 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Hierarchical Summarization for Longform Spoken Dialog
Aug 21, 2021
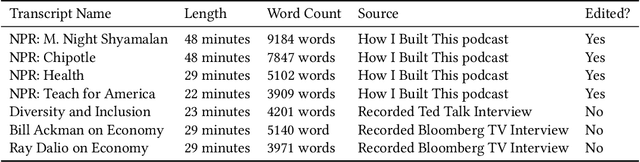
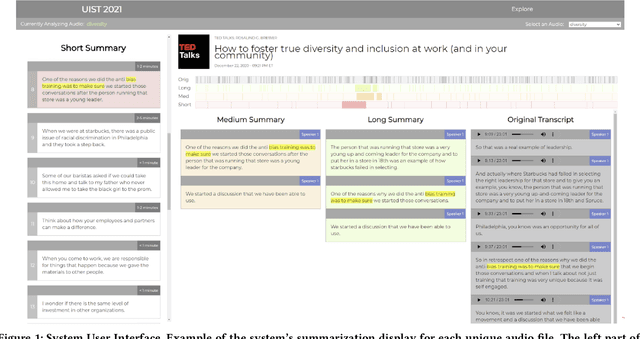

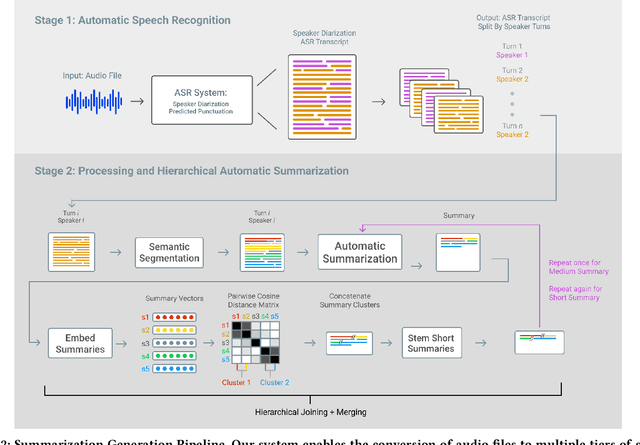
Every day we are surrounded by spoken dialog. This medium delivers rich diverse streams of information auditorily; however, systematically understanding dialog can often be non-trivial. Despite the pervasiveness of spoken dialog, automated speech understanding and quality information extraction remains markedly poor, especially when compared to written prose. Furthermore, compared to understanding text, auditory communication poses many additional challenges such as speaker disfluencies, informal prose styles, and lack of structure. These concerns all demonstrate the need for a distinctly speech tailored interactive system to help users understand and navigate the spoken language domain. While individual automatic speech recognition (ASR) and text summarization methods already exist, they are imperfect technologies; neither consider user purpose and intent nor address spoken language induced complications. Consequently, we design a two stage ASR and text summarization pipeline and propose a set of semantic segmentation and merging algorithms to resolve these speech modeling challenges. Our system enables users to easily browse and navigate content as well as recover from errors in these underlying technologies. Finally, we present an evaluation of the system which highlights user preference for hierarchical summarization as a tool to quickly skim audio and identify content of interest to the user.
HEAR 2021: Holistic Evaluation of Audio Representations
Mar 06, 2022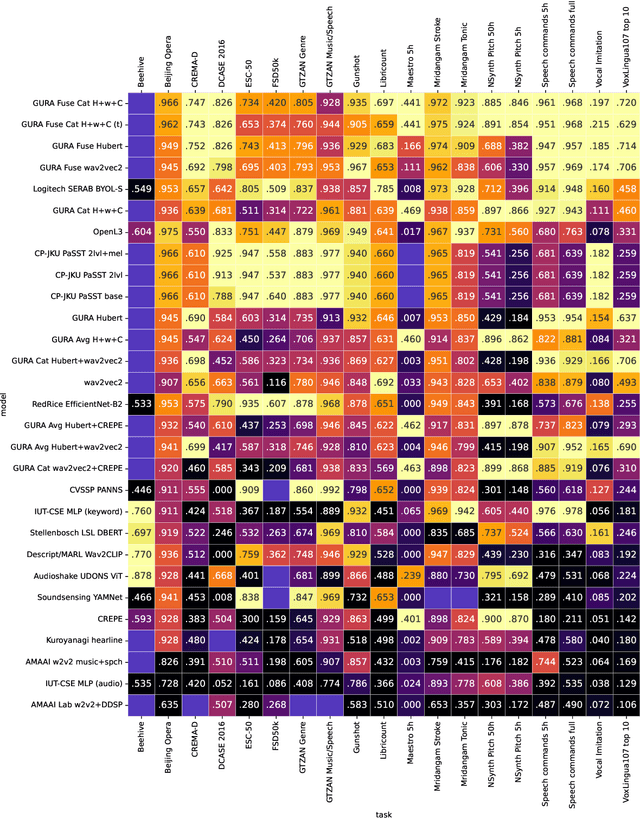
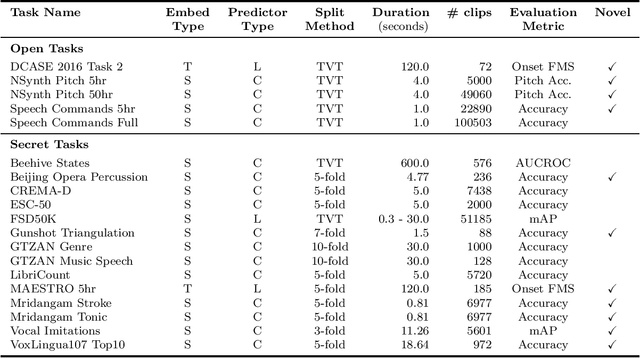

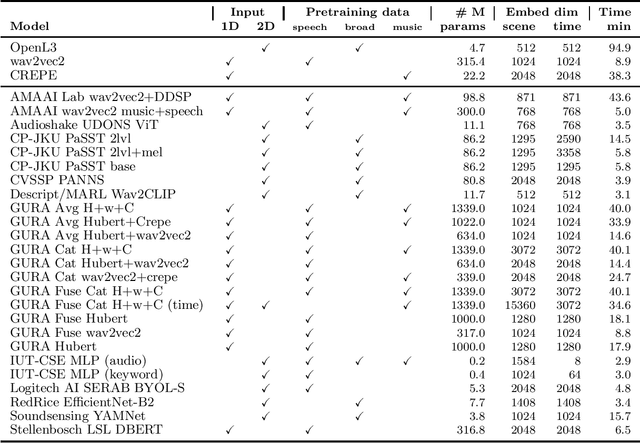
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
Not always about you: Prioritizing community needs when developing endangered language technology
Apr 12, 2022

Languages are classified as low-resource when they lack the quantity of data necessary for training statistical and machine learning tools and models. Causes of resource scarcity vary but can include poor access to technology for developing these resources, a relatively small population of speakers, or a lack of urgency for collecting such resources in bilingual populations where the second language is high-resource. As a result, the languages described as low-resource in the literature are as different as Finnish on the one hand, with millions of speakers using it in every imaginable domain, and Seneca, with only a small-handful of fluent speakers using the language primarily in a restricted domain. While issues stemming from the lack of resources necessary to train models unite this disparate group of languages, many other issues cut across the divide between widely-spoken low resource languages and endangered languages. In this position paper, we discuss the unique technological, cultural, practical, and ethical challenges that researchers and indigenous speech community members face when working together to develop language technology to support endangered language documentation and revitalization. We report the perspectives of language teachers, Master Speakers and elders from indigenous communities, as well as the point of view of academics. We describe an ongoing fruitful collaboration and make recommendations for future partnerships between academic researchers and language community stakeholders.
Leveraging Multi-domain, Heterogeneous Data using Deep Multitask Learning for Hate Speech Detection
Mar 23, 2021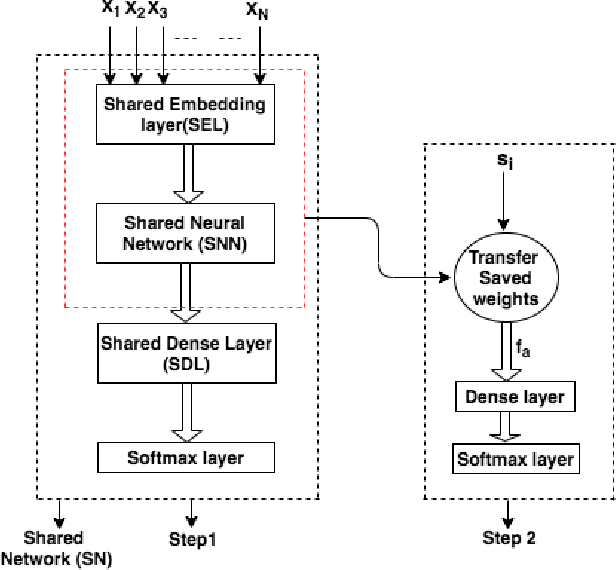

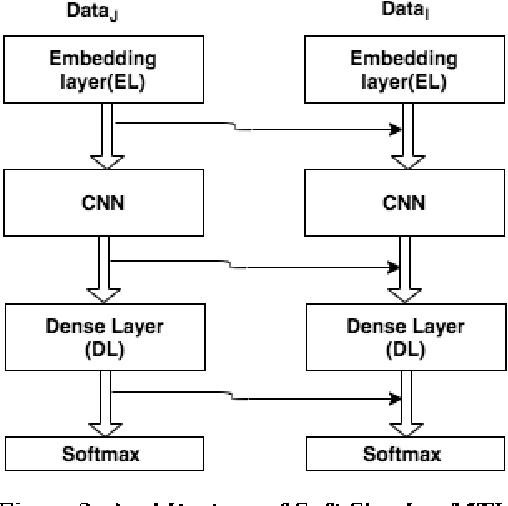
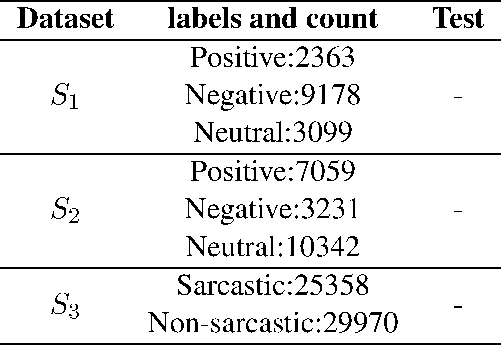
With the exponential rise in user-generated web content on social media, the proliferation of abusive languages towards an individual or a group across the different sections of the internet is also rapidly increasing. It is very challenging for human moderators to identify the offensive contents and filter those out. Deep neural networks have shown promise with reasonable accuracy for hate speech detection and allied applications. However, the classifiers are heavily dependent on the size and quality of the training data. Such a high-quality large data set is not easy to obtain. Moreover, the existing data sets that have emerged in recent times are not created following the same annotation guidelines and are often concerned with different types and sub-types related to hate. To solve this data sparsity problem, and to obtain more global representative features, we propose a Convolution Neural Network (CNN) based multi-task learning models (MTLs)\footnote{code is available at https://github.com/imprasshant/STL-MTL} to leverage information from multiple sources. Empirical analysis performed on three benchmark datasets shows the efficacy of the proposed approach with the significant improvement in accuracy and F-score to obtain state-of-the-art performance with respect to the existing systems.
Visually grounded cross-lingual keyword spotting in speech
Jun 13, 2018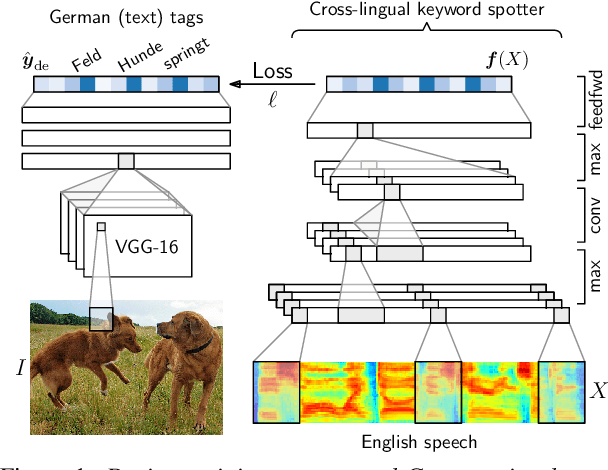

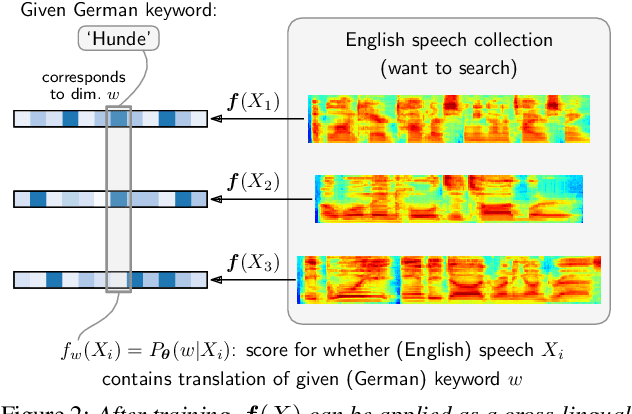
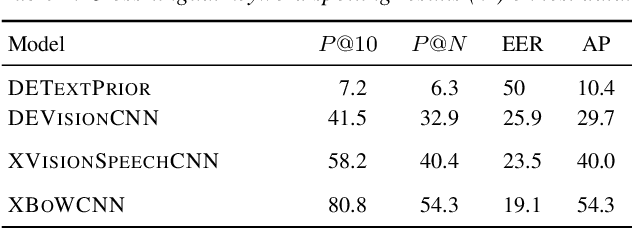
Recent work considered how images paired with speech can be used as supervision for building speech systems when transcriptions are not available. We ask whether visual grounding can be used for cross-lingual keyword spotting: given a text keyword in one language, the task is to retrieve spoken utterances containing that keyword in another language. This could enable searching through speech in a low-resource language using text queries in a high-resource language. As a proof-of-concept, we use English speech with German queries: we use a German visual tagger to add keyword labels to each training image, and then train a neural network to map English speech to German keywords. Without seeing parallel speech-transcriptions or translations, the model achieves a precision at ten of 58%. We show that most erroneous retrievals contain equivalent or semantically relevant keywords; excluding these would improve P@10 to 91%.
Detecting Abusive Albanian
Jul 30, 2021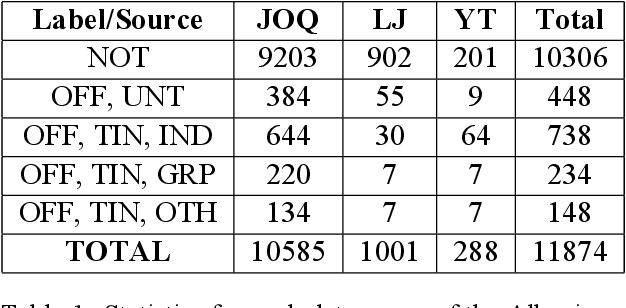
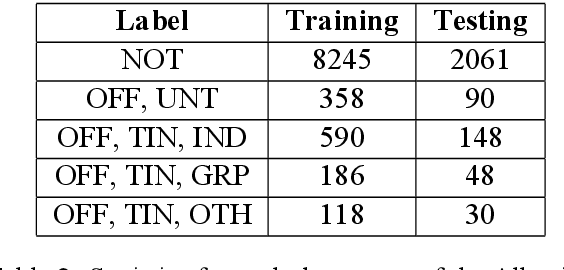
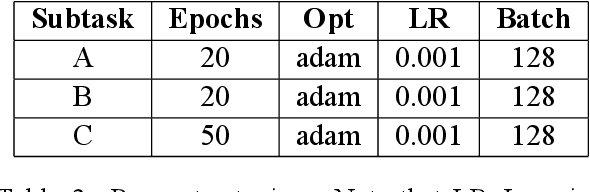
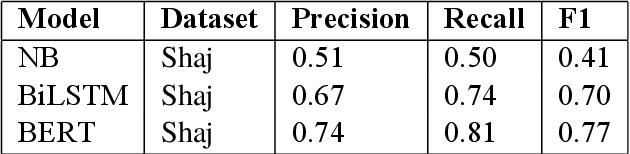
The ever growing usage of social media in the recent years has had a direct impact on the increased presence of hate speech and offensive speech in online platforms. Research on effective detection of such content has mainly focused on English and a few other widespread languages, while the leftover majority fail to have the same work put into them and thus cannot benefit from the steady advancements made in the field. In this paper we present \textsc{Shaj}, an annotated Albanian dataset for hate speech and offensive speech that has been constructed from user-generated content on various social media platforms. Its annotation follows the hierarchical schema introduced in OffensEval. The dataset is tested using three different classification models, the best of which achieves an F1 score of 0.77 for the identification of offensive language, 0.64 F1 score for the automatic categorization of offensive types and lastly, 0.52 F1 score for the offensive language target identification.
STFT spectral loss for training a neural speech waveform model
Oct 30, 2018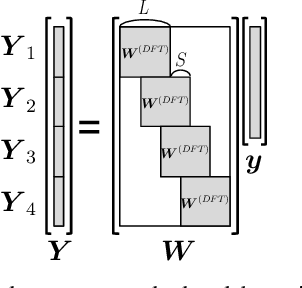
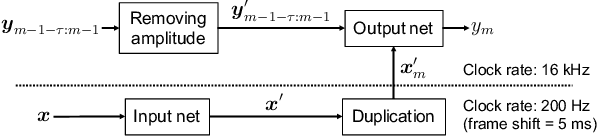
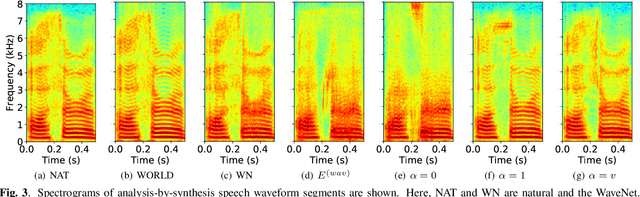
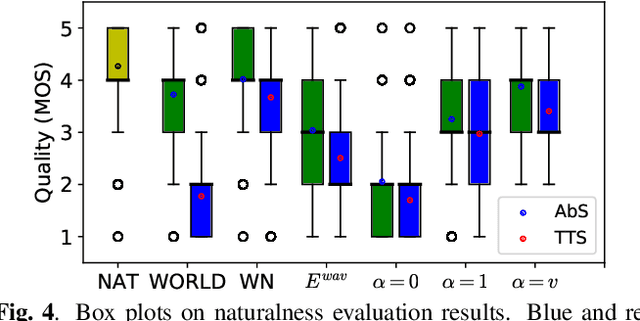
This paper proposes a new loss using short-time Fourier transform (STFT) spectra for the aim of training a high-performance neural speech waveform model that predicts raw continuous speech waveform samples directly. Not only amplitude spectra but also phase spectra obtained from generated speech waveforms are used to calculate the proposed loss. We also mathematically show that training of the waveform model on the basis of the proposed loss can be interpreted as maximum likelihood training that assumes the amplitude and phase spectra of generated speech waveforms following Gaussian and von Mises distributions, respectively. Furthermore, this paper presents a simple network architecture as the speech waveform model, which is composed of uni-directional long short-term memories (LSTMs) and an auto-regressive structure. Experimental results showed that the proposed neural model synthesized high-quality speech waveforms.
Understanding the visual speech signal
Oct 03, 2017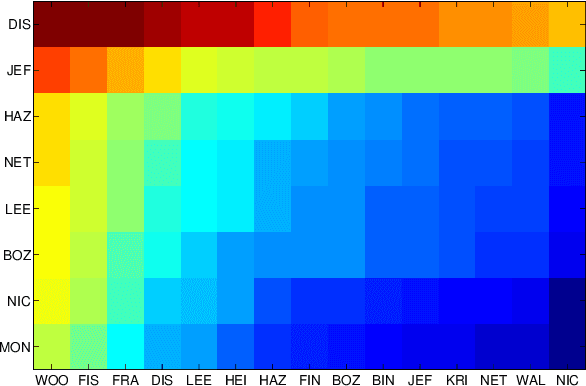
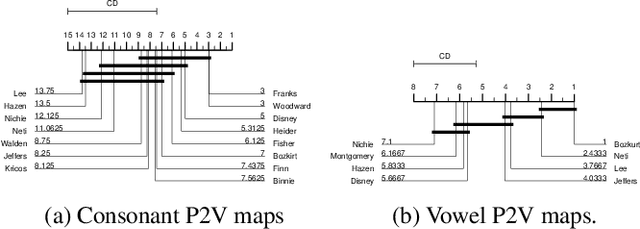
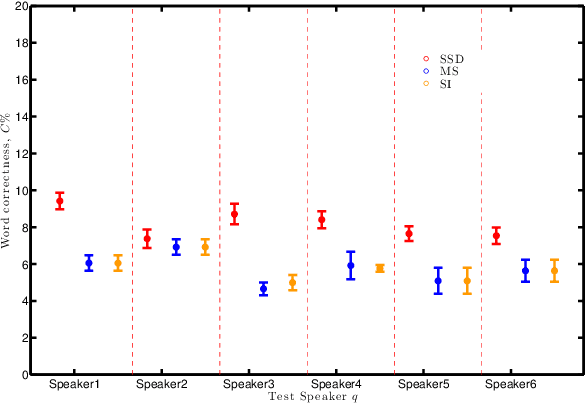
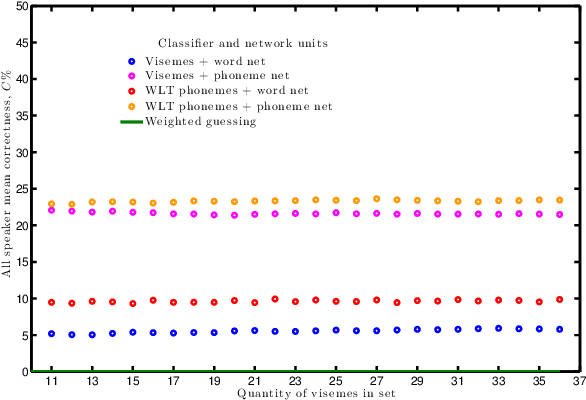
For machines to lipread, or understand speech from lip movement, they decode lip-motions (known as visemes) into the spoken sounds. We investigate the visual speech channel to further our understanding of visemes. This has applications beyond machine lipreading; speech therapists, animators, and psychologists can benefit from this work. We explain the influence of speaker individuality, and demonstrate how one can use visemes to boost lipreading.
Online End-to-End Neural Diarization Handling Overlapping Speech and Flexible Numbers of Speakers
Jan 21, 2021
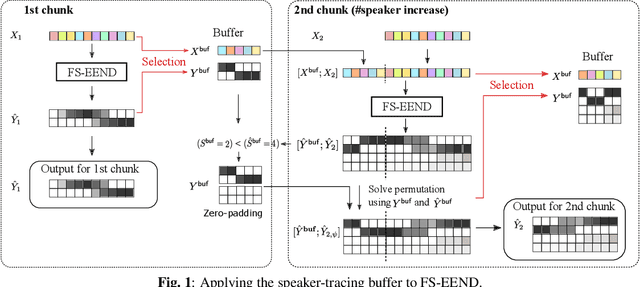


This paper proposes an online end-to-end diarization that can handle overlapping speech and flexible numbers of speakers. The end-to-end neural speaker diarization (EEND) model has already achieved significant improvement when compared with conventional clustering-based methods. However, the original EEND has two limitations: i) EEND does not perform well in online scenarios; ii) the number of speakers must be fixed in advance. This paper solves both problems by applying a modified extension of the speaker-tracing buffer method that deals with variable numbers of speakers. Experiments on CALLHOME and DIHARD II datasets show that the proposed online method achieves comparable performance to the offline EEND method. Compared with the state-of-the-art online method based on a fully supervised approach (UIS-RNN), the proposed method shows better performance on the DIHARD II dataset.
Direction of Arrival Estimation of Noisy Speech Using Convolutional Recurrent Neural Networks with Higher-Order Ambisonics Signals
Mar 01, 2021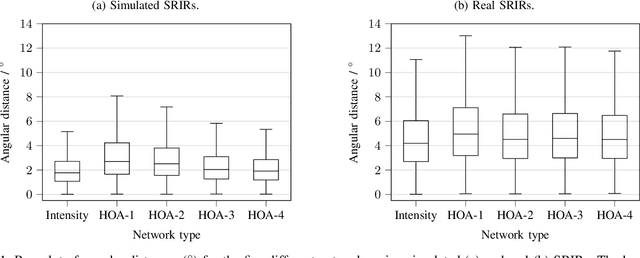
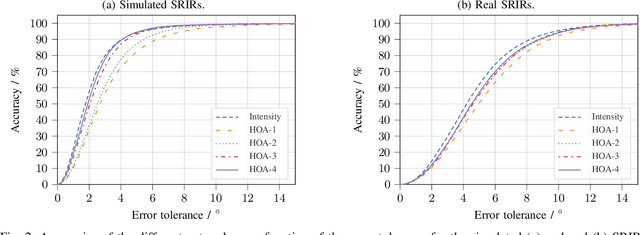
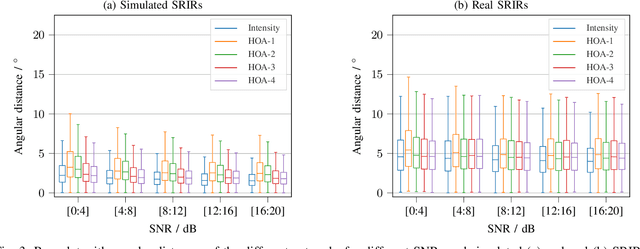
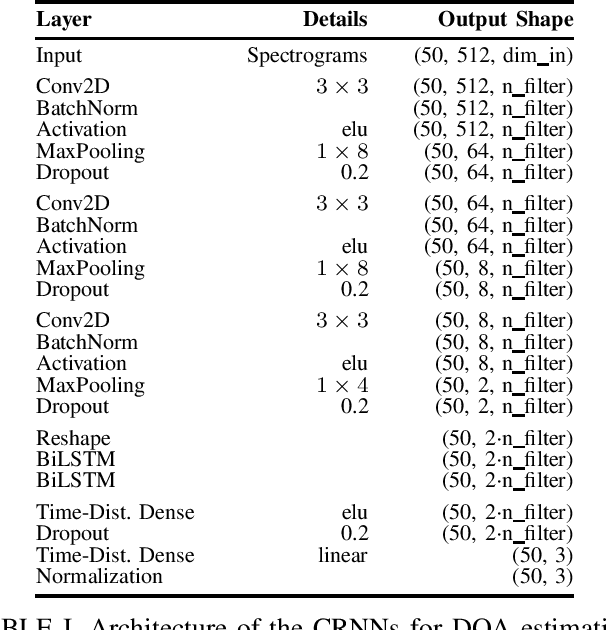
Training convolutional recurrent neural networks on first-order Ambisonics signals is a well-known approach when estimating the direction of arrival for speech/sound signals. In this work, we investigate whether increasing the order of Ambisonics up to the fourth order further improves the estimation performance of convolutional recurrent neural networks. While our results on data based on simulated spatial room impulse responses show that the use of higher Ambisonics orders does have the potential to provide better localization results, no further improvement was shown on data based on real spatial room impulse responses from order two onwards. Rather, it seems to be crucial to extract meaningful features from the raw data. First order features derived from the acoustic intensity vector were superior to pure higher-order magnitude and phase features in almost all scenarios.