 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Including STDP to eligibility propagation in multi-layer recurrent spiking neural networks
Jan 05, 2022
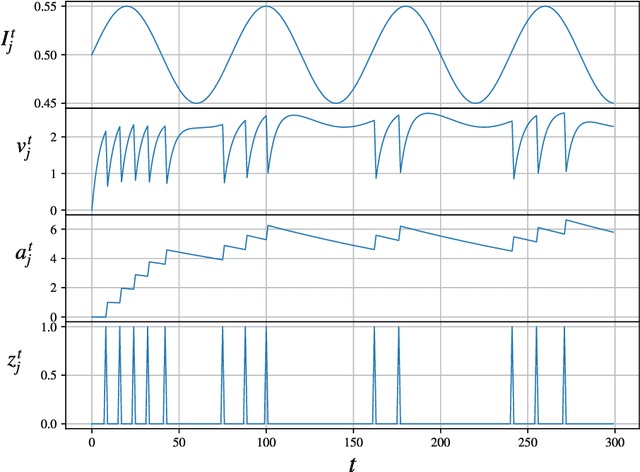
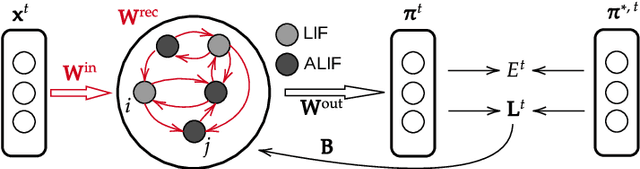
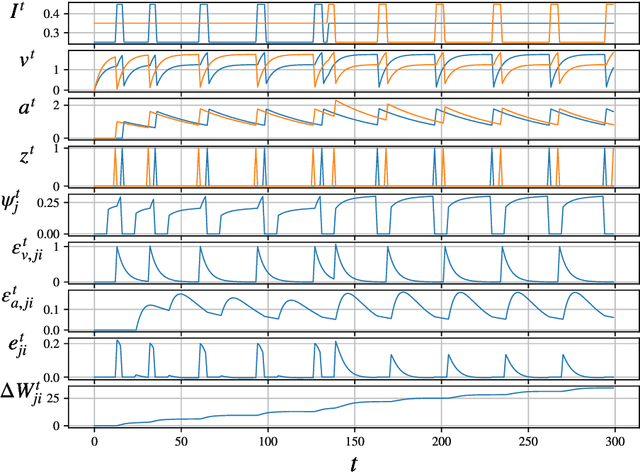
Spiking neural networks (SNNs) in neuromorphic systems are more energy efficient compared to deep learning-based methods, but there is no clear competitive learning algorithm for training such SNNs. Eligibility propagation (e-prop) offers an efficient and biologically plausible way to train competitive recurrent SNNs in low-power neuromorphic hardware. In this report, previous performance of e-prop on a speech classification task is reproduced, and the effects of including STDP-like behavior are analyzed. Including STDP to the ALIF neuron model improves the classification performance, but this is not the case for the Izhikevich e-prop neuron. Finally, it was found that e-prop implemented in a single-layer recurrent SNN consistently outperforms a multi-layer variant.
Reducing Confusion in Active Learning for Part-Of-Speech Tagging
Nov 02, 2020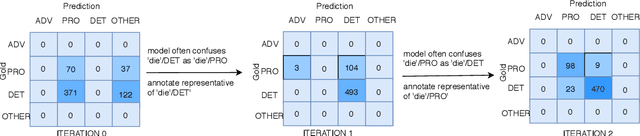

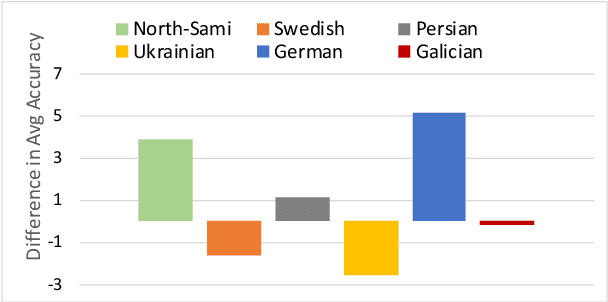

Active learning (AL) uses a data selection algorithm to select useful training samples to minimize annotation cost. This is now an essential tool for building low-resource syntactic analyzers such as part-of-speech (POS) taggers. Existing AL heuristics are generally designed on the principle of selecting uncertain yet representative training instances, where annotating these instances may reduce a large number of errors. However, in an empirical study across six typologically diverse languages (German, Swedish, Galician, North Sami, Persian, and Ukrainian), we found the surprising result that even in an oracle scenario where we know the true uncertainty of predictions, these current heuristics are far from optimal. Based on this analysis, we pose the problem of AL as selecting instances which maximally reduce the confusion between particular pairs of output tags. Extensive experimentation on the aforementioned languages shows that our proposed AL strategy outperforms other AL strategies by a significant margin. We also present auxiliary results demonstrating the importance of proper calibration of models, which we ensure through cross-view training, and analysis demonstrating how our proposed strategy selects examples that more closely follow the oracle data distribution.
Radically Old Way of Computing Spectra: Applications in End-to-End ASR
Apr 02, 2021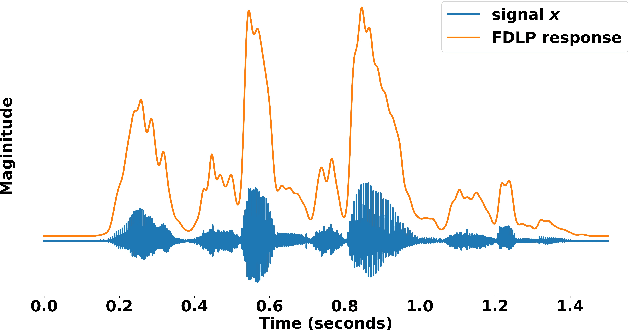

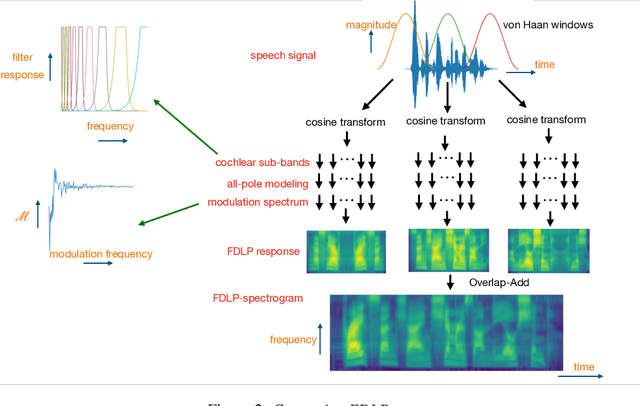

We propose a technique to compute spectrograms using Frequency Domain Linear Prediction (FDLP) that uses all-pole models to fit the squared Hilbert envelope of speech in different frequency sub-bands. The spectrogram of a complete speech utterance is computed by overlap-add of contiguous all-pole model responses. A long context window of 1.5 seconds allows us to capture the low frequency temporal modulations of speech in the spectrogram. For an end-to-end automatic speech recognition task, the FDLP spectrogram performs on par with the standard mel spectrogram features for clean read speech training and test data. For more realistic speech data with train-test domain mismatches or reverberations, FDLP spectrogram shows up to 25% and 22% relative WER improvements over mel spectrogram respectively.
Topic Identification for Speech without ASR
Jul 11, 2017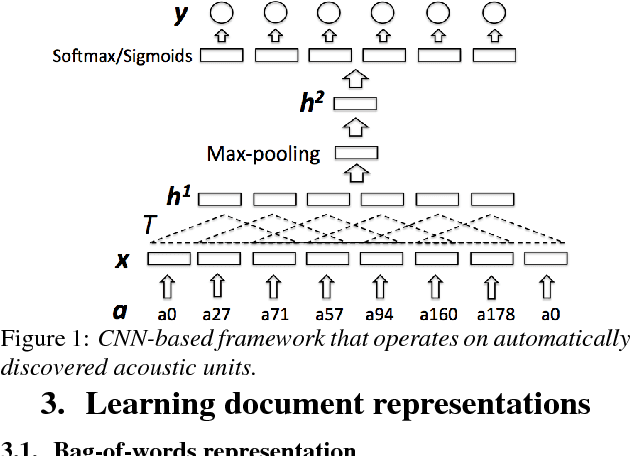
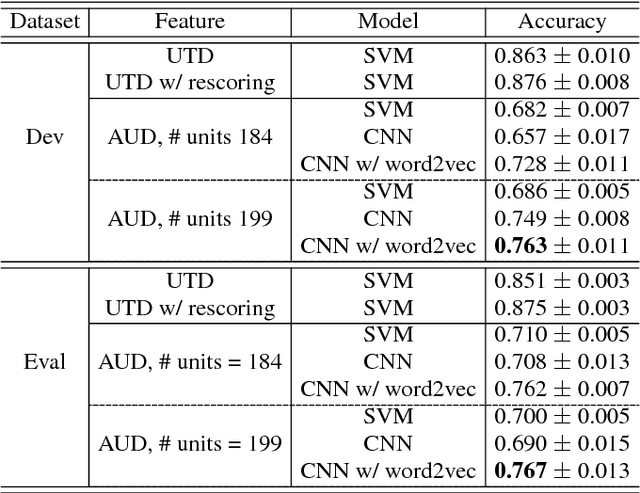
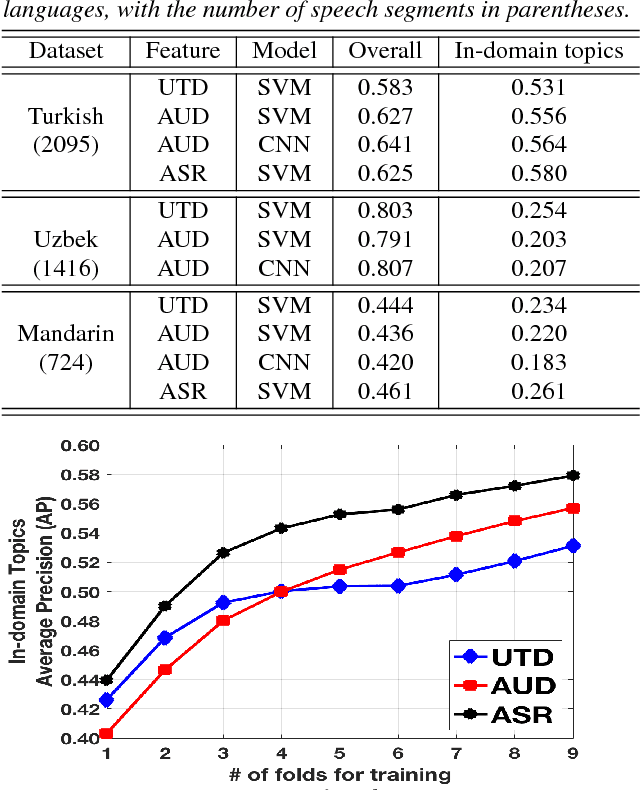
Modern topic identification (topic ID) systems for speech use automatic speech recognition (ASR) to produce speech transcripts, and perform supervised classification on such ASR outputs. However, under resource-limited conditions, the manually transcribed speech required to develop standard ASR systems can be severely limited or unavailable. In this paper, we investigate alternative unsupervised solutions to obtaining tokenizations of speech in terms of a vocabulary of automatically discovered word-like or phoneme-like units, without depending on the supervised training of ASR systems. Moreover, using automatic phoneme-like tokenizations, we demonstrate that a convolutional neural network based framework for learning spoken document representations provides competitive performance compared to a standard bag-of-words representation, as evidenced by comprehensive topic ID evaluations on both single-label and multi-label classification tasks.
WaveFuzz: A Clean-Label Poisoning Attack to Protect Your Voice
Mar 25, 2022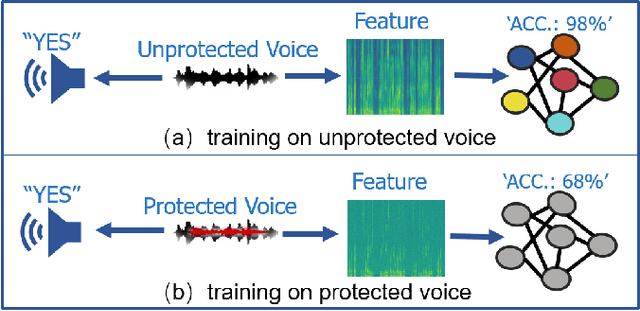
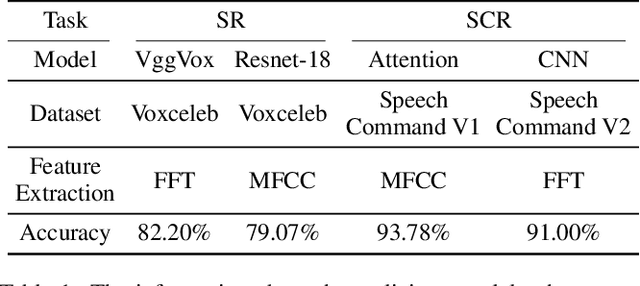
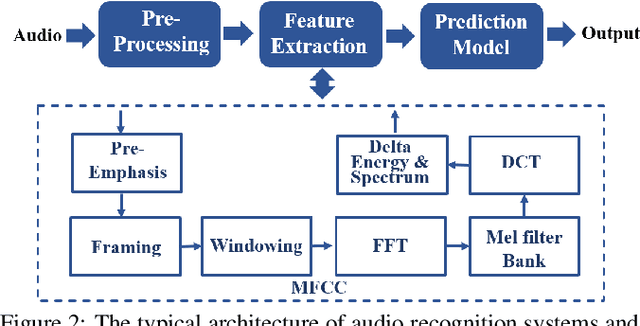
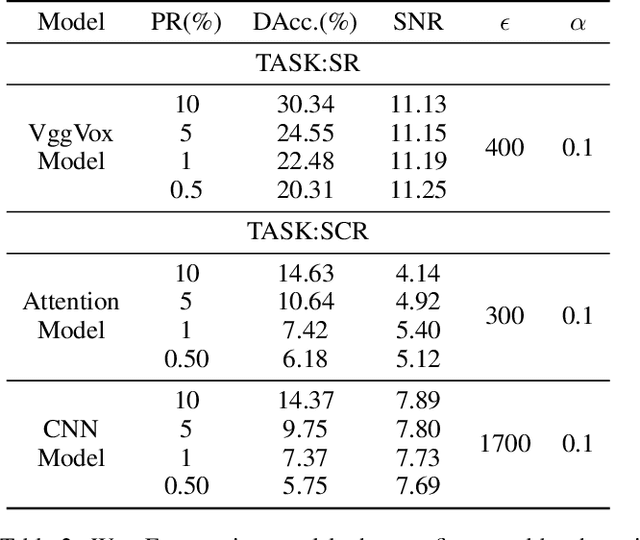
People are not always receptive to their voice data being collected and misused. Training the audio intelligence systems needs these data to build useful features, but the cost for getting permissions or purchasing data is very high, which inevitably encourages hackers to collect these voice data without people's awareness. To discourage the hackers from proactively collecting people's voice data, we are the first to propose a clean-label poisoning attack, called WaveFuzz, which can prevent intelligence audio models from building useful features from protected (poisoned) voice data but still preserve the semantic information to the humans. Specifically, WaveFuzz perturbs the voice data to cause Mel Frequency Cepstral Coefficients (MFCC) (typical representations of audio signals) to generate the poisoned frequency features. These poisoned features are then fed to audio prediction models, which degrades the performance of audio intelligence systems. Empirically, we show the efficacy of WaveFuzz by attacking two representative types of intelligent audio systems, i.e., speaker recognition system (SR) and speech command recognition system (SCR). For example, the accuracies of models are declined by $19.78\%$ when only $10\%$ of the poisoned voice data is to fine-tune models, and the accuracies of models declined by $6.07\%$ when only $10\%$ of the training voice data is poisoned. Consequently, WaveFuzz is an effective technique that enables people to fight back to protect their own voice data, which sheds new light on ameliorating privacy issues.
Sequential End-to-End Intent and Slot Label Classification and Localization
Jun 08, 2021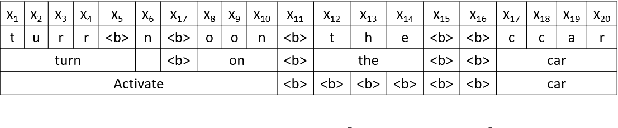

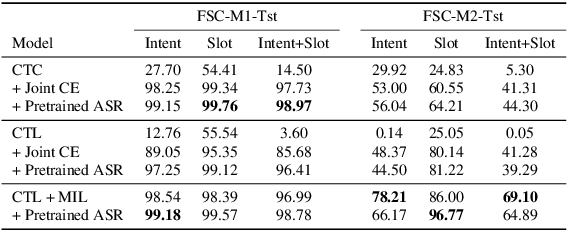
Human-computer interaction (HCI) is significantly impacted by delayed responses from a spoken dialogue system. Hence, end-to-end (e2e) spoken language understanding (SLU) solutions have recently been proposed to decrease latency. Such approaches allow for the extraction of semantic information directly from the speech signal, thus bypassing the need for a transcript from an automatic speech recognition (ASR) system. In this paper, we propose a compact e2e SLU architecture for streaming scenarios, where chunks of the speech signal are processed continuously to predict intent and slot values. Our model is based on a 3D convolutional neural network (3D-CNN) and a unidirectional long short-term memory (LSTM). We compare the performance of two alignment-free losses: the connectionist temporal classification (CTC) method and its adapted version, namely connectionist temporal localization (CTL). The latter performs not only the classification but also localization of sequential audio events. The proposed solution is evaluated on the Fluent Speech Command dataset and results show our model ability to process incoming speech signal, reaching accuracy as high as 98.97 % for CTC and 98.78 % for CTL on single-label classification, and as high as 95.69 % for CTC and 95.28 % for CTL on two-label prediction.
Studying Positive Speech on Twitter
Feb 24, 2017
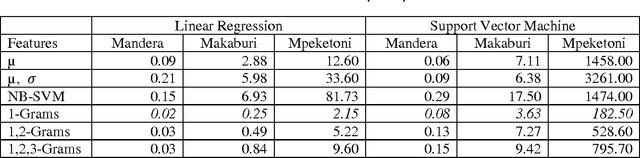

We present results of empirical studies on positive speech on Twitter. By positive speech we understand speech that works for the betterment of a given situation, in this case relations between different communities in a conflict-prone country. We worked with four Twitter data sets. Through semi-manual opinion mining, we found that positive speech accounted for < 1% of the data . In fully automated studies, we tested two approaches: unsupervised statistical analysis, and supervised text classification based on distributed word representation. We discuss benefits and challenges of those approaches and report empirical evidence obtained in the study.
DeLoRes: Decorrelating Latent Spaces for Low-Resource Audio Representation Learning
Apr 13, 2022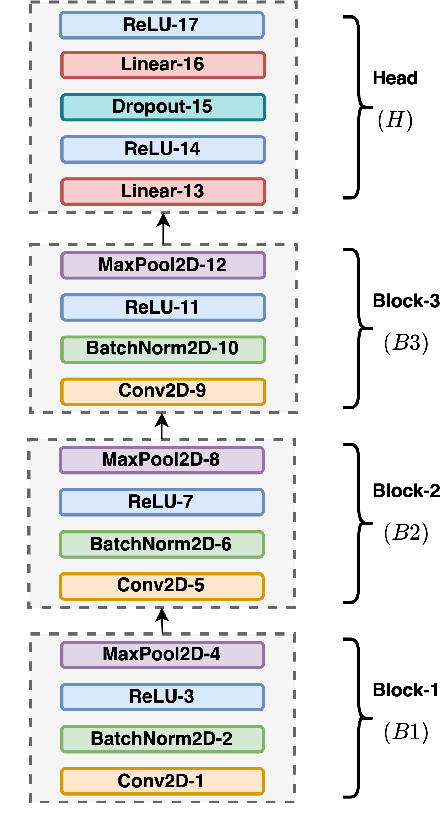
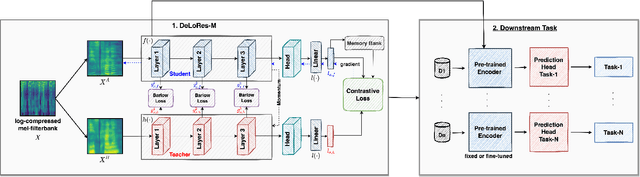
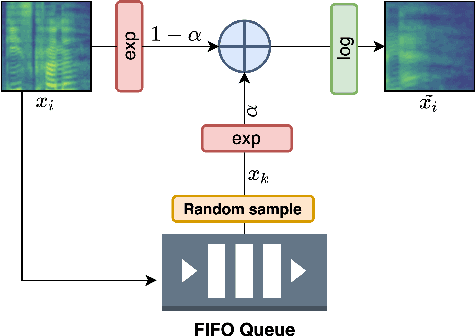
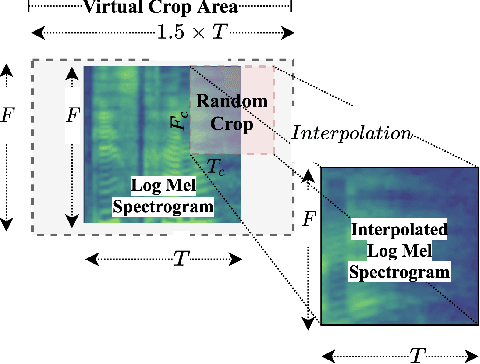
Inspired by the recent progress in self-supervised learning for computer vision, in this paper, through the DeLoRes learning framework, we introduce two new general-purpose audio representation learning approaches, the DeLoRes-S and DeLoRes-M. Our main objective is to make our network learn representations in a resource-constrained setting (both data and compute), that can generalize well across a diverse set of downstream tasks. Inspired from the Barlow Twins objective function, we propose to learn embeddings that are invariant to distortions of an input audio sample, while making sure that they contain non-redundant information about the sample. To achieve this, we measure the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of an audio segment sampled from an audio file and make it as close to the identity matrix as possible. We call this the DeLoRes learning framework, which we employ in different fashions with the DeLoRes-S and DeLoRes-M. We use a combination of a small subset of the large-scale AudioSet dataset and FSD50K for self-supervised learning and are able to learn with less than half the parameters compared to state-of-the-art algorithms. For evaluation, we transfer these learned representations to 11 downstream classification tasks, including speech, music, and animal sounds, and achieve state-of-the-art results on 7 out of 11 tasks on linear evaluation with DeLoRes-M and show competitive results with DeLoRes-S, even when pre-trained using only a fraction of the total data when compared to prior art. Our transfer learning evaluation setup also shows extremely competitive results for both DeLoRes-S and DeLoRes-M, with DeLoRes-M achieving state-of-the-art in 4 tasks.
Audio Interval Retrieval using Convolutional Neural Networks
Sep 21, 2021
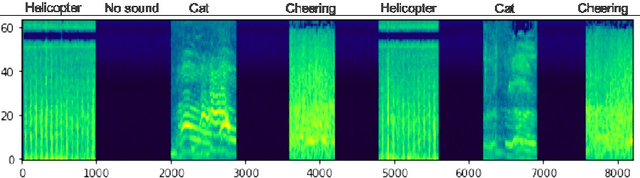
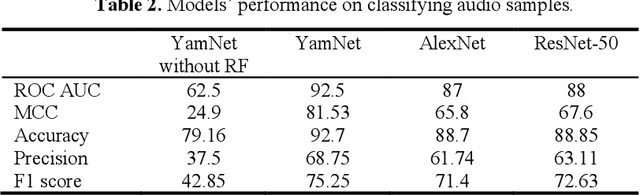
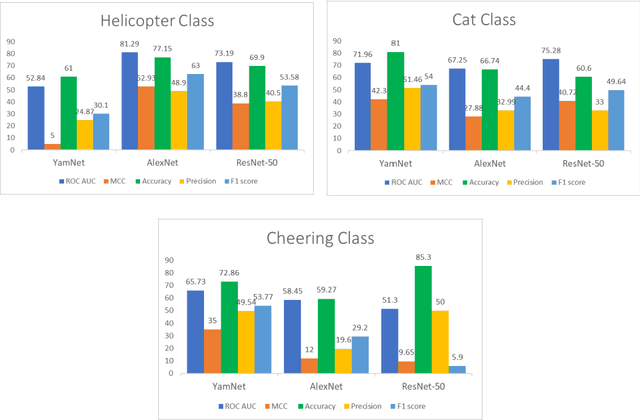
Modern streaming services are increasingly labeling videos based on their visual or audio content. This typically augments the use of technologies such as AI and ML by allowing to use natural speech for searching by keywords and video descriptions. Prior research has successfully provided a number of solutions for speech to text, in the case of a human speech, but this article aims to investigate possible solutions to retrieve sound events based on a natural language query, and estimate how effective and accurate they are. In this study, we specifically focus on the YamNet, AlexNet, and ResNet-50 pre-trained models to automatically classify audio samples using their respective melspectrograms into a number of predefined classes. The predefined classes can represent sounds associated with actions within a video fragment. Two tests are conducted to evaluate the performance of the models on two separate problems: audio classification and intervals retrieval based on a natural language query. Results show that the benchmarked models are comparable in terms of performance, with YamNet slightly outperforming the other two models. YamNet was able to classify single fixed-size audio samples with 92.7% accuracy and 68.75% precision while its average accuracy on intervals retrieval was 71.62% and precision was 41.95%. The investigated method may be embedded into an automated event marking architecture for streaming services.
A Quantitative and Qualitative Analysis of Schizophrenia Language
Jan 25, 2022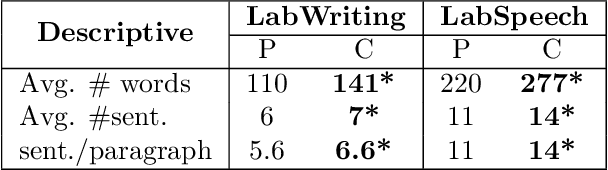
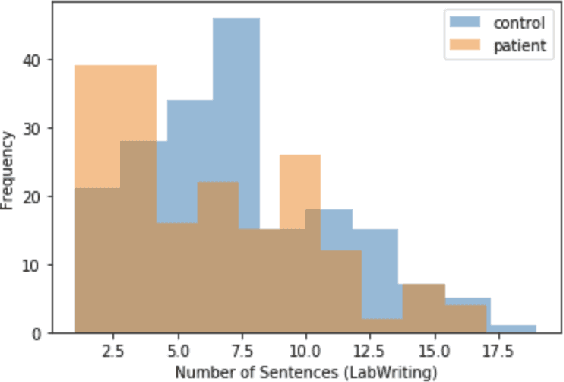
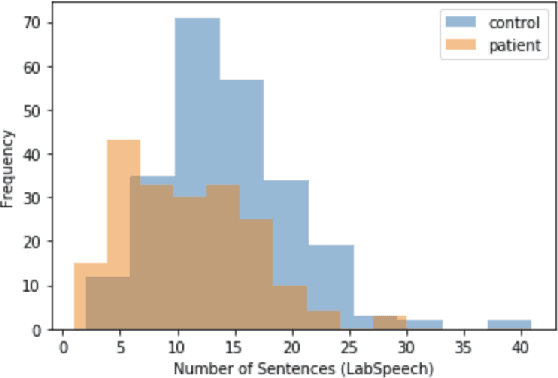
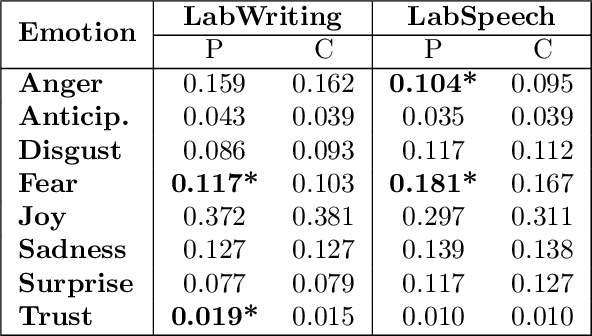
Schizophrenia is one of the most disabling mental health conditions to live with. Approximately one percent of the population has schizophrenia which makes it fairly common, and it affects many people and their families. Patients with schizophrenia suffer different symptoms: formal thought disorder (FTD), delusions, and emotional flatness. In this paper, we quantitatively and qualitatively analyze the language of patients with schizophrenia measuring various linguistic features in two modalities: speech and written text. We examine the following features: coherence and cohesion of thoughts, emotions, specificity, level of committed belief (LCB), and personality traits. Our results show that patients with schizophrenia score high in fear and neuroticism compared to healthy controls. In addition, they are more committed to their beliefs, and their writing lacks details. They score lower in most of the linguistic features of cohesion with significant p-values.