 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
LPC Augment: An LPC-Based ASR Data Augmentation Algorithm for Low and Zero-Resource Children's Dialects
Feb 22, 2022
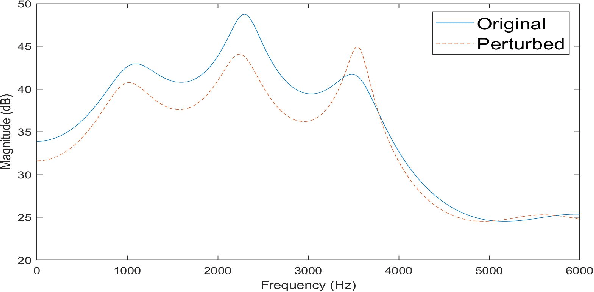
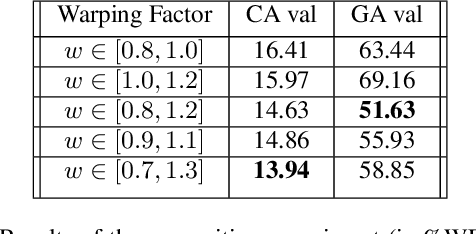
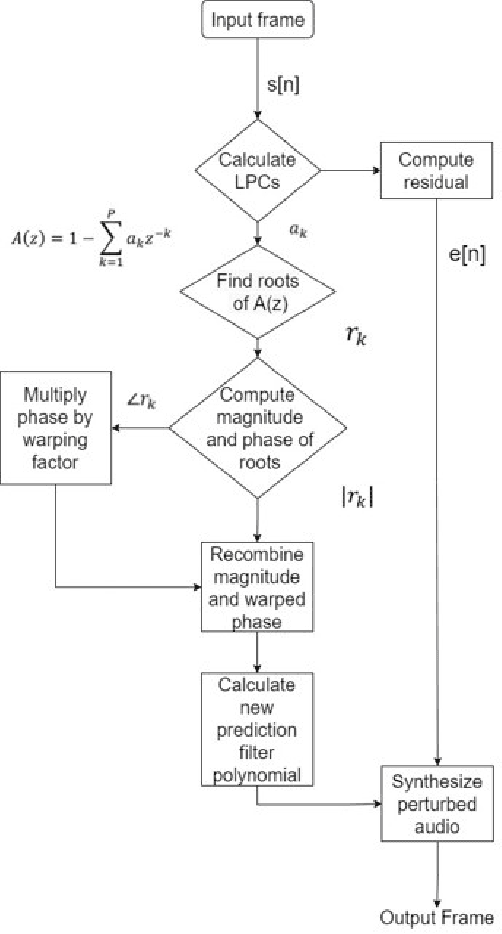
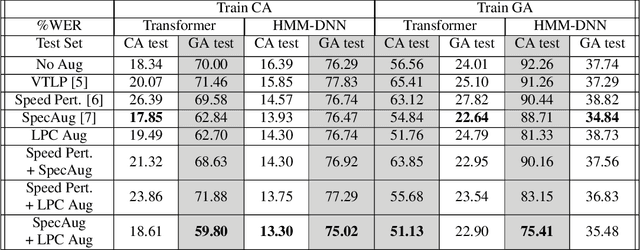
This paper proposes a novel linear prediction coding-based data aug-mentation method for children's low and zero resource dialect ASR. The data augmentation procedure consists of perturbing the formant peaks of the LPC spectrum during LPC analysis and reconstruction. The method is evaluated on two novel children's speech datasets with one containing California English from the Southern CaliforniaArea and the other containing a mix of Southern American English and African American English from the Atlanta, Georgia area. We test the proposed method in training both an HMM-DNN system and an end-to-end system to show model-robustness and demonstrate that the algorithm improves ASR performance, especially for zero resource dialect children's task, as compared to common data augmentation methods such as VTLP, Speed Perturbation, and SpecAugment.
* 5 pages, 2 figures
WLASL-LEX: a Dataset for Recognising Phonological Properties in American Sign Language
Mar 11, 2022
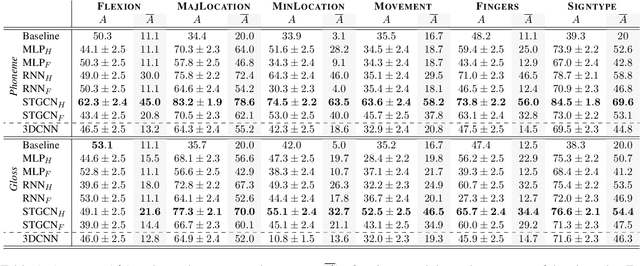

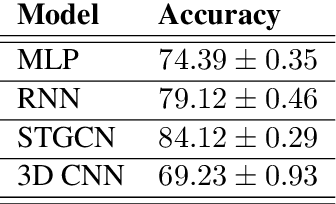
Signed Language Processing (SLP) concerns the automated processing of signed languages, the main means of communication of Deaf and hearing impaired individuals. SLP features many different tasks, ranging from sign recognition to translation and production of signed speech, but has been overlooked by the NLP community thus far. In this paper, we bring to attention the task of modelling the phonology of sign languages. We leverage existing resources to construct a large-scale dataset of American Sign Language signs annotated with six different phonological properties. We then conduct an extensive empirical study to investigate whether data-driven end-to-end and feature-based approaches can be optimised to automatically recognise these properties. We find that, despite the inherent challenges of the task, graph-based neural networks that operate over skeleton features extracted from raw videos are able to succeed at the task to a varying degree. Most importantly, we show that this performance pertains even on signs unobserved during training.
Deep Text-to-Speech System with Seq2Seq Model
Mar 11, 2019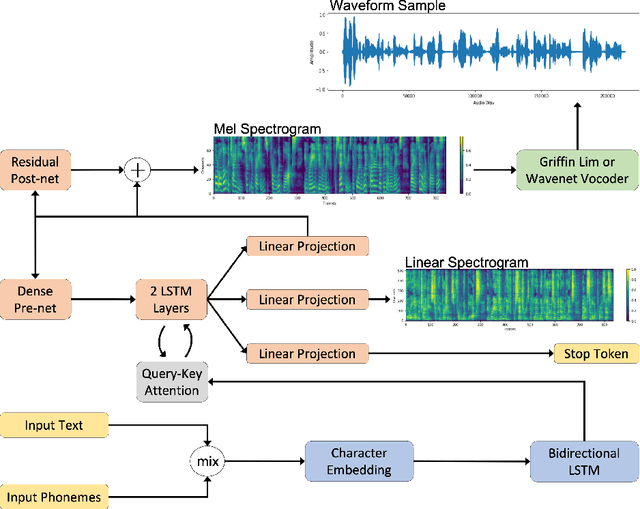
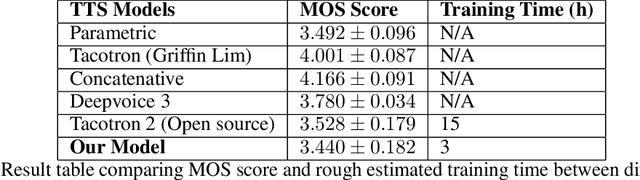
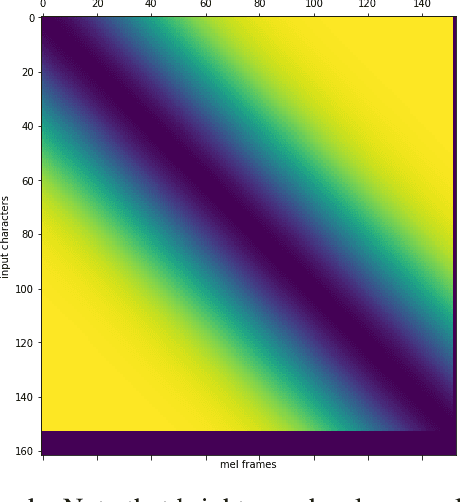
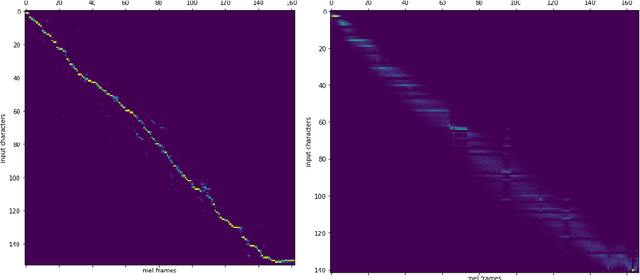
Recent trends in neural network based text-to-speech/speech synthesis pipelines have employed recurrent Seq2seq architectures that can synthesize realistic sounding speech directly from text characters. These systems however have complex architectures and takes a substantial amount of time to train. We introduce several modifications to these Seq2seq architectures that allow for faster training time, and also allows us to reduce the complexity of the model architecture at the same time. We show that our proposed model can achieve attention alignment much faster than previous architectures and that good audio quality can be achieved with a model that's much smaller in size. Sample audio available at https://soundcloud.com/gary-wang-23/sets/tts-samples-for-cmpt-419.
Audio visual character profiles for detecting background characters in entertainment media
Mar 21, 2022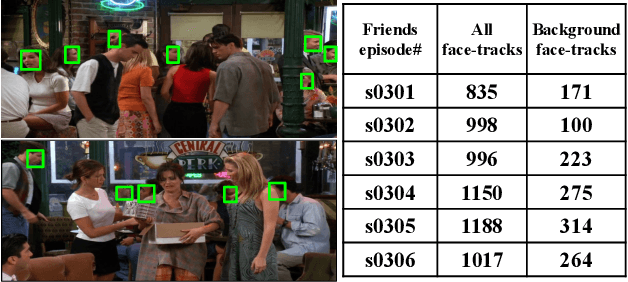
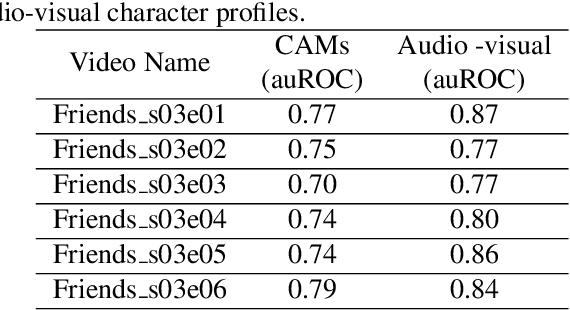
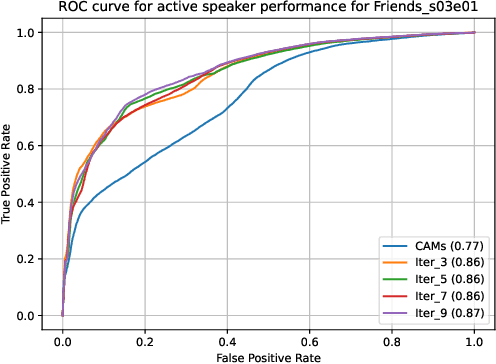
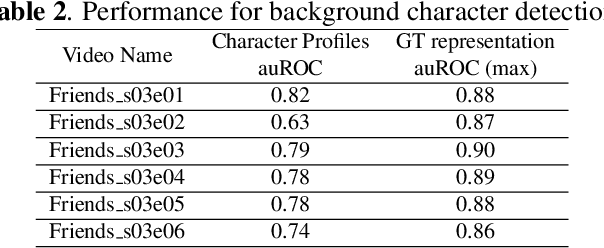
An essential goal of computational media intelligence is to support understanding how media stories -- be it news, commercial or entertainment media -- represent and reflect society and these portrayals are perceived. People are a central element of media stories. This paper focuses on understanding the representation and depiction of background characters in media depictions, primarily movies and TV shows. We define the background characters as those who do not participate vocally in any scene throughout the movie and address the problem of localizing background characters in videos. We use an active speaker localization system to extract high-confidence face-speech associations and generate audio-visual profiles for talking characters in a movie by automatically clustering them. Using a face verification system, we then prune all the face-tracks which match any of the generated character profiles and obtain the background character face-tracks. We curate a background character dataset which provides annotations for background character for a set of TV shows, and use it to evaluate the performance of the background character detection framework.
PHO-LID: A Unified Model Incorporating Acoustic-Phonetic and Phonotactic Information for Language Identification
Mar 31, 2022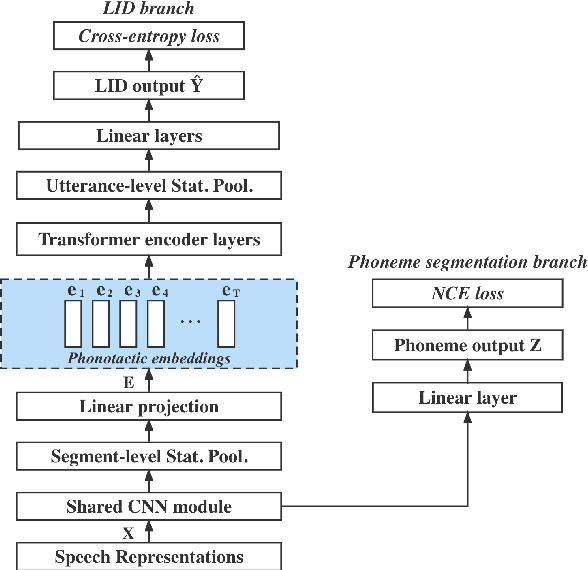
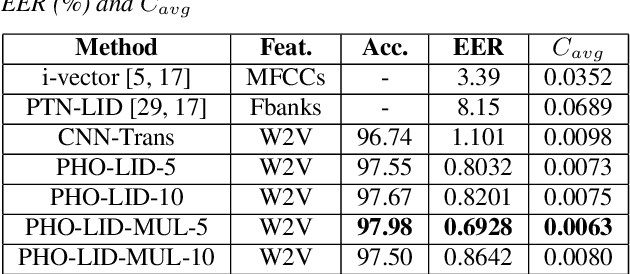
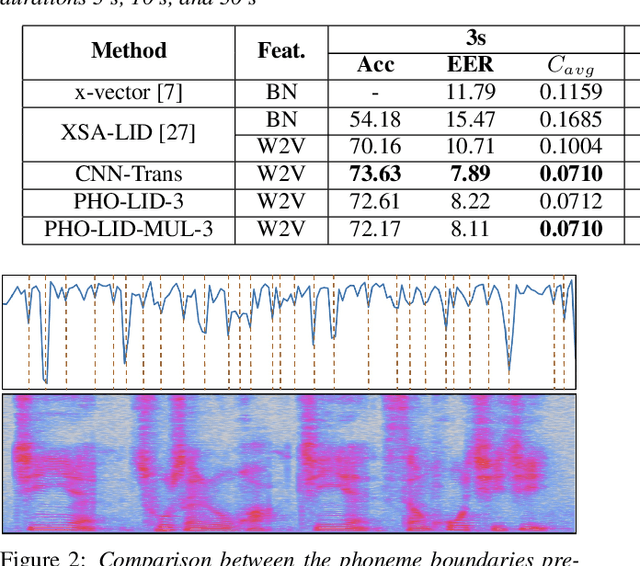
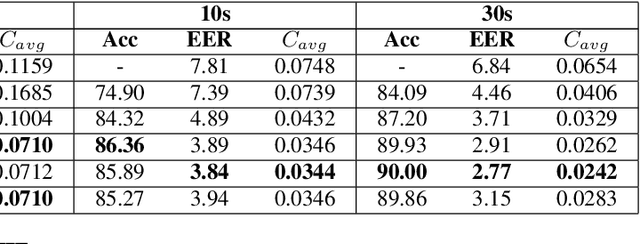
We propose a novel model to hierarchically incorporate phoneme and phonotactic information for language identification (LID) without requiring phoneme annotations for training. In this model, named PHO-LID, a self-supervised phoneme segmentation task and a LID task share a convolutional neural network (CNN) module, which encodes both language identity and sequential phonemic information in the input speech to generate an intermediate sequence of phonotactic embeddings. These embeddings are then fed into transformer encoder layers for utterance-level LID. We call this architecture CNN-Trans. We evaluate it on AP17-OLR data and the MLS14 set of NIST LRE 2017, and show that the PHO-LID model with multi-task optimization exhibits the highest LID performance among all models, achieving over 40% relative improvement in terms of average cost on AP17-OLR data compared to a CNN-Trans model optimized only for LID. The visualized confusion matrices imply that our proposed method achieves higher performance on languages of the same cluster in NIST LRE 2017 data than the CNN-Trans model. A comparison between predicted phoneme boundaries and corresponding audio spectrograms illustrates the leveraging of phoneme information for LID.
Towards an Efficient Voice Identification Using Wav2Vec2.0 and HuBERT Based on the Quran Reciters Dataset
Nov 11, 2021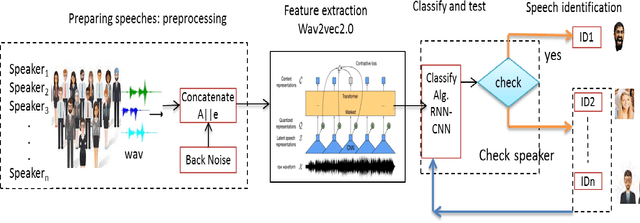
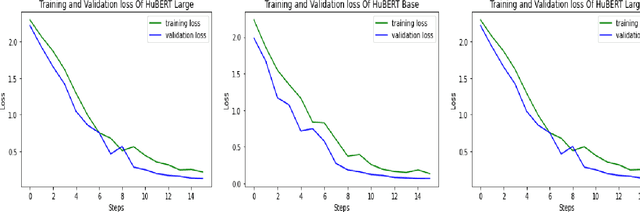
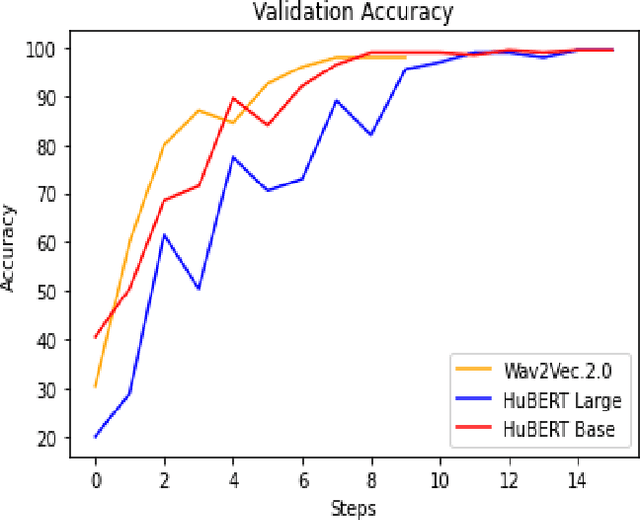
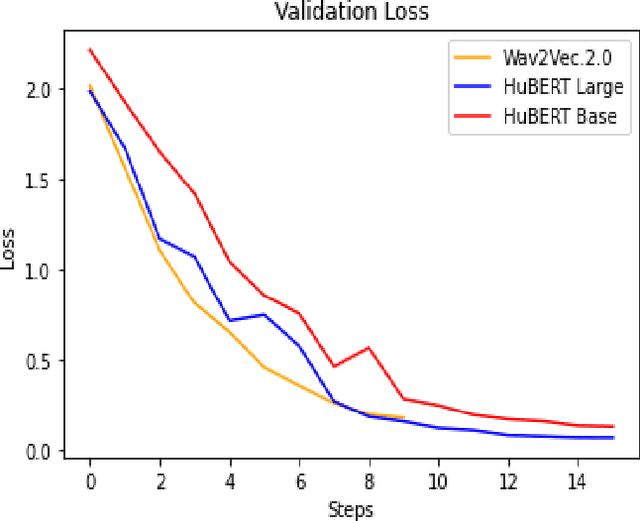
Current authentication and trusted systems depend on classical and biometric methods to recognize or authorize users. Such methods include audio speech recognitions, eye, and finger signatures. Recent tools utilize deep learning and transformers to achieve better results. In this paper, we develop a deep learning constructed model for Arabic speakers identification by using Wav2Vec2.0 and HuBERT audio representation learning tools. The end-to-end Wav2Vec2.0 paradigm acquires contextualized speech representations learnings by randomly masking a set of feature vectors, and then applies a transformer neural network. We employ an MLP classifier that is able to differentiate between invariant labeled classes. We show several experimental results that safeguard the high accuracy of the proposed model. The experiments ensure that an arbitrary wave signal for a certain speaker can be identified with 98% and 97.1% accuracies in the cases of Wav2Vec2.0 and HuBERT, respectively.
Automatic Identification and Classification of Bragging in Social Media
Mar 11, 2022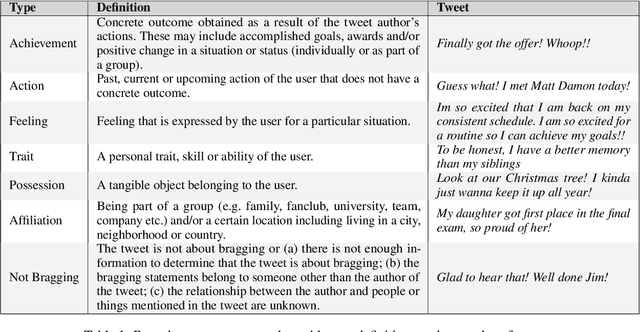

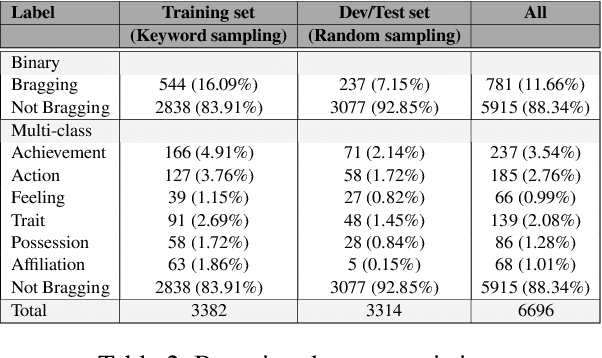

Bragging is a speech act employed with the goal of constructing a favorable self-image through positive statements about oneself. It is widespread in daily communication and especially popular in social media, where users aim to build a positive image of their persona directly or indirectly. In this paper, we present the first large scale study of bragging in computational linguistics, building on previous research in linguistics and pragmatics. To facilitate this, we introduce a new publicly available data set of tweets annotated for bragging and their types. We empirically evaluate different transformer-based models injected with linguistic information in (a) binary bragging classification, i.e., if tweets contain bragging statements or not; and (b) multi-class bragging type prediction including not bragging. Our results show that our models can predict bragging with macro F1 up to 72.42 and 35.95 in the binary and multi-class classification tasks respectively. Finally, we present an extensive linguistic and error analysis of bragging prediction to guide future research on this topic.
Towards a Competitive End-to-End Speech Recognition for CHiME-6 Dinner Party Transcription
Apr 22, 2020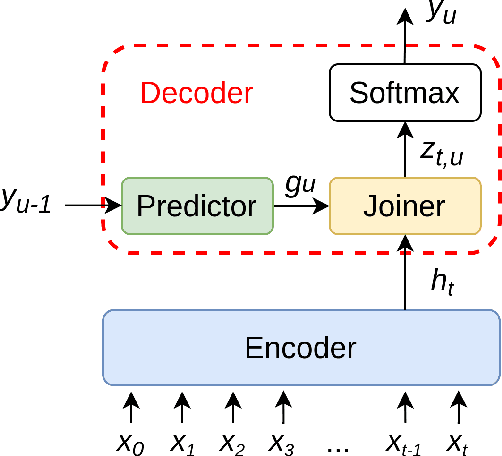

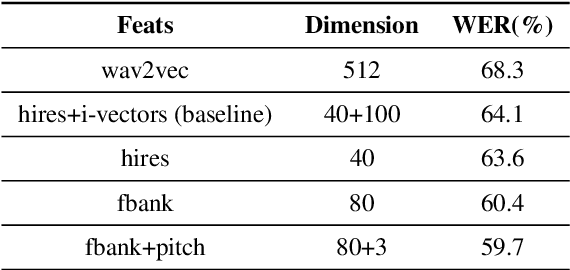

While end-to-end ASR systems have proven competitive with the conventional hybrid approach, they are prone to accuracy degradation when it comes to noisy and low-resource conditions. In this paper, we argue that, even in such difficult cases, some end-to-end approaches show performance close to the hybrid baseline. To demonstrate this, we use the CHiME-6 Challenge data as an example of challenging environments and noisy conditions of everyday speech. We experimentally compare and analyze CTC-Attention versus RNN-Transducer approaches along with RNN versus Transformer architectures. We also provide a comparison of acoustic features and speech enhancements. Besides, we evaluate the effectiveness of neural network language models for hypothesis re-scoring in low-resource conditions. Our best end-to-end model based on RNN-Transducer, together with improved beam search, reaches quality by only 3.8% WER abs. worse than the LF-MMI TDNN-F CHiME-6 Challenge baseline. With the Guided Source Separation based speech enhancement, this approach outperforms the hybrid baseline system by 2.7% WER abs. and the end-to-end system best known before by 25.7% WER abs.
ADEPT: A Dataset for Evaluating Prosody Transfer
Jun 15, 2021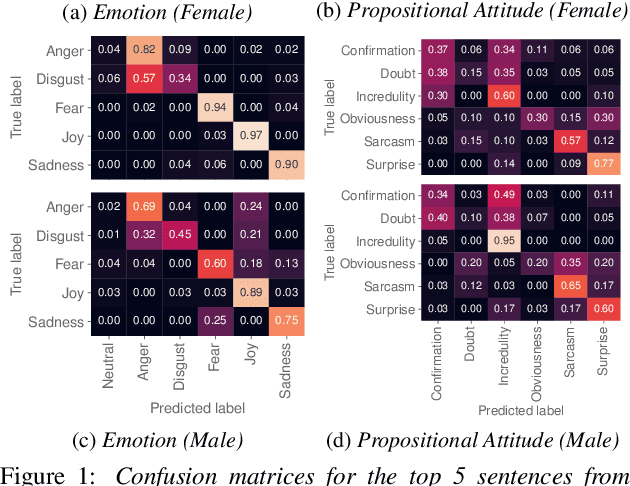
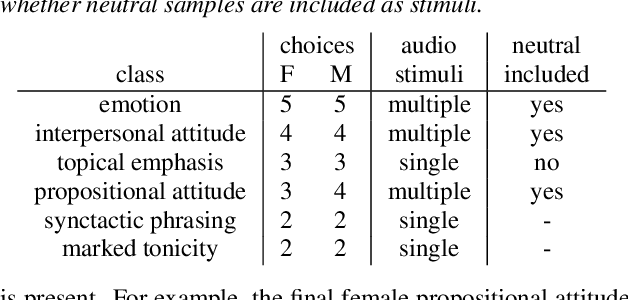
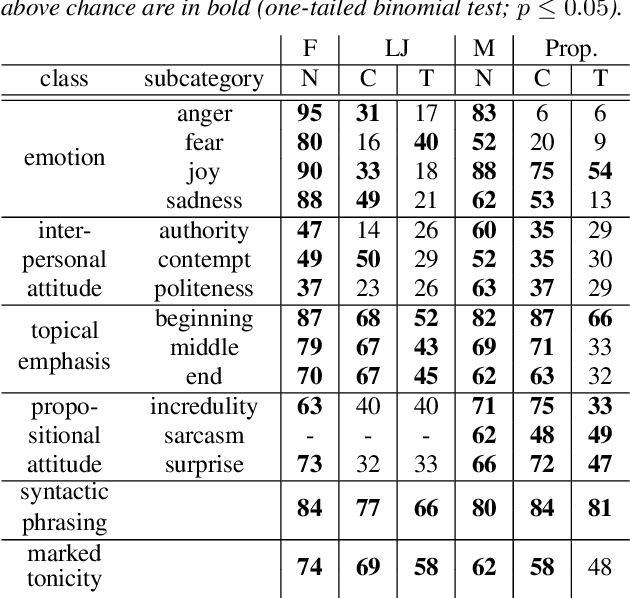
Text-to-speech is now able to achieve near-human naturalness and research focus has shifted to increasing expressivity. One popular method is to transfer the prosody from a reference speech sample. There have been considerable advances in using prosody transfer to generate more expressive speech, but the field lacks a clear definition of what successful prosody transfer means and a method for measuring it. We introduce a dataset of prosodically-varied reference natural speech samples for evaluating prosody transfer. The samples include global variations reflecting emotion and interpersonal attitude, and local variations reflecting topical emphasis, propositional attitude, syntactic phrasing and marked tonicity. The corpus only includes prosodic variations that listeners are able to distinguish with reasonable accuracy, and we report these figures as a benchmark against which text-to-speech prosody transfer can be compared. We conclude the paper with a demonstration of our proposed evaluation methodology, using the corpus to evaluate two text-to-speech models that perform prosody transfer.
L3DAS22 Challenge: Learning 3D Audio Sources in a Real Office Environment
Feb 21, 2022
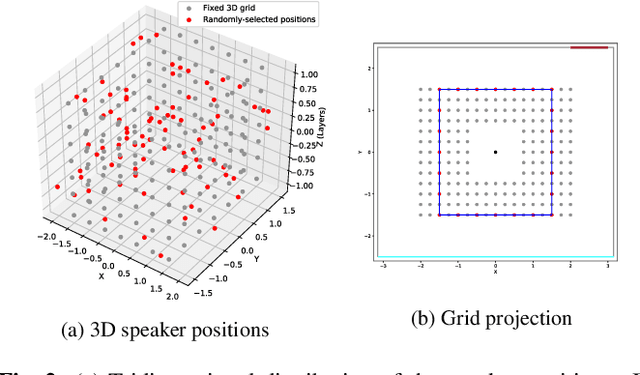
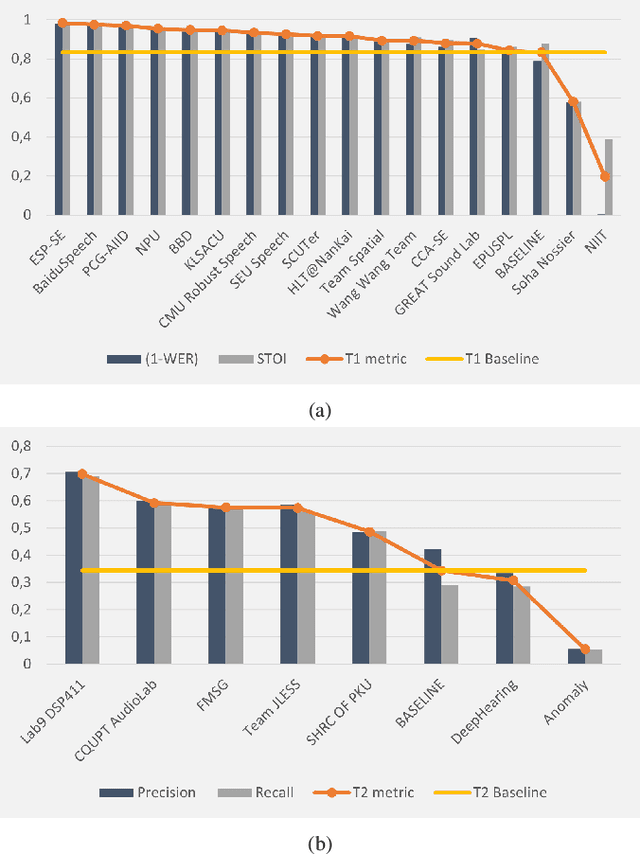
The L3DAS22 Challenge is aimed at encouraging the development of machine learning strategies for 3D speech enhancement and 3D sound localization and detection in office-like environments. This challenge improves and extends the tasks of the L3DAS21 edition. We generated a new dataset, which maintains the same general characteristics of L3DAS21 datasets, but with an extended number of data points and adding constrains that improve the baseline model's efficiency and overcome the major difficulties encountered by the participants of the previous challenge. We updated the baseline model of Task 1, using the architecture that ranked first in the previous challenge edition. We wrote a new supporting API, improving its clarity and ease-of-use. In the end, we present and discuss the results submitted by all participants. L3DAS22 Challenge website: www.l3das.com/icassp2022.