 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Detecting Online Hate Speech Using Context Aware Models
May 22, 2018
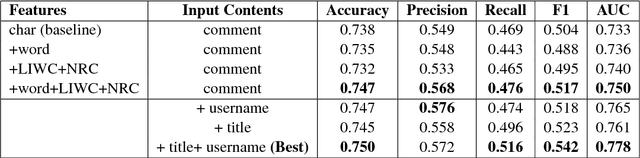
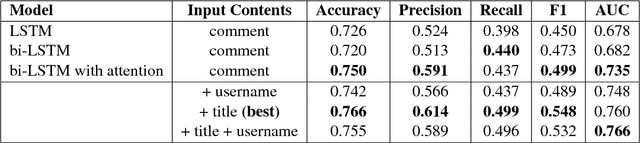
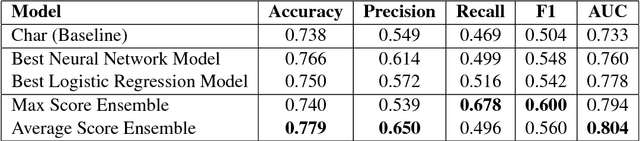
In the wake of a polarizing election, the cyber world is laden with hate speech. Context accompanying a hate speech text is useful for identifying hate speech, which however has been largely overlooked in existing datasets and hate speech detection models. In this paper, we provide an annotated corpus of hate speech with context information well kept. Then we propose two types of hate speech detection models that incorporate context information, a logistic regression model with context features and a neural network model with learning components for context. Our evaluation shows that both models outperform a strong baseline by around 3% to 4% in F1 score and combining these two models further improve the performance by another 7% in F1 score.
Generation of Speaker Representations Using Heterogeneous Training Batch Assembly
Mar 30, 2022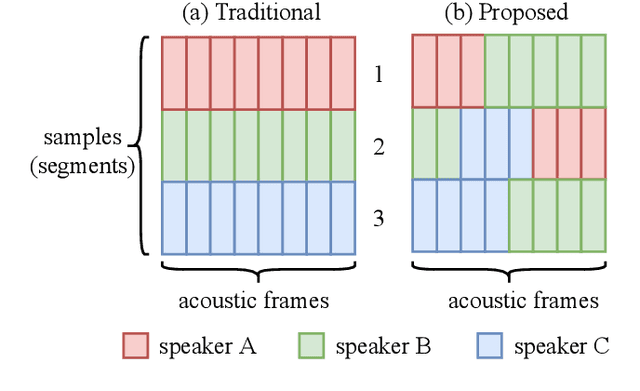
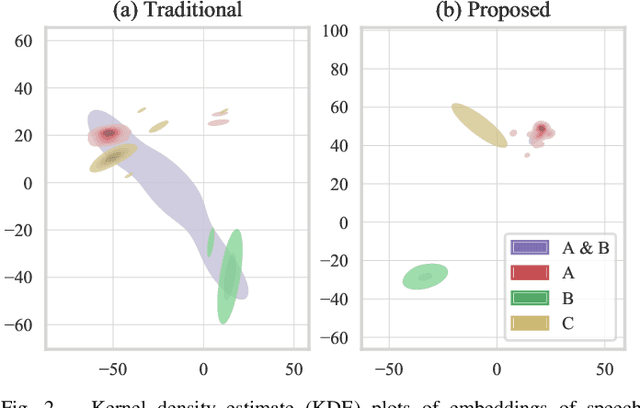
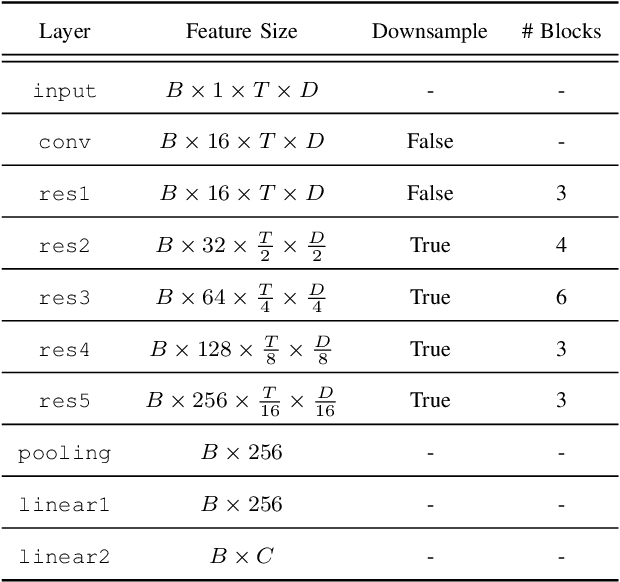
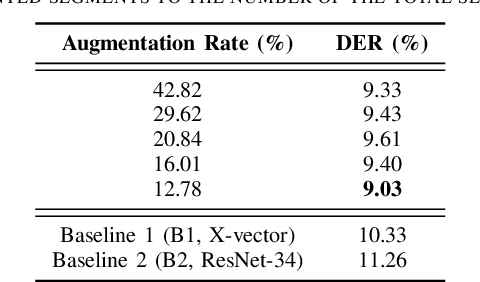
In traditional speaker diarization systems, a well-trained speaker model is a key component to extract representations from consecutive and partially overlapping segments in a long speech session. To be more consistent with the back-end segmentation and clustering, we propose a new CNN-based speaker modeling scheme, which takes into account the heterogeneity of the speakers in each training segment and batch. We randomly and synthetically augment the training data into a set of segments, each of which contains more than one speaker and some overlapping parts. A soft label is imposed on each segment based on its speaker occupation ratio, and the standard cross entropy loss is implemented in model training. In this way, the speaker model should have the ability to generate a geometrically meaningful embedding for each multi-speaker segment. Experimental results show that our system is superior to the baseline system using x-vectors in two speaker diarization tasks. In the CALLHOME task trained on the NIST SRE and Switchboard datasets, our system achieves a relative reduction of 12.93% in DER. In Track 2 of CHiME-6, our system provides 13.24%, 12.60%, and 5.65% relative reductions in DER, JER, and WER, respectively.
Trainable Adaptive Window Switching for Speech Enhancement
Nov 05, 2018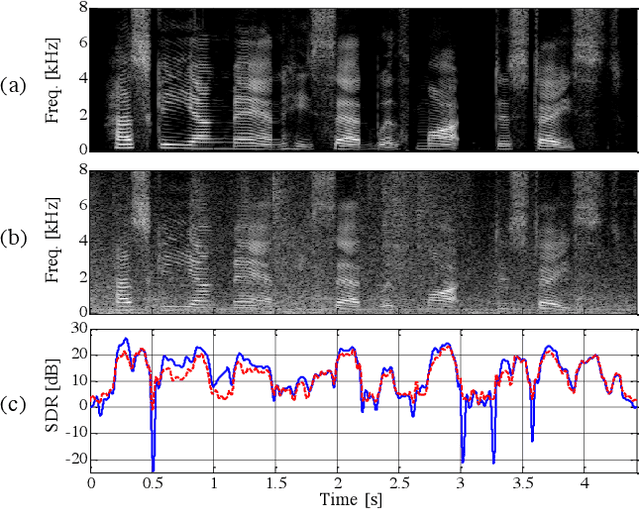
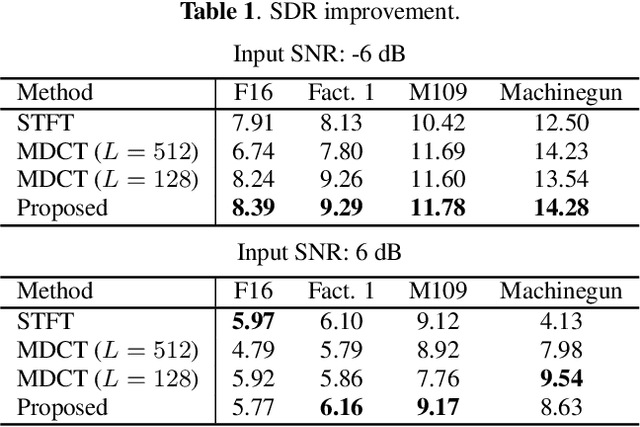
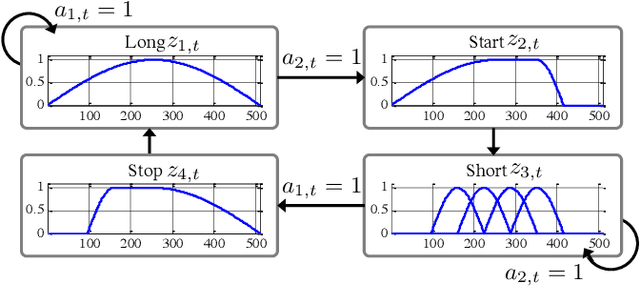
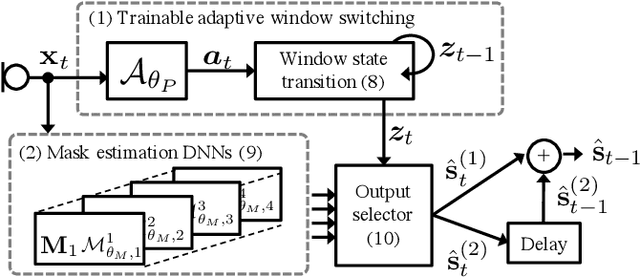
This study proposes a trainable adaptive window switching (AWS) method and apply it to a deep-neural-network (DNN) for speech enhancement in the modified discrete cosine transform domain. Time-frequency (T-F) mask processing in the short-time Fourier transform (STFT)-domain is a typical speech enhancement method. To recover the target signal precisely, DNN-based short-time frequency transforms have recently been investigated and used instead of the STFT. However, since such a fixed-resolution short-time frequency transform method has a T-F resolution problem based on the uncertainty principle, not only the short-time frequency transform but also the length of the windowing function should be optimized. To overcome this problem, we incorporate AWS into the speech enhancement procedure, and the windowing function of each time-frame is manipulated using a DNN depending on the input signal. We confirmed that the proposed method achieved a higher signal-to-distortion ratio than conventional speech enhancement methods in fixed-resolution frequency domains.
Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
Oct 30, 2019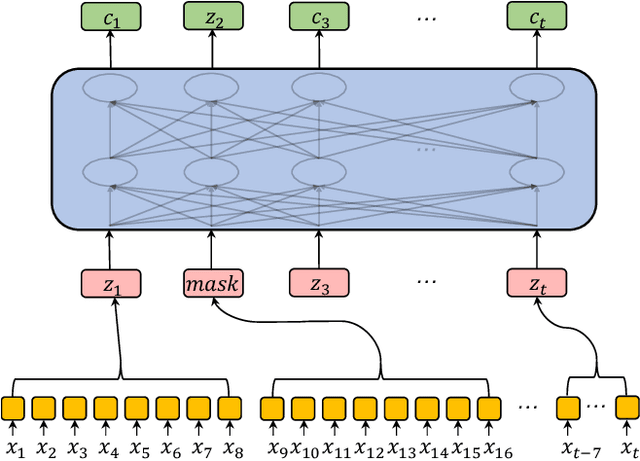
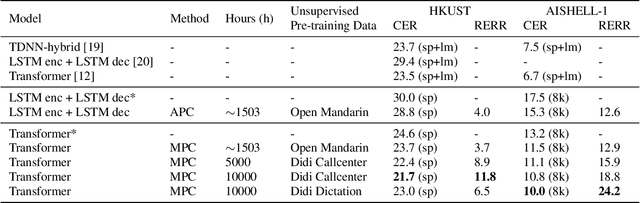
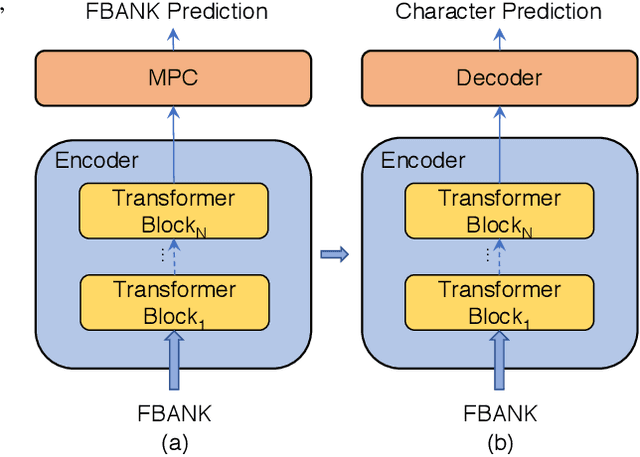
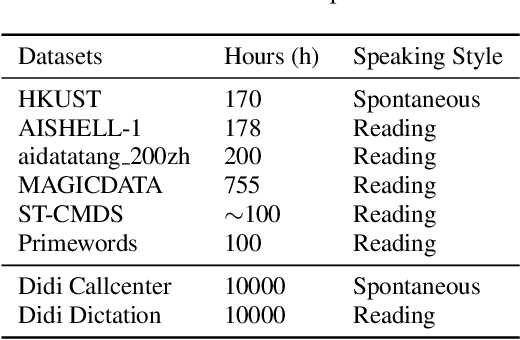
Speech recognition technologies are gaining enormous popularity in various industrial applications. However, building a good speech recognition system usually requires significant amounts of transcribed data, which is expensive to collect. To tackle this problem, an unsupervised pre-training method called Masked Predictive Coding is proposed, which can be applied for unsupervised pre-training with state-of-the-arts Transformer based model. Experiments on HKUST show that using the same training data and other open source Mandarin data, we can achieve a CER of 22.9, or a 3.8% relative improvements over a strong Transformer baseline. With more pre-training data, we can further reduce the CER to 21.0, or a 11.8% relative CER reduction over baseline.
Automatic Tuberculosis and COVID-19 cough classification using deep learning
May 11, 2022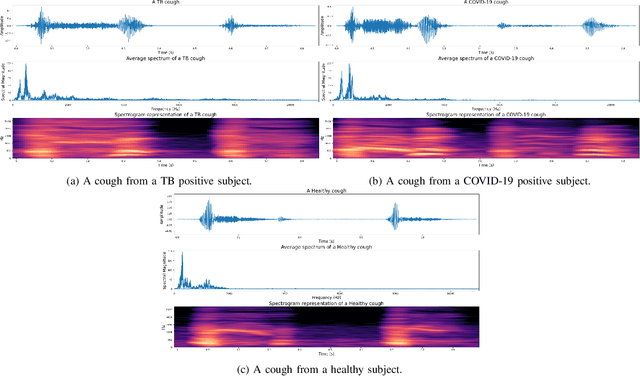
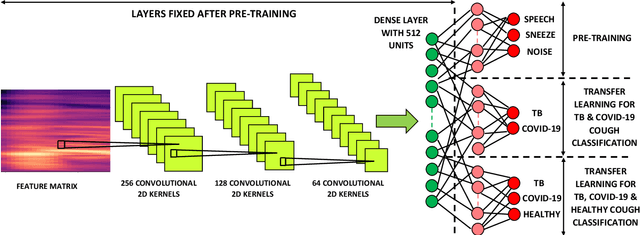
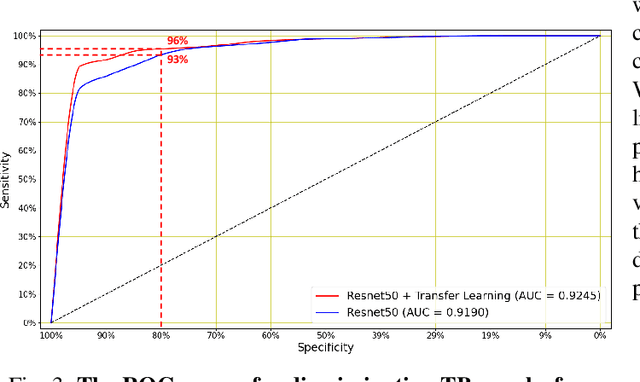
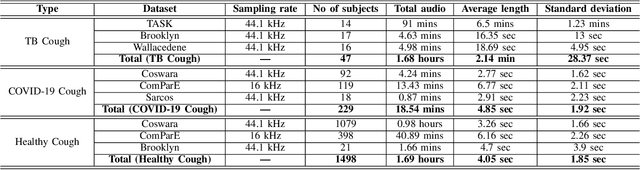
We present a deep learning based automatic cough classifier which can discriminate tuberculosis (TB) coughs from COVID-19 coughs and healthy coughs. Both TB and COVID-19 are respiratory disease, have cough as a predominant symptom and claim thousands of lives each year. The cough audio recordings were collected at both indoor and outdoor settings and also uploaded using smartphones from subjects around the globe, thus contain various levels of noise. This cough data include 1.68 hours of TB coughs, 18.54 minutes of COVID-19 coughs and 1.69 hours of healthy coughs from 47 TB patients, 229 COVID-19 patients and 1498 healthy patients and were used to train and evaluate a CNN, LSTM and Resnet50. These three deep architectures were also pre-trained on 2.14 hours of sneeze, 2.91 hours of speech and 2.79 hours of noise for improved performance. The class-imbalance in our dataset was addressed by using SMOTE data balancing technique and using performance metrics such as F1-score and AUC. Our study shows that the highest F1-scores of 0.9259 and 0.8631 have been achieved from a pre-trained Resnet50 for two-class (TB vs COVID-19) and three-class (TB vs COVID-19 vs healthy) cough classification tasks, respectively. The application of deep transfer learning has improved the classifiers' performance and makes them more robust as they generalise better over the cross-validation folds. Their performances exceed the TB triage test requirements set by the world health organisation (WHO). The features producing the best performance contain higher order of MFCCs suggesting that the differences between TB and COVID-19 coughs are not perceivable by the human ear. This type of cough audio classification is non-contact, cost-effective and can easily be deployed on a smartphone, thus it can be an excellent tool for both TB and COVID-19 screening.
Multimodal speech synthesis architecture for unsupervised speaker adaptation
Aug 20, 2018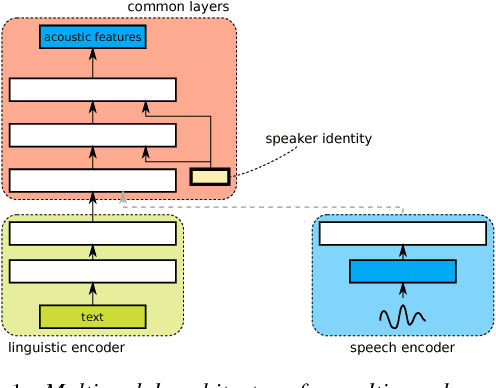
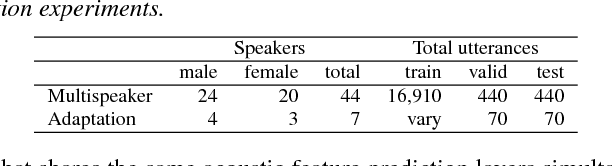
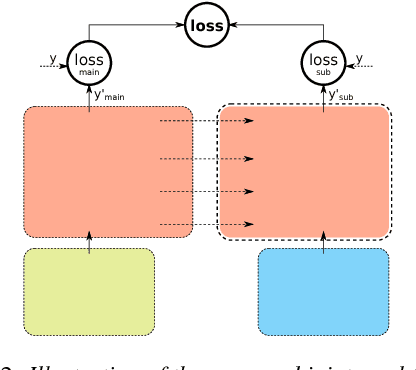
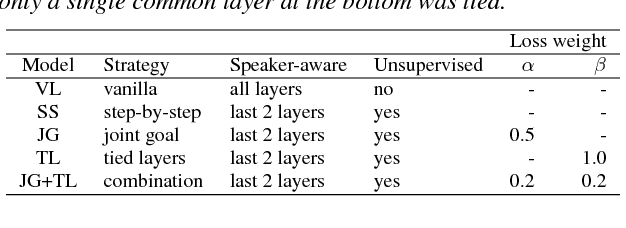
This paper proposes a new architecture for speaker adaptation of multi-speaker neural-network speech synthesis systems, in which an unseen speaker's voice can be built using a relatively small amount of speech data without transcriptions. This is sometimes called "unsupervised speaker adaptation". More specifically, we concatenate the layers to the audio inputs when performing unsupervised speaker adaptation while we concatenate them to the text inputs when synthesizing speech from text. Two new training schemes for the new architecture are also proposed in this paper. These training schemes are not limited to speech synthesis, other applications are suggested. Experimental results show that the proposed model not only enables adaptation to unseen speakers using untranscribed speech but it also improves the performance of multi-speaker modeling and speaker adaptation using transcribed audio files.
Multi-Encoder Learning and Stream Fusion for Transformer-Based End-to-End Automatic Speech Recognition
Mar 31, 2021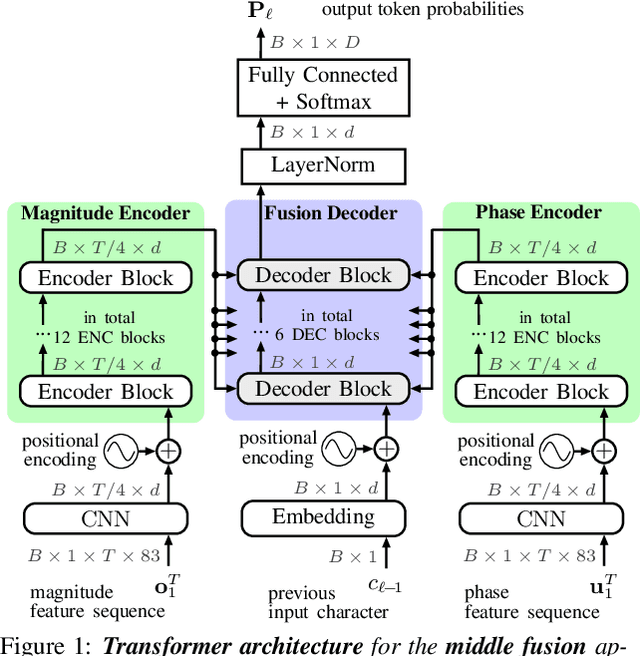
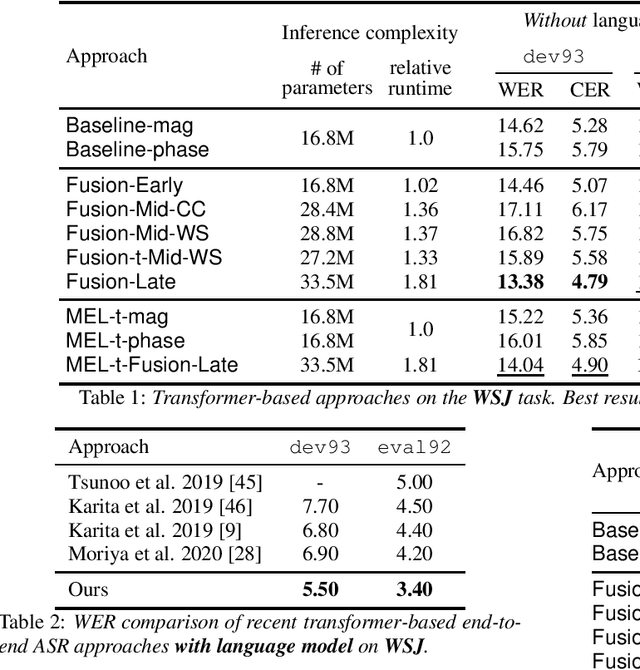
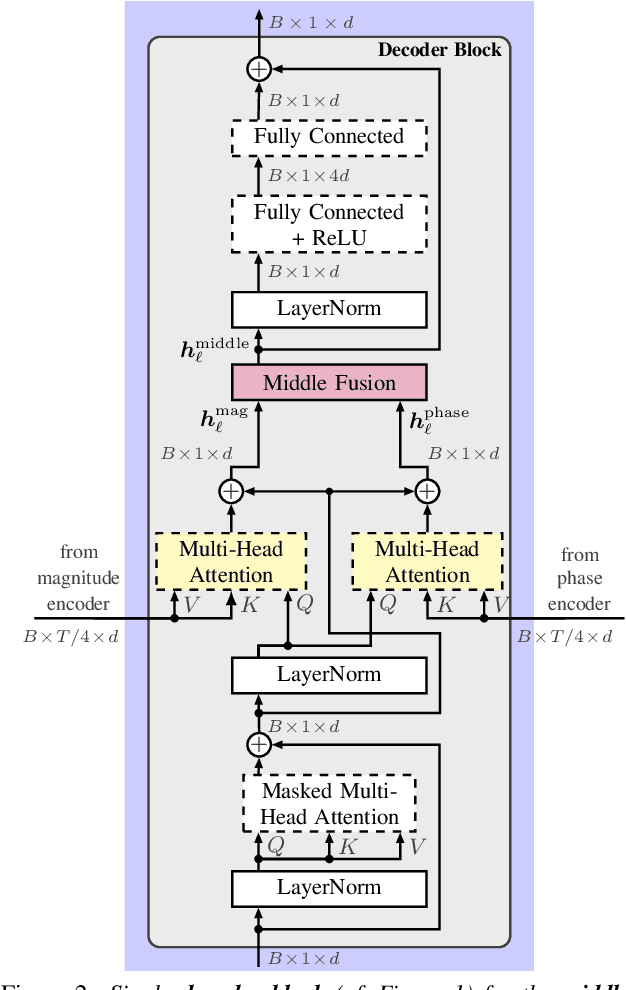
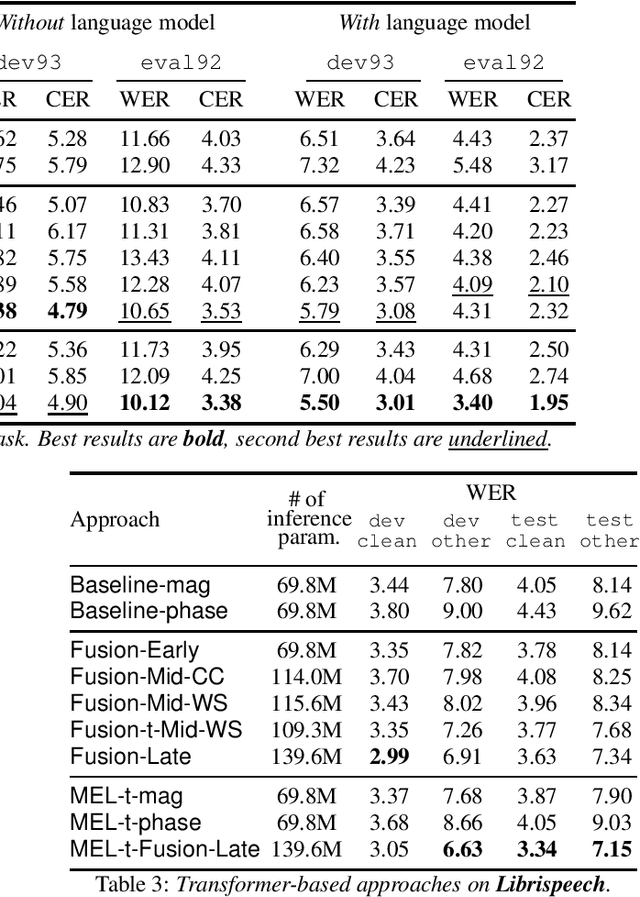
Stream fusion, also known as system combination, is a common technique in automatic speech recognition for traditional hybrid hidden Markov model approaches, yet mostly unexplored for modern deep neural network end-to-end model architectures. Here, we investigate various fusion techniques for the all-attention-based encoder-decoder architecture known as the transformer, striving to achieve optimal fusion by investigating different fusion levels in an example single-microphone setting with fusion of standard magnitude and phase features. We introduce a novel multi-encoder learning method that performs a weighted combination of two encoder-decoder multi-head attention outputs only during training. Employing then only the magnitude feature encoder in inference, we are able to show consistent improvement on Wall Street Journal (WSJ) with language model and on Librispeech, without increase in runtime or parameters. Combining two such multi-encoder trained models by a simple late fusion in inference, we achieve state-of-the-art performance for transformer-based models on WSJ with a significant WER reduction of 19\% relative compared to the current benchmark approach.
Unmanned Aerial Vehicle Control Through Domain-based Automatic Speech Recognition
Sep 09, 2020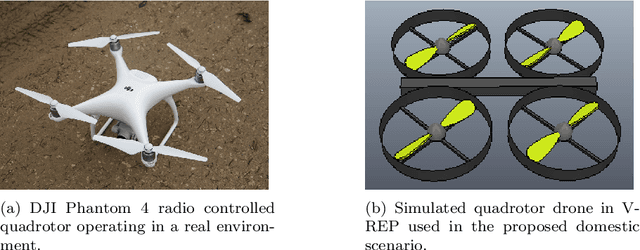
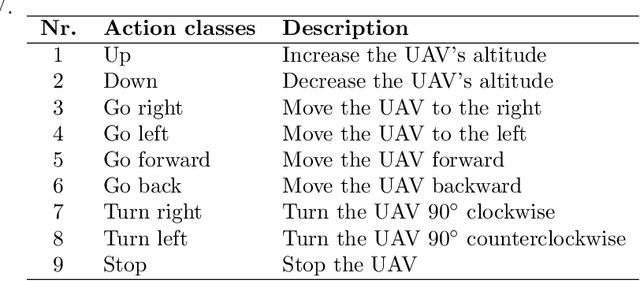
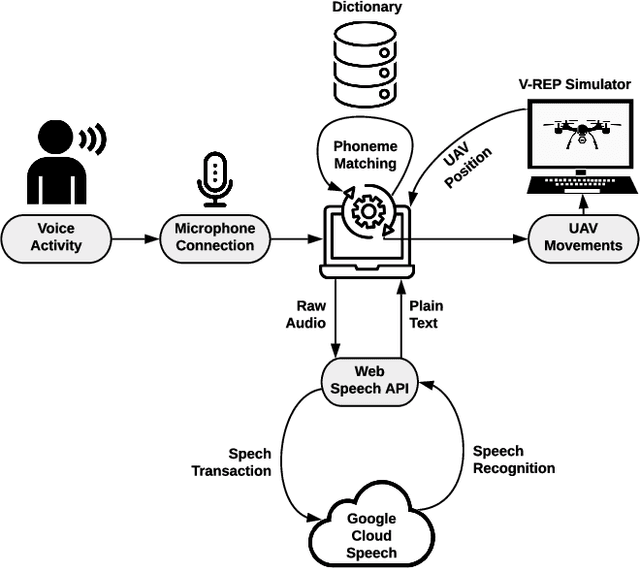
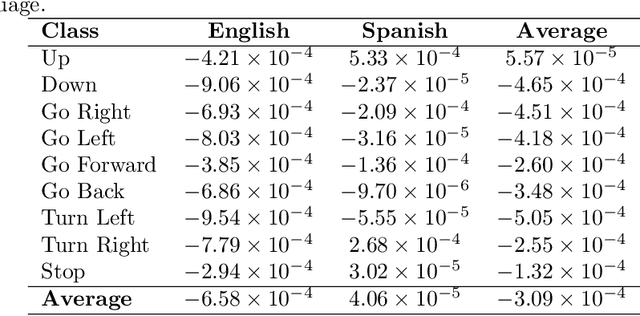
Currently, unmanned aerial vehicles, such as drones, are becoming a part of our lives and reaching out to many areas of society, including the industrialized world. A common alternative to control the movements and actions of the drone is through unwired tactile interfaces, for which different remote control devices can be found. However, control through such devices is not a natural, human-like communication interface, which sometimes is difficult to master for some users. In this work, we present a domain-based speech recognition architecture to effectively control an unmanned aerial vehicle such as a drone. The drone control is performed using a more natural, human-like way to communicate the instructions. Moreover, we implement an algorithm for command interpretation using both Spanish and English languages, as well as to control the movements of the drone in a simulated domestic environment. The conducted experiments involve participants giving voice commands to the drone in both languages in order to compare the effectiveness of each of them, considering the mother tongue of the participants in the experiment. Additionally, different levels of distortion have been applied to the voice commands in order to test the proposed approach when facing noisy input signals. The obtained results show that the unmanned aerial vehicle is capable of interpreting user voice instructions achieving an improvement in speech-to-action recognition for both languages when using phoneme matching in comparison to only using the cloud-based algorithm without domain-based instructions. Using raw audio inputs, the cloud-based approach achieves 74.81% and 97.04% accuracy for English and Spanish instructions respectively, whereas using our phoneme matching approach the results are improved achieving 93.33% and 100.00% accuracy for English and Spanish languages.
BiosecurID: a multimodal biometric database
Nov 02, 2021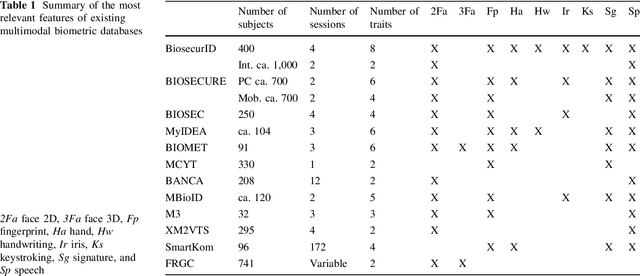

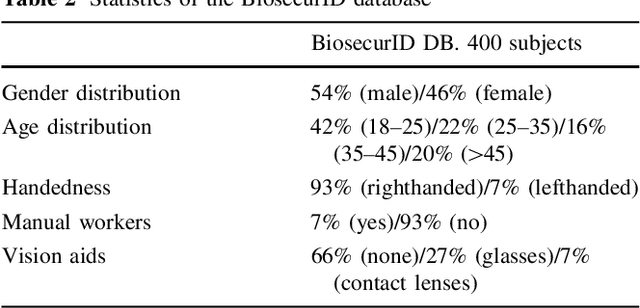
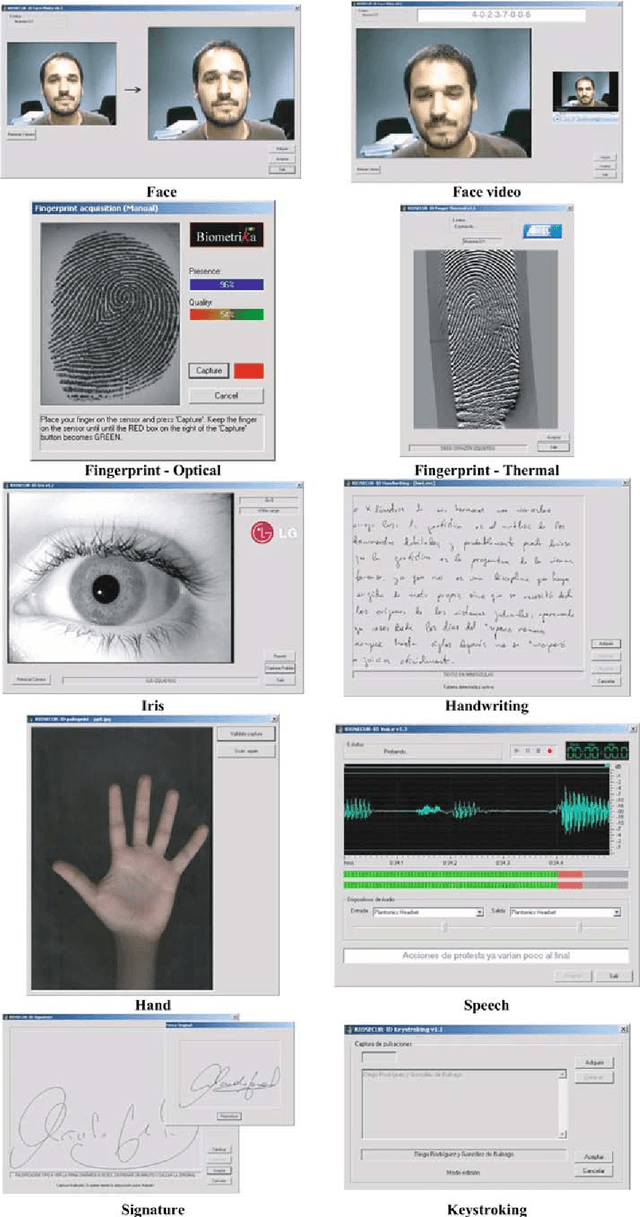
A new multimodal biometric database, acquired in the framework of the BiosecurID project, is presented together with the description of the acquisition setup and protocol. The database includes eight unimodal biometric traits, namely: speech, iris, face (still images, videos of talking faces), handwritten signature and handwritten text (on-line dynamic signals, off-line scanned images), fingerprints (acquired with two different sensors), hand (palmprint, contour-geometry) and keystroking. The database comprises 400 subjects and presents features such as: realistic acquisition scenario, balanced gender and population distributions, availability of information about particular demographic groups (age, gender, handedness), acquisition of replay attacks for speech and keystroking, skilled forgeries for signatures, and compatibility with other existing databases. All these characteristics make it very useful in research and development of unimodal and multimodal biometric systems.
Dynamic Temporal Alignment of Speech to Lips
Aug 19, 2018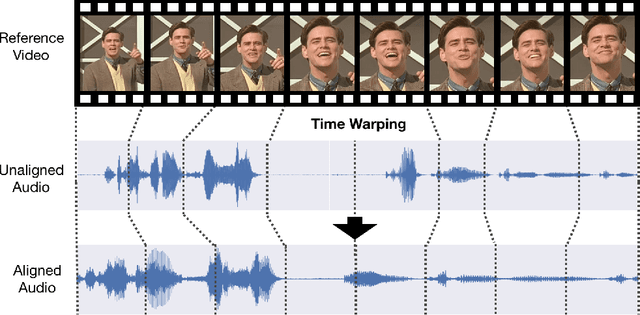
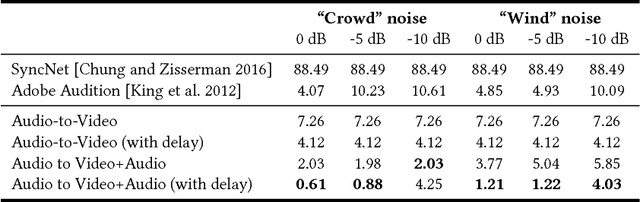
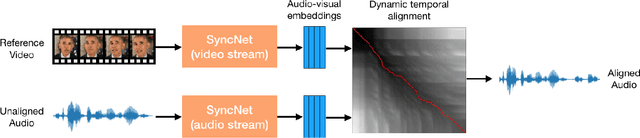
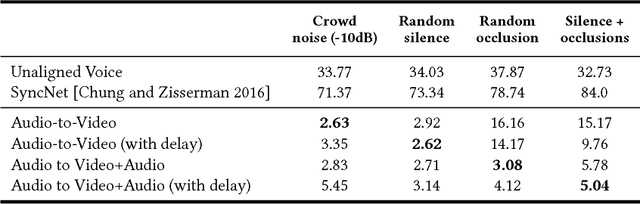
Many speech segments in movies are re-recorded in a studio during postproduction, to compensate for poor sound quality as recorded on location. Manual alignment of the newly-recorded speech with the original lip movements is a tedious task. We present an audio-to-video alignment method for automating speech to lips alignment, stretching and compressing the audio signal to match the lip movements. This alignment is based on deep audio-visual features, mapping the lips video and the speech signal to a shared representation. Using this shared representation we compute the lip-sync error between every short speech period and every video frame, followed by the determination of the optimal corresponding frame for each short sound period over the entire video clip. We demonstrate successful alignment both quantitatively, using a human perception-inspired metric, as well as qualitatively. The strongest advantage of our audio-to-video approach is in cases where the original voice in unclear, and where a constant shift of the sound can not give a perfect alignment. In these cases state-of-the-art methods will fail.