 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Hierarchical Summarization for Longform Spoken Dialog
Aug 21, 2021
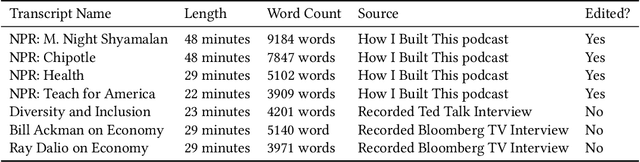
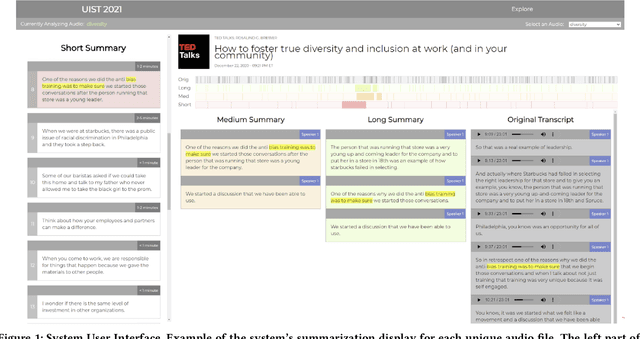

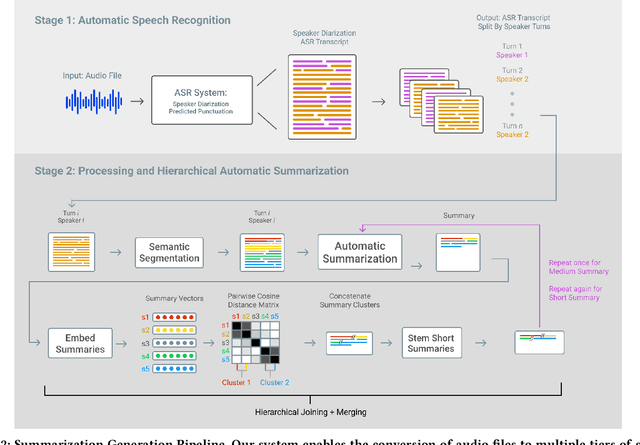
Every day we are surrounded by spoken dialog. This medium delivers rich diverse streams of information auditorily; however, systematically understanding dialog can often be non-trivial. Despite the pervasiveness of spoken dialog, automated speech understanding and quality information extraction remains markedly poor, especially when compared to written prose. Furthermore, compared to understanding text, auditory communication poses many additional challenges such as speaker disfluencies, informal prose styles, and lack of structure. These concerns all demonstrate the need for a distinctly speech tailored interactive system to help users understand and navigate the spoken language domain. While individual automatic speech recognition (ASR) and text summarization methods already exist, they are imperfect technologies; neither consider user purpose and intent nor address spoken language induced complications. Consequently, we design a two stage ASR and text summarization pipeline and propose a set of semantic segmentation and merging algorithms to resolve these speech modeling challenges. Our system enables users to easily browse and navigate content as well as recover from errors in these underlying technologies. Finally, we present an evaluation of the system which highlights user preference for hierarchical summarization as a tool to quickly skim audio and identify content of interest to the user.
Advanced Rich Transcription System for Estonian Speech
Jan 11, 2019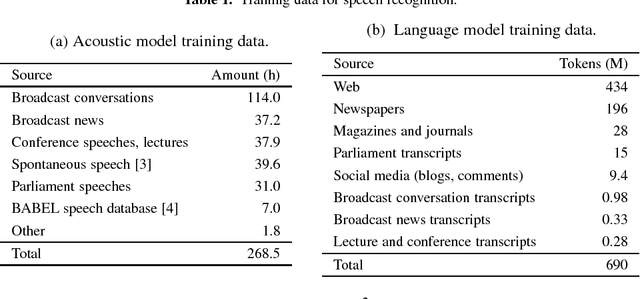
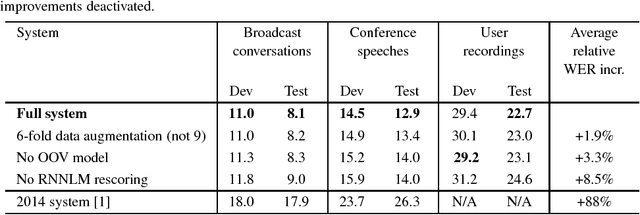

This paper describes the current TT\"U speech transcription system for Estonian speech. The system is designed to handle semi-spontaneous speech, such as broadcast conversations, lecture recordings and interviews recorded in diverse acoustic conditions. The system is based on the Kaldi toolkit. Multi-condition training using background noise profiles extracted automatically from untranscribed data is used to improve the robustness of the system. Out-of-vocabulary words are recovered using a phoneme n-gram based decoding subgraph and a FST-based phoneme-to-grapheme model. The system achieves a word error rate of 8.1% on a test set of broadcast conversations. The system also performs punctuation recovery and speaker identification. Speaker identification models are trained using a recently proposed weakly supervised training method.
* Published in Baltic HLT 2018 (putting it on arXiv because Google Scholar doesn't index it properly)
Attentive Temporal Pooling for Conformer-based Streaming Language Identification in Long-form Speech
Feb 24, 2022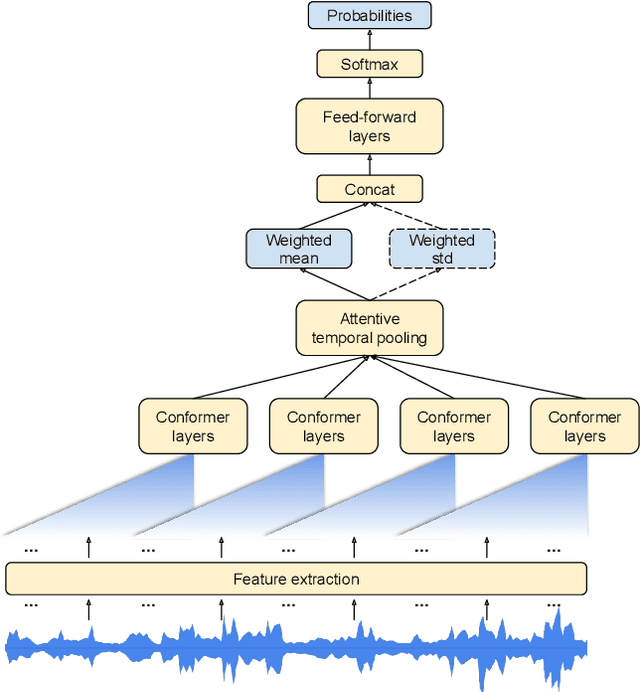
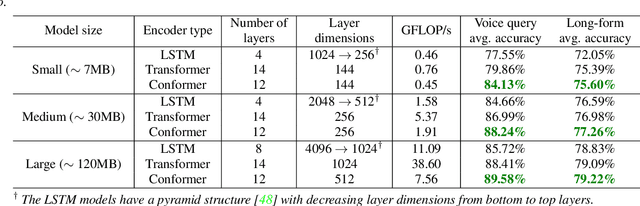
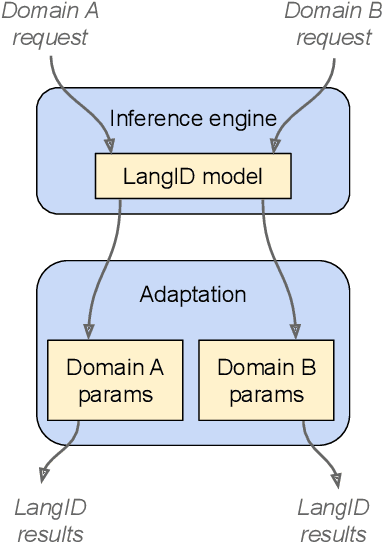
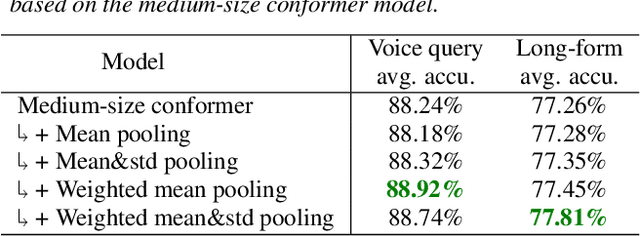
In this paper, we introduce a novel language identification system based on conformer layers. We propose an attentive temporal pooling mechanism to allow the model to carry information in long-form audio via a recurrent form, such that the inference can be performed in a streaming fashion. Additionally, a simple domain adaptation mechanism is introduced to allow adapting an existing language identification model to a new domain where the prior language distribution is different. We perform a comparative study of different model topologies under different constraints of model size, and find that conformer-base models outperform LSTM and transformer based models. Our experiments also show that attentive temporal pooling and domain adaptation significantly improve the model accuracy.
Improved Language Identification Through Cross-Lingual Self-Supervised Learning
Jul 08, 2021
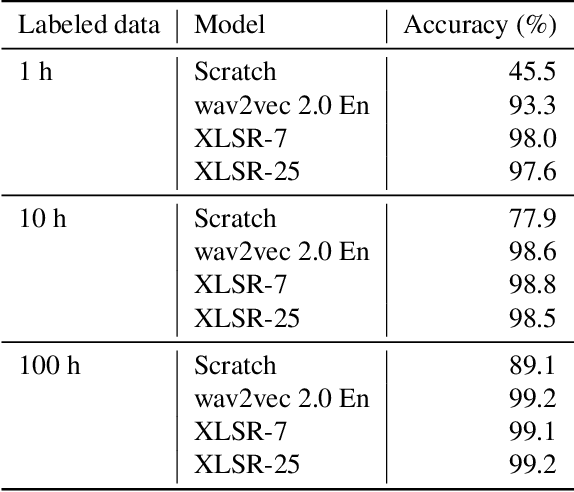
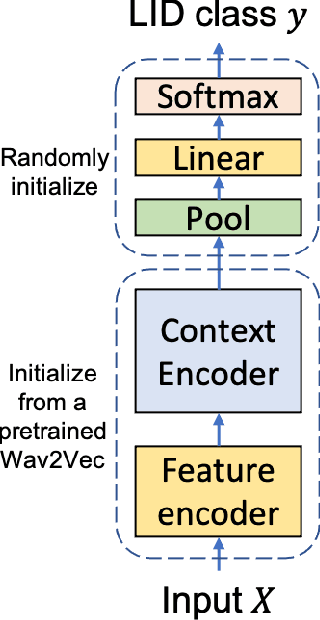
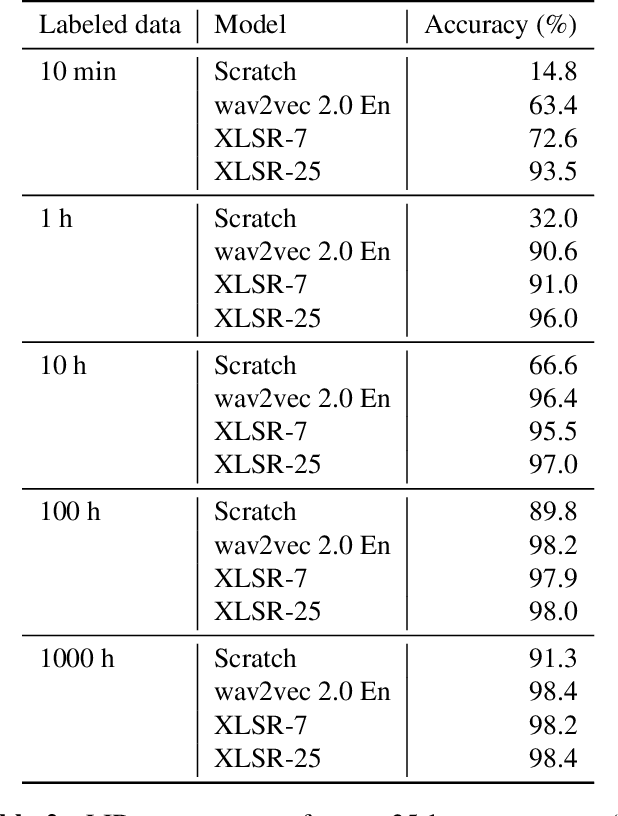
Language identification greatly impacts the success of downstream tasks such as automatic speech recognition. Recently, self-supervised speech representations learned by wav2vec 2.0 have been shown to be very effective for a range of speech tasks. We extend previous self-supervised work on language identification by experimenting with pre-trained models which were learned on real-world unconstrained speech in multiple languages and not just on English. We show that models pre-trained on many languages perform better and enable language identification systems that require very little labeled data to perform well. Results on a 25 languages setup show that with only 10 minutes of labeled data per language, a cross-lingually pre-trained model can achieve over 93% accuracy.
A wearable sensor vest for social humanoid robots with GPGPU, IoT, and modular software architecture
Jan 06, 2022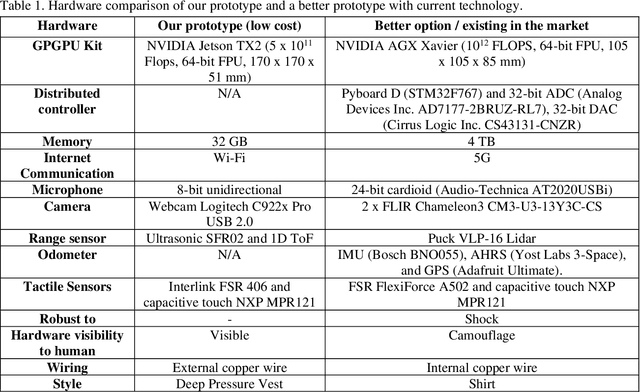

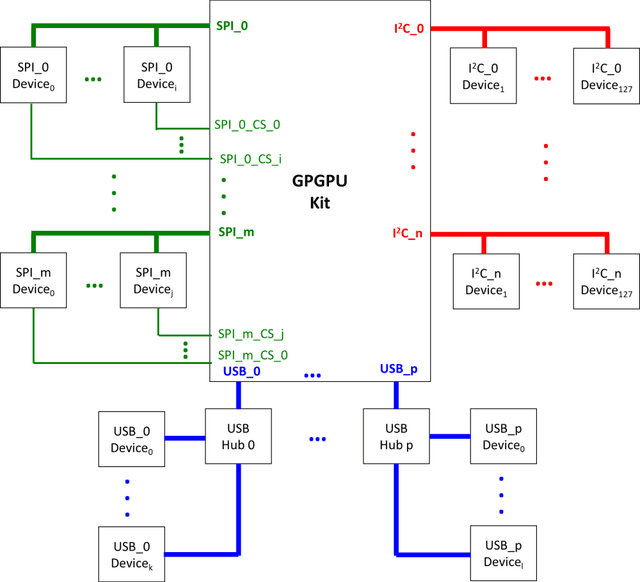
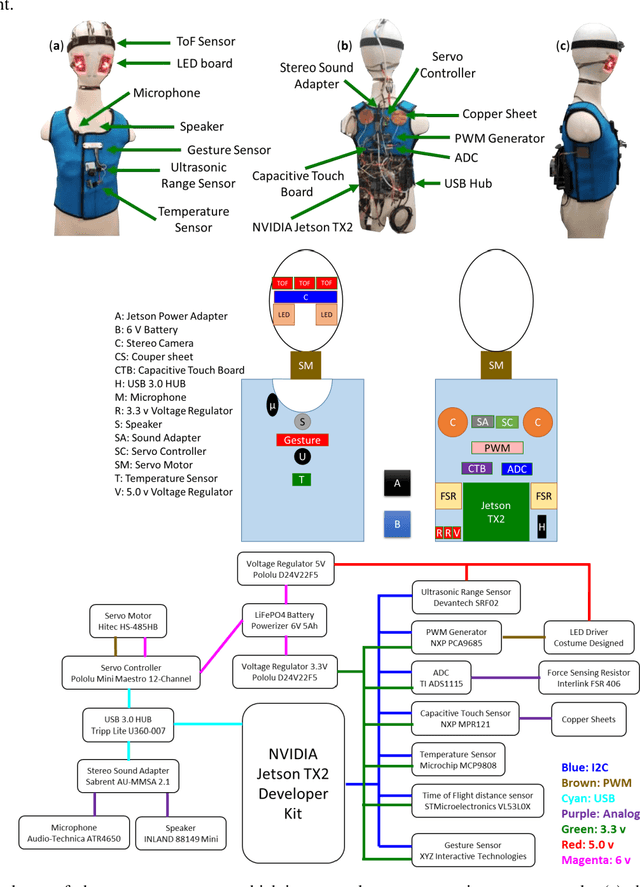
Currently, most social robots interact with their surroundings and humans through sensors that are integral parts of the robots, which limits the usability of the sensors, human-robot interaction, and interchangeability. A wearable sensor garment that fits many robots is needed in many applications. This article presents an affordable wearable sensor vest, and an open-source software architecture with the Internet of Things (IoT) for social humanoid robots. The vest consists of touch, temperature, gesture, distance, vision sensors, and a wireless communication module. The IoT feature allows the robot to interact with humans locally and over the Internet. The designed architecture works for any social robot that has a general-purpose graphics processing unit (GPGPU), I2C/SPI buses, Internet connection, and the Robotics Operating System (ROS). The modular design of this architecture enables developers to easily add/remove/update complex behaviors. The proposed software architecture provides IoT technology, GPGPU nodes, I2C and SPI bus mangers, audio-visual interaction nodes (speech to text, text to speech, and image understanding), and isolation between behavior nodes and other nodes. The proposed IoT solution consists of related nodes in the robot, a RESTful web service, and user interfaces. We used the HTTP protocol as a means of two-way communication with the social robot over the Internet. Developers can easily edit or add nodes in C, C++, and Python programming languages. Our architecture can be used for designing more sophisticated behaviors for social humanoid robots.
* This is the preprint version. The final version is published in Robotics and Autonomous Systems, Volume 139, 2021, Page 103536, ISSN 0921-8890, https://doi.org/10.1016/j.robot.2020.103536
Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
Oct 30, 2019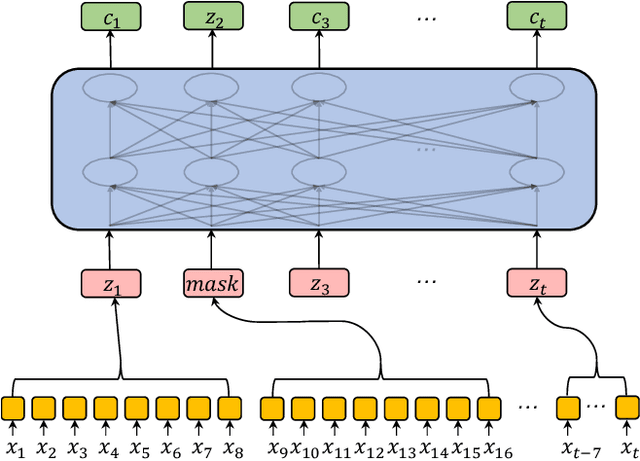
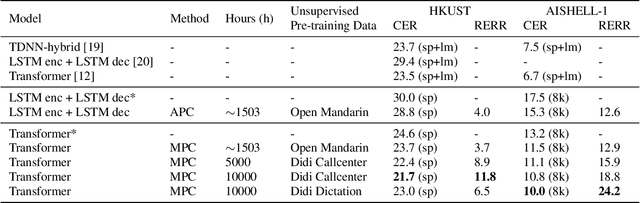
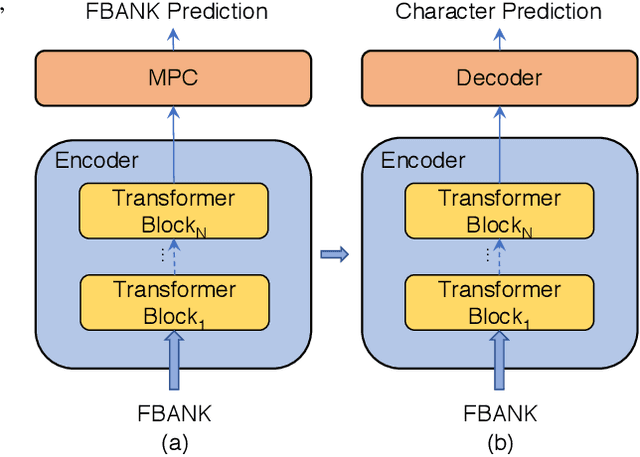
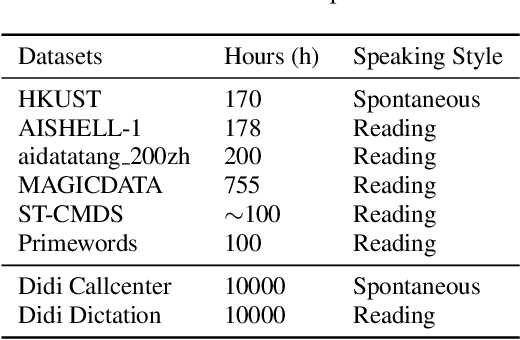
Speech recognition technologies are gaining enormous popularity in various industrial applications. However, building a good speech recognition system usually requires significant amounts of transcribed data, which is expensive to collect. To tackle this problem, an unsupervised pre-training method called Masked Predictive Coding is proposed, which can be applied for unsupervised pre-training with state-of-the-arts Transformer based model. Experiments on HKUST show that using the same training data and other open source Mandarin data, we can achieve a CER of 22.9, or a 3.8% relative improvements over a strong Transformer baseline. With more pre-training data, we can further reduce the CER to 21.0, or a 11.8% relative CER reduction over baseline.
Does Audio Deepfake Detection Generalize?
Mar 31, 2022
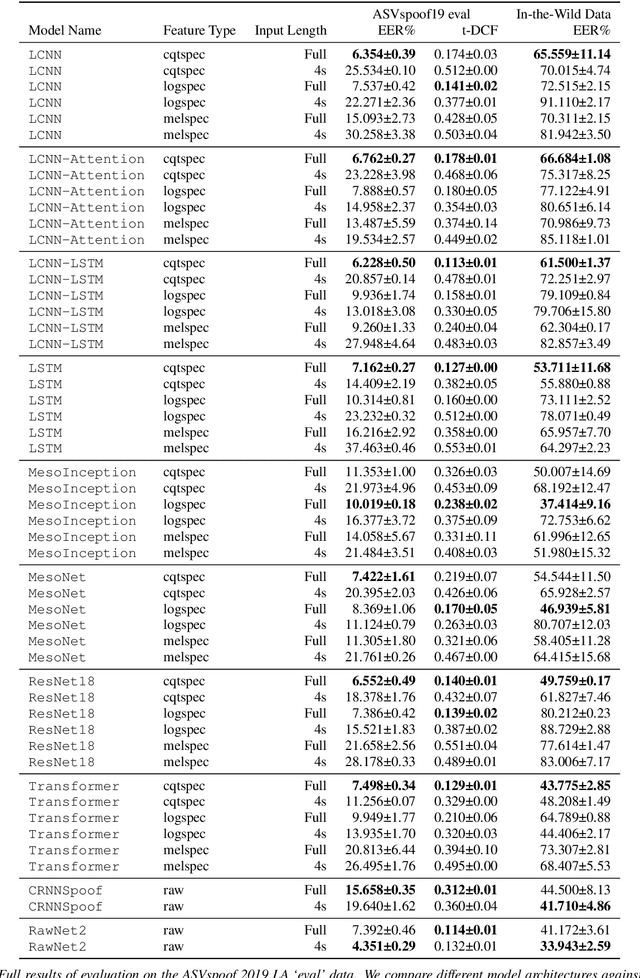
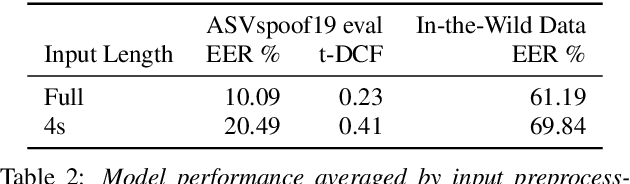
Current text-to-speech algorithms produce realistic fakes of human voices, making deepfake detection a much-needed area of research. While researchers have presented various techniques for detecting audio spoofs, it is often unclear exactly why these architectures are successful: Preprocessing steps, hyperparameter settings, and the degree of fine-tuning are not consistent across related work. Which factors contribute to success, and which are accidental? In this work, we address this problem: We systematize audio spoofing detection by re-implementing and uniformly evaluating architectures from related work. We identify overarching features for successful audio deepfake detection, such as using cqtspec or logspec features instead of melspec features, which improves performance by 37% EER on average, all other factors constant. Additionally, we evaluate generalization capabilities: We collect and publish a new dataset consisting of 37.9 hours of found audio recordings of celebrities and politicians, of which 17.2 hours are deepfakes. We find that related work performs poorly on such real-world data (performance degradation of up to one thousand percent). This may suggest that the community has tailored its solutions too closely to the prevailing ASVSpoof benchmark and that deepfakes are much harder to detect outside the lab than previously thought.
Multimodal Depression Classification Using Articulatory Coordination Features And Hierarchical Attention Based Text Embeddings
Feb 13, 2022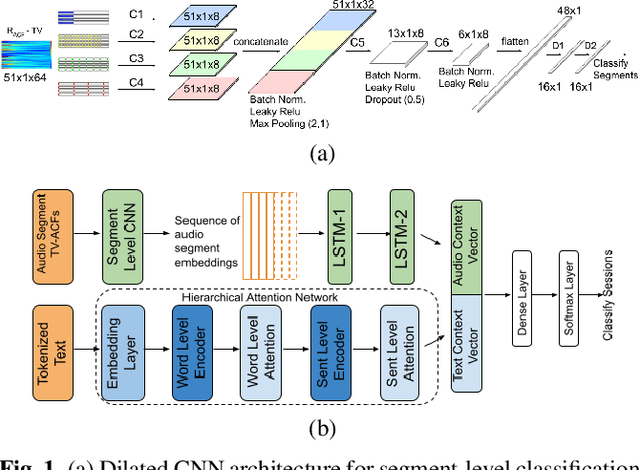

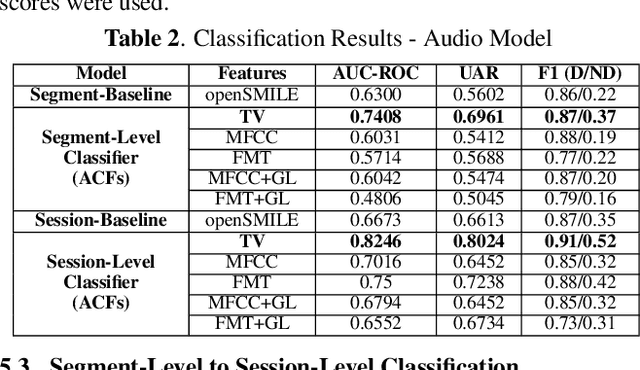
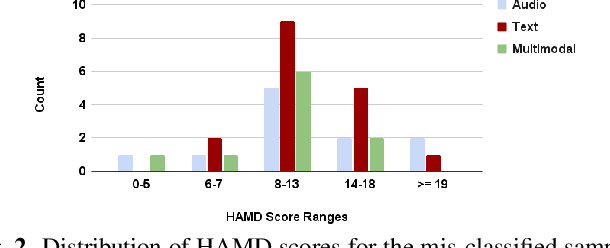
Multimodal depression classification has gained immense popularity over the recent years. We develop a multimodal depression classification system using articulatory coordination features extracted from vocal tract variables and text transcriptions obtained from an automatic speech recognition tool that yields improvements of area under the receiver operating characteristics curve compared to uni-modal classifiers (7.5% and 13.7% for audio and text respectively). We show that in the case of limited training data, a segment-level classifier can first be trained to then obtain a session-wise prediction without hindering the performance, using a multi-stage convolutional recurrent neural network. A text model is trained using a Hierarchical Attention Network (HAN). The multimodal system is developed by combining embeddings from the session-level audio model and the HAN text model
Detecting Abusive Albanian
Jul 30, 2021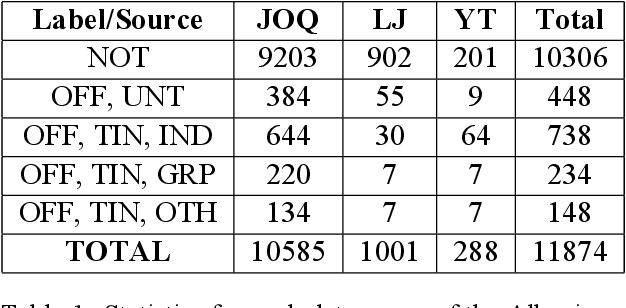
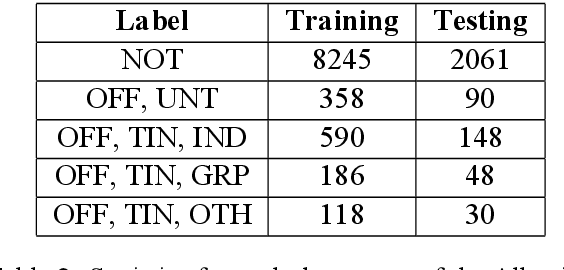
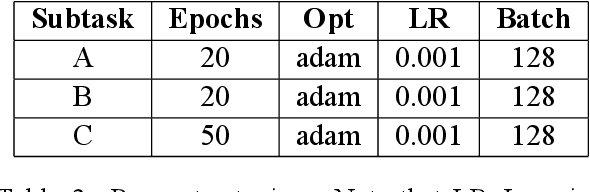
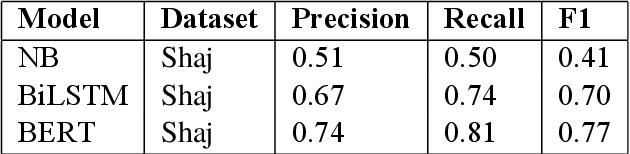
The ever growing usage of social media in the recent years has had a direct impact on the increased presence of hate speech and offensive speech in online platforms. Research on effective detection of such content has mainly focused on English and a few other widespread languages, while the leftover majority fail to have the same work put into them and thus cannot benefit from the steady advancements made in the field. In this paper we present \textsc{Shaj}, an annotated Albanian dataset for hate speech and offensive speech that has been constructed from user-generated content on various social media platforms. Its annotation follows the hierarchical schema introduced in OffensEval. The dataset is tested using three different classification models, the best of which achieves an F1 score of 0.77 for the identification of offensive language, 0.64 F1 score for the automatic categorization of offensive types and lastly, 0.52 F1 score for the offensive language target identification.
Large-Scale Visual Speech Recognition
Oct 01, 2018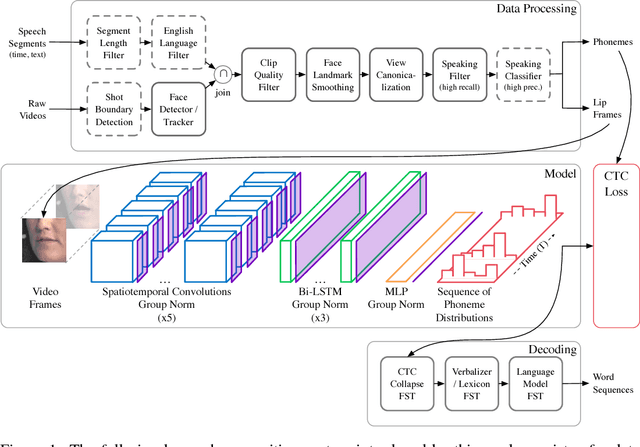
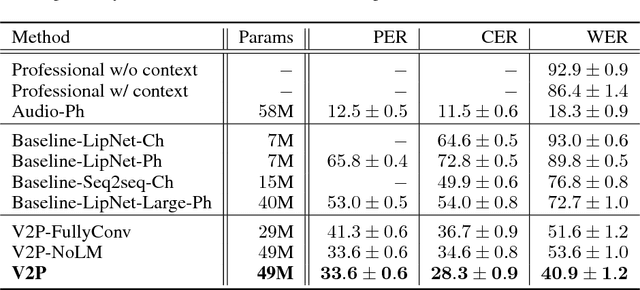


This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.