 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Look Who's Talking: Active Speaker Detection in the Wild
Aug 17, 2021
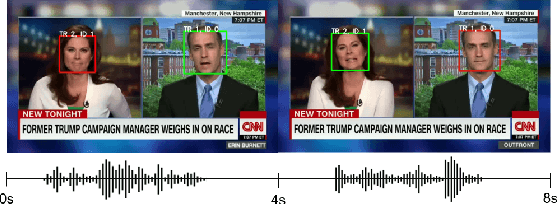
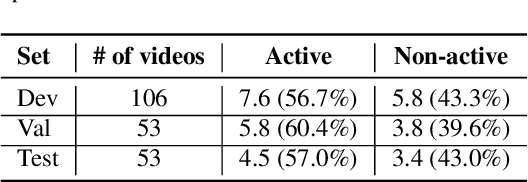
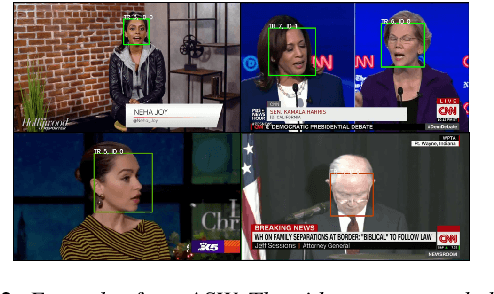
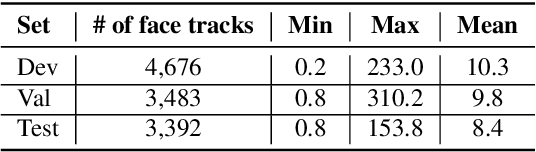
In this work, we present a novel audio-visual dataset for active speaker detection in the wild. A speaker is considered active when his or her face is visible and the voice is audible simultaneously. Although active speaker detection is a crucial pre-processing step for many audio-visual tasks, there is no existing dataset of natural human speech to evaluate the performance of active speaker detection. We therefore curate the Active Speakers in the Wild (ASW) dataset which contains videos and co-occurring speech segments with dense speech activity labels. Videos and timestamps of audible segments are parsed and adopted from VoxConverse, an existing speaker diarisation dataset that consists of videos in the wild. Face tracks are extracted from the videos and active segments are annotated based on the timestamps of VoxConverse in a semi-automatic way. Two reference systems, a self-supervised system and a fully supervised one, are evaluated on the dataset to provide the baseline performances of ASW. Cross-domain evaluation is conducted in order to show the negative effect of dubbed videos in the training data.
Tensor-Train Long Short-Term Memory for Monaural Speech Enhancement
Dec 25, 2018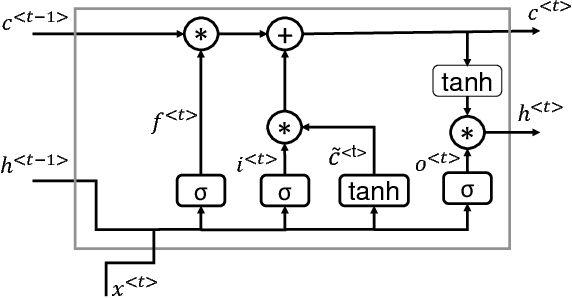
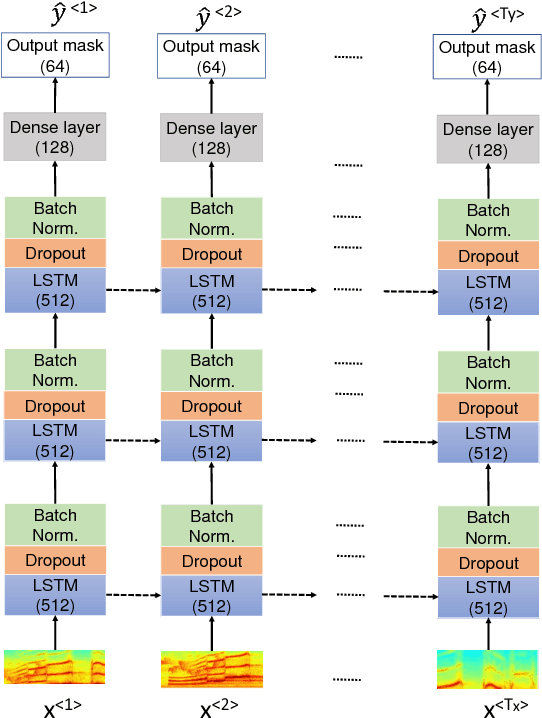
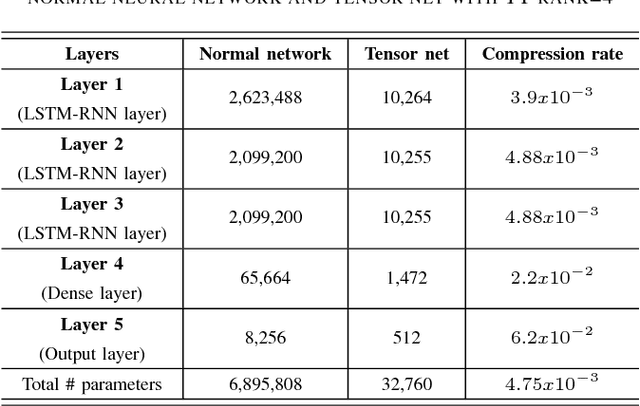
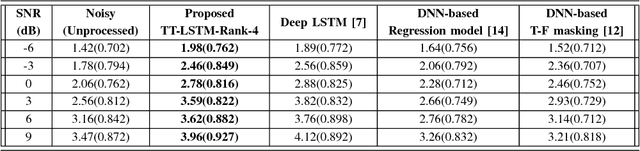
In recent years, Long Short-Term Memory (LSTM) has become a popular choice for speech separation and speech enhancement task. The capability of LSTM network can be enhanced by widening and adding more layers. However, this would introduce millions of parameters in the network and also increase the requirement of computational resources. These limitations hinders the efficient implementation of RNN models in low-end devices such as mobile phones and embedded systems with limited memory. To overcome these issues, we proposed to use an efficient alternative approach of reducing parameters by representing the weight matrix parameters of LSTM based on Tensor-Train (TT) format. We called this Tensor-Train factorized LSTM as TT-LSTM model. Based on this TT-LSTM units, we proposed a deep TensorNet model for single-channel speech enhancement task. Experimental results in various test conditions and in terms of standard speech quality and intelligibility metrics, demonstrated that the proposed deep TT-LSTM based speech enhancement framework can achieve competitive performances with the state-of-the-art uncompressed RNN model, even though the proposed model architecture is orders of magnitude less complex.
NewsPod: Automatic and Interactive News Podcasts
Feb 15, 2022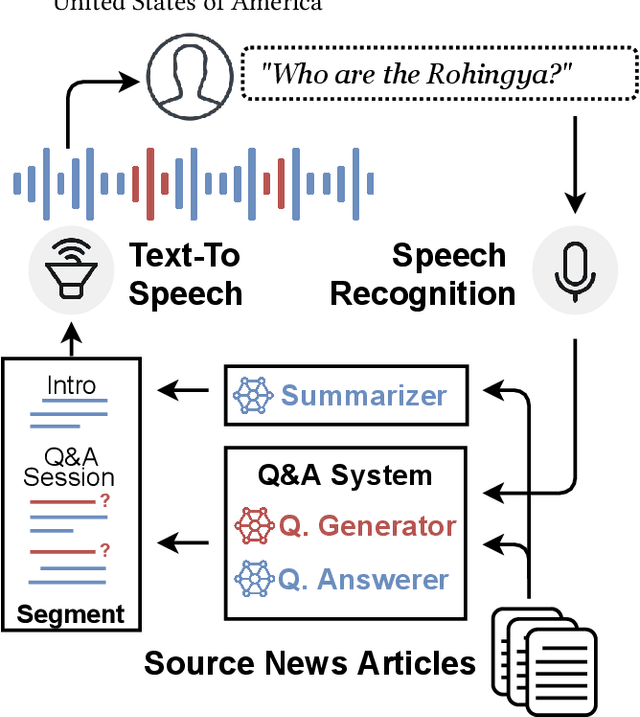
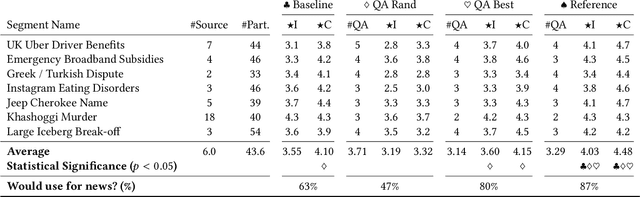
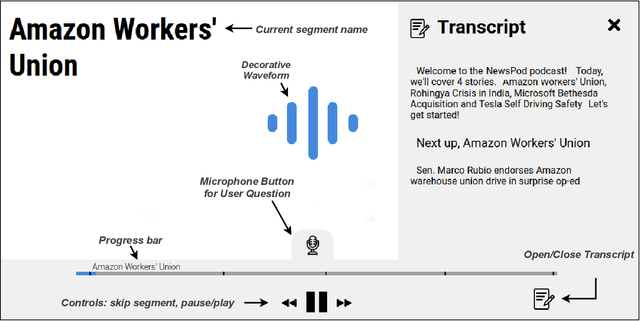
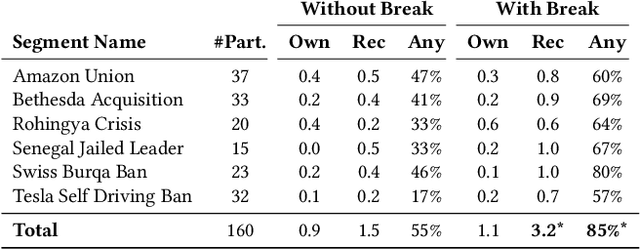
News podcasts are a popular medium to stay informed and dive deep into news topics. Today, most podcasts are handcrafted by professionals. In this work, we advance the state-of-the-art in automatically generated podcasts, making use of recent advances in natural language processing and text-to-speech technology. We present NewsPod, an automatically generated, interactive news podcast. The podcast is divided into segments, each centered on a news event, with each segment structured as a Question and Answer conversation, whose goal is to engage the listener. A key aspect of the design is the use of distinct voices for each role (questioner, responder), to better simulate a conversation. Another novel aspect of NewsPod allows listeners to interact with the podcast by asking their own questions and receiving automatically generated answers. We validate the soundness of this system design through two usability studies, focused on evaluating the narrative style and interactions with the podcast, respectively. We find that NewsPod is preferred over a baseline by participants, with 80% claiming they would use the system in the future.
Sonority Measurement Using System, Source, and Suprasegmental Information
Jul 01, 2021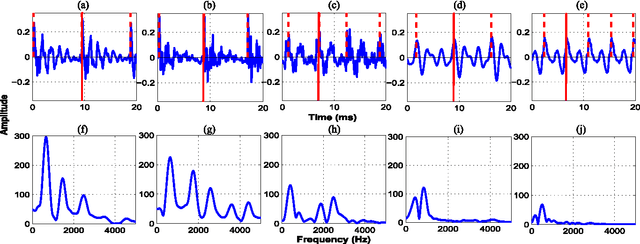
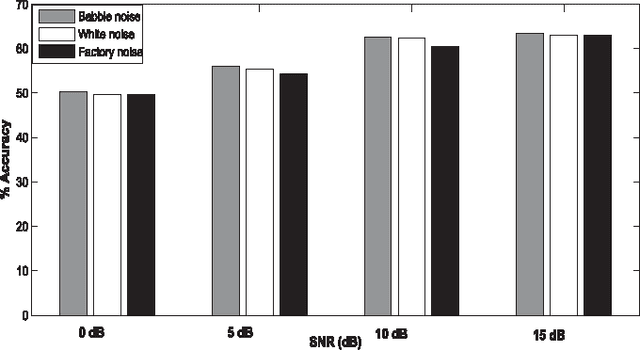
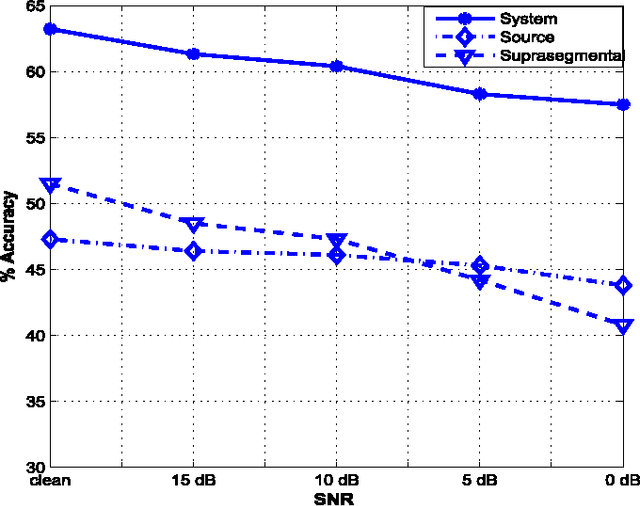
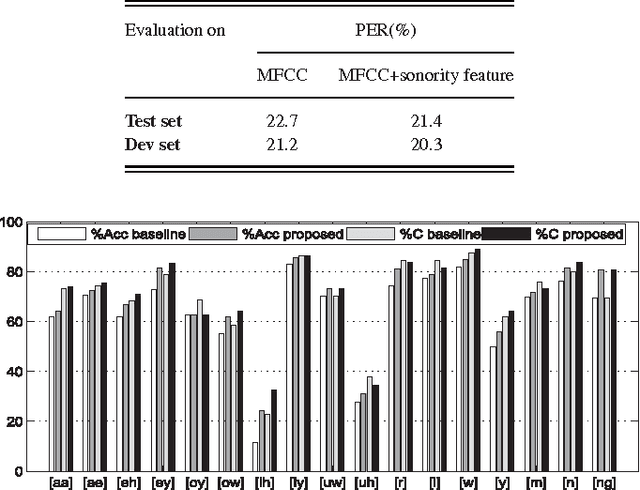
Sonorant sounds are characterized by regions with prominent formant structure, high energy and high degree of periodicity. In this work, the vocal-tract system, excitation source and suprasegmental features derived from the speech signal are analyzed to measure the sonority information present in each of them. Vocal-tract system information is extracted from the Hilbert envelope of numerator of group delay function. It is derived from zero time windowed speech signal that provides better resolution of the formants. A five-dimensional feature set is computed from the estimated formants to measure the prominence of the spectral peaks. A feature representing strength of excitation is derived from the Hilbert envelope of linear prediction residual, which represents the source information. Correlation of speech over ten consecutive pitch periods is used as the suprasegmental feature representing periodicity information. The combination of evidences from the three different aspects of speech provides better discrimination among different sonorant classes, compared to the baseline MFCC features. The usefulness of the proposed sonority feature is demonstrated in the tasks of phoneme recognition and sonorant classification.
Reducing Confusion in Active Learning for Part-Of-Speech Tagging
Nov 02, 2020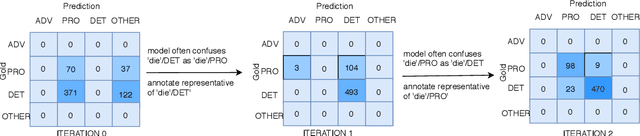

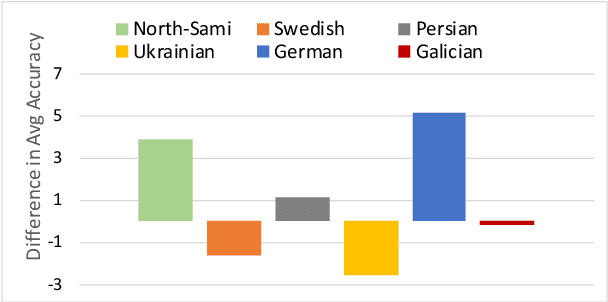

Active learning (AL) uses a data selection algorithm to select useful training samples to minimize annotation cost. This is now an essential tool for building low-resource syntactic analyzers such as part-of-speech (POS) taggers. Existing AL heuristics are generally designed on the principle of selecting uncertain yet representative training instances, where annotating these instances may reduce a large number of errors. However, in an empirical study across six typologically diverse languages (German, Swedish, Galician, North Sami, Persian, and Ukrainian), we found the surprising result that even in an oracle scenario where we know the true uncertainty of predictions, these current heuristics are far from optimal. Based on this analysis, we pose the problem of AL as selecting instances which maximally reduce the confusion between particular pairs of output tags. Extensive experimentation on the aforementioned languages shows that our proposed AL strategy outperforms other AL strategies by a significant margin. We also present auxiliary results demonstrating the importance of proper calibration of models, which we ensure through cross-view training, and analysis demonstrating how our proposed strategy selects examples that more closely follow the oracle data distribution.
SoK: A Modularized Approach to Study the Security of Automatic Speech Recognition Systems
Mar 19, 2021
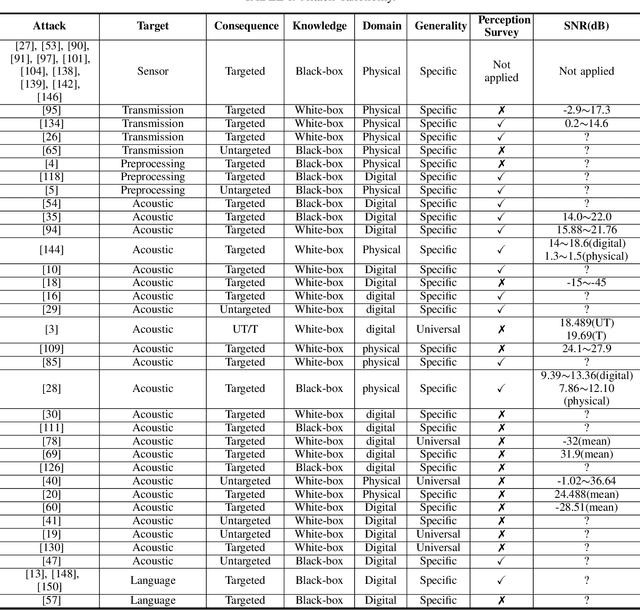

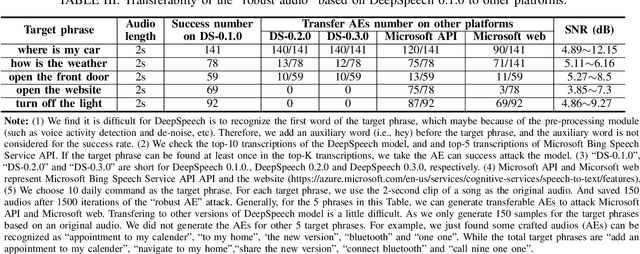
With the wide use of Automatic Speech Recognition (ASR) in applications such as human machine interaction, simultaneous interpretation, audio transcription, etc., its security protection becomes increasingly important. Although recent studies have brought to light the weaknesses of popular ASR systems that enable out-of-band signal attack, adversarial attack, etc., and further proposed various remedies (signal smoothing, adversarial training, etc.), a systematic understanding of ASR security (both attacks and defenses) is still missing, especially on how realistic such threats are and how general existing protection could be. In this paper, we present our systematization of knowledge for ASR security and provide a comprehensive taxonomy for existing work based on a modularized workflow. More importantly, we align the research in this domain with that on security in Image Recognition System (IRS), which has been extensively studied, using the domain knowledge in the latter to help understand where we stand in the former. Generally, both IRS and ASR are perceptual systems. Their similarities allow us to systematically study existing literature in ASR security based on the spectrum of attacks and defense solutions proposed for IRS, and pinpoint the directions of more advanced attacks and the directions potentially leading to more effective protection in ASR. In contrast, their differences, especially the complexity of ASR compared with IRS, help us learn unique challenges and opportunities in ASR security. Particularly, our experimental study shows that transfer learning across ASR models is feasible, even in the absence of knowledge about models (even their types) and training data.
WHAM!: Extending Speech Separation to Noisy Environments
Jul 02, 2019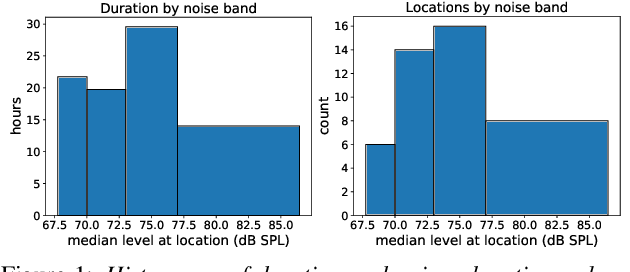
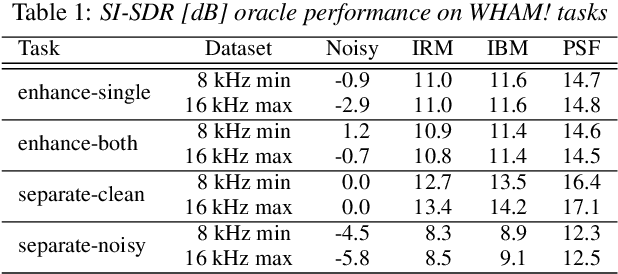
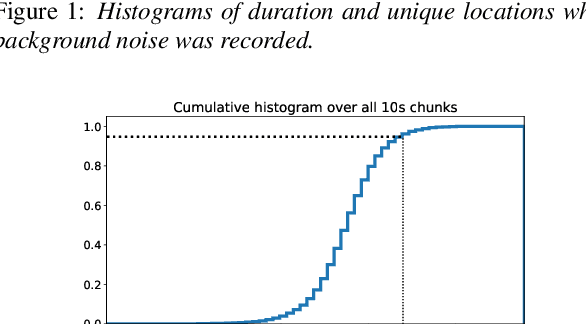
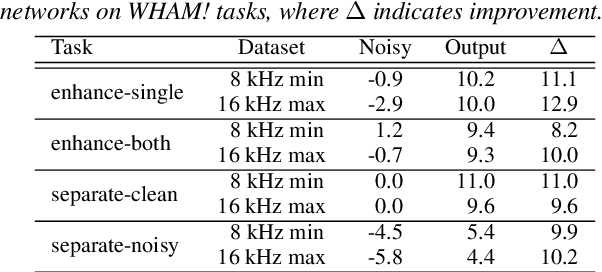
Recent progress in separating the speech signals from multiple overlapping speakers using a single audio channel has brought us closer to solving the cocktail party problem. However, most studies in this area use a constrained problem setup, comparing performance when speakers overlap almost completely, at artificially low sampling rates, and with no external background noise. In this paper, we strive to move the field towards more realistic and challenging scenarios. To that end, we created the WSJ0 Hipster Ambient Mixtures (WHAM!) dataset, consisting of two speaker mixtures from the wsj0-2mix dataset combined with real ambient noise samples. The samples were collected in coffee shops, restaurants, and bars in the San Francisco Bay Area, and are made publicly available. We benchmark various speech separation architectures and objective functions to evaluate their robustness to noise. While separation performance decreases as a result of noise, we still observe substantial gains relative to the noisy signals for most approaches.
A deep complex network with multi-frame filtering for stereophonic acoustic echo cancellation
Feb 03, 2022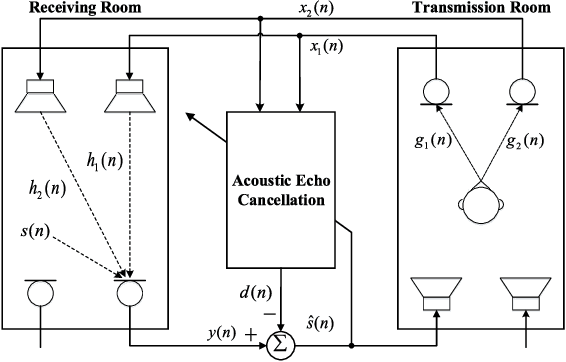
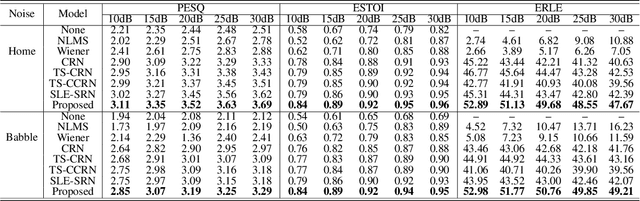
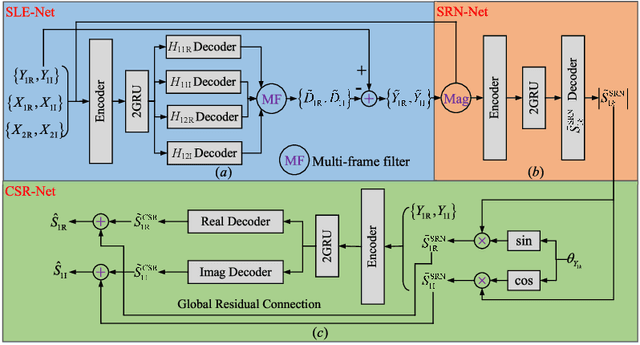
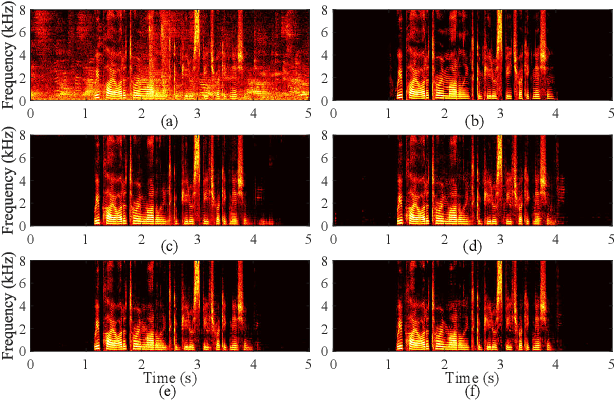
In hands-free communication system, the coupling between the loudspeaker and the microphone will generate echo signal, which can severely impair the quality of communication. Meanwhile, various types of noise in the communication environment further destroy the speech quality and intelligibility. It is hard to extract the near-end signal from the microphone input signal within one step, especially in low signal-to-noise ratios. In this paper, we propose a multi-stage approach to address this issue. On the one hand, we decompose the echo cancellation into two stages, including linear echo cancellation module and residual echo suppression module. A multi-frame filtering strategy is introduced to benefit estimating linear echo by utilizing more inter-frame information. On the other hand, we decouple the complex spectral mapping into magnitude estimation and complex spectra refine. Experimental results demonstrate that our proposed approach achieves stage-of-the-art performance over previous advanced algorithms under various conditions.
The Mirrornet : Learning Audio Synthesizer Controls Inspired by Sensorimotor Interaction
Oct 12, 2021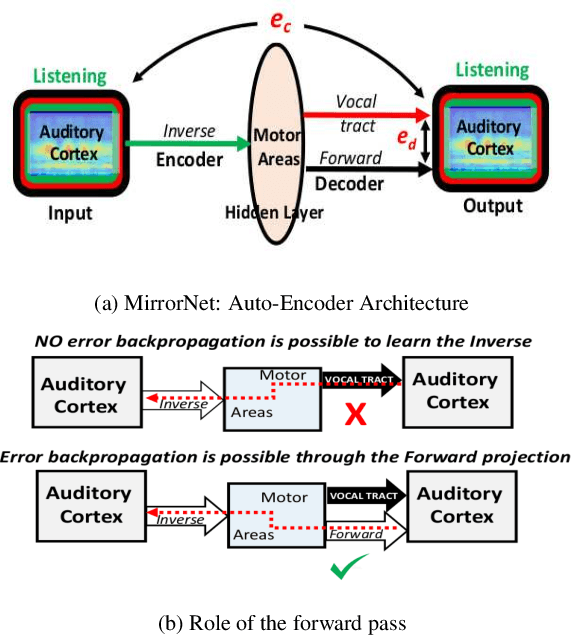
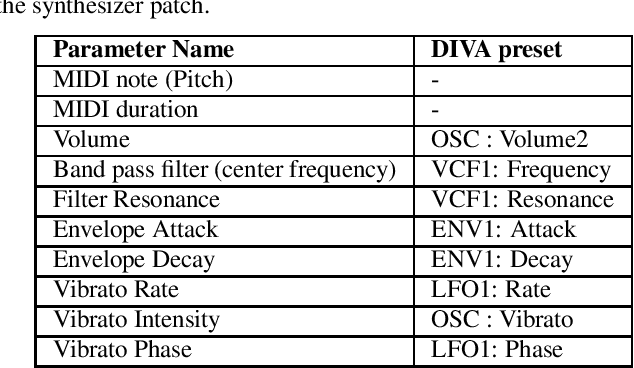
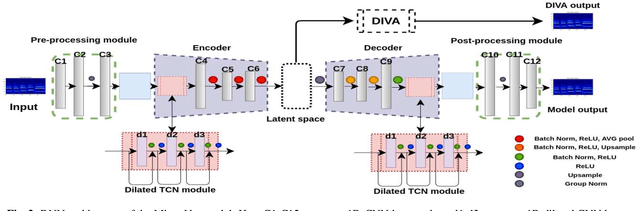
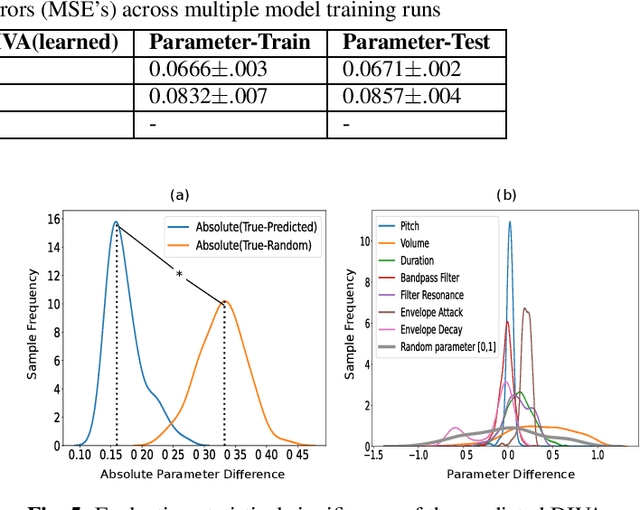
Experiments to understand the sensorimotor neural interactions in the human cortical speech system support the existence of a bidirectional flow of interactions between the auditory and motor regions. Their key function is to enable the brain to 'learn' how to control the vocal tract for speech production. This idea is the impetus for the recently proposed "MirrorNet", a constrained autoencoder architecture. In this paper, the MirrorNet is applied to learn, in an unsupervised manner, the controls of a specific audio synthesizer (DIVA) to produce melodies only from their auditory spectrograms. The results demonstrate how the MirrorNet discovers the synthesizer parameters to generate the melodies that closely resemble the original and those of unseen melodies, and even determine the best set parameters to approximate renditions of complex piano melodies generated by a different synthesizer. This generalizability of the MirrorNet illustrates its potential to discover from sensory data the controls of arbitrary motor-plants such as autonomous vehicles.
Defining maximum acceptable latency of AI-enhanced CAI tools
Jan 08, 2022
Recent years have seen an increasing number of studies around the design of computer-assisted interpreting tools with integrated automatic speech processing and their use by trainees and professional interpreters. This paper discusses the role of system latency of such tools and presents the results of an experiment designed to investigate the maximum system latency that is cognitively acceptable for interpreters working in the simultaneous modality. The results show that interpreters can cope with a system latency of 3 seconds without any major impact in the rendition of the original text, both in terms of accuracy and fluency. This value is above the typical latency of available AI-based CAI tools and paves the way to experiment with larger context-based language models and higher latencies.