 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unified and Multilingual Author Profiling for Detecting Haters
Sep 19, 2021
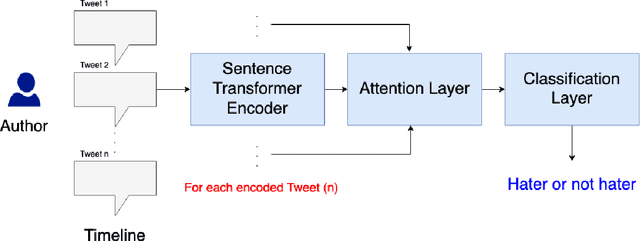

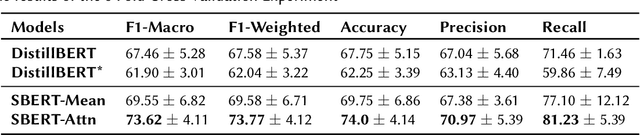
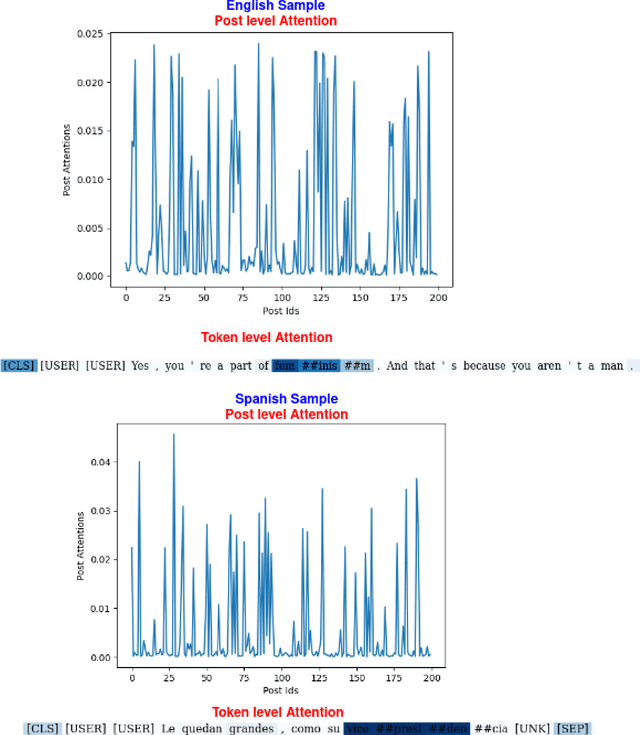
This paper presents a unified user profiling framework to identify hate speech spreaders by processing their tweets regardless of the language. The framework encodes the tweets with sentence transformers and applies an attention mechanism to select important tweets for learning user profiles. Furthermore, the attention layer helps to explain why a user is a hate speech spreader by producing attention weights at both token and post level. Our proposed model outperformed the state-of-the-art multilingual transformer models.
* 9 pages, 2 figures, see the original paper: http://ceur-ws.org/Vol-2936/paper-157.pdf
Similarity-and-Independence-Aware Beamformer with Iterative Casting and Boost Start for Target Source Extraction Using Reference
Oct 18, 2021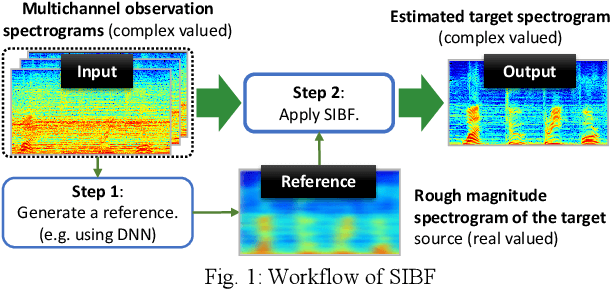
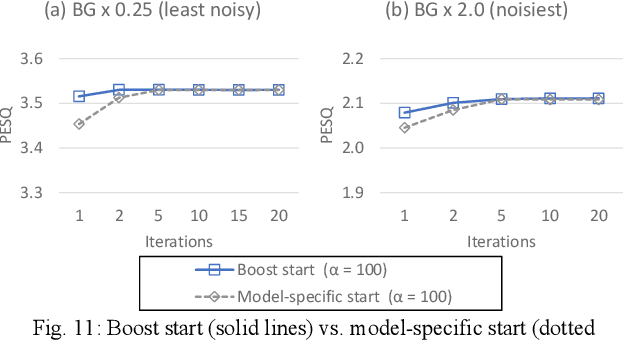
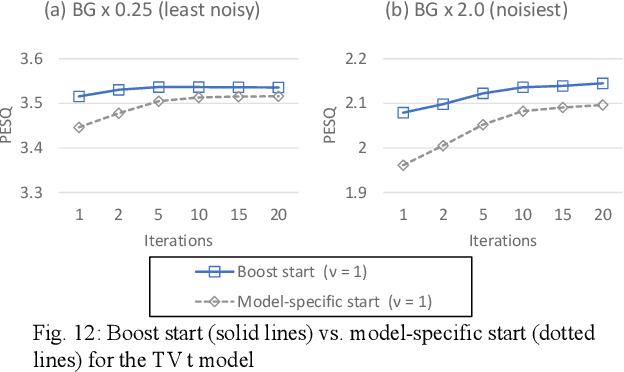
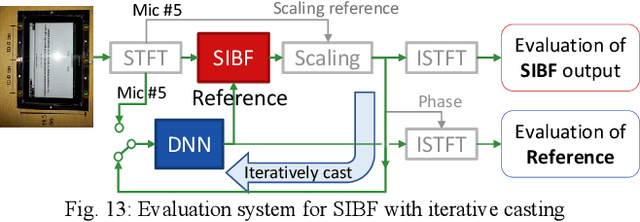
Target source extraction is significant for improving human speech intelligibility and the speech recognition performance of computers. This study describes a method for target source extraction, called the similarity-and-independence-aware beamformer (SIBF). The SIBF extracts the target source using a rough magnitude spectrogram as the reference signal. The advantage of the SIBF is that it can obtain a more accurate signal than the spectrogram generated by target-enhancing methods such as speech enhancement based on deep neural networks. For the extraction, we extend the framework of deflationary independent component analysis (ICA) by considering the similarities between the reference and extracted target sources, in addition to the mutual independence of all the potential sources. To solve the extraction problem by maximum-likelihood estimation, we introduce three source models that can reflect the similarities. The major contributions of this study are as follows. First, the extraction performance is improved using two methods, namely boost start for faster convergence and iterative casting for generating a more accurate reference. The effectiveness of these methods is verified through experiments using the CHiME3 dataset. Second, a concept of a fixed point pertaining to accuracy is developed. This concept facilitates understanding the relationship between the reference and SIBF output in terms of accuracy. Third, a unified formulation of the SIBF and mask-based beamformer is realized to apply the expertise of conventional BFs to the SIBF. The findings of this study can also improve the performance of the SIBF and promote research on ICA and conventional beamformers. Index Terms: beamformer, independent component analysis, source separation, speech enhancement, target source extraction
A Pyramid Recurrent Network for Predicting Crowdsourced Speech-Quality Ratings of Real-World Signals
Jul 31, 2020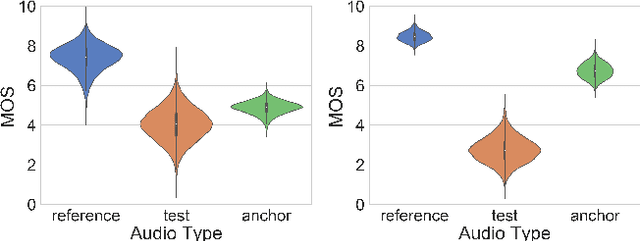
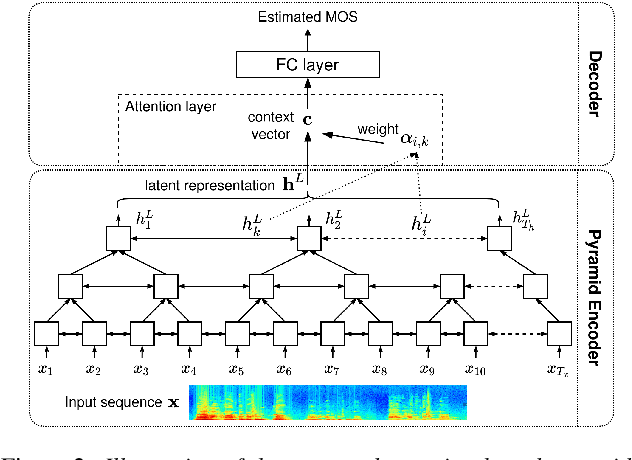
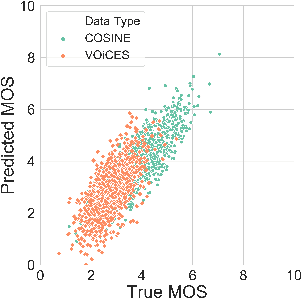
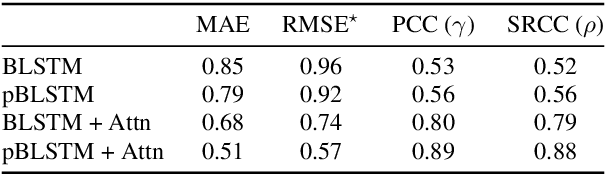
The real-world capabilities of objective speech quality measures are limited since current measures (1) are developed from simulated data that does not adequately model real environments; or they (2) predict objective scores that are not always strongly correlated with subjective ratings. Additionally, a large dataset of real-world signals with listener quality ratings does not currently exist, which would help facilitate real-world assessment. In this paper, we collect and predict the perceptual quality of real-world speech signals that are evaluated by human listeners. We first collect a large quality rating dataset by conducting crowdsourced listening studies on two real-world corpora. We further develop a novel approach that predicts human quality ratings using a pyramid bidirectional long short term memory (pBLSTM) network with an attention mechanism. The results show that the proposed model achieves statistically lower estimation errors than prior assessment approaches, where the predicted scores strongly correlate with human judgments.
Speech recognition for medical conversations
Jun 20, 2018
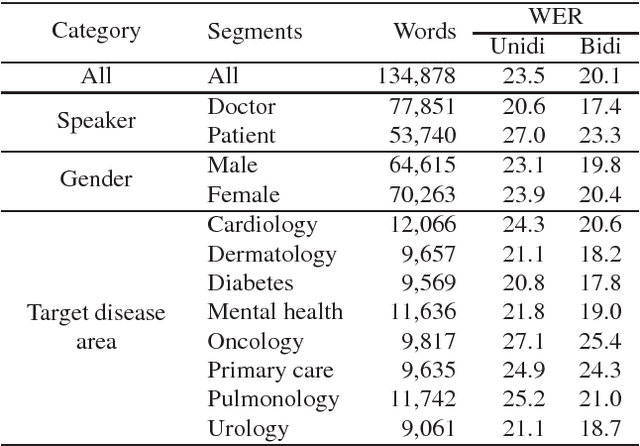
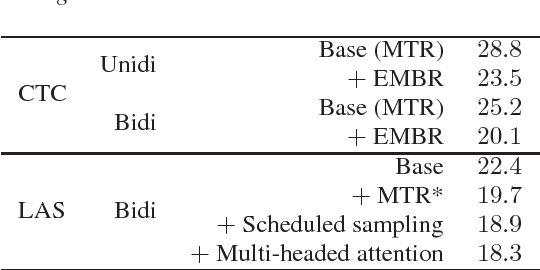
In this work we explored building automatic speech recognition models for transcribing doctor patient conversation. We collected a large scale dataset of clinical conversations ($14,000$ hr), designed the task to represent the real word scenario, and explored several alignment approaches to iteratively improve data quality. We explored both CTC and LAS systems for building speech recognition models. The LAS was more resilient to noisy data and CTC required more data clean up. A detailed analysis is provided for understanding the performance for clinical tasks. Our analysis showed the speech recognition models performed well on important medical utterances, while errors occurred in causal conversations. Overall we believe the resulting models can provide reasonable quality in practice.
Denoising Diffusion Gamma Models
Oct 10, 2021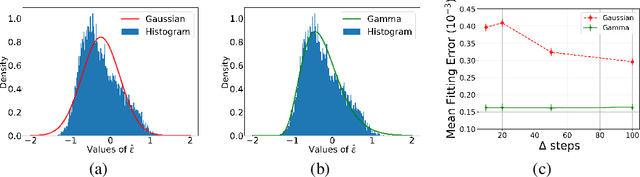
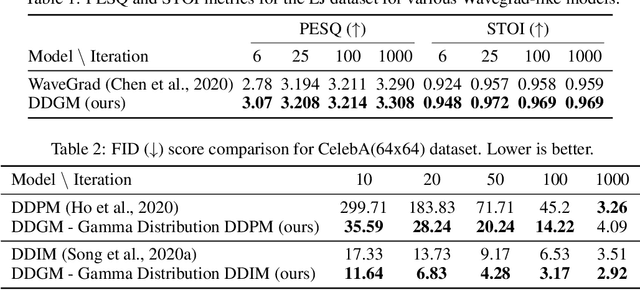
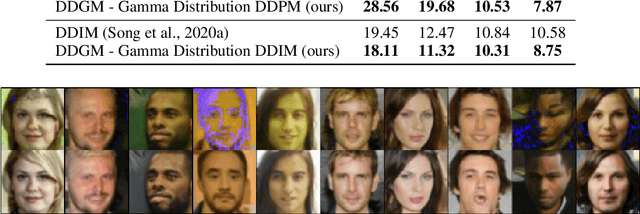
Generative diffusion processes are an emerging and effective tool for image and speech generation. In the existing methods, the underlying noise distribution of the diffusion process is Gaussian noise. However, fitting distributions with more degrees of freedom could improve the performance of such generative models. In this work, we investigate other types of noise distribution for the diffusion process. Specifically, we introduce the Denoising Diffusion Gamma Model (DDGM) and show that noise from Gamma distribution provides improved results for image and speech generation. Our approach preserves the ability to efficiently sample state in the training diffusion process while using Gamma noise.
Integrating Categorical Features in End-to-End ASR
Oct 06, 2021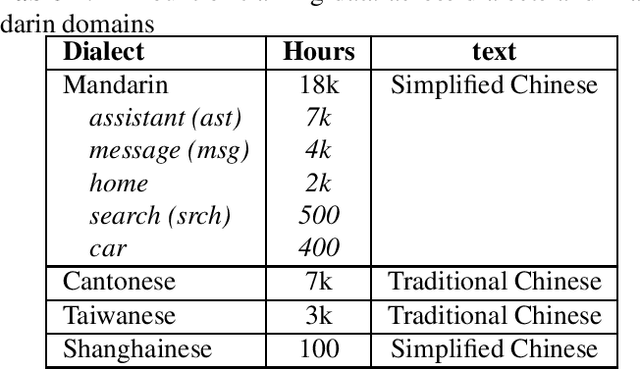
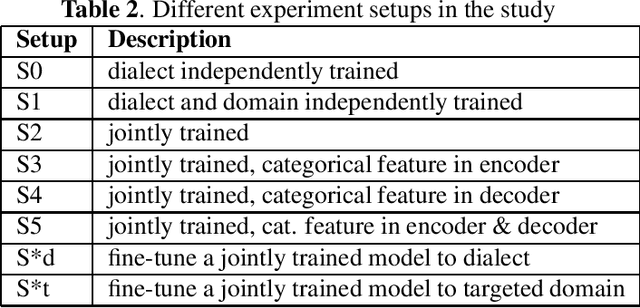
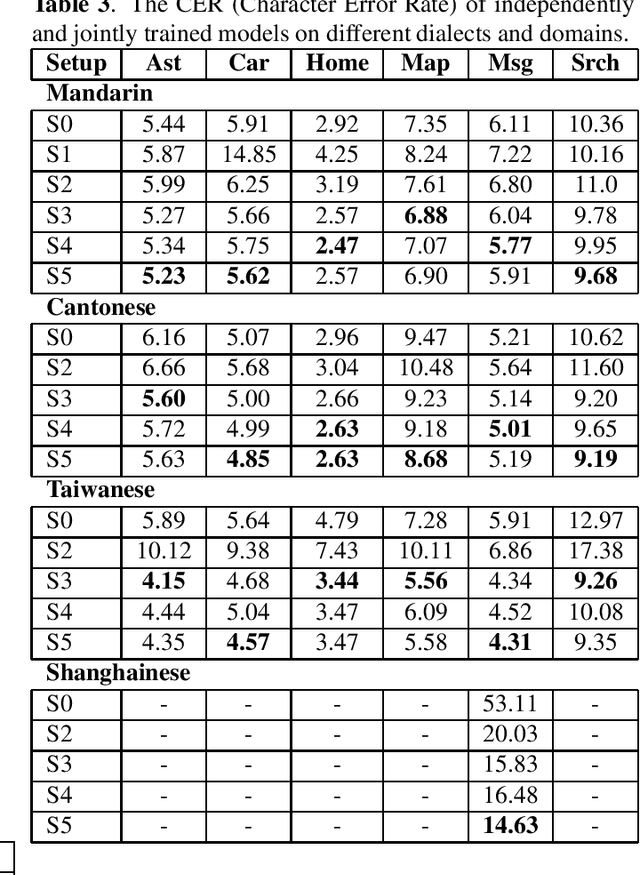
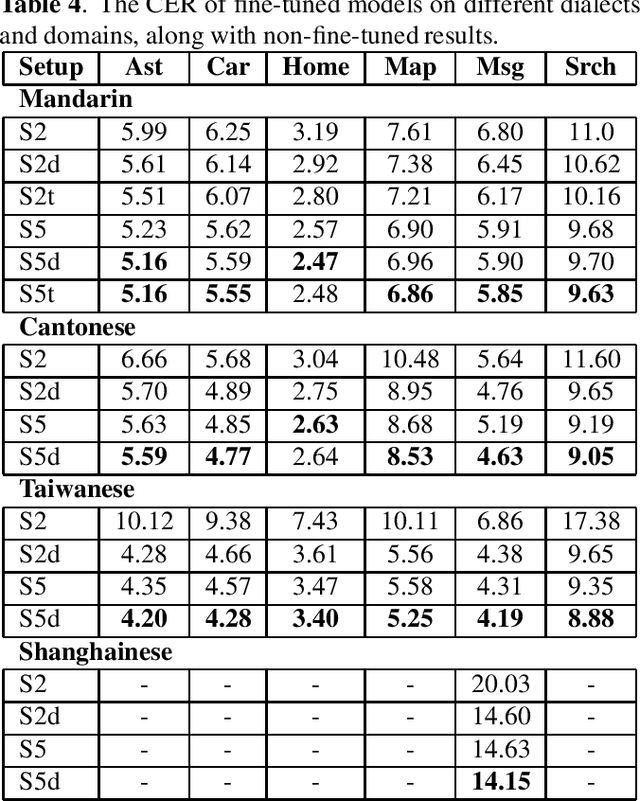
All-neural, end-to-end ASR systems gained rapid interest from the speech recognition community. Such systems convert speech input to text units using a single trainable neural network model. E2E models require large amounts of paired speech text data that is expensive to obtain. The amount of data available varies across different languages and dialects. It is critical to make use of all these data so that both low resource languages and high resource languages can be improved. When we want to deploy an ASR system for a new application domain, the amount of domain specific training data is very limited. To be able to leverage data from existing domains is important for ASR accuracy in the new domain. In this paper, we treat all these aspects as categorical information in an ASR system, and propose a simple yet effective way to integrate categorical features into E2E model. We perform detailed analysis on various training strategies, and find that building a joint model that includes categorical features can be more accurate than multiple independently trained models.
Emotional Voice Conversion using multitask learning with Text-to-speech
Nov 11, 2019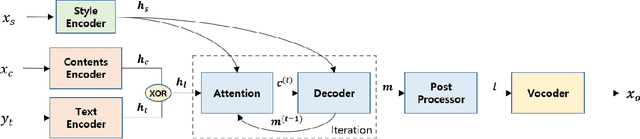

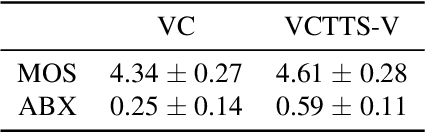
Voice conversion (VC) is a task to transform a person's voice to different style while conserving linguistic contents. Previous state-of-the-art on VC is based on sequence-to-sequence (seq2seq) model, which could mislead linguistic information. There was an attempt to overcome it by using textual supervision, it requires explicit alignment which loses the benefit of using seq2seq model. In this paper, a voice converter using multitask learning with text-to-speech (TTS) is presented. The embedding space of seq2seq-based TTS has abundant information on the text. The role of the decoder of TTS is to convert embedding space to speech, which is same to VC. In the proposed model, the whole network is trained to minimize loss of VC and TTS. VC is expected to capture more linguistic information and to preserve training stability by multitask learning. Experiments of VC were performed on a male Korean emotional text-speech dataset, and it is shown that multitask learning is helpful to keep linguistic contents in VC.
Convolutional Neural Network-based Speech Enhancement for Cochlear Implant Recipients
Jul 03, 2019
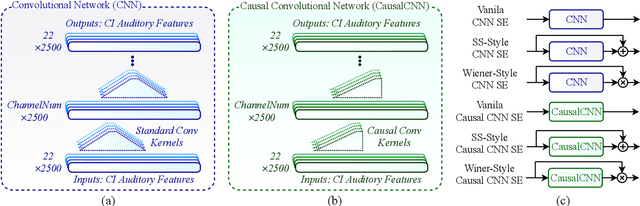
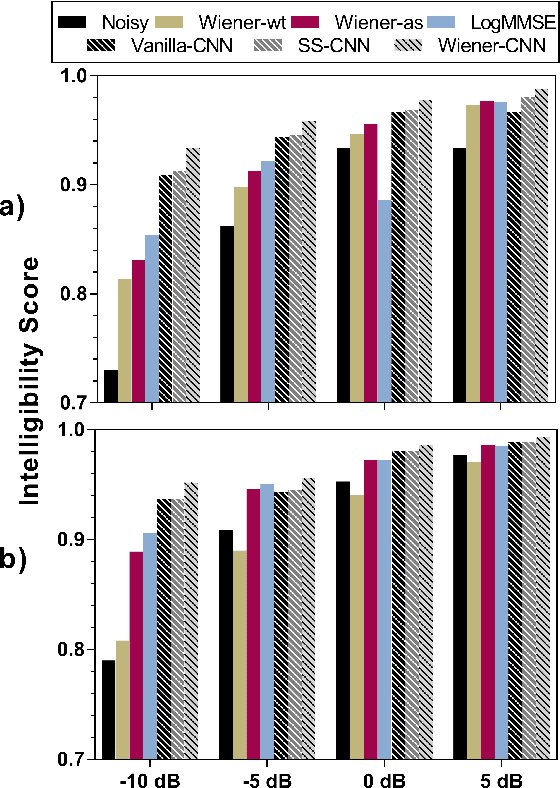
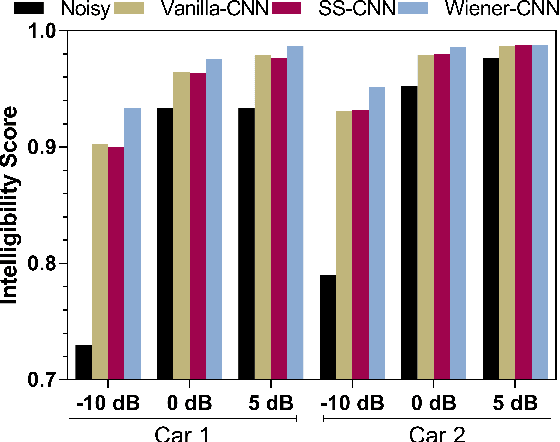
Attempts to develop speech enhancement algorithms with improved speech intelligibility for cochlear implant (CI) users have met with limited success. To improve speech enhancement methods for CI users, we propose to perform speech enhancement in a cochlear filter-bank feature space, a feature-set specifically designed for CI users based on CI auditory stimuli. We leverage a convolutional neural network (CNN) to extract both stationary and non-stationary components of environmental acoustics and speech. We propose three CNN architectures: (1) vanilla CNN that directly generates the enhanced signal; (2) spectral-subtraction-style CNN (SS-CNN) that first predicts noise and then generates the enhanced signal by subtracting noise from the noisy signal; (3) Wiener-style CNN (Wiener-CNN) that generates an optimal mask for suppressing noise. An important problem of the proposed networks is that they introduce considerable delays, which limits their real-time application for CI users. To address this, this study also considers causal variations of these networks. Our experiments show that the proposed networks (both causal and non-causal forms) achieve significant improvement over existing baseline systems. We also found that causal Wiener-CNN outperforms other networks, and leads to the best overall envelope coefficient measure (ECM). The proposed algorithms represent a viable option for implementation on the CCi-MOBILE research platform as a pre-processor for CI users in naturalistic environments.
Supervised Speech Separation Based on Deep Learning: An Overview
Jun 15, 2018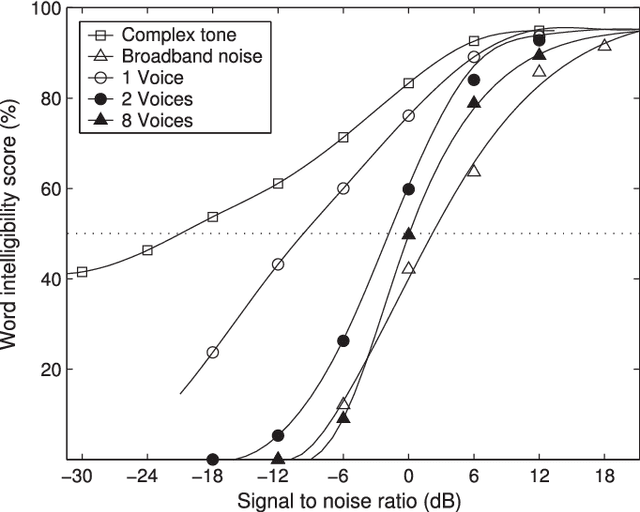
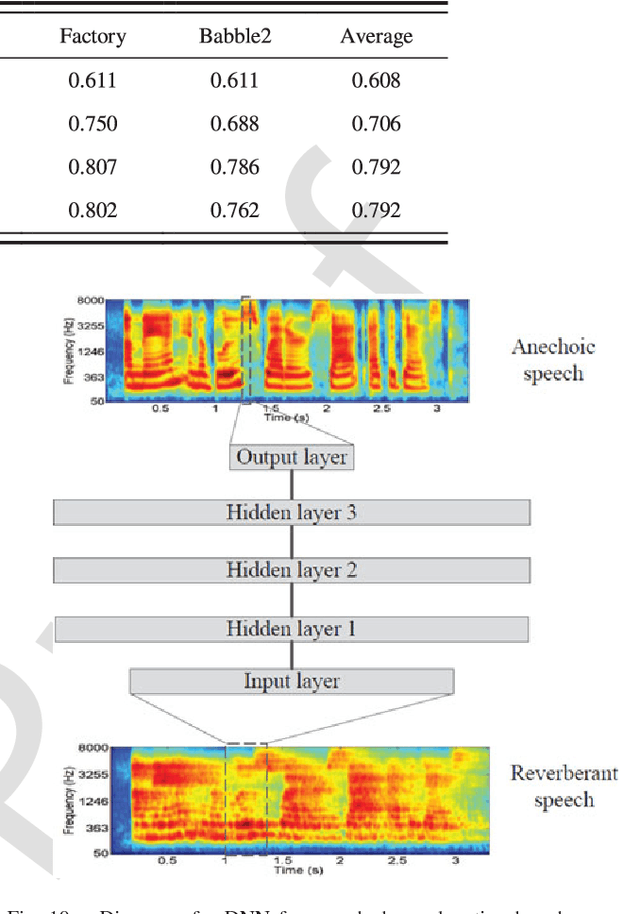
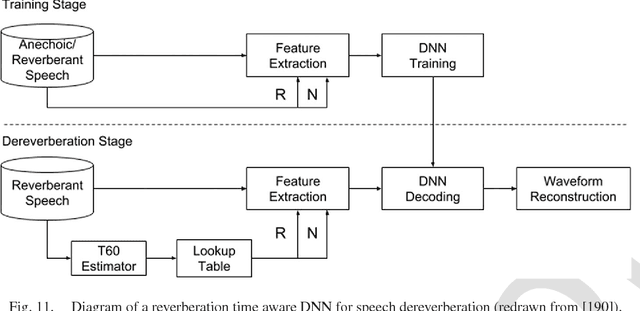
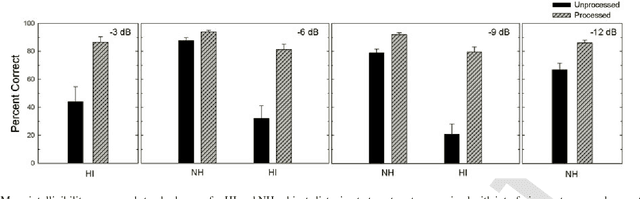
Speech separation is the task of separating target speech from background interference. Traditionally, speech separation is studied as a signal processing problem. A more recent approach formulates speech separation as a supervised learning problem, where the discriminative patterns of speech, speakers, and background noise are learned from training data. Over the past decade, many supervised separation algorithms have been put forward. In particular, the recent introduction of deep learning to supervised speech separation has dramatically accelerated progress and boosted separation performance. This article provides a comprehensive overview of the research on deep learning based supervised speech separation in the last several years. We first introduce the background of speech separation and the formulation of supervised separation. Then we discuss three main components of supervised separation: learning machines, training targets, and acoustic features. Much of the overview is on separation algorithms where we review monaural methods, including speech enhancement (speech-nonspeech separation), speaker separation (multi-talker separation), and speech dereverberation, as well as multi-microphone techniques. The important issue of generalization, unique to supervised learning, is discussed. This overview provides a historical perspective on how advances are made. In addition, we discuss a number of conceptual issues, including what constitutes the target source.
Adversarial Approximate Inference for Speech to Electroglottograph Conversion
Mar 28, 2019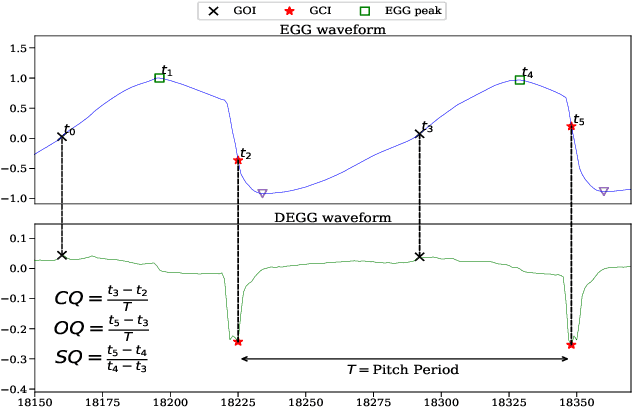
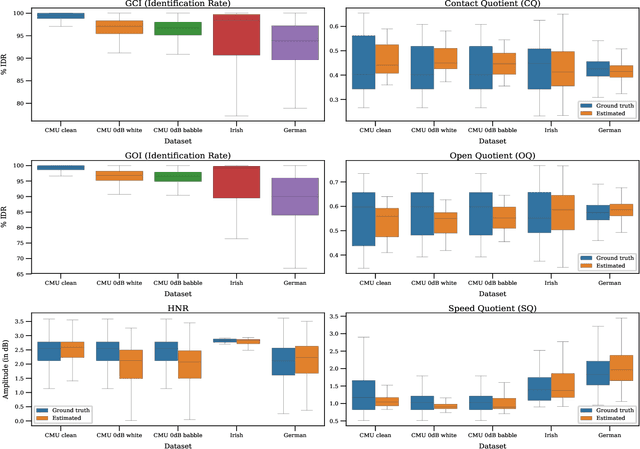

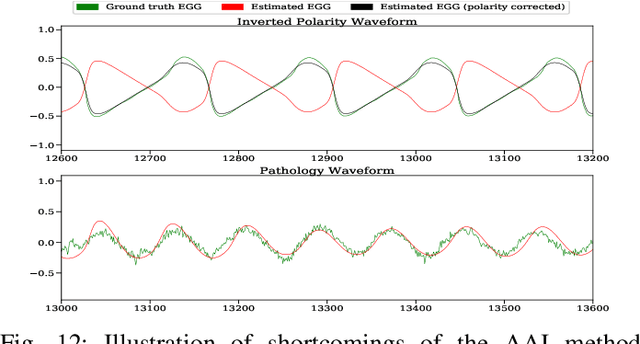
Speech produced by human vocal apparatus conveys substantial non-semantic information including the gender of the speaker, voice quality, affective state, abnormalities in the vocal apparatus etc. Such information is attributed to the properties of the voice source signal, which is usually estimated from the speech signal. However, most of the source estimation techniques depend heavily on the goodness of the model assumptions and are prone to noise. A popular alternative is to indirectly obtain the source information through the Electroglottographic (EGG) signal that measures the electrical admittance around the vocal folds using a dedicated hardware. In this paper, we address the problem of estimating the EGG signal directly from the speech signal, devoid of any hardware. Sampling from the intractable conditional distribution of the EGG signal given the speech signal is accomplished through optimization of an evidence lower bound. This is constructed via minimization of the KL-divergence between the true and the approximated posteriors of a latent variable learned using a deep neural auto-encoder that serves an informative prior which reconstructs the EGG signal. We demonstrate the efficacy of the method to generate EGG signal by conducting several experiments on datasets comprising multiple speakers, voice qualities, noise settings and speech pathologies. The proposed method is evaluated on many benchmark metrics and is found to agree with the gold standards while being better than the state-of-the-art algorithms on a few tasks such as epoch extraction.