 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Monaural Multi-Talker Speech Recognition using Factorial Speech Processing Models
Oct 05, 2016
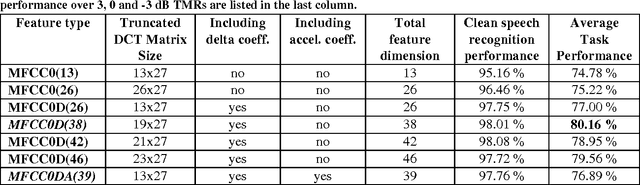
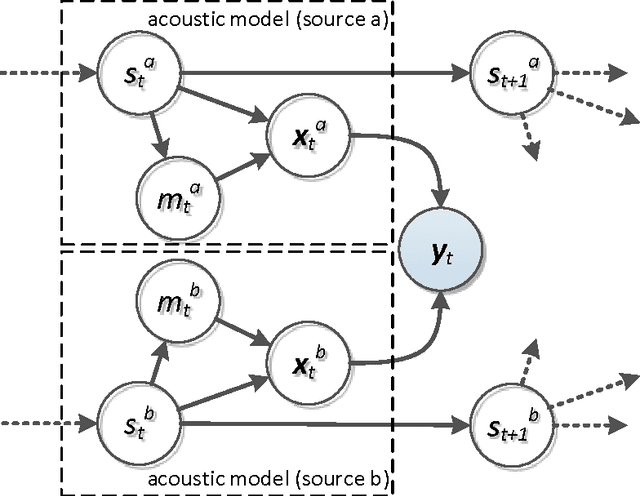

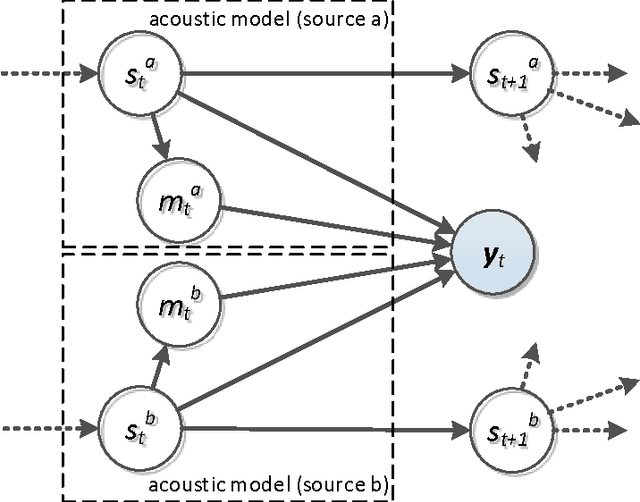
A Pascal challenge entitled monaural multi-talker speech recognition was developed, targeting the problem of robust automatic speech recognition against speech like noises which significantly degrades the performance of automatic speech recognition systems. In this challenge, two competing speakers say a simple command simultaneously and the objective is to recognize speech of the target speaker. Surprisingly during the challenge, a team from IBM research, could achieve a performance better than human listeners on this task. The proposed method of the IBM team, consist of an intermediate speech separation and then a single-talker speech recognition. This paper reconsiders the task of this challenge based on gain adapted factorial speech processing models. It develops a joint-token passing algorithm for direct utterance decoding of both target and masker speakers, simultaneously. Comparing it to the challenge winner, it uses maximum uncertainty during the decoding which cannot be used in the past two-phased method. It provides detailed derivation of inference on these models based on general inference procedures of probabilistic graphical models. As another improvement, it uses deep neural networks for joint-speaker identification and gain estimation which makes these two steps easier than before producing competitive results for these steps. The proposed method of this work outperforms past super-human results and even the results were achieved recently by Microsoft research, using deep neural networks. It achieved 5.5% absolute task performance improvement compared to the first super-human system and 2.7% absolute task performance improvement compared to its recent competitor.
Perceptual-based deep-learning denoiser as a defense against adversarial attacks on ASR systems
Jul 12, 2021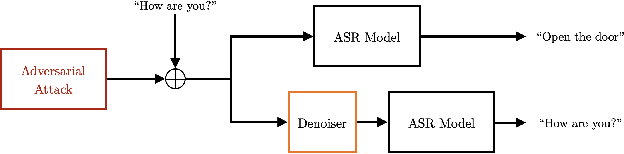
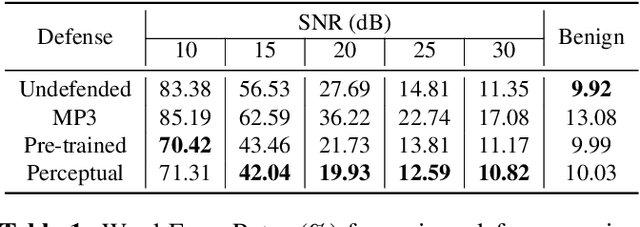
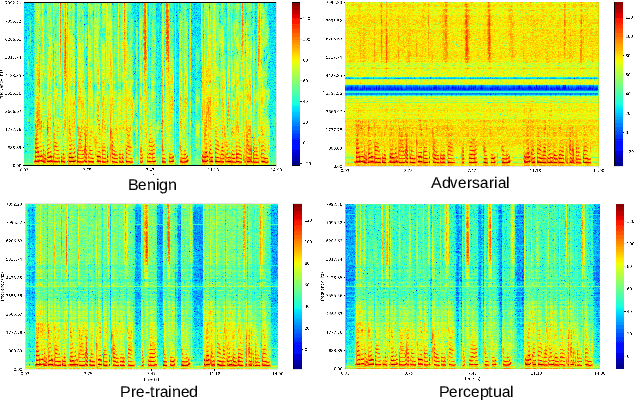
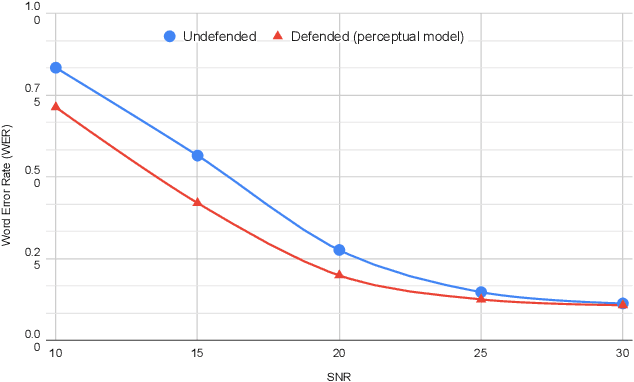
In this paper we investigate speech denoising as a defense against adversarial attacks on automatic speech recognition (ASR) systems. Adversarial attacks attempt to force misclassification by adding small perturbations to the original speech signal. We propose to counteract this by employing a neural-network based denoiser as a pre-processor in the ASR pipeline. The denoiser is independent of the downstream ASR model, and thus can be rapidly deployed in existing systems. We found that training the denoisier using a perceptually motivated loss function resulted in increased adversarial robustness without compromising ASR performance on benign samples. Our defense was evaluated (as a part of the DARPA GARD program) on the 'Kenansville' attack strategy across a range of attack strengths and speech samples. An average improvement in Word Error Rate (WER) of about 7.7% was observed over the undefended model at 20 dB signal-to-noise-ratio (SNR) attack strength.
TalkTive: A Conversational Agent Using Backchannels to Engage Older Adults in Neurocognitive Disorders Screening
Feb 16, 2022

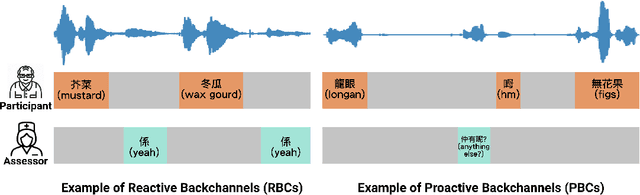

Conversational agents (CAs) have the great potential in mitigating the clinicians' burden in screening for neurocognitive disorders among older adults. It is important, therefore, to develop CAs that can be engaging, to elicit conversational speech input from older adult participants for supporting assessment of cognitive abilities. As an initial step, this paper presents research in developing the backchanneling ability in CAs in the form of a verbal response to engage the speaker. We analyzed 246 conversations of cognitive assessments between older adults and human assessors, and derived the categories of reactive backchannels (e.g. "hmm") and proactive backchannels (e.g. "please keep going"). This is used in the development of TalkTive, a CA which can predict both timing and form of backchanneling during cognitive assessments. The study then invited 36 older adult participants to evaluate the backchanneling feature. Results show that proactive backchanneling is more appreciated by participants than reactive backchanneling.
Pre-training in Deep Reinforcement Learning for Automatic Speech Recognition
Oct 24, 2019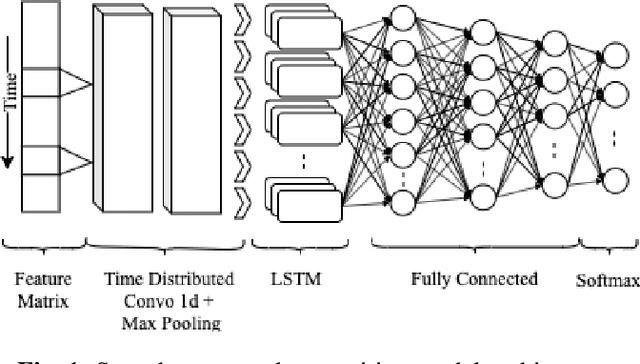

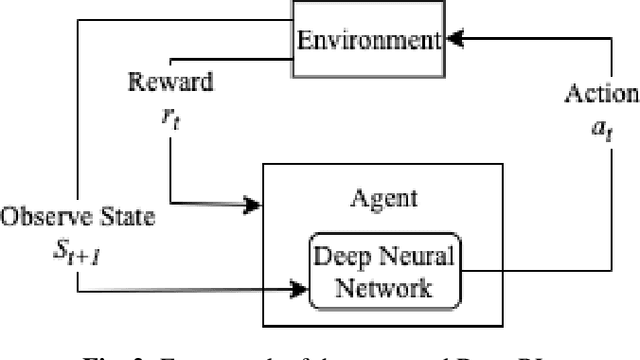
Deep reinforcement learning (deep RL) is a combination of deep learning with reinforcement learning principles to create efficient methods that can learn by interacting with its environment. This led to breakthroughs in many complex tasks that were previously difficult to solve. However, deep RL requires a large amount of training time that makes it difficult to use in various real-life applications like human-computer interaction (HCI). Therefore, in this paper, we study pre-training in deep RL to reduce the training time and improve the performance in speech recognition, a popular application of HCI. We achieve significantly improved performance in less time on a publicly available speech command recognition dataset.
cif-based collaborative decoding for end-to-end contextual speech recognition
Dec 17, 2020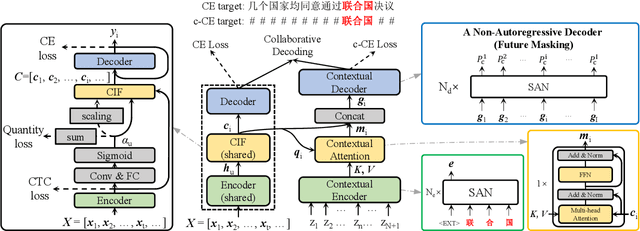
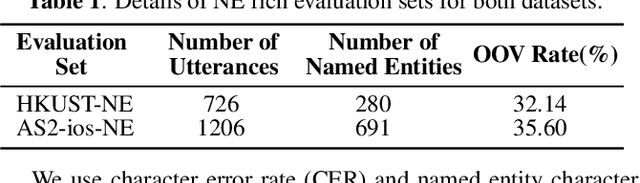
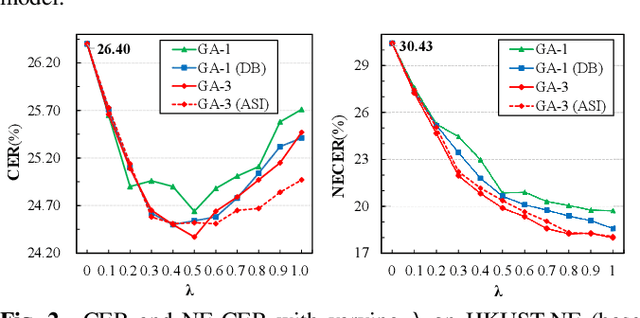
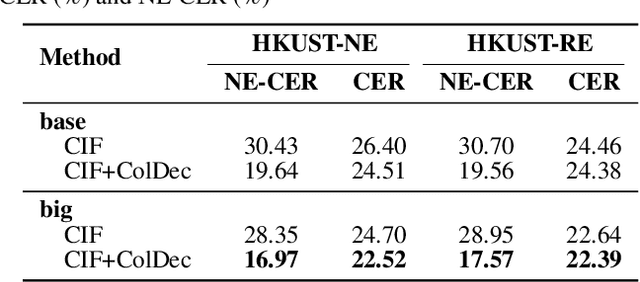
End-to-end (E2E) models have achieved promising results on multiple speech recognition benchmarks, and shown the potential to become the mainstream. However, the unified structure and the E2E training hamper injecting contextual information into them for contextual biasing. Though contextual LAS (CLAS) gives an excellent all-neural solution, the degree of biasing to given context information is not explicitly controllable. In this paper, we focus on incorporating context information into the continuous integrate-and-fire (CIF) based model that supports contextual biasing in a more controllable fashion. Specifically, an extra context processing network is introduced to extract contextual embeddings, integrate acoustically relevant context information and decode the contextual output distribution, thus forming a collaborative decoding with the decoder of the CIF-based model. Evaluated on the named entity rich evaluation sets of HKUST/AISHELL-2, our method brings relative character error rate (CER) reduction of 8.83%/21.13% and relative named entity character error rate (NE-CER) reduction of 40.14%/51.50% when compared with a strong baseline. Besides, it keeps the performance on original evaluation set without degradation.
A Hierarchical Model for Spoken Language Recognition
Jan 04, 2022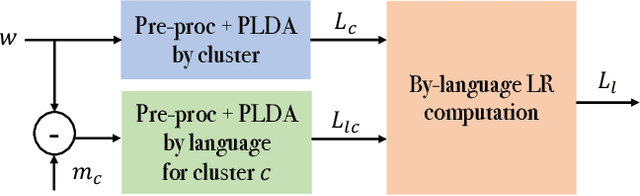
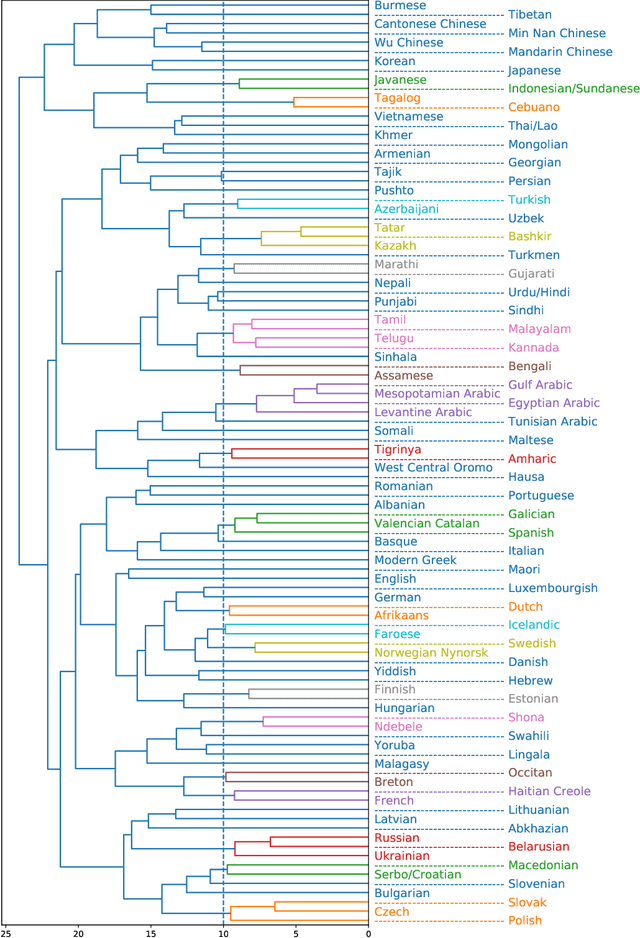
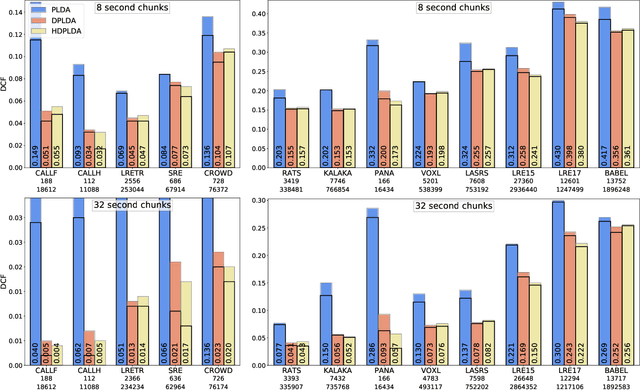
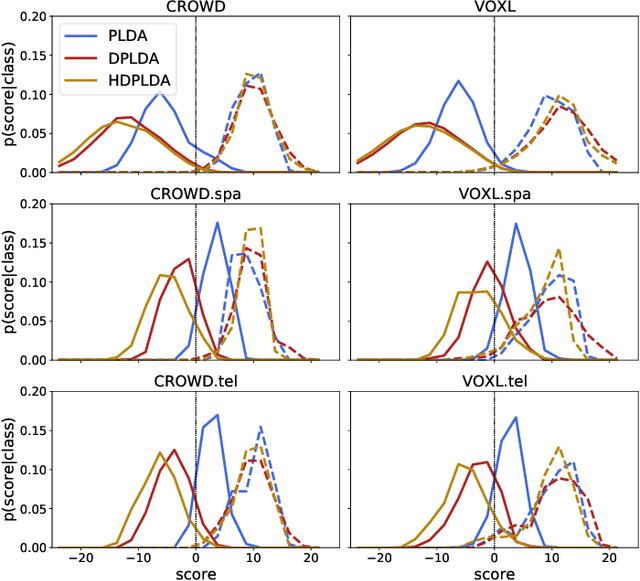
Spoken language recognition (SLR) refers to the automatic process used to determine the language present in a speech sample. SLR is an important task in its own right, for example, as a tool to analyze or categorize large amounts of multi-lingual data. Further, it is also an essential tool for selecting downstream applications in a work flow, for example, to chose appropriate speech recognition or machine translation models. SLR systems are usually composed of two stages, one where an embedding representing the audio sample is extracted and a second one which computes the final scores for each language. In this work, we approach the SLR task as a detection problem and implement the second stage as a probabilistic linear discriminant analysis (PLDA) model. We show that discriminative training of the PLDA parameters gives large gains with respect to the usual generative training. Further, we propose a novel hierarchical approach were two PLDA models are trained, one to generate scores for clusters of highly related languages and a second one to generate scores conditional to each cluster. The final language detection scores are computed as a combination of these two sets of scores. The complete model is trained discriminatively to optimize a cross-entropy objective. We show that this hierarchical approach consistently outperforms the non-hierarchical one for detection of highly related languages, in many cases by large margins. We train our systems on a collection of datasets including 100 languages and test them both on matched and mismatched conditions, showing that the gains are robust to condition mismatch.
Unsupervised Representation Learning with Future Observation Prediction for Speech Emotion Recognition
Oct 24, 2019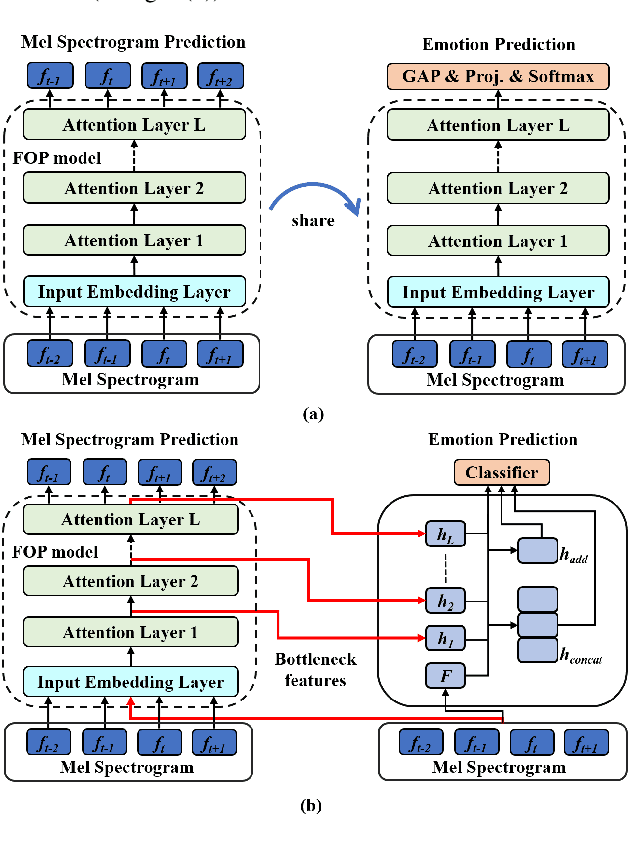

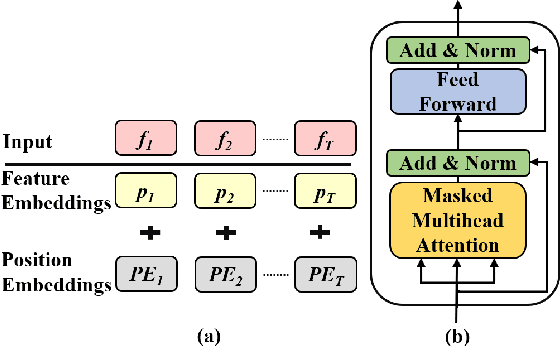
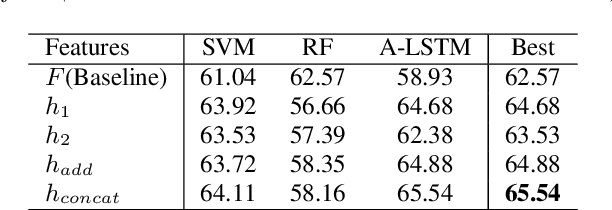
Prior works on speech emotion recognition utilize various unsupervised learning approaches to deal with low-resource samples. However, these methods pay less attention to modeling the long-term dynamic dependency, which is important for speech emotion recognition. To deal with this problem, this paper combines the unsupervised representation learning strategy -- Future Observation Prediction (FOP), with transfer learning approaches (such as Fine-tuning and Hypercolumns). To verify the effectiveness of the proposed method, we conduct experiments on the IEMOCAP database. Experimental results demonstrate that our method is superior to currently advanced unsupervised learning strategies.
Audio-Based Deep Learning Frameworks for Detecting COVID-19
Feb 10, 2022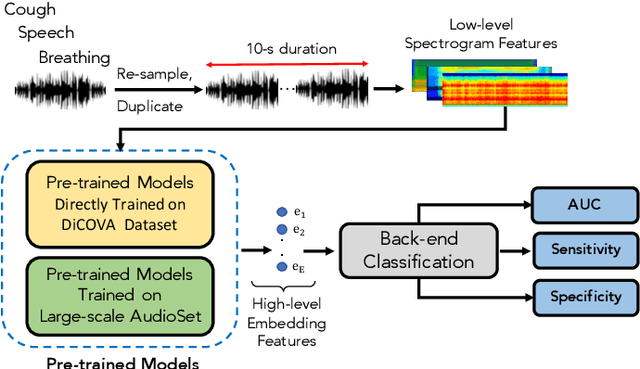

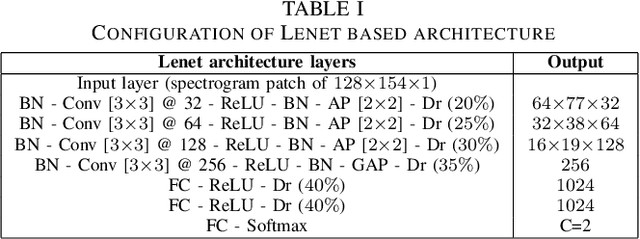
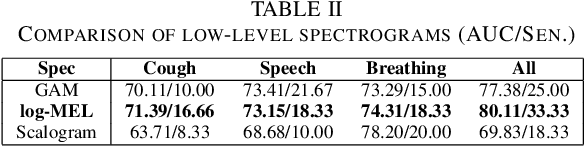
This paper evaluates a wide range of audio-based deep learning frameworks applied to the breathing, cough, and speech sounds for detecting COVID-19. In general, the audio recording inputs are transformed into low-level spectrogram features, then they are fed into pre-trained deep learning models to extract high-level embedding features. Next, the dimension of these high-level embedding features are reduced before finetuning using Light Gradient Boosting Machine (LightGBM) as a back-end classification. Our experiments on the Second DiCOVA Challenge achieved the highest Area Under the Curve (AUC), F1 score, sensitivity score, and specificity score of 89.03%, 64.41%, 63.33%, and 95.13%, respectively. Based on these scores, our method outperforms the state-of-the-art systems, and improves the challenge baseline by 4.33%, 6.00% and 8.33% in terms of AUC, F1 score and sensitivity score, respectively.
A Further Study of Unsupervised Pre-training for Transformer Based Speech Recognition
May 20, 2020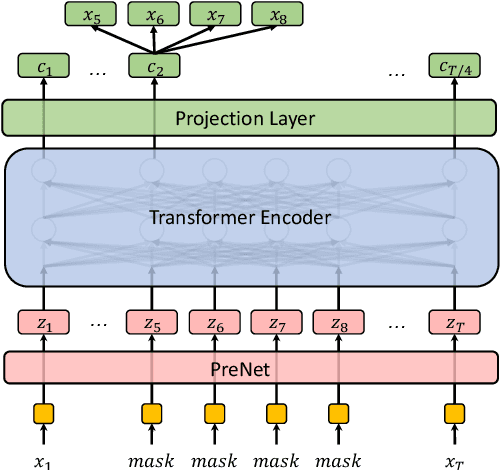

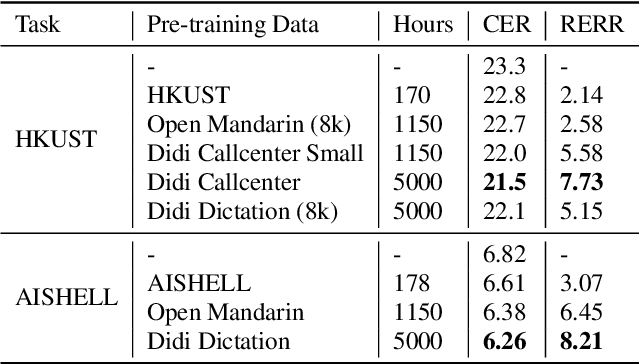
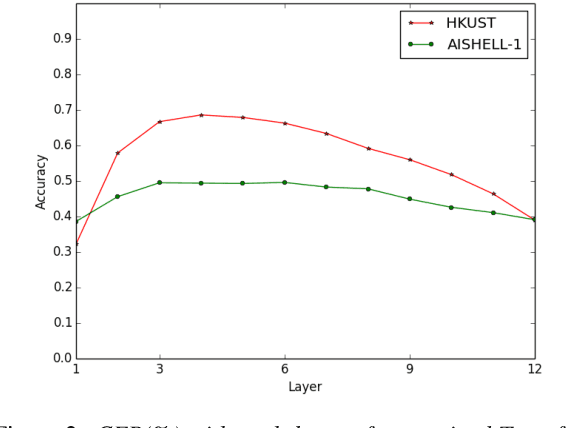
Building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, many unsupervised pre-training methods have been proposed. Among these methods, Masked Predictive Coding achieved significant improvements on various speech recognition datasets with BERT-like Masked Reconstruction loss and Transformer backbone. However, many aspects of MPC have not been fully investigated. In this paper, we conduct a further study on MPC and focus on three important aspects: the effect of pre-training data speaking style, its extension on streaming model, and how to better transfer learned knowledge from pre-training stage to downstream tasks. Experiments reveled that pre-training data with matching speaking style is more useful on downstream recognition tasks. A unified training objective with APC and MPC provided 8.46% relative error reduction on streaming model trained on HKUST. Also, the combination of target data adaption and layer-wise discriminative training helped the knowledge transfer of MPC, which achieved 3.99% relative error reduction on AISHELL over a strong baseline.
Supervised and Unsupervised Approaches for Controlling Narrow Lexical Focus in Sequence-to-Sequence Speech Synthesis
Jan 25, 2021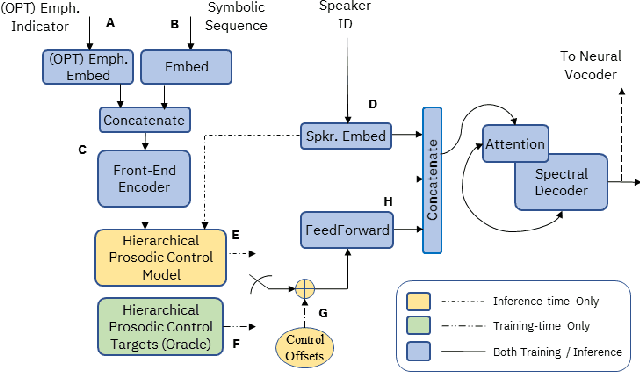
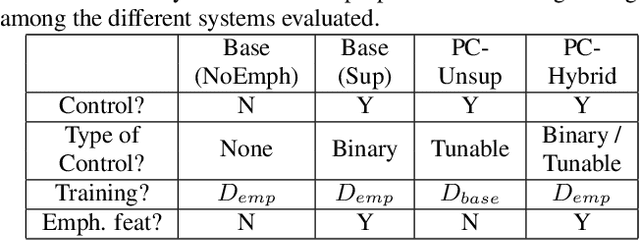
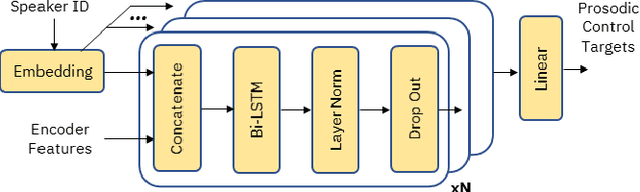
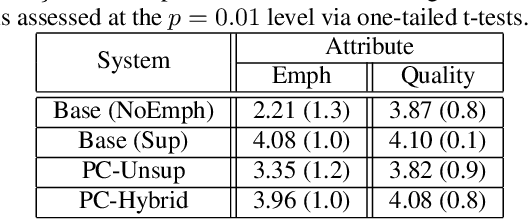
Although Sequence-to-Sequence (S2S) architectures have become state-of-the-art in speech synthesis, capable of generating outputs that approach the perceptual quality of natural samples, they are limited by a lack of flexibility when it comes to controlling the output. In this work we present a framework capable of controlling the prosodic output via a set of concise, interpretable, disentangled parameters. We apply this framework to the realization of emphatic lexical focus, proposing a variety of architectures designed to exploit different levels of supervision based on the availability of labeled resources. We evaluate these approaches via listening tests that demonstrate we are able to successfully realize controllable focus while maintaining the same, or higher, naturalness over an established baseline, and we explore how the different approaches compare when synthesizing in a target voice with or without labeled data.