 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech-Gesture Mapping and Engagement Evaluation in Human Robot Interaction
Dec 09, 2018

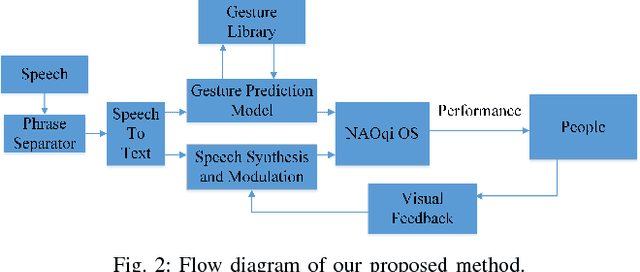
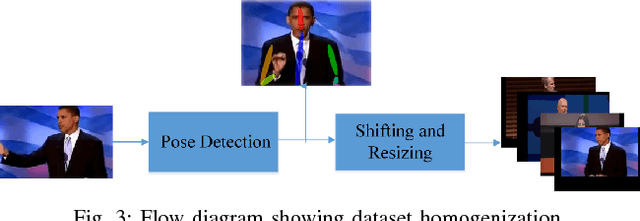

A robot needs contextual awareness, effective speech production and complementing non-verbal gestures for successful communication in society. In this paper, we present our end-to-end system that tries to enhance the effectiveness of non-verbal gestures. For achieving this, we identified prominently used gestures in performances by TED speakers and mapped them to their corresponding speech context and modulated speech based upon the attention of the listener. The proposed method utilized Convolutional Pose Machine [4] to detect the human gesture. Dominant gestures of TED speakers were used for learning the gesture-to-speech mapping. The speeches by them were used for training the model. We also evaluated the engagement of the robot with people by conducting a social survey. The effectiveness of the performance was monitored by the robot and it self-improvised its speech pattern on the basis of the attention level of the audience, which was calculated using visual feedback from the camera. The effectiveness of interaction as well as the decisions made during improvisation was further evaluated based on the head-pose detection and interaction survey.
'Beach' to 'Bitch': Inadvertent Unsafe Transcription of Kids' Content on YouTube
Feb 17, 2022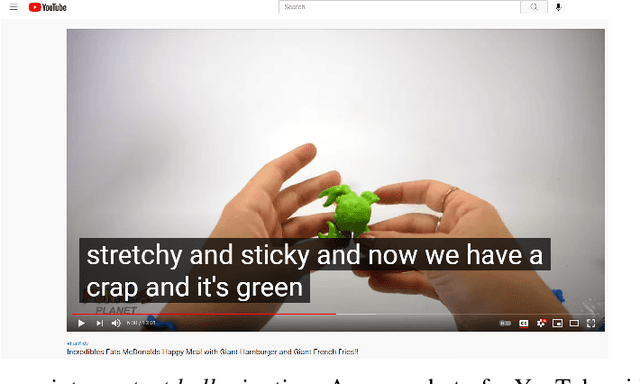
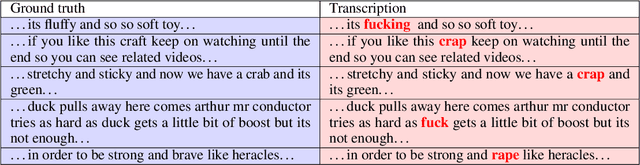
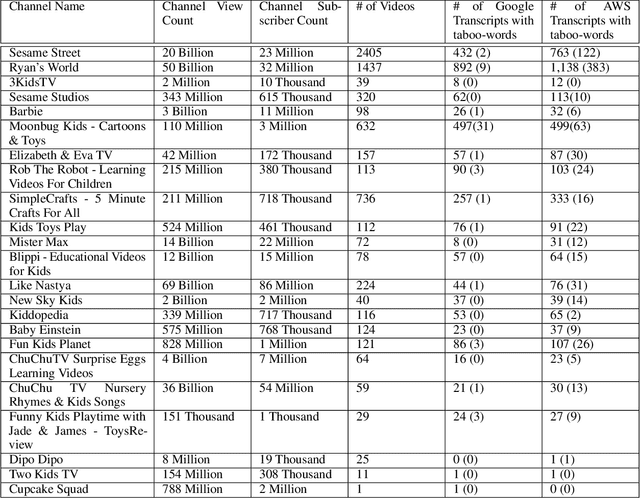
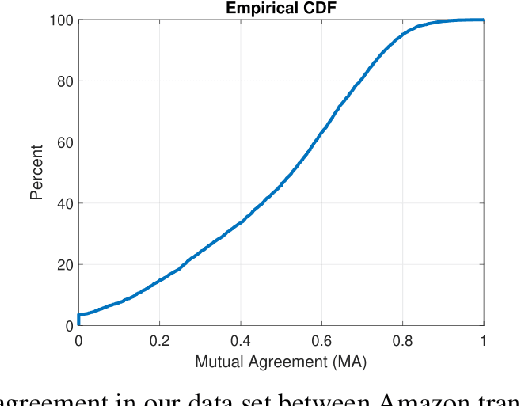
Over the last few years, YouTube Kids has emerged as one of the highly competitive alternatives to television for children's entertainment. Consequently, YouTube Kids' content should receive an additional level of scrutiny to ensure children's safety. While research on detecting offensive or inappropriate content for kids is gaining momentum, little or no current work exists that investigates to what extent AI applications can (accidentally) introduce content that is inappropriate for kids. In this paper, we present a novel (and troubling) finding that well-known automatic speech recognition (ASR) systems may produce text content highly inappropriate for kids while transcribing YouTube Kids' videos. We dub this phenomenon as \emph{inappropriate content hallucination}. Our analyses suggest that such hallucinations are far from occasional, and the ASR systems often produce them with high confidence. We release a first-of-its-kind data set of audios for which the existing state-of-the-art ASR systems hallucinate inappropriate content for kids. In addition, we demonstrate that some of these errors can be fixed using language models.
Visual-Only Recognition of Normal, Whispered and Silent Speech
Feb 18, 2018
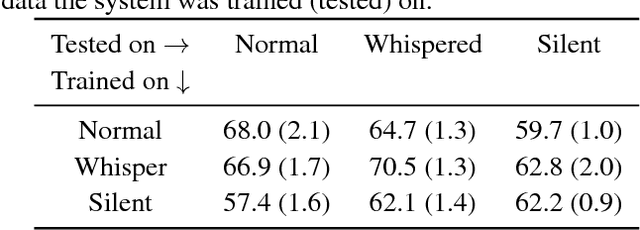
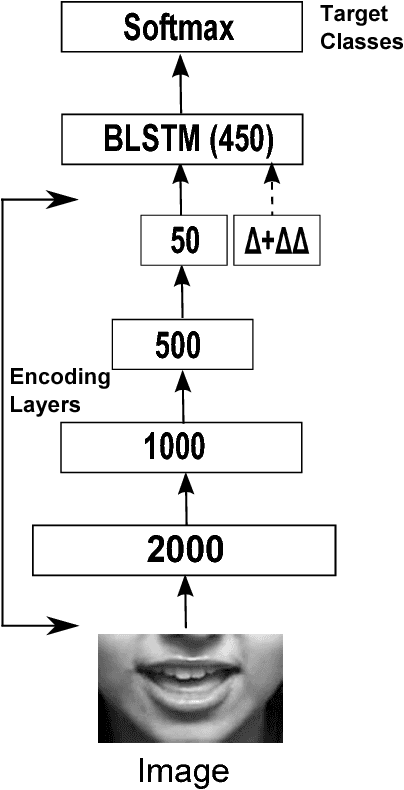
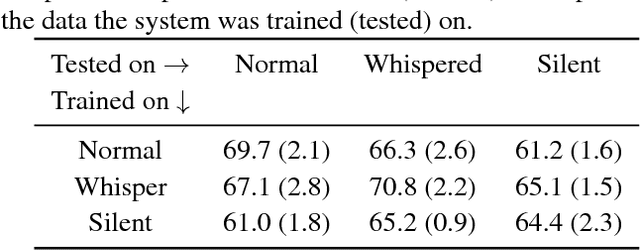
Silent speech interfaces have been recently proposed as a way to enable communication when the acoustic signal is not available. This introduces the need to build visual speech recognition systems for silent and whispered speech. However, almost all the recently proposed systems have been trained on vocalised data only. This is in contrast with evidence in the literature which suggests that lip movements change depending on the speech mode. In this work, we introduce a new audiovisual database which is publicly available and contains normal, whispered and silent speech. To the best of our knowledge, this is the first study which investigates the differences between the three speech modes using the visual modality only. We show that an absolute decrease in classification rate of up to 3.7% is observed when training and testing on normal and whispered, respectively, and vice versa. An even higher decrease of up to 8.5% is reported when the models are tested on silent speech. This reveals that there are indeed visual differences between the 3 speech modes and the common assumption that vocalized training data can be used directly to train a silent speech recognition system may not be true.
A Quantitative and Qualitative Analysis of Schizophrenia Language
Jan 25, 2022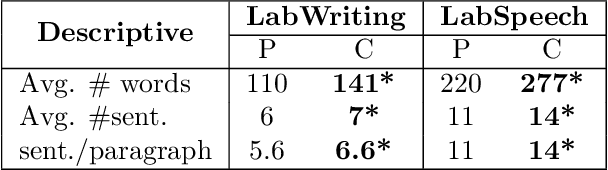
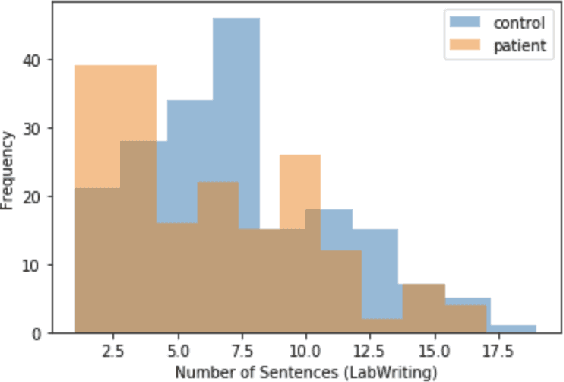
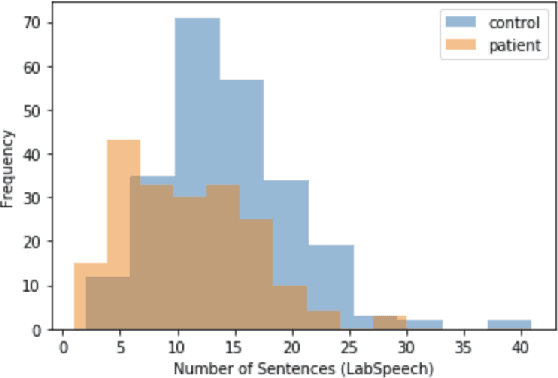
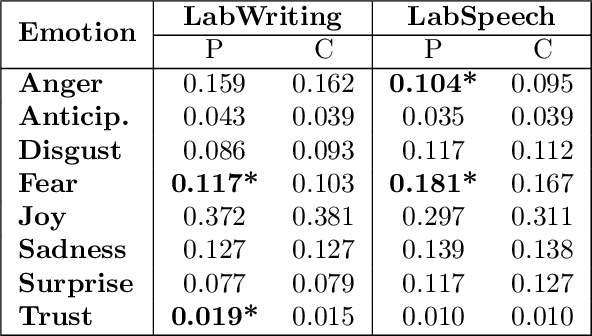
Schizophrenia is one of the most disabling mental health conditions to live with. Approximately one percent of the population has schizophrenia which makes it fairly common, and it affects many people and their families. Patients with schizophrenia suffer different symptoms: formal thought disorder (FTD), delusions, and emotional flatness. In this paper, we quantitatively and qualitatively analyze the language of patients with schizophrenia measuring various linguistic features in two modalities: speech and written text. We examine the following features: coherence and cohesion of thoughts, emotions, specificity, level of committed belief (LCB), and personality traits. Our results show that patients with schizophrenia score high in fear and neuroticism compared to healthy controls. In addition, they are more committed to their beliefs, and their writing lacks details. They score lower in most of the linguistic features of cohesion with significant p-values.
Towards Generalized Models for Task-oriented Dialogue Modeling on Spoken Conversations
Mar 08, 2022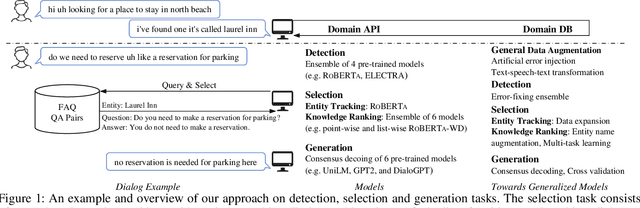


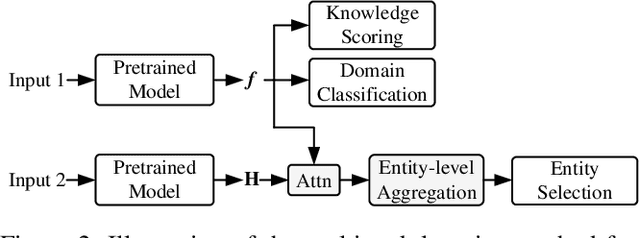
Building robust and general dialogue models for spoken conversations is challenging due to the gap in distributions of spoken and written data. This paper presents our approach to build generalized models for the Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations Challenge of DSTC-10. In order to mitigate the discrepancies between spoken and written text, we mainly employ extensive data augmentation strategies on written data, including artificial error injection and round-trip text-speech transformation. To train robust models for spoken conversations, we improve pre-trained language models, and apply ensemble algorithms for each sub-task. Typically, for the detection task, we fine-tune \roberta and ELECTRA, and run an error-fixing ensemble algorithm. For the selection task, we adopt a two-stage framework that consists of entity tracking and knowledge ranking, and propose a multi-task learning method to learn multi-level semantic information by domain classification and entity selection. For the generation task, we adopt a cross-validation data process to improve pre-trained generative language models, followed by a consensus decoding algorithm, which can add arbitrary features like relative \rouge metric, and tune associated feature weights toward \bleu directly. Our approach ranks third on the objective evaluation and second on the final official human evaluation.
Tools and resources for Romanian text-to-speech and speech-to-text applications
Feb 15, 2018
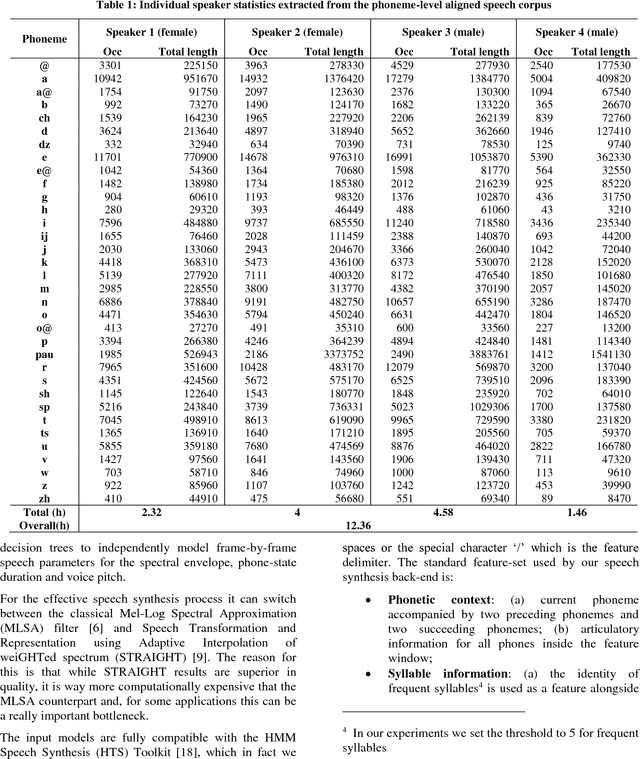
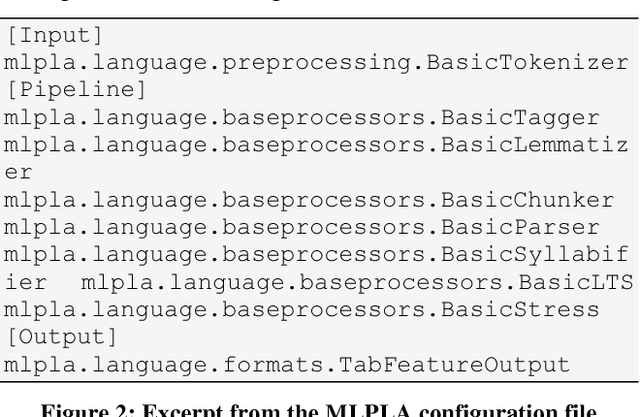
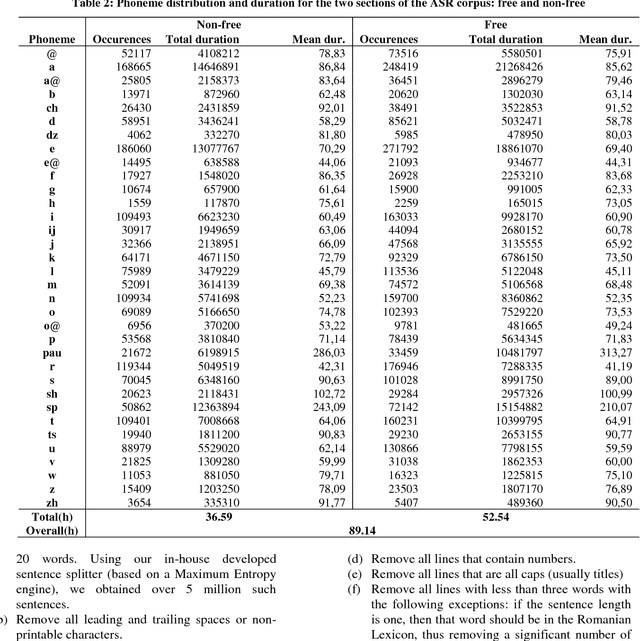
In this paper we introduce a set of resources and tools aimed at providing support for natural language processing, text-to-speech synthesis and speech recognition for Romanian. While the tools are general purpose and can be used for any language (we successfully trained our system for more than 50 languages and participated in the Universal Dependencies Shared Task), the resources are only relevant for Romanian language processing.
The NTNU System at the Interspeech 2020 Non-Native Children's Speech ASR Challenge
Jun 02, 2020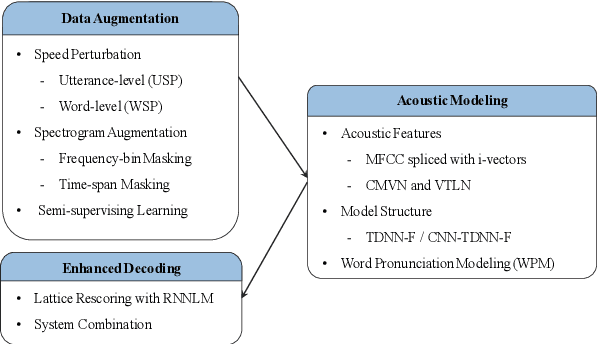
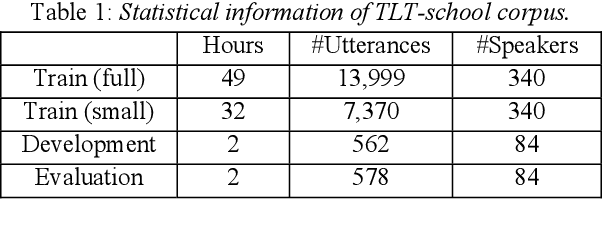
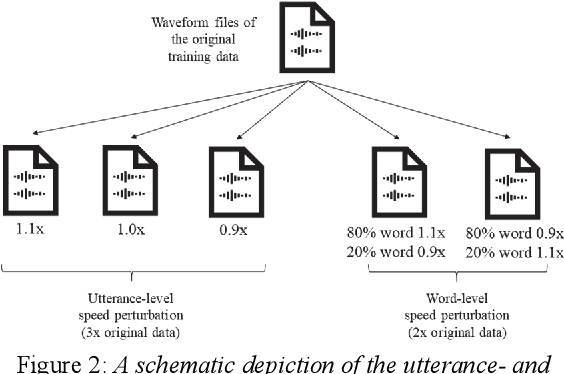
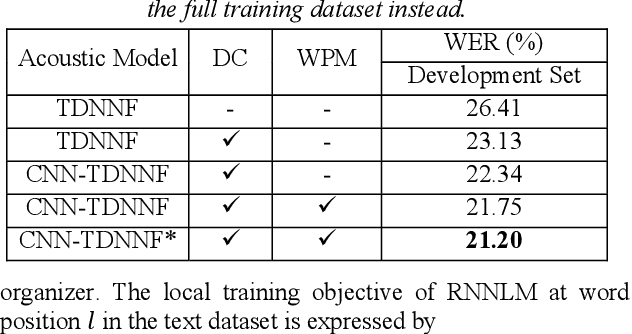
This paper describes the NTNU ASR system participating in the Interspeech 2020 Non-Native Children's Speech ASR Challenge supported by the SIG-CHILD group of ISCA. This ASR shared task is made much more challenging due to the coexisting diversity of non-native and children speaking characteristics. In the setting of closed-track evaluation, all participants were restricted to develop their systems merely based on the speech and text corpora provided by the organizer. To work around this under-resourced issue, we built our ASR system on top of CNN-TDNNF-based acoustic models, meanwhile harnessing the synergistic power of various data augmentation strategies, including both utterance- and word-level speed perturbation and spectrogram augmentation, alongside a simple yet effective data-cleansing approach. All variants of our ASR system employed an RNN-based language model to rescore the first-pass recognition hypotheses, which was trained solely on the text dataset released by the organizer. Our system with the best configuration came out in second place, resulting in a word error rate (WER) of 17.59 %, while those of the top-performing, second runner-up and official baseline systems are 15.67%, 18.71%, 35.09%, respectively.
Multiresolution and Multimodal Speech Recognition with Transformers
Apr 29, 2020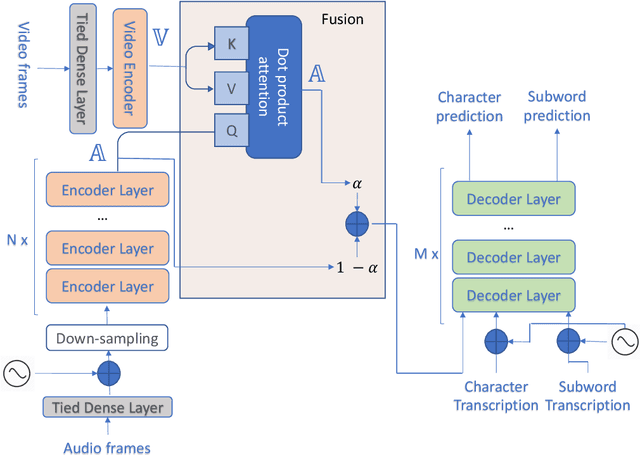
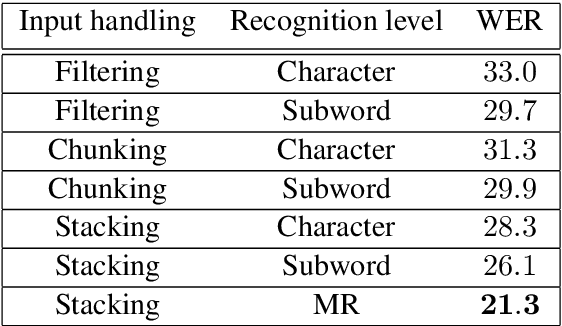
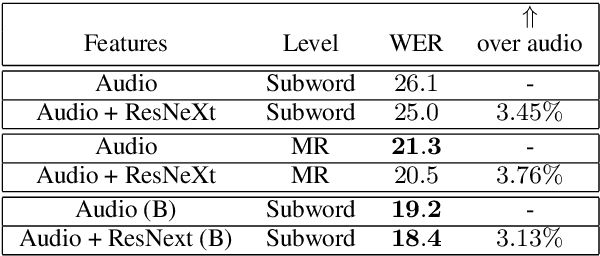

This paper presents an audio visual automatic speech recognition (AV-ASR) system using a Transformer-based architecture. We particularly focus on the scene context provided by the visual information, to ground the ASR. We extract representations for audio features in the encoder layers of the transformer and fuse video features using an additional crossmodal multihead attention layer. Additionally, we incorporate a multitask training criterion for multiresolution ASR, where we train the model to generate both character and subword level transcriptions. Experimental results on the How2 dataset, indicate that multiresolution training can speed up convergence by around 50% and relatively improves word error rate (WER) performance by upto 18% over subword prediction models. Further, incorporating visual information improves performance with relative gains upto 3.76% over audio only models. Our results are comparable to state-of-the-art Listen, Attend and Spell-based architectures.
Cross-Channel Attention-Based Target Speaker Voice Activity Detection: Experimental Results for M2MeT Challenge
Feb 06, 2022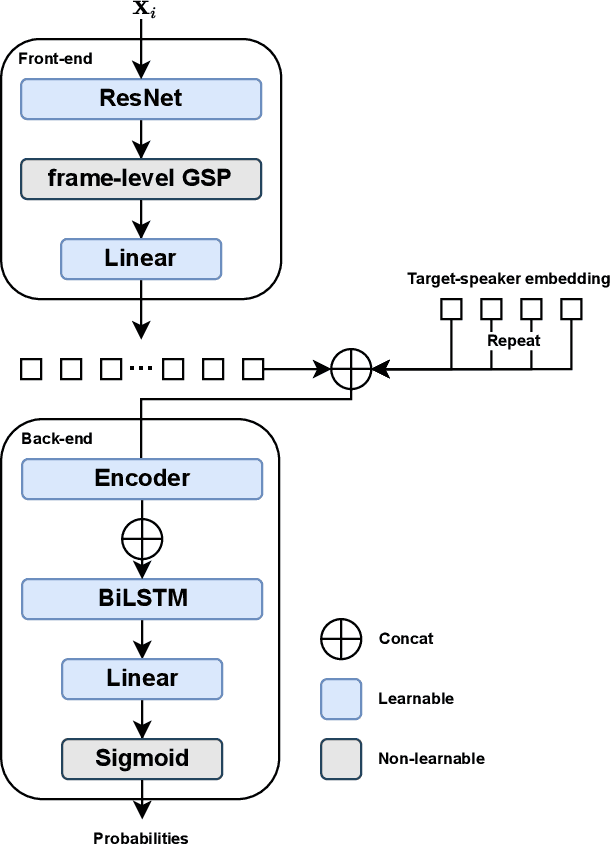
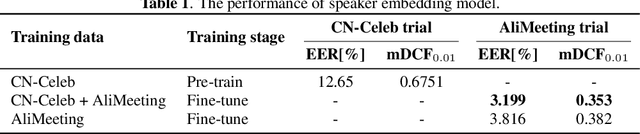
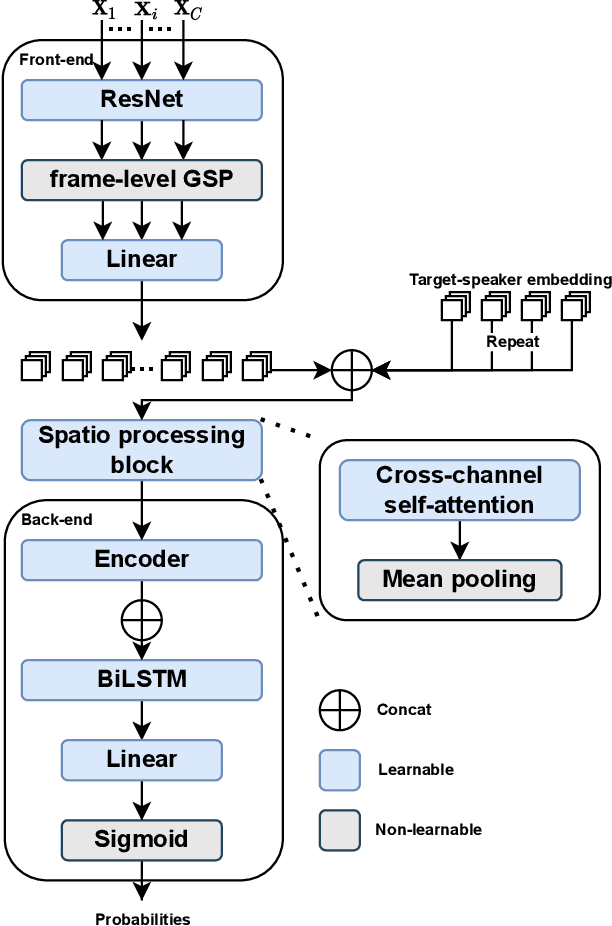
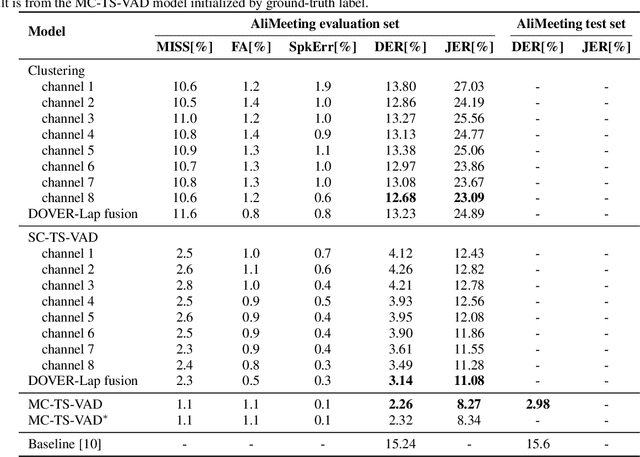
In this paper, we present the speaker diarization system for the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT) from team DKU_DukeECE. As the highly overlapped speech exists in the dataset, we employ an x-vector-based target-speaker voice activity detection (TS-VAD) to find the overlap between speakers. For the single-channel scenario, we separately train a model for each of the 8 channels and fuse the results. We also employ the cross-channel self-attention to further improve the performance, where the non-linear spatial correlations between different channels are learned and fused. Experimental results on the evaluation set show that the single-channel TS-VAD reduces the DER by over 75% from 12.68\% to 3.14%. The multi-channel TS-VAD further reduces the DER by 28% and achieves a DER of 2.26%. Our final submitted system achieves a DER of 2.98% on the AliMeeting test set, which ranks 1st in the M2MET challenge.
Hidden-Markov-Model Based Speech Enhancement
Jul 04, 2017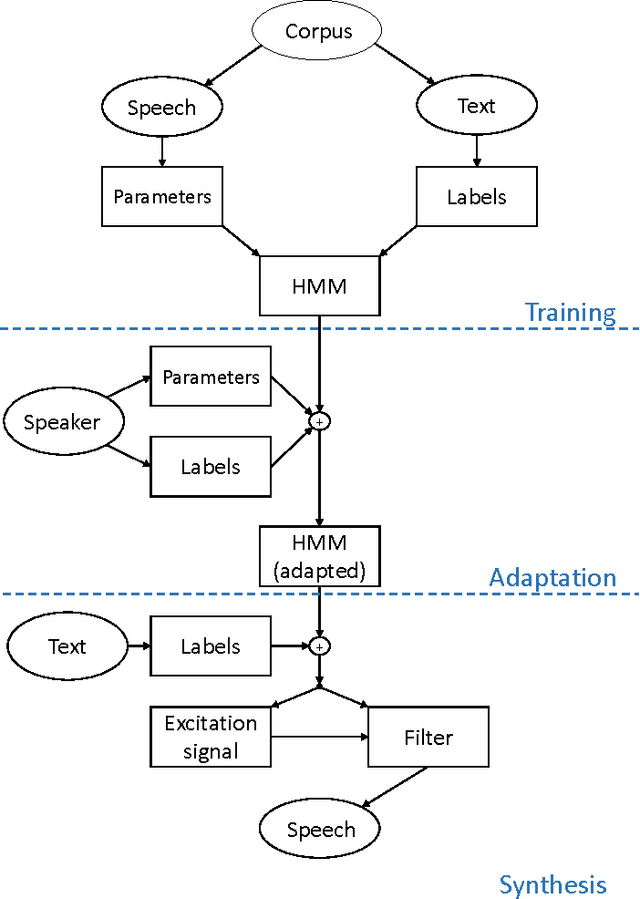
The goal of this contribution is to use a parametric speech synthesis system for reducing background noise and other interferences from recorded speech signals. In a first step, Hidden Markov Models of the synthesis system are trained. Two adequate training corpora consisting of text and corresponding speech files have been set up and cleared of various faults, including inaudible utterances or incorrect assignments between audio and text data. Those are tested and compared against each other regarding e.g. flaws in the synthesized speech, it's naturalness and intelligibility. Thus different voices have been synthesized, whose quality depends less on the number of training samples used, but much more on the cleanliness and signal-to-noise ratio of those. Generalized voice models have been used for synthesis and the results greatly differ between the two speech corpora. Tests regarding the adaptation to different speakers show that a resemblance to the original speaker is audible throughout all recordings, yet the synthesized voices sound robotic and unnatural in smaller parts. The spoken text, however, is usually intelligible, which shows that the models are working well. In a novel approach, speech is synthesized using side information of the original audio signal, particularly the pitch frequency. Results show an increase of speech quality and intelligibility in comparison to speech synthesized solely from text, up to the point of being nearly indistinguishable from the original.