 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Machine Perceptual Quality: Evaluating the Impact of Severe Lossy Compression on Audio and Image Models
Jan 15, 2024
In the field of neural data compression, the prevailing focus has been on optimizing algorithms for either classical distortion metrics, such as PSNR or SSIM, or human perceptual quality. With increasing amounts of data consumed by machines rather than humans, a new paradigm of machine-oriented compression$\unicode{x2013}$which prioritizes the retention of features salient for machine perception over traditional human-centric criteria$\unicode{x2013}$has emerged, creating several new challenges to the development, evaluation, and deployment of systems utilizing lossy compression. In particular, it is unclear how different approaches to lossy compression will affect the performance of downstream machine perception tasks. To address this under-explored area, we evaluate various perception models$\unicode{x2013}$including image classification, image segmentation, speech recognition, and music source separation$\unicode{x2013}$under severe lossy compression. We utilize several popular codecs spanning conventional, neural, and generative compression architectures. Our results indicate three key findings: (1) using generative compression, it is feasible to leverage highly compressed data while incurring a negligible impact on machine perceptual quality; (2) machine perceptual quality correlates strongly with deep similarity metrics, indicating a crucial role of these metrics in the development of machine-oriented codecs; and (3) using lossy compressed datasets, (e.g. ImageNet) for pre-training can lead to counter-intuitive scenarios where lossy compression increases machine perceptual quality rather than degrading it. To encourage engagement on this growing area of research, our code and experiments are available at: https://github.com/danjacobellis/MPQ.
Accent-VITS:accent transfer for end-to-end TTS
Dec 29, 2023Accent transfer aims to transfer an accent from a source speaker to synthetic speech in the target speaker's voice. The main challenge is how to effectively disentangle speaker timbre and accent which are entangled in speech. This paper presents a VITS-based end-to-end accent transfer model named Accent-VITS.Based on the main structure of VITS, Accent-VITS makes substantial improvements to enable effective and stable accent transfer.We leverage a hierarchical CVAE structure to model accent pronunciation information and acoustic features, respectively, using bottleneck features and mel spectrums as constraints.Moreover, the text-to-wave mapping in VITS is decomposed into text-to-accent and accent-to-wave mappings in Accent-VITS. In this way, the disentanglement of accent and speaker timbre becomes be more stable and effective.Experiments on multi-accent and Mandarin datasets show that Accent-VITS achieves higher speaker similarity, accent similarity and speech naturalness as compared with a strong baseline.
Chain of Generation: Multi-Modal Gesture Synthesis via Cascaded Conditional Control
Dec 26, 2023This study aims to improve the generation of 3D gestures by utilizing multimodal information from human speech. Previous studies have focused on incorporating additional modalities to enhance the quality of generated gestures. However, these methods perform poorly when certain modalities are missing during inference. To address this problem, we suggest using speech-derived multimodal priors to improve gesture generation. We introduce a novel method that separates priors from speech and employs multimodal priors as constraints for generating gestures. Our approach utilizes a chain-like modeling method to generate facial blendshapes, body movements, and hand gestures sequentially. Specifically, we incorporate rhythm cues derived from facial deformation and stylization prior based on speech emotions, into the process of generating gestures. By incorporating multimodal priors, our method improves the quality of generated gestures and eliminate the need for expensive setup preparation during inference. Extensive experiments and user studies confirm that our proposed approach achieves state-of-the-art performance.
Multi-objective Non-intrusive Hearing-aid Speech Assessment Model
Nov 15, 2023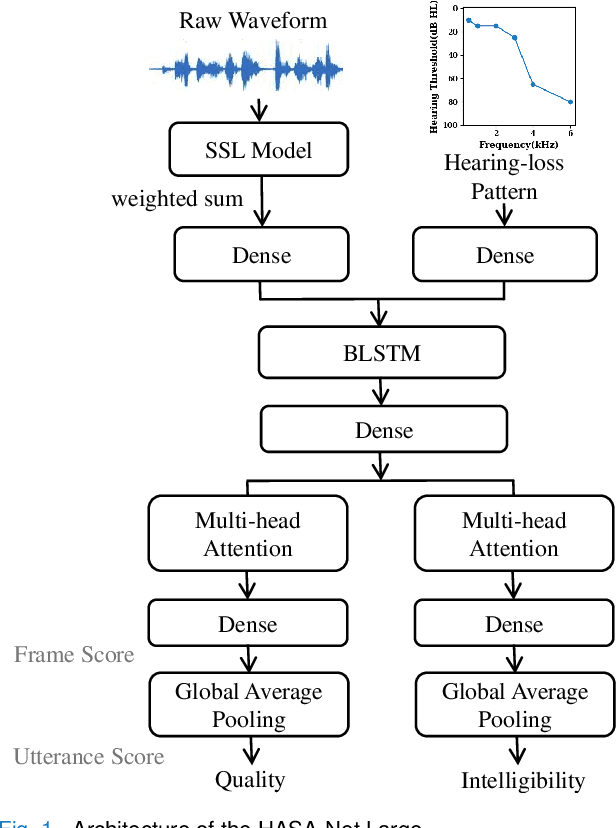
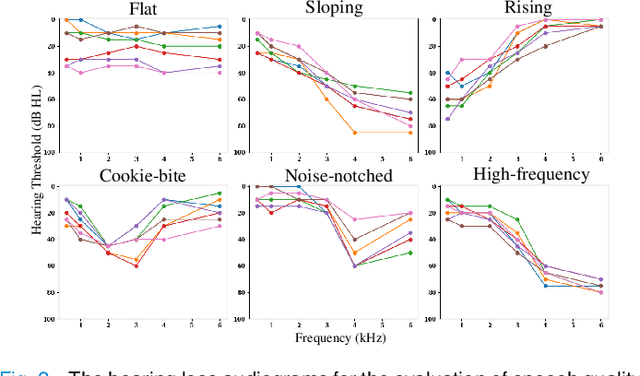
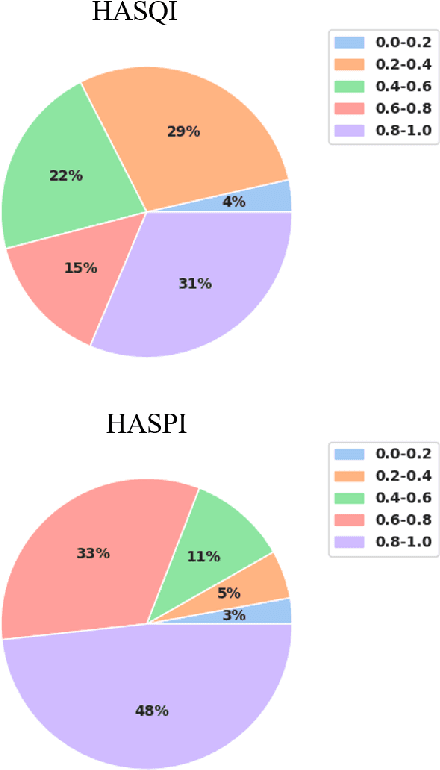
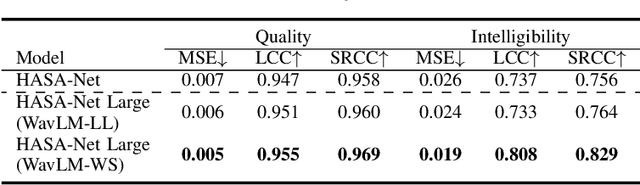
Without the need for a clean reference, non-intrusive speech assessment methods have caught great attention for objective evaluations. While deep learning models have been used to develop non-intrusive speech assessment methods with promising results, there is limited research on hearing-impaired subjects. This study proposes a multi-objective non-intrusive hearing-aid speech assessment model, called HASA-Net Large, which predicts speech quality and intelligibility scores based on input speech signals and specified hearing-loss patterns. Our experiments showed the utilization of pre-trained SSL models leads to a significant boost in speech quality and intelligibility predictions compared to using spectrograms as input. Additionally, we examined three distinct fine-tuning approaches that resulted in further performance improvements. Furthermore, we demonstrated that incorporating SSL models resulted in greater transferability to OOD dataset. Finally, this study introduces HASA-Net Large, which is a non-invasive approach for evaluating speech quality and intelligibility. HASA-Net Large utilizes raw waveforms and hearing-loss patterns to accurately predict speech quality and intelligibility levels for individuals with normal and impaired hearing and demonstrates superior prediction performance and transferability.
How does end-to-end speech recognition training impact speech enhancement artifacts?
Nov 20, 2023Jointly training a speech enhancement (SE) front-end and an automatic speech recognition (ASR) back-end has been investigated as a way to mitigate the influence of \emph{processing distortion} generated by single-channel SE on ASR. In this paper, we investigate the effect of such joint training on the signal-level characteristics of the enhanced signals from the viewpoint of the decomposed noise and artifact errors. The experimental analyses provide two novel findings: 1) ASR-level training of the SE front-end reduces the artifact errors while increasing the noise errors, and 2) simply interpolating the enhanced and observed signals, which achieves a similar effect of reducing artifacts and increasing noise, improves ASR performance without jointly modifying the SE and ASR modules, even for a strong ASR back-end using a WavLM feature extractor. Our findings provide a better understanding of the effect of joint training and a novel insight for designing an ASR agnostic SE front-end.
Synthetic Data Generation Techniques for Developing AI-based Speech Assessments for Parkinson's Disease (A Comparative Study)
Dec 04, 2023Changes in speech and language are among the first signs of Parkinson's disease (PD). Thus, clinicians have tried to identify individuals with PD from their voices for years. Doctors can leverage AI-based speech assessments to spot PD thanks to advancements in artificial intelligence (AI). Such AI systems can be developed using machine learning classifiers that have been trained using individuals' voices. Although several studies have shown reasonable results in developing such AI systems, these systems would need more data samples to achieve promising performance. This paper explores using deep learning-based data generation techniques on the accuracy of machine learning classifiers that are the core of such systems.
Sparsity-Driven EEG Channel Selection for Brain-Assisted Speech Enhancement
Nov 23, 2023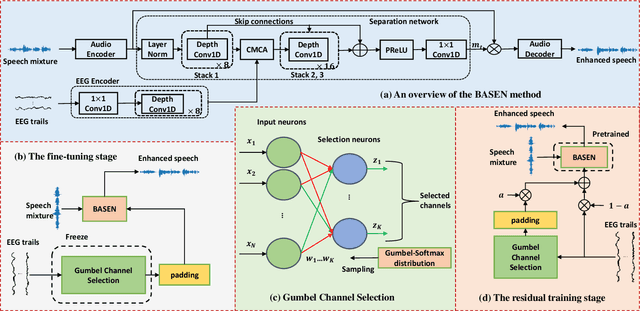
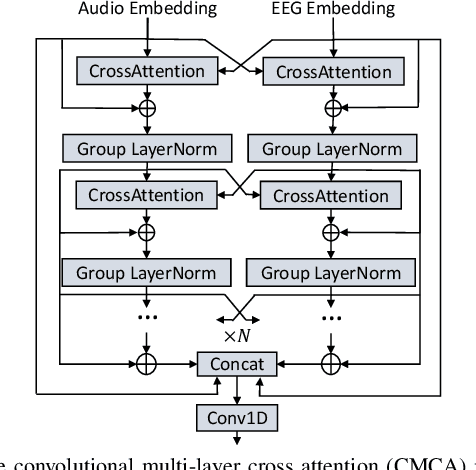
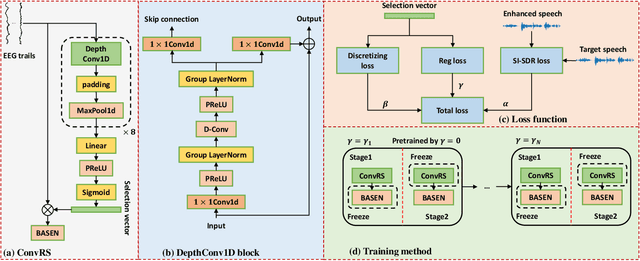
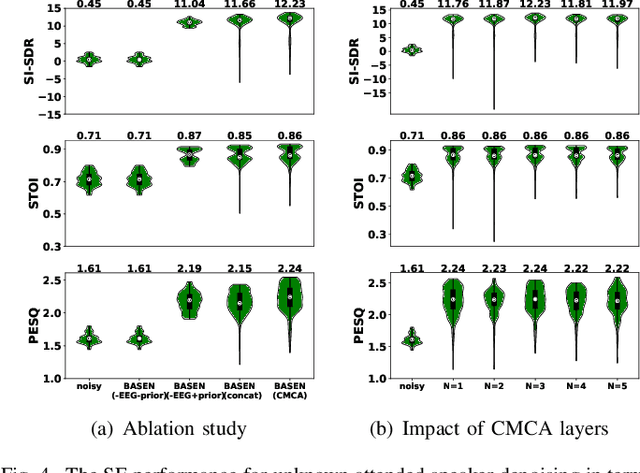
Speech enhancement is widely used as a front-end to improve the speech quality in many audio systems, while it is still hard to extract the target speech in multi-talker conditions without prior information on the speaker identity. It was shown by auditory attention decoding that the attended speaker can be revealed by the electroencephalogram (EEG) of the listener implicitly. In this work, we therefore propose a novel end-to-end brain-assisted speech enhancement network (BASEN), which incorporates the listeners' EEG signals and adopts a temporal convolutional network together with a convolutional multi-layer cross attention module to fuse EEG-audio features. Considering that an EEG cap with sparse channels exhibits multiple benefits and in practice many electrodes might contribute marginally, we further propose two channel selection methods, called residual Gumbel selection and convolutional regularization selection. They are dedicated to tackling the issues of training instability and duplicated channel selections, respectively. Experimental results on a public dataset show the superiority of the proposed baseline BASEN over existing approaches. The proposed channel selection methods can significantly reduce the amount of informative EEG channels with a negligible impact on the performance.
Singer Identity Representation Learning using Self-Supervised Techniques
Jan 10, 2024Significant strides have been made in creating voice identity representations using speech data. However, the same level of progress has not been achieved for singing voices. To bridge this gap, we suggest a framework for training singer identity encoders to extract representations suitable for various singing-related tasks, such as singing voice similarity and synthesis. We explore different self-supervised learning techniques on a large collection of isolated vocal tracks and apply data augmentations during training to ensure that the representations are invariant to pitch and content variations. We evaluate the quality of the resulting representations on singer similarity and identification tasks across multiple datasets, with a particular emphasis on out-of-domain generalization. Our proposed framework produces high-quality embeddings that outperform both speaker verification and wav2vec 2.0 pre-trained baselines on singing voice while operating at 44.1 kHz. We release our code and trained models to facilitate further research on singing voice and related areas.
* Accepted at the ISMIR conference, Milan, Italy, 2023
MuTox: Universal MUltilingual Audio-based TOXicity Dataset and Zero-shot Detector
Jan 10, 2024Research in toxicity detection in natural language processing for the speech modality (audio-based) is quite limited, particularly for languages other than English. To address these limitations and lay the groundwork for truly multilingual audio-based toxicity detection, we introduce MuTox, the first highly multilingual audio-based dataset with toxicity labels. The dataset comprises 20,000 audio utterances for English and Spanish, and 4,000 for the other 19 languages. To demonstrate the quality of this dataset, we trained the MuTox audio-based toxicity classifier, which enables zero-shot toxicity detection across a wide range of languages. This classifier outperforms existing text-based trainable classifiers by more than 1% AUC, while expanding the language coverage more than tenfold. When compared to a wordlist-based classifier that covers a similar number of languages, MuTox improves precision and recall by approximately 2.5 times. This significant improvement underscores the potential of MuTox in advancing the field of audio-based toxicity detection.
MossFormer2: Combining Transformer and RNN-Free Recurrent Network for Enhanced Time-Domain Monaural Speech Separation
Dec 19, 2023Our previously proposed MossFormer has achieved promising performance in monaural speech separation. However, it predominantly adopts a self-attention-based MossFormer module, which tends to emphasize longer-range, coarser-scale dependencies, with a deficiency in effectively modelling finer-scale recurrent patterns. In this paper, we introduce a novel hybrid model that provides the capabilities to model both long-range, coarse-scale dependencies and fine-scale recurrent patterns by integrating a recurrent module into the MossFormer framework. Instead of applying the recurrent neural networks (RNNs) that use traditional recurrent connections, we present a recurrent module based on a feedforward sequential memory network (FSMN), which is considered "RNN-free" recurrent network due to the ability to capture recurrent patterns without using recurrent connections. Our recurrent module mainly comprises an enhanced dilated FSMN block by using gated convolutional units (GCU) and dense connections. In addition, a bottleneck layer and an output layer are also added for controlling information flow. The recurrent module relies on linear projections and convolutions for seamless, parallel processing of the entire sequence. The integrated MossFormer2 hybrid model demonstrates remarkable enhancements over MossFormer and surpasses other state-of-the-art methods in WSJ0-2/3mix, Libri2Mix, and WHAM!/WHAMR! benchmarks.