 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unsupervised acoustic unit discovery for speech synthesis using discrete latent-variable neural networks
Apr 16, 2019
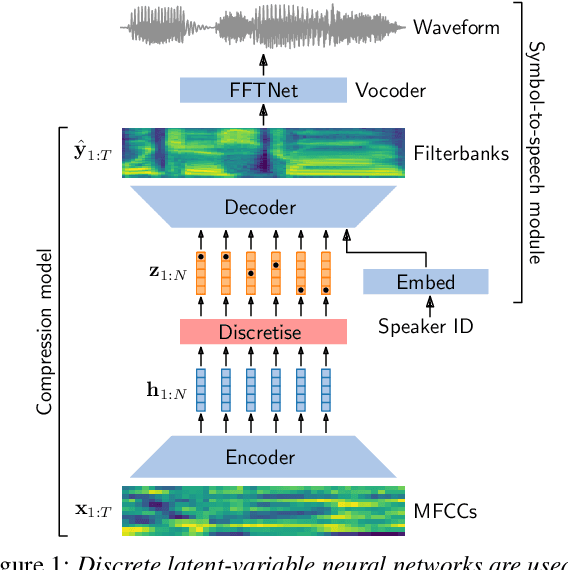
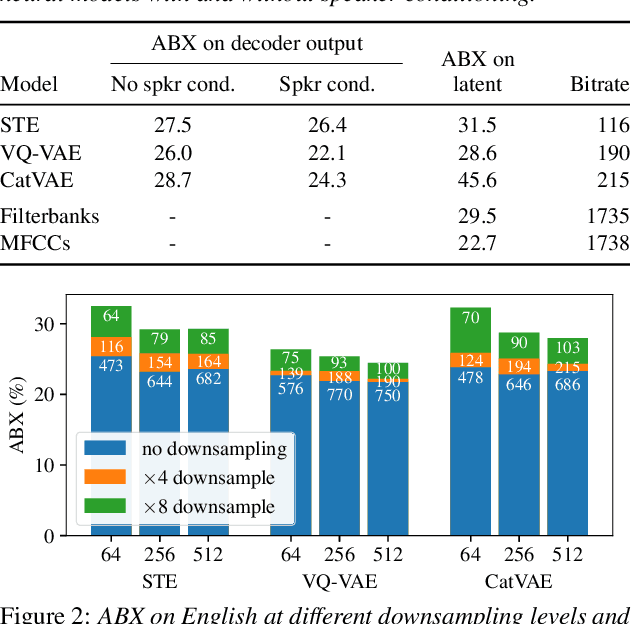
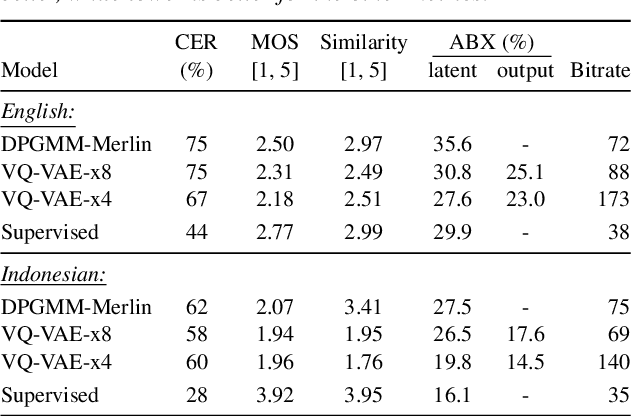
For our submission to the ZeroSpeech 2019 challenge, we apply discrete latent-variable neural networks to unlabelled speech and use the discovered units for speech synthesis. Unsupervised discrete subword modelling could be useful for studies of phonetic category learning in infants or in low-resource speech technology requiring symbolic input. We use an autoencoder (AE) architecture with intermediate discretisation. We decouple acoustic unit discovery from speaker modelling by conditioning the AE's decoder on the training speaker identity. At test time, unit discovery is performed on speech from an unseen speaker, followed by unit decoding conditioned on a known target speaker to obtain reconstructed filterbanks. This output is fed to a neural vocoder to synthesise speech in the target speaker's voice. For discretisation, categorical variational autoencoders (CatVAEs), vector-quantised VAEs (VQ-VAEs) and straight-through estimation are compared at different compression levels on two languages. Our final model uses convolutional encoding, VQ-VAE discretisation, deconvolutional decoding and an FFTNet vocoder. We show that decoupled speaker conditioning intrinsically improves discrete acoustic representations, yielding competitive synthesis quality compared to the challenge baseline.
The NTNU System at the Interspeech 2020 Non-Native Children's Speech ASR Challenge
May 18, 2020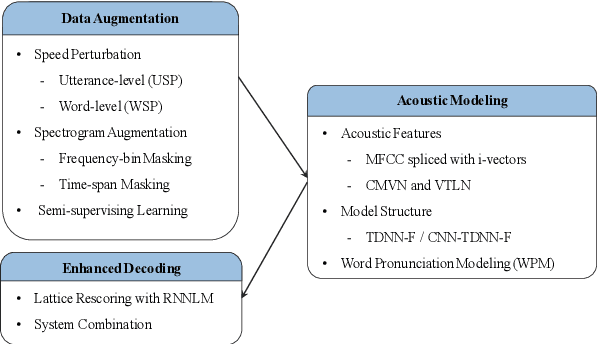
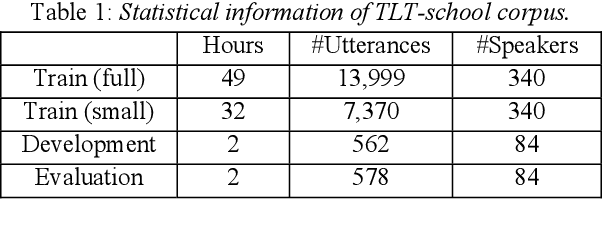
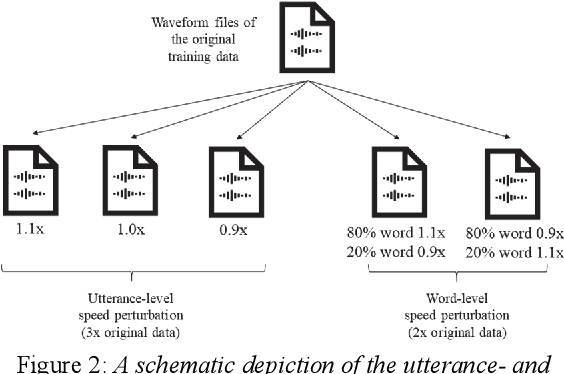
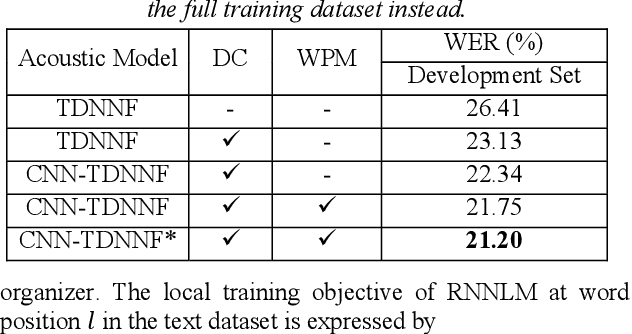
This paper describes the NTNU ASR system participating in the Interspeech 2020 Non-Native Children's Speech ASR Challenge supported by the SIG-CHILD group of ISCA. This ASR shared task is made much more challenging due to the coexisting diversity of non-native and children speaking characteristics. In the setting of closed-track evaluation, all participants were restricted to develop their systems merely based on the speech and text corpora provided by the organizer. To work around this under-resourced issue, we built our ASR system on top of CNN-TDNNF-based acoustic models, meanwhile harnessing the synergistic power of various data augmentation strategies, including both utterance- and word-level speed perturbation and spectrogram augmentation, alongside a simple yet effective data-cleansing approach. All variants of our ASR system employed an RNN-based language model to rescore the first-pass recognition hypotheses, which was trained solely on the text dataset released by the organizer. Our system with the best configuration came out in second place, resulting in a word error rate (WER) of 17.59 %, while those of the top-performing, second runner-up and official baseline systems are 15.67%, 18.71%, 35.09%, respectively.
A Fast Network Exploration Strategy to Profile Low Energy Consumption for Keyword Spotting
Feb 04, 2022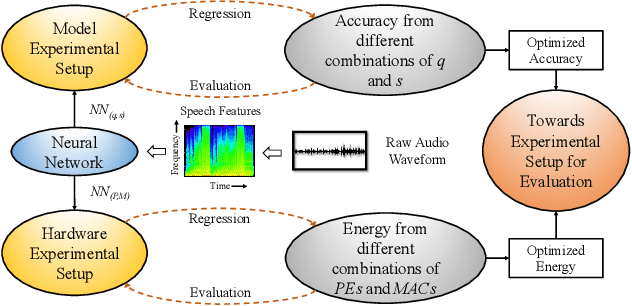
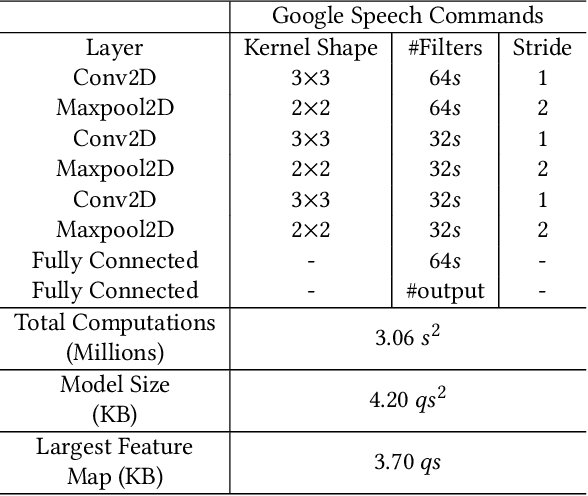
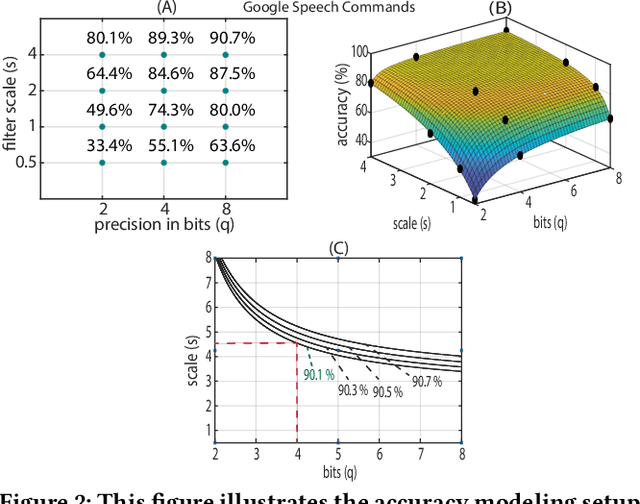
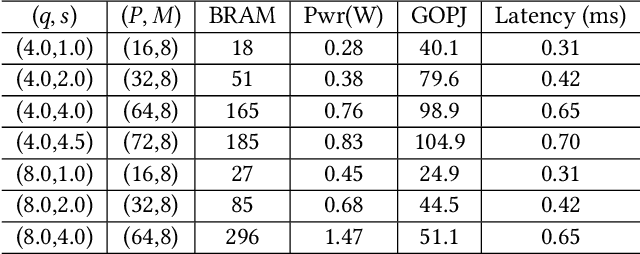
Keyword Spotting nowadays is an integral part of speech-oriented user interaction targeted for smart devices. To this extent, neural networks are extensively used for their flexibility and high accuracy. However, coming up with a suitable configuration for both accuracy requirements and hardware deployment is a challenge. We propose a regression-based network exploration technique that considers the scaling of the network filters ($s$) and quantization ($q$) of the network layers, leading to a friendly and energy-efficient configuration for FPGA hardware implementation. We experiment with different combinations of $\mathcal{NN}\scriptstyle\langle q,\,s\rangle \displaystyle$ on the FPGA to profile the energy consumption of the deployed network so that the user can choose the most energy-efficient network configuration promptly. Our accelerator design is deployed on the Xilinx AC 701 platform and has at least 2.1$\times$ and 4$\times$ improvements on energy and energy efficiency results, respectively, compared to recent hardware implementations for keyword spotting.
A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
Aug 23, 2020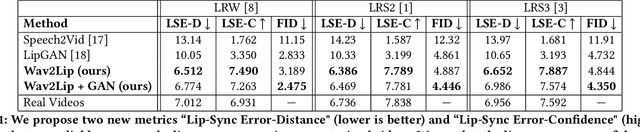
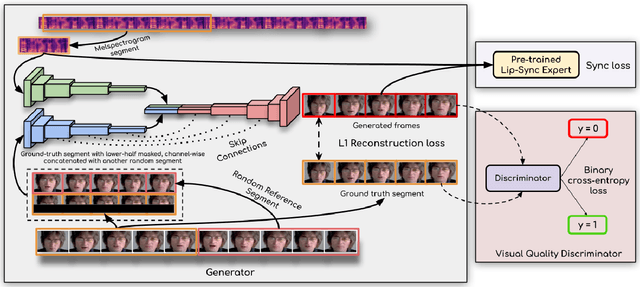
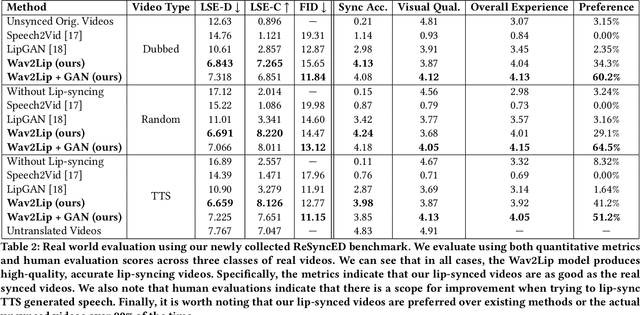
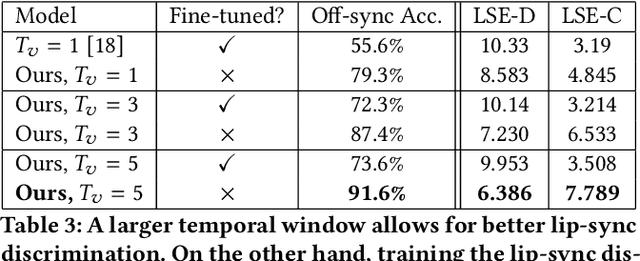
In this work, we investigate the problem of lip-syncing a talking face video of an arbitrary identity to match a target speech segment. Current works excel at producing accurate lip movements on a static image or videos of specific people seen during the training phase. However, they fail to accurately morph the lip movements of arbitrary identities in dynamic, unconstrained talking face videos, resulting in significant parts of the video being out-of-sync with the new audio. We identify key reasons pertaining to this and hence resolve them by learning from a powerful lip-sync discriminator. Next, we propose new, rigorous evaluation benchmarks and metrics to accurately measure lip synchronization in unconstrained videos. Extensive quantitative evaluations on our challenging benchmarks show that the lip-sync accuracy of the videos generated by our Wav2Lip model is almost as good as real synced videos. We provide a demo video clearly showing the substantial impact of our Wav2Lip model and evaluation benchmarks on our website: \url{cvit.iiit.ac.in/research/projects/cvit-projects/a-lip-sync-expert-is-all-you-need-for-speech-to-lip-generation-in-the-wild}. The code and models are released at this GitHub repository: \url{github.com/Rudrabha/Wav2Lip}. You can also try out the interactive demo at this link: \url{bhaasha.iiit.ac.in/lipsync}.
Emotion Recognition in Speech using Cross-Modal Transfer in the Wild
Aug 16, 2018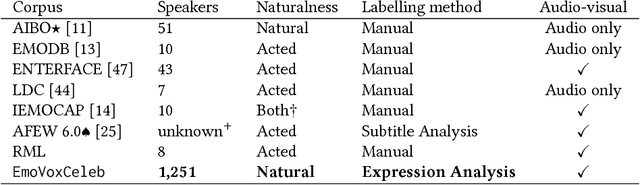



Obtaining large, human labelled speech datasets to train models for emotion recognition is a notoriously challenging task, hindered by annotation cost and label ambiguity. In this work, we consider the task of learning embeddings for speech classification without access to any form of labelled audio. We base our approach on a simple hypothesis: that the emotional content of speech correlates with the facial expression of the speaker. By exploiting this relationship, we show that annotations of expression can be transferred from the visual domain (faces) to the speech domain (voices) through cross-modal distillation. We make the following contributions: (i) we develop a strong teacher network for facial emotion recognition that achieves the state of the art on a standard benchmark; (ii) we use the teacher to train a student, tabula rasa, to learn representations (embeddings) for speech emotion recognition without access to labelled audio data; and (iii) we show that the speech emotion embedding can be used for speech emotion recognition on external benchmark datasets. Code, models and data are available.
DNN-Based Semantic Model for Rescoring N-best Speech Recognition List
Nov 02, 2020
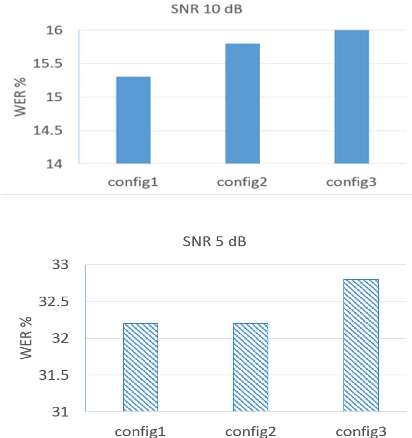
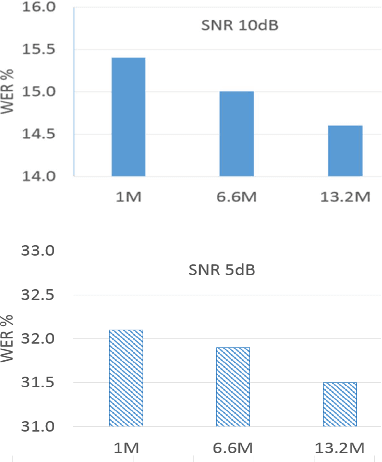
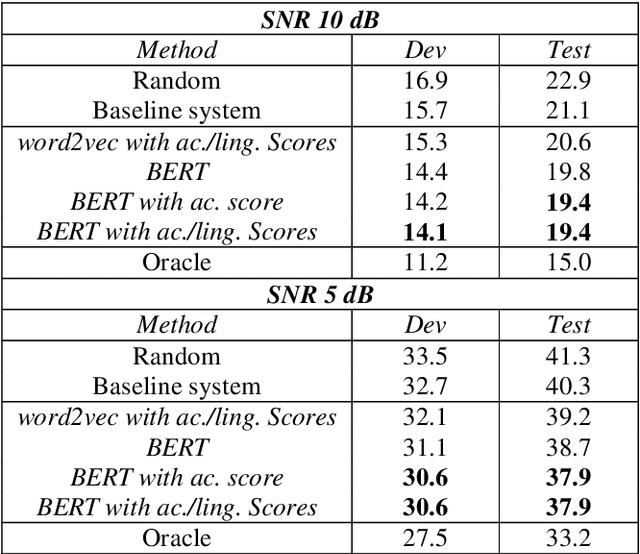
The word error rate (WER) of an automatic speech recognition (ASR) system increases when a mismatch occurs between the training and the testing conditions due to the noise, etc. In this case, the acoustic information can be less reliable. This work aims to improve ASR by modeling long-term semantic relations to compensate for distorted acoustic features. We propose to perform this through rescoring of the ASR N-best hypotheses list. To achieve this, we train a deep neural network (DNN). Our DNN rescoring model is aimed at selecting hypotheses that have better semantic consistency and therefore lower WER. We investigate two types of representations as part of input features to our DNN model: static word embeddings (from word2vec) and dynamic contextual embeddings (from BERT). Acoustic and linguistic features are also included. We perform experiments on the publicly available dataset TED-LIUM mixed with real noise. The proposed rescoring approaches give significant improvement of the WER over the ASR system without rescoring models in two noisy conditions and with n-gram and RNNLM.
Streaming End-to-End ASR based on Blockwise Non-Autoregressive Models
Jul 20, 2021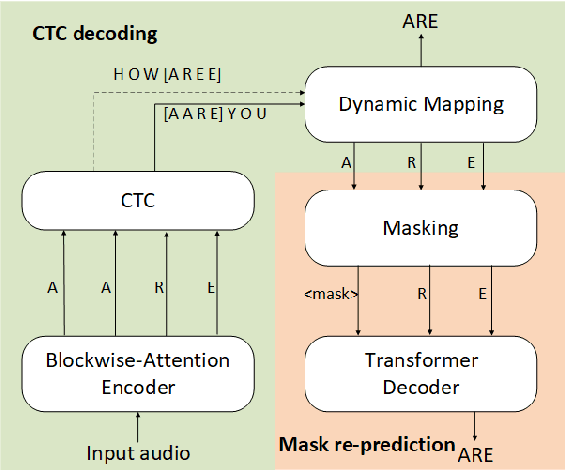
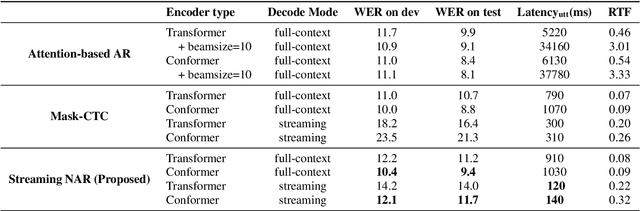
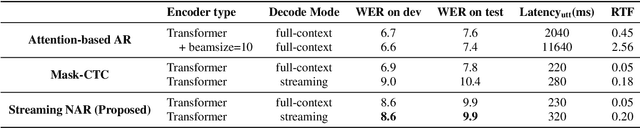
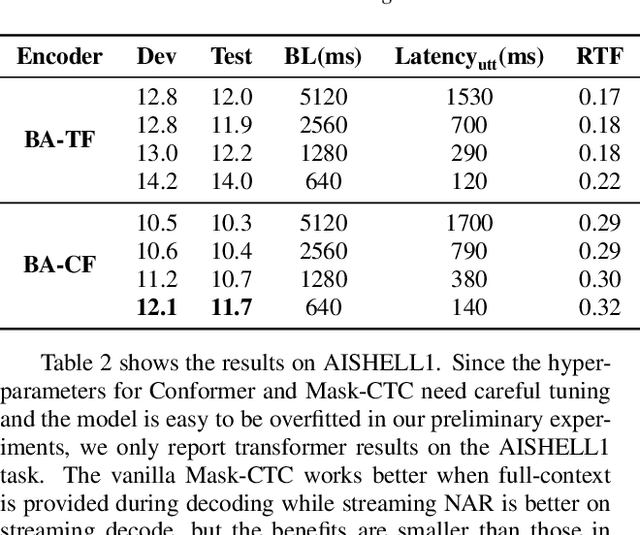
Non-autoregressive (NAR) modeling has gained more and more attention in speech processing. With recent state-of-the-art attention-based automatic speech recognition (ASR) structure, NAR can realize promising real-time factor (RTF) improvement with only small degradation of accuracy compared to the autoregressive (AR) models. However, the recognition inference needs to wait for the completion of a full speech utterance, which limits their applications on low latency scenarios. To address this issue, we propose a novel end-to-end streaming NAR speech recognition system by combining blockwise-attention and connectionist temporal classification with mask-predict (Mask-CTC) NAR. During inference, the input audio is separated into small blocks and then processed in a blockwise streaming way. To address the insertion and deletion error at the edge of the output of each block, we apply an overlapping decoding strategy with a dynamic mapping trick that can produce more coherent sentences. Experimental results show that the proposed method improves online ASR recognition in low latency conditions compared to vanilla Mask-CTC. Moreover, it can achieve a much faster inference speed compared to the AR attention-based models. All of our codes will be publicly available at https://github.com/espnet/espnet.
Bunched LPCNet : Vocoder for Low-cost Neural Text-To-Speech Systems
Aug 11, 2020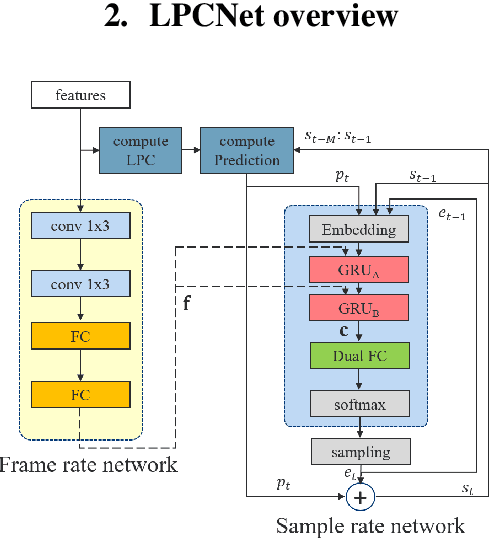
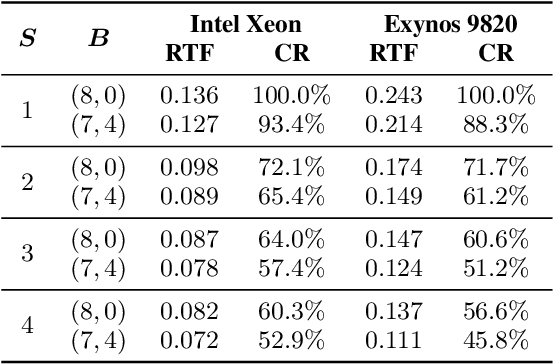
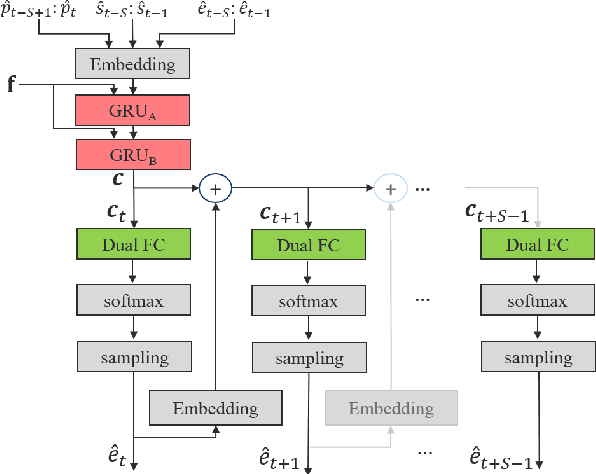
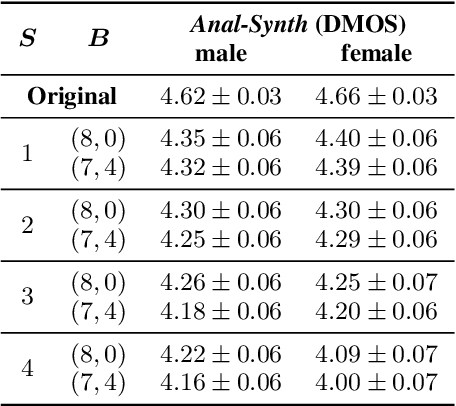
LPCNet is an efficient vocoder that combines linear prediction and deep neural network modules to keep the computational complexity low. In this work, we present two techniques to further reduce it's complexity, aiming for a low-cost LPCNet vocoder-based neural Text-to-Speech (TTS) System. These techniques are: 1) Sample-bunching, which allows LPCNet to generate more than one audio sample per inference; and 2) Bit-bunching, which reduces the computations in the final layer of LPCNet. With the proposed bunching techniques, LPCNet, in conjunction with a Deep Convolutional TTS (DCTTS) acoustic model, shows a 2.19x improvement over the baseline run-time when running on a mobile device, with a less than 0.1 decrease in TTS mean opinion score (MOS).
The Mirrornet : Learning Audio Synthesizer Controls Inspired by Sensorimotor Interaction
Oct 12, 2021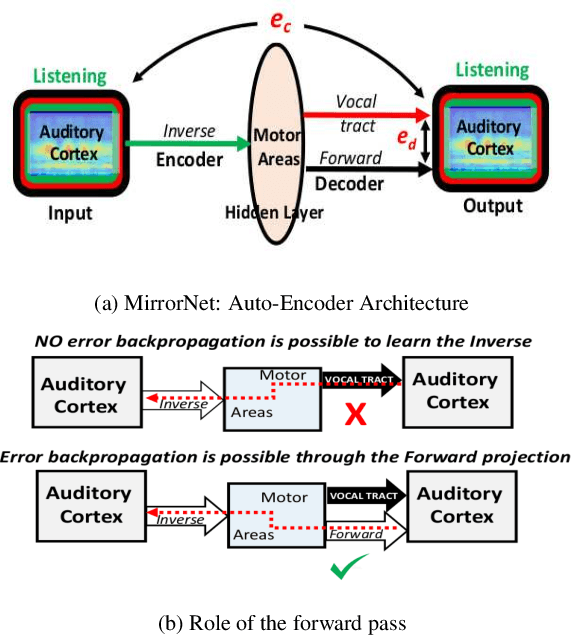
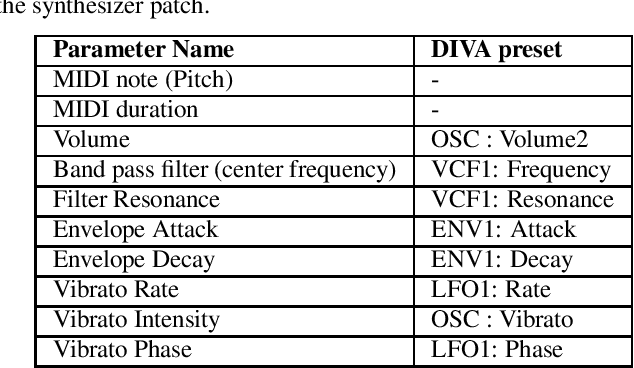
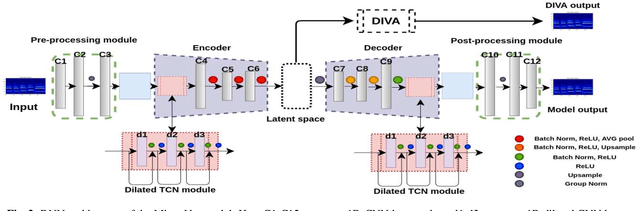
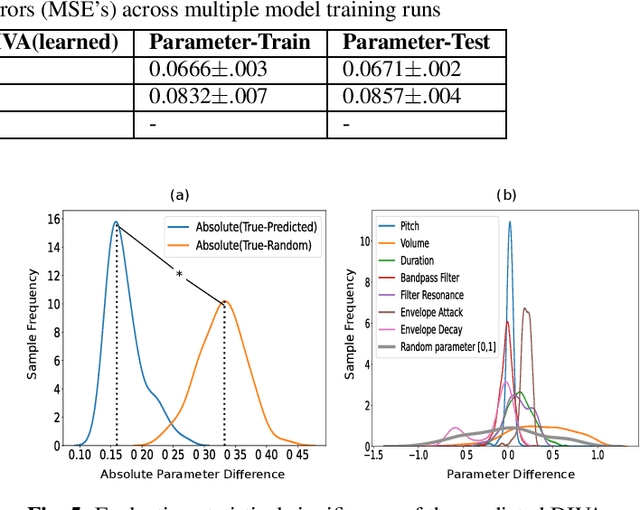
Experiments to understand the sensorimotor neural interactions in the human cortical speech system support the existence of a bidirectional flow of interactions between the auditory and motor regions. Their key function is to enable the brain to 'learn' how to control the vocal tract for speech production. This idea is the impetus for the recently proposed "MirrorNet", a constrained autoencoder architecture. In this paper, the MirrorNet is applied to learn, in an unsupervised manner, the controls of a specific audio synthesizer (DIVA) to produce melodies only from their auditory spectrograms. The results demonstrate how the MirrorNet discovers the synthesizer parameters to generate the melodies that closely resemble the original and those of unseen melodies, and even determine the best set parameters to approximate renditions of complex piano melodies generated by a different synthesizer. This generalizability of the MirrorNet illustrates its potential to discover from sensory data the controls of arbitrary motor-plants such as autonomous vehicles.
Persian Ezafe Recognition Using Transformers and Its Role in Part-Of-Speech Tagging
Oct 04, 2020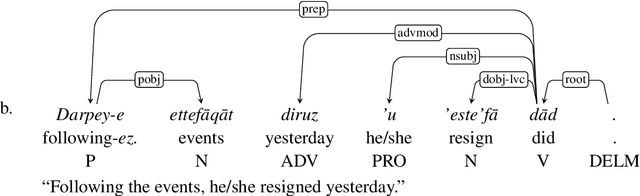
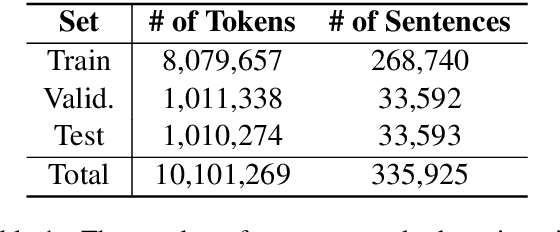
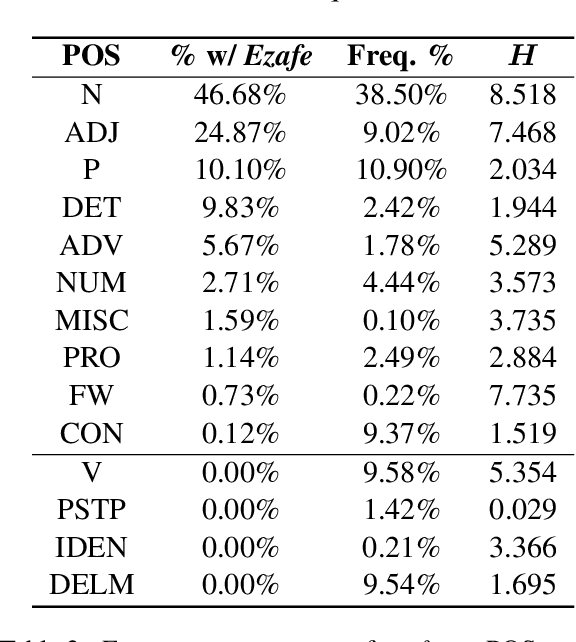
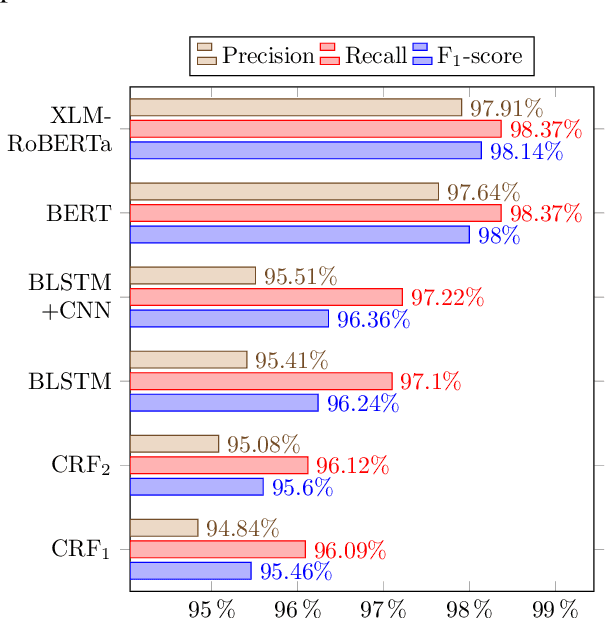
Ezafe is a grammatical particle in some Iranian languages that links two words together. Regardless of the important information it conveys, it is almost always not indicated in Persian script, resulting in mistakes in reading complex sentences and errors in natural language processing tasks. In this paper, we experiment with different machine learning methods to achieve state-of-the-art results in the task of ezafe recognition. Transformer-based methods, BERT and XLMRoBERTa, achieve the best results, the latter achieving 2.68% F1-score more than the previous state-of-the-art. We, moreover, use ezafe information to improve Persian part-of-speech tagging results and show that such information will not be useful to transformer-based methods and explain why that might be the case.