 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A wearable sensor vest for social humanoid robots with GPGPU, IoT, and modular software architecture
Jan 06, 2022
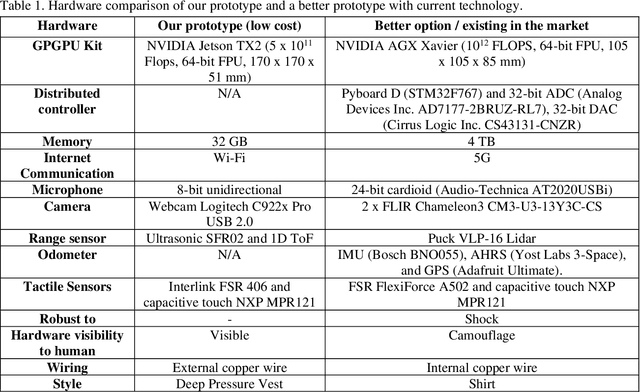

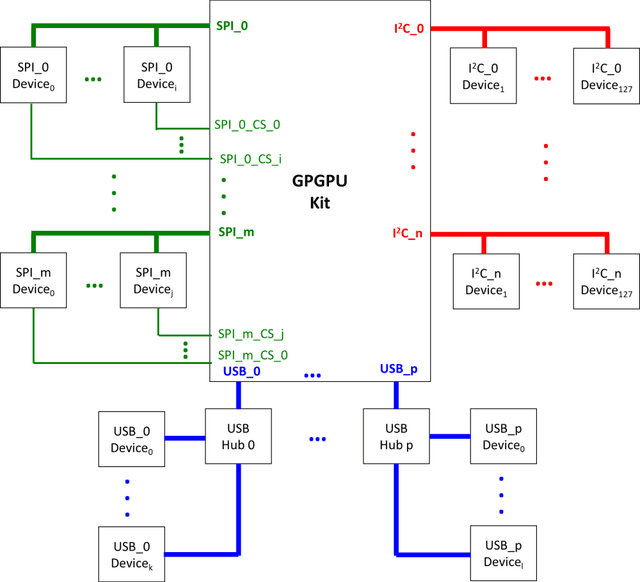
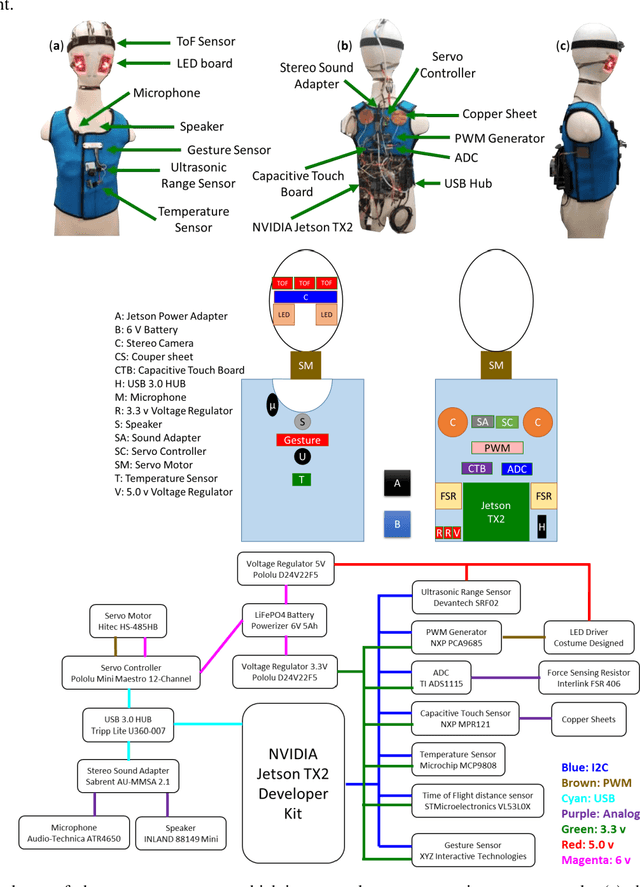
Currently, most social robots interact with their surroundings and humans through sensors that are integral parts of the robots, which limits the usability of the sensors, human-robot interaction, and interchangeability. A wearable sensor garment that fits many robots is needed in many applications. This article presents an affordable wearable sensor vest, and an open-source software architecture with the Internet of Things (IoT) for social humanoid robots. The vest consists of touch, temperature, gesture, distance, vision sensors, and a wireless communication module. The IoT feature allows the robot to interact with humans locally and over the Internet. The designed architecture works for any social robot that has a general-purpose graphics processing unit (GPGPU), I2C/SPI buses, Internet connection, and the Robotics Operating System (ROS). The modular design of this architecture enables developers to easily add/remove/update complex behaviors. The proposed software architecture provides IoT technology, GPGPU nodes, I2C and SPI bus mangers, audio-visual interaction nodes (speech to text, text to speech, and image understanding), and isolation between behavior nodes and other nodes. The proposed IoT solution consists of related nodes in the robot, a RESTful web service, and user interfaces. We used the HTTP protocol as a means of two-way communication with the social robot over the Internet. Developers can easily edit or add nodes in C, C++, and Python programming languages. Our architecture can be used for designing more sophisticated behaviors for social humanoid robots.
* This is the preprint version. The final version is published in Robotics and Autonomous Systems, Volume 139, 2021, Page 103536, ISSN 0921-8890, https://doi.org/10.1016/j.robot.2020.103536
Leveraging Multi-domain, Heterogeneous Data using Deep Multitask Learning for Hate Speech Detection
Mar 23, 2021

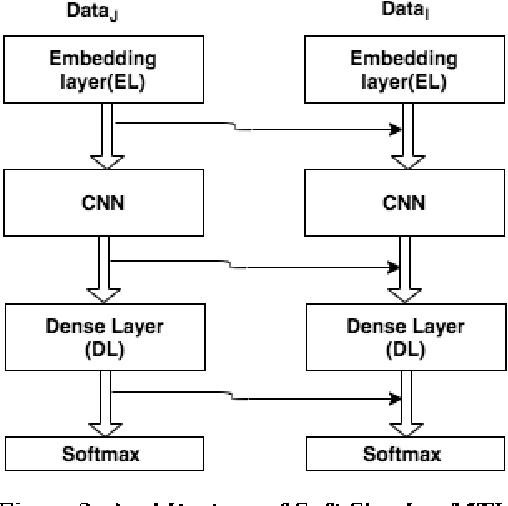
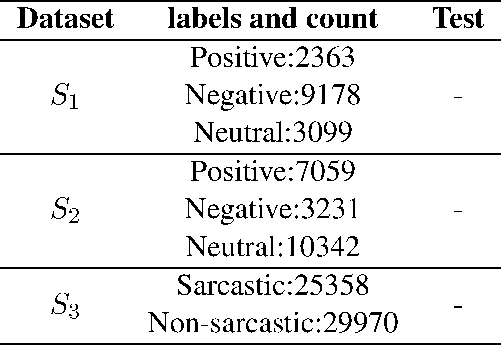
With the exponential rise in user-generated web content on social media, the proliferation of abusive languages towards an individual or a group across the different sections of the internet is also rapidly increasing. It is very challenging for human moderators to identify the offensive contents and filter those out. Deep neural networks have shown promise with reasonable accuracy for hate speech detection and allied applications. However, the classifiers are heavily dependent on the size and quality of the training data. Such a high-quality large data set is not easy to obtain. Moreover, the existing data sets that have emerged in recent times are not created following the same annotation guidelines and are often concerned with different types and sub-types related to hate. To solve this data sparsity problem, and to obtain more global representative features, we propose a Convolution Neural Network (CNN) based multi-task learning models (MTLs)\footnote{code is available at https://github.com/imprasshant/STL-MTL} to leverage information from multiple sources. Empirical analysis performed on three benchmark datasets shows the efficacy of the proposed approach with the significant improvement in accuracy and F-score to obtain state-of-the-art performance with respect to the existing systems.
A Context-Aware Feature Fusion Framework for Punctuation Restoration
Mar 23, 2022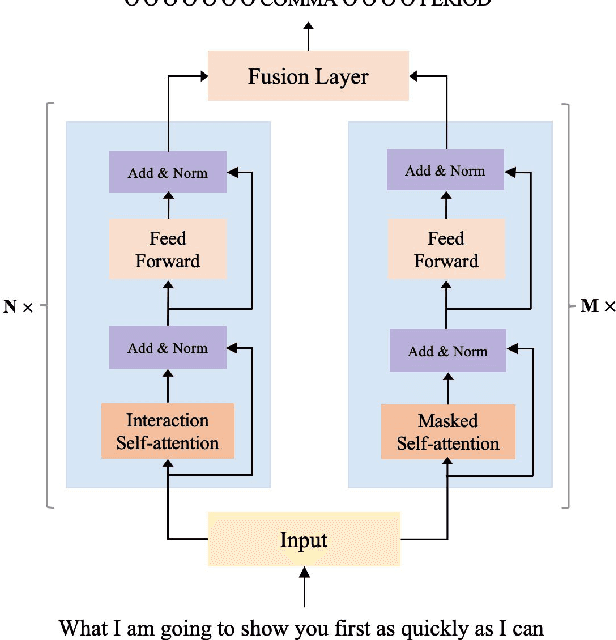
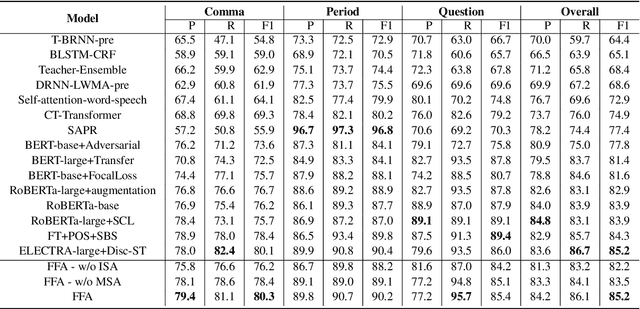
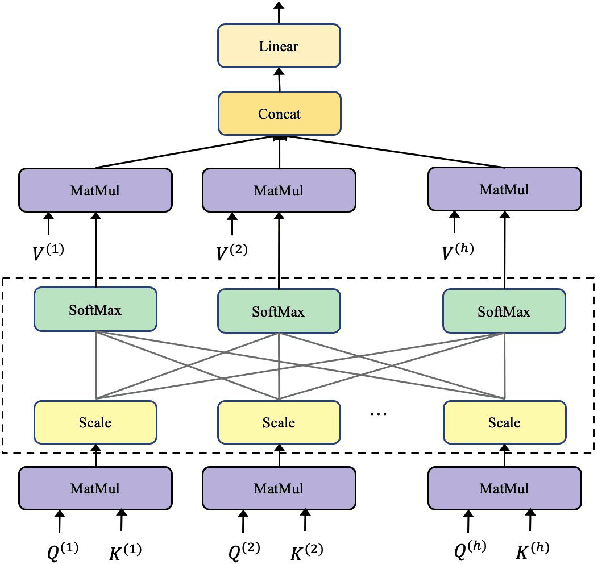
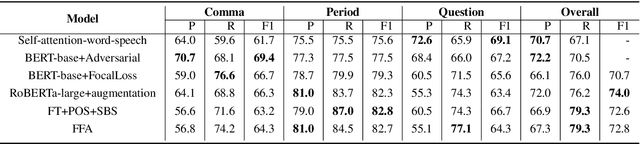
To accomplish the punctuation restoration task, most existing approaches focused on leveraging extra information (e.g., part-of-speech tags) or addressing the class imbalance problem. Recent works have widely applied the transformer-based language models and significantly improved their effectiveness. To the best of our knowledge, an inherent issue has remained neglected: the attention of individual heads in the transformer will be diluted or powerless while feeding the long non-punctuation utterances. Since those previous contexts, not the followings, are comparatively more valuable to the current position, it's hard to achieve a good balance by independent attention. In this paper, we propose a novel Feature Fusion framework based on two-type Attentions (FFA) to alleviate the shortage. It introduces a two-stream architecture. One module involves interaction between attention heads to encourage the communication, and another masked attention module captures the dependent feature representation. Then, it aggregates two feature embeddings to fuse information and enhances context-awareness. The experiments on the popular benchmark dataset IWSLT demonstrate that our approach is effective. Without additional data, it obtains comparable performance to the current state-of-the-art models.
Enrollment-less training for personalized voice activity detection
Jun 23, 2021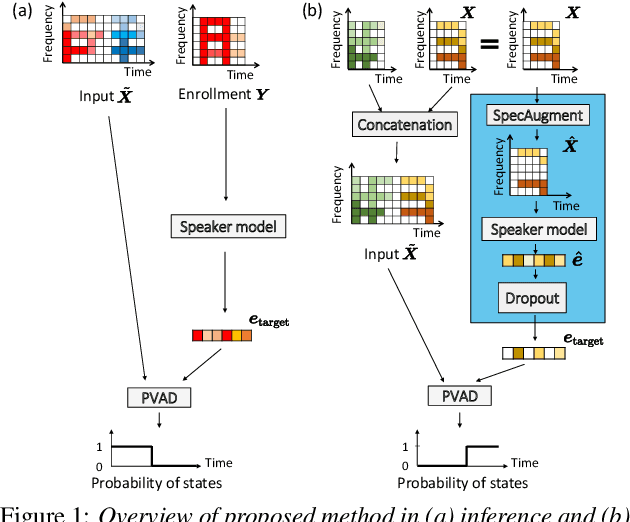
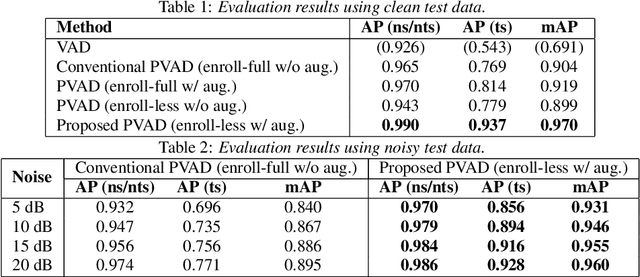
We present a novel personalized voice activity detection (PVAD) learning method that does not require enrollment data during training. PVAD is a task to detect the speech segments of a specific target speaker at the frame level using enrollment speech of the target speaker. Since PVAD must learn speakers' speech variations to clarify the boundary between speakers, studies on PVAD used large-scale datasets that contain many utterances for each speaker. However, the datasets to train a PVAD model are often limited because substantial cost is needed to prepare such a dataset. In addition, we cannot utilize the datasets used to train the standard VAD because they often lack speaker labels. To solve these problems, our key idea is to use one utterance as both a kind of enrollment speech and an input to the PVAD during training, which enables PVAD training without enrollment speech. In our proposed method, called enrollment-less training, we augment one utterance so as to create variability between the input and the enrollment speech while keeping the speaker identity, which avoids the mismatch between training and inference. Our experimental results demonstrate the efficacy of the method.
Attentive Modality Hopping Mechanism for Speech Emotion Recognition
Nov 29, 2019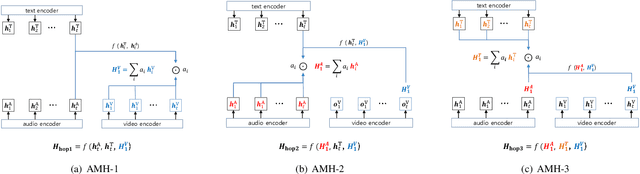
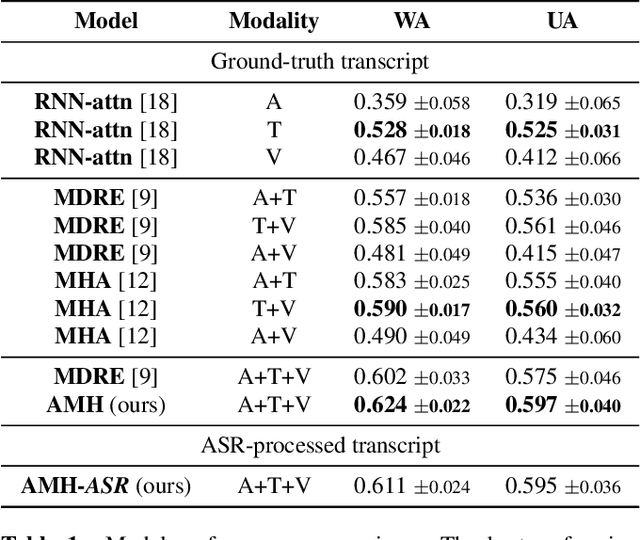
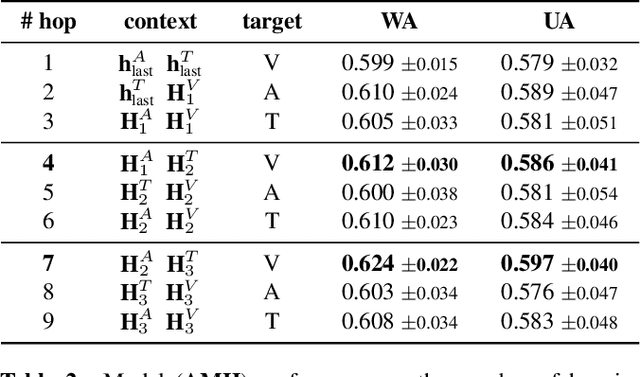
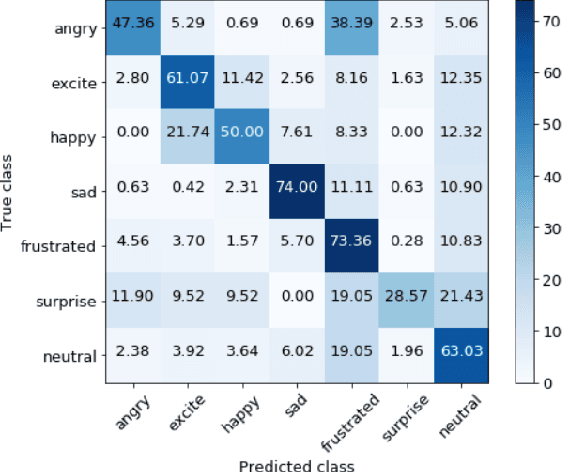
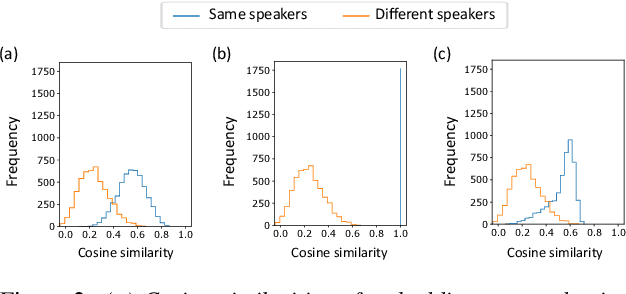
In this work, we explore the impact of visual modality in addition to speech and text for improving the accuracy of the emotion detection system. The traditional approaches tackle this task by fusing the knowledge from the various modalities independently for performing emotion classification. In contrast to these approaches, we tackle the problem by introducing an attention mechanism to combine the information. In this regard, we first apply a neural network to obtain hidden representations of the modalities. Then, the attention mechanism is defined to select and aggregate important parts of the video data by conditioning on the audio and text data. Furthermore, the attention mechanism is again applied to attend important parts of the speech and textual data, by considering other modality. Experiments are performed on the standard IEMOCAP dataset using all three modalities (audio, text, and video). The achieved results show a significant improvement of 3.65% in terms of weighted accuracy compared to the baseline system.
Adversarial Example Detection by Classification for Deep Speech Recognition
Oct 22, 2019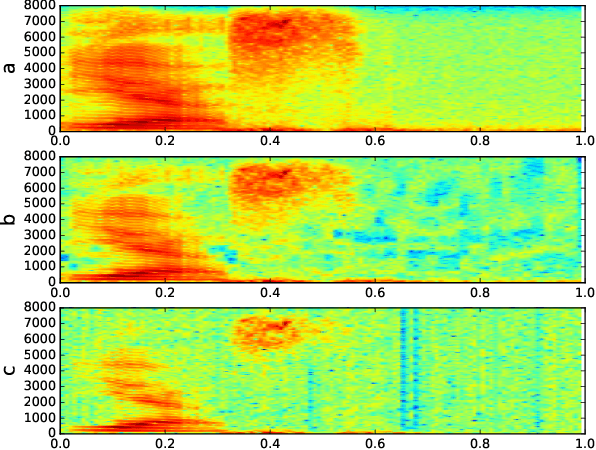
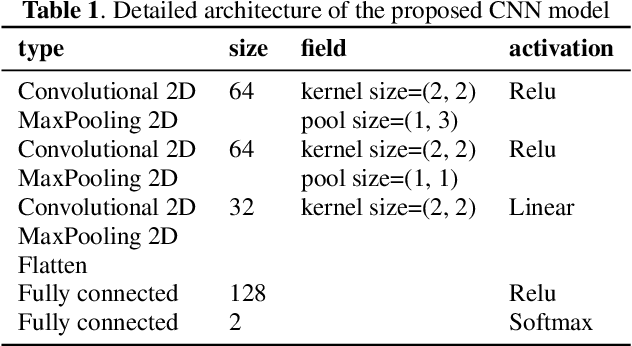
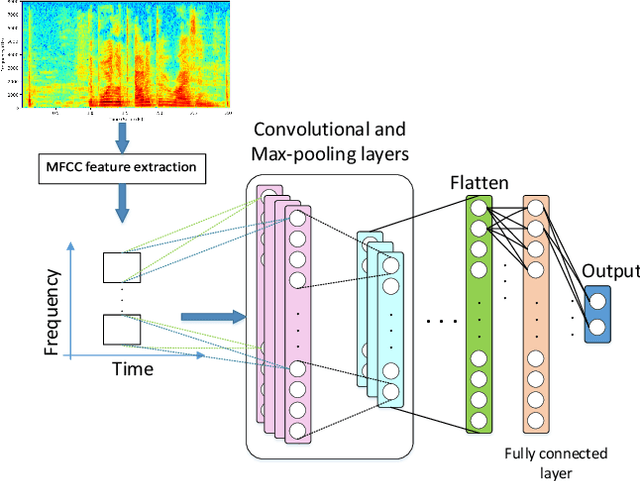
Machine Learning systems are vulnerable to adversarial attacks and will highly likely produce incorrect outputs under these attacks. There are white-box and black-box attacks regarding to adversary's access level to the victim learning algorithm. To defend the learning systems from these attacks, existing methods in the speech domain focus on modifying input signals and testing the behaviours of speech recognizers. We, however, formulate the defense as a classification problem and present a strategy for systematically generating adversarial example datasets: one for white-box attacks and one for black-box attacks, containing both adversarial and normal examples. The white-box attack is a gradient-based method on Baidu DeepSpeech with the Mozilla Common Voice database while the black-box attack is a gradient-free method on a deep model-based keyword spotting system with the Google Speech Command dataset. The generated datasets are used to train a proposed Convolutional Neural Network (CNN), together with cepstral features, to detect adversarial examples. Experimental results show that, it is possible to accurately distinct between adversarial and normal examples for known attacks, in both single-condition and multi-condition training settings, while the performance degrades dramatically for unknown attacks. The adversarial datasets and the source code are made publicly available.
Multimodal Depression Classification Using Articulatory Coordination Features And Hierarchical Attention Based Text Embeddings
Feb 13, 2022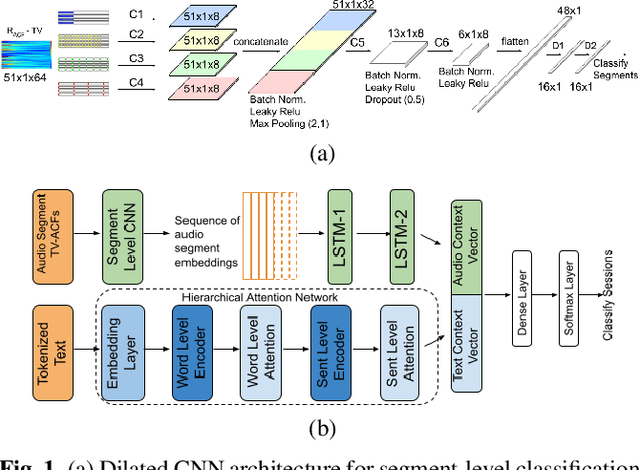

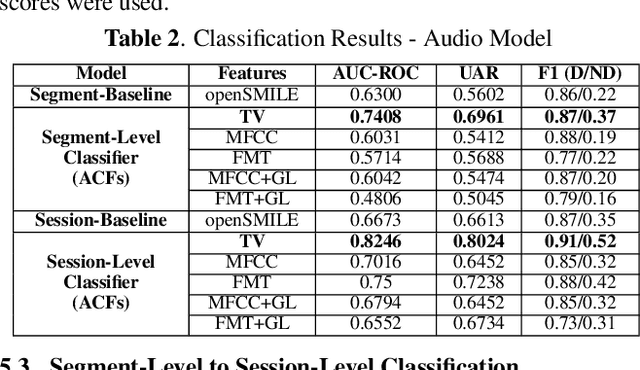
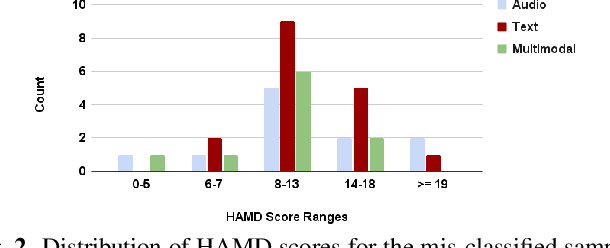
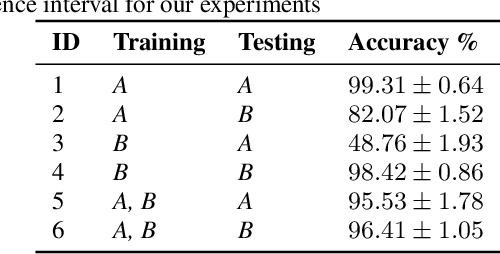
Multimodal depression classification has gained immense popularity over the recent years. We develop a multimodal depression classification system using articulatory coordination features extracted from vocal tract variables and text transcriptions obtained from an automatic speech recognition tool that yields improvements of area under the receiver operating characteristics curve compared to uni-modal classifiers (7.5% and 13.7% for audio and text respectively). We show that in the case of limited training data, a segment-level classifier can first be trained to then obtain a session-wise prediction without hindering the performance, using a multi-stage convolutional recurrent neural network. A text model is trained using a Hierarchical Attention Network (HAN). The multimodal system is developed by combining embeddings from the session-level audio model and the HAN text model
Direction of Arrival Estimation of Noisy Speech Using Convolutional Recurrent Neural Networks with Higher-Order Ambisonics Signals
Mar 01, 2021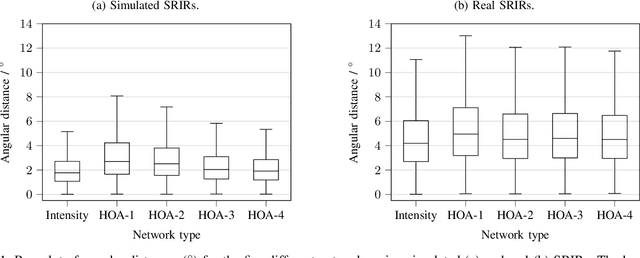
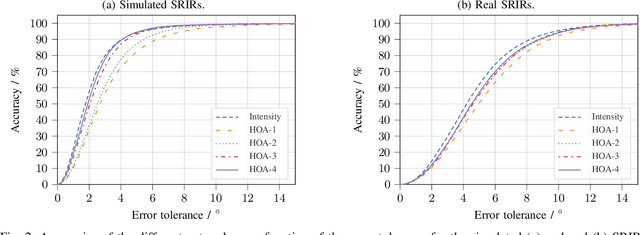
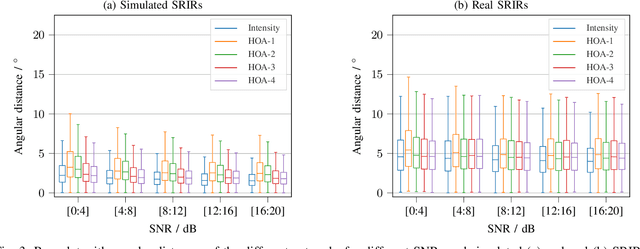
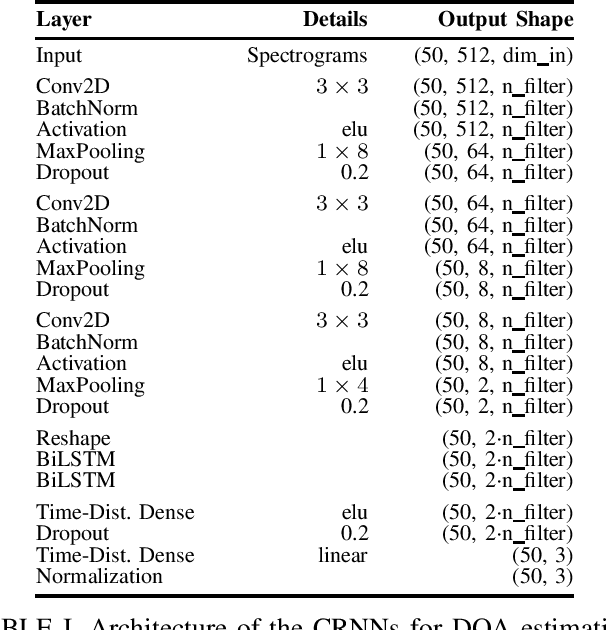
Training convolutional recurrent neural networks on first-order Ambisonics signals is a well-known approach when estimating the direction of arrival for speech/sound signals. In this work, we investigate whether increasing the order of Ambisonics up to the fourth order further improves the estimation performance of convolutional recurrent neural networks. While our results on data based on simulated spatial room impulse responses show that the use of higher Ambisonics orders does have the potential to provide better localization results, no further improvement was shown on data based on real spatial room impulse responses from order two onwards. Rather, it seems to be crucial to extract meaningful features from the raw data. First order features derived from the acoustic intensity vector were superior to pure higher-order magnitude and phase features in almost all scenarios.
Online End-to-End Neural Diarization Handling Overlapping Speech and Flexible Numbers of Speakers
Jan 21, 2021
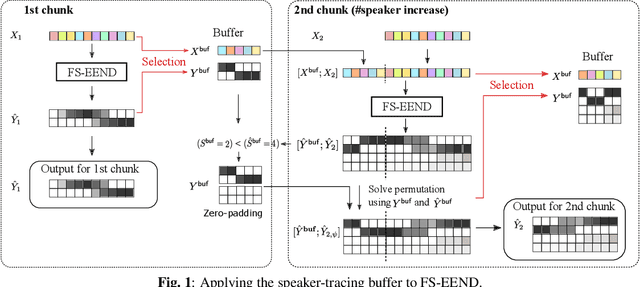


This paper proposes an online end-to-end diarization that can handle overlapping speech and flexible numbers of speakers. The end-to-end neural speaker diarization (EEND) model has already achieved significant improvement when compared with conventional clustering-based methods. However, the original EEND has two limitations: i) EEND does not perform well in online scenarios; ii) the number of speakers must be fixed in advance. This paper solves both problems by applying a modified extension of the speaker-tracing buffer method that deals with variable numbers of speakers. Experiments on CALLHOME and DIHARD II datasets show that the proposed online method achieves comparable performance to the offline EEND method. Compared with the state-of-the-art online method based on a fully supervised approach (UIS-RNN), the proposed method shows better performance on the DIHARD II dataset.
Does Audio Deepfake Detection Generalize?
Mar 31, 2022
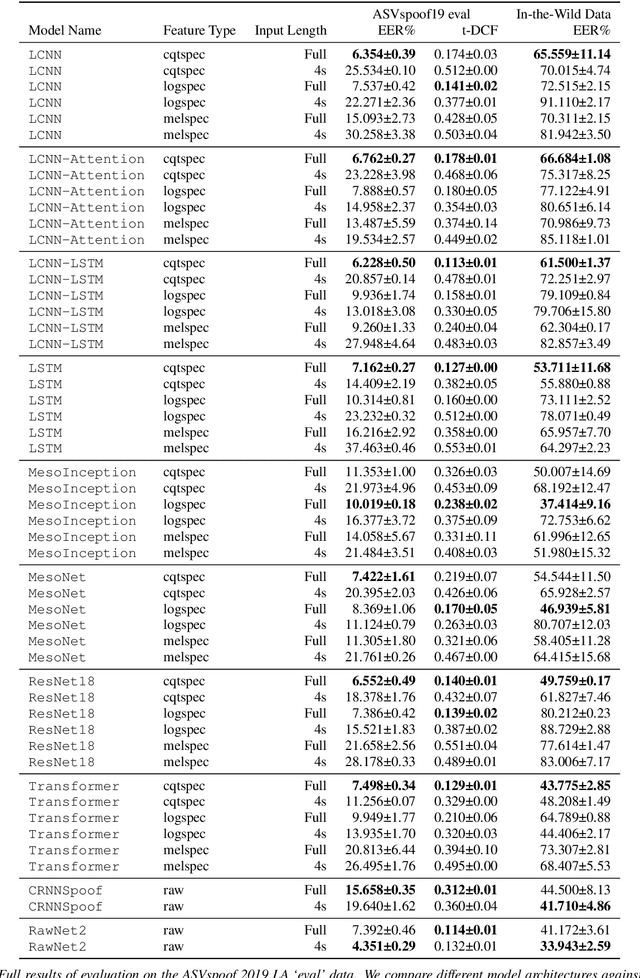
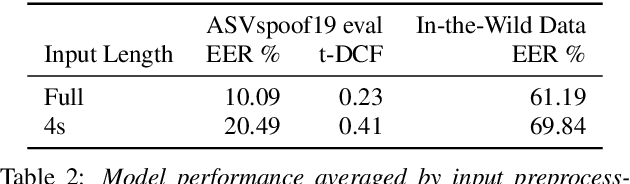
Current text-to-speech algorithms produce realistic fakes of human voices, making deepfake detection a much-needed area of research. While researchers have presented various techniques for detecting audio spoofs, it is often unclear exactly why these architectures are successful: Preprocessing steps, hyperparameter settings, and the degree of fine-tuning are not consistent across related work. Which factors contribute to success, and which are accidental? In this work, we address this problem: We systematize audio spoofing detection by re-implementing and uniformly evaluating architectures from related work. We identify overarching features for successful audio deepfake detection, such as using cqtspec or logspec features instead of melspec features, which improves performance by 37% EER on average, all other factors constant. Additionally, we evaluate generalization capabilities: We collect and publish a new dataset consisting of 37.9 hours of found audio recordings of celebrities and politicians, of which 17.2 hours are deepfakes. We find that related work performs poorly on such real-world data (performance degradation of up to one thousand percent). This may suggest that the community has tailored its solutions too closely to the prevailing ASVSpoof benchmark and that deepfakes are much harder to detect outside the lab than previously thought.