 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Hate Towards the Political Opponent: A Twitter Corpus Study of the 2020 US Elections on the Basis of Offensive Speech and Stance Detection
Mar 02, 2021

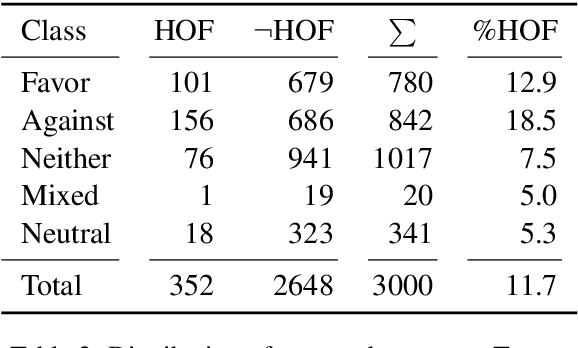
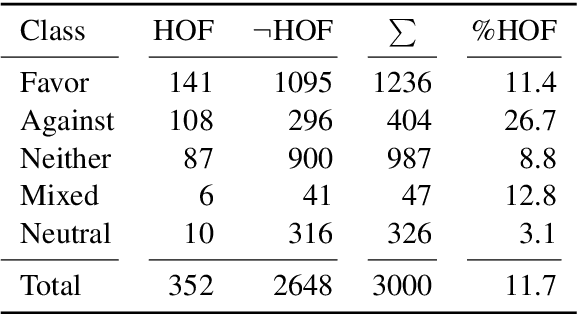
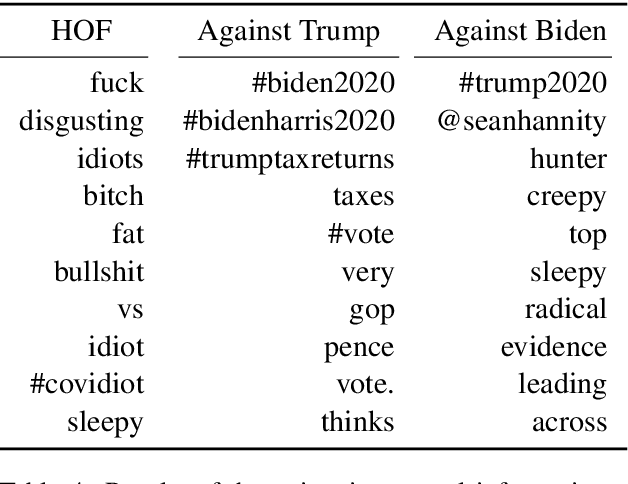
The 2020 US Elections have been, more than ever before, characterized by social media campaigns and mutual accusations. We investigate in this paper if this manifests also in online communication of the supporters of the candidates Biden and Trump, by uttering hateful and offensive communication. We formulate an annotation task, in which we join the tasks of hateful/offensive speech detection and stance detection, and annotate 3000 Tweets from the campaign period, if they express a particular stance towards a candidate. Next to the established classes of favorable and against, we add mixed and neutral stances and also annotate if a candidate is mentioned without an opinion expression. Further, we annotate if the tweet is written in an offensive style. This enables us to analyze if supporters of Joe Biden and the Democratic Party communicate differently than supporters of Donald Trump and the Republican Party. A BERT baseline classifier shows that the detection if somebody is a supporter of a candidate can be performed with high quality (.89 F1 for Trump and .91 F1 for Biden), while the detection that somebody expresses to be against a candidate is more challenging (.79 F1 and .64 F1, respectively). The automatic detection of hate/offensive speech remains challenging (with .53 F1). Our corpus is publicly available and constitutes a novel resource for computational modelling of offensive language under consideration of stances.
Dynamic Temporal Alignment of Speech to Lips
Aug 19, 2018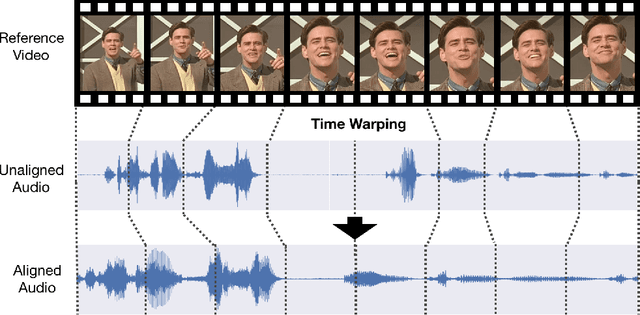
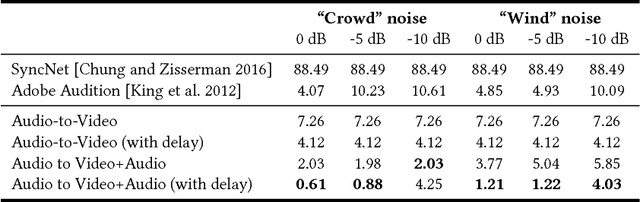
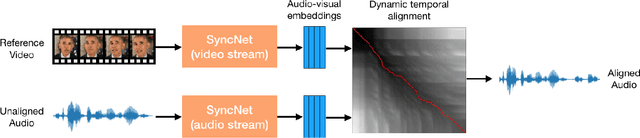
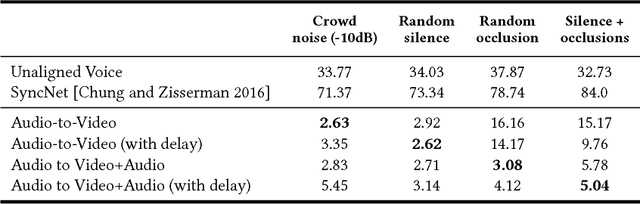
Many speech segments in movies are re-recorded in a studio during postproduction, to compensate for poor sound quality as recorded on location. Manual alignment of the newly-recorded speech with the original lip movements is a tedious task. We present an audio-to-video alignment method for automating speech to lips alignment, stretching and compressing the audio signal to match the lip movements. This alignment is based on deep audio-visual features, mapping the lips video and the speech signal to a shared representation. Using this shared representation we compute the lip-sync error between every short speech period and every video frame, followed by the determination of the optimal corresponding frame for each short sound period over the entire video clip. We demonstrate successful alignment both quantitatively, using a human perception-inspired metric, as well as qualitatively. The strongest advantage of our audio-to-video approach is in cases where the original voice in unclear, and where a constant shift of the sound can not give a perfect alignment. In these cases state-of-the-art methods will fail.
The PyTorch-Kaldi Speech Recognition Toolkit
Nov 19, 2018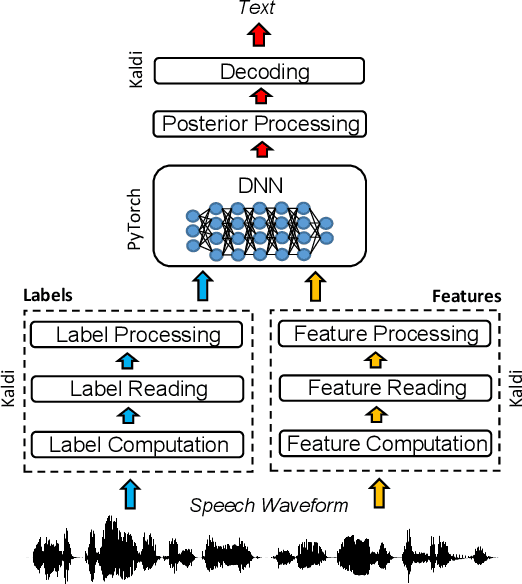
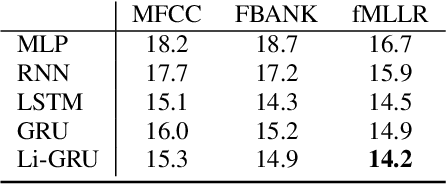

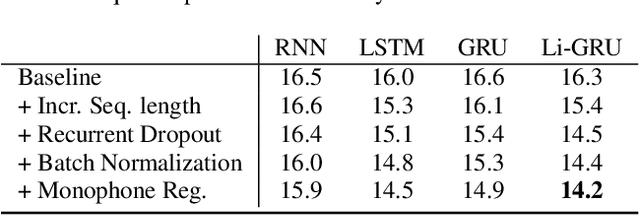
The availability of open-source software is playing a remarkable role in the popularization of speech recognition and deep learning. Kaldi, for instance, is nowadays an established framework used to develop state-of-the-art speech recognizers. PyTorch is used to build neural networks with the Python language and has recently spawn tremendous interest within the machine learning community thanks to its simplicity and flexibility. The PyTorch-Kaldi project aims to bridge the gap between these popular toolkits, trying to inherit the efficiency of Kaldi and the flexibility of PyTorch. PyTorch-Kaldi is not only a simple interface between these software, but it embeds several useful features for developing modern speech recognizers. For instance, the code is specifically designed to naturally plug-in user-defined acoustic models. As an alternative, users can exploit several pre-implemented neural networks that can be customized using intuitive configuration files. PyTorch-Kaldi supports multiple feature and label streams as well as combinations of neural networks, enabling the use of complex neural architectures. The toolkit is publicly-released along with a rich documentation and is designed to properly work locally or on HPC clusters. Experiments, that are conducted on several datasets and tasks, show that PyTorch-Kaldi can effectively be used to develop modern state-of-the-art speech recognizers.
English Broadcast News Speech Recognition by Humans and Machines
Apr 30, 2019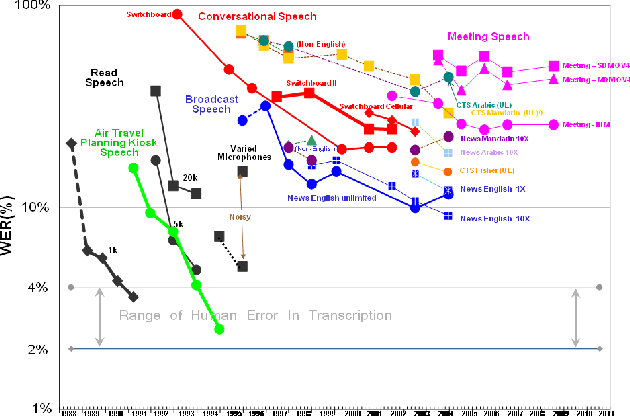
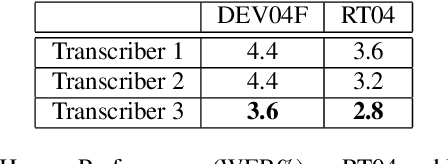


With recent advances in deep learning, considerable attention has been given to achieving automatic speech recognition performance close to human performance on tasks like conversational telephone speech (CTS) recognition. In this paper we evaluate the usefulness of these proposed techniques on broadcast news (BN), a similar challenging task. We also perform a set of recognition measurements to understand how close the achieved automatic speech recognition results are to human performance on this task. On two publicly available BN test sets, DEV04F and RT04, our speech recognition system using LSTM and residual network based acoustic models with a combination of n-gram and neural network language models performs at 6.5% and 5.9% word error rate. By achieving new performance milestones on these test sets, our experiments show that techniques developed on other related tasks, like CTS, can be transferred to achieve similar performance. In contrast, the best measured human recognition performance on these test sets is much lower, at 3.6% and 2.8% respectively, indicating that there is still room for new techniques and improvements in this space, to reach human performance levels.
A Surprising Density of Illusionable Natural Speech
Jun 05, 2019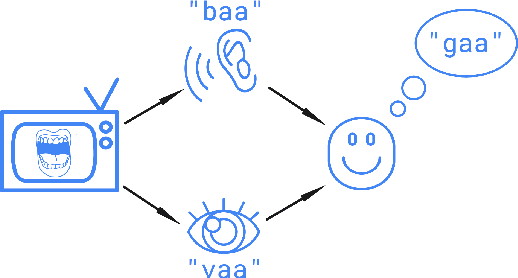

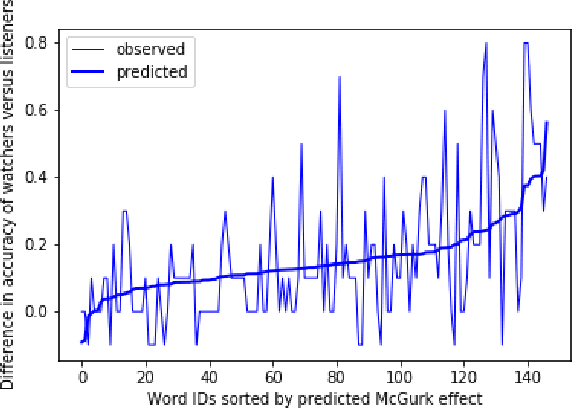
Recent work on adversarial examples has demonstrated that most natural inputs can be perturbed to fool even state-of-the-art machine learning systems. But does this happen for humans as well? In this work, we investigate: what fraction of natural instances of speech can be turned into "illusions" which either alter humans' perception or result in different people having significantly different perceptions? We first consider the McGurk effect, the phenomenon by which adding a carefully chosen video clip to the audio channel affects the viewer's perception of what is said (McGurk and MacDonald, 1976). We obtain empirical estimates that a significant fraction of both words and sentences occurring in natural speech have some susceptibility to this effect. We also learn models for predicting McGurk illusionability. Finally we demonstrate that the Yanny or Laurel auditory illusion (Pressnitzer et al., 2018) is not an isolated occurrence by generating several very different new instances. We believe that the surprising density of illusionable natural speech warrants further investigation, from the perspectives of both security and cognitive science. Supplementary videos are available at: https://www.youtube.com/playlist?list=PLaX7t1K-e_fF2iaenoKznCatm0RC37B_k.
Computational bioacoustics with deep learning: a review and roadmap
Dec 13, 2021
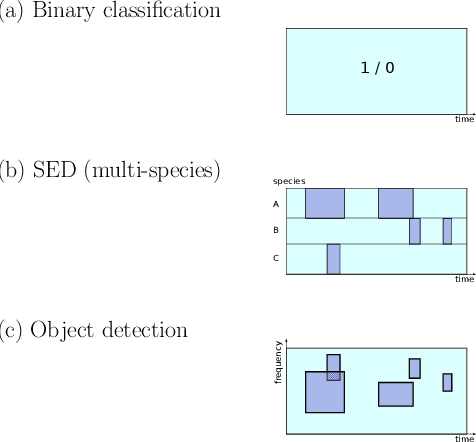
Animal vocalisations and natural soundscapes are fascinating objects of study, and contain valuable evidence about animal behaviours, populations and ecosystems. They are studied in bioacoustics and ecoacoustics, with signal processing and analysis an important component. Computational bioacoustics has accelerated in recent decades due to the growth of affordable digital sound recording devices, and to huge progress in informatics such as big data, signal processing and machine learning. Methods are inherited from the wider field of deep learning, including speech and image processing. However, the tasks, demands and data characteristics are often different from those addressed in speech or music analysis. There remain unsolved problems, and tasks for which evidence is surely present in many acoustic signals, but not yet realised. In this paper I perform a review of the state of the art in deep learning for computational bioacoustics, aiming to clarify key concepts and identify and analyse knowledge gaps. Based on this, I offer a subjective but principled roadmap for computational bioacoustics with deep learning: topics that the community should aim to address, in order to make the most of future developments in AI and informatics, and to use audio data in answering zoological and ecological questions.
Attacker Attribution of Audio Deepfakes
Mar 28, 2022
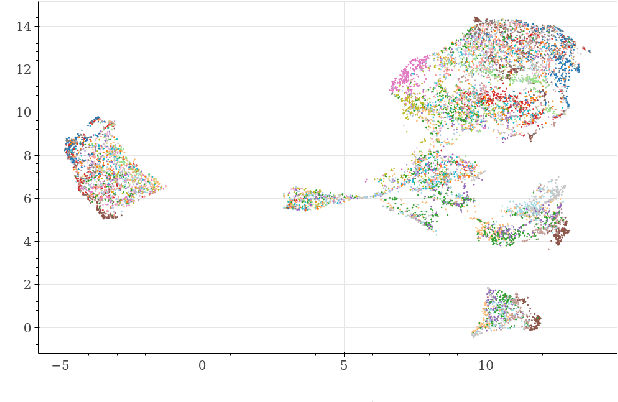
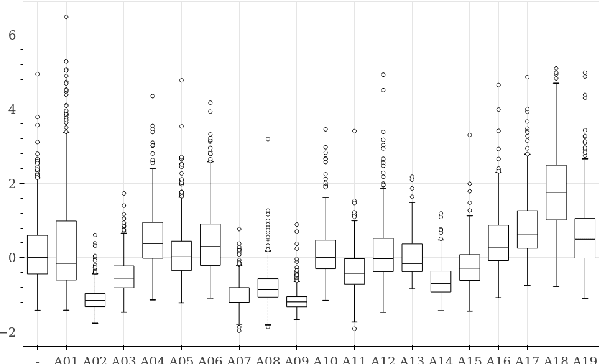
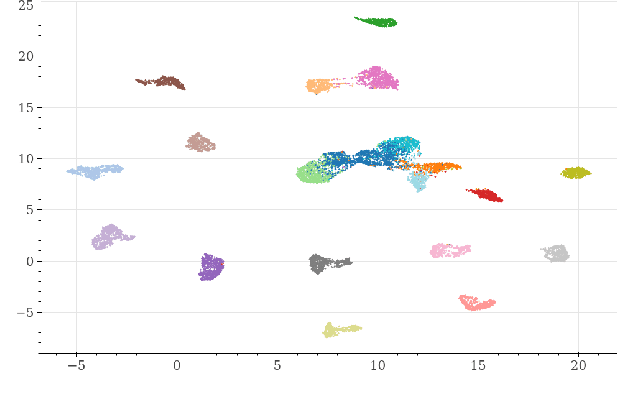
Deepfakes are synthetically generated media often devised with malicious intent. They have become increasingly more convincing with large training datasets advanced neural networks. These fakes are readily being misused for slander, misinformation and fraud. For this reason, intensive research for developing countermeasures is also expanding. However, recent work is almost exclusively limited to deepfake detection - predicting if audio is real or fake. This is despite the fact that attribution (who created which fake?) is an essential building block of a larger defense strategy, as practiced in the field of cybersecurity for a long time. This paper considers the problem of deepfake attacker attribution in the domain of audio. We present several methods for creating attacker signatures using low-level acoustic descriptors and machine learning embeddings. We show that speech signal features are inadequate for characterizing attacker signatures. However, we also demonstrate that embeddings from a recurrent neural network can successfully characterize attacks from both known and unknown attackers. Our attack signature embeddings result in distinct clusters, both for seen and unseen audio deepfakes. We show that these embeddings can be used in downstream-tasks to high-effect, scoring 97.10% accuracy in attacker-id classification.
Detecting Emotion Carriers by Combining Acoustic and Lexical Representations
Dec 13, 2021
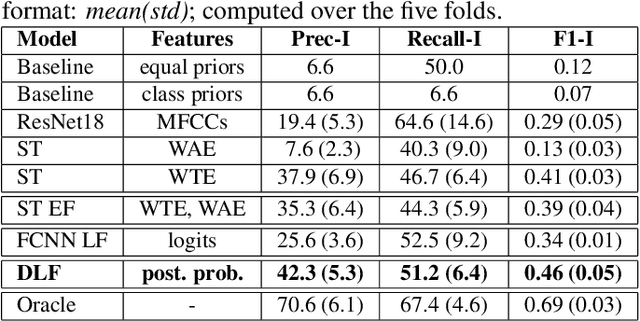
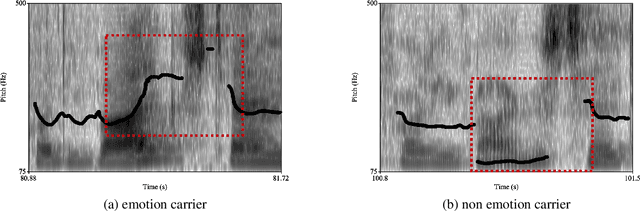
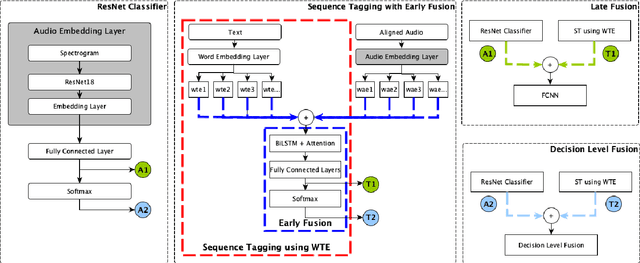
Personal narratives (PN) - spoken or written - are recollections of facts, people, events, and thoughts from one's own experience. Emotion recognition and sentiment analysis tasks are usually defined at the utterance or document level. However, in this work, we focus on Emotion Carriers (EC) defined as the segments (speech or text) that best explain the emotional state of the narrator ("loss of father", "made me choose"). Once extracted, such EC can provide a richer representation of the user state to improve natural language understanding and dialogue modeling. In previous work, it has been shown that EC can be identified using lexical features. However, spoken narratives should provide a richer description of the context and the users' emotional state. In this paper, we leverage word-based acoustic and textual embeddings as well as early and late fusion techniques for the detection of ECs in spoken narratives. For the acoustic word-level representations, we use Residual Neural Networks (ResNet) pretrained on separate speech emotion corpora and fine-tuned to detect EC. Experiments with different fusion and system combination strategies show that late fusion leads to significant improvements for this task.
Should we hard-code the recurrence concept or learn it instead ? Exploring the Transformer architecture for Audio-Visual Speech Recognition
May 19, 2020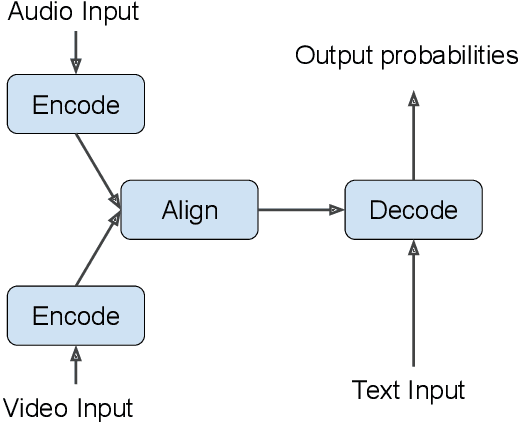
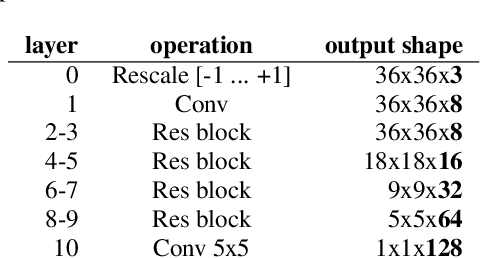
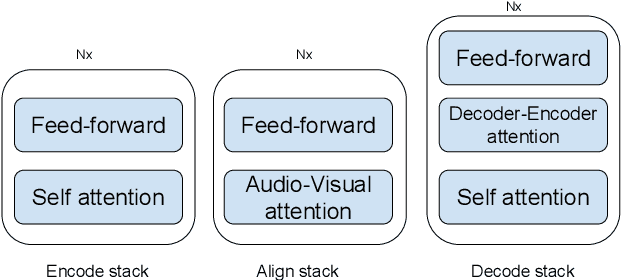
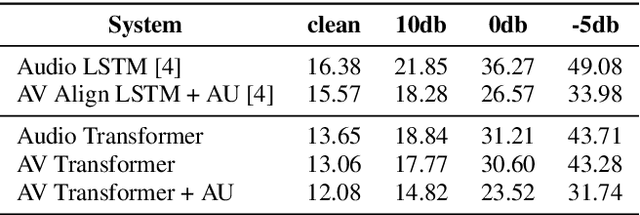
The audio-visual speech fusion strategy AV Align has shown significant performance improvements in audio-visual speech recognition (AVSR) on the challenging LRS2 dataset. Performance improvements range between 7% and 30% depending on the noise level when leveraging the visual modality of speech in addition to the auditory one. This work presents a variant of AV Align where the recurrent Long Short-term Memory (LSTM) computation block is replaced by the more recently proposed Transformer block. We compare the two methods, discussing in greater detail their strengths and weaknesses. We find that Transformers also learn cross-modal monotonic alignments, but suffer from the same visual convergence problems as the LSTM model, calling for a deeper investigation into the dominant modality problem in machine learning.
VAIS ASR: Building a conversational speech recognition system using language model combination
Oct 12, 2019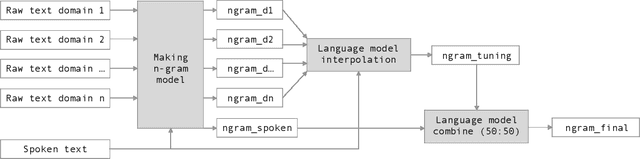
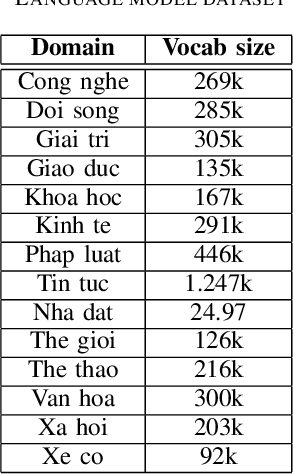
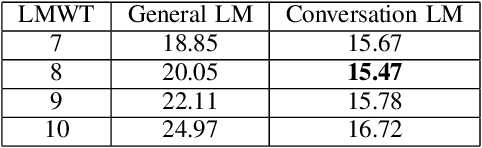
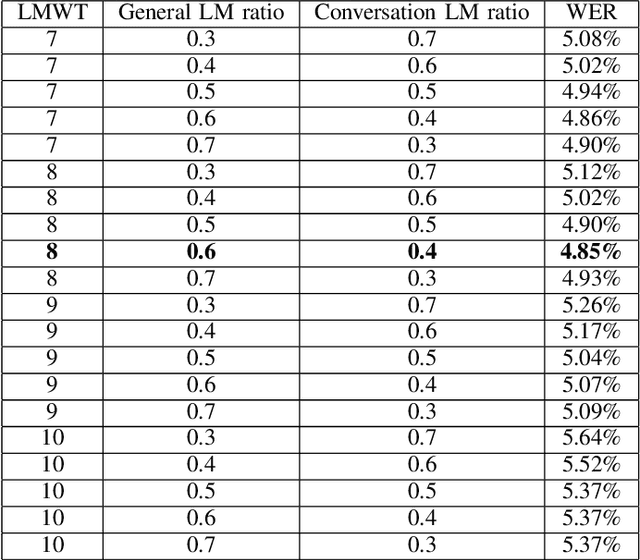
Automatic Speech Recognition (ASR) systems have been evolving quickly and reaching human parity in certain cases. The systems usually perform pretty well on reading style and clean speech, however, most of the available systems suffer from situation where the speaking style is conversation and in noisy environments. It is not straight-forward to tackle such problems due to difficulties in data collection for both speech and text. In this paper, we attempt to mitigate the problems using language models combination techniques that allows us to utilize both large amount of writing style text and small number of conversation text data. Evaluation on the VLSP 2019 ASR challenges showed that our system achieved 4.85% WER on the VLSP 2018 and 15.09% WER on the VLSP 2019 data sets.