 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Learning Speaker Embedding from Text-to-Speech
Oct 21, 2020
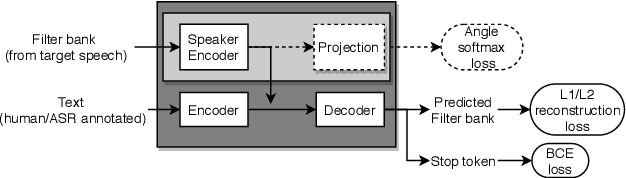

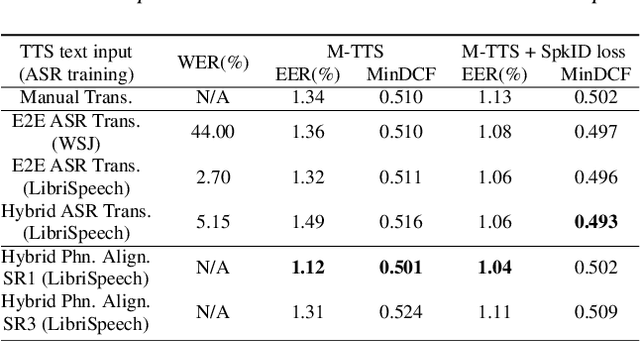
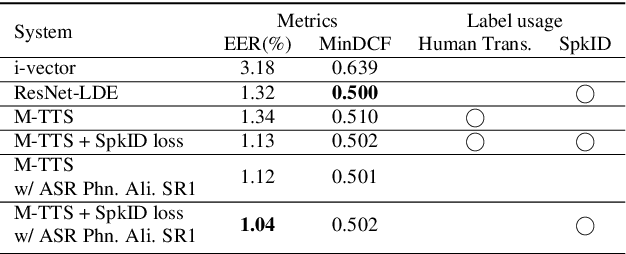
Zero-shot multi-speaker Text-to-Speech (TTS) generates target speaker voices given an input text and the corresponding speaker embedding. In this work, we investigate the effectiveness of the TTS reconstruction objective to improve representation learning for speaker verification. We jointly trained end-to-end Tacotron 2 TTS and speaker embedding networks in a self-supervised fashion. We hypothesize that the embeddings will contain minimal phonetic information since the TTS decoder will obtain that information from the textual input. TTS reconstruction can also be combined with speaker classification to enhance these embeddings further. Once trained, the speaker encoder computes representations for the speaker verification task, while the rest of the TTS blocks are discarded. We investigated training TTS from either manual or ASR-generated transcripts. The latter allows us to train embeddings on datasets without manual transcripts. We compared ASR transcripts and Kaldi phone alignments as TTS inputs, showing that the latter performed better due to their finer resolution. Unsupervised TTS embeddings improved EER by 2.06\% absolute with regard to i-vectors for the LibriTTS dataset. TTS with speaker classification loss improved EER by 0.28\% and 0.73\% absolutely from a model using only speaker classification loss in LibriTTS and Voxceleb1 respectively.
Simplified Self-Attention for Transformer-based End-to-End Speech Recognition
May 21, 2020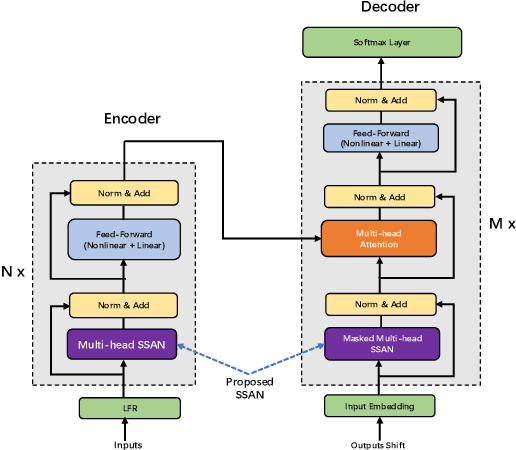
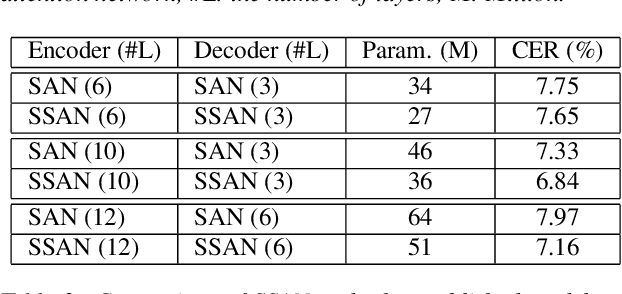
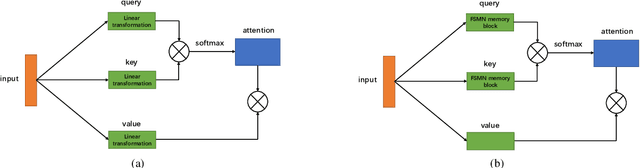
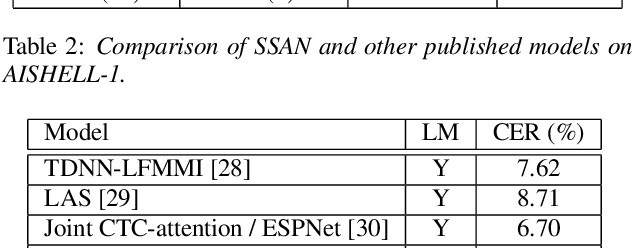
Transformer models have been introduced into end-to-end speech recognition with state-of-the-art performance on various tasks owing to their superiority in modeling long-term dependencies. However, such improvements are usually obtained through the use of very large neural networks. Transformer models mainly include two submodules - position-wise feedforward layers and self-attention (SAN) layers. In this paper, to reduce the model complexity while maintaining good performance, we propose a simplified self-attention (SSAN) layer which employs FSMN memory block instead of projection layers to form query and key vectors for transformer-based end-to-end speech recognition. We evaluate the SSAN-based and the conventional SAN-based transformers on the public AISHELL-1, internal 1000-hour and 20,000-hour large-scale Mandarin tasks. Results show that our proposed SSAN-based transformer model can achieve over 20% relative reduction in model parameters and 6.7% relative CER reduction on the AISHELL-1 task. With impressively 20% parameter reduction, our model shows no loss of recognition performance on the 20,000-hour large-scale task.
Advanced Rich Transcription System for Estonian Speech
Jan 11, 2019
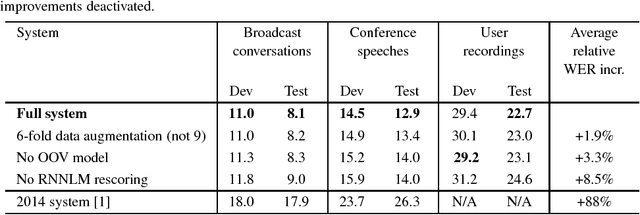

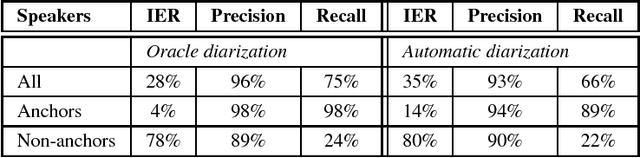
This paper describes the current TT\"U speech transcription system for Estonian speech. The system is designed to handle semi-spontaneous speech, such as broadcast conversations, lecture recordings and interviews recorded in diverse acoustic conditions. The system is based on the Kaldi toolkit. Multi-condition training using background noise profiles extracted automatically from untranscribed data is used to improve the robustness of the system. Out-of-vocabulary words are recovered using a phoneme n-gram based decoding subgraph and a FST-based phoneme-to-grapheme model. The system achieves a word error rate of 8.1% on a test set of broadcast conversations. The system also performs punctuation recovery and speaker identification. Speaker identification models are trained using a recently proposed weakly supervised training method.
* Published in Baltic HLT 2018 (putting it on arXiv because Google Scholar doesn't index it properly)
Towards Interpretable and Transferable Speech Emotion Recognition: Latent Representation Based Analysis of Features, Methods and Corpora
May 05, 2021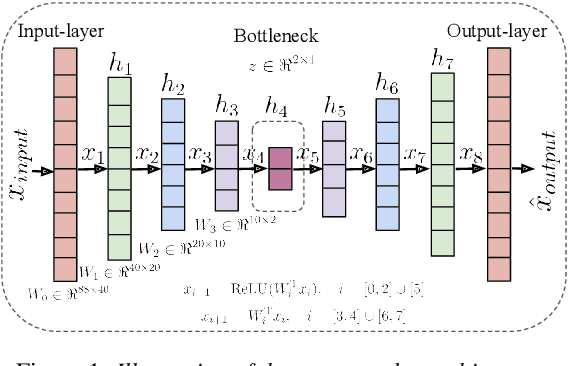
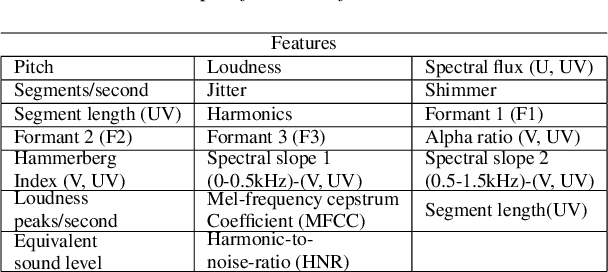
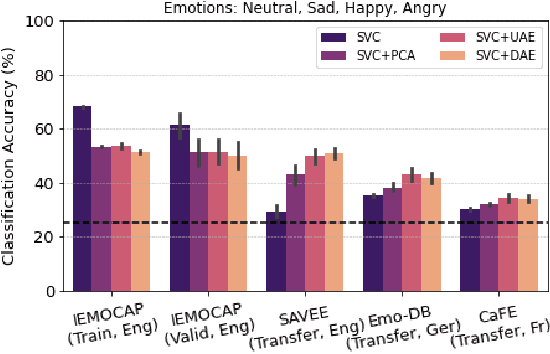
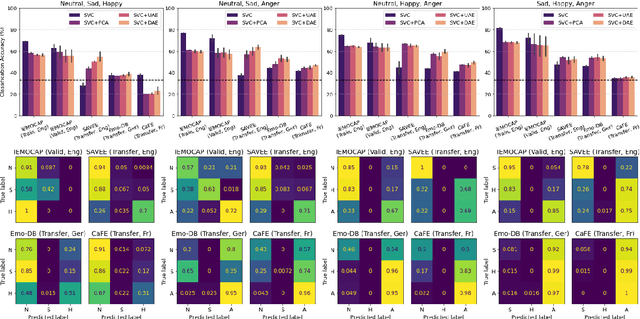
In recent years, speech emotion recognition (SER) has been used in wide ranging applications, from healthcare to the commercial sector. In addition to signal processing approaches, methods for SER now also use deep learning techniques. However, generalizing over languages, corpora and recording conditions is still an open challenge in the field. Furthermore, due to the black-box nature of deep learning algorithms, a newer challenge is the lack of interpretation and transparency in the models and the decision making process. This is critical when the SER systems are deployed in applications that influence human lives. In this work we address this gap by providing an in-depth analysis of the decision making process of the proposed SER system. Towards that end, we present low-complexity SER based on undercomplete- and denoising- autoencoders that achieve an average classification accuracy of over 55\% for four-class emotion classification. Following this, we investigate the clustering of emotions in the latent space to understand the influence of the corpora on the model behavior and to obtain a physical interpretation of the latent embedding. Lastly, we explore the role of each input feature towards the performance of the SER.
End-to-End Speech-Translation with Knowledge Distillation: FBK@IWSLT2020
Jun 04, 2020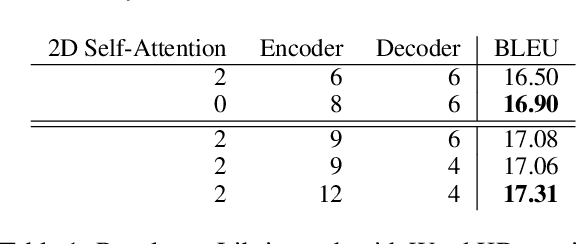
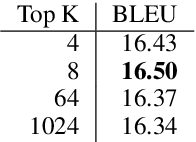
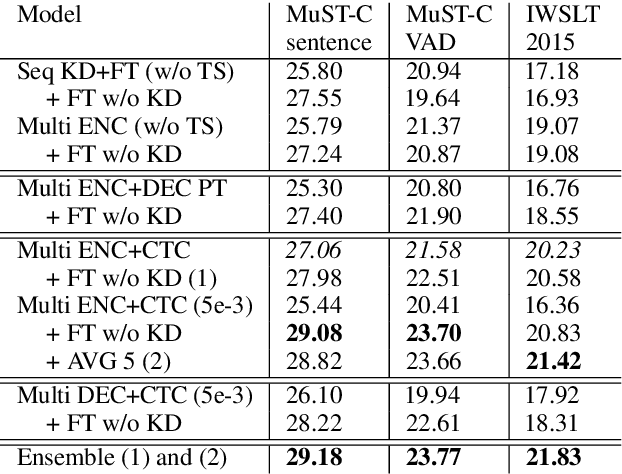
This paper describes FBK's participation in the IWSLT 2020 offline speech translation (ST) task. The task evaluates systems' ability to translate English TED talks audio into German texts. The test talks are provided in two versions: one contains the data already segmented with automatic tools and the other is the raw data without any segmentation. Participants can decide whether to work on custom segmentation or not. We used the provided segmentation. Our system is an end-to-end model based on an adaptation of the Transformer for speech data. Its training process is the main focus of this paper and it is based on: i) transfer learning (ASR pretraining and knowledge distillation), ii) data augmentation (SpecAugment, time stretch and synthetic data), iii) combining synthetic and real data marked as different domains, and iv) multi-task learning using the CTC loss. Finally, after the training with word-level knowledge distillation is complete, our ST models are fine-tuned using label smoothed cross entropy. Our best model scored 29 BLEU on the MuST-C En-De test set, which is an excellent result compared to recent papers, and 23.7 BLEU on the same data segmented with VAD, showing the need for researching solutions addressing this specific data condition.
Streaming parallel transducer beam search with fast-slow cascaded encoders
Mar 29, 2022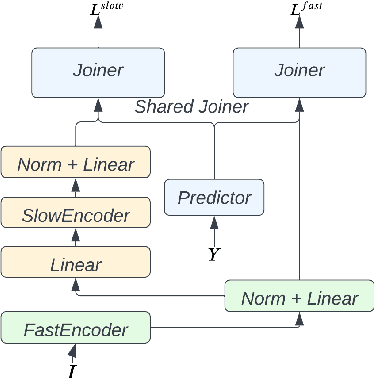
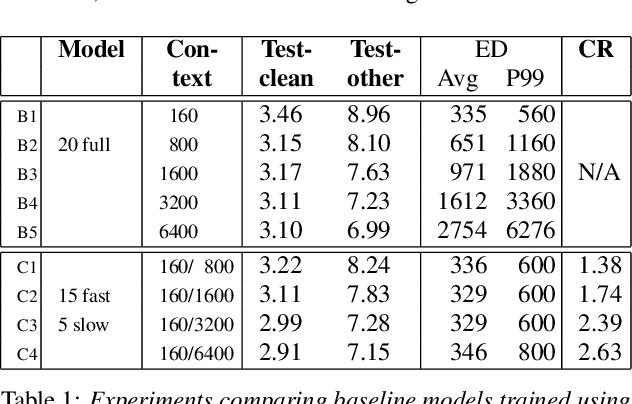
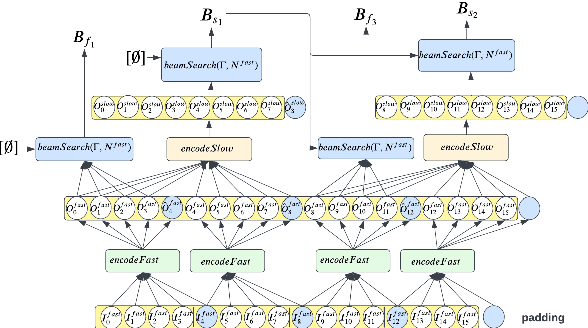
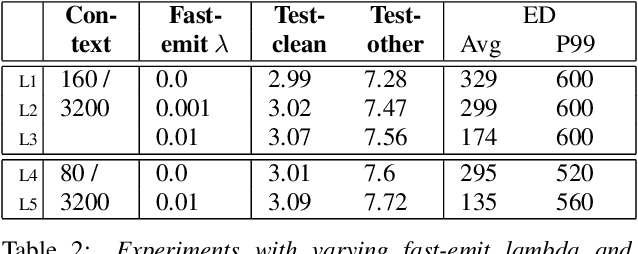
Streaming ASR with strict latency constraints is required in many speech recognition applications. In order to achieve the required latency, streaming ASR models sacrifice accuracy compared to non-streaming ASR models due to lack of future input context. Previous research has shown that streaming and non-streaming ASR for RNN Transducers can be unified by cascading causal and non-causal encoders. This work improves upon this cascaded encoders framework by leveraging two streaming non-causal encoders with variable input context sizes that can produce outputs at different audio intervals (e.g. fast and slow). We propose a novel parallel time-synchronous beam search algorithm for transducers that decodes from fast-slow encoders, where the slow encoder corrects the mistakes generated from the fast encoder. The proposed algorithm, achieves up to 20% WER reduction with a slight increase in token emission delays on the public Librispeech dataset and in-house datasets. We also explore techniques to reduce the computation by distributing processing between the fast and slow encoders. Lastly, we explore sharing the parameters in the fast encoder to reduce the memory footprint. This enables low latency processing on edge devices with low computation cost and a low memory footprint.
BiosecurID: a multimodal biometric database
Nov 02, 2021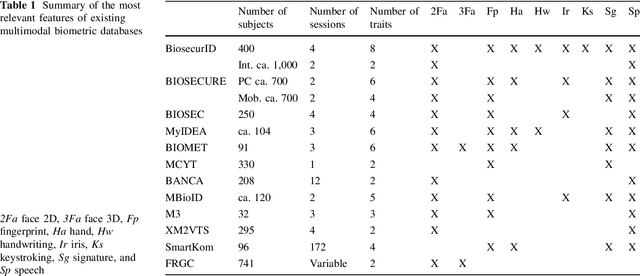

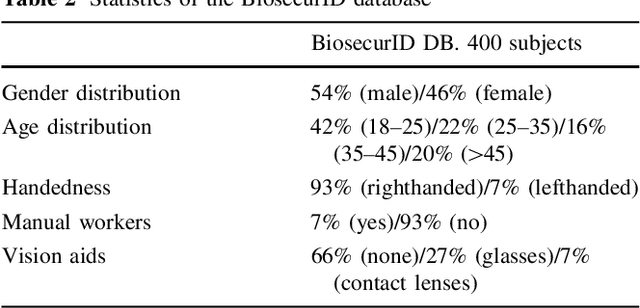
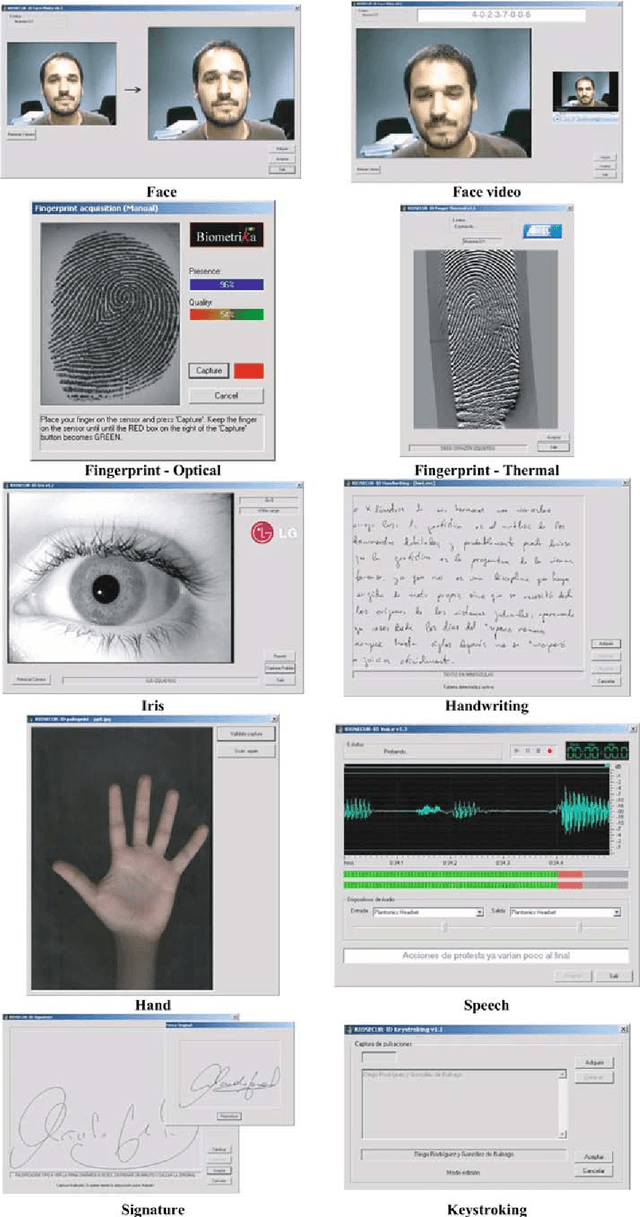
A new multimodal biometric database, acquired in the framework of the BiosecurID project, is presented together with the description of the acquisition setup and protocol. The database includes eight unimodal biometric traits, namely: speech, iris, face (still images, videos of talking faces), handwritten signature and handwritten text (on-line dynamic signals, off-line scanned images), fingerprints (acquired with two different sensors), hand (palmprint, contour-geometry) and keystroking. The database comprises 400 subjects and presents features such as: realistic acquisition scenario, balanced gender and population distributions, availability of information about particular demographic groups (age, gender, handedness), acquisition of replay attacks for speech and keystroking, skilled forgeries for signatures, and compatibility with other existing databases. All these characteristics make it very useful in research and development of unimodal and multimodal biometric systems.
Data Processing for Optimizing Naturalness of Vietnamese Text-to-speech System
Apr 20, 2020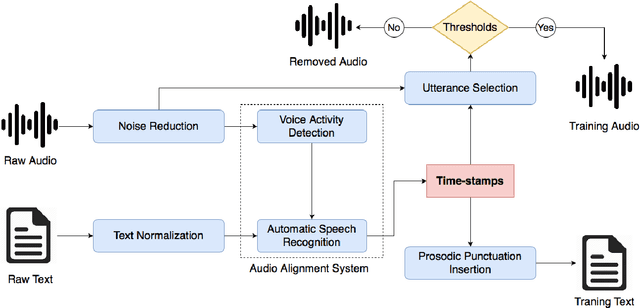
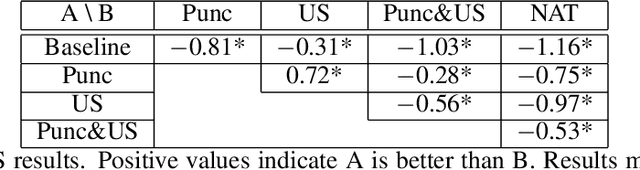
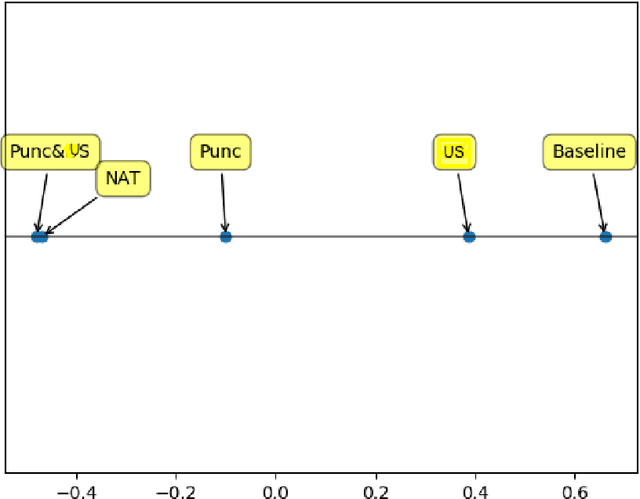
Abstract End-to-end text-to-speech (TTS) systems has proved its great success in the presence of a large amount of high-quality training data recorded in anechoic room with high-quality microphone. Another approach is to use available source of found data like radio broadcast news. We aim to optimize the naturalness of TTS system on the found data using a novel data processing method. The data processing method includes 1) utterance selection and 2) prosodic punctuation insertion to prepare training data which can optimize the naturalness of TTS systems. We showed that using the processing data method, an end-to-end TTS achieved a mean opinion score (MOS) of 4.1 compared to 4.3 of natural speech. We showed that the punctuation insertion contributed the most to the result. To facilitate the research and development of TTS systems, we distributed the processed data of one speaker at https://forms.gle/6Hk5YkqgDxAaC2BU6.
Large-Scale Visual Speech Recognition
Oct 01, 2018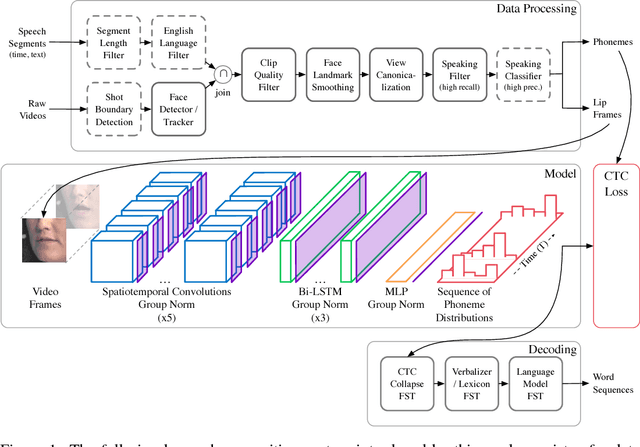
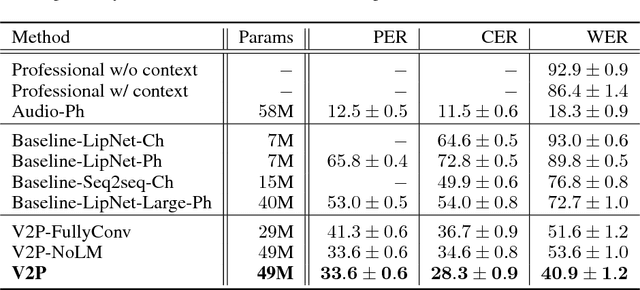


This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.
Slangvolution: A Causal Analysis of Semantic Change and Frequency Dynamics in Slang
Mar 09, 2022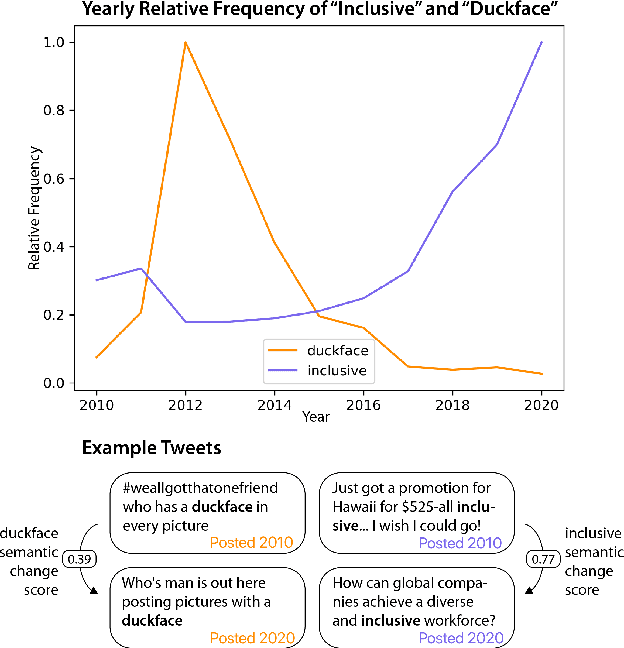

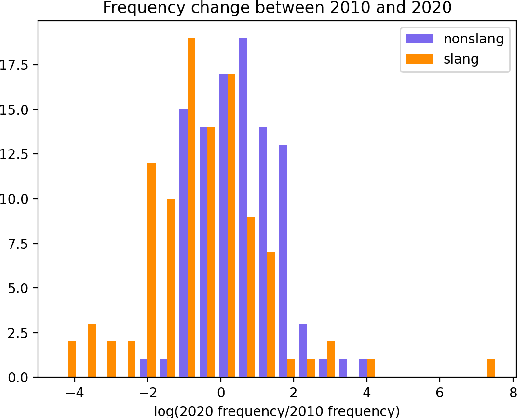
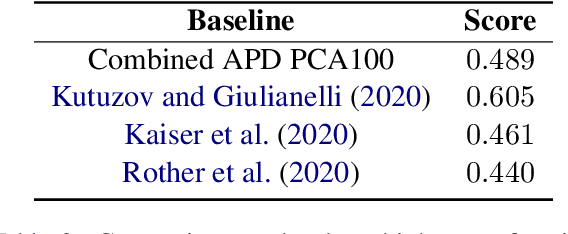
Languages are continuously undergoing changes, and the mechanisms that underlie these changes are still a matter of debate. In this work, we approach language evolution through the lens of causality in order to model not only how various distributional factors associate with language change, but how they causally affect it. In particular, we study slang, which is an informal language that is typically restricted to a specific group or social setting. We analyze the semantic change and frequency shift of slang words and compare them to those of standard, nonslang words. With causal discovery and causal inference techniques, we measure the effect that word type (slang/nonslang) has on both semantic change and frequency shift, as well as its relationship to frequency, polysemy and part of speech. Our analysis provides some new insights in the study of semantic change, e.g., we show that slang words undergo less semantic change but tend to have larger frequency shifts over time.