 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
DeLoRes: Decorrelating Latent Spaces for Low-Resource Audio Representation Learning
Apr 13, 2022
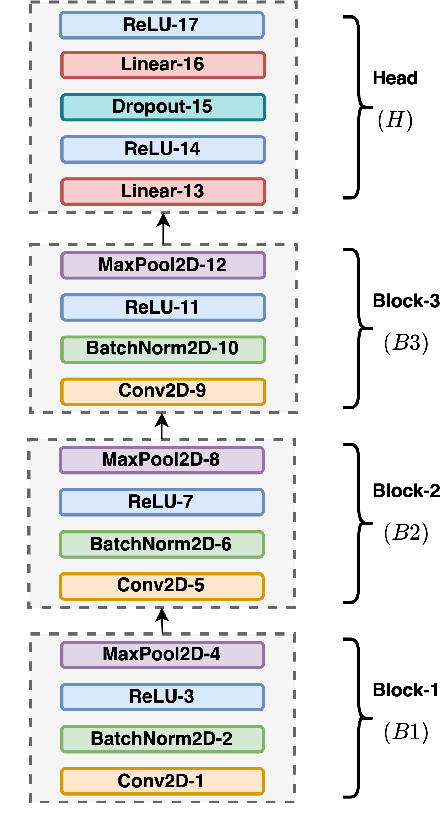
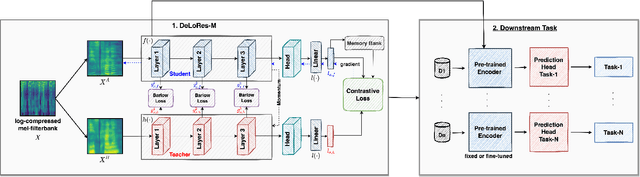
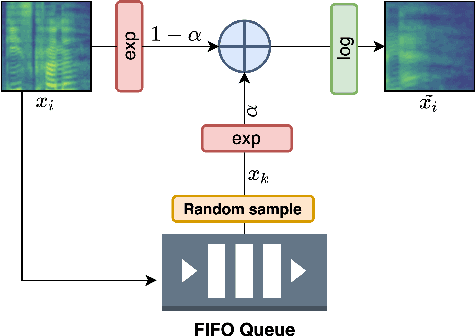
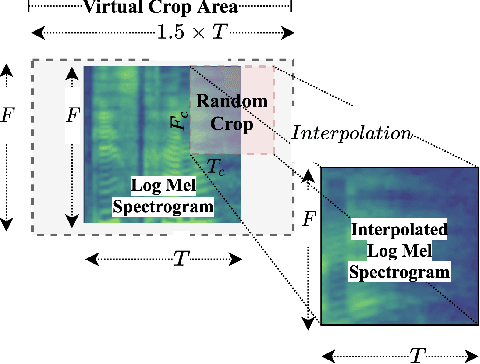
Inspired by the recent progress in self-supervised learning for computer vision, in this paper, through the DeLoRes learning framework, we introduce two new general-purpose audio representation learning approaches, the DeLoRes-S and DeLoRes-M. Our main objective is to make our network learn representations in a resource-constrained setting (both data and compute), that can generalize well across a diverse set of downstream tasks. Inspired from the Barlow Twins objective function, we propose to learn embeddings that are invariant to distortions of an input audio sample, while making sure that they contain non-redundant information about the sample. To achieve this, we measure the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of an audio segment sampled from an audio file and make it as close to the identity matrix as possible. We call this the DeLoRes learning framework, which we employ in different fashions with the DeLoRes-S and DeLoRes-M. We use a combination of a small subset of the large-scale AudioSet dataset and FSD50K for self-supervised learning and are able to learn with less than half the parameters compared to state-of-the-art algorithms. For evaluation, we transfer these learned representations to 11 downstream classification tasks, including speech, music, and animal sounds, and achieve state-of-the-art results on 7 out of 11 tasks on linear evaluation with DeLoRes-M and show competitive results with DeLoRes-S, even when pre-trained using only a fraction of the total data when compared to prior art. Our transfer learning evaluation setup also shows extremely competitive results for both DeLoRes-S and DeLoRes-M, with DeLoRes-M achieving state-of-the-art in 4 tasks.
WaveFuzz: A Clean-Label Poisoning Attack to Protect Your Voice
Mar 25, 2022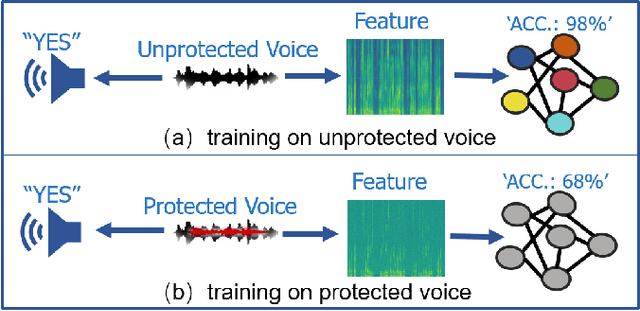
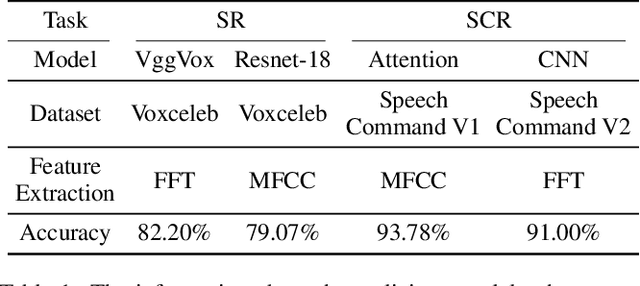
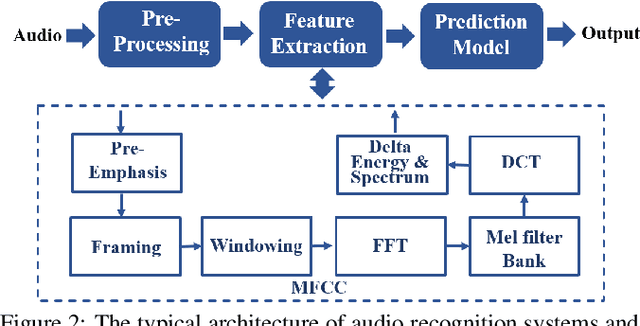
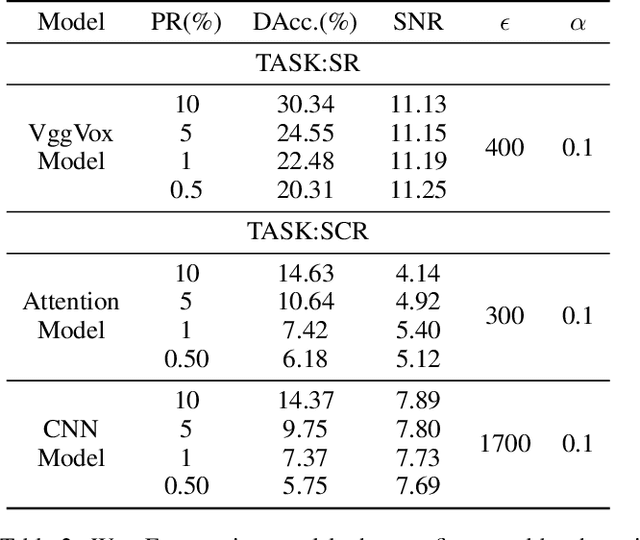
People are not always receptive to their voice data being collected and misused. Training the audio intelligence systems needs these data to build useful features, but the cost for getting permissions or purchasing data is very high, which inevitably encourages hackers to collect these voice data without people's awareness. To discourage the hackers from proactively collecting people's voice data, we are the first to propose a clean-label poisoning attack, called WaveFuzz, which can prevent intelligence audio models from building useful features from protected (poisoned) voice data but still preserve the semantic information to the humans. Specifically, WaveFuzz perturbs the voice data to cause Mel Frequency Cepstral Coefficients (MFCC) (typical representations of audio signals) to generate the poisoned frequency features. These poisoned features are then fed to audio prediction models, which degrades the performance of audio intelligence systems. Empirically, we show the efficacy of WaveFuzz by attacking two representative types of intelligent audio systems, i.e., speaker recognition system (SR) and speech command recognition system (SCR). For example, the accuracies of models are declined by $19.78\%$ when only $10\%$ of the poisoned voice data is to fine-tune models, and the accuracies of models declined by $6.07\%$ when only $10\%$ of the training voice data is poisoned. Consequently, WaveFuzz is an effective technique that enables people to fight back to protect their own voice data, which sheds new light on ameliorating privacy issues.
End-to-end Microphone Permutation and Number Invariant Multi-channel Speech Separation
Oct 30, 2019
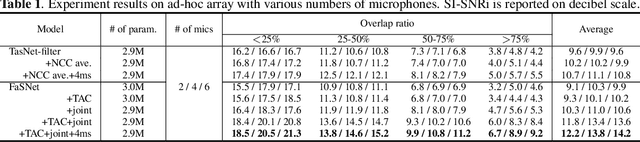
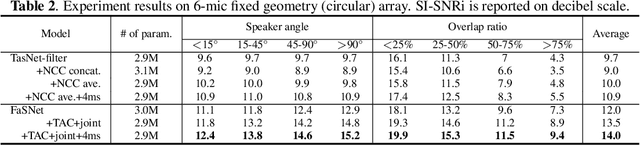
An important problem in ad-hoc microphone speech separation is how to guarantee the robustness of a system with respect to the locations and numbers of microphones. The former requires the system to be invariant to different indexing of the microphones with the same locations, while the latter requires the system to be able to process inputs with varying dimensions. Conventional optimization-based beamforming techniques satisfy these requirements by definition, while for deep learning-based end-to-end systems those constraints are not fully addressed. In this paper, we propose transform-average-concatenate (TAC), a simple design paradigm for channel permutation and number invariant multi-channel speech separation. Based on the filter-and-sum network (FaSNet), a recently proposed end-to-end time-domain beamforming system, we show how TAC significantly improves the separation performance across various numbers of microphones in noisy reverberant separation tasks with ad-hoc arrays. Moreover, we show that TAC also significantly improves the separation performance with fixed geometry array configuration, further proving the effectiveness of the proposed paradigm in the general problem of multi-microphone speech separation.
TransCouplet:Transformer based Chinese Couplet Generation
Dec 03, 2021
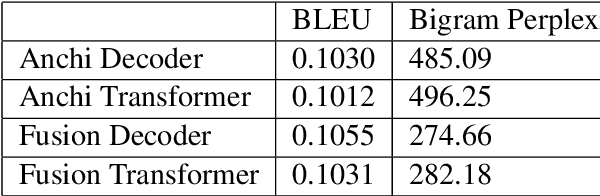
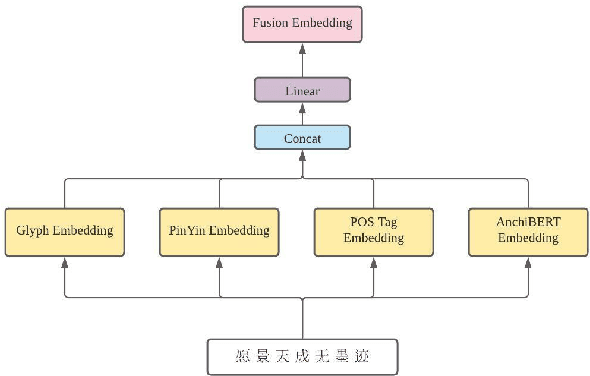
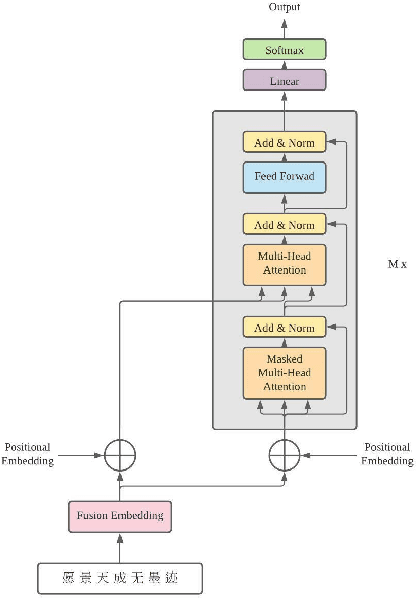
Chinese couplet is a special form of poetry composed of complex syntax with ancient Chinese language. Due to the complexity of semantic and grammatical rules, creation of a suitable couplet is a formidable challenge. This paper presents a transformer-based sequence-to-sequence couplet generation model. With the utilization of AnchiBERT, the model is able to capture ancient Chinese language understanding. Moreover, we evaluate the Glyph, PinYin and Part-of-Speech tagging on the couplet grammatical rules to further improve the model.
Towards Visually Grounded Sub-Word Speech Unit Discovery
Feb 21, 2019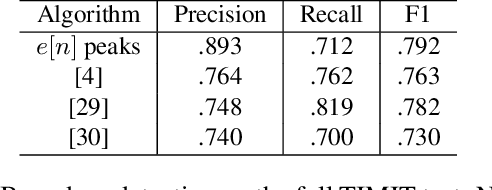
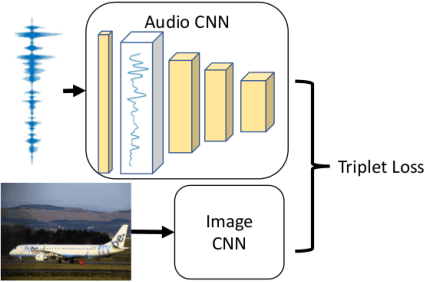
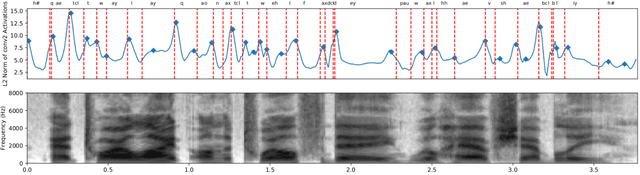
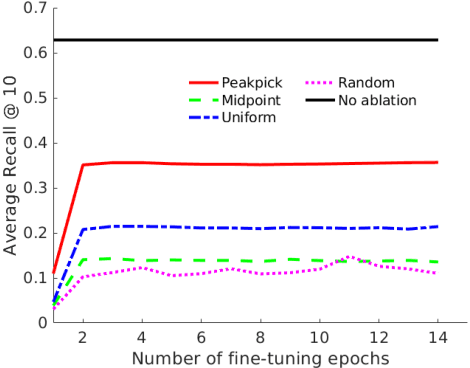
In this paper, we investigate the manner in which interpretable sub-word speech units emerge within a convolutional neural network model trained to associate raw speech waveforms with semantically related natural image scenes. We show how diphone boundaries can be superficially extracted from the activation patterns of intermediate layers of the model, suggesting that the model may be leveraging these events for the purpose of word recognition. We present a series of experiments investigating the information encoded by these events.
On Laughter and Speech-Laugh, Based on Observations of Child-Robot Interaction
Aug 30, 2019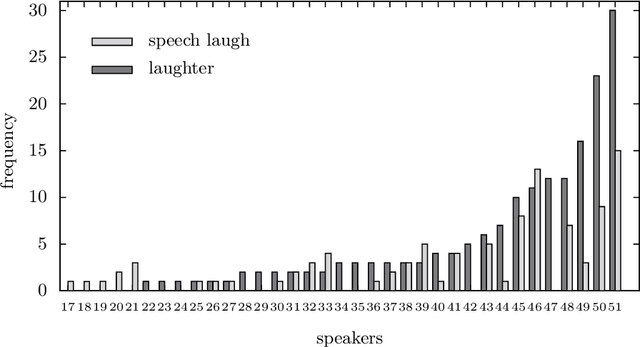
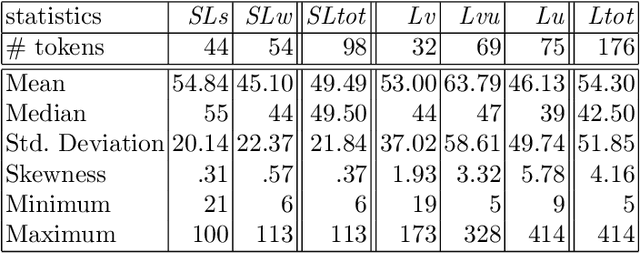
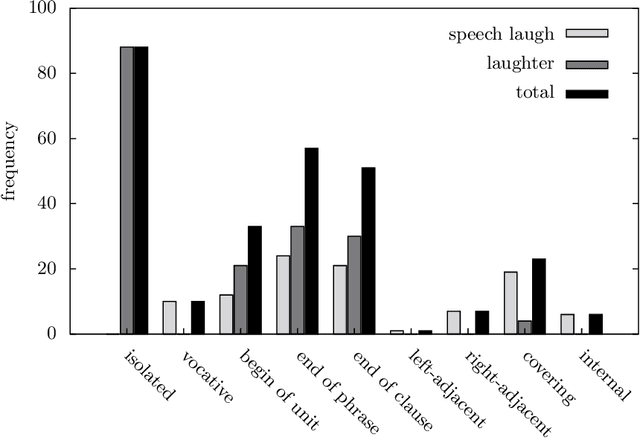
In this article, we study laughter found in child-robot interaction where it had not been prompted intentionally. Different types of laughter and speech-laugh are annotated and processed. In a descriptive part, we report on the position of laughter and speech-laugh in syntax and dialogue structure, and on communicative functions. In a second part, we report on automatic classification performance and on acoustic characteristics, based on extensive feature selection procedures.
LaughNet: synthesizing laughter utterances from waveform silhouettes and a single laughter example
Oct 11, 2021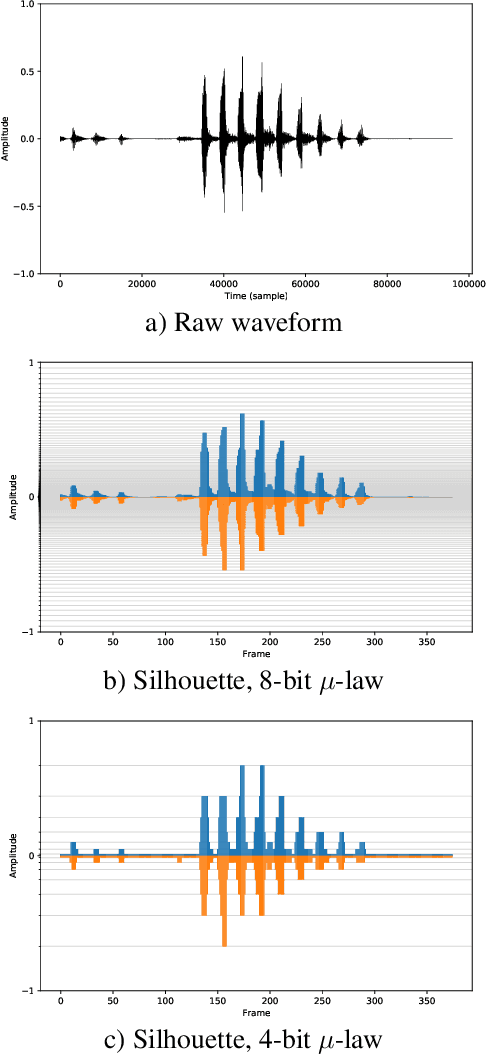
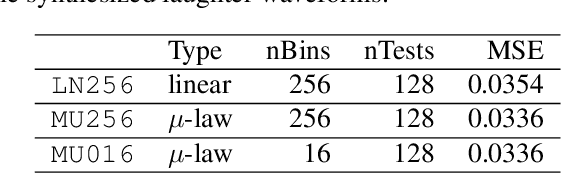
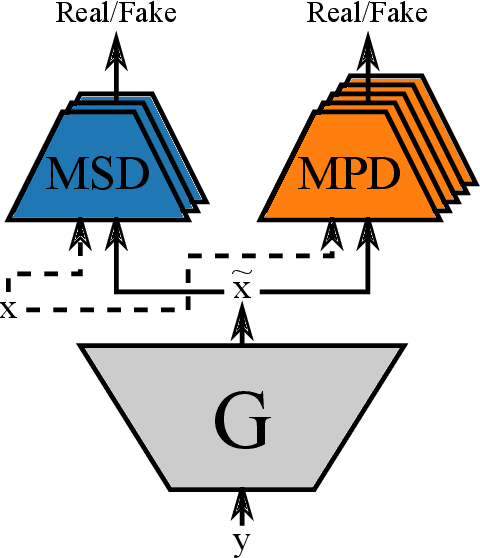
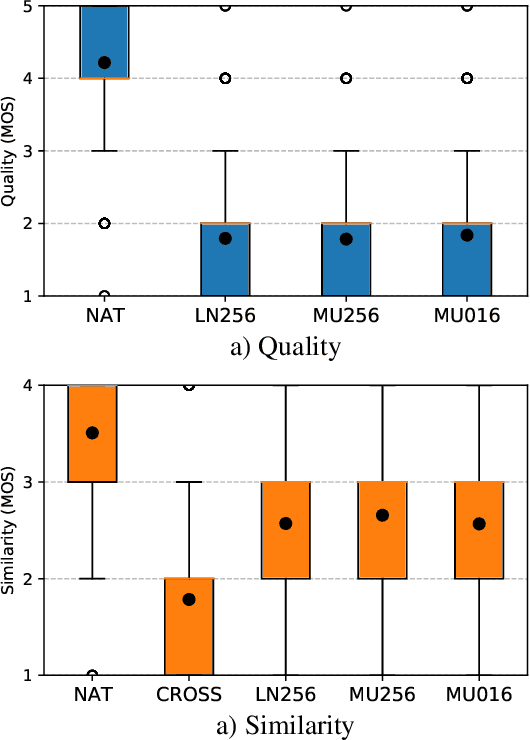
Emotional and controllable speech synthesis is a topic that has received much attention. However, most studies focused on improving the expressiveness and controllability in the context of linguistic content, even though natural verbal human communication is inseparable from spontaneous non-speech expressions such as laughter, crying, or grunting. We propose a model called LaughNet for synthesizing laughter by using waveform silhouettes as inputs. The motivation is not simply synthesizing new laughter utterances but testing a novel synthesis-control paradigm that uses an abstract representation of the waveform. We conducted basic listening test experiments, and the results showed that LaughNet can synthesize laughter utterances with moderate quality and retain the characteristics of the training example. More importantly, the generated waveforms have shapes similar to the input silhouettes. For future work, we will test the same method on other types of human nonverbal expressions and integrate it into more elaborated synthesis systems.
Low-Resource Speech-to-Text Translation
Jun 18, 2018
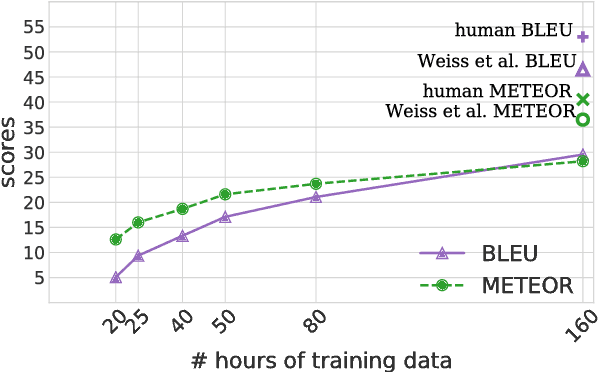
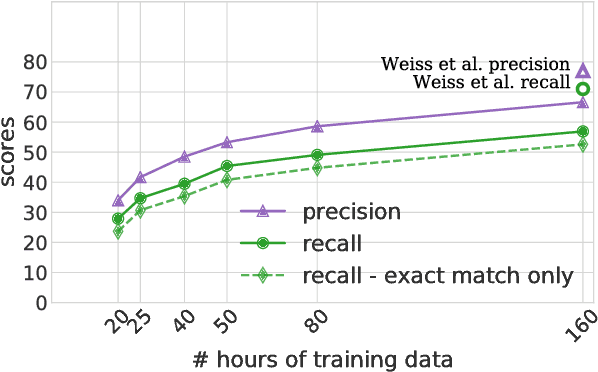

Speech-to-text translation has many potential applications for low-resource languages, but the typical approach of cascading speech recognition with machine translation is often impossible, since the transcripts needed to train a speech recognizer are usually not available for low-resource languages. Recent work has found that neural encoder-decoder models can learn to directly translate foreign speech in high-resource scenarios, without the need for intermediate transcription. We investigate whether this approach also works in settings where both data and computation are limited. To make the approach efficient, we make several architectural changes, including a change from character-level to word-level decoding. We find that this choice yields crucial speed improvements that allow us to train with fewer computational resources, yet still performs well on frequent words. We explore models trained on between 20 and 160 hours of data, and find that although models trained on less data have considerably lower BLEU scores, they can still predict words with relatively high precision and recall---around 50% for a model trained on 50 hours of data, versus around 60% for the full 160 hour model. Thus, they may still be useful for some low-resource scenarios.
CochleaNet: A Robust Language-independent Audio-Visual Model for Speech Enhancement
Sep 23, 2019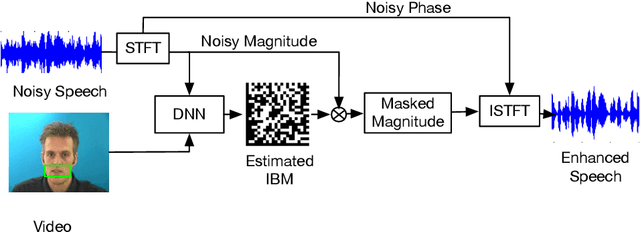
Noisy situations cause huge problems for suffers of hearing loss as hearing aids often make the signal more audible but do not always restore the intelligibility. In noisy settings, humans routinely exploit the audio-visual (AV) nature of the speech to selectively suppress the background noise and to focus on the target speaker. In this paper, we present a causal, language, noise and speaker independent AV deep neural network (DNN) architecture for speech enhancement (SE). The model exploits the noisy acoustic cues and noise robust visual cues to focus on the desired speaker and improve the speech intelligibility. To evaluate the proposed SE framework a first of its kind AV binaural speech corpus, called ASPIRE, is recorded in real noisy environments including cafeteria and restaurant. We demonstrate superior performance of our approach in terms of objective measures and subjective listening tests over the state-of-the-art SE approaches as well as recent DNN based SE models. In addition, our work challenges a popular belief that a scarcity of multi-language large vocabulary AV corpus and wide variety of noises is a major bottleneck to build a robust language, speaker and noise independent SE systems. We show that a model trained on synthetic mixture of Grid corpus (with 33 speakers and a small English vocabulary) and ChiME 3 Noises (consisting of only bus, pedestrian, cafeteria, and street noises) generalise well not only on large vocabulary corpora but also on completely unrelated languages (such as Mandarin), wide variety of speakers and noises.
Top-Down Influence? Predicting CEO Personality and Risk Impact from Speech Transcripts
Jan 19, 2022
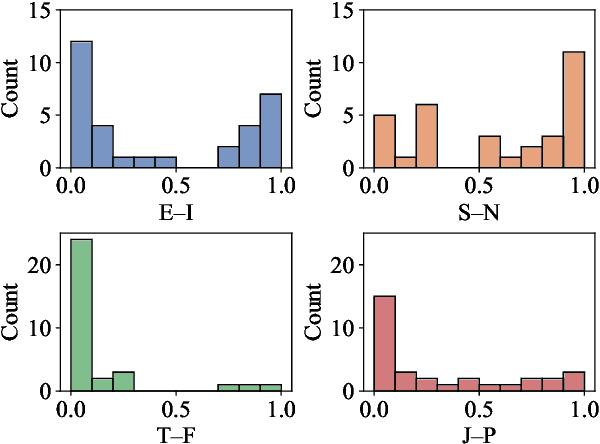
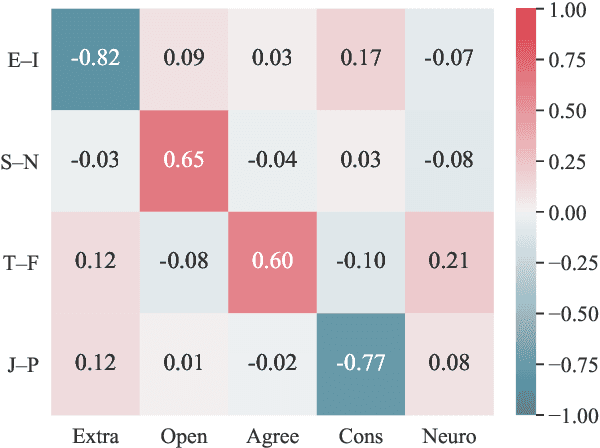
How much does a CEO's personality impact the performance of their company? Management theory posits a great influence, but it is difficult to show empirically -- there is a lack of publicly available self-reported personality data of top managers. Instead, we propose a text-based personality regressor using crowd-sourced Myers--Briggs Type Indicator (MBTI) assessments. The ratings have a high internal and external validity and can be predicted with moderate to strong correlations for three out of four dimensions. Providing evidence for the upper echelons theory, we demonstrate that the predicted CEO personalities have explanatory power of financial risk.