 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Machine Speech Chain with One-shot Speaker Adaptation
Mar 28, 2018
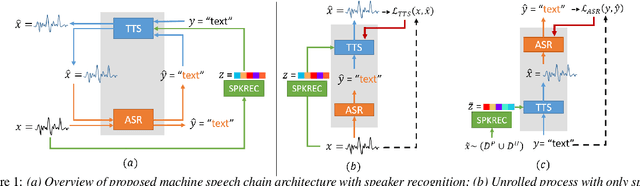
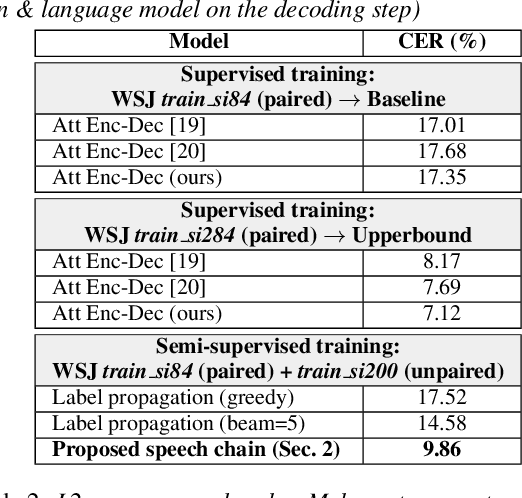
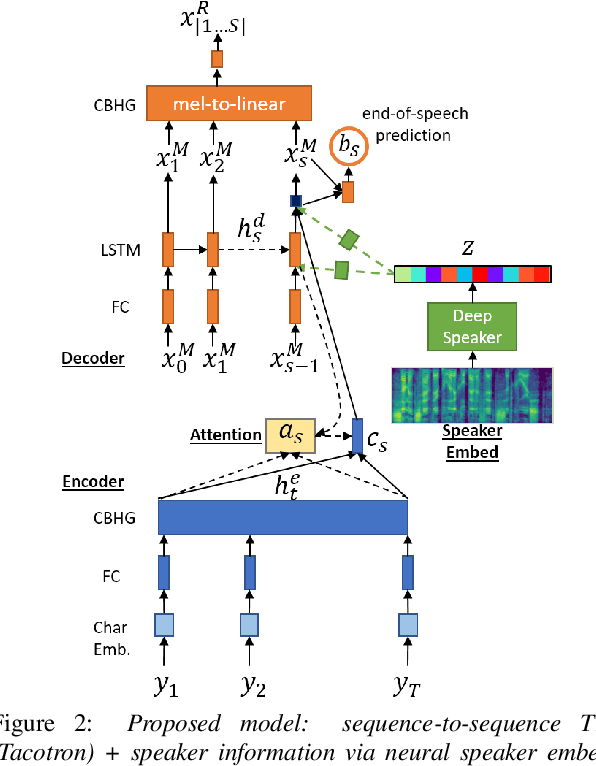
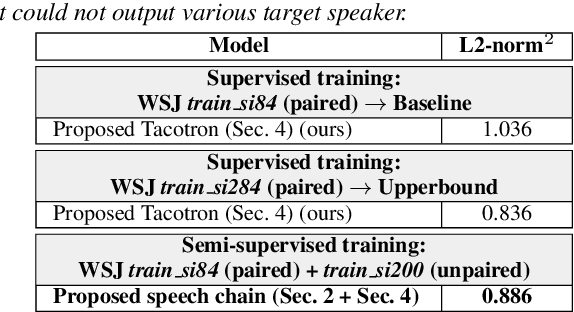
In previous work, we developed a closed-loop speech chain model based on deep learning, in which the architecture enabled the automatic speech recognition (ASR) and text-to-speech synthesis (TTS) components to mutually improve their performance. This was accomplished by the two parts teaching each other using both labeled and unlabeled data. This approach could significantly improve model performance within a single-speaker speech dataset, but only a slight increase could be gained in multi-speaker tasks. Furthermore, the model is still unable to handle unseen speakers. In this paper, we present a new speech chain mechanism by integrating a speaker recognition model inside the loop. We also propose extending the capability of TTS to handle unseen speakers by implementing one-shot speaker adaptation. This enables TTS to mimic voice characteristics from one speaker to another with only a one-shot speaker sample, even from a text without any speaker information. In the speech chain loop mechanism, ASR also benefits from the ability to further learn an arbitrary speaker's characteristics from the generated speech waveform, resulting in a significant improvement in the recognition rate.
American Hate Crime Trends Prediction with Event Extraction
Nov 09, 2021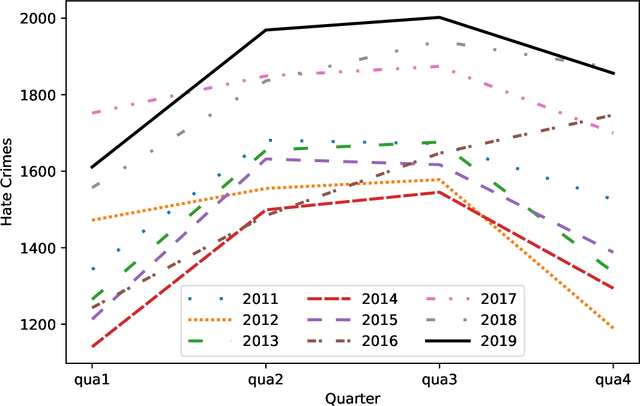
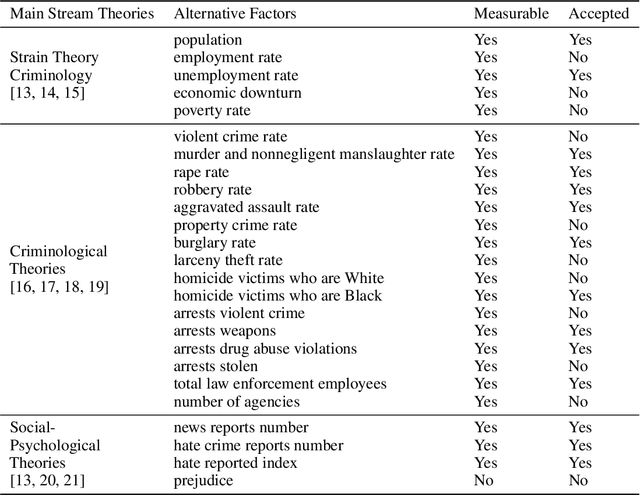
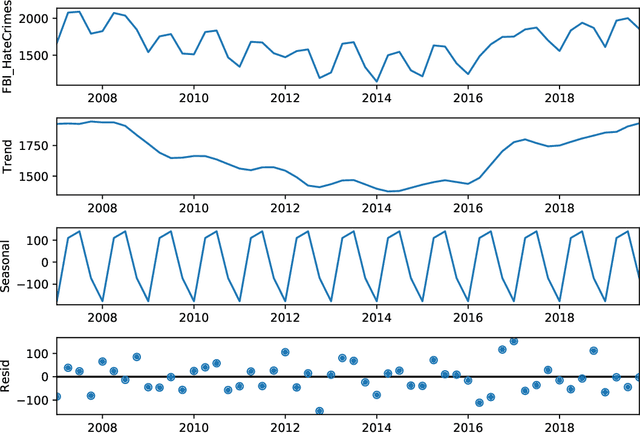

Social media platforms may provide potential space for discourses that contain hate speech, and even worse, can act as a propagation mechanism for hate crimes. The FBI's Uniform Crime Reporting (UCR) Program collects hate crime data and releases statistic report yearly. These statistics provide information in determining national hate crime trends. The statistics can also provide valuable holistic and strategic insight for law enforcement agencies or justify lawmakers for specific legislation. However, the reports are mostly released next year and lag behind many immediate needs. Recent research mainly focuses on hate speech detection in social media text or empirical studies on the impact of a confirmed crime. This paper proposes a framework that first utilizes text mining techniques to extract hate crime events from New York Times news, then uses the results to facilitate predicting American national-level and state-level hate crime trends. Experimental results show that our method can significantly enhance the prediction performance compared with time series or regression methods without event-related factors. Our framework broadens the methods of national-level and state-level hate crime trends prediction.
The HCCL-DKU system for fake audio generation task of the 2022 ICASSP ADD Challenge
Jan 29, 2022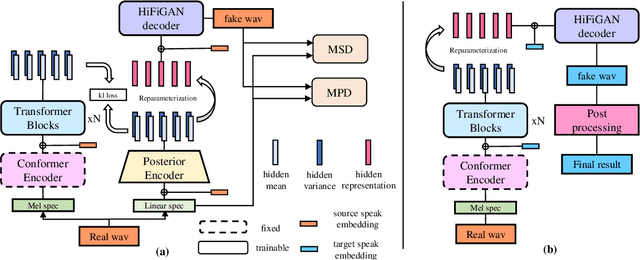

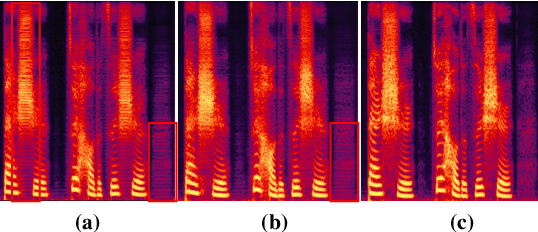
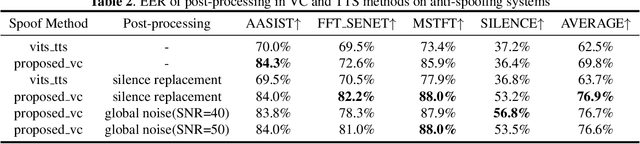
The voice conversion task is to modify the speaker identity of continuous speech while preserving the linguistic content. Generally, the naturalness and similarity are two main metrics for evaluating the conversion quality, which has been improved significantly in recent years. This paper presents the HCCL-DKU entry for the fake audio generation task of the 2022 ICASSP ADD challenge. We propose a novel ppg-based voice conversion model that adopts a fully end-to-end structure. Experimental results show that the proposed method outperforms other conversion models, including Tacotron-based and Fastspeech-based models, on conversion quality and spoofing performance against anti-spoofing systems. In addition, we investigate several post-processing methods for better spoofing power. Finally, we achieve second place with a deception success rate of 0.916 in the ADD challenge.
wav2vec: Unsupervised Pre-training for Speech Recognition
Apr 11, 2019
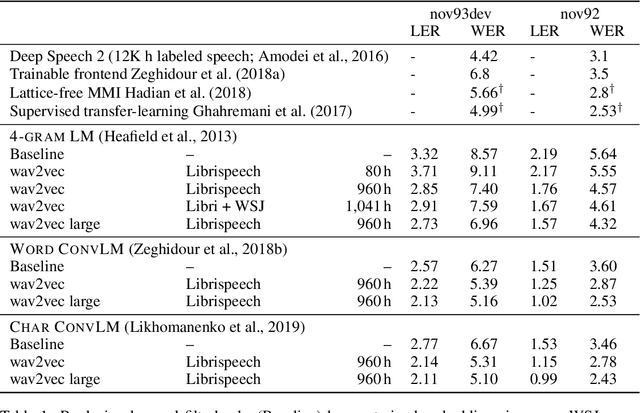
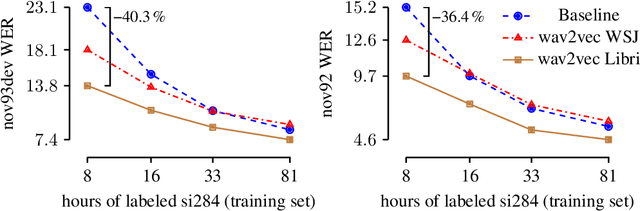
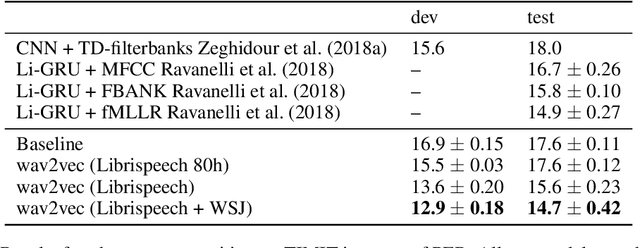
We explore unsupervised pre-training for speech recognition by learning representations of raw audio. wav2vec is trained on large amounts of unlabeled audio data and the resulting representations are then used to improve acoustic model training. We pre-train a simple multi-layer convolutional neural network optimized via a noise contrastive binary classification task. Our experiments on WSJ reduce WER of a strong character-based log-mel filterbank baseline by up to 32% when only a few hours of transcribed data is available. Our approach achieves 2.78% WER on the nov92 test set. This outperforms Deep Speech 2, the best reported character-based system in the literature while using three orders of magnitude less labeled training data.
A Comparison of Label-Synchronous and Frame-Synchronous End-to-End Models for Speech Recognition
May 20, 2020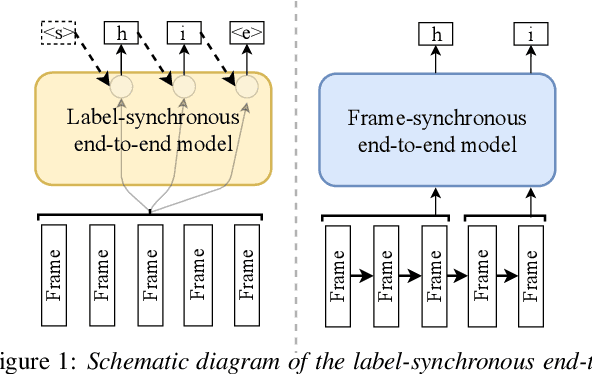

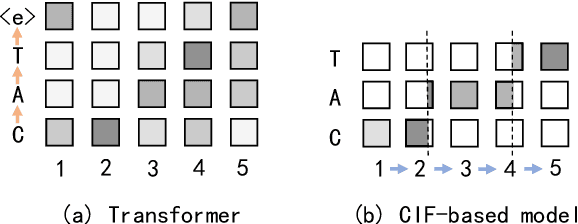
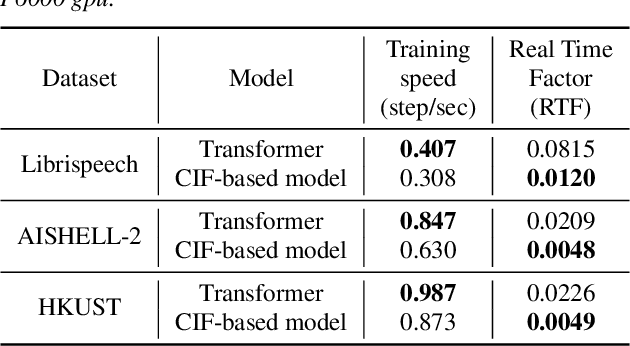
End-to-end models are gaining wider attention in the field of automatic speech recognition (ASR). One of their advantages is the simplicity of building that directly recognizes the speech frame sequence into the text label sequence by neural networks. According to the driving end in the recognition process, end-to-end ASR models could be categorized into two types: label-synchronous and frame-synchronous, each of which has unique model behaviour and characteristic. In this work, we make a detailed comparison on a representative label-synchronous model (transformer) and a soft frame-synchronous model (continuous integrate-and-fire (CIF) based model). The results on three public dataset and a large-scale dataset with 12000 hours of training data show that the two types of models have respective advantages that are consistent with their synchronous mode.
Contextualizing Hate Speech Classifiers with Post-hoc Explanation
May 05, 2020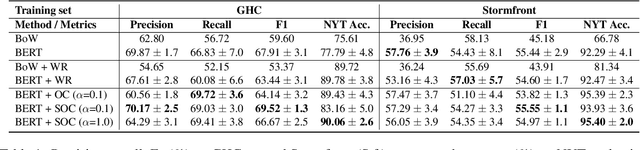
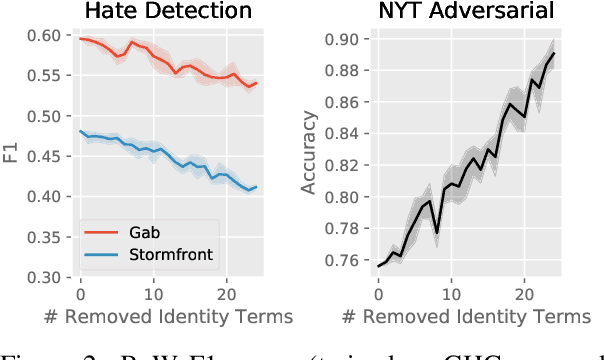
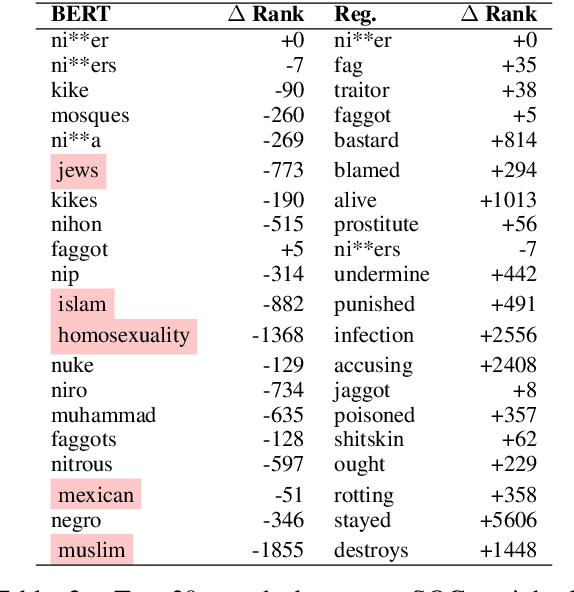

Hate speech classifiers trained on imbalanced datasets struggle to determine if group identifiers like "gay" or "black" are used in offensive or prejudiced ways. Such biases manifest in false positives when these identifiers are present, due to models' inability to learn the contexts which constitute a hateful usage of identifiers. We extract post-hoc explanations from fine-tuned BERT classifiers to detect bias towards identity terms. Then, we propose a novel regularization technique based on these explanations that encourages models to learn from the context of group identifiers in addition to the identifiers themselves. Our approach improved over baselines in limiting false positives on out-of-domain data while maintaining or improving in-domain performance.
Meta Learning for End-to-End Low-Resource Speech Recognition
Oct 26, 2019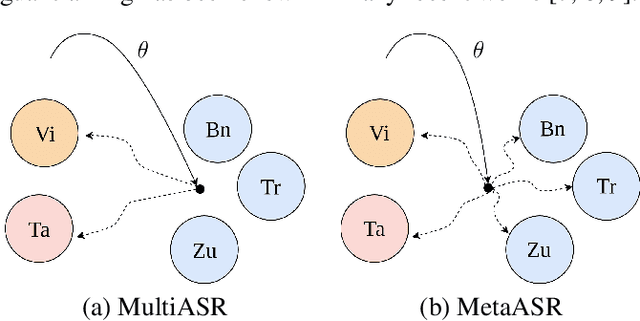



In this paper, we proposed to apply meta learning approach for low-resource automatic speech recognition (ASR). We formulated ASR for different languages as different tasks, and meta-learned the initialization parameters from many pretraining languages to achieve fast adaptation on unseen target language, via recently proposed model-agnostic meta learning algorithm (MAML). We evaluated the proposed approach using six languages as pretraining tasks and four languages as target tasks. Preliminary results showed that the proposed method, MetaASR, significantly outperforms the state-of-the-art multitask pretraining approach on all target languages with different combinations of pretraining languages. In addition, since MAML's model-agnostic property, this paper also opens new research direction of applying meta learning to more speech-related applications.
WaveCycleGAN: Synthetic-to-natural speech waveform conversion using cycle-consistent adversarial networks
Sep 28, 2018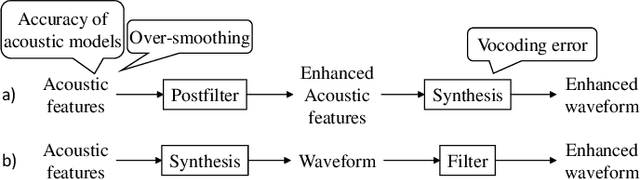
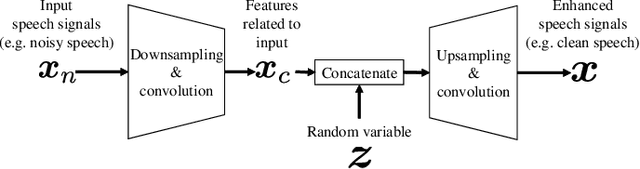
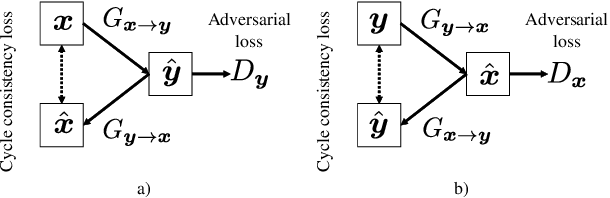
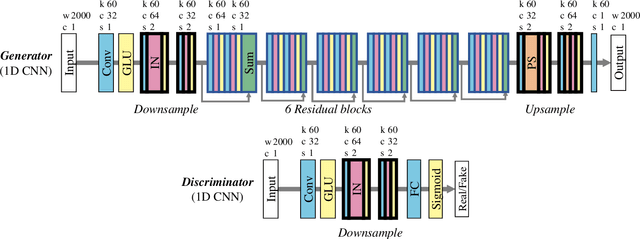
We propose a learning-based filter that allows us to directly modify a synthetic speech waveform into a natural speech waveform. Speech-processing systems using a vocoder framework such as statistical parametric speech synthesis and voice conversion are convenient especially for a limited number of data because it is possible to represent and process interpretable acoustic features over a compact space, such as the fundamental frequency (F0) and mel-cepstrum. However, a well-known problem that leads to the quality degradation of generated speech is an over-smoothing effect that eliminates some detailed structure of generated/converted acoustic features. To address this issue, we propose a synthetic-to-natural speech waveform conversion technique that uses cycle-consistent adversarial networks and which does not require any explicit assumption about speech waveform in adversarial learning. In contrast to current techniques, since our modification is performed at the waveform level, we expect that the proposed method will also make it possible to generate `vocoder-less' sounding speech even if the input speech is synthesized using a vocoder framework. The experimental results demonstrate that our proposed method can 1) alleviate the over-smoothing effect of the acoustic features despite the direct modification method used for the waveform and 2) greatly improve the naturalness of the generated speech sounds.
Integrating Recurrence Dynamics for Speech Emotion Recognition
Nov 09, 2018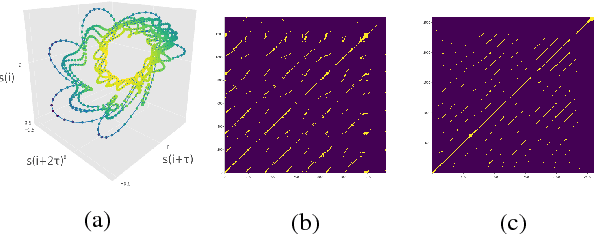

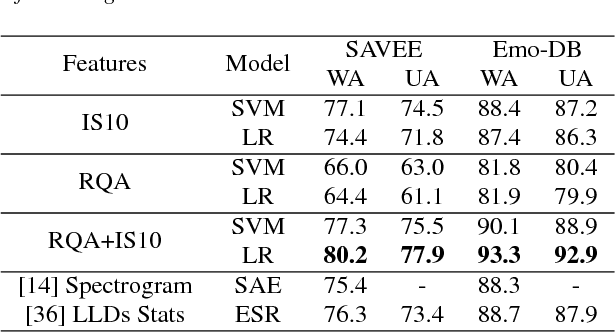
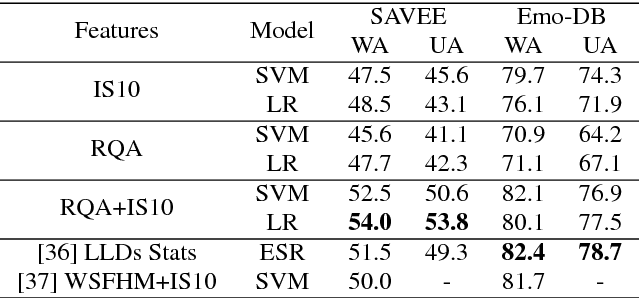
We investigate the performance of features that can capture nonlinear recurrence dynamics embedded in the speech signal for the task of Speech Emotion Recognition (SER). Reconstruction of the phase space of each speech frame and the computation of its respective Recurrence Plot (RP) reveals complex structures which can be measured by performing Recurrence Quantification Analysis (RQA). These measures are aggregated by using statistical functionals over segment and utterance periods. We report SER results for the proposed feature set on three databases using different classification methods. When fusing the proposed features with traditional feature sets, we show an improvement in unweighted accuracy of up to 5.7% and 10.7% on Speaker-Dependent (SD) and Speaker-Independent (SI) SER tasks, respectively, over the baseline. Following a segment-based approach we demonstrate state-of-the-art performance on IEMOCAP using a Bidirectional Recurrent Neural Network.
Star Temporal Classification: Sequence Classification with Partially Labeled Data
Jan 28, 2022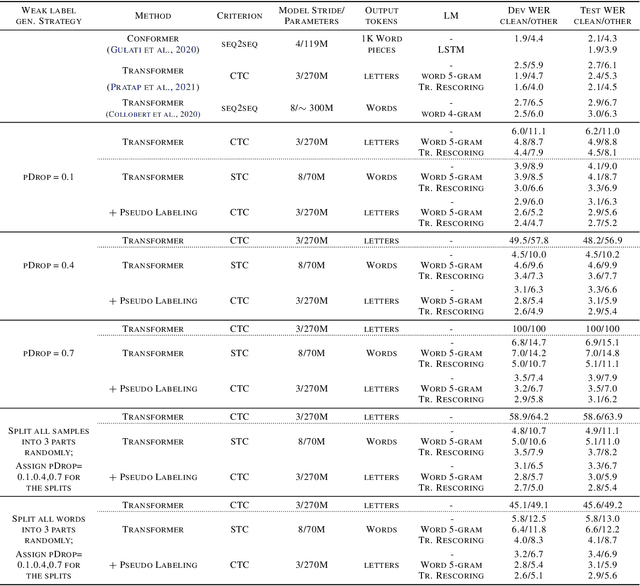
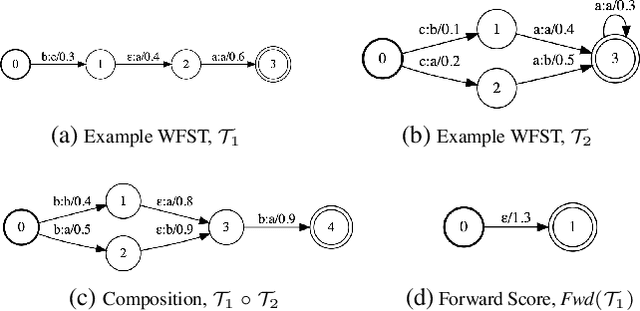
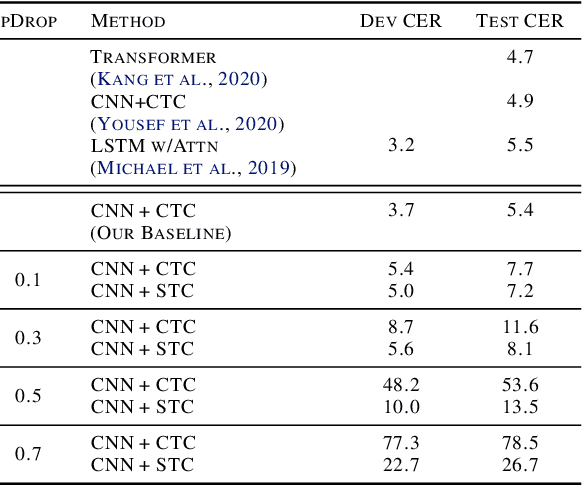
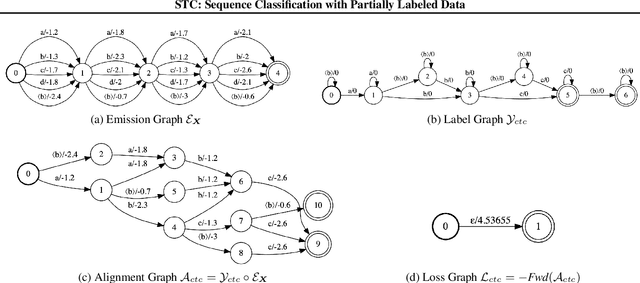
We develop an algorithm which can learn from partially labeled and unsegmented sequential data. Most sequential loss functions, such as Connectionist Temporal Classification (CTC), break down when many labels are missing. We address this problem with Star Temporal Classification (STC) which uses a special star token to allow alignments which include all possible tokens whenever a token could be missing. We express STC as the composition of weighted finite-state transducers (WFSTs) and use GTN (a framework for automatic differentiation with WFSTs) to compute gradients. We perform extensive experiments on automatic speech recognition. These experiments show that STC can recover most of the performance of supervised baseline when up to 70% of the labels are missing. We also perform experiments in handwriting recognition to show that our method easily applies to other sequence classification tasks.