 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
CopyPaste: An Augmentation Method for Speech Emotion Recognition
Oct 27, 2020
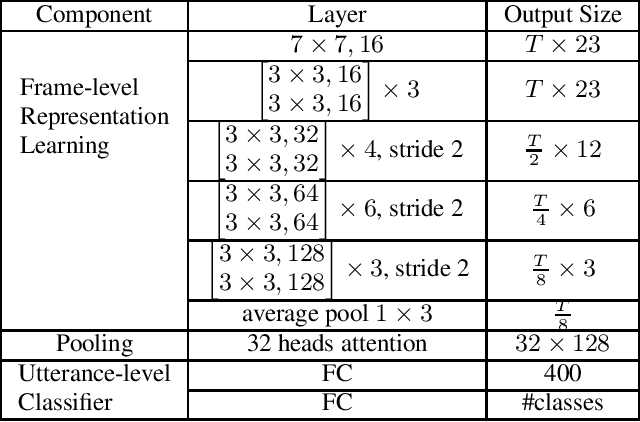
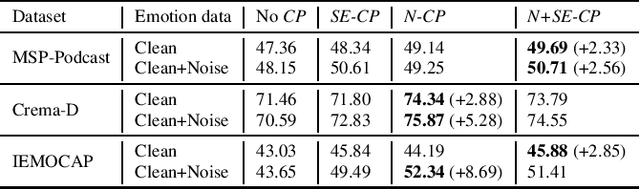
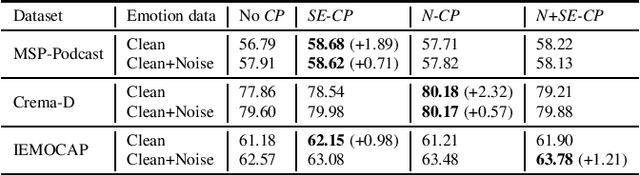
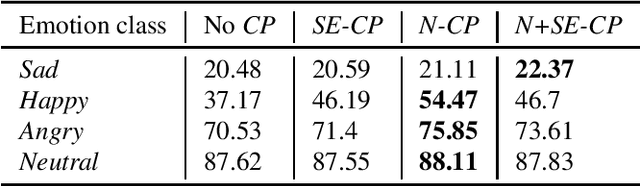
Data augmentation is a widely used strategy for training robust machine learning models. It partially alleviates the problem of limited data for tasks like speech emotion recognition (SER), where collecting data is expensive and challenging. This study proposes CopyPaste, a perceptually motivated novel augmentation procedure for SER. Assuming that the presence of emotions other than neutral dictates a speaker's overall perceived emotion in a recording, concatenation of an emotional (emotion E) and a neutral utterance can still be labeled with emotion E. We hypothesize that SER performance can be improved using these concatenated utterances in model training. To verify this, three CopyPaste schemes are tested on two deep learning models: one trained independently and another using transfer learning from an x-vector model, a speaker recognition model. We observed that all three CopyPaste schemes improve SER performance on all the three datasets considered: MSP-Podcast, Crema-D, and IEMOCAP. Additionally, CopyPaste performs better than noise augmentation and, using them together improves the SER performance further. Our experiments on noisy test sets suggested that CopyPaste is effective even in noisy test conditions.
Sandglasset: A Light Multi-Granularity Self-attentive Network For Time-Domain Speech Separation
Mar 08, 2021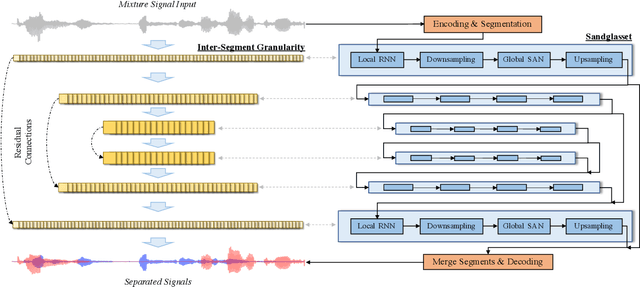
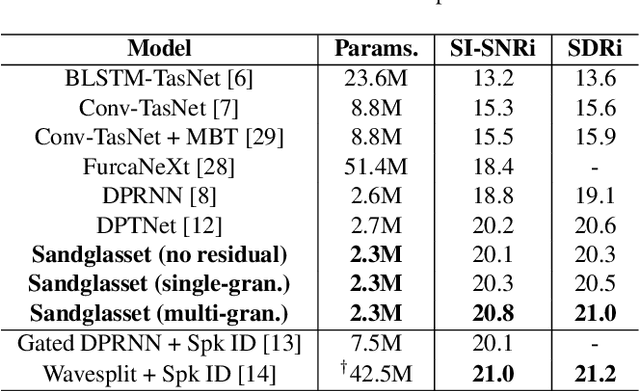
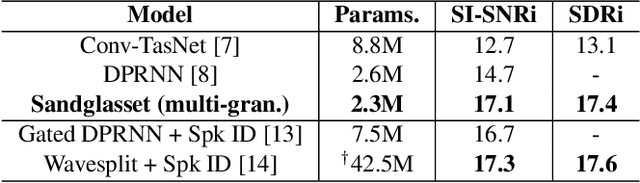
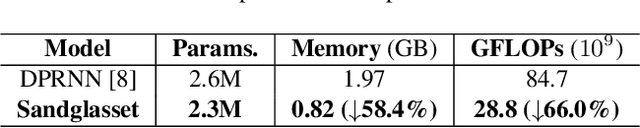
One of the leading single-channel speech separation (SS) models is based on a TasNet with a dual-path segmentation technique, where the size of each segment remains unchanged throughout all layers. In contrast, our key finding is that multi-granularity features are essential for enhancing contextual modeling and computational efficiency. We introduce a self-attentive network with a novel sandglass-shape, namely Sandglasset, which advances the state-of-the-art (SOTA) SS performance at significantly smaller model size and computational cost. Forward along each block inside Sandglasset, the temporal granularity of the features gradually becomes coarser until reaching half of the network blocks, and then successively turns finer towards the raw signal level. We also unfold that residual connections between features with the same granularity are critical for preserving information after passing through the bottleneck layer. Experiments show our Sandglasset with only 2.3M parameters has achieved the best results on two benchmark SS datasets -- WSJ0-2mix and WSJ0-3mix, where the SI-SNRi scores have been improved by absolute 0.8 dB and 2.4 dB, respectively, comparing to the prior SOTA results.
Towards Learning Universal Audio Representations
Nov 23, 2021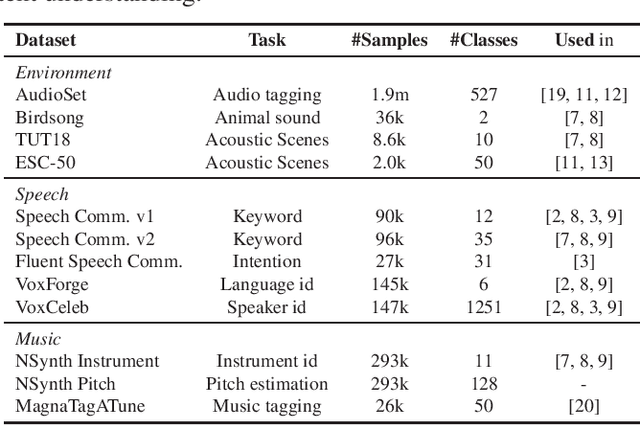
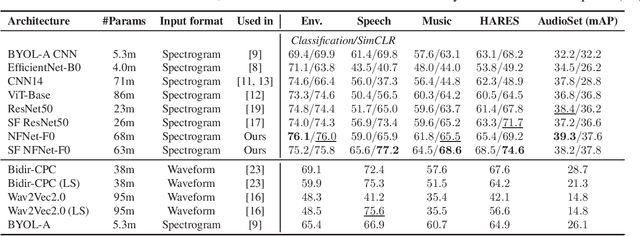
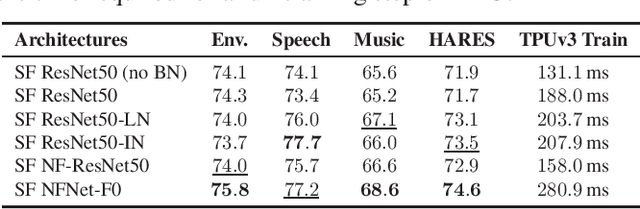
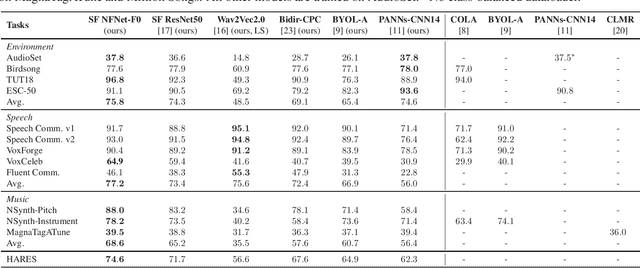
The ability to learn universal audio representations that can solve diverse speech, music, and environment tasks can spur many applications that require general sound content understanding. In this work, we introduce a holistic audio representation evaluation suite (HARES) spanning 12 downstream tasks across audio domains and provide a thorough empirical study of recent sound representation learning systems on that benchmark. We discover that previous sound event classification or speech models do not generalize outside of their domains. We observe that more robust audio representations can be learned with the SimCLR objective; however, the model's transferability depends heavily on the model architecture. We find the Slowfast architecture is good at learning rich representations required by different domains, but its performance is affected by the normalization scheme. Based on these findings, we propose a novel normalizer-free Slowfast NFNet and achieve state-of-the-art performance across all domains.
Contextualized Translation of Automatically Segmented Speech
Aug 05, 2020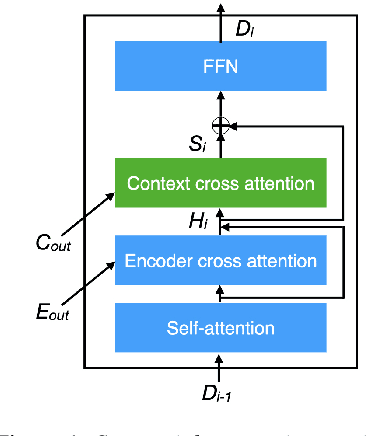
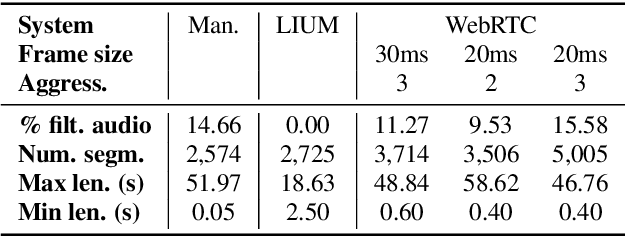
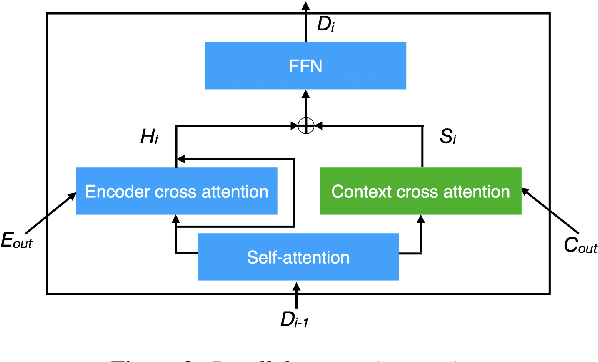
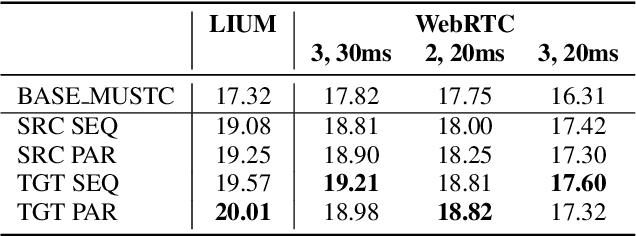
Direct speech-to-text translation (ST) models are usually trained on corpora segmented at sentence level, but at inference time they are commonly fed with audio split by a voice activity detector (VAD). Since VAD segmentation is not syntax-informed, the resulting segments do not necessarily correspond to well-formed sentences uttered by the speaker but, most likely, to fragments of one or more sentences. This segmentation mismatch degrades considerably the quality of ST models' output. So far, researchers have focused on improving audio segmentation towards producing sentence-like splits. In this paper, instead, we address the issue in the model, making it more robust to a different, potentially sub-optimal segmentation. To this aim, we train our models on randomly segmented data and compare two approaches: fine-tuning and adding the previous segment as context. We show that our context-aware solution is more robust to VAD-segmented input, outperforming a strong base model and the fine-tuning on different VAD segmentations of an English-German test set by up to 4.25 BLEU points.
Unified and Multilingual Author Profiling for Detecting Haters
Sep 19, 2021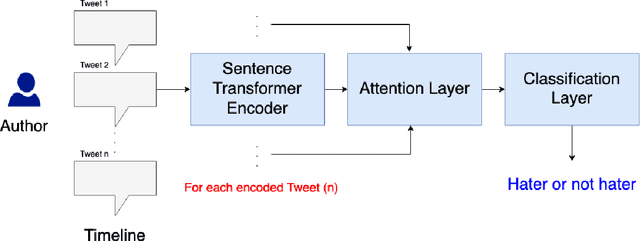

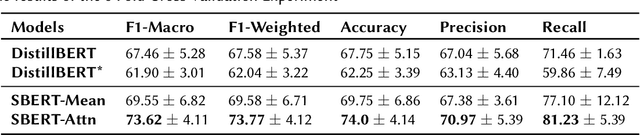
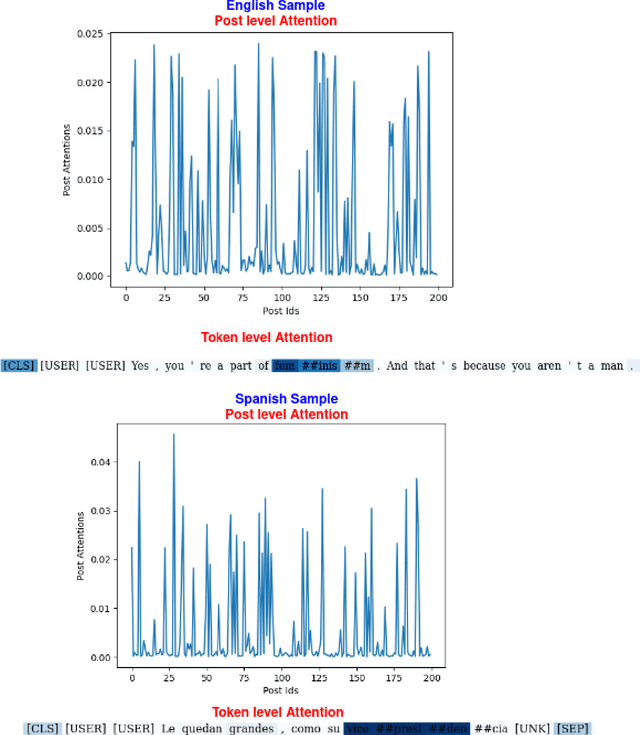
This paper presents a unified user profiling framework to identify hate speech spreaders by processing their tweets regardless of the language. The framework encodes the tweets with sentence transformers and applies an attention mechanism to select important tweets for learning user profiles. Furthermore, the attention layer helps to explain why a user is a hate speech spreader by producing attention weights at both token and post level. Our proposed model outperformed the state-of-the-art multilingual transformer models.
* 9 pages, 2 figures, see the original paper: http://ceur-ws.org/Vol-2936/paper-157.pdf
Improving Security in McAdams Coefficient-Based Speaker Anonymization by Watermarking Method
Jul 15, 2021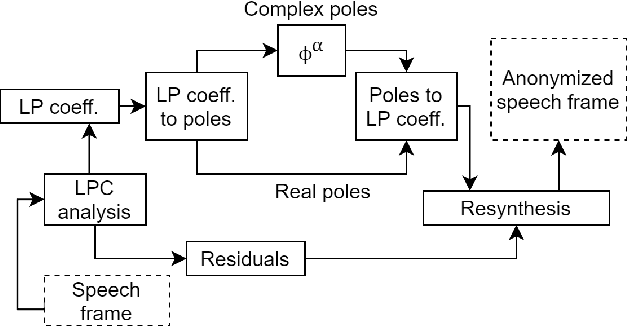
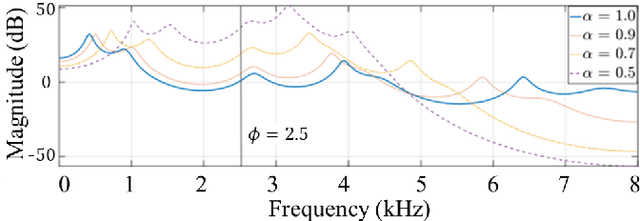
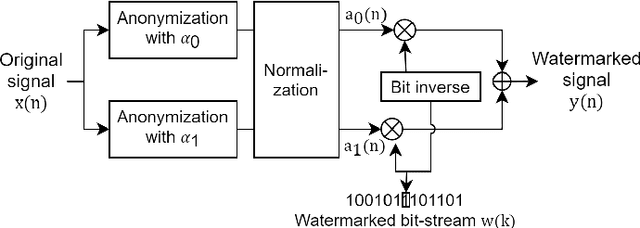
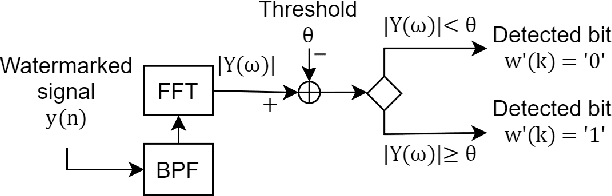
Speaker anonymization aims to suppress speaker individuality to protect privacy in speech while preserving the other aspects, such as speech content. One effective solution for anonymization is to modify the McAdams coefficient. In this work, we propose a method to improve the security for speaker anonymization based on the McAdams coefficient by using a speech watermarking approach. The proposed method consists of two main processes: one for embedding and one for detection. In embedding process, two different McAdams coefficients represent binary bits ``0" and ``1". The watermarked speech is then obtained by frame-by-frame bit inverse switching. Subsequently, the detection process is carried out by a power spectrum comparison. We conducted objective evaluations with reference to the VoicePrivacy 2020 Challenge (VP2020) and of the speech watermarking with reference to the Information Hiding Challenge (IHC) and found that our method could satisfy the blind detection, inaudibility, and robustness requirements in watermarking. It also significantly improved the anonymization performance in comparison to the secondary baseline system in VP2020.
Similarity-and-Independence-Aware Beamformer with Iterative Casting and Boost Start for Target Source Extraction Using Reference
Oct 18, 2021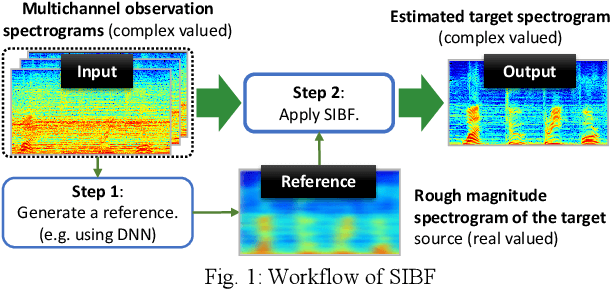
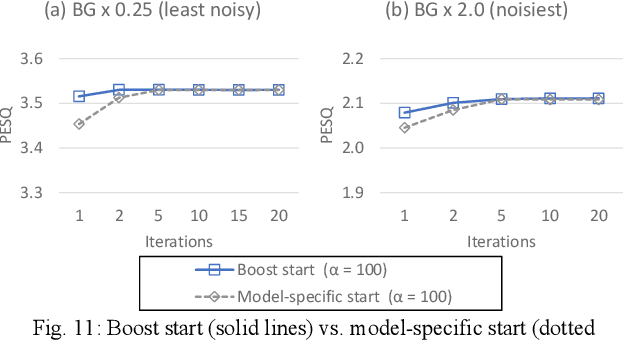
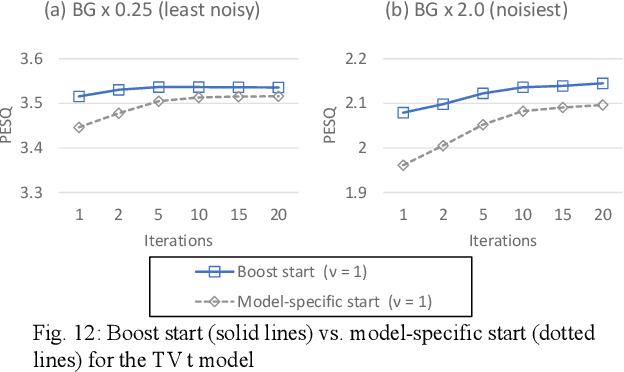
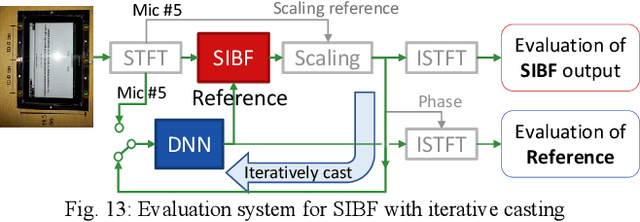
Target source extraction is significant for improving human speech intelligibility and the speech recognition performance of computers. This study describes a method for target source extraction, called the similarity-and-independence-aware beamformer (SIBF). The SIBF extracts the target source using a rough magnitude spectrogram as the reference signal. The advantage of the SIBF is that it can obtain a more accurate signal than the spectrogram generated by target-enhancing methods such as speech enhancement based on deep neural networks. For the extraction, we extend the framework of deflationary independent component analysis (ICA) by considering the similarities between the reference and extracted target sources, in addition to the mutual independence of all the potential sources. To solve the extraction problem by maximum-likelihood estimation, we introduce three source models that can reflect the similarities. The major contributions of this study are as follows. First, the extraction performance is improved using two methods, namely boost start for faster convergence and iterative casting for generating a more accurate reference. The effectiveness of these methods is verified through experiments using the CHiME3 dataset. Second, a concept of a fixed point pertaining to accuracy is developed. This concept facilitates understanding the relationship between the reference and SIBF output in terms of accuracy. Third, a unified formulation of the SIBF and mask-based beamformer is realized to apply the expertise of conventional BFs to the SIBF. The findings of this study can also improve the performance of the SIBF and promote research on ICA and conventional beamformers. Index Terms: beamformer, independent component analysis, source separation, speech enhancement, target source extraction
Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
Oct 31, 2019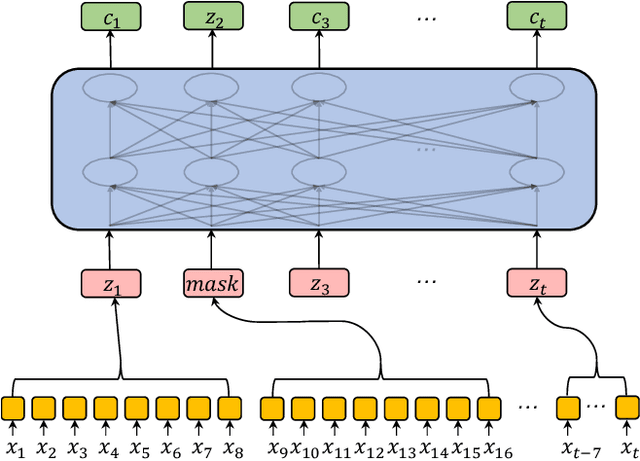
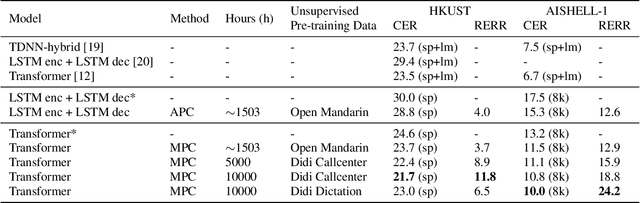
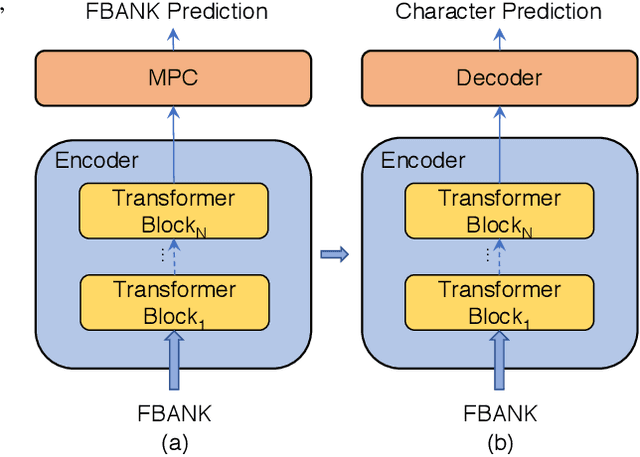
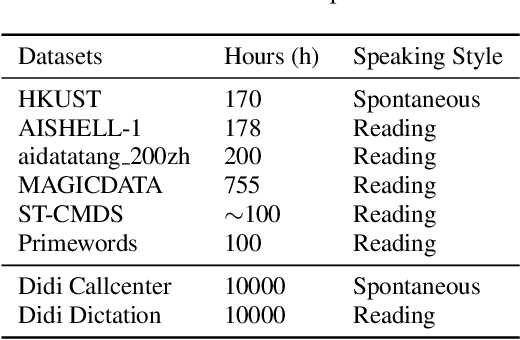
Speech recognition technologies are gaining enormous popularity in various industrial applications. However, building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, an unsupervised pre-training method called Masked Predictive Coding is proposed, which can be applied for unsupervised pre-training with Transformer based model. Experiments on HKUST show that using the same training data, we can achieve CER 23.3%, exceeding the best end-to-end model by over 0.2% absolute CER. With more pre-training data, we can further reduce the CER to 21.0%, or a 11.8% relative CER reduction over baseline.
Video-Driven Speech Reconstruction using Generative Adversarial Networks
Jun 14, 2019

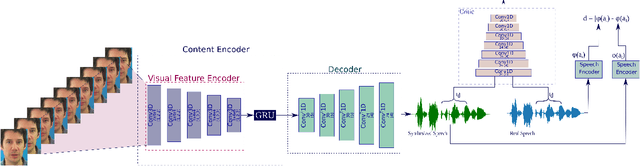
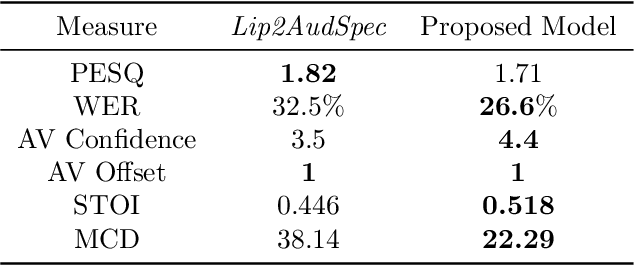
Speech is a means of communication which relies on both audio and visual information. The absence of one modality can often lead to confusion or misinterpretation of information. In this paper we present an end-to-end temporal model capable of directly synthesising audio from silent video, without needing to transform to-and-from intermediate features. Our proposed approach, based on GANs is capable of producing natural sounding, intelligible speech which is synchronised with the video. The performance of our model is evaluated on the GRID dataset for both speaker dependent and speaker independent scenarios. To the best of our knowledge this is the first method that maps video directly to raw audio and the first to produce intelligible speech when tested on previously unseen speakers. We evaluate the synthesised audio not only based on the sound quality but also on the accuracy of the spoken words.
Unpaired Image-to-Speech Synthesis with Multimodal Information Bottleneck
Aug 19, 2019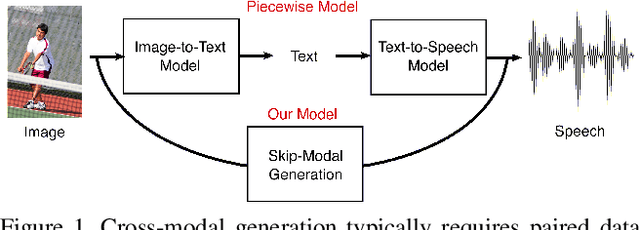
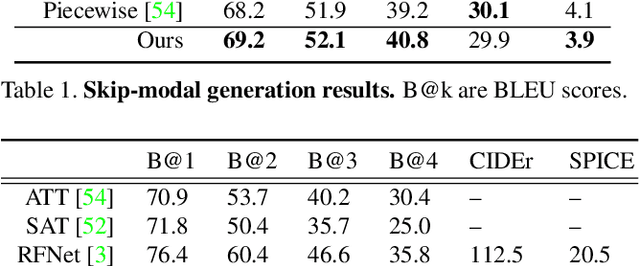
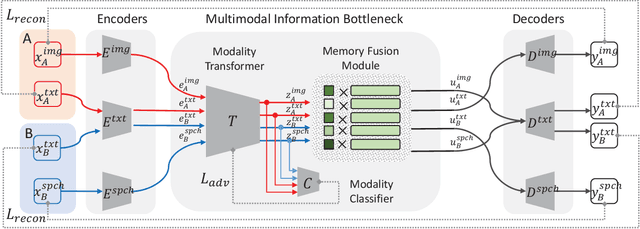
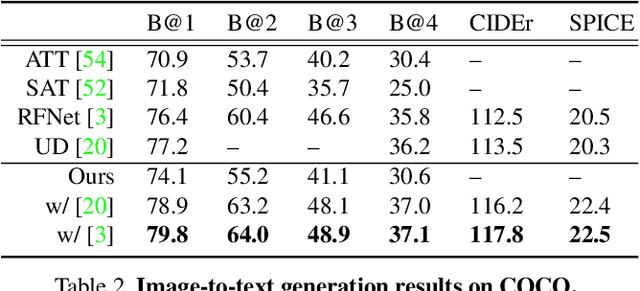
Deep generative models have led to significant advances in cross-modal generation such as text-to-image synthesis. Training these models typically requires paired data with direct correspondence between modalities. We introduce the novel problem of translating instances from one modality to another without paired data by leveraging an intermediate modality shared by the two other modalities. To demonstrate this, we take the problem of translating images to speech. In this case, one could leverage disjoint datasets with one shared modality, e.g., image-text pairs and text-speech pairs, with text as the shared modality. We call this problem "skip-modal generation" because the shared modality is skipped during the generation process. We propose a multimodal information bottleneck approach that learns the correspondence between modalities from unpaired data (image and speech) by leveraging the shared modality (text). We address fundamental challenges of skip-modal generation: 1) learning multimodal representations using a single model, 2) bridging the domain gap between two unrelated datasets, and 3) learning the correspondence between modalities from unpaired data. We show qualitative results on image-to-speech synthesis; this is the first time such results have been reported in the literature. We also show that our approach improves performance on traditional cross-modal generation, suggesting that it improves data efficiency in solving individual tasks.