 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unsupervised feature learning for speech using correspondence and Siamese networks
Mar 28, 2020
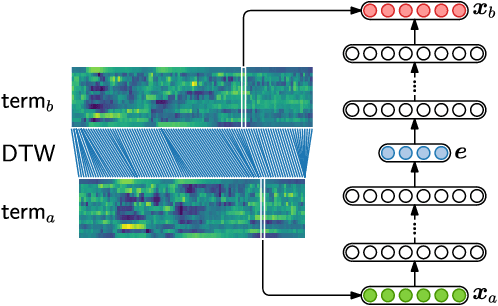
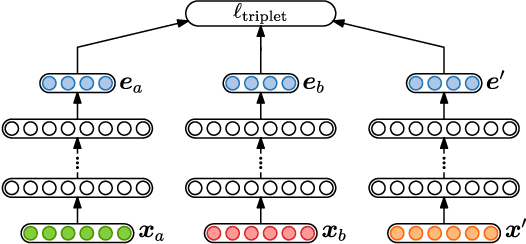
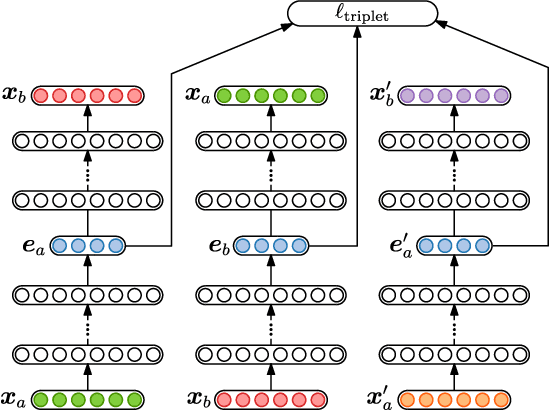
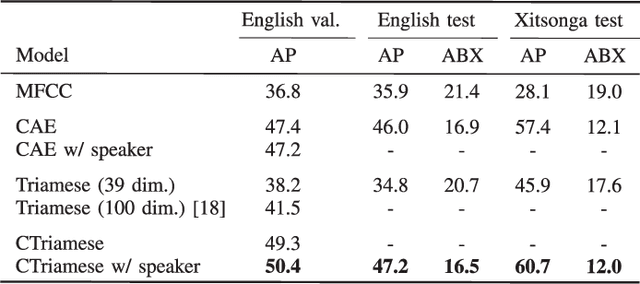
In zero-resource settings where transcribed speech audio is unavailable, unsupervised feature learning is essential for downstream speech processing tasks. Here we compare two recent methods for frame-level acoustic feature learning. For both methods, unsupervised term discovery is used to find pairs of word examples of the same unknown type. Dynamic programming is then used to align the feature frames between each word pair, serving as weak top-down supervision for the two models. For the correspondence autoencoder (CAE), matching frames are presented as input-output pairs. The Triamese network uses a contrastive loss to reduce the distance between frames of the same predicted word type while increasing the distance between negative examples. For the first time, these feature extractors are compared on the same discrimination tasks using the same weak supervision pairs. We find that, on the two datasets considered here, the CAE outperforms the Triamese network. However, we show that a new hybrid correspondence-Triamese approach (CTriamese), consistently outperforms both the CAE and Triamese models in terms of average precision and ABX error rates on both English and Xitsonga evaluation data.
* 5 pages, 3 figures, 2 tables; accepted to the IEEE Signal Processing Letters, (c) 2020 IEEE
Towards localisation of keywords in speech using weak supervision
Dec 14, 2020Developments in weakly supervised and self-supervised models could enable speech technology in low-resource settings where full transcriptions are not available. We consider whether keyword localisation is possible using two forms of weak supervision where location information is not provided explicitly. In the first, only the presence or absence of a word is indicated, i.e. a bag-of-words (BoW) labelling. In the second, visual context is provided in the form of an image paired with an unlabelled utterance; a model then needs to be trained in a self-supervised fashion using the paired data. For keyword localisation, we adapt a saliency-based method typically used in the vision domain. We compare this to an existing technique that performs localisation as a part of the network architecture. While the saliency-based method is more flexible (it can be applied without architectural restrictions), we identify a critical limitation when using it for keyword localisation. Of the two forms of supervision, the visually trained model performs worse than the BoW-trained model. We show qualitatively that the visually trained model sometimes locate semantically related words, but this is not consistent. While our results show that there is some signal allowing for localisation, it also calls for other localisation methods better matched to these forms of weak supervision.
Recurrent Neural Network Transducer for Audio-Visual Speech Recognition
Nov 08, 2019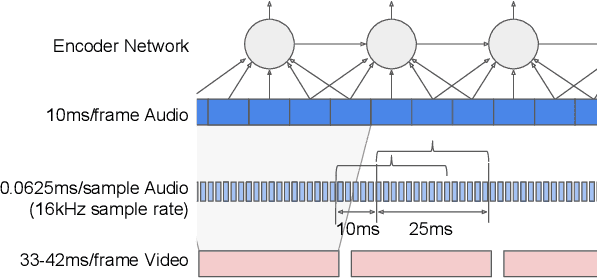
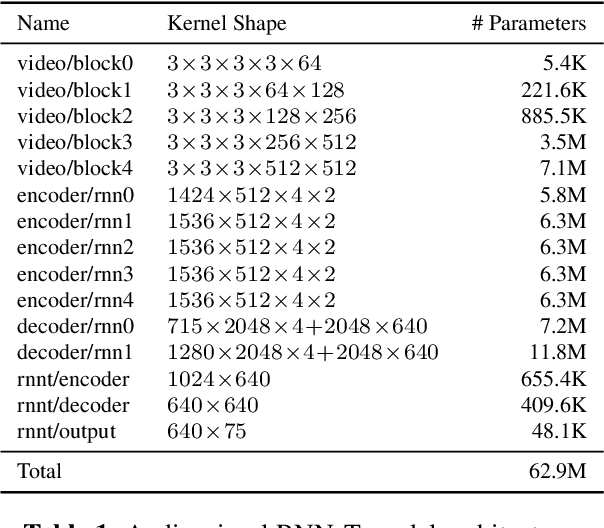
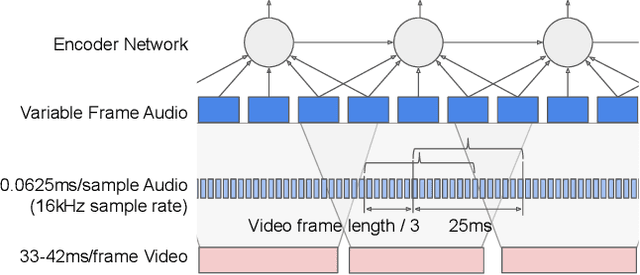

This work presents a large-scale audio-visual speech recognition system based on a recurrent neural network transducer (RNN-T) architecture. To support the development of such a system, we built a large audio-visual (A/V) dataset of segmented utterances extracted from YouTube public videos, leading to 31k hours of audio-visual training content. The performance of an audio-only, visual-only, and audio-visual system are compared on two large-vocabulary test sets: a set of utterance segments from public YouTube videos called YTDEV18 and the publicly available LRS3-TED set. To highlight the contribution of the visual modality, we also evaluated the performance of our system on the YTDEV18 set artificially corrupted with background noise and overlapping speech. To the best of our knowledge, our system significantly improves the state-of-the-art on the LRS3-TED set.
Speech enhancement with variational autoencoders and alpha-stable distributions
Feb 08, 2019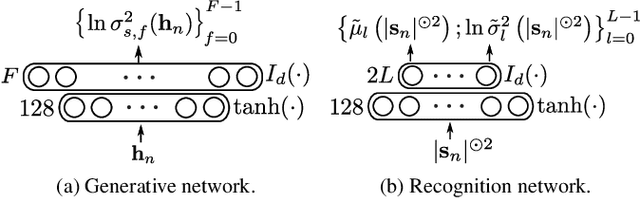
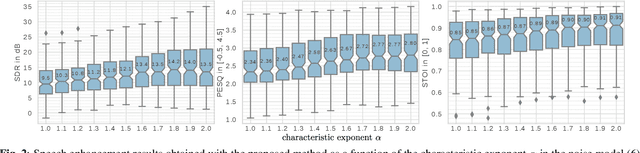
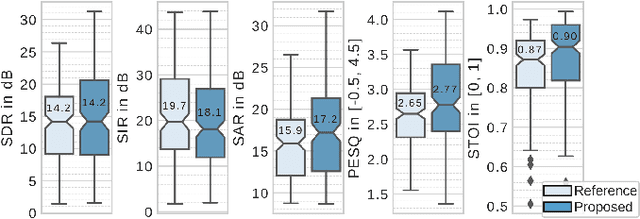
This paper focuses on single-channel semi-supervised speech enhancement. We learn a speaker-independent deep generative speech model using the framework of variational autoencoders. The noise model remains unsupervised because we do not assume prior knowledge of the noisy recording environment. In this context, our contribution is to propose a noise model based on alpha-stable distributions, instead of the more conventional Gaussian non-negative matrix factorization approach found in previous studies. We develop a Monte Carlo expectation-maximization algorithm for estimating the model parameters at test time. Experimental results show the superiority of the proposed approach both in terms of perceptual quality and intelligibility of the enhanced speech signal.
* 5 pages, 3 figures, audio examples and code available online : https://team.inria.fr/perception/research/icassp2019-asvae/. arXiv admin note: text overlap with arXiv:1811.06713
Deep Iterative Phase Retrieval for Ptychography
Feb 17, 2022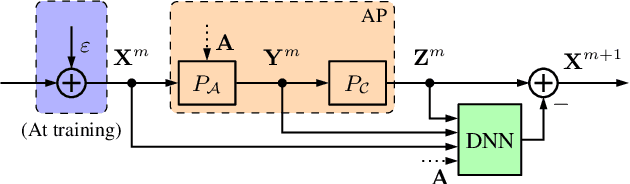

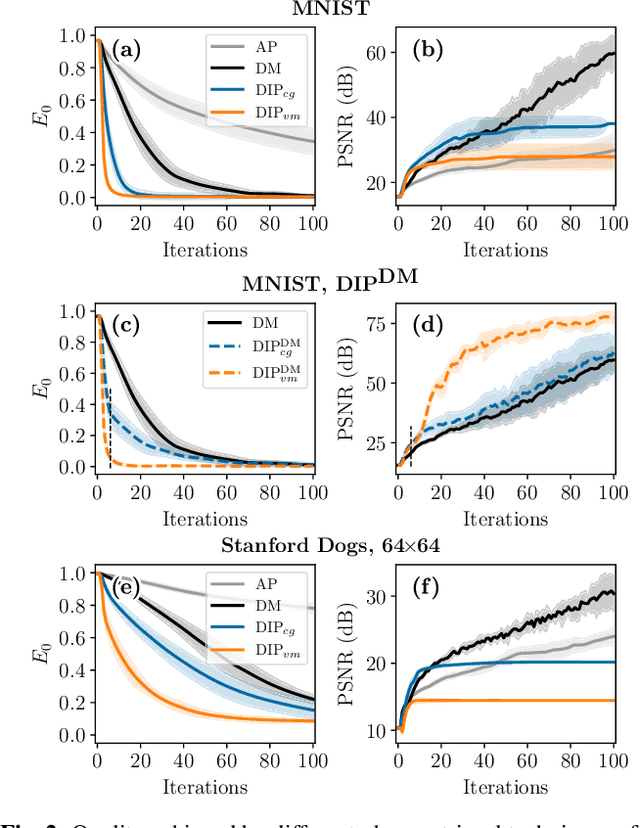
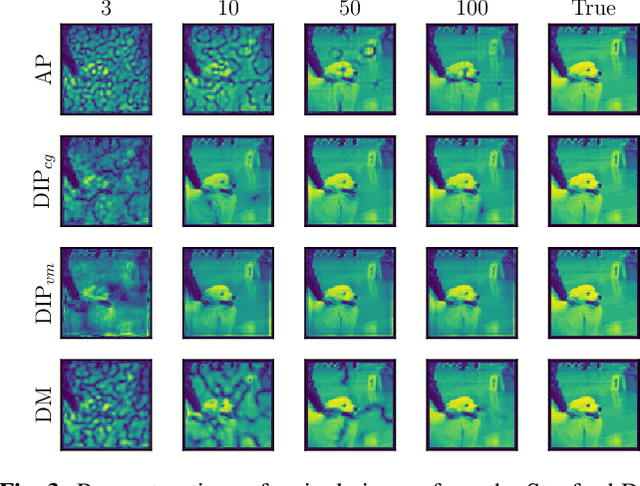
One of the most prominent challenges in the field of diffractive imaging is the phase retrieval (PR) problem: In order to reconstruct an object from its diffraction pattern, the inverse Fourier transform must be computed. This is only possible given the full complex-valued diffraction data, i.e. magnitude and phase. However, in diffractive imaging, generally only magnitudes can be directly measured while the phase needs to be estimated. In this work we specifically consider ptychography, a sub-field of diffractive imaging, where objects are reconstructed from multiple overlapping diffraction images. We propose an augmentation of existing iterative phase retrieval algorithms with a neural network designed for refining the result of each iteration. For this purpose we adapt and extend a recently proposed architecture from the speech processing field. Evaluation results show the proposed approach delivers improved convergence rates in terms of both iteration count and algorithm runtime.
A Hierarchical Model for Spoken Language Recognition
Jan 04, 2022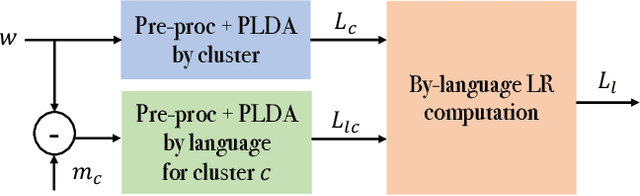
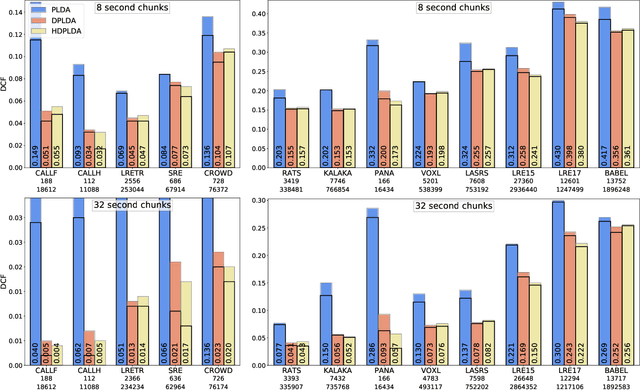
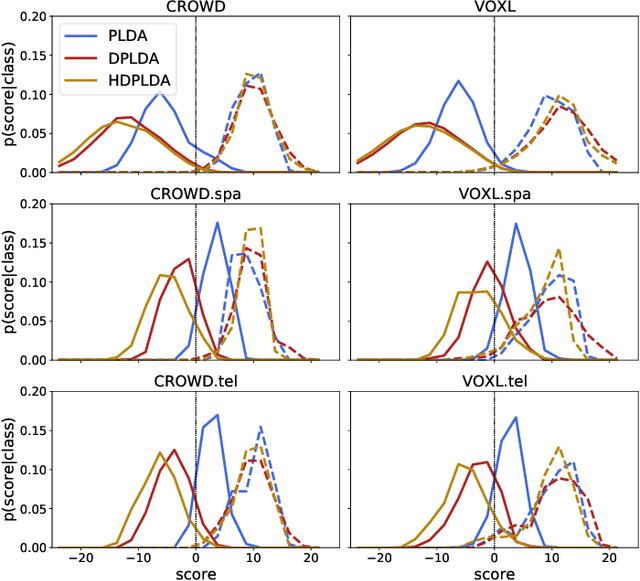
Spoken language recognition (SLR) refers to the automatic process used to determine the language present in a speech sample. SLR is an important task in its own right, for example, as a tool to analyze or categorize large amounts of multi-lingual data. Further, it is also an essential tool for selecting downstream applications in a work flow, for example, to chose appropriate speech recognition or machine translation models. SLR systems are usually composed of two stages, one where an embedding representing the audio sample is extracted and a second one which computes the final scores for each language. In this work, we approach the SLR task as a detection problem and implement the second stage as a probabilistic linear discriminant analysis (PLDA) model. We show that discriminative training of the PLDA parameters gives large gains with respect to the usual generative training. Further, we propose a novel hierarchical approach were two PLDA models are trained, one to generate scores for clusters of highly related languages and a second one to generate scores conditional to each cluster. The final language detection scores are computed as a combination of these two sets of scores. The complete model is trained discriminatively to optimize a cross-entropy objective. We show that this hierarchical approach consistently outperforms the non-hierarchical one for detection of highly related languages, in many cases by large margins. We train our systems on a collection of datasets including 100 languages and test them both on matched and mismatched conditions, showing that the gains are robust to condition mismatch.
AISHELL-1: An Open-Source Mandarin Speech Corpus and A Speech Recognition Baseline
Sep 16, 2017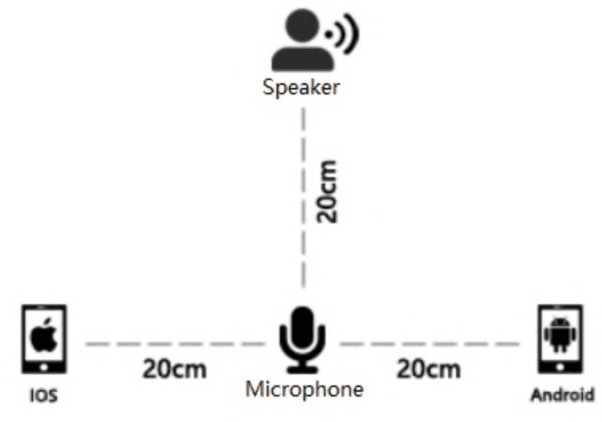
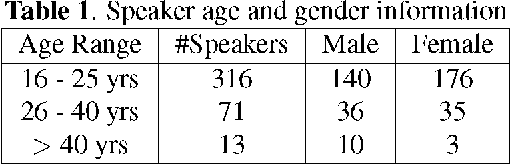

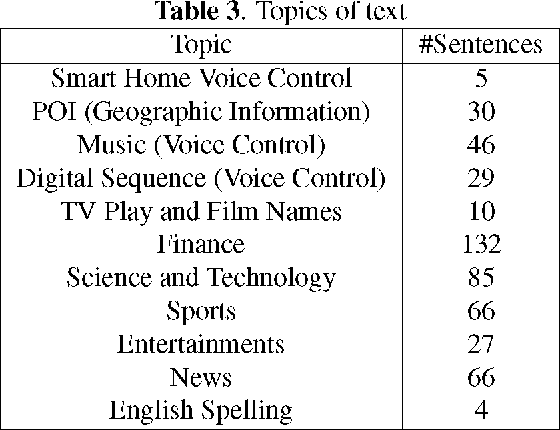
An open-source Mandarin speech corpus called AISHELL-1 is released. It is by far the largest corpus which is suitable for conducting the speech recognition research and building speech recognition systems for Mandarin. The recording procedure, including audio capturing devices and environments are presented in details. The preparation of the related resources, including transcriptions and lexicon are described. The corpus is released with a Kaldi recipe. Experimental results implies that the quality of audio recordings and transcriptions are promising.
End-to-End Multi-speaker Speech Recognition with Transformer
Feb 13, 2020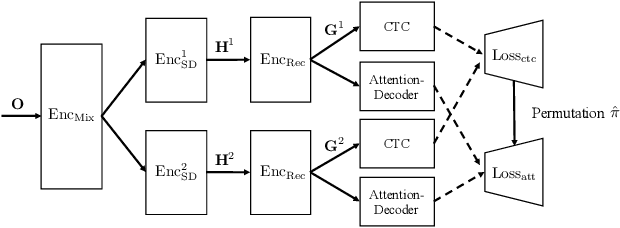

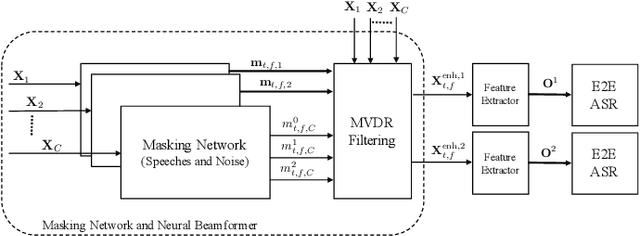

Recently, fully recurrent neural network (RNN) based end-to-end models have been proven to be effective for multi-speaker speech recognition in both the single-channel and multi-channel scenarios. In this work, we explore the use of Transformer models for these tasks by focusing on two aspects. First, we replace the RNN-based encoder-decoder in the speech recognition model with a Transformer architecture. Second, in order to use the Transformer in the masking network of the neural beamformer in the multi-channel case, we modify the self-attention component to be restricted to a segment rather than the whole sequence in order to reduce computation. Besides the model architecture improvements, we also incorporate an external dereverberation preprocessing, the weighted prediction error (WPE), enabling our model to handle reverberated signals. Experiments on the spatialized wsj1-2mix corpus show that the Transformer-based models achieve 40.9% and 25.6% relative WER reduction, down to 12.1% and 6.4% WER, under the anechoic condition in single-channel and multi-channel tasks, respectively, while in the reverberant case, our methods achieve 41.5% and 13.8% relative WER reduction, down to 16.5% and 15.2% WER.
TalkTive: A Conversational Agent Using Backchannels to Engage Older Adults in Neurocognitive Disorders Screening
Feb 16, 2022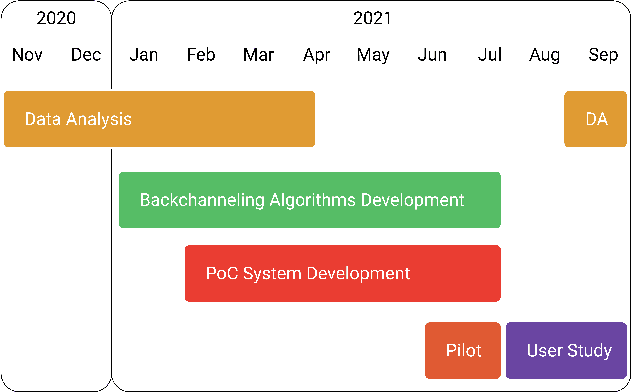

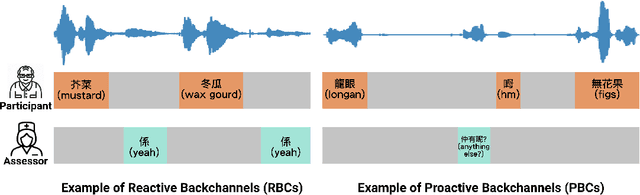

Conversational agents (CAs) have the great potential in mitigating the clinicians' burden in screening for neurocognitive disorders among older adults. It is important, therefore, to develop CAs that can be engaging, to elicit conversational speech input from older adult participants for supporting assessment of cognitive abilities. As an initial step, this paper presents research in developing the backchanneling ability in CAs in the form of a verbal response to engage the speaker. We analyzed 246 conversations of cognitive assessments between older adults and human assessors, and derived the categories of reactive backchannels (e.g. "hmm") and proactive backchannels (e.g. "please keep going"). This is used in the development of TalkTive, a CA which can predict both timing and form of backchanneling during cognitive assessments. The study then invited 36 older adult participants to evaluate the backchanneling feature. Results show that proactive backchanneling is more appreciated by participants than reactive backchanneling.
WaveNODE: A Continuous Normalizing Flow for Speech Synthesis
Jun 09, 2020
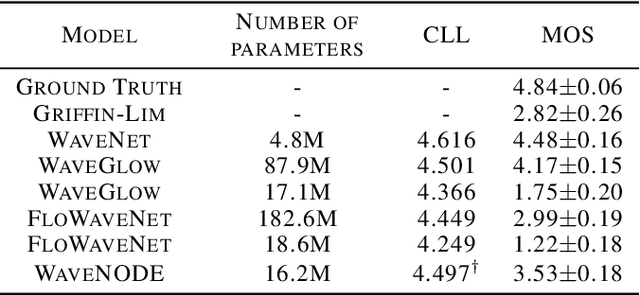
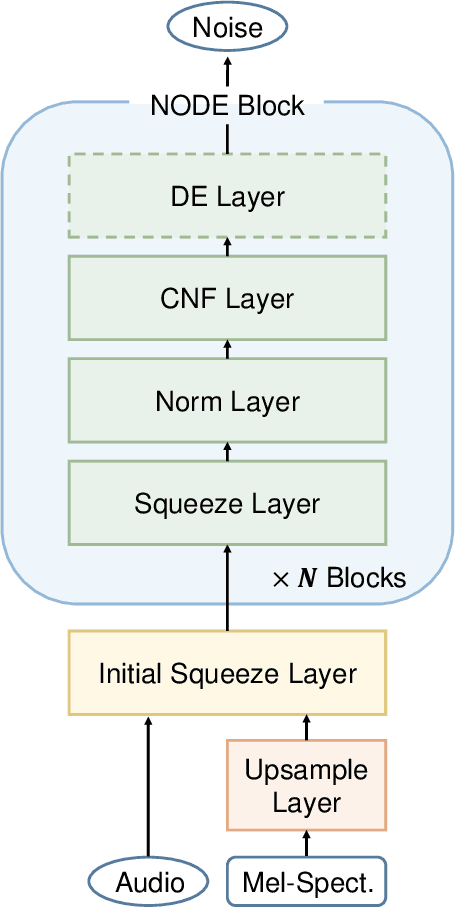

In recent years, various flow-based generative models have been proposed to generate high-fidelity waveforms in real-time. However, these models require either a well-trained teacher network or a number of flow steps making them memory-inefficient. In this paper, we propose a novel generative model called WaveNODE which exploits a continuous normalizing flow for speech synthesis. Unlike the conventional models, WaveNODE places no constraint on the function used for flow operation, thus allowing the usage of more flexible and complex functions. Moreover, WaveNODE can be optimized to maximize the likelihood without requiring any teacher network or auxiliary loss terms. We experimentally show that WaveNODE achieves comparable performance with fewer parameters compared to the conventional flow-based vocoders.