 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Fusion of Self-supervised Learned Models for MOS Prediction
Apr 11, 2022
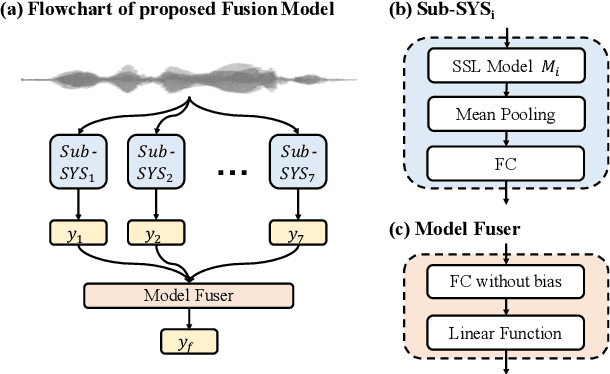
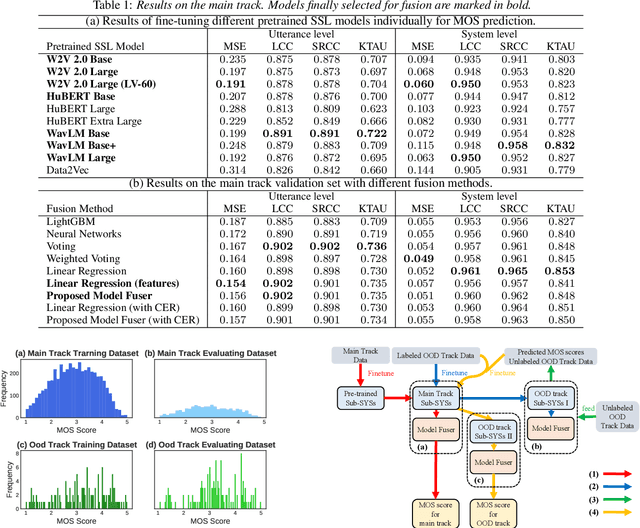
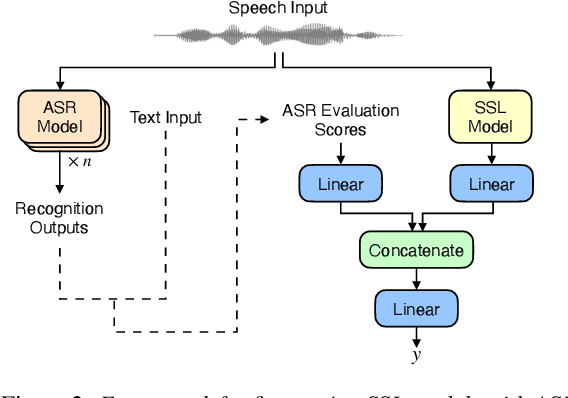
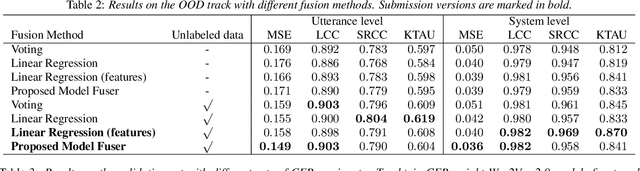
We participated in the mean opinion score (MOS) prediction challenge, 2022. This challenge aims to predict MOS scores of synthetic speech on two tracks, the main track and a more challenging sub-track: out-of-domain (OOD). To improve the accuracy of the predicted scores, we have explored several model fusion-related strategies and proposed a fused framework in which seven pretrained self-supervised learned (SSL) models have been engaged. These pretrained SSL models are derived from three ASR frameworks, including Wav2Vec, Hubert, and WavLM. For the OOD track, we followed the 7 SSL models selected on the main track and adopted a semi-supervised learning method to exploit the unlabeled data. According to the official analysis results, our system has achieved 1st rank in 6 out of 16 metrics and is one of the top 3 systems for 13 out of 16 metrics. Specifically, we have achieved the highest LCC, SRCC, and KTAU scores at the system level on main track, as well as the best performance on the LCC, SRCC, and KTAU evaluation metrics at the utterance level on OOD track. Compared with the basic SSL models, the prediction accuracy of the fused system has been largely improved, especially on OOD sub-track.
Audio-Based Deep Learning Frameworks for Detecting COVID-19
Mar 02, 2022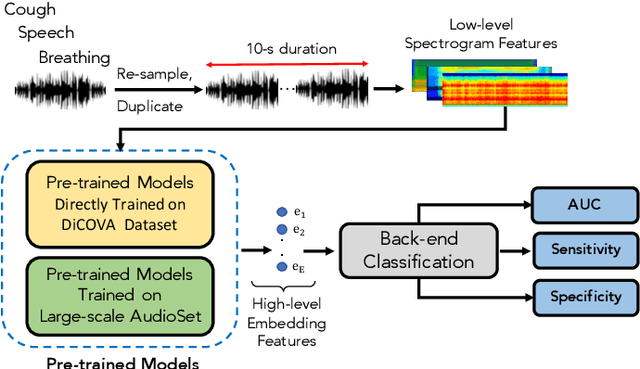

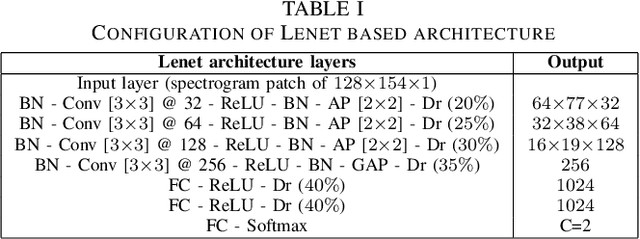
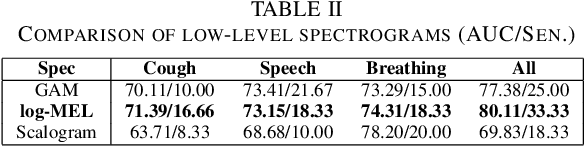
This paper evaluates a wide range of audio-based deep learning frameworks applied to the breathing, cough, and speech sounds for detecting COVID-19. In general, the audio recording inputs are transformed into low-level spectrogram features, then they are fed into pre-trained deep learning models to extract high-level embedding features. Next, the dimension of these high-level embedding features are reduced before finetuning using Light Gradient Boosting Machine (LightGBM) as a back-end classification. Our experiments on the Second DiCOVA Challenge achieved the highest Area Under the Curve (AUC), F1 score, sensitivity score, and specificity score of 89.03%, 64.41%, 63.33%, and 95.13%, respectively. Based on these scores, our method outperforms the state-of-the-art systems, and improves the challenge baseline by 4.33%, 6.00% and 8.33% in terms of AUC, F1 score and sensitivity score, respectively.
SVSNet: An End-to-end Speaker Voice Similarity Assessment Model
Jul 20, 2021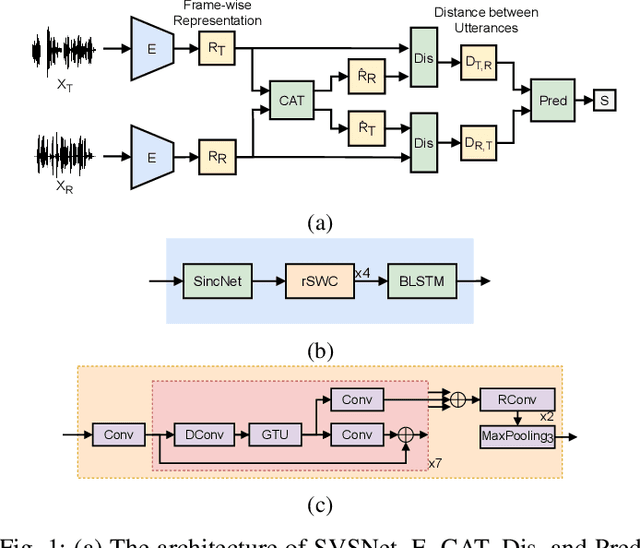
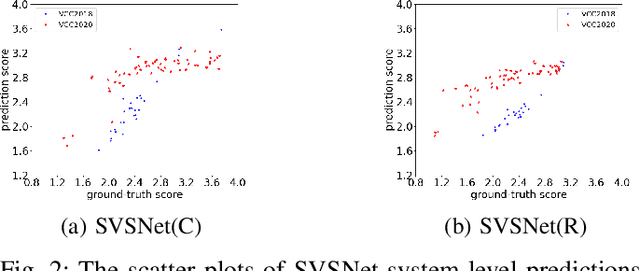
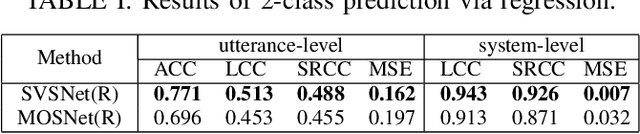
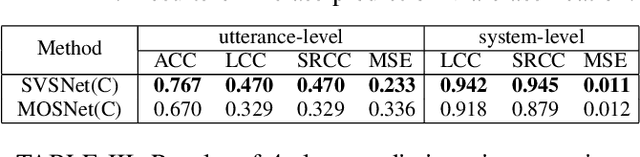
Neural evaluation metrics derived for numerous speech generation tasks have recently attracted great attention. In this paper, we propose SVSNet, the first end-to-end neural network model to assess the speaker voice similarity between natural speech and synthesized speech. Unlike most neural evaluation metrics that use hand-crafted features, SVSNet directly takes the raw waveform as input to more completely utilize speech information for prediction. SVSNet consists of encoder, co-attention, distance calculation, and prediction modules and is trained in an end-to-end manner. The experimental results on the Voice Conversion Challenge 2018 and 2020 (VCC2018 and VCC2020) datasets show that SVSNet notably outperforms well-known baseline systems in the assessment of speaker similarity at the utterance and system levels.
Speech recognition for medical conversations
Jun 20, 2018
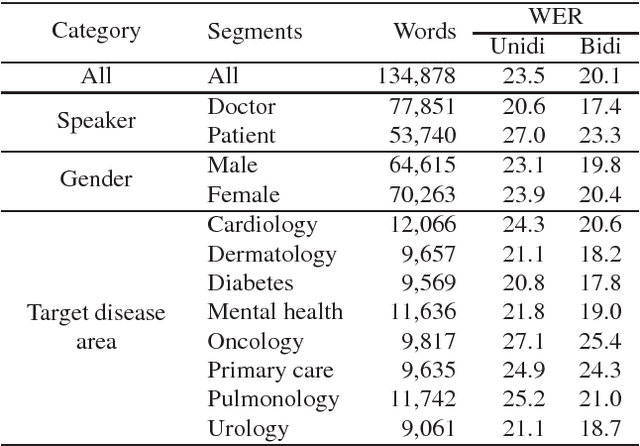
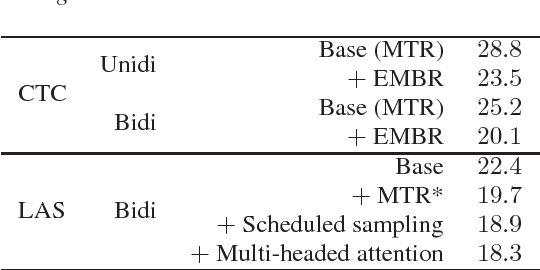
In this work we explored building automatic speech recognition models for transcribing doctor patient conversation. We collected a large scale dataset of clinical conversations ($14,000$ hr), designed the task to represent the real word scenario, and explored several alignment approaches to iteratively improve data quality. We explored both CTC and LAS systems for building speech recognition models. The LAS was more resilient to noisy data and CTC required more data clean up. A detailed analysis is provided for understanding the performance for clinical tasks. Our analysis showed the speech recognition models performed well on important medical utterances, while errors occurred in causal conversations. Overall we believe the resulting models can provide reasonable quality in practice.
Speech based Depression Severity Level Classification Using a Multi-Stage Dilated CNN-LSTM Model
Apr 09, 2021


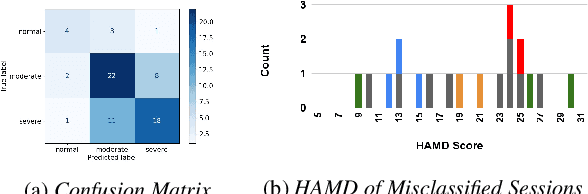
Speech based depression classification has gained immense popularity over the recent years. However, most of the classification studies have focused on binary classification to distinguish depressed subjects from non-depressed subjects. In this paper, we formulate the depression classification task as a severity level classification problem to provide more granularity to the classification outcomes. We use articulatory coordination features (ACFs) developed to capture the changes of neuromotor coordination that happens as a result of psychomotor slowing, a necessary feature of Major Depressive Disorder. The ACFs derived from the vocal tract variables (TVs) are used to train a dilated Convolutional Neural Network based depression classification model to obtain segment-level predictions. Then, we propose a Recurrent Neural Network based approach to obtain session-level predictions from segment-level predictions. We show that strengths of the segment-wise classifier are amplified when a session-wise classifier is trained on embeddings obtained from it. The model trained on ACFs derived from TVs show relative improvement of 27.47% in Unweighted Average Recall (UAR) at the session-level classification task, compared to the ACFs derived from Mel Frequency Cepstral Coefficients (MFCCs).
Emotional Voice Conversion using multitask learning with Text-to-speech
Nov 11, 2019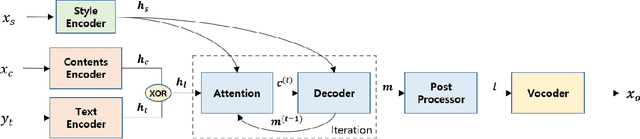

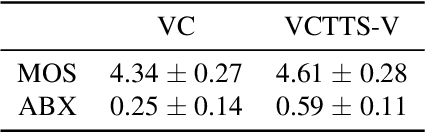
Voice conversion (VC) is a task to transform a person's voice to different style while conserving linguistic contents. Previous state-of-the-art on VC is based on sequence-to-sequence (seq2seq) model, which could mislead linguistic information. There was an attempt to overcome it by using textual supervision, it requires explicit alignment which loses the benefit of using seq2seq model. In this paper, a voice converter using multitask learning with text-to-speech (TTS) is presented. The embedding space of seq2seq-based TTS has abundant information on the text. The role of the decoder of TTS is to convert embedding space to speech, which is same to VC. In the proposed model, the whole network is trained to minimize loss of VC and TTS. VC is expected to capture more linguistic information and to preserve training stability by multitask learning. Experiments of VC were performed on a male Korean emotional text-speech dataset, and it is shown that multitask learning is helpful to keep linguistic contents in VC.
A Study of Acoustic Features in Arabic Speaker Identification under Noisy Environmental Conditions
Oct 23, 2021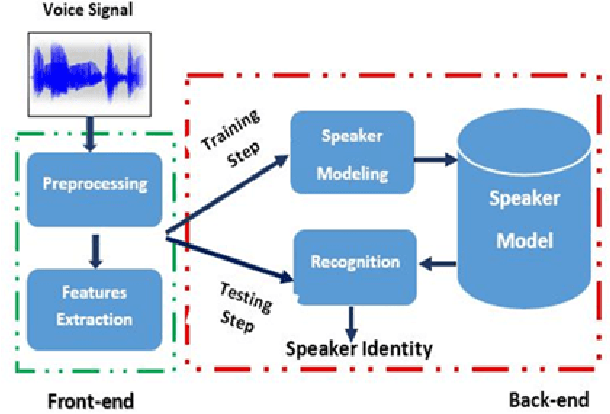
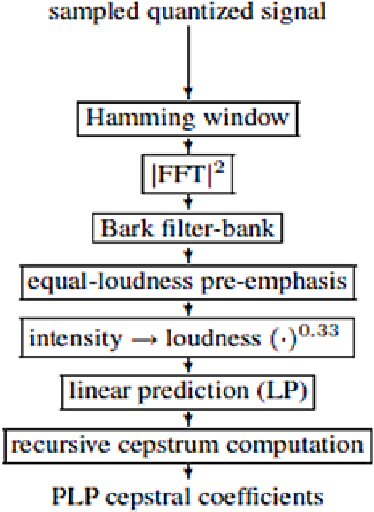

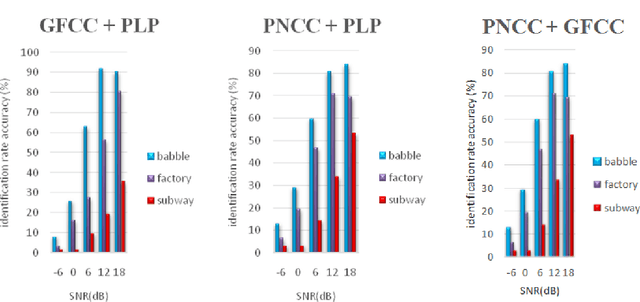
One of the major parts of the voice recognition field is the choice of acoustic features which have to be robust against the variability of the speech signal, mismatched conditions, and noisy environments. Thus, different speech feature extraction techniques have been developed. In this paper, we investigate the robustness of several front-end techniques in Arabic speaker identification. We evaluate five different features in babble, factory and subway conditions at the various signal to noise ratios (SNR). The obtained results showed that two of the auditory feature i.e. gammatone frequency cepstral coefficient (GFCC) and power normalization cepstral coefficients (PNCC), unlike their combination performs substantially better than a conventional speaker features i.e. Mel-frequency cepstral coefficients (MFCC).
Are you wearing a mask? Improving mask detection from speech using augmentation by cycle-consistent GANs
Jun 17, 2020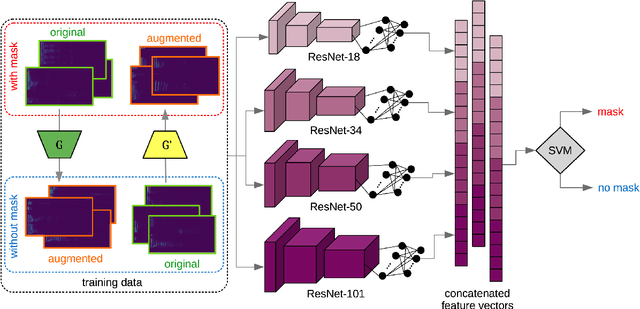
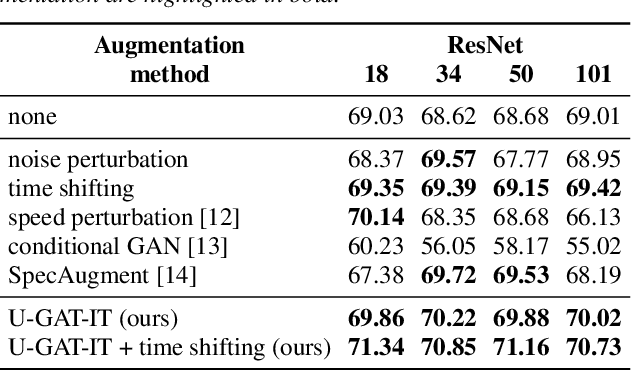
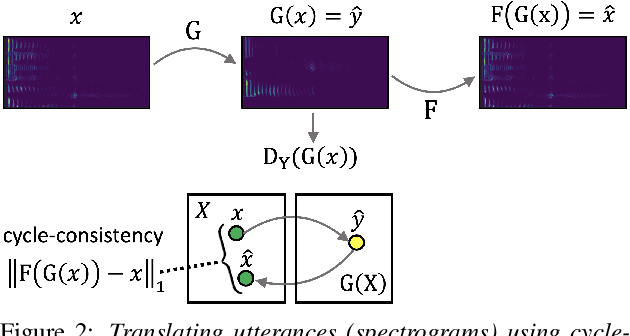

The task of detecting whether a person wears a face mask from speech is useful in modelling speech in forensic investigations, communication between surgeons or people protecting themselves against infectious diseases such as COVID-19. In this paper, we propose a novel data augmentation approach for mask detection from speech. Our approach is based on (i) training Generative Adversarial Networks (GANs) with cycle-consistency loss to translate unpaired utterances between two classes (with mask and without mask), and on (ii) generating new training utterances using the cycle-consistent GANs, assigning opposite labels to each translated utterance. Original and translated utterances are converted into spectrograms which are provided as input to a set of ResNet neural networks with various depths. The networks are combined into an ensemble through a Support Vector Machines (SVM) classifier. With this system, we participated in the Mask Sub-Challenge (MSC) of the INTERSPEECH 2020 Computational Paralinguistics Challenge, surpassing the baseline proposed by the organizers by 2.8%. Our data augmentation technique provided a performance boost of 0.9% on the private test set. Furthermore, we show that our data augmentation approach yields better results than other baseline and state-of-the-art augmentation methods.
Convolutional Neural Network-based Speech Enhancement for Cochlear Implant Recipients
Jul 03, 2019
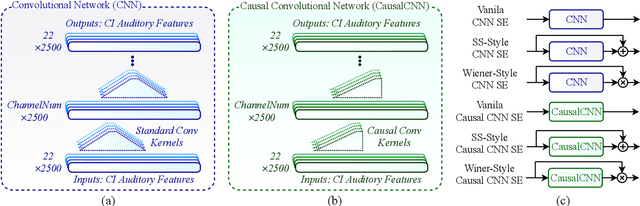
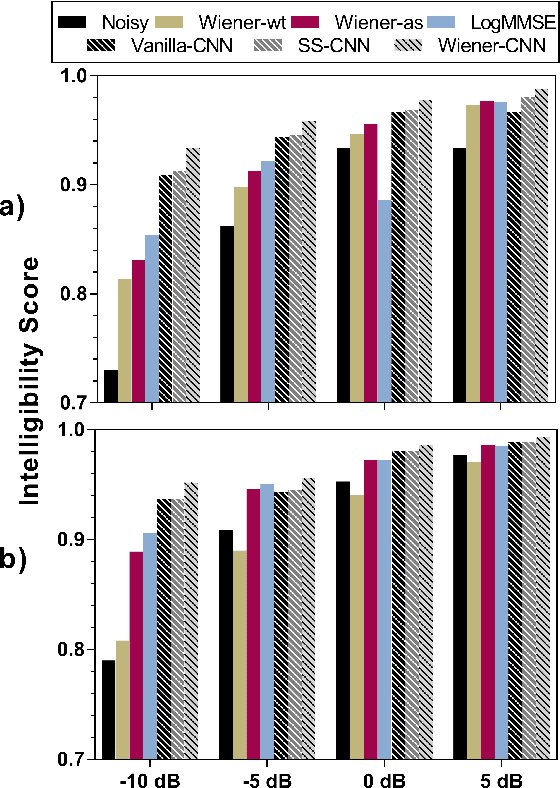
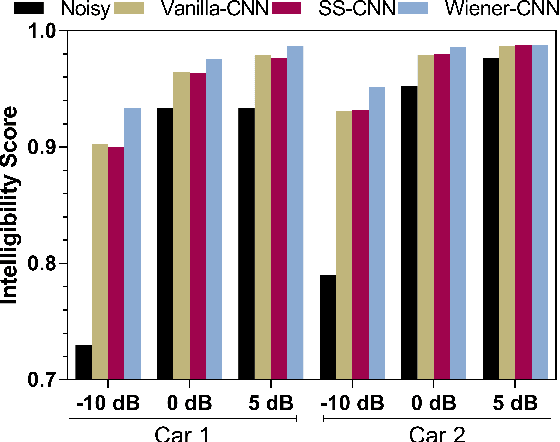
Attempts to develop speech enhancement algorithms with improved speech intelligibility for cochlear implant (CI) users have met with limited success. To improve speech enhancement methods for CI users, we propose to perform speech enhancement in a cochlear filter-bank feature space, a feature-set specifically designed for CI users based on CI auditory stimuli. We leverage a convolutional neural network (CNN) to extract both stationary and non-stationary components of environmental acoustics and speech. We propose three CNN architectures: (1) vanilla CNN that directly generates the enhanced signal; (2) spectral-subtraction-style CNN (SS-CNN) that first predicts noise and then generates the enhanced signal by subtracting noise from the noisy signal; (3) Wiener-style CNN (Wiener-CNN) that generates an optimal mask for suppressing noise. An important problem of the proposed networks is that they introduce considerable delays, which limits their real-time application for CI users. To address this, this study also considers causal variations of these networks. Our experiments show that the proposed networks (both causal and non-causal forms) achieve significant improvement over existing baseline systems. We also found that causal Wiener-CNN outperforms other networks, and leads to the best overall envelope coefficient measure (ECM). The proposed algorithms represent a viable option for implementation on the CCi-MOBILE research platform as a pre-processor for CI users in naturalistic environments.
Spatial Concept-Based Navigation with Human Speech Instructions via Probabilistic Inference on Bayesian Generative Model
Feb 18, 2020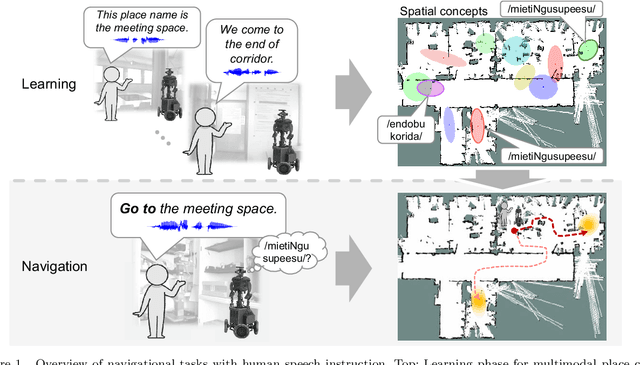

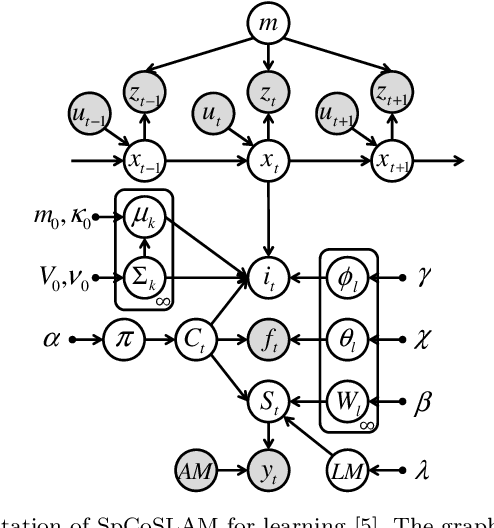
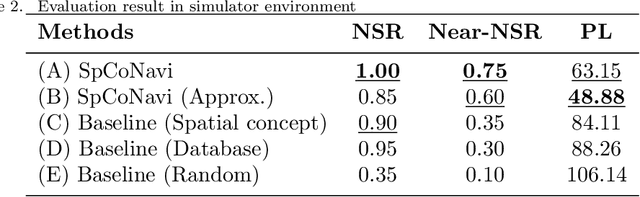
Robots are required to not only learn spatial concepts autonomously but also utilize such knowledge for various tasks in a domestic environment. Spatial concept represents a multimodal place category acquired from the robot's spatial experience including vision, speech-language, and self-position. The aim of this study is to enable a mobile robot to perform navigational tasks with human speech instructions, such as `Go to the kitchen', via probabilistic inference on a Bayesian generative model using spatial concepts. Specifically, path planning was formalized as the maximization of probabilistic distribution on the path-trajectory under speech instruction, based on a control-as-inference framework. Furthermore, we described the relationship between probabilistic inference based on the Bayesian generative model and control problem including reinforcement learning. We demonstrated path planning based on human instruction using acquired spatial concepts to verify the usefulness of the proposed approach in the simulator and in real environments. Experimentally, places instructed by the user's speech commands showed high probability values, and the trajectory toward the target place was correctly estimated. Our approach, based on probabilistic inference concerning decision-making, can lead to further improvement in robot autonomy.