 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Semantic query-by-example speech search using visual grounding
Apr 15, 2019
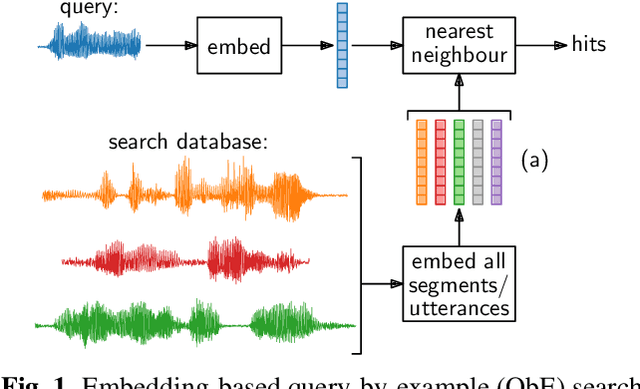
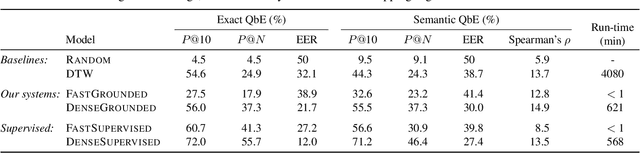
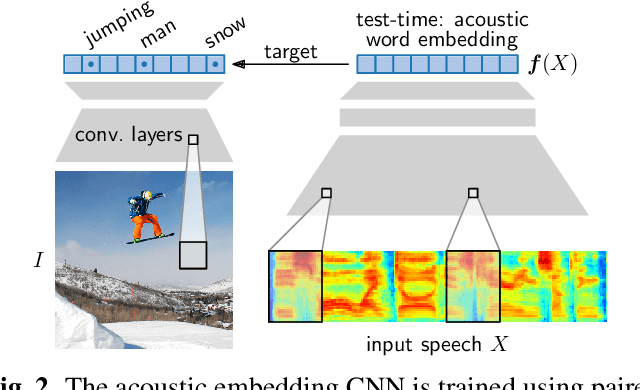
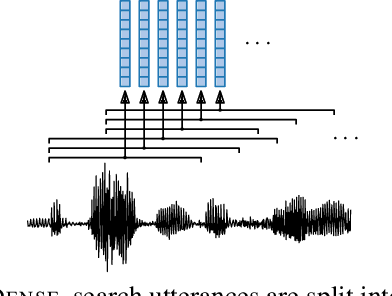
A number of recent studies have started to investigate how speech systems can be trained on untranscribed speech by leveraging accompanying images at training time. Examples of tasks include keyword prediction and within- and across-mode retrieval. Here we consider how such models can be used for query-by-example (QbE) search, the task of retrieving utterances relevant to a given spoken query. We are particularly interested in semantic QbE, where the task is not only to retrieve utterances containing exact instances of the query, but also utterances whose meaning is relevant to the query. We follow a segmental QbE approach where variable-duration speech segments (queries, search utterances) are mapped to fixed-dimensional embedding vectors. We show that a QbE system using an embedding function trained on visually grounded speech data outperforms a purely acoustic QbE system in terms of both exact and semantic retrieval performance.
Improving Generalizability in Implicitly Abusive Language Detection with Concept Activation Vectors
Apr 05, 2022
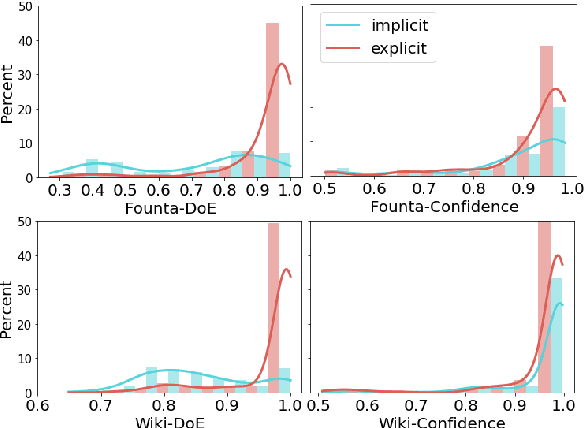
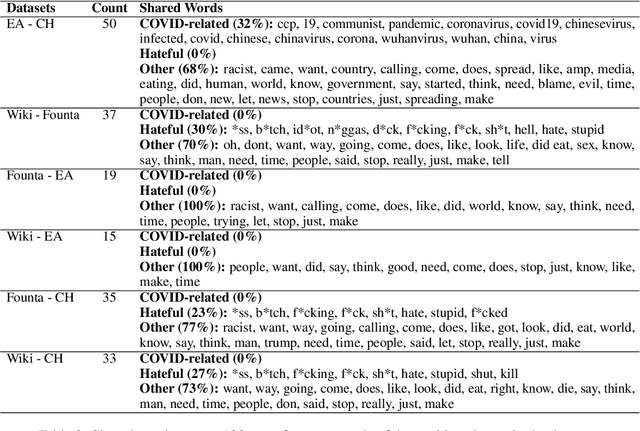
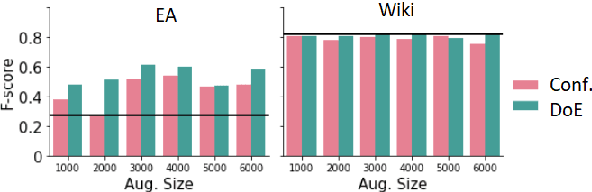
Robustness of machine learning models on ever-changing real-world data is critical, especially for applications affecting human well-being such as content moderation. New kinds of abusive language continually emerge in online discussions in response to current events (e.g., COVID-19), and the deployed abuse detection systems should be updated regularly to remain accurate. In this paper, we show that general abusive language classifiers tend to be fairly reliable in detecting out-of-domain explicitly abusive utterances but fail to detect new types of more subtle, implicit abuse. Next, we propose an interpretability technique, based on the Testing Concept Activation Vector (TCAV) method from computer vision, to quantify the sensitivity of a trained model to the human-defined concepts of explicit and implicit abusive language, and use that to explain the generalizability of the model on new data, in this case, COVID-related anti-Asian hate speech. Extending this technique, we introduce a novel metric, Degree of Explicitness, for a single instance and show that the new metric is beneficial in suggesting out-of-domain unlabeled examples to effectively enrich the training data with informative, implicitly abusive texts.
FastCorrect: Fast Error Correction with Edit Alignment for Automatic Speech Recognition
May 09, 2021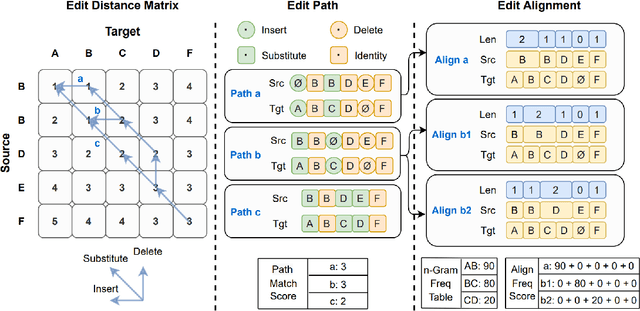
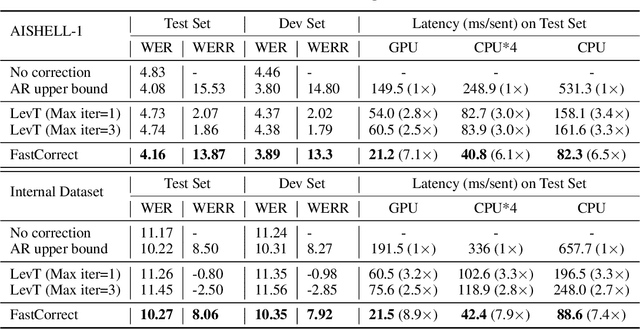
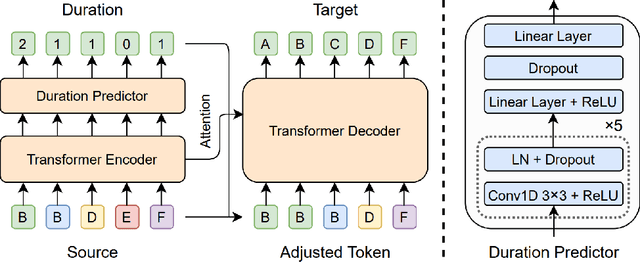
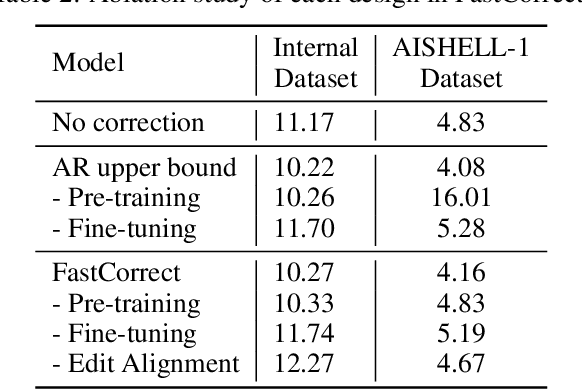
Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER) than original ASR outputs. Previous works usually use a sequence-to-sequence model to correct an ASR output sentence autoregressively, which causes large latency and cannot be deployed in online ASR services. A straightforward solution to reduce latency, inspired by non-autoregressive (NAR) neural machine translation, is to use an NAR sequence generation model for ASR error correction, which, however, comes at the cost of significantly increased ASR error rate. In this paper, observing distinctive error patterns and correction operations (i.e., insertion, deletion, and substitution) in ASR, we propose FastCorrect, a novel NAR error correction model based on edit alignment. In training, FastCorrect aligns each source token from an ASR output sentence to the target tokens from the corresponding ground-truth sentence based on the edit distance between the source and target sentences, and extracts the number of target tokens corresponding to each source token during edition/correction, which is then used to train a length predictor and to adjust the source tokens to match the length of the target sentence for parallel generation. In inference, the token number predicted by the length predictor is used to adjust the source tokens for target sequence generation. Experiments on the public AISHELL-1 dataset and an internal industrial-scale ASR dataset show the effectiveness of FastCorrect for ASR error correction: 1) it speeds up the inference by 6-9 times and maintains the accuracy (8-14% WER reduction) compared with the autoregressive correction model; and 2) it outperforms the accuracy of popular NAR models adopted in neural machine translation by a large margin.
Hate Speech Detection and Racial Bias Mitigation in Social Media based on BERT model
Aug 28, 2020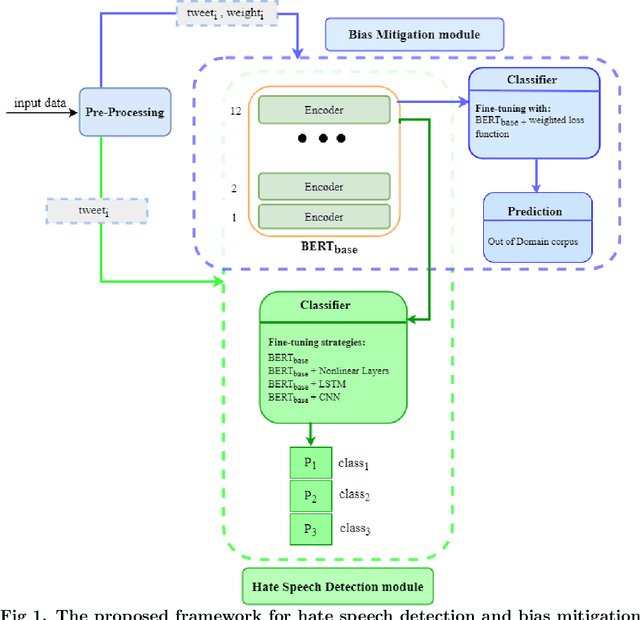
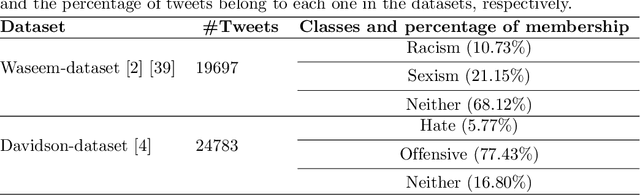
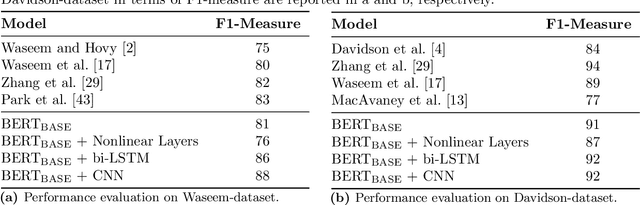
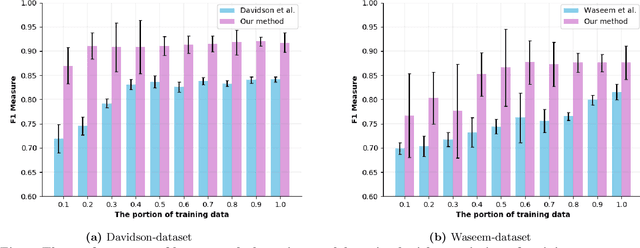
Disparate biases associated with datasets and trained classifiers in hateful and abusive content identification tasks have raised many concerns recently. Although the problem of biased datasets on abusive language detection has been addressed more frequently, biases arising from trained classifiers have not yet been a matter of concern. Here, we first introduce a transfer learning approach for hate speech detection based on an existing pre-trained language model called BERT and evaluate the proposed model on two publicly available datasets annotated for racism, sexism, hate or offensive content on Twitter. Next, we introduce a bias alleviation mechanism in hate speech detection task to mitigate the effect of bias in training set during the fine-tuning of our pre-trained BERT-based model. Toward that end, we use an existing regularization method to reweight input samples, thereby decreasing the effects of high correlated training set' s n-grams with class labels, and then fine-tune our pre-trained BERT-based model with the new re-weighted samples. To evaluate our bias alleviation mechanism, we employ a cross-domain approach in which we use the trained classifiers on the aforementioned datasets to predict the labels of two new datasets from Twitter, AAE-aligned and White-aligned groups, which indicate tweets written in African-American English (AAE) and Standard American English (SAE) respectively. The results show the existence of systematic racial bias in trained classifiers as they tend to assign tweets written in AAE from AAE-aligned group to negative classes such as racism, sexism, hate, and offensive more often than tweets written in SAE from White-aligned. However, the racial bias in our classifiers reduces significantly after our bias alleviation mechanism is incorporated. This work could institute the first step towards debiasing hate speech and abusive language detection systems.
CopyPaste: An Augmentation Method for Speech Emotion Recognition
Oct 27, 2020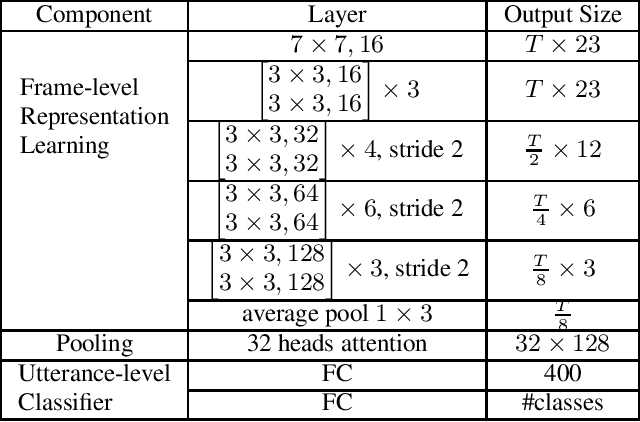
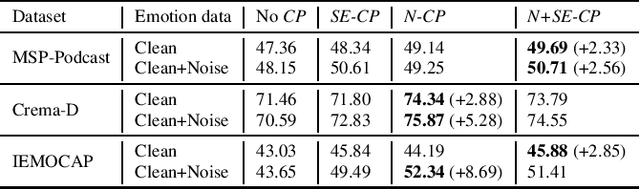
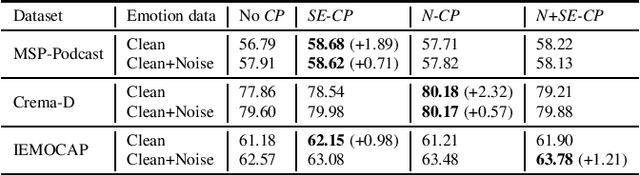
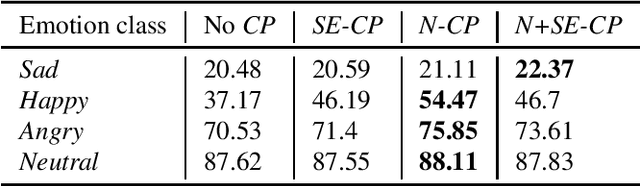
Data augmentation is a widely used strategy for training robust machine learning models. It partially alleviates the problem of limited data for tasks like speech emotion recognition (SER), where collecting data is expensive and challenging. This study proposes CopyPaste, a perceptually motivated novel augmentation procedure for SER. Assuming that the presence of emotions other than neutral dictates a speaker's overall perceived emotion in a recording, concatenation of an emotional (emotion E) and a neutral utterance can still be labeled with emotion E. We hypothesize that SER performance can be improved using these concatenated utterances in model training. To verify this, three CopyPaste schemes are tested on two deep learning models: one trained independently and another using transfer learning from an x-vector model, a speaker recognition model. We observed that all three CopyPaste schemes improve SER performance on all the three datasets considered: MSP-Podcast, Crema-D, and IEMOCAP. Additionally, CopyPaste performs better than noise augmentation and, using them together improves the SER performance further. Our experiments on noisy test sets suggested that CopyPaste is effective even in noisy test conditions.
Improved Language Identification Through Cross-Lingual Self-Supervised Learning
Jul 24, 2021
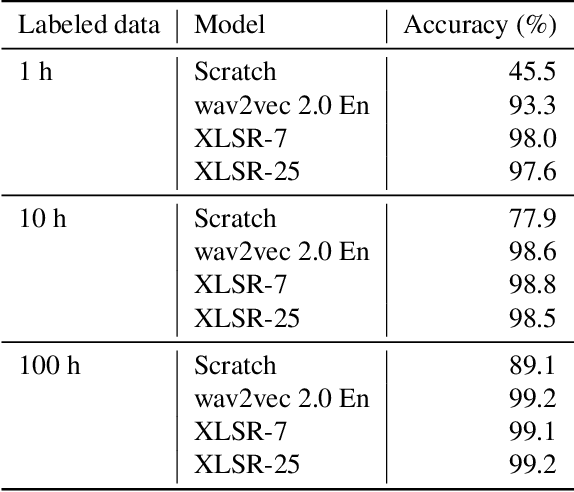
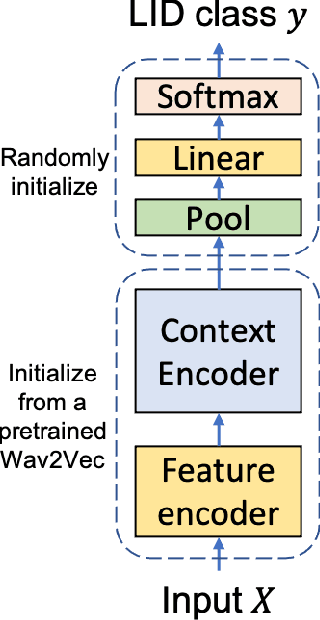
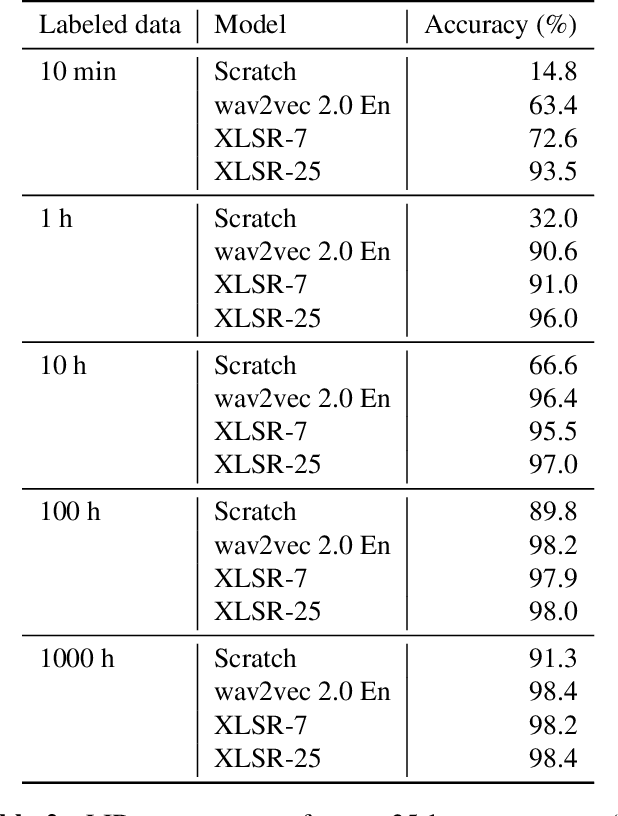
Language identification greatly impacts the success of downstream tasks such as automatic speech recognition. Recently, self-supervised speech representations learned by wav2vec 2.0 have been shown to be very effective for a range of speech tasks. We extend previous self-supervised work on language identification by experimenting with pre-trained models which were learned on real-world unconstrained speech in multiple languages and not just on English. We show that models pre-trained on many languages perform better and enable language identification systems that require very little labeled data to perform well. Results on a 25 languages setup show that with only 10 minutes of labeled data per language, a cross-lingually pre-trained model can achieve over 93% accuracy.
Sandglasset: A Light Multi-Granularity Self-attentive Network For Time-Domain Speech Separation
Mar 08, 2021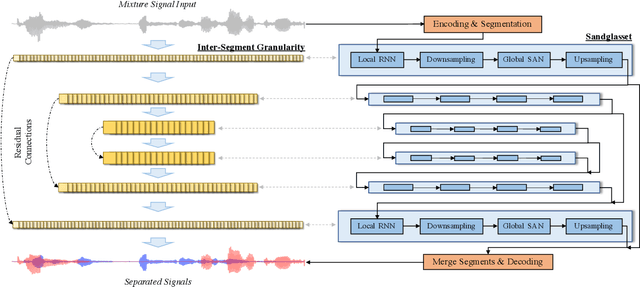
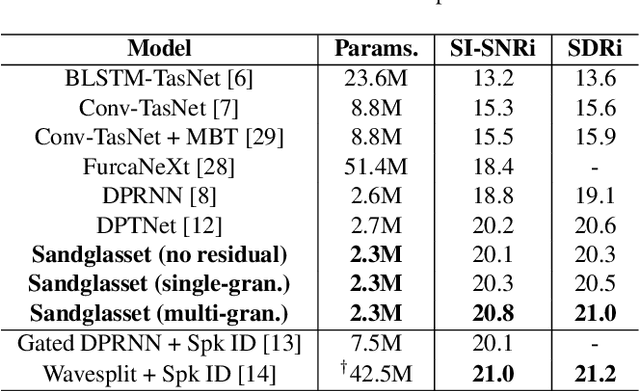
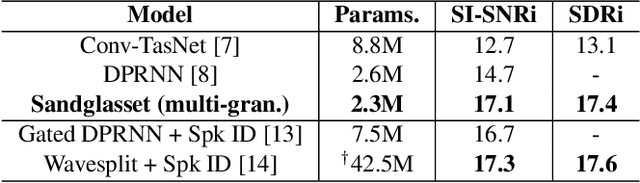
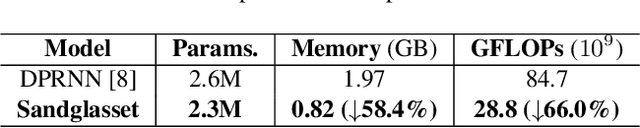
One of the leading single-channel speech separation (SS) models is based on a TasNet with a dual-path segmentation technique, where the size of each segment remains unchanged throughout all layers. In contrast, our key finding is that multi-granularity features are essential for enhancing contextual modeling and computational efficiency. We introduce a self-attentive network with a novel sandglass-shape, namely Sandglasset, which advances the state-of-the-art (SOTA) SS performance at significantly smaller model size and computational cost. Forward along each block inside Sandglasset, the temporal granularity of the features gradually becomes coarser until reaching half of the network blocks, and then successively turns finer towards the raw signal level. We also unfold that residual connections between features with the same granularity are critical for preserving information after passing through the bottleneck layer. Experiments show our Sandglasset with only 2.3M parameters has achieved the best results on two benchmark SS datasets -- WSJ0-2mix and WSJ0-3mix, where the SI-SNRi scores have been improved by absolute 0.8 dB and 2.4 dB, respectively, comparing to the prior SOTA results.
Contextualized Translation of Automatically Segmented Speech
Aug 05, 2020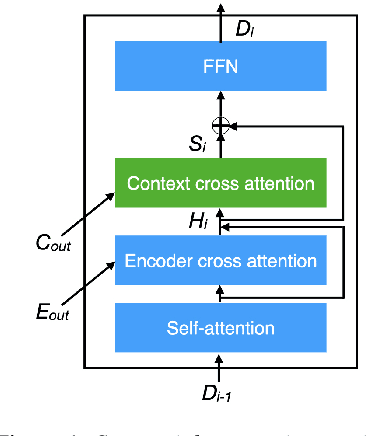
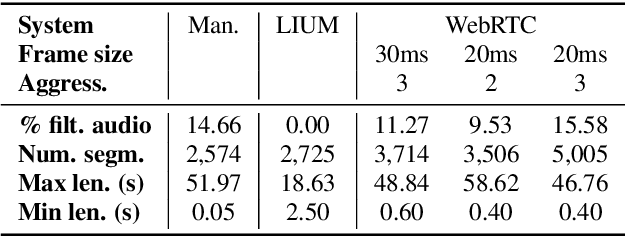
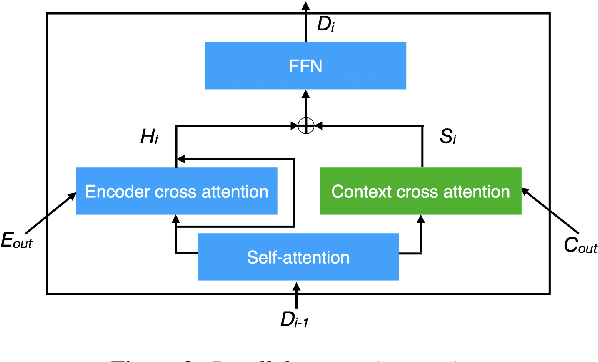
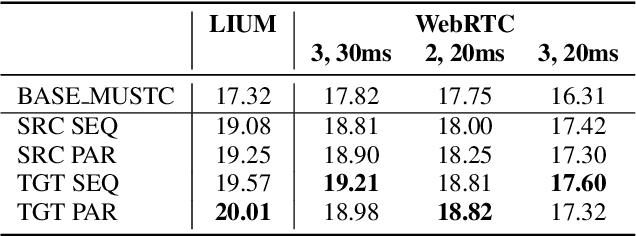
Direct speech-to-text translation (ST) models are usually trained on corpora segmented at sentence level, but at inference time they are commonly fed with audio split by a voice activity detector (VAD). Since VAD segmentation is not syntax-informed, the resulting segments do not necessarily correspond to well-formed sentences uttered by the speaker but, most likely, to fragments of one or more sentences. This segmentation mismatch degrades considerably the quality of ST models' output. So far, researchers have focused on improving audio segmentation towards producing sentence-like splits. In this paper, instead, we address the issue in the model, making it more robust to a different, potentially sub-optimal segmentation. To this aim, we train our models on randomly segmented data and compare two approaches: fine-tuning and adding the previous segment as context. We show that our context-aware solution is more robust to VAD-segmented input, outperforming a strong base model and the fine-tuning on different VAD segmentations of an English-German test set by up to 4.25 BLEU points.
Video-Driven Speech Reconstruction using Generative Adversarial Networks
Jun 14, 2019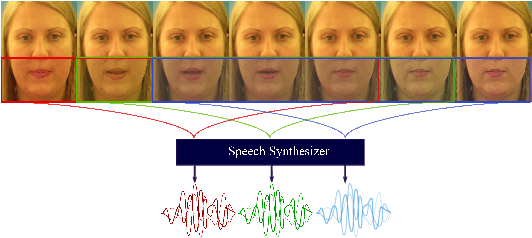

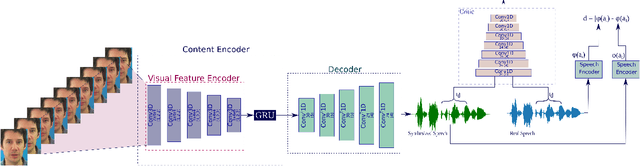
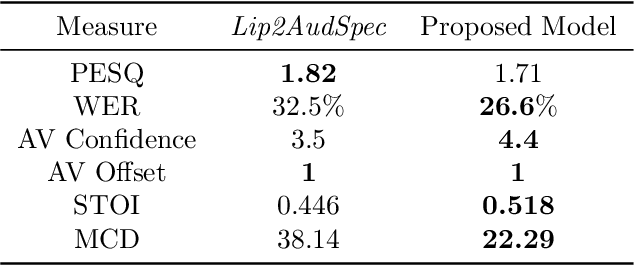
Speech is a means of communication which relies on both audio and visual information. The absence of one modality can often lead to confusion or misinterpretation of information. In this paper we present an end-to-end temporal model capable of directly synthesising audio from silent video, without needing to transform to-and-from intermediate features. Our proposed approach, based on GANs is capable of producing natural sounding, intelligible speech which is synchronised with the video. The performance of our model is evaluated on the GRID dataset for both speaker dependent and speaker independent scenarios. To the best of our knowledge this is the first method that maps video directly to raw audio and the first to produce intelligible speech when tested on previously unseen speakers. We evaluate the synthesised audio not only based on the sound quality but also on the accuracy of the spoken words.
Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
Oct 31, 2019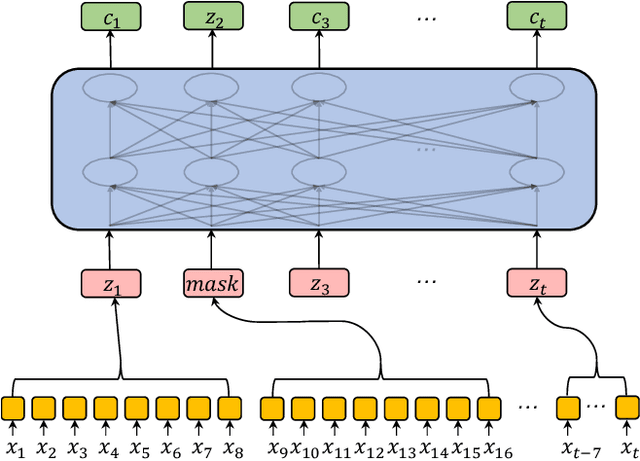
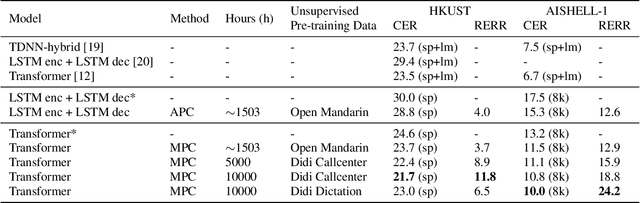
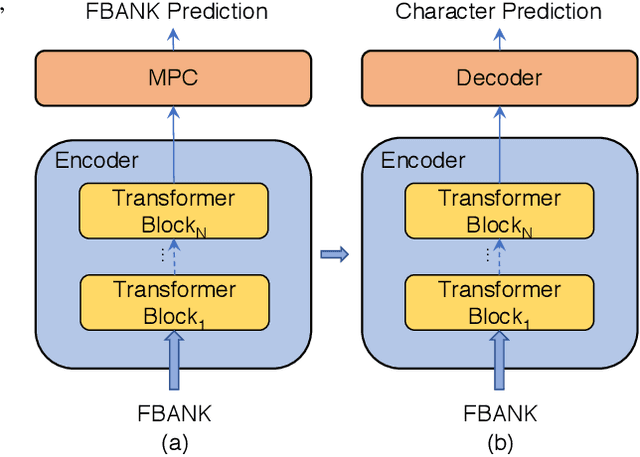
Speech recognition technologies are gaining enormous popularity in various industrial applications. However, building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, an unsupervised pre-training method called Masked Predictive Coding is proposed, which can be applied for unsupervised pre-training with Transformer based model. Experiments on HKUST show that using the same training data, we can achieve CER 23.3%, exceeding the best end-to-end model by over 0.2% absolute CER. With more pre-training data, we can further reduce the CER to 21.0%, or a 11.8% relative CER reduction over baseline.