 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
WaveNODE: A Continuous Normalizing Flow for Speech Synthesis
Jun 09, 2020
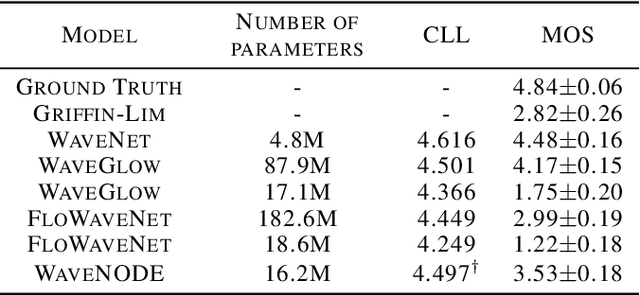
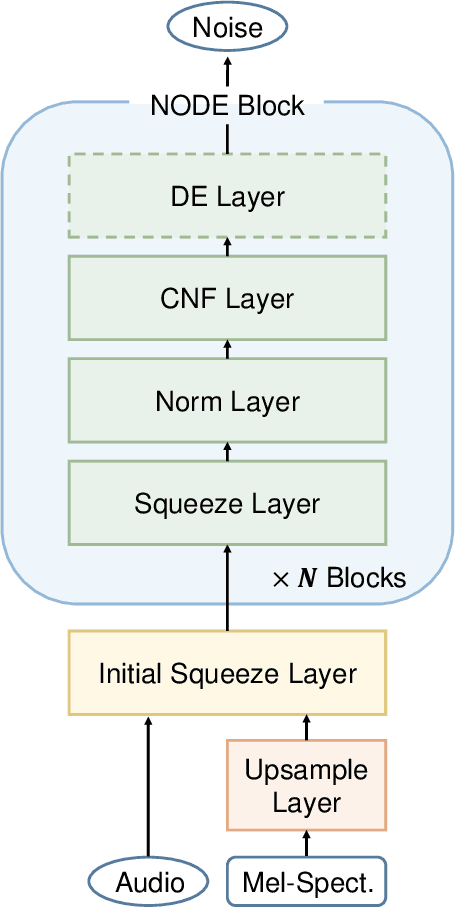

In recent years, various flow-based generative models have been proposed to generate high-fidelity waveforms in real-time. However, these models require either a well-trained teacher network or a number of flow steps making them memory-inefficient. In this paper, we propose a novel generative model called WaveNODE which exploits a continuous normalizing flow for speech synthesis. Unlike the conventional models, WaveNODE places no constraint on the function used for flow operation, thus allowing the usage of more flexible and complex functions. Moreover, WaveNODE can be optimized to maximize the likelihood without requiring any teacher network or auxiliary loss terms. We experimentally show that WaveNODE achieves comparable performance with fewer parameters compared to the conventional flow-based vocoders.
Audio-Based Deep Learning Frameworks for Detecting COVID-19
Feb 10, 2022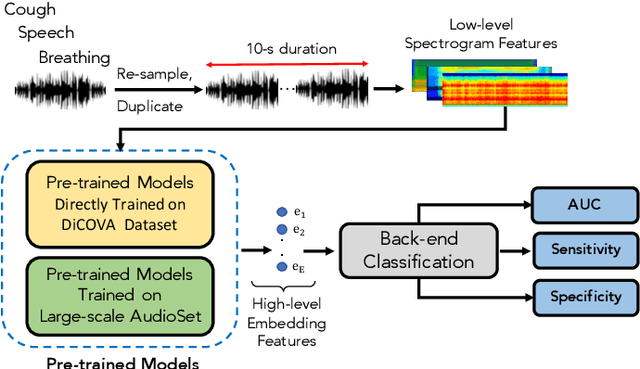

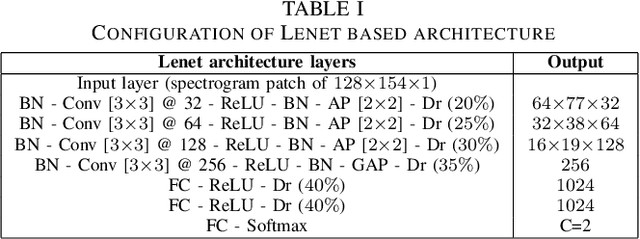
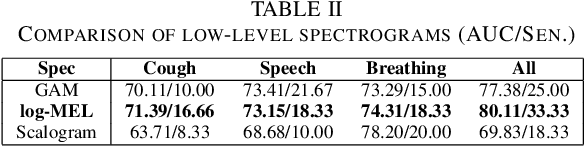
This paper evaluates a wide range of audio-based deep learning frameworks applied to the breathing, cough, and speech sounds for detecting COVID-19. In general, the audio recording inputs are transformed into low-level spectrogram features, then they are fed into pre-trained deep learning models to extract high-level embedding features. Next, the dimension of these high-level embedding features are reduced before finetuning using Light Gradient Boosting Machine (LightGBM) as a back-end classification. Our experiments on the Second DiCOVA Challenge achieved the highest Area Under the Curve (AUC), F1 score, sensitivity score, and specificity score of 89.03%, 64.41%, 63.33%, and 95.13%, respectively. Based on these scores, our method outperforms the state-of-the-art systems, and improves the challenge baseline by 4.33%, 6.00% and 8.33% in terms of AUC, F1 score and sensitivity score, respectively.
wav2letter++: The Fastest Open-source Speech Recognition System
Dec 18, 2018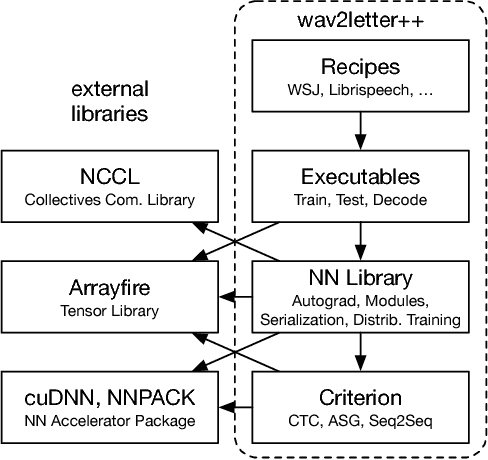
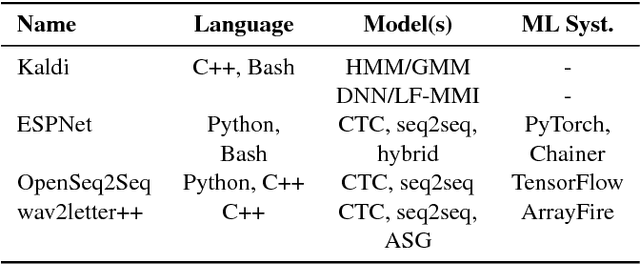

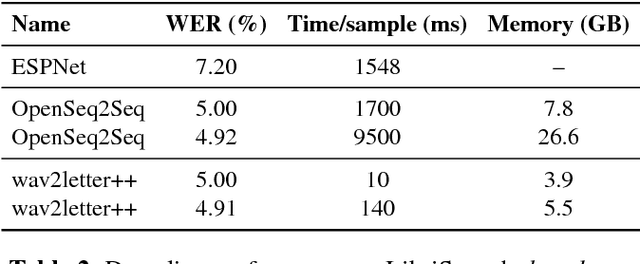
This paper introduces wav2letter++, the fastest open-source deep learning speech recognition framework. wav2letter++ is written entirely in C++, and uses the ArrayFire tensor library for maximum efficiency. Here we explain the architecture and design of the wav2letter++ system and compare it to other major open-source speech recognition systems. In some cases wav2letter++ is more than 2x faster than other optimized frameworks for training end-to-end neural networks for speech recognition. We also show that wav2letter++'s training times scale linearly to 64 GPUs, the highest we tested, for models with 100 million parameters. High-performance frameworks enable fast iteration, which is often a crucial factor in successful research and model tuning on new datasets and tasks.
Time Alignment using Lip Images for Frame-based Electrolaryngeal Voice Conversion
Sep 08, 2021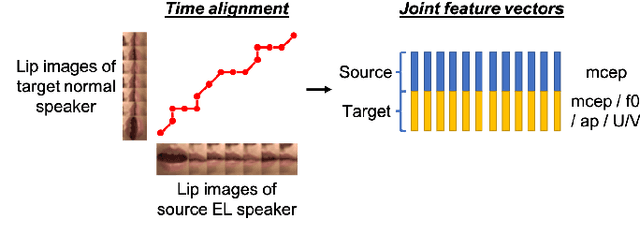
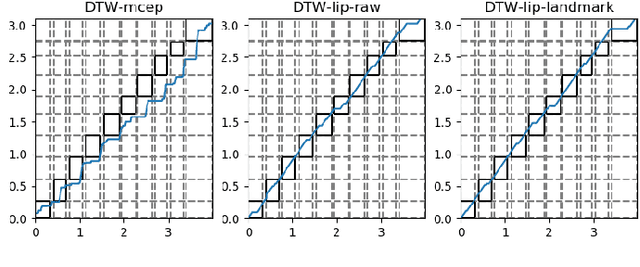
Voice conversion (VC) is an effective approach to electrolaryngeal (EL) speech enhancement, a task that aims to improve the quality of the artificial voice from an electrolarynx device. In frame-based VC methods, time alignment needs to be performed prior to model training, and the dynamic time warping (DTW) algorithm is widely adopted to compute the best time alignment between each utterance pair. The validity is based on the assumption that the same phonemes of the speakers have similar features and can be mapped by measuring a pre-defined distance between speech frames of the source and the target. However, the special characteristics of the EL speech can break the assumption, resulting in a sub-optimal DTW alignment. In this work, we propose to use lip images for time alignment, as we assume that the lip movements of laryngectomee remain normal compared to healthy people. We investigate two naive lip representations and distance metrics, and experimental results demonstrate that the proposed method can significantly outperform the audio-only alignment in terms of objective and subjective evaluations.
Streamable Neural Audio Synthesis With Non-Causal Convolutions
Apr 14, 2022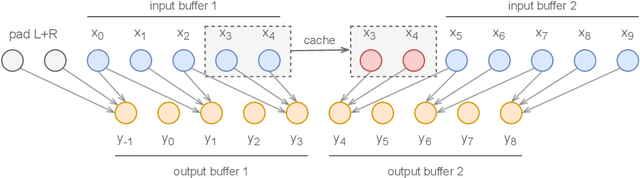
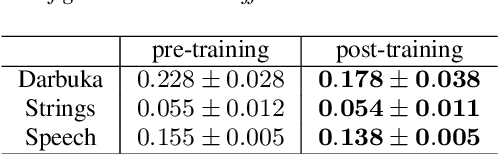
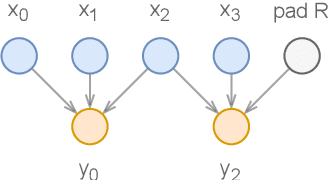
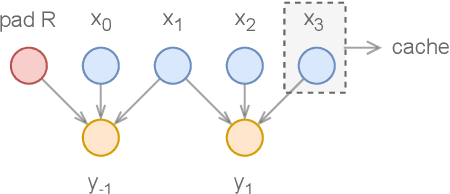
Deep learning models are mostly used in an offline inference fashion. However, this strongly limits the use of these models inside audio generation setups, as most creative workflows are based on real-time digital signal processing. Although approaches based on recurrent networks can be naturally adapted to this buffer-based computation, the use of convolutions still poses some serious challenges. To tackle this issue, the use of causal streaming convolutions have been proposed. However, this requires specific complexified training and can impact the resulting audio quality. In this paper, we introduce a new method allowing to produce non-causal streaming models. This allows to make any convolutional model compatible with real-time buffer-based processing. As our method is based on a post-training reconfiguration of the model, we show that it is able to transform models trained without causal constraints into a streaming model. We show how our method can be adapted to fit complex architectures with parallel branches. To evaluate our method, we apply it on the recent RAVE model, which provides high-quality real-time audio synthesis. We test our approach on multiple music and speech datasets and show that it is faster than overlap-add methods, while having no impact on the generation quality. Finally, we introduce two open-source implementation of our work as Max/MSP and PureData externals, and as a VST audio plugin. This allows to endow traditional digital audio workstation with real-time neural audio synthesis on a laptop CPU.
End-to-end Microphone Permutation and Number Invariant Multi-channel Speech Separation
Nov 26, 2019
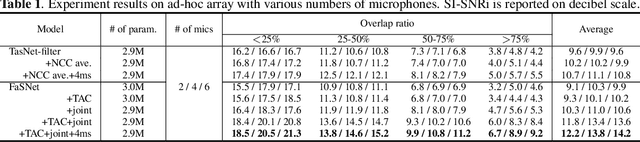
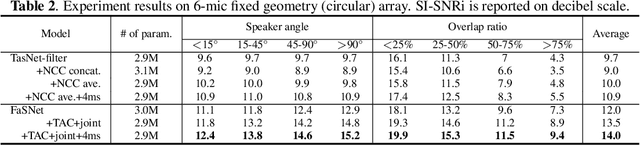
An important problem in ad-hoc microphone speech separation is how to guarantee the robustness of a system with respect to the locations and numbers of microphones. The former requires the system to be invariant to different indexing of the microphones with the same locations, while the latter requires the system to be able to process inputs with varying dimensions. Conventional optimization-based beamforming techniques satisfy these requirements by definition, while for deep learning-based end-to-end systems those constraints are not fully addressed. In this paper, we propose transform-average-concatenate (TAC), a simple design paradigm for channel permutation and number invariant multi-channel speech separation. Based on the filter-and-sum network (FaSNet), a recently proposed end-to-end time-domain beamforming system, we show how TAC significantly improves the separation performance across various numbers of microphones in noisy reverberant separation tasks with ad-hoc arrays. Moreover, we show that TAC also significantly improves the separation performance with fixed geometry array configuration, further proving the effectiveness of the proposed paradigm in the general problem of multi-microphone speech separation.
Real Time Speech Enhancement in the Waveform Domain
Jun 23, 2020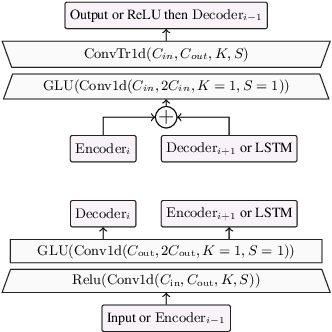
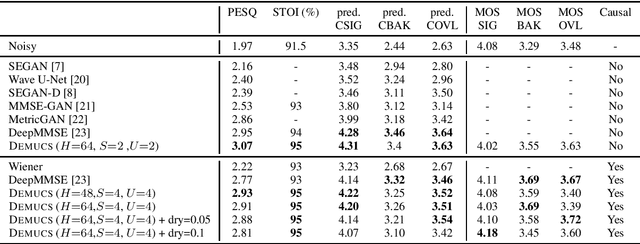
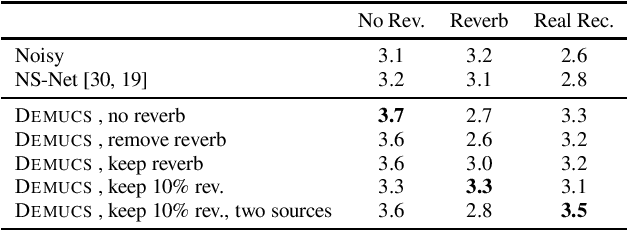

We present a causal speech enhancement model working on the raw waveform that runs in real-time on a laptop CPU. The proposed model is based on an encoder-decoder architecture with skip-connections. It is optimized on both time and frequency domains, using multiple loss functions. Empirical evidence shows that it is capable of removing various kinds of background noise including stationary and non-stationary noises, as well as room reverb. Additionally, we suggest a set of data augmentation techniques applied directly on the raw waveform which further improve model performance and its generalization abilities. We perform evaluations on several standard benchmarks, both using objective metrics and human judgements. The proposed model matches state-of-the-art performance of both causal and non causal methods while working directly on the raw waveform.
The Zero Resource Speech Challenge 2019: TTS without T
Apr 25, 2019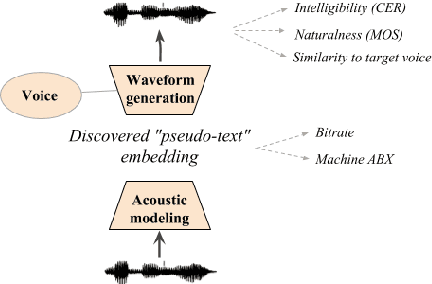
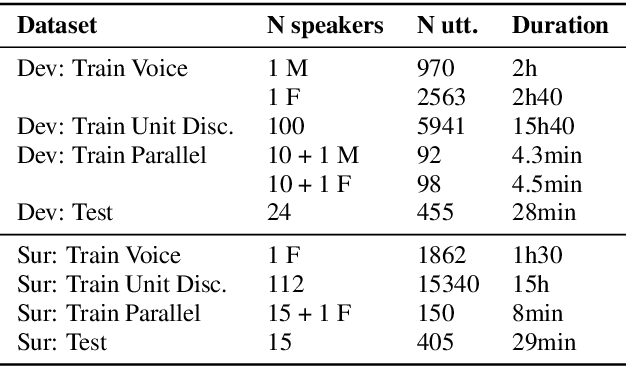
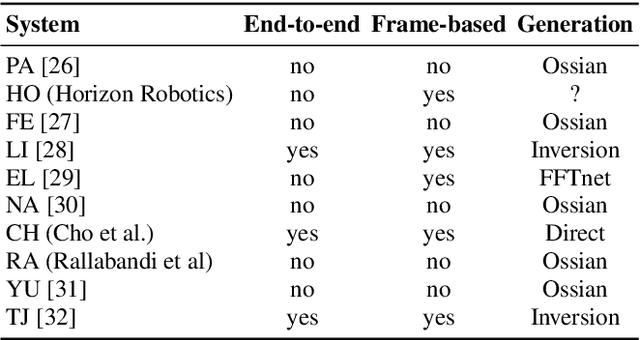
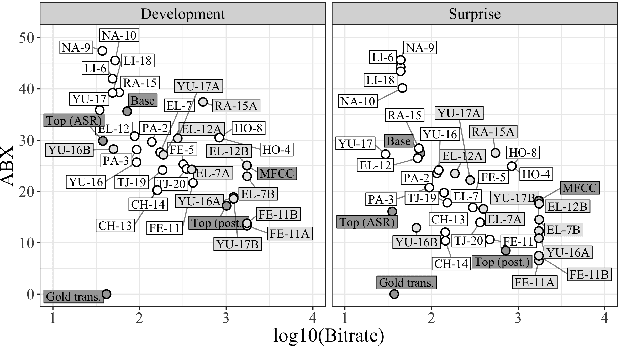
We present the Zero Resource Speech Challenge 2019, which proposes to build a speech synthesizer without any text or phonetic labels: hence, TTS without T (text-to-speech without text). We provide raw audio for a target voice in an unknown language (the Voice dataset), but no alignment, text or labels. Participants must discover subword units in an unsupervised way (using the Unit Discovery dataset) and align them to the voice recordings in a way that works best for the purpose of synthesizing novel utterances from novel speakers, similar to the target speaker's voice. We describe the metrics used for evaluation, a baseline system consisting of unsupervised subword unit discovery plus a standard TTS system, and a topline TTS using gold phoneme transcriptions. We present an overview of the 19 submitted systems from 11 teams and discuss the main results.
Combining Multiple Views for Visual Speech Recognition
Jun 28, 2018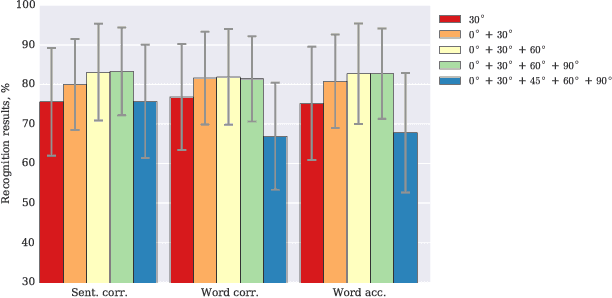
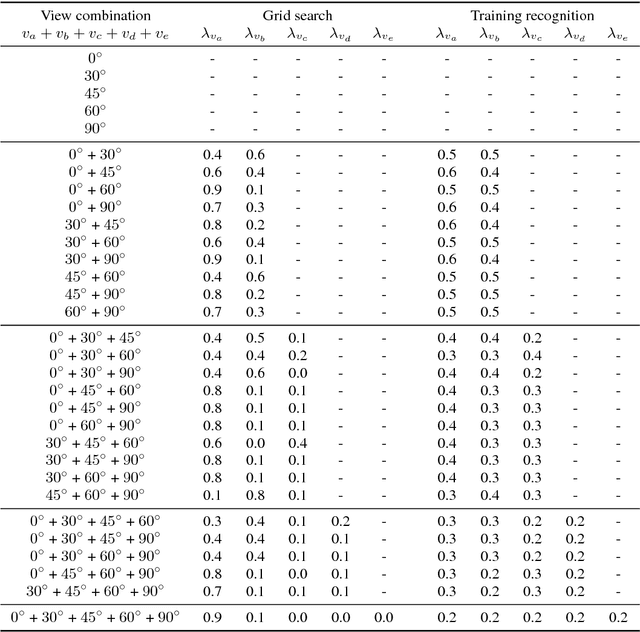
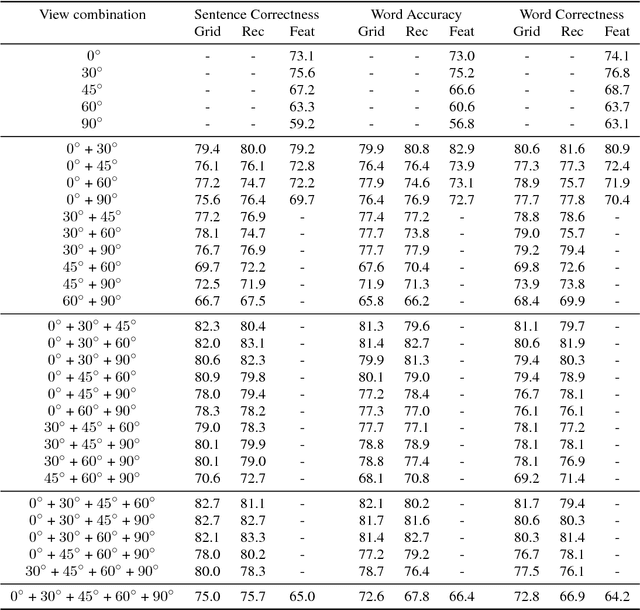
Visual speech recognition is a challenging research problem with a particular practical application of aiding audio speech recognition in noisy scenarios. Multiple camera setups can be beneficial for the visual speech recognition systems in terms of improved performance and robustness. In this paper, we explore this aspect and provide a comprehensive study on combining multiple views for visual speech recognition. The thorough analysis covers fusion of all possible view angle combinations both at feature level and decision level. The employed visual speech recognition system in this study extracts features through a PCA-based convolutional neural network, followed by an LSTM network. Finally, these features are processed in a tandem system, being fed into a GMM-HMM scheme. The decision fusion acts after this point by combining the Viterbi path log-likelihoods. The results show that the complementary information contained in recordings from different view angles improves the results significantly. For example, the sentence correctness on the test set is increased from 76% for the highest performing single view ($30^\circ$) to up to 83% when combining this view with the frontal and $60^\circ$ view angles.