 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Channel-Attention Dense U-Net for Multichannel Speech Enhancement
Jan 30, 2020
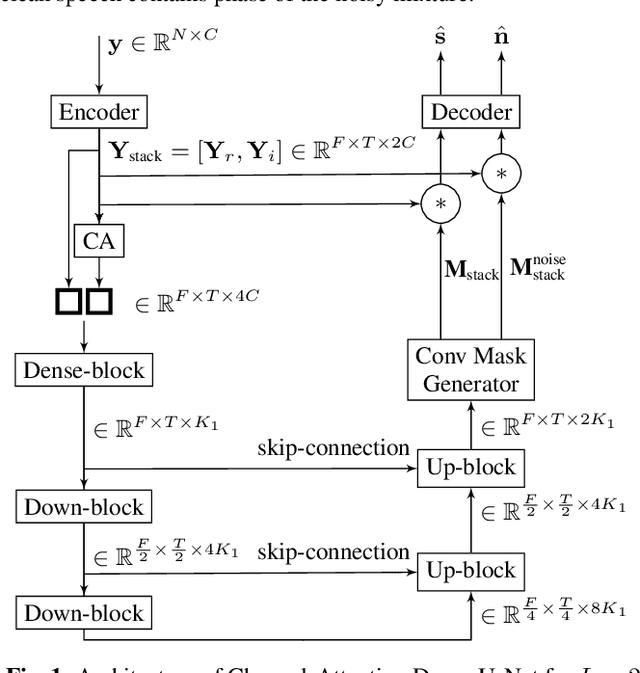
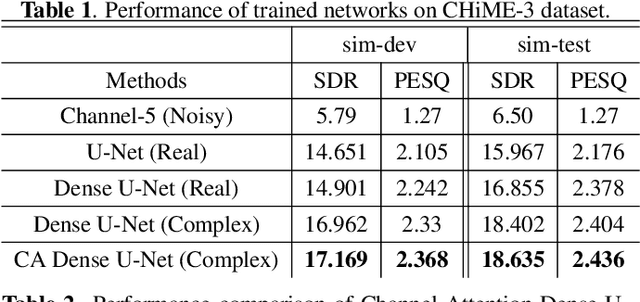
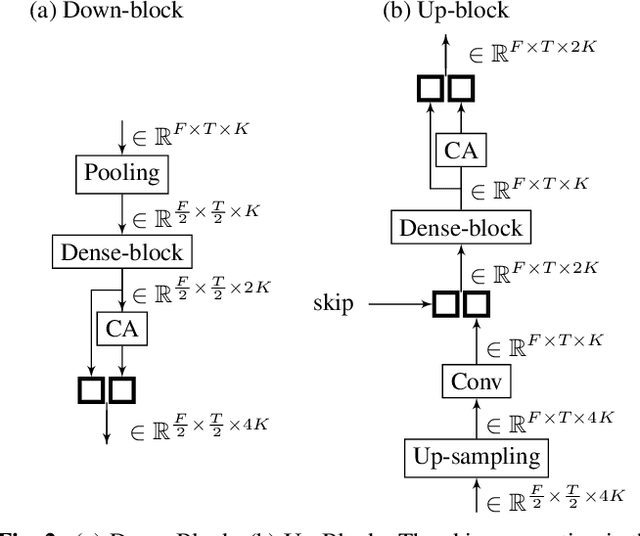
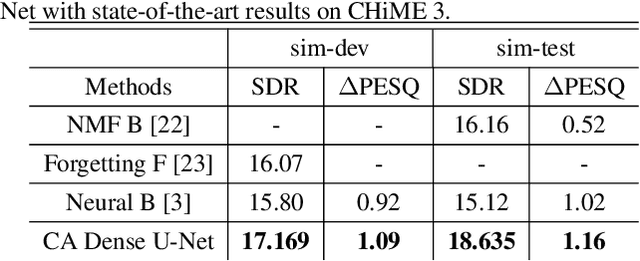
Supervised deep learning has gained significant attention for speech enhancement recently. The state-of-the-art deep learning methods perform the task by learning a ratio/binary mask that is applied to the mixture in the time-frequency domain to produce the clean speech. Despite the great performance in the single-channel setting, these frameworks lag in performance in the multichannel setting as the majority of these methods a) fail to exploit the available spatial information fully, and b) still treat the deep architecture as a black box which may not be well-suited for multichannel audio processing. This paper addresses these drawbacks, a) by utilizing complex ratio masking instead of masking on the magnitude of the spectrogram, and more importantly, b) by introducing a channel-attention mechanism inside the deep architecture to mimic beamforming. We propose Channel-Attention Dense U-Net, in which we apply the channel-attention unit recursively on feature maps at every layer of the network, enabling the network to perform non-linear beamforming. We demonstrate the superior performance of the network against the state-of-the-art approaches on the CHiME-3 dataset.
On using 2D sequence-to-sequence models for speech recognition
Nov 20, 2019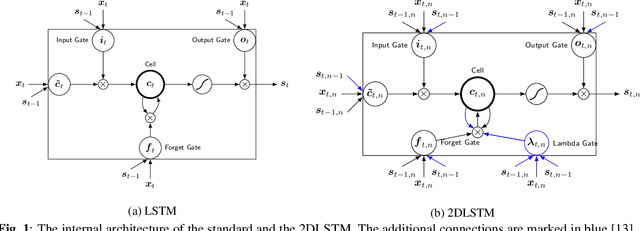

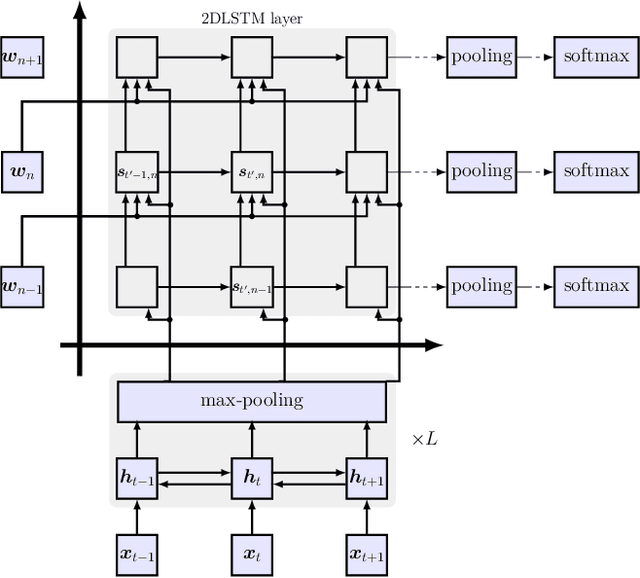
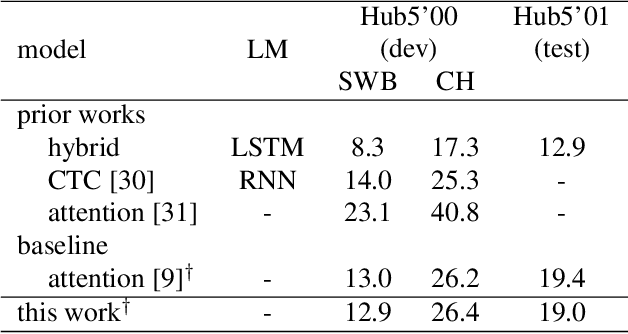
Attention-based sequence-to-sequence models have shown promising results in automatic speech recognition. Using these architectures, one-dimensional input and output sequences are related by an attention approach, thereby replacing more explicit alignment processes, like in classical HMM-based modeling. In contrast, here we apply a novel two-dimensional long short-term memory (2DLSTM) architecture to directly model the input/output relation between audio/feature vector sequences and word sequences. The proposed model is an alternative model such that instead of using any type of attention components, we apply a 2DLSTM layer to assimilate the context from both input observations and output transcriptions. The experimental evaluation on the Switchboard 300h automatic speech recognition task shows word error rates for the 2DLSTM model that are competitive to end-to-end attention-based model.
A unified sequence-to-sequence front-end model for Mandarin text-to-speech synthesis
Nov 11, 2019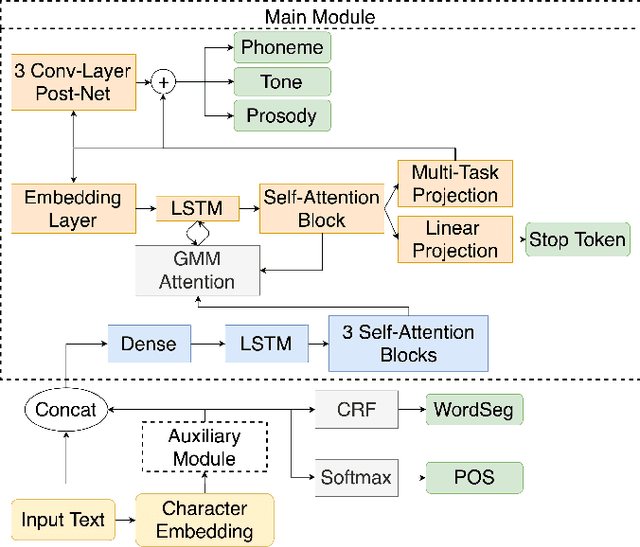

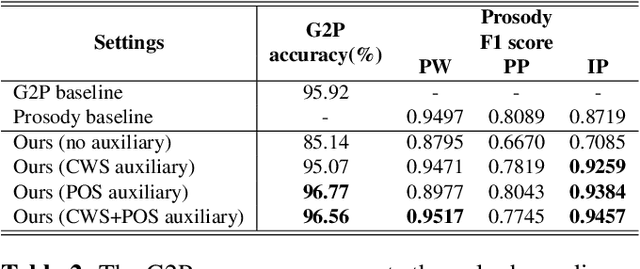
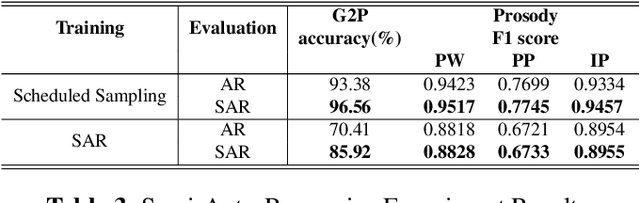
In Mandarin text-to-speech (TTS) system, the front-end text processing module significantly influences the intelligibility and naturalness of synthesized speech. Building a typical pipeline-based front-end which consists of multiple individual components requires extensive efforts. In this paper, we proposed a unified sequence-to-sequence front-end model for Mandarin TTS that converts raw texts to linguistic features directly. Compared to the pipeline-based front-end, our unified front-end can achieve comparable performance in polyphone disambiguation and prosody word prediction, and improve intonation phrase prediction by 0.0738 in F1 score. We also implemented the unified front-end with Tacotron and WaveRNN to build a Mandarin TTS system. The synthesized speech by that got a comparable MOS (4.38) with the pipeline-based front-end (4.37) and close to human recordings (4.49).
Can Social Robots Effectively Elicit Curiosity in STEM Topics from K-1 Students During Oral Assessments?
Feb 19, 2022

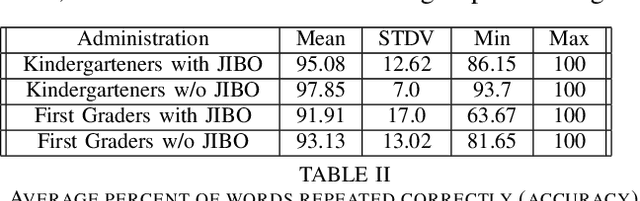

This paper presents the results of a pilot study that introduces social robots into kindergarten and first-grade classroom tasks. This study aims to understand 1) how effective social robots are in administering educational activities and assessments, and 2) if these interactions with social robots can serve as a gateway into learning about robotics and STEM for young children. We administered a commonly-used assessment (GFTA3) of speech production using a social robot and compared the quality of recorded responses to those obtained with a human assessor. In a comparison done between 40 children, we found no significant differences in the student responses between the two conditions over the three metrics used: word repetition accuracy, number of times additional help was needed, and similarity of prosody to the assessor. We also found that interactions with the robot were successfully able to stimulate curiosity in robotics, and therefore STEM, from a large number of the 164 student participants.
* 6 pages, 2 figures
Visualization and Interpretation of Latent Spaces for Controlling Expressive Speech Synthesis through Audio Analysis
Mar 27, 2019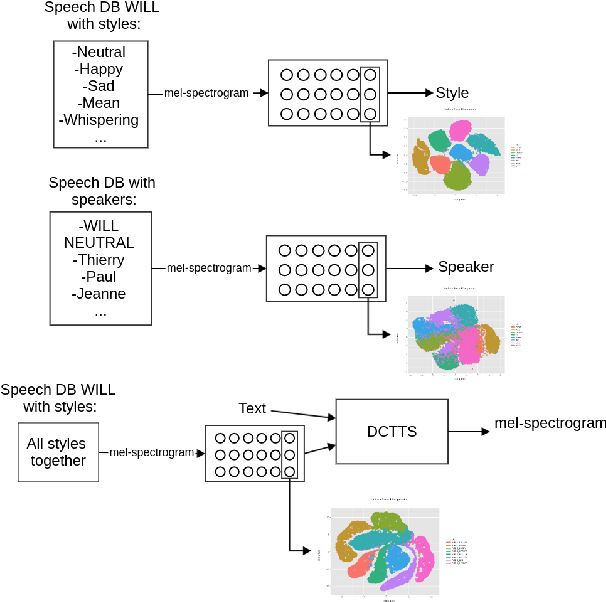
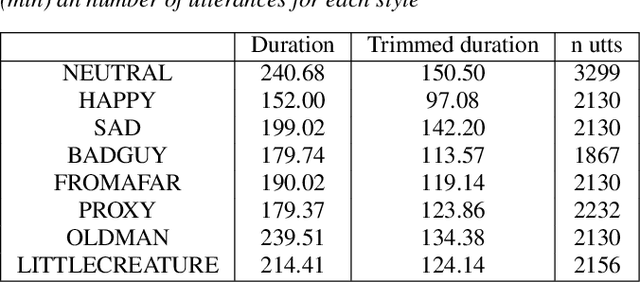
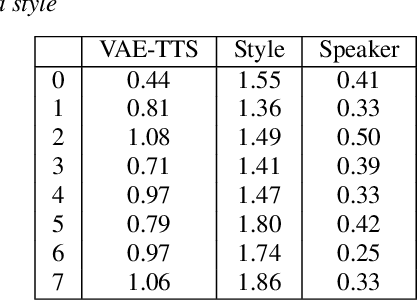
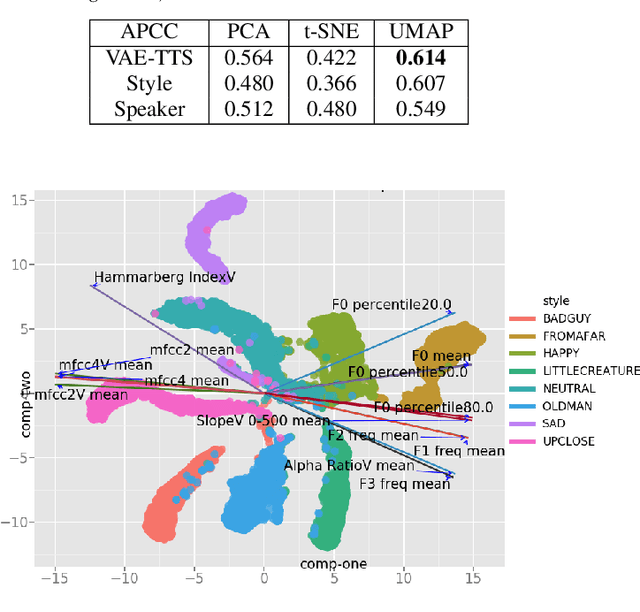
The field of Text-to-Speech has experienced huge improvements last years benefiting from deep learning techniques. Producing realistic speech becomes possible now. As a consequence, the research on the control of the expressiveness, allowing to generate speech in different styles or manners, has attracted increasing attention lately. Systems able to control style have been developed and show impressive results. However the control parameters often consist of latent variables and remain complex to interpret. In this paper, we analyze and compare different latent spaces and obtain an interpretation of their influence on expressive speech. This will enable the possibility to build controllable speech synthesis systems with an understandable behaviour.
Dialog-context aware end-to-end speech recognition
Aug 07, 2018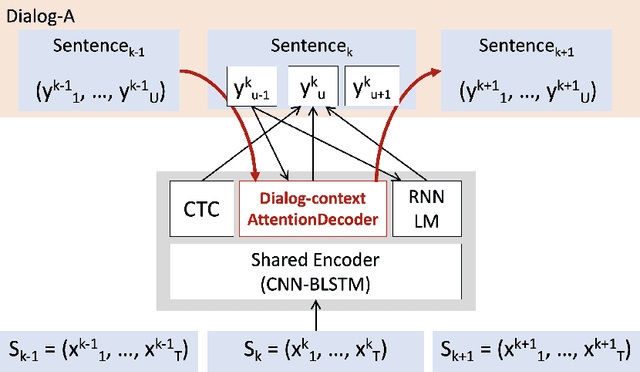


Existing speech recognition systems are typically built at the sentence level, although it is known that dialog context, e.g. higher-level knowledge that spans across sentences or speakers, can help the processing of long conversations. The recent progress in end-to-end speech recognition systems promises to integrate all available information (e.g. acoustic, language resources) into a single model, which is then jointly optimized. It seems natural that such dialog context information should thus also be integrated into the end-to-end models to improve further recognition accuracy. In this work, we present a dialog-context aware speech recognition model, which explicitly uses context information beyond sentence-level information, in an end-to-end fashion. Our dialog-context model captures a history of sentence-level context so that the whole system can be trained with dialog-context information in an end-to-end manner. We evaluate our proposed approach on the Switchboard conversational speech corpus and show that our system outperforms a comparable sentence-level end-to-end speech recognition system.
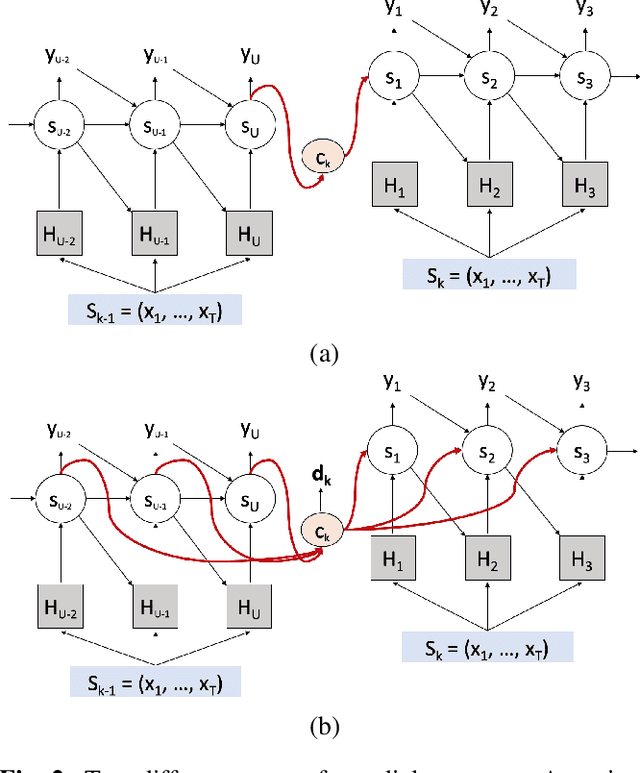
Guided Training: A Simple Method for Single-channel Speaker Separation
Mar 26, 2021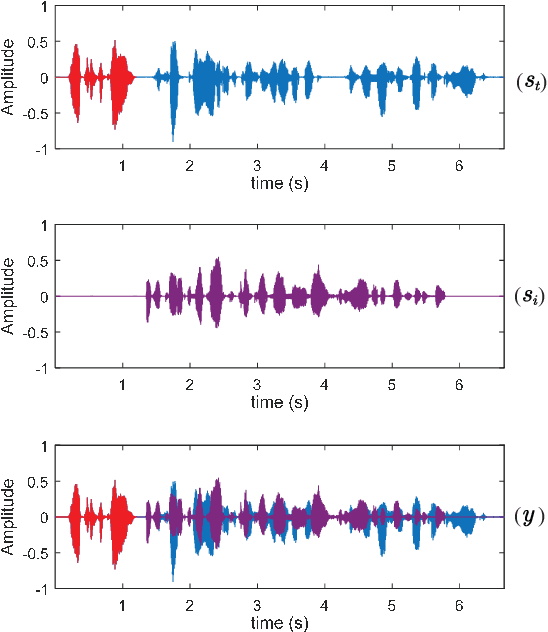
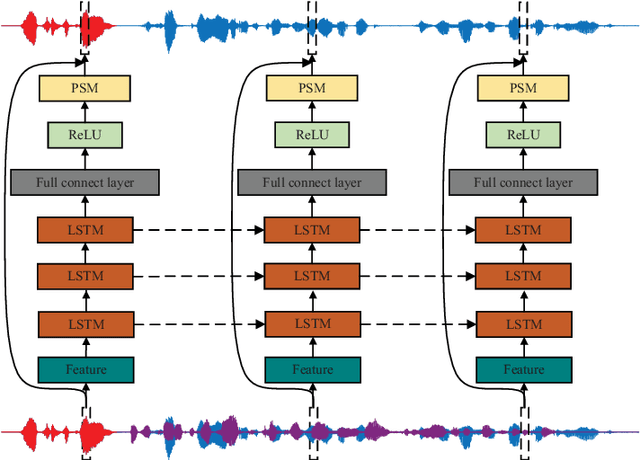
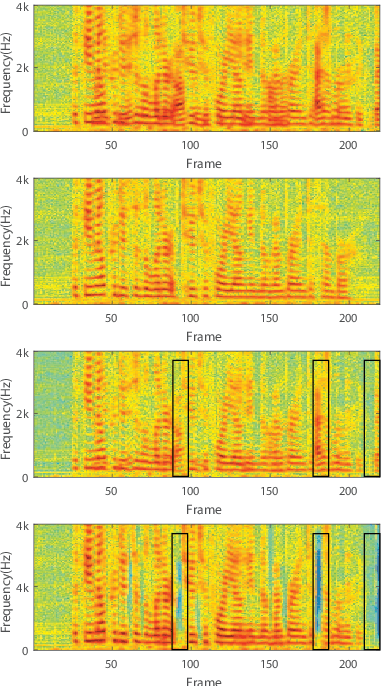
Deep learning has shown a great potential for speech separation, especially for speech and non-speech separation. However, it encounters permutation problem for multi-speaker separation where both target and interference are speech. Permutation Invariant training (PIT) was proposed to solve this problem by permuting the order of the multiple speakers. Another way is to use an anchor speech, a short speech of the target speaker, to model the speaker identity. In this paper, we propose a simple strategy to train a long short-term memory (LSTM) model to solve the permutation problem in speaker separation. Specifically, we insert a short speech of target speaker at the beginning of a mixture as guide information. So, the first appearing speaker is defined as the target. Due to the powerful capability on sequence modeling, LSTM can use its memory cells to track and separate target speech from interfering speech. Experimental results show that the proposed training strategy is effective for speaker separation.
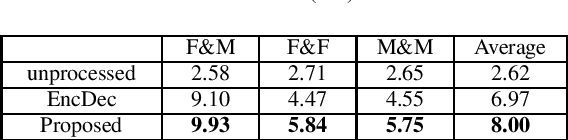
Machine Learning for Stuttering Identification: Review, Challenges & Future Directions
Jul 12, 2021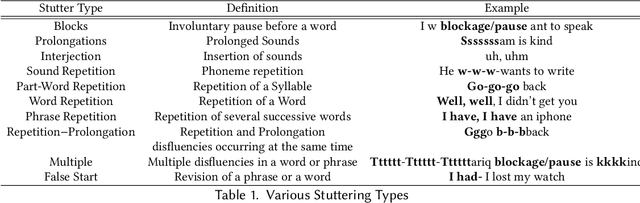
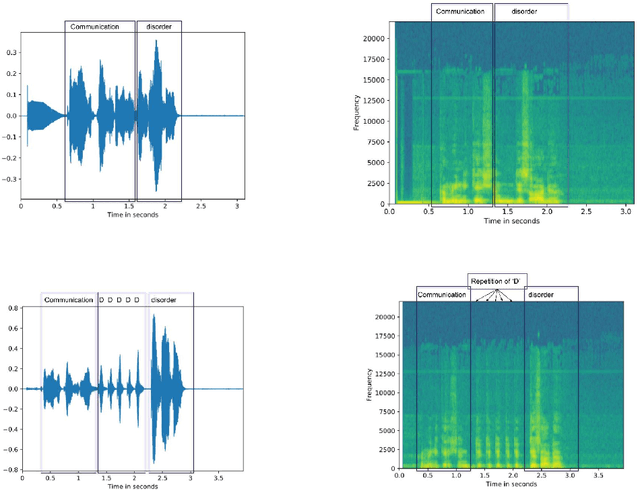
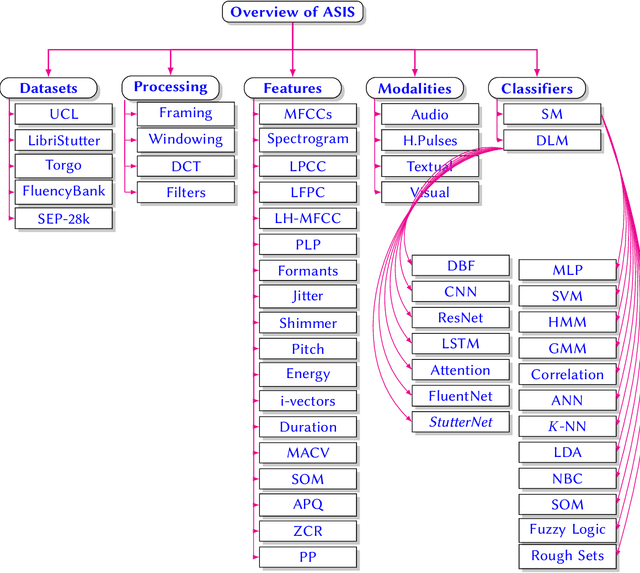
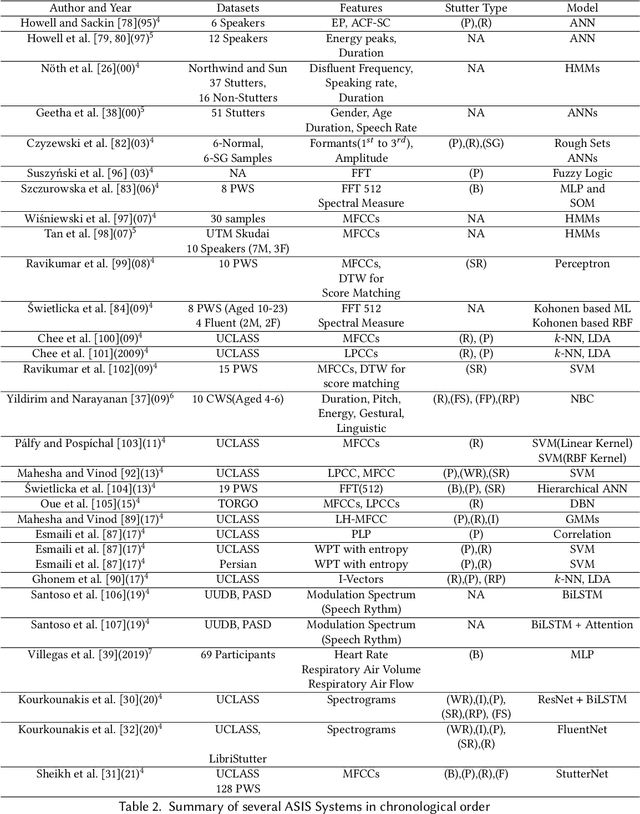
Stuttering is a speech disorder during which the flow of speech is interrupted by involuntary pauses and repetition of sounds. Stuttering identification is an interesting interdisciplinary domain research problem which involves pathology, psychology, acoustics, and signal processing that makes it hard and complicated to detect. Recent developments in machine and deep learning have dramatically revolutionized speech domain, however minimal attention has been given to stuttering identification. This work fills the gap by trying to bring researchers together from interdisciplinary fields. In this paper, we review comprehensively acoustic features, statistical and deep learning based stuttering/disfluency classification methods. We also present several challenges and possible future directions.
Attentional Speech Recognition Models Misbehave on Out-of-domain Utterances
Feb 12, 2020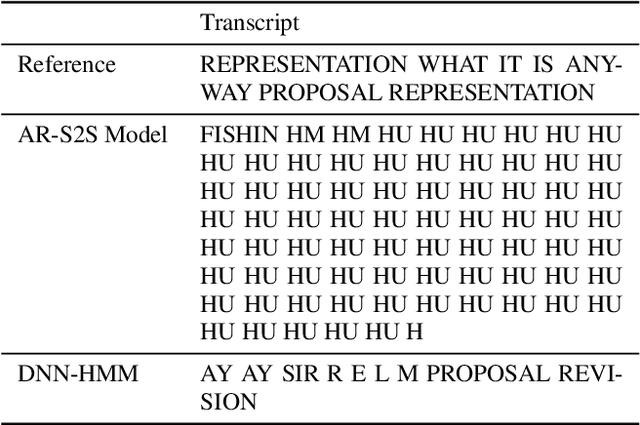
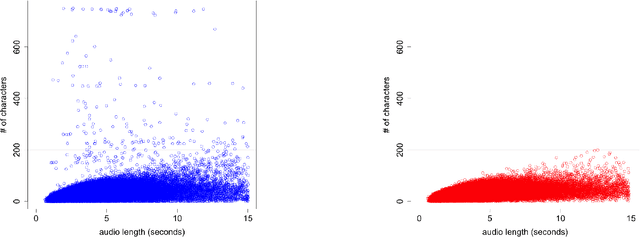
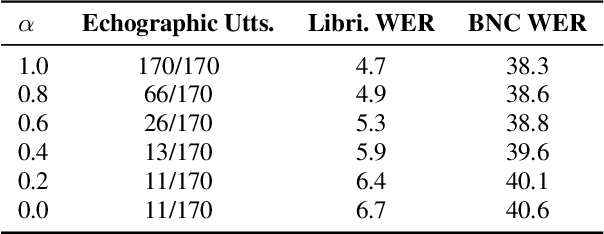
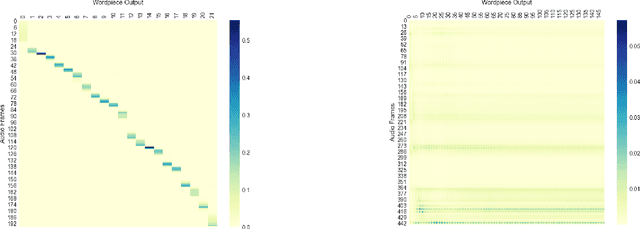
We discuss the problem of echographic transcription in autoregressive sequence-to-sequence attentional architectures for automatic speech recognition, where a model produces very long sequences of repetitive outputs when presented with out-of-domain utterances. We decode audio from the British National Corpus with an attentional encoder-decoder model trained solely on the LibriSpeech corpus. We observe that there are many 5-second recordings that produce more than 500 characters of decoding output (i.e. more than 100 characters per second). A frame-synchronous hybrid (DNN-HMM) model trained on the same data does not produce these unusually long transcripts. These decoding issues are reproducible in a speech transformer model from ESPnet, and to a lesser extent in a self-attention CTC model, suggesting that these issues are intrinsic to the use of the attention mechanism. We create a separate length prediction model to predict the correct number of wordpieces in the output, which allows us to identify and truncate problematic decoding results without increasing word error rates on the LibriSpeech task.
Cross Lingual Speech Emotion Recognition: Urdu vs. Western Languages
Dec 15, 2018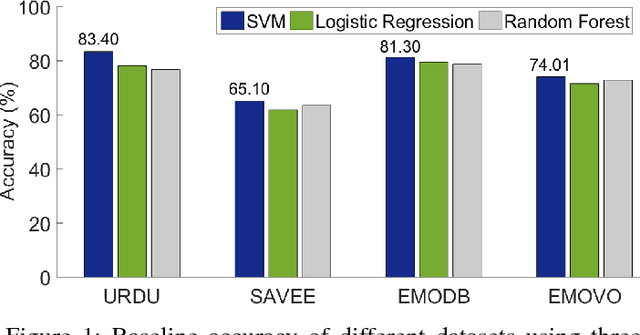
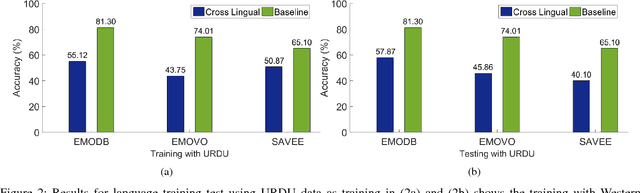
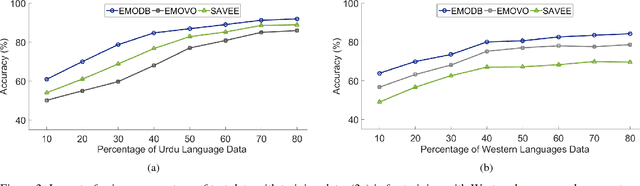
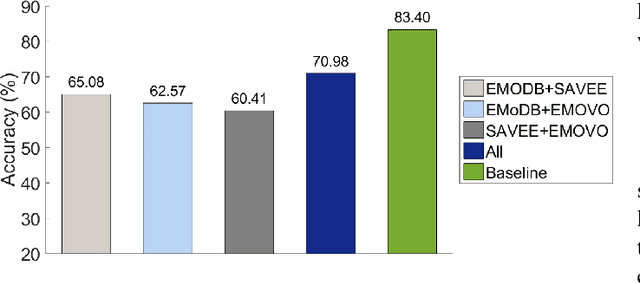
Cross-lingual speech emotion recognition is an important task for practical applications. The performance of automatic speech emotion recognition systems degrades in cross-corpus scenarios, particularly in scenarios involving multiple languages or a previously unseen language such as Urdu for which limited or no data is available. In this study, we investigate the problem of cross-lingual emotion recognition for Urdu language and contribute URDU---the first ever spontaneous Urdu-language speech emotion database. Evaluations are performed using three different Western languages against Urdu and experimental results on different possible scenarios suggest various interesting aspects for designing more adaptive emotion recognition system for such limited languages. In results, selecting training instances of multiple languages can deliver comparable results to baseline and augmentation a fraction of testing language data while training can help to boost accuracy for speech emotion recognition. URDU data is publicly available for further research.