 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Effective parameter estimation methods for an ExcitNet model in generative text-to-speech systems
May 21, 2019
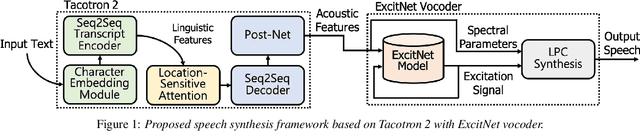

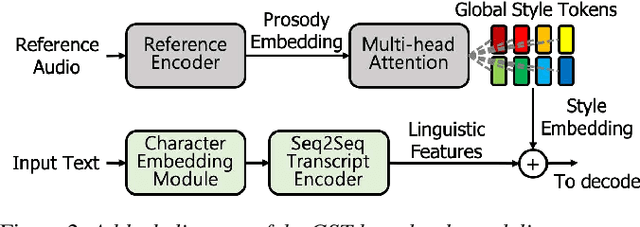
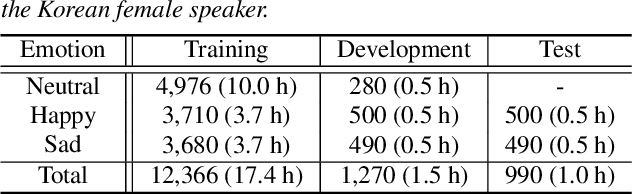
In this paper, we propose a high-quality generative text-to-speech (TTS) system using an effective spectrum and excitation estimation method. Our previous research verified the effectiveness of the ExcitNet-based speech generation model in a parametric TTS framework. However, the challenge remains to build a high-quality speech synthesis system because auxiliary conditional features estimated by a simple deep neural network often contain large prediction errors, and the errors are inevitably propagated throughout the autoregressive generation process of the ExcitNet vocoder. To generate more natural speech signals, we exploited a sequence-to-sequence (seq2seq) acoustic model with an attention-based generative network (e.g., Tacotron 2) to estimate the condition parameters of the ExcitNet vocoder. Because the seq2seq acoustic model accurately estimates spectral parameters, and because the ExcitNet model effectively generates the corresponding time-domain excitation signals, combining these two models can synthesize natural speech signals. Furthermore, we verified the merit of the proposed method in producing expressive speech segments by adopting a global style token-based emotion embedding method. The experimental results confirmed that the proposed system significantly outperforms the systems with a similarly configured conventional WaveNet vocoder and our best prior parametric TTS counterpart.
SSAST: Self-Supervised Audio Spectrogram Transformer
Oct 19, 2021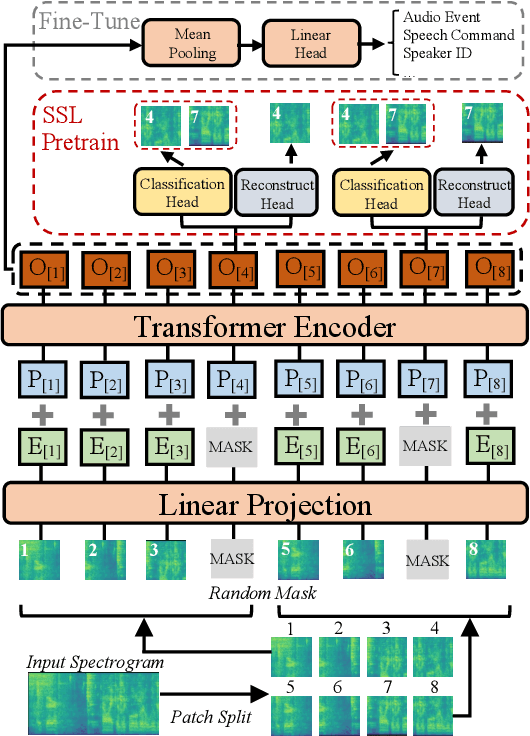
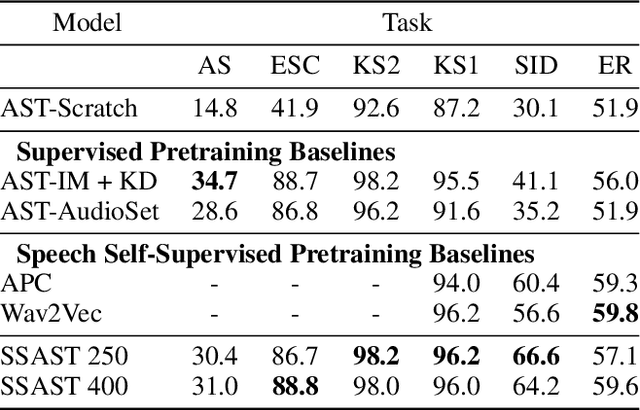
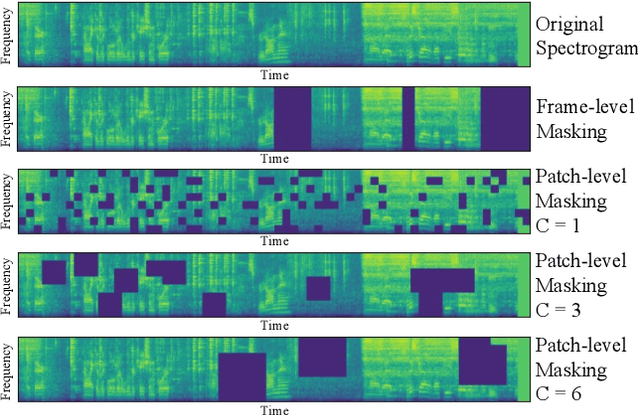
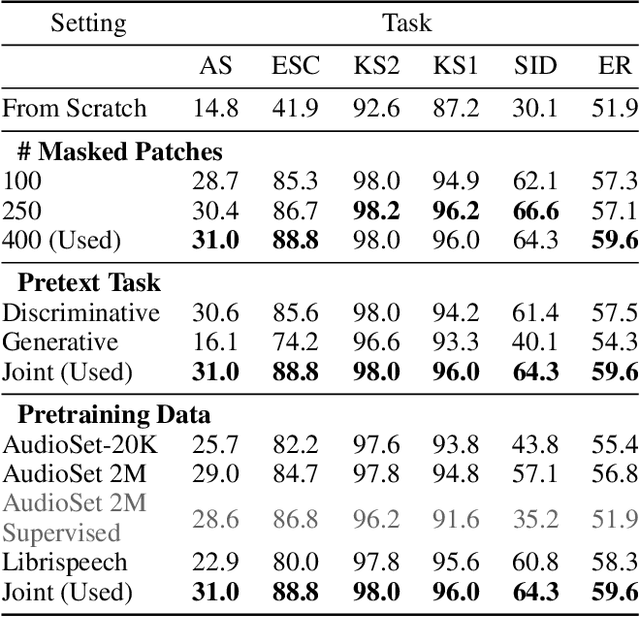
Recently, neural networks based purely on self-attention, such as the Vision Transformer (ViT), have been shown to outperform deep learning models constructed with convolutional neural networks (CNNs) on various vision tasks, thus extending the success of Transformers, which were originally developed for language processing, to the vision domain. A recent study showed that a similar methodology can also be applied to the audio domain. Specifically, the Audio Spectrogram Transformer (AST) achieves state-of-the-art results on various audio classification benchmarks. However, pure Transformer models tend to require more training data compared to CNNs, and the success of the AST relies on supervised pretraining that requires a large amount of labeled data and a complex training pipeline, thus limiting the practical usage of AST. This paper focuses on audio and speech classification, and aims to alleviate the data requirement issues with the AST by leveraging self-supervised learning using unlabeled data. Specifically, we propose to pretrain the AST model with joint discriminative and generative masked spectrogram patch modeling (MSPM) using unlabeled audio from AudioSet and Librispeech. We evaluate our pretrained models on both audio and speech classification tasks including audio event classification, keyword spotting, emotion recognition, and speaker identification. The proposed self-supervised framework significantly boosts AST performance on all tasks, with an average improvement of 60.9%, leading to similar or even better results than a supervised pretrained AST. To the best of our knowledge, it is the first patch-based self-supervised learning framework in the audio and speech domain, and also the first self-supervised learning framework for AST.
Harmonic gated compensation network plus for ICASSP 2022 DNS CHALLENGE
Feb 25, 2022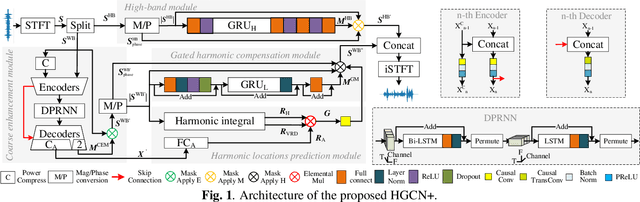
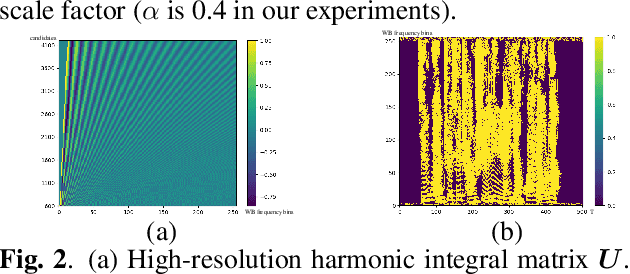

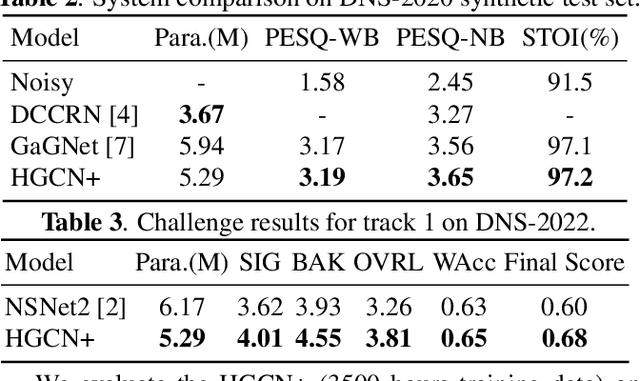
The harmonic structure of speech is resistant to noise, but the harmonics may still be partially masked by noise. Therefore, we previously proposed a harmonic gated compensation network (HGCN) to predict the full harmonic locations based on the unmasked harmonics and process the result of a coarse enhancement module to recover the masked harmonics. In addition, the auditory loudness loss function is used to train the network. For the DNS Challenge, we update HGCN with the following aspects, resulting in HGCN+. First, a high-band module is employed to help the model handle full-band signals. Second, cosine is used to model the harmonic structure more accurately. Then, the dual-path encoder and dual-path rnn (DPRNN) are introduced to take full advantage of the features. Finally, a gated residual linear structure replaces the gated convolution in the compensation module to increase the receptive field of frequency. The experimental results show that each updated module brings performance improvement to the model. HGCN+ also outperforms the referenced models on both wide-band and full-band test sets.
NIST SRE CTS Superset: A large-scale dataset for telephony speaker recognition
Aug 16, 2021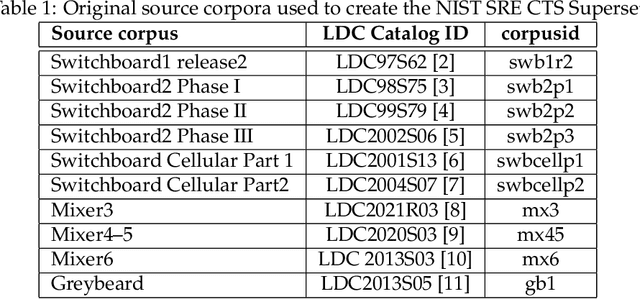
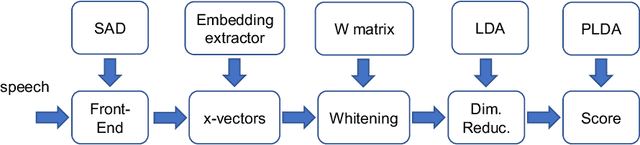
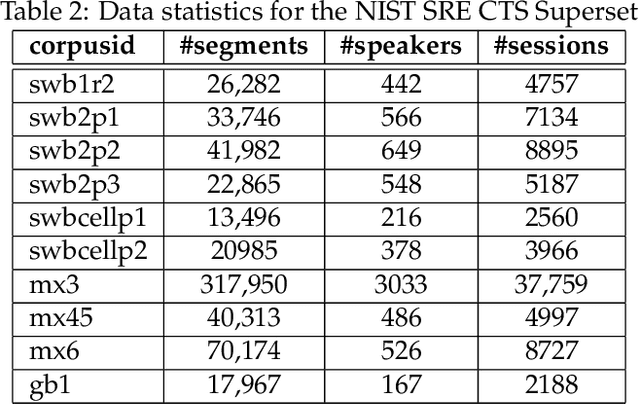
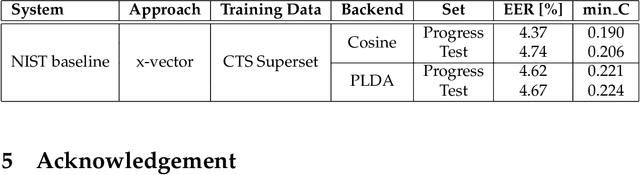
This document provides a brief description of the National Institute of Standards and Technology (NIST) speaker recognition evaluation (SRE) conversational telephone speech (CTS) Superset. The CTS Superset has been created in an attempt to provide the research community with a large-scale dataset along with uniform metadata that can be used to effectively train and develop telephony (narrowband) speaker recognition systems. It contains a large number of telephony speech segments from more than 6800 speakers with speech durations distributed uniformly in the [10s, 60s] range. The segments have been extracted from the source corpora used to compile prior SRE datasets (SRE1996-2012), including the Greybeard corpus as well as the Switchboard and Mixer series collected by the Linguistic Data Consortium (LDC). In addition to the brief description, we also report speaker recognition results on the NIST 2020 CTS Speaker Recognition Challenge, obtained using a system trained with the CTS Superset. The results will serve as a reference baseline for the challenge.
Fair Hate Speech Detection through Evaluation of Social Group Counterfactuals
Oct 24, 2020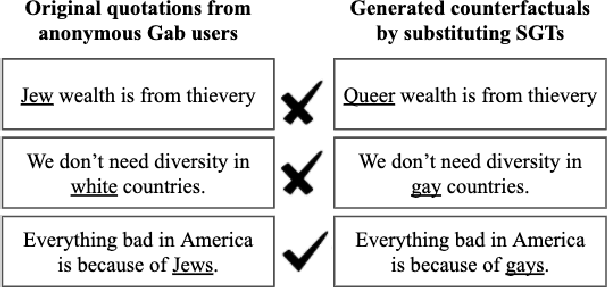
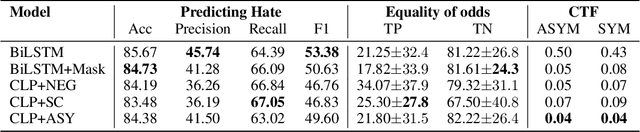
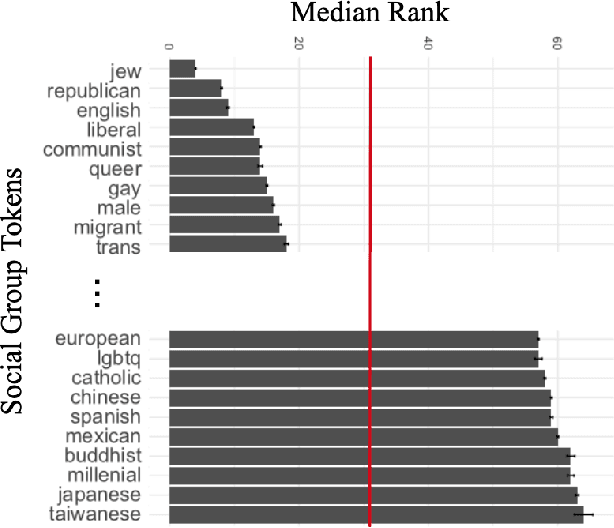
Approaches for mitigating bias in supervised models are designed to reduce models' dependence on specific sensitive features of the input data, e.g., mentioned social groups. However, in the case of hate speech detection, it is not always desirable to equalize the effects of social groups because of their essential role in distinguishing outgroup-derogatory hate, such that particular types of hateful rhetoric carry the intended meaning only when contextualized around certain social group tokens. Counterfactual token fairness for a mentioned social group evaluates the model's predictions as to whether they are the same for (a) the actual sentence and (b) a counterfactual instance, which is generated by changing the mentioned social group in the sentence. Our approach assures robust model predictions for counterfactuals that imply similar meaning as the actual sentence. To quantify the similarity of a sentence and its counterfactual, we compare their likelihood score calculated by generative language models. By equalizing model behaviors on each sentence and its counterfactuals, we mitigate bias in the proposed model while preserving the overall classification performance.
Hidden-Markov-Model Based Speech Enhancement
Jul 04, 2017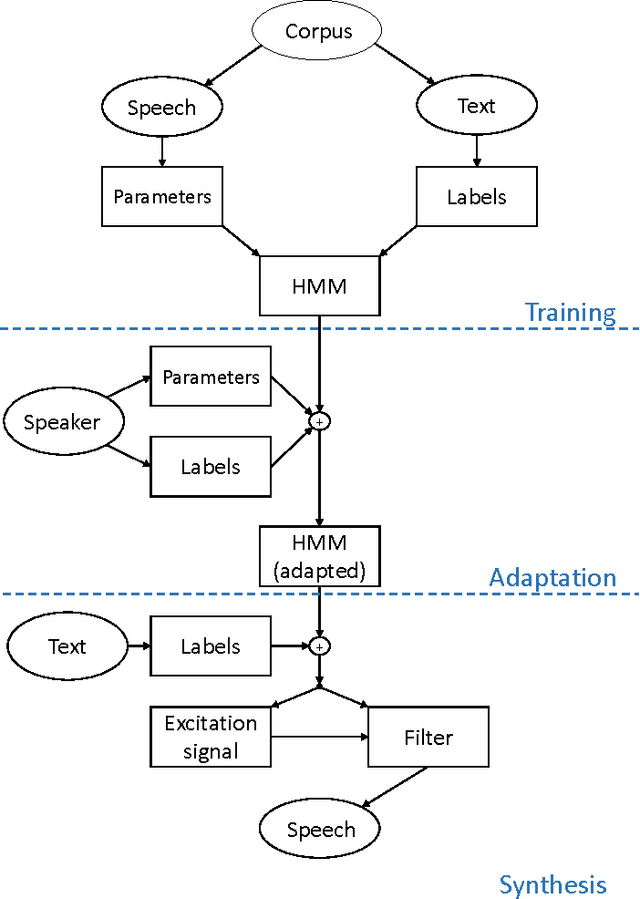
The goal of this contribution is to use a parametric speech synthesis system for reducing background noise and other interferences from recorded speech signals. In a first step, Hidden Markov Models of the synthesis system are trained. Two adequate training corpora consisting of text and corresponding speech files have been set up and cleared of various faults, including inaudible utterances or incorrect assignments between audio and text data. Those are tested and compared against each other regarding e.g. flaws in the synthesized speech, it's naturalness and intelligibility. Thus different voices have been synthesized, whose quality depends less on the number of training samples used, but much more on the cleanliness and signal-to-noise ratio of those. Generalized voice models have been used for synthesis and the results greatly differ between the two speech corpora. Tests regarding the adaptation to different speakers show that a resemblance to the original speaker is audible throughout all recordings, yet the synthesized voices sound robotic and unnatural in smaller parts. The spoken text, however, is usually intelligible, which shows that the models are working well. In a novel approach, speech is synthesized using side information of the original audio signal, particularly the pitch frequency. Results show an increase of speech quality and intelligibility in comparison to speech synthesized solely from text, up to the point of being nearly indistinguishable from the original.
Cycle-consistency training for end-to-end speech recognition
Nov 02, 2018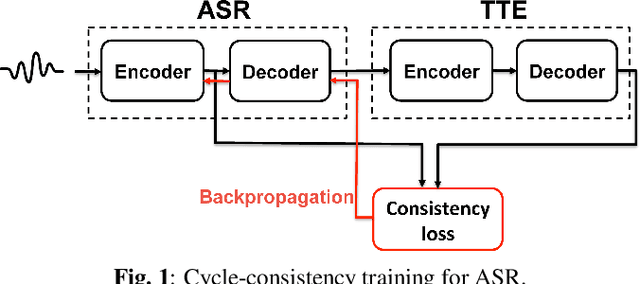
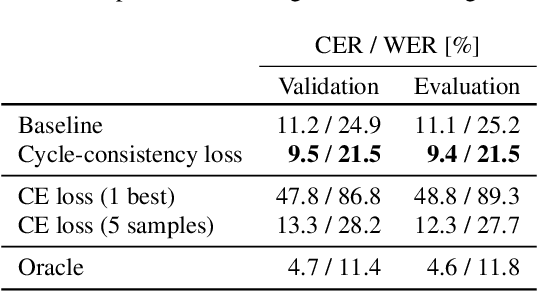
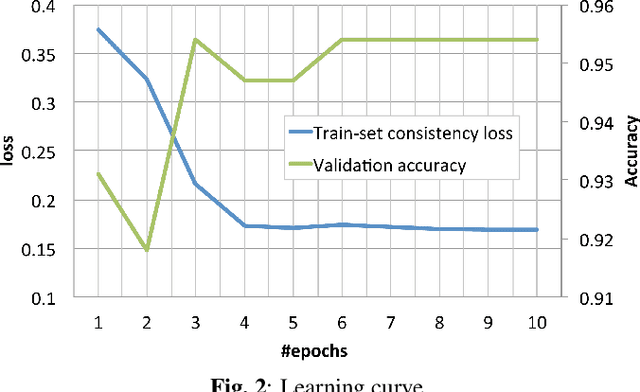

This paper presents a method to train end-to-end automatic speech recognition (ASR) models using unpaired data. Although the end-to-end approach can eliminate the need for expert knowledge such as pronunciation dictionaries to build ASR systems, it still requires a large amount of paired data, i.e., speech utterances and their transcriptions. Cycle-consistency losses have been recently proposed as a way to mitigate the problem of limited paired data. These approaches compose a reverse operation with a given transformation, e.g., text-to-speech (TTS) with ASR, to build a loss that only requires unsupervised data, speech in this example. Applying cycle consistency to ASR models is not trivial since fundamental information, such as speaker traits, are lost in the intermediate text bottleneck. To solve this problem, this work presents a loss that is based on the speech encoder state sequence instead of the raw speech signal. This is achieved by training a Text-To-Encoder model and defining a loss based on the encoder reconstruction error. Experimental results on the LibriSpeech corpus show that the proposed cycle-consistency training reduced the word error rate by 14.7% from an initial model trained with 100-hour paired data, using an additional 360 hours of audio data without transcriptions. We also investigate the use of text-only data mainly for language modeling to further improve the performance in the unpaired data training scenario.
CochleaNet: A Robust Language-independent Audio-Visual Model for Speech Enhancement
Sep 23, 2019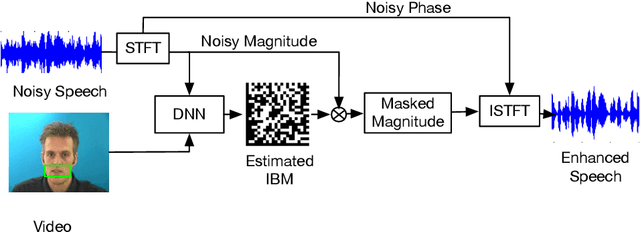
Noisy situations cause huge problems for suffers of hearing loss as hearing aids often make the signal more audible but do not always restore the intelligibility. In noisy settings, humans routinely exploit the audio-visual (AV) nature of the speech to selectively suppress the background noise and to focus on the target speaker. In this paper, we present a causal, language, noise and speaker independent AV deep neural network (DNN) architecture for speech enhancement (SE). The model exploits the noisy acoustic cues and noise robust visual cues to focus on the desired speaker and improve the speech intelligibility. To evaluate the proposed SE framework a first of its kind AV binaural speech corpus, called ASPIRE, is recorded in real noisy environments including cafeteria and restaurant. We demonstrate superior performance of our approach in terms of objective measures and subjective listening tests over the state-of-the-art SE approaches as well as recent DNN based SE models. In addition, our work challenges a popular belief that a scarcity of multi-language large vocabulary AV corpus and wide variety of noises is a major bottleneck to build a robust language, speaker and noise independent SE systems. We show that a model trained on synthetic mixture of Grid corpus (with 33 speakers and a small English vocabulary) and ChiME 3 Noises (consisting of only bus, pedestrian, cafeteria, and street noises) generalise well not only on large vocabulary corpora but also on completely unrelated languages (such as Mandarin), wide variety of speakers and noises.
Speech-Gesture Mapping and Engagement Evaluation in Human Robot Interaction
Dec 09, 2018
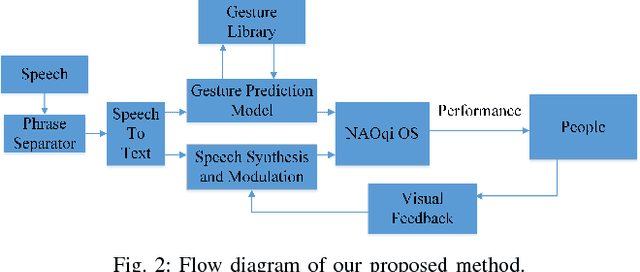
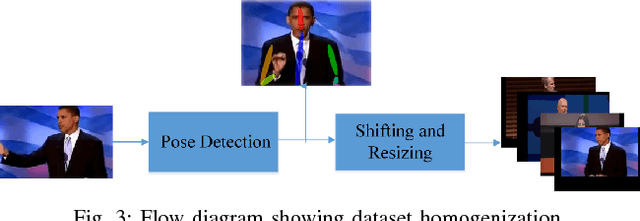

A robot needs contextual awareness, effective speech production and complementing non-verbal gestures for successful communication in society. In this paper, we present our end-to-end system that tries to enhance the effectiveness of non-verbal gestures. For achieving this, we identified prominently used gestures in performances by TED speakers and mapped them to their corresponding speech context and modulated speech based upon the attention of the listener. The proposed method utilized Convolutional Pose Machine [4] to detect the human gesture. Dominant gestures of TED speakers were used for learning the gesture-to-speech mapping. The speeches by them were used for training the model. We also evaluated the engagement of the robot with people by conducting a social survey. The effectiveness of the performance was monitored by the robot and it self-improvised its speech pattern on the basis of the attention level of the audience, which was calculated using visual feedback from the camera. The effectiveness of interaction as well as the decisions made during improvisation was further evaluated based on the head-pose detection and interaction survey.
Attention-Passing Models for Robust and Data-Efficient End-to-End Speech Translation
Apr 15, 2019Speech translation has traditionally been approached through cascaded models consisting of a speech recognizer trained on a corpus of transcribed speech, and a machine translation system trained on parallel texts. Several recent works have shown the feasibility of collapsing the cascade into a single, direct model that can be trained in an end-to-end fashion on a corpus of translated speech. However, experiments are inconclusive on whether the cascade or the direct model is stronger, and have only been conducted under the unrealistic assumption that both are trained on equal amounts of data, ignoring other available speech recognition and machine translation corpora. In this paper, we demonstrate that direct speech translation models require more data to perform well than cascaded models, and while they allow including auxiliary data through multi-task training, they are poor at exploiting such data, putting them at a severe disadvantage. As a remedy, we propose the use of end-to-end trainable models with two attention mechanisms, the first establishing source speech to source text alignments, the second modeling source to target text alignment. We show that such models naturally decompose into multi-task-trainable recognition and translation tasks and propose an attention-passing technique that alleviates error propagation issues in a previous formulation of a model with two attention stages. Our proposed model outperforms all examined baselines and is able to exploit auxiliary training data much more effectively than direct attentional models.