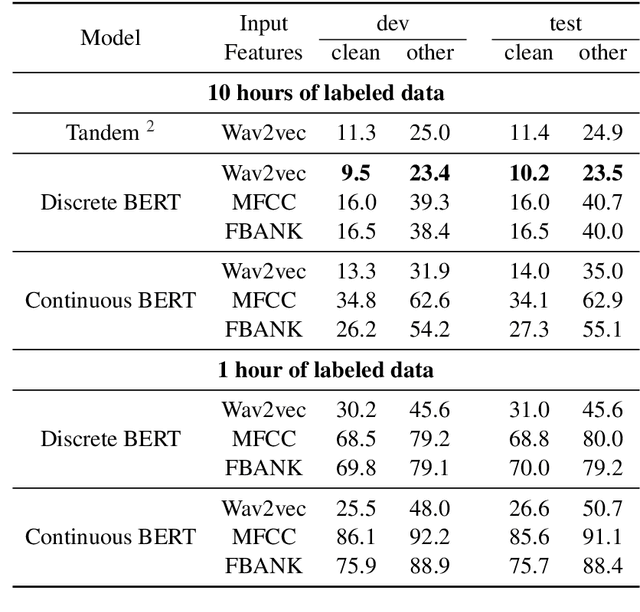
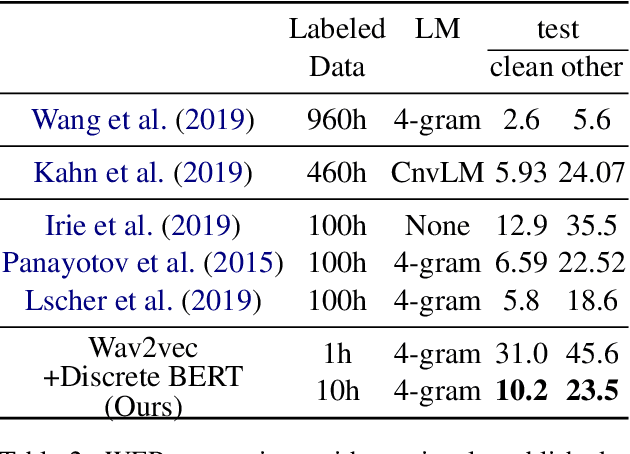
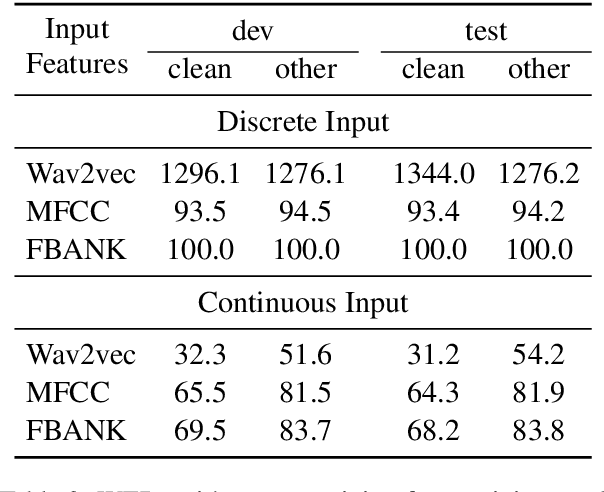
We present pre-training approaches for self-supervised representation learning of speech data. A BERT, masked language model, loss on discrete features is compared with an InfoNCE-based constrastive loss on continuous speech features. The pre-trained models are then fine-tuned with a Connectionist Temporal Classification (CTC) loss to predict target character sequences. To study impact of stacking multiple feature learning modules trained using different self-supervised loss functions, we test the discrete and continuous BERT pre-training approaches on spectral features and on learned acoustic representations, showing synergitic behaviour between acoustically motivated and masked language model loss functions. In low-resource conditions using only 10 hours of labeled data, we achieve Word Error Rates (WER) of 10.2\% and 23.5\% on the standard test "clean" and "other" benchmarks of the Librispeech dataset, which is almost on bar with previously published work that uses 10 times more labeled data. Moreover, compared to previous work that uses two models in tandem, by using one model for both BERT pre-trainining and fine-tuning, our model provides an average relative WER reduction of 9%.
Detecting Anomalies within Time Series using Local Neural Transformations
Feb 08, 2022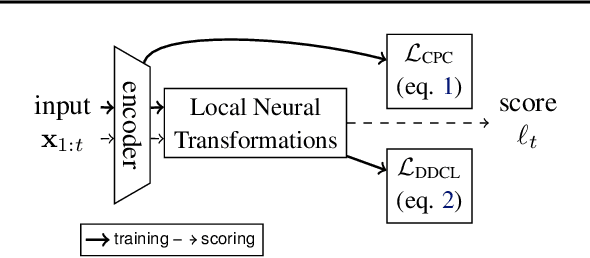
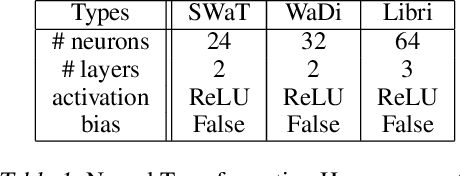
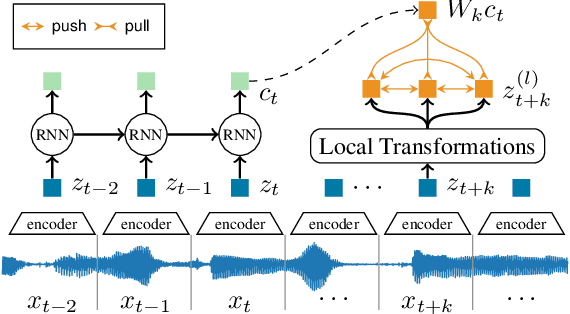
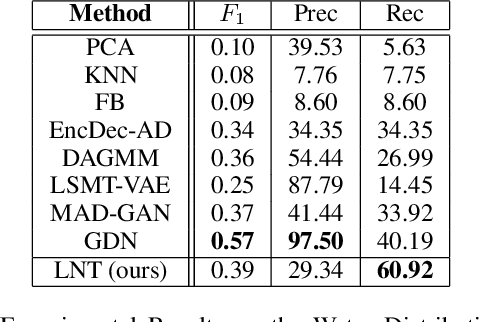
We develop a new method to detect anomalies within time series, which is essential in many application domains, reaching from self-driving cars, finance, and marketing to medical diagnosis and epidemiology. The method is based on self-supervised deep learning that has played a key role in facilitating deep anomaly detection on images, where powerful image transformations are available. However, such transformations are widely unavailable for time series. Addressing this, we develop Local Neural Transformations(LNT), a method learning local transformations of time series from data. The method produces an anomaly score for each time step and thus can be used to detect anomalies within time series. We prove in a theoretical analysis that our novel training objective is more suitable for transformation learning than previous deep Anomaly detection(AD) methods. Our experiments demonstrate that LNT can find anomalies in speech segments from the LibriSpeech data set and better detect interruptions to cyber-physical systems than previous work. Visualization of the learned transformations gives insight into the type of transformations that LNT learns.
Discriminative Learning for Monaural Speech Separation Using Deep Embedding Features
Jul 23, 2019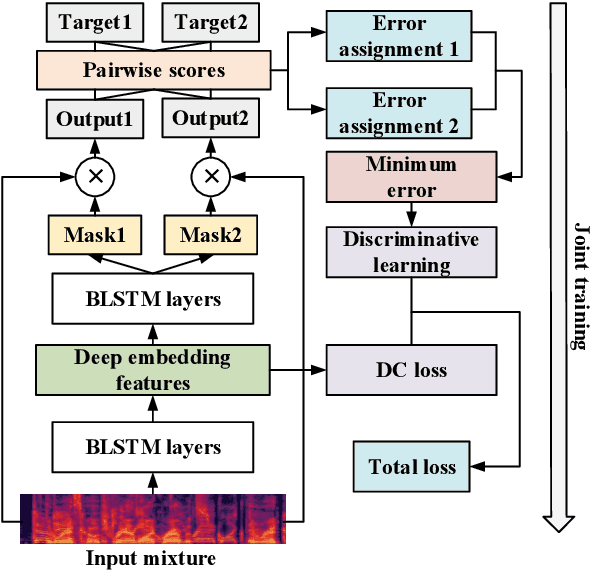
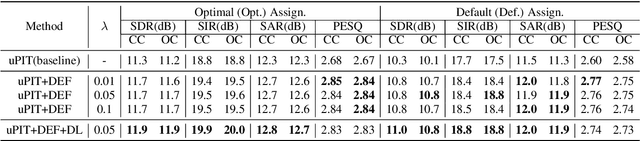
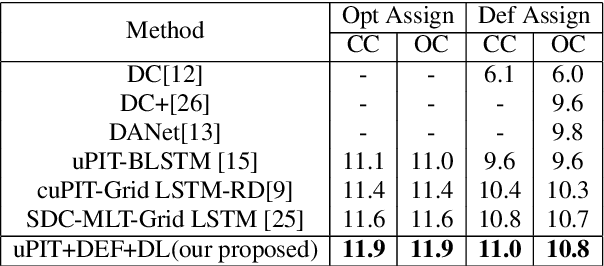
Deep clustering (DC) and utterance-level permutation invariant training (uPIT) have been demonstrated promising for speaker-independent speech separation. DC is usually formulated as two-step processes: embedding learning and embedding clustering, which results in complex separation pipelines and a huge obstacle in directly optimizing the actual separation objectives. As for uPIT, it only minimizes the chosen permutation with the lowest mean square error, doesn't discriminate it with other permutations. In this paper, we propose a discriminative learning method for speaker-independent speech separation using deep embedding features. Firstly, a DC network is trained to extract deep embedding features, which contain each source's information and have an advantage in discriminating each target speakers. Then these features are used as the input for uPIT to directly separate the different sources. Finally, uPIT and DC are jointly trained, which directly optimizes the actual separation objectives. Moreover, in order to maximize the distance of each permutation, the discriminative learning is applied to fine tuning the whole model. Our experiments are conducted on WSJ0-2mix dataset. Experimental results show that the proposed models achieve better performances than DC and uPIT for speaker-independent speech separation.
Flavored Tacotron: Conditional Learning for Prosodic-linguistic Features
Apr 08, 2021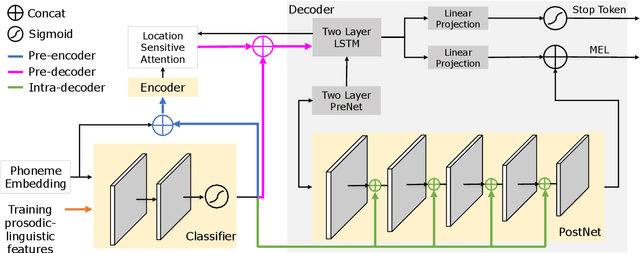
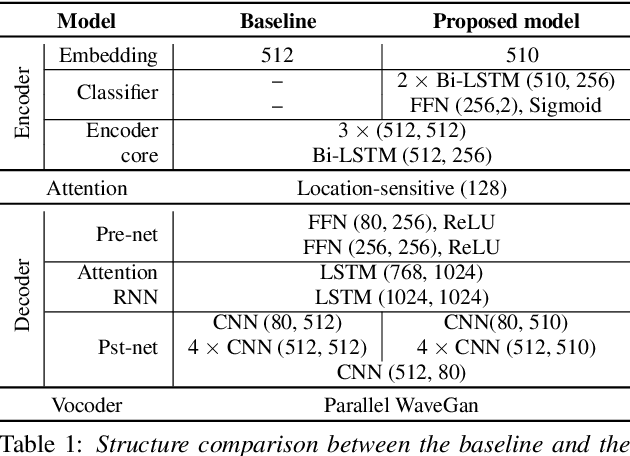
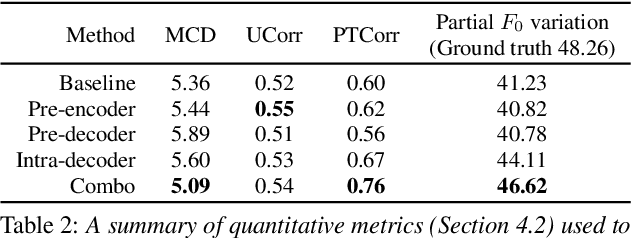
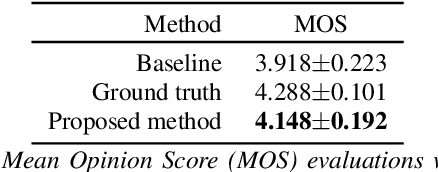
Neural sequence-to-sequence text-to-speech synthesis (TTS), such as Tacotron-2, transforms text into high-quality speech. However, generating speech with natural prosody still remains a challenge. Yasuda et. al. show that unlike natural speech, Tacotron-2's encoder doesn't fully represent prosodic features (e.g. syllable stress in English) from characters, and result in flat fundamental frequency variations. In this work, we propose a novel carefully designed strategy for conditioning Tacotron-2 on two fundamental prosodic features in English -- stress syllable and pitch accent, that help achieve more natural prosody. To this end, we use of a classifier to learn these features in an end-to-end fashion, and apply feature conditioning at three parts of Tacotron-2's Text-To-Mel Spectrogram: pre-encoder, post-encoder, and intra-decoder. Further, we show that jointly conditioned features at pre-encoder and intra-decoder stages result in prosodically natural synthesized speech (vs. Tacotron-2), and allows the model to produce speech with more accurate pitch accent and stress patterns. Quantitative evaluations show that our formulation achieves higher fundamental frequency contour correlation, and lower Mel Cepstral Distortion measure between synthesized and natural speech. And subjective evaluation shows that the proposed method's Mean Opinion Score of 4.14 fairs higher than baseline Tacotron-2, 3.91, when compared against natural speech (LJSpeech corpus), 4.28.
Calibrated Learning to Defer with One-vs-All Classifiers
Feb 08, 2022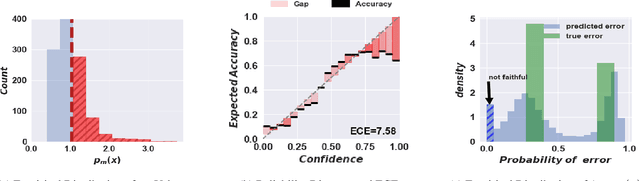
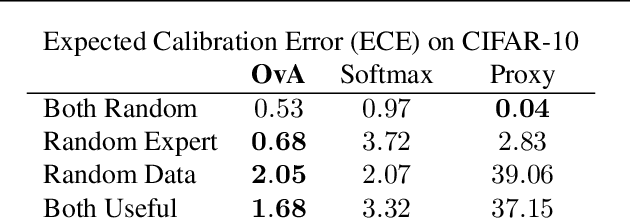
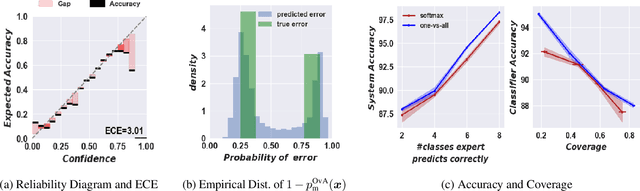

The learning to defer (L2D) framework has the potential to make AI systems safer. For a given input, the system can defer the decision to a human if the human is more likely than the model to take the correct action. We study the calibration of L2D systems, investigating if the probabilities they output are sound. We find that Mozannar & Sontag's (2020) multiclass framework is not calibrated with respect to expert correctness. Moreover, it is not even guaranteed to produce valid probabilities due to its parameterization being degenerate for this purpose. We propose an L2D system based on one-vs-all classifiers that is able to produce calibrated probabilities of expert correctness. Furthermore, our loss function is also a consistent surrogate for multiclass L2D, like Mozannar & Sontag's (2020). Our experiments verify that not only is our system calibrated, but this benefit comes at no cost to accuracy. Our model's accuracy is always comparable (and often superior) to Mozannar & Sontag's (2020) model's in tasks ranging from hate speech detection to galaxy classification to diagnosis of skin lesions.