 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Leveraging End-to-End Speech Recognition with Neural Architecture Search
Dec 11, 2019
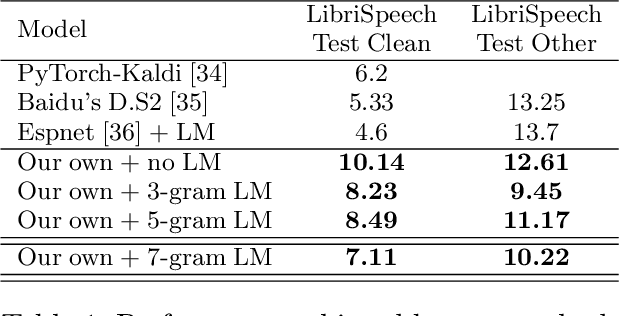
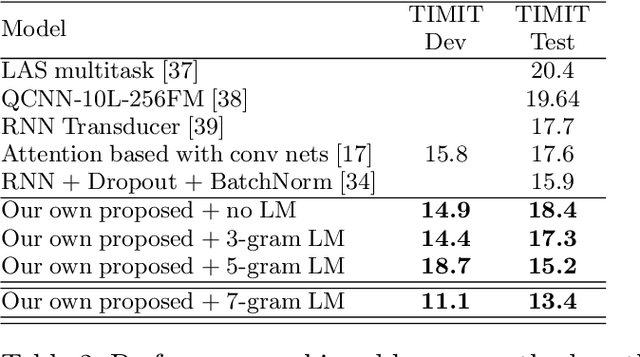

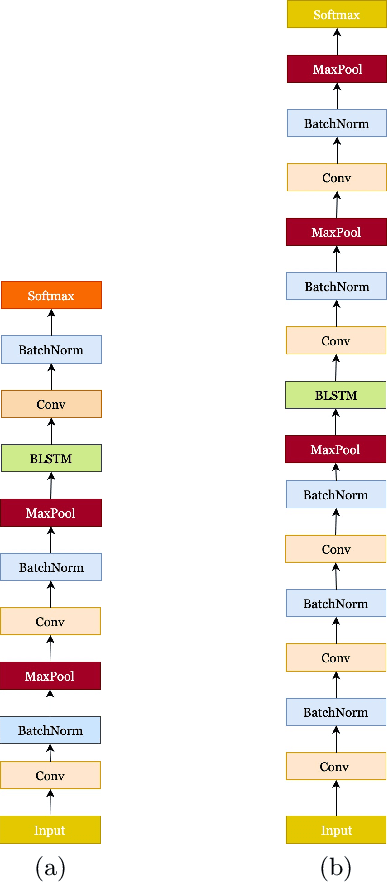
Deep neural networks (DNNs) have been demonstrated to outperform many traditional machine learning algorithms in Automatic Speech Recognition (ASR). In this paper, we show that a large improvement in the accuracy of deep speech models can be achieved with effective Neural Architecture Optimization at a very low computational cost. Phone recognition tests with the popular LibriSpeech and TIMIT benchmarks proved this fact by displaying the ability to discover and train novel candidate models within a few hours (less than a day) many times faster than the attention-based seq2seq models. Our method achieves test error of 7% Word Error Rate (WER) on the LibriSpeech corpus and 13% Phone Error Rate (PER) on the TIMIT corpus, on par with state-of-the-art results.
Lip-Reading Driven Deep Learning Approach for Speech Enhancement
Jul 31, 2018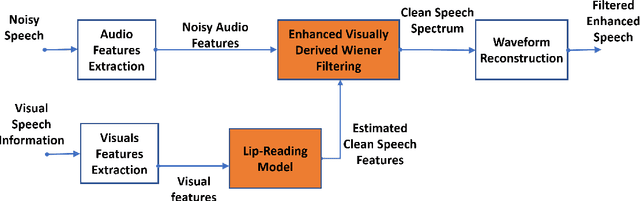
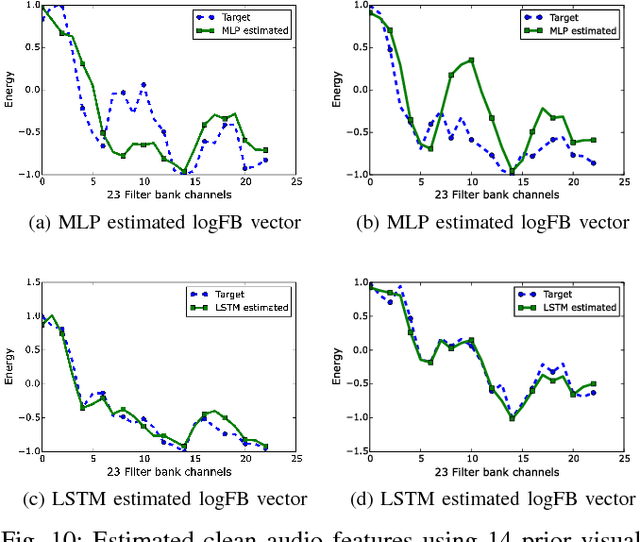
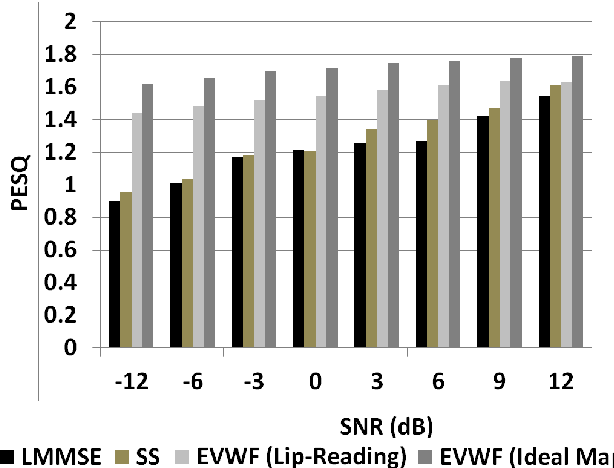
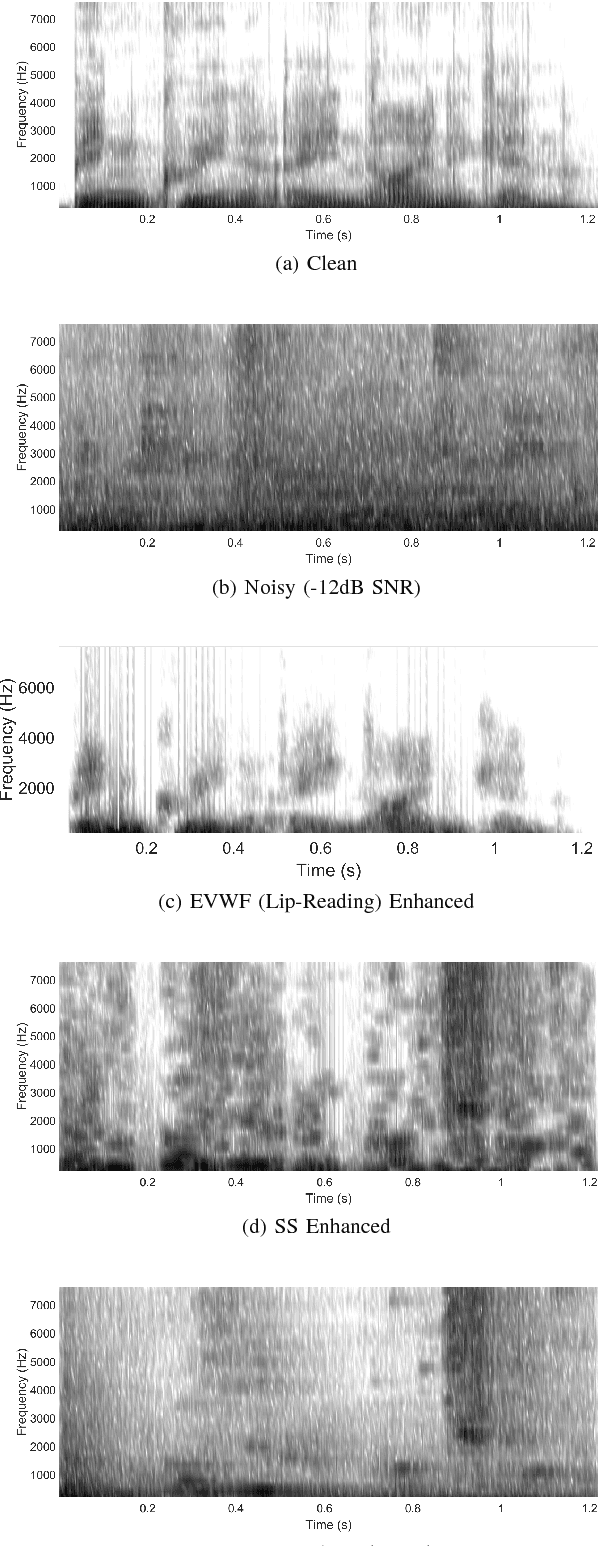
This paper proposes a novel lip-reading driven deep learning framework for speech enhancement. The proposed approach leverages the complementary strengths of both deep learning and analytical acoustic modelling (filtering based approach) as compared to recently published, comparatively simpler benchmark approaches that rely only on deep learning. The proposed audio-visual (AV) speech enhancement framework operates at two levels. In the first level, a novel deep learning-based lip-reading regression model is employed. In the second level, lip-reading approximated clean-audio features are exploited, using an enhanced, visually-derived Wiener filter (EVWF), for the clean audio power spectrum estimation. Specifically, a stacked long-short-term memory (LSTM) based lip-reading regression model is designed for clean audio features estimation using only temporal visual features considering different number of prior visual frames. For clean speech spectrum estimation, a new filterbank-domain EVWF is formulated, which exploits estimated speech features. The proposed EVWF is compared with conventional Spectral Subtraction and Log-Minimum Mean-Square Error methods using both ideal AV mapping and LSTM driven AV mapping. The potential of the proposed speech enhancement framework is evaluated under different dynamic real-world commercially-motivated scenarios (e.g. cafe, public transport, pedestrian area) at different SNR levels (ranging from low to high SNRs) using benchmark Grid and ChiME3 corpora. For objective testing, perceptual evaluation of speech quality is used to evaluate the quality of restored speech. For subjective testing, the standard mean-opinion-score method is used with inferential statistics. Comparative simulation results demonstrate significant lip-reading and speech enhancement improvement in terms of both speech quality and speech intelligibility.
Does Audio Deepfake Detection Generalize?
Mar 31, 2022
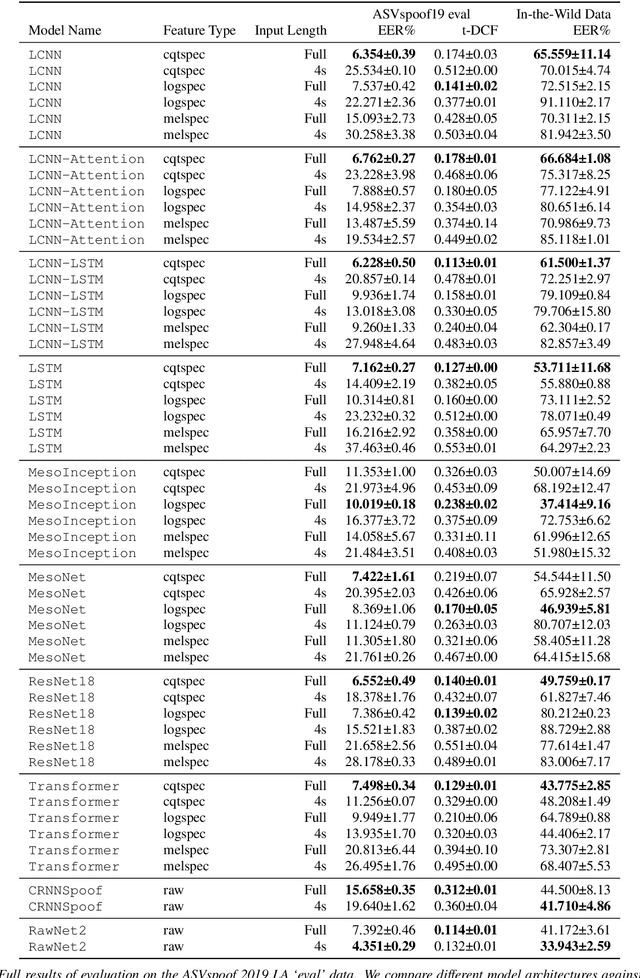
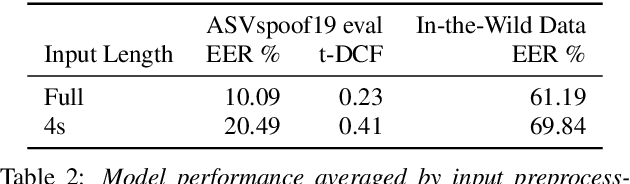
Current text-to-speech algorithms produce realistic fakes of human voices, making deepfake detection a much-needed area of research. While researchers have presented various techniques for detecting audio spoofs, it is often unclear exactly why these architectures are successful: Preprocessing steps, hyperparameter settings, and the degree of fine-tuning are not consistent across related work. Which factors contribute to success, and which are accidental? In this work, we address this problem: We systematize audio spoofing detection by re-implementing and uniformly evaluating architectures from related work. We identify overarching features for successful audio deepfake detection, such as using cqtspec or logspec features instead of melspec features, which improves performance by 37% EER on average, all other factors constant. Additionally, we evaluate generalization capabilities: We collect and publish a new dataset consisting of 37.9 hours of found audio recordings of celebrities and politicians, of which 17.2 hours are deepfakes. We find that related work performs poorly on such real-world data (performance degradation of up to one thousand percent). This may suggest that the community has tailored its solutions too closely to the prevailing ASVSpoof benchmark and that deepfakes are much harder to detect outside the lab than previously thought.
Class-Conditional Defense GAN Against End-to-End Speech Attacks
Oct 22, 2020
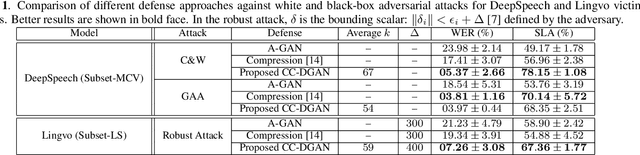

In this paper we propose a novel defense approach against end-to-end adversarial attacks developed to fool advanced speech-to-text systems such as DeepSpeech and Lingvo. Unlike conventional defense approaches, the proposed approach does not directly employ low-level transformations such as autoencoding a given input signal aiming at removing potential adversarial perturbation. Instead of that, we find an optimal input vector for a class conditional generative adversarial network through minimizing the relative chordal distance adjustment between a given test input and the generator network. Then, we reconstruct the 1D signal from the synthesized spectrogram and the original phase information derived from the given input signal. Hence, this reconstruction does not add any extra noise to the signal and according to our experimental results, our defense-GAN considerably outperforms conventional defense algorithms both in terms of word error rate and sentence level recognition accuracy.
Benchmarking and challenges in security and privacy for voice biometrics
Sep 01, 2021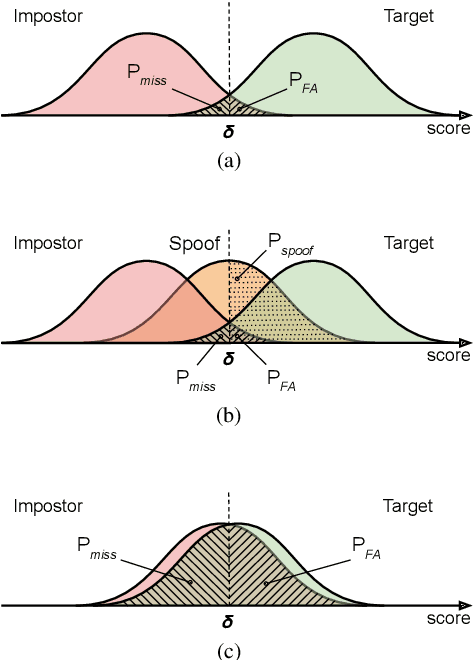
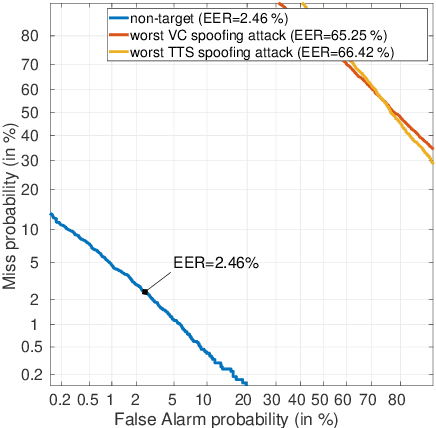
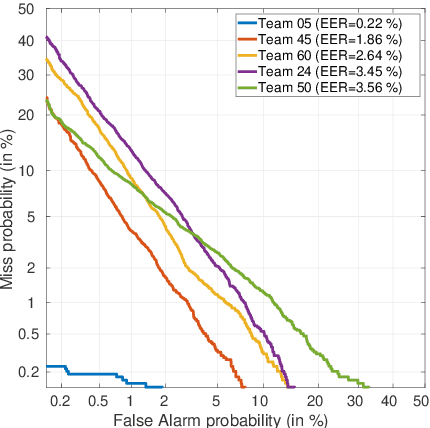
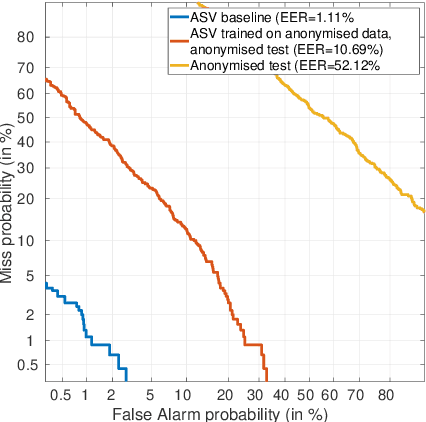
For many decades, research in speech technologies has focused upon improving reliability. With this now meeting user expectations for a range of diverse applications, speech technology is today omni-present. As result, a focus on security and privacy has now come to the fore. Here, the research effort is in its relative infancy and progress calls for greater, multidisciplinary collaboration with security, privacy, legal and ethical experts among others. Such collaboration is now underway. To help catalyse the efforts, this paper provides a high-level overview of some related research. It targets the non-speech audience and describes the benchmarking methodology that has spearheaded progress in traditional research and which now drives recent security and privacy initiatives related to voice biometrics. We describe: the ASVspoof challenge relating to the development of spoofing countermeasures; the VoicePrivacy initiative which promotes research in anonymisation for privacy preservation.
Bridging the Gap Between Monaural Speech Enhancement and Recognition with Distortion-Independent Acoustic Modeling
Mar 13, 2019
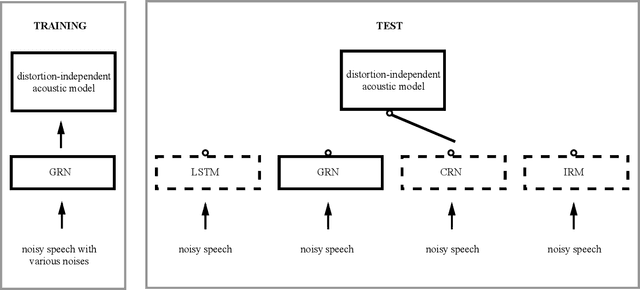
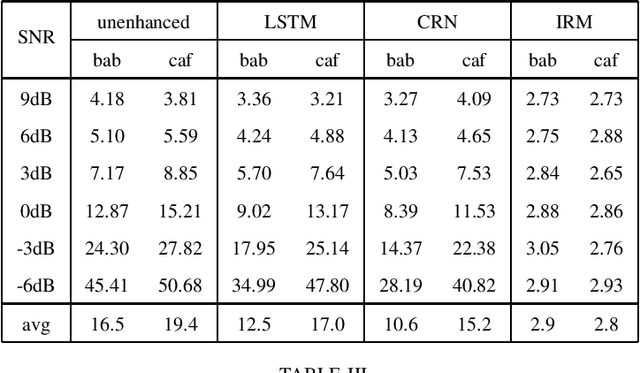
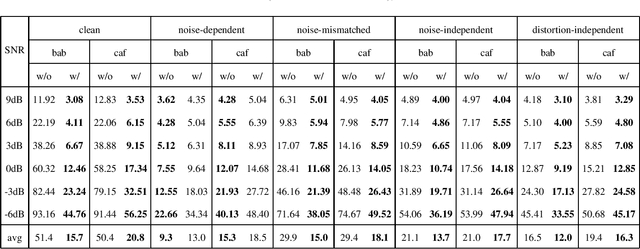
Monaural speech enhancement has made dramatic advances since the introduction of deep learning a few years ago. Although enhanced speech has been demonstrated to have better intelligibility and quality for human listeners, feeding it directly to automatic speech recognition (ASR) systems trained with noisy speech has not produced expected improvements in ASR performance. The lack of an enhancement benefit on recognition, or the gap between monaural speech enhancement and recognition, is often attributed to speech distortions introduced in the enhancement process. In this study, we analyze the distortion problem, compare different acoustic models, and investigate a distortion-independent training scheme for monaural speech recognition. Experimental results suggest that distortion-independent acoustic modeling is able to overcome the distortion problem. Such an acoustic model can also work with speech enhancement models different from the one used during training. Moreover, the models investigated in this paper outperform the previous best system on the CHiME-2 corpus.
NN3A: Neural Network supported Acoustic Echo Cancellation, Noise Suppression and Automatic Gain Control for Real-Time Communications
Oct 16, 2021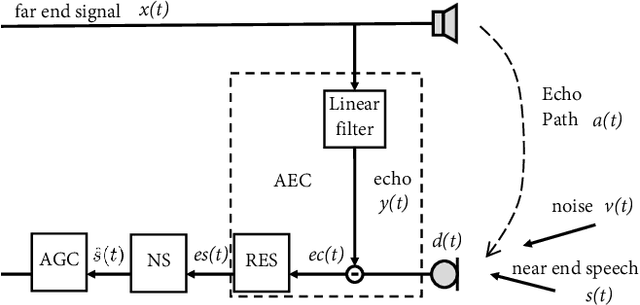
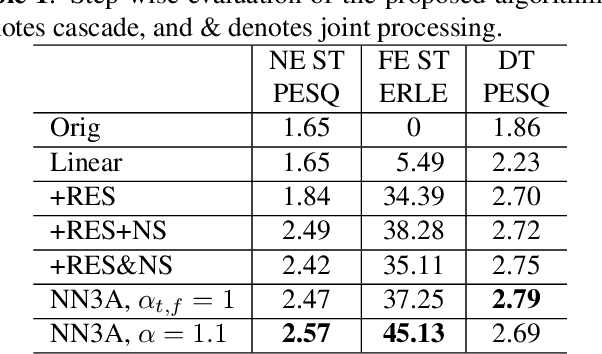
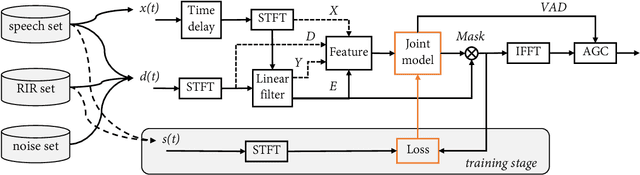
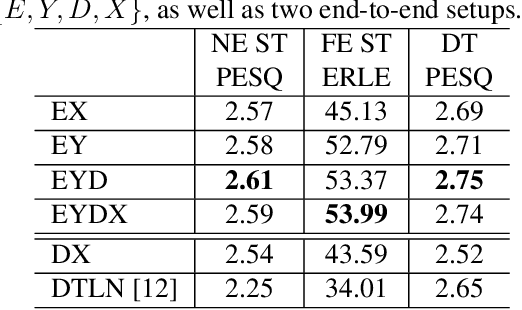
Acoustic echo cancellation (AEC), noise suppression (NS) and automatic gain control (AGC) are three often required modules for real-time communications (RTC). This paper proposes a neural network supported algorithm for RTC, namely NN3A, which incorporates an adaptive filter and a multi-task model for residual echo suppression, noise reduction and near-end speech activity detection. The proposed algorithm is shown to outperform both a method using separate models and an end-to-end alternative. It is further shown that there exists a trade-off in the model between residual suppression and near-end speech distortion, which could be balanced by a novel loss weighting function. Several practical aspects of training the joint model are also investigated to push its performance to limit.
Nonnegative HMM for Babble Noise Derived from Speech HMM: Application to Speech Enhancement
Sep 16, 2017
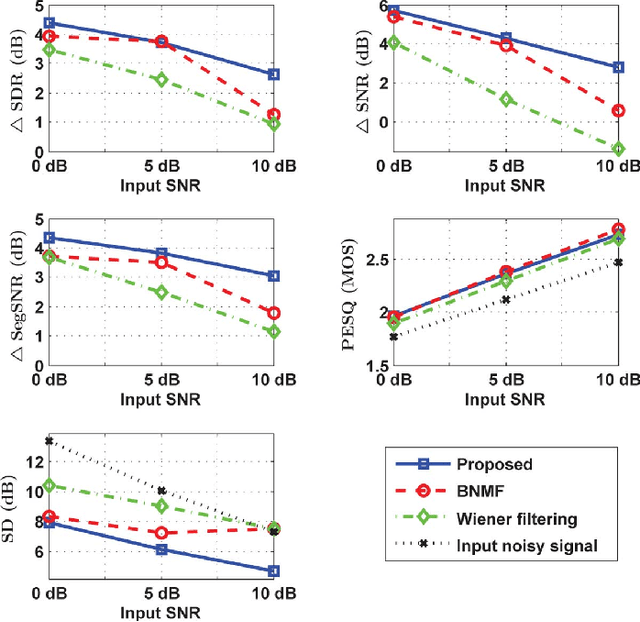
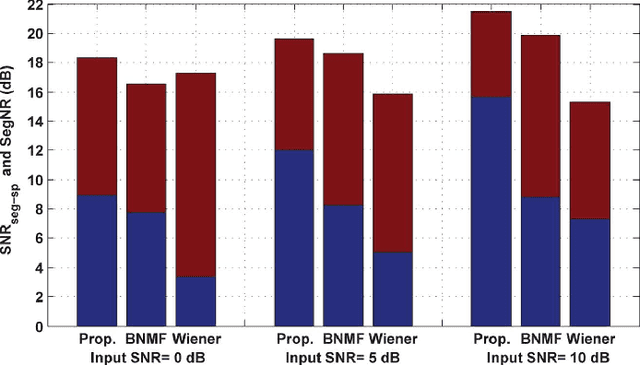
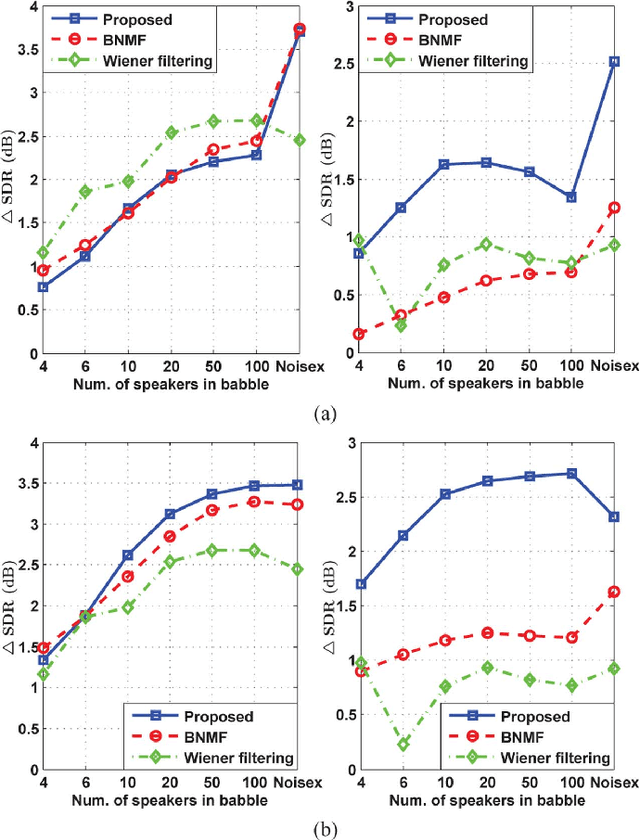
Deriving a good model for multitalker babble noise can facilitate different speech processing algorithms, e.g. noise reduction, to reduce the so-called cocktail party difficulty. In the available systems, the fact that the babble waveform is generated as a sum of N different speech waveforms is not exploited explicitly. In this paper, first we develop a gamma hidden Markov model for power spectra of the speech signal, and then formulate it as a sparse nonnegative matrix factorization (NMF). Second, the sparse NMF is extended by relaxing the sparsity constraint, and a novel model for babble noise (gamma nonnegative HMM) is proposed in which the babble basis matrix is the same as the speech basis matrix, and only the activation factors (weights) of the basis vectors are different for the two signals over time. Finally, a noise reduction algorithm is proposed using the derived speech and babble models. All of the stationary model parameters are estimated using the expectation-maximization (EM) algorithm, whereas the time-varying parameters, i.e. the gain parameters of speech and babble signals, are estimated using a recursive EM algorithm. The objective and subjective listening evaluations show that the proposed babble model and the final noise reduction algorithm significantly outperform the conventional methods.
Pre-training in Deep Reinforcement Learning for Automatic Speech Recognition
Oct 26, 2019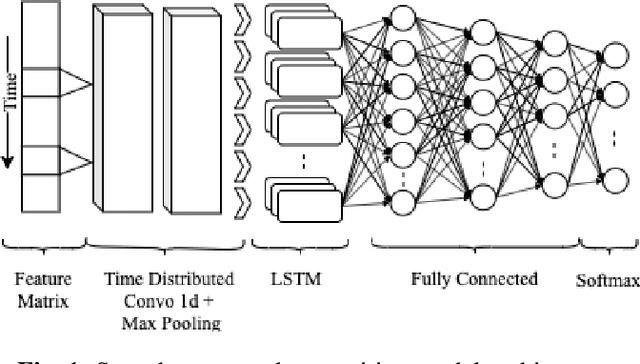

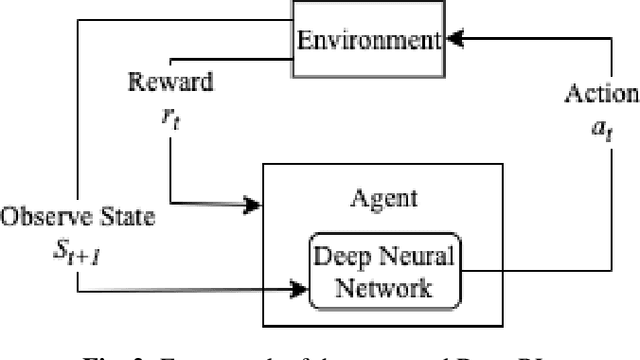
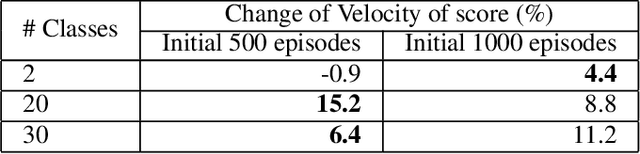
Deep reinforcement learning (deep RL) is a combination of deep learning with reinforcement learning principles to create efficient methods that can learn by interacting with its environment. This led to breakthroughs in many complex tasks that were previously difficult to solve. However, deep RL requires a large amount of training time that makes it difficult to use in various real-life applications like human-computer interaction (HCI). Therefore, in this paper, we study pre-training in deep RL to reduce the training time and improve the performance in speech recognition, a popular application of HCI. We achieve significantly improved performance in less time on a publicly available speech command recognition dataset.
Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining
Dec 14, 2019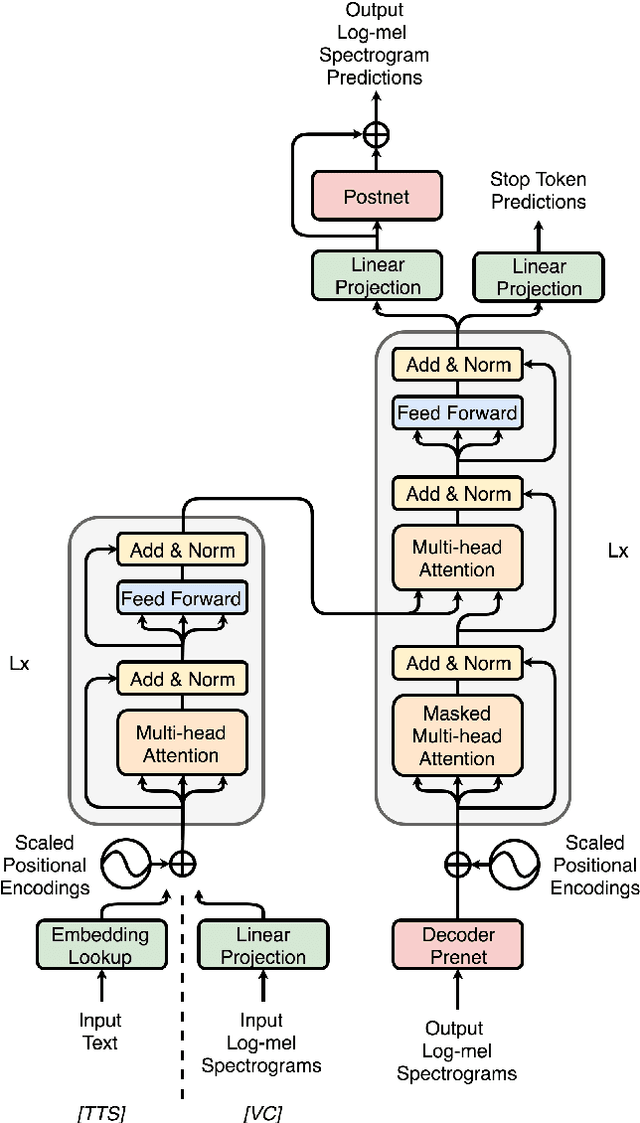
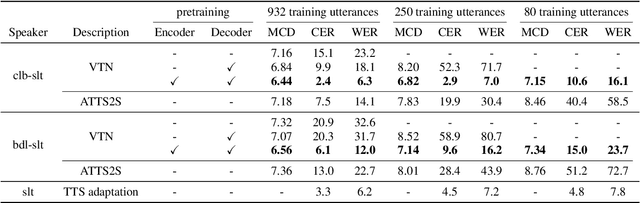
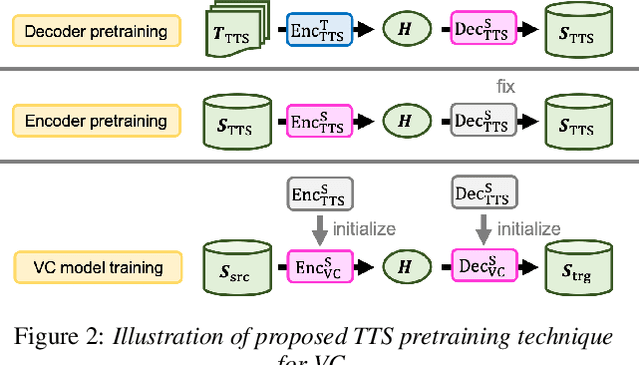
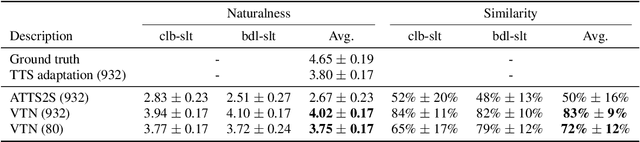
We introduce a novel sequence-to-sequence (seq2seq) voice conversion (VC) model based on the Transformer architecture with text-to-speech (TTS) pretraining. Seq2seq VC models are attractive owing to their ability to convert prosody. While seq2seq models based on recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been successfully applied to VC, the use of the Transformer network, which has shown promising results in various speech processing tasks, has not yet been investigated. Nonetheless, their data-hungry property and the mispronunciation of converted speech make seq2seq models far from practical. To this end, we propose a simple yet effective pretraining technique to transfer knowledge from learned TTS models, which benefit from large-scale, easily accessible TTS corpora. VC models initialized with such pretrained model parameters are able to generate effective hidden representations for high-fidelity, highly intelligible converted speech. Experimental results show that such a pretraining scheme can facilitate data-efficient training and outperform an RNN-based seq2seq VC model in terms of intelligibility, naturalness, and similarity.