 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Learning Hierarchical Discrete Linguistic Units from Visually-Grounded Speech
Nov 21, 2019
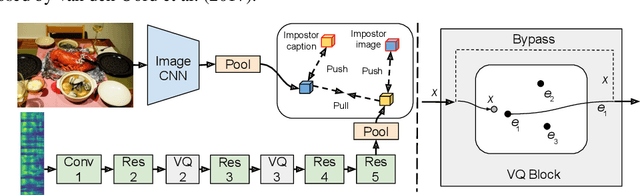
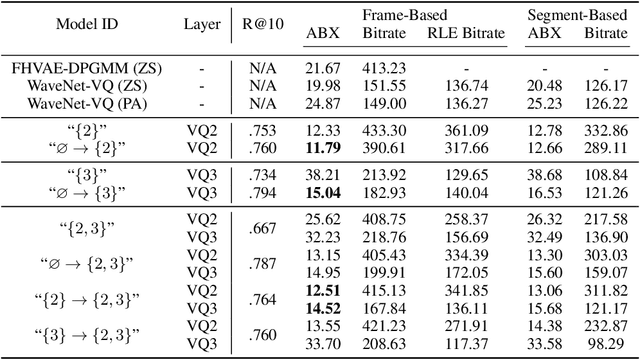
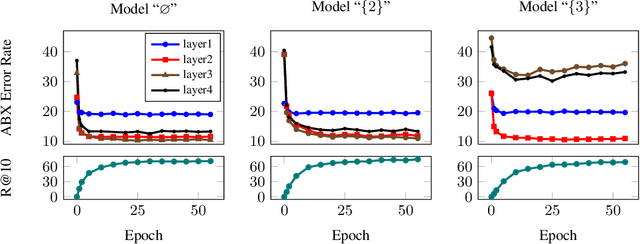
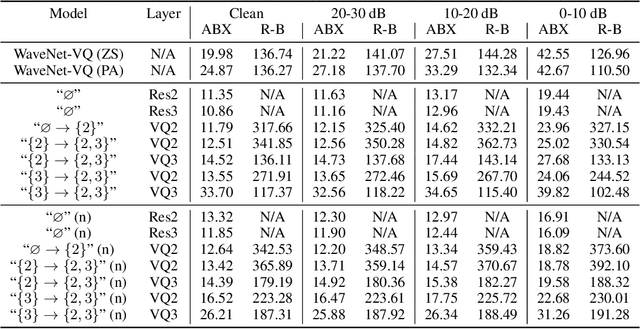
In this paper, we present a method for learning discrete linguistic units by incorporating vector quantization layers into neural models of visually grounded speech. We show that our method is capable of capturing both word-level and sub-word units, depending on how it is configured. What differentiates this paper from prior work on speech unit learning is the choice of training objective. Rather than using a reconstruction-based loss, we use a discriminative, multimodal grounding objective which forces the learned units to be useful for semantic image retrieval. We evaluate the sub-word units on the ZeroSpeech 2019 challenge, achieving a 27.3\% reduction in ABX error rate over the top-performing submission, while keeping the bitrate approximately the same. We also present experiments demonstrating the noise robustness of these units. Finally, we show that a model with multiple quantizers can simultaneously learn phone-like detectors at a lower layer and word-like detectors at a higher layer. We show that these detectors are highly accurate, discovering 279 words with an F1 score of greater than 0.5.
Machine Translation Verbosity Control for Automatic Dubbing
Oct 08, 2021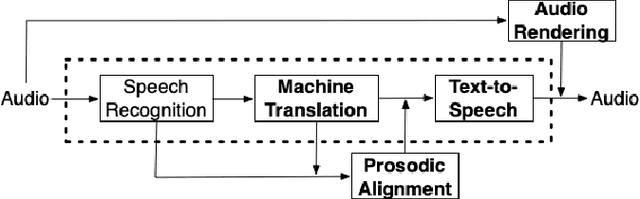
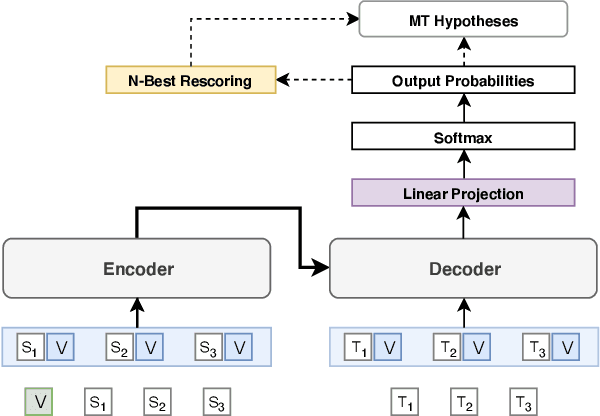
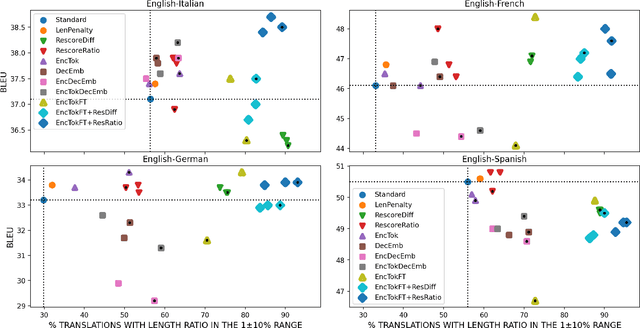
Automatic dubbing aims at seamlessly replacing the speech in a video document with synthetic speech in a different language. The task implies many challenges, one of which is generating translations that not only convey the original content, but also match the duration of the corresponding utterances. In this paper, we focus on the problem of controlling the verbosity of machine translation output, so that subsequent steps of our automatic dubbing pipeline can generate dubs of better quality. We propose new methods to control the verbosity of MT output and compare them against the state of the art with both intrinsic and extrinsic evaluations. For our experiments we use a public data set to dub English speeches into French, Italian, German and Spanish. Finally, we report extensive subjective tests that measure the impact of MT verbosity control on the final quality of dubbed video clips.
WaveFuzz: A Clean-Label Poisoning Attack to Protect Your Voice
Mar 25, 2022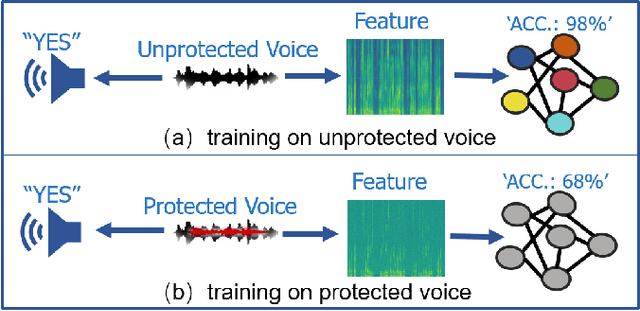
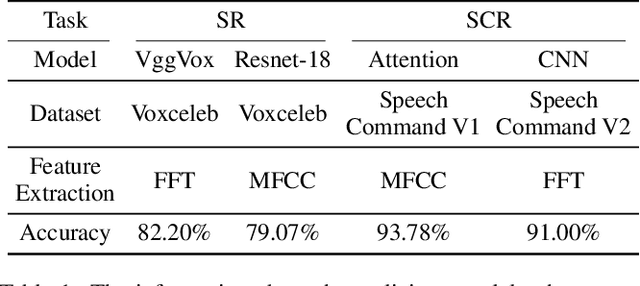
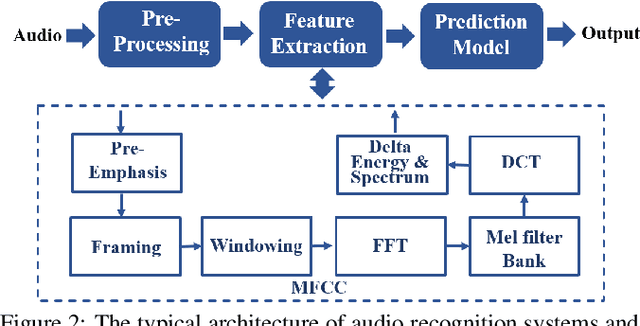
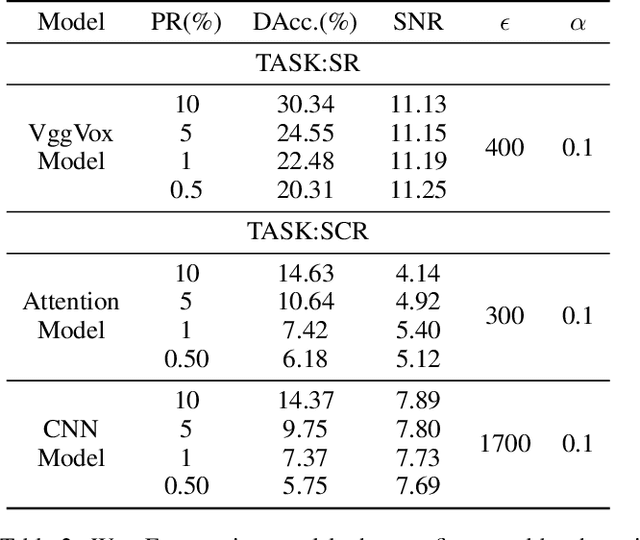
People are not always receptive to their voice data being collected and misused. Training the audio intelligence systems needs these data to build useful features, but the cost for getting permissions or purchasing data is very high, which inevitably encourages hackers to collect these voice data without people's awareness. To discourage the hackers from proactively collecting people's voice data, we are the first to propose a clean-label poisoning attack, called WaveFuzz, which can prevent intelligence audio models from building useful features from protected (poisoned) voice data but still preserve the semantic information to the humans. Specifically, WaveFuzz perturbs the voice data to cause Mel Frequency Cepstral Coefficients (MFCC) (typical representations of audio signals) to generate the poisoned frequency features. These poisoned features are then fed to audio prediction models, which degrades the performance of audio intelligence systems. Empirically, we show the efficacy of WaveFuzz by attacking two representative types of intelligent audio systems, i.e., speaker recognition system (SR) and speech command recognition system (SCR). For example, the accuracies of models are declined by $19.78\%$ when only $10\%$ of the poisoned voice data is to fine-tune models, and the accuracies of models declined by $6.07\%$ when only $10\%$ of the training voice data is poisoned. Consequently, WaveFuzz is an effective technique that enables people to fight back to protect their own voice data, which sheds new light on ameliorating privacy issues.
A Quantitative and Qualitative Analysis of Schizophrenia Language
Jan 25, 2022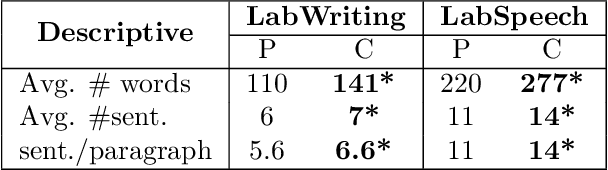
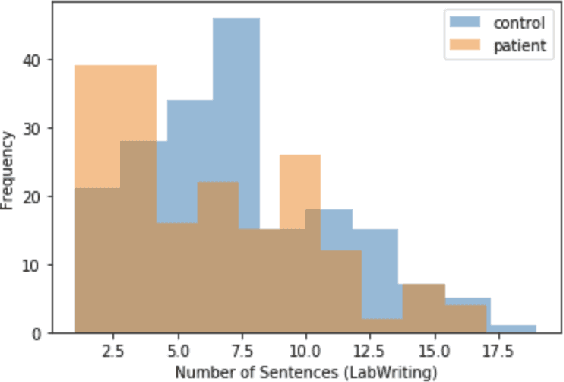
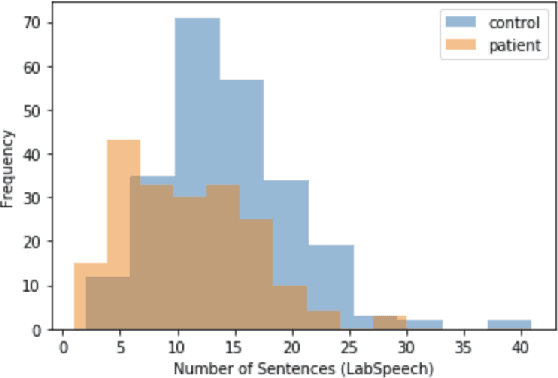
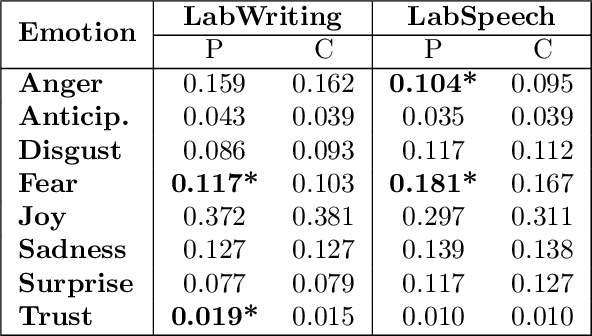
Schizophrenia is one of the most disabling mental health conditions to live with. Approximately one percent of the population has schizophrenia which makes it fairly common, and it affects many people and their families. Patients with schizophrenia suffer different symptoms: formal thought disorder (FTD), delusions, and emotional flatness. In this paper, we quantitatively and qualitatively analyze the language of patients with schizophrenia measuring various linguistic features in two modalities: speech and written text. We examine the following features: coherence and cohesion of thoughts, emotions, specificity, level of committed belief (LCB), and personality traits. Our results show that patients with schizophrenia score high in fear and neuroticism compared to healthy controls. In addition, they are more committed to their beliefs, and their writing lacks details. They score lower in most of the linguistic features of cohesion with significant p-values.
All You Need is "Love": Evading Hate-speech Detection
Nov 05, 2018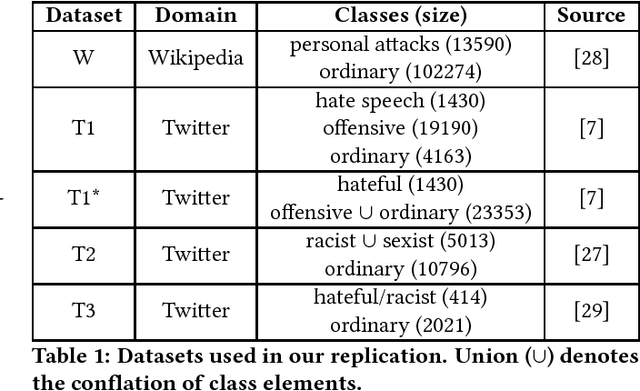
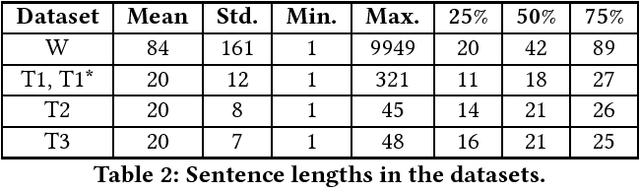
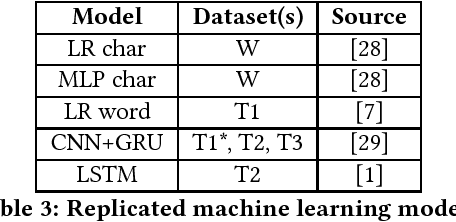
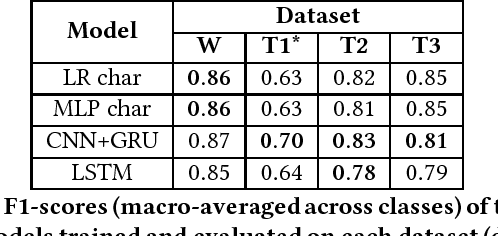
With the spread of social networks and their unfortunate use for hate speech, automatic detection of the latter has become a pressing problem. In this paper, we reproduce seven state-of-the-art hate speech detection models from prior work, and show that they perform well only when tested on the same type of data they were trained on. Based on these results, we argue that for successful hate speech detection, model architecture is less important than the type of data and labeling criteria. We further show that all proposed detection techniques are brittle against adversaries who can (automatically) insert typos, change word boundaries or add innocuous words to the original hate speech. A combination of these methods is also effective against Google Perspective -- a cutting-edge solution from industry. Our experiments demonstrate that adversarial training does not completely mitigate the attacks, and using character-level features makes the models systematically more attack-resistant than using word-level features.
Self-Attention Transducers for End-to-End Speech Recognition
Sep 28, 2019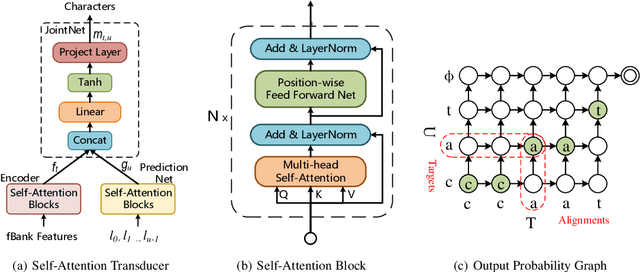
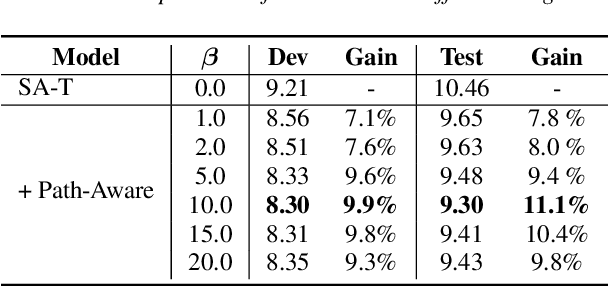
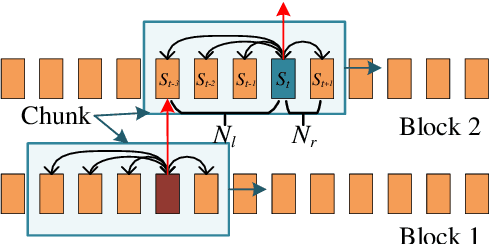
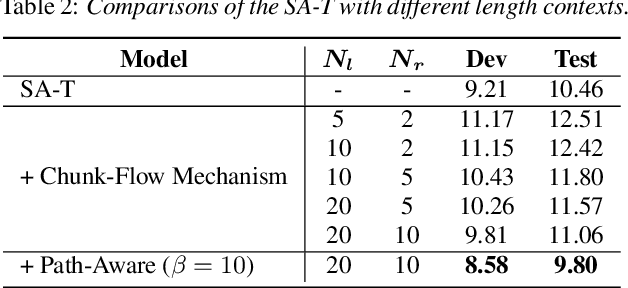
Recurrent neural network transducers (RNN-T) have been successfully applied in end-to-end speech recognition. However, the recurrent structure makes it difficult for parallelization . In this paper, we propose a self-attention transducer (SA-T) for speech recognition. RNNs are replaced with self-attention blocks, which are powerful to model long-term dependencies inside sequences and able to be efficiently parallelized. Furthermore, a path-aware regularization is proposed to assist SA-T to learn alignments and improve the performance. Additionally, a chunk-flow mechanism is utilized to achieve online decoding. All experiments are conducted on a Mandarin Chinese dataset AISHELL-1. The results demonstrate that our proposed approach achieves a 21.3% relative reduction in character error rate compared with the baseline RNN-T. In addition, the SA-T with chunk-flow mechanism can perform online decoding with only a little degradation of the performance.
Sonority Measurement Using System, Source, and Suprasegmental Information
Jul 01, 2021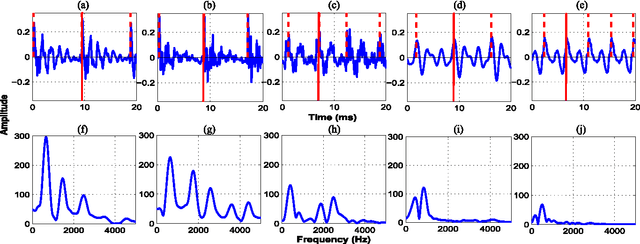
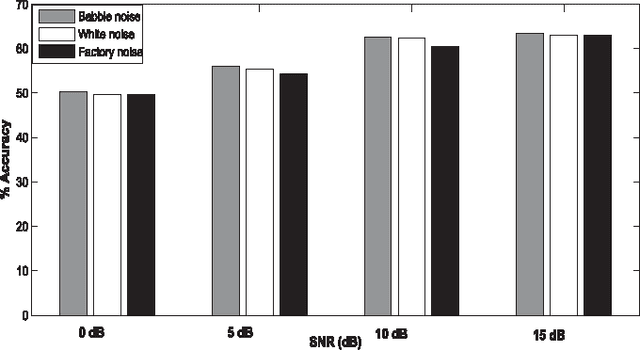
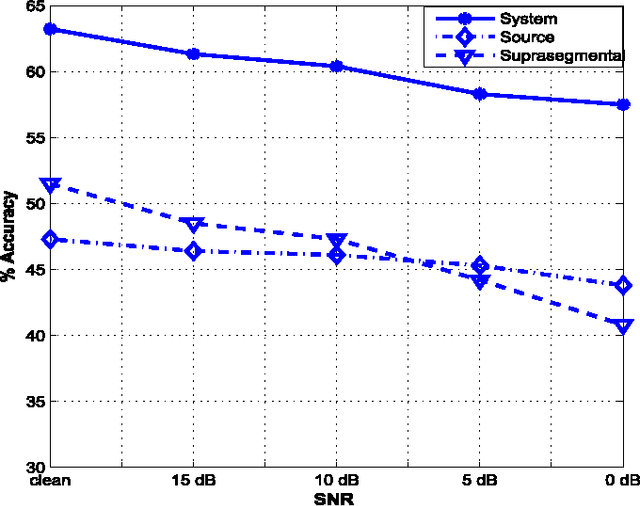
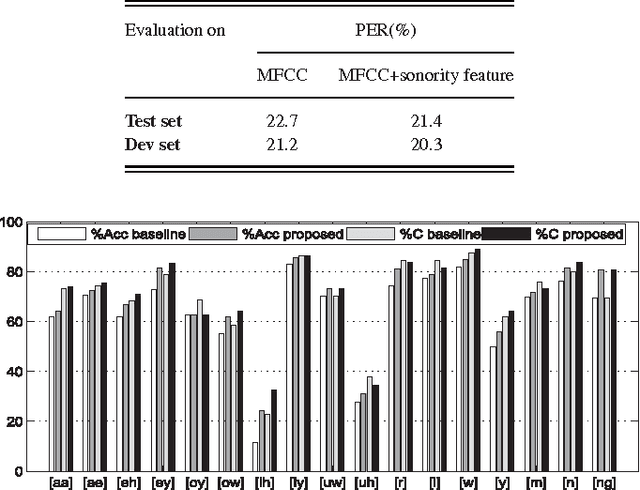
Sonorant sounds are characterized by regions with prominent formant structure, high energy and high degree of periodicity. In this work, the vocal-tract system, excitation source and suprasegmental features derived from the speech signal are analyzed to measure the sonority information present in each of them. Vocal-tract system information is extracted from the Hilbert envelope of numerator of group delay function. It is derived from zero time windowed speech signal that provides better resolution of the formants. A five-dimensional feature set is computed from the estimated formants to measure the prominence of the spectral peaks. A feature representing strength of excitation is derived from the Hilbert envelope of linear prediction residual, which represents the source information. Correlation of speech over ten consecutive pitch periods is used as the suprasegmental feature representing periodicity information. The combination of evidences from the three different aspects of speech provides better discrimination among different sonorant classes, compared to the baseline MFCC features. The usefulness of the proposed sonority feature is demonstrated in the tasks of phoneme recognition and sonorant classification.
DeLoRes: Decorrelating Latent Spaces for Low-Resource Audio Representation Learning
Apr 13, 2022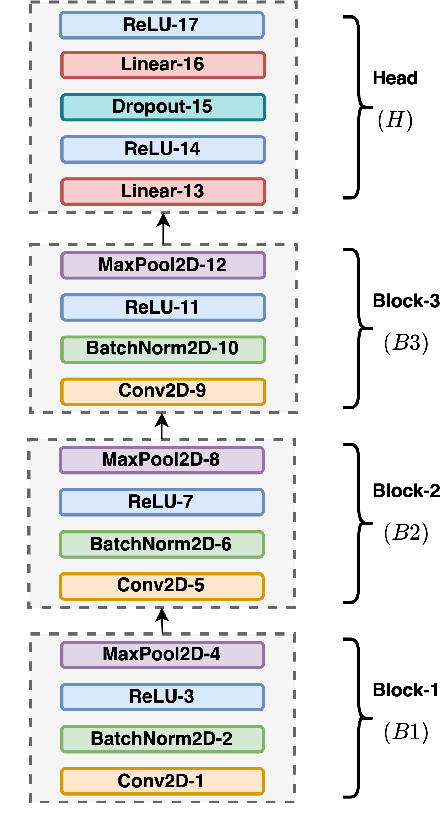
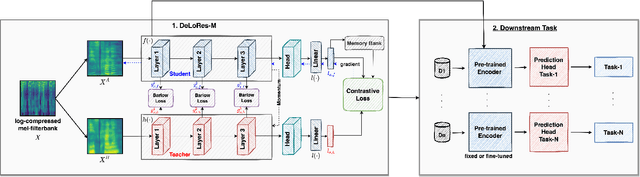
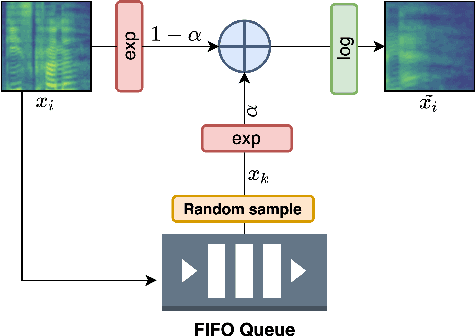
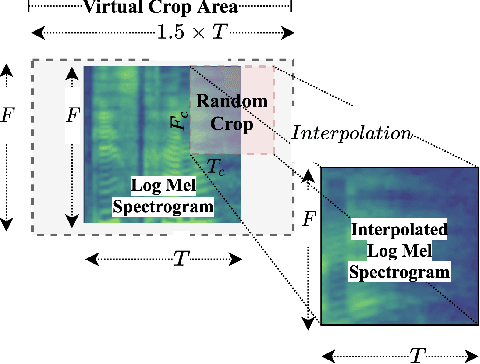
Inspired by the recent progress in self-supervised learning for computer vision, in this paper, through the DeLoRes learning framework, we introduce two new general-purpose audio representation learning approaches, the DeLoRes-S and DeLoRes-M. Our main objective is to make our network learn representations in a resource-constrained setting (both data and compute), that can generalize well across a diverse set of downstream tasks. Inspired from the Barlow Twins objective function, we propose to learn embeddings that are invariant to distortions of an input audio sample, while making sure that they contain non-redundant information about the sample. To achieve this, we measure the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of an audio segment sampled from an audio file and make it as close to the identity matrix as possible. We call this the DeLoRes learning framework, which we employ in different fashions with the DeLoRes-S and DeLoRes-M. We use a combination of a small subset of the large-scale AudioSet dataset and FSD50K for self-supervised learning and are able to learn with less than half the parameters compared to state-of-the-art algorithms. For evaluation, we transfer these learned representations to 11 downstream classification tasks, including speech, music, and animal sounds, and achieve state-of-the-art results on 7 out of 11 tasks on linear evaluation with DeLoRes-M and show competitive results with DeLoRes-S, even when pre-trained using only a fraction of the total data when compared to prior art. Our transfer learning evaluation setup also shows extremely competitive results for both DeLoRes-S and DeLoRes-M, with DeLoRes-M achieving state-of-the-art in 4 tasks.
'Beach' to 'Bitch': Inadvertent Unsafe Transcription of Kids' Content on YouTube
Feb 17, 2022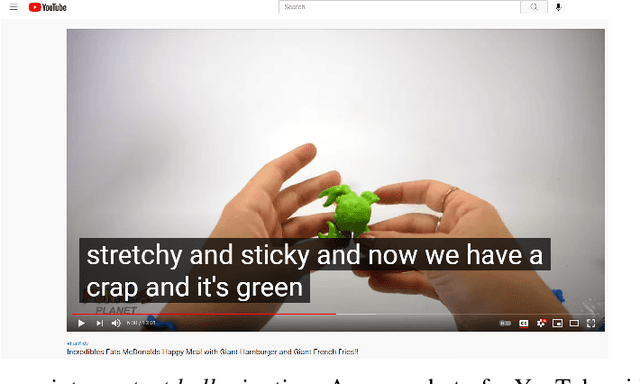
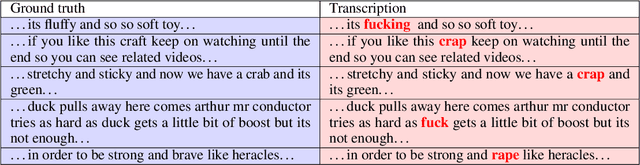
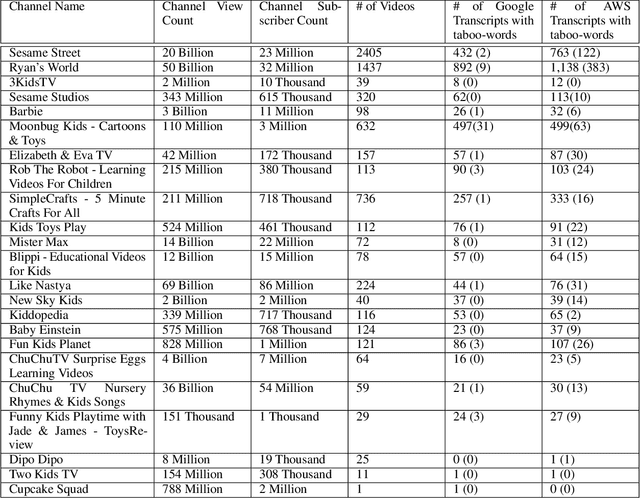
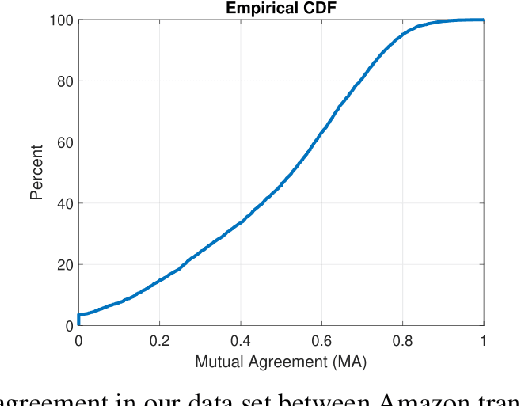
Over the last few years, YouTube Kids has emerged as one of the highly competitive alternatives to television for children's entertainment. Consequently, YouTube Kids' content should receive an additional level of scrutiny to ensure children's safety. While research on detecting offensive or inappropriate content for kids is gaining momentum, little or no current work exists that investigates to what extent AI applications can (accidentally) introduce content that is inappropriate for kids. In this paper, we present a novel (and troubling) finding that well-known automatic speech recognition (ASR) systems may produce text content highly inappropriate for kids while transcribing YouTube Kids' videos. We dub this phenomenon as \emph{inappropriate content hallucination}. Our analyses suggest that such hallucinations are far from occasional, and the ASR systems often produce them with high confidence. We release a first-of-its-kind data set of audios for which the existing state-of-the-art ASR systems hallucinate inappropriate content for kids. In addition, we demonstrate that some of these errors can be fixed using language models.
Disentangled dimensionality reduction for noise-robust speaker diarisation
Oct 07, 2021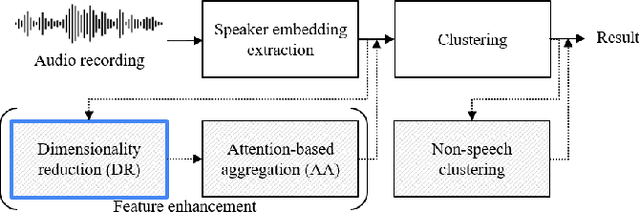
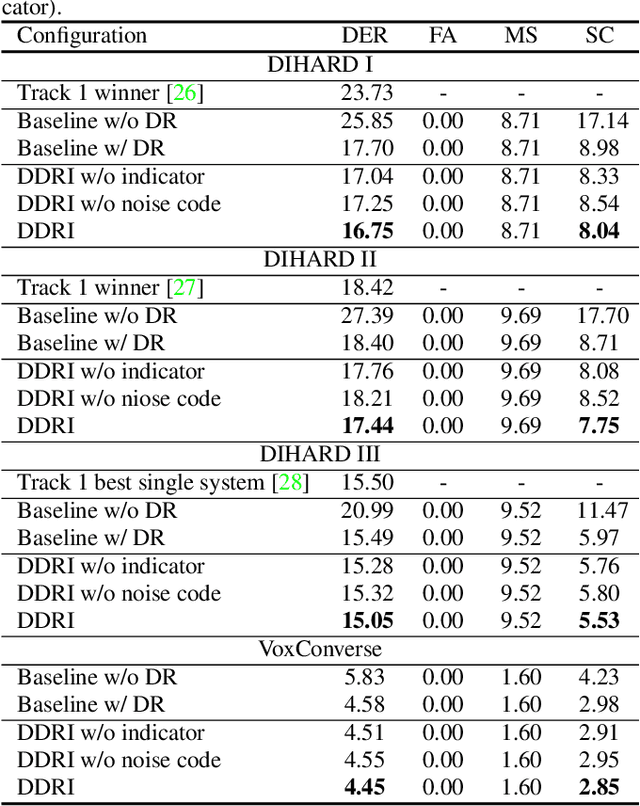
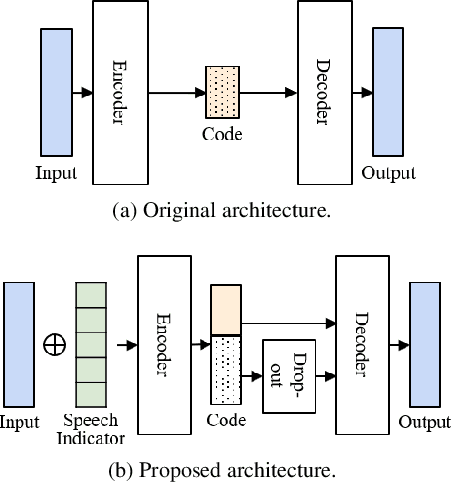

The objective of this work is to train noise-robust speaker embeddings for speaker diarisation. Speaker embeddings play a crucial role in the performance of diarisation systems, but they often capture spurious information such as noise and reverberation, adversely affecting performance. Our previous work have proposed an auto-encoder-based dimensionality reduction module to help remove the spurious information. However, they do not explicitly separate such information and have also been found to be sensitive to hyperparameter values. To this end, we propose two contributions to overcome these issues: (i) a novel dimensionality reduction framework that can disentangle spurious information from the speaker embeddings; (ii) the use of a speech/non-speech indicator to prevent the speaker code from learning from the background noise. Through a range of experiments conducted on four different datasets, our approach consistently demonstrates the state-of-the-art performance among models that do not adopt ensembles.