 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Investigating the Lombard Effect Influence on End-to-End Audio-Visual Speech Recognition
Jun 05, 2019
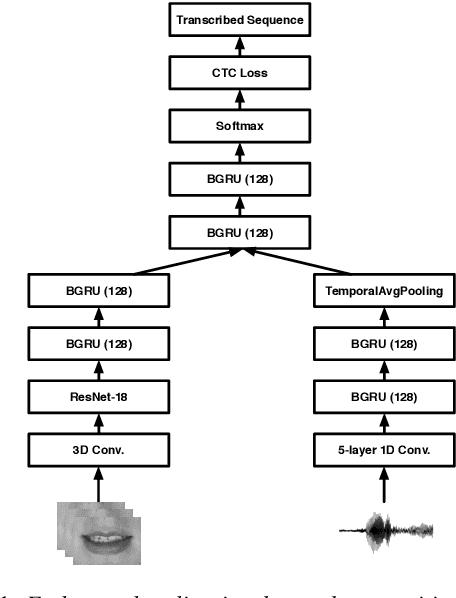

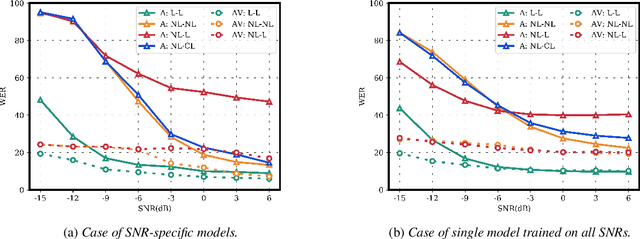
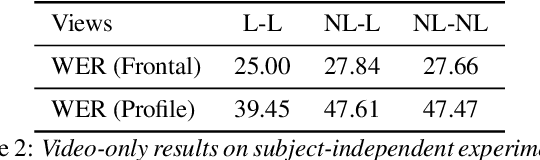
Several audio-visual speech recognition models have been recently proposed which aim to improve the robustness over audio-only models in the present of noise. However, almost all of them ignore the impact of the Lombard effect, i.e., the change in speaking style in noisy environments which aims to make speech more intelligible and affects both the acoustic characteristics of speech and the lip movements. In this paper, we investigate the impact of the Lombard effect in audio-visual speech recognition. To the best of our knowledge, this is the first work which does so using end-to-end deep architectures and presents results on unseen speakers. Our results show that properly modelling Lombard speech is always beneficial. Even if a relatively small amount of Lombard speech is added to the training set then the performance in a real scenario, where noisy Lombard speech is present, can be significantly improved. We also show that the standard approach followed in the literature, where a model is trained and tested on noisy plain speech, provides a correct estimate of the video-only performance and slightly underestimates the audio-visual performance. In case of audio-only approaches, performance is overestimated for SNRs higher than -3dB and underestimated for lower SNRs.
Emotionless: Privacy-Preserving Speech Analysis for Voice Assistants
Aug 09, 2019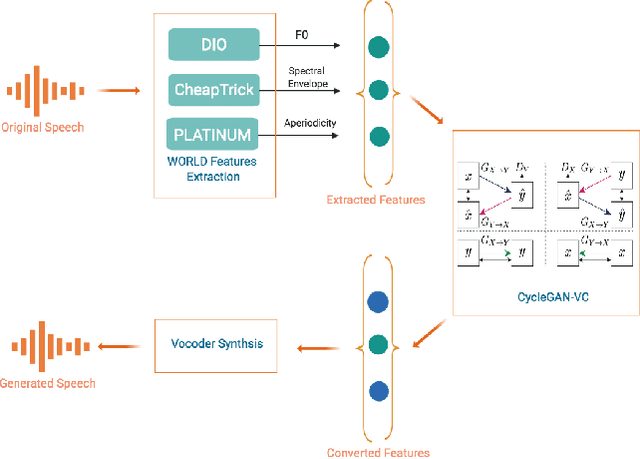
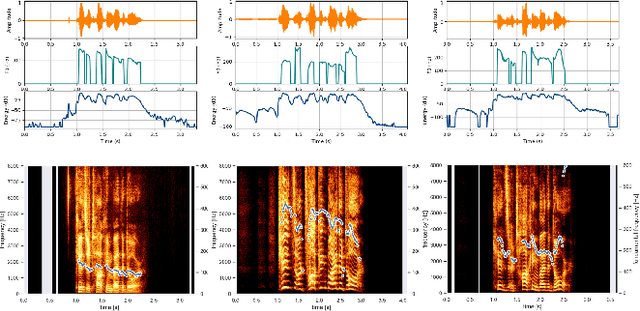
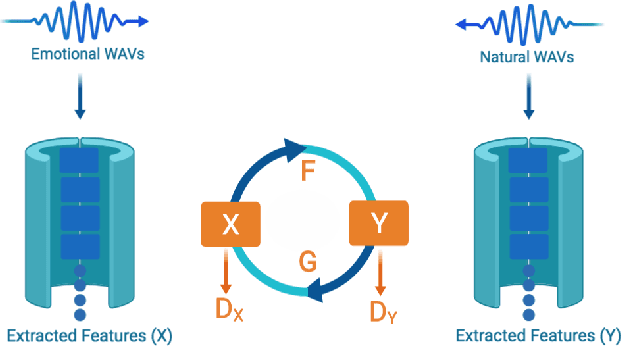
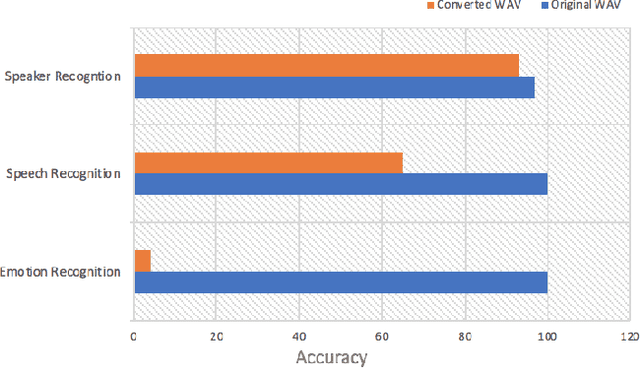
Voice-enabled interactions provide more human-like experiences in many popular IoT systems. Cloud-based speech analysis services extract useful information from voice input using speech recognition techniques. The voice signal is a rich resource that discloses several possible states of a speaker, such as emotional state, confidence and stress levels, physical condition, age, gender, and personal traits. Service providers can build a very accurate profile of a user's demographic category, personal preferences, and may compromise privacy. To address this problem, a privacy-preserving intermediate layer between users and cloud services is proposed to sanitize the voice input. It aims to maintain utility while preserving user privacy. It achieves this by collecting real time speech data and analyzes the signal to ensure privacy protection prior to sharing of this data with services providers. Precisely, the sensitive representations are extracted from the raw signal by using transformation functions and then wrapped it via voice conversion technology. Experimental evaluation based on emotion recognition to assess the efficacy of the proposed method shows that identification of sensitive emotional state of the speaker is reduced by ~96 %.
FastCorrect: Fast Error Correction with Edit Alignment for Automatic Speech Recognition
May 09, 2021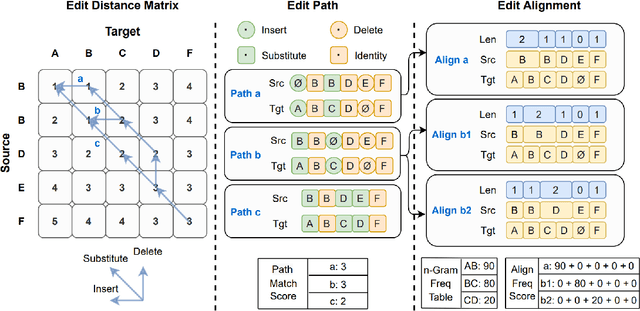
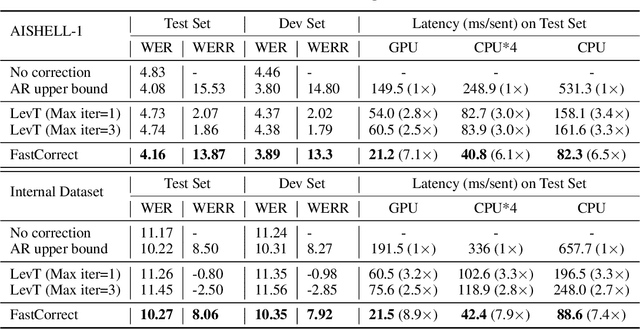
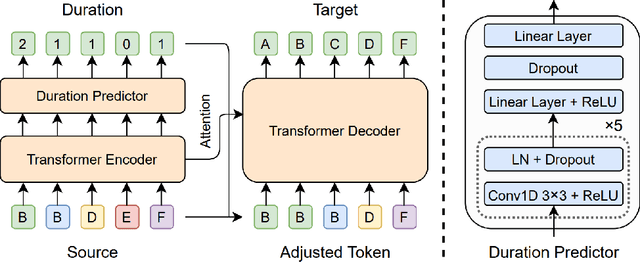
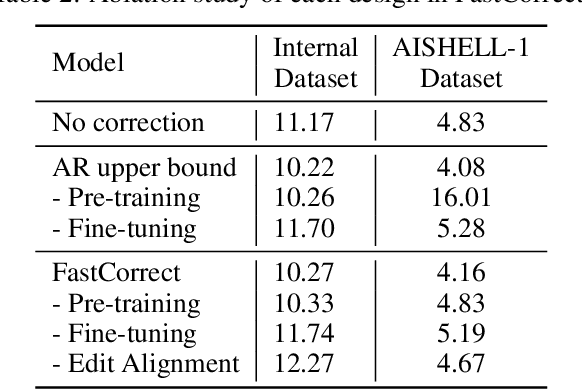
Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER) than original ASR outputs. Previous works usually use a sequence-to-sequence model to correct an ASR output sentence autoregressively, which causes large latency and cannot be deployed in online ASR services. A straightforward solution to reduce latency, inspired by non-autoregressive (NAR) neural machine translation, is to use an NAR sequence generation model for ASR error correction, which, however, comes at the cost of significantly increased ASR error rate. In this paper, observing distinctive error patterns and correction operations (i.e., insertion, deletion, and substitution) in ASR, we propose FastCorrect, a novel NAR error correction model based on edit alignment. In training, FastCorrect aligns each source token from an ASR output sentence to the target tokens from the corresponding ground-truth sentence based on the edit distance between the source and target sentences, and extracts the number of target tokens corresponding to each source token during edition/correction, which is then used to train a length predictor and to adjust the source tokens to match the length of the target sentence for parallel generation. In inference, the token number predicted by the length predictor is used to adjust the source tokens for target sequence generation. Experiments on the public AISHELL-1 dataset and an internal industrial-scale ASR dataset show the effectiveness of FastCorrect for ASR error correction: 1) it speeds up the inference by 6-9 times and maintains the accuracy (8-14% WER reduction) compared with the autoregressive correction model; and 2) it outperforms the accuracy of popular NAR models adopted in neural machine translation by a large margin.
Decoding Imagined Speech using Wavelet Features and Deep Neural Networks
Mar 19, 2020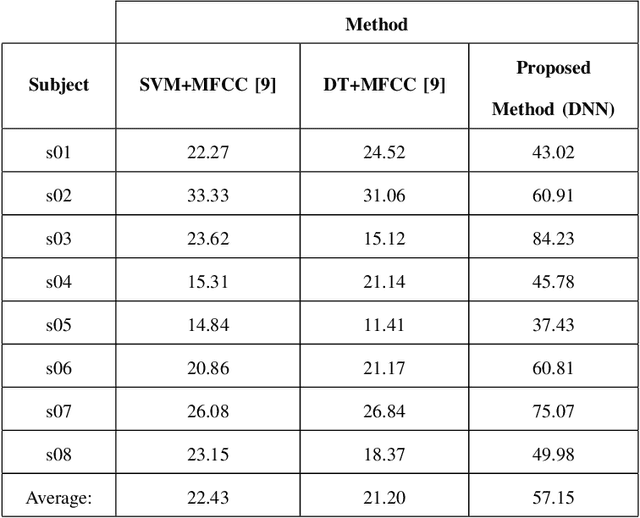
This paper proposes a novel approach that uses deep neural networks for classifying imagined speech, significantly increasing the classification accuracy. The proposed approach employs only the EEG channels over specific areas of the brain for classification, and derives distinct feature vectors from each of those channels. This gives us more data to train a classifier, enabling us to use deep learning approaches. Wavelet and temporal domain features are extracted from each channel. The final class label of each test trial is obtained by applying a majority voting on the classification results of the individual channels considered in the trial. This approach is used for classifying all the 11 prompts in the KaraOne dataset of imagined speech. The proposed architecture and the approach of treating the data have resulted in an average classification accuracy of 57.15%, which is an improvement of around 35% over the state-of-the-art results.
Improved Language Identification Through Cross-Lingual Self-Supervised Learning
Jul 24, 2021
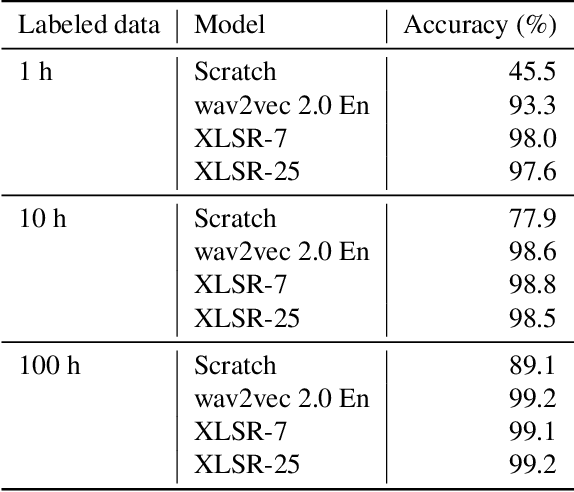
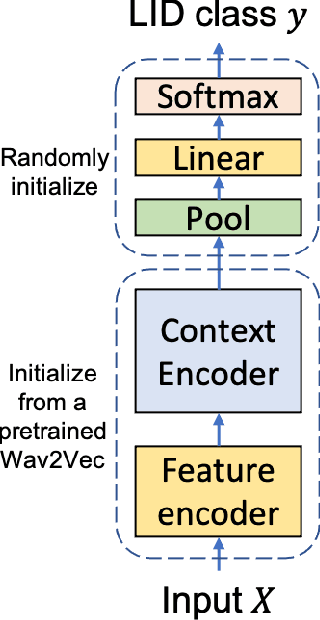
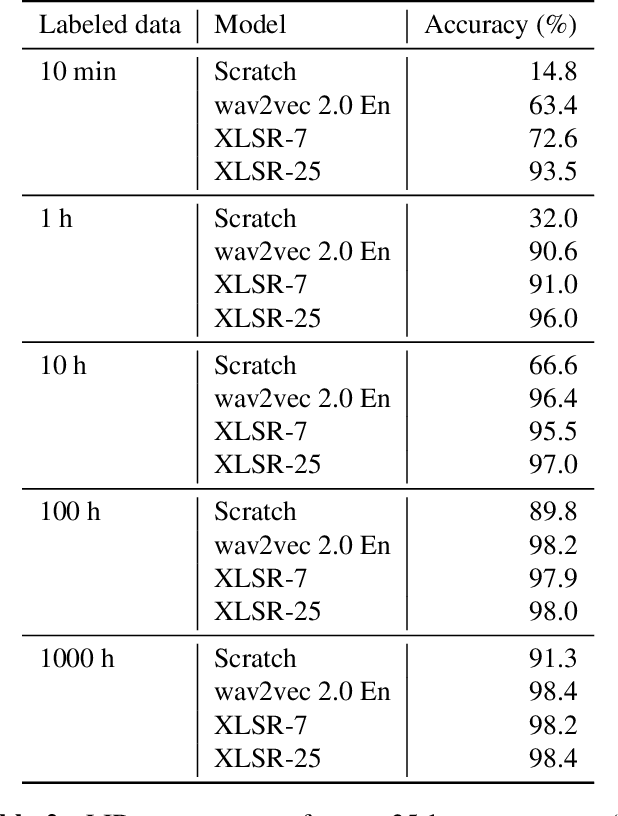
Language identification greatly impacts the success of downstream tasks such as automatic speech recognition. Recently, self-supervised speech representations learned by wav2vec 2.0 have been shown to be very effective for a range of speech tasks. We extend previous self-supervised work on language identification by experimenting with pre-trained models which were learned on real-world unconstrained speech in multiple languages and not just on English. We show that models pre-trained on many languages perform better and enable language identification systems that require very little labeled data to perform well. Results on a 25 languages setup show that with only 10 minutes of labeled data per language, a cross-lingually pre-trained model can achieve over 93% accuracy.
Filterbank design for end-to-end speech separation
Oct 23, 2019
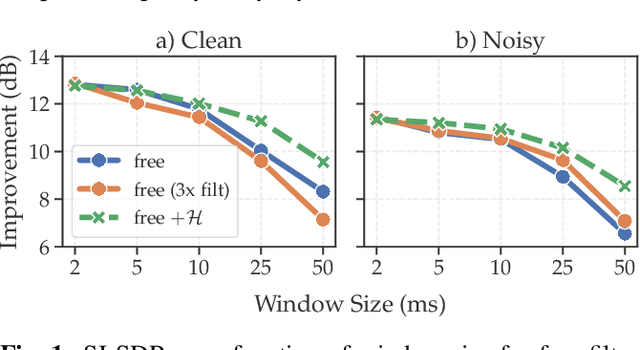
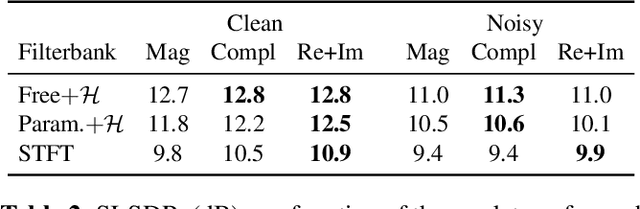
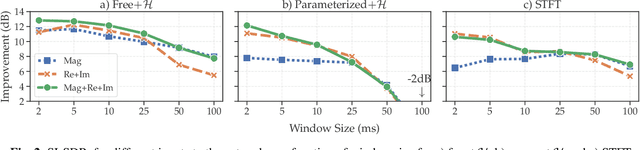
Single-channel speech separation has recently made great progress thanks to learned filterbanks as used in ConvTasNet. In parallel, parameterized filterbanks have been proposed for speaker recognition where only center frequencies and bandwidths are learned. In this work, we extend real-valued learned and parameterized filterbanks into complex-valued analytic filterbanks and define a set of corresponding representations and masking strategies. We evaluate these filterbanks on a newly released noisy speech separation dataset (WHAM). The results show that the proposed analytic learned filterbank consistently outperforms the real-valued filterbank of ConvTasNet. Also, we validate the use of parameterized filterbanks and show that complex-valued representations and masks are beneficial in all conditions. Finally, we show that the STFT achieves its best performance for 2ms windows.
Detecting Adversarial Attacks On Audio-Visual Speech Recognition
Dec 18, 2019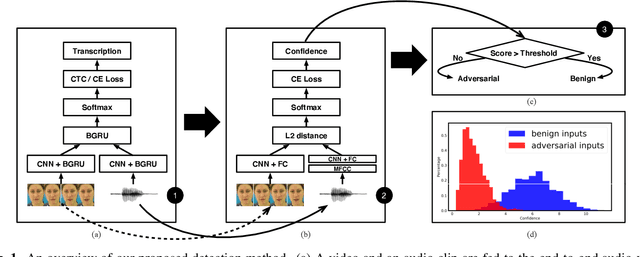
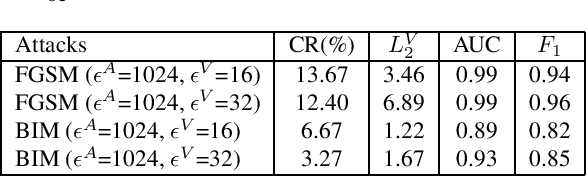

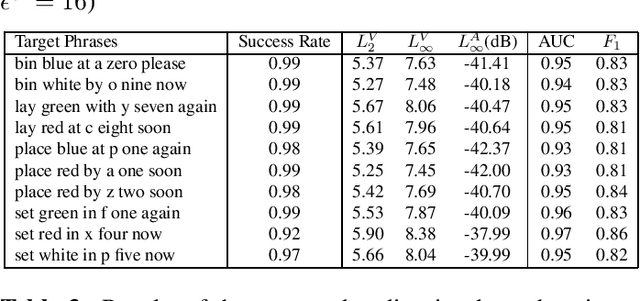
Adversarial attacks pose a threat to deep learning models. However, research on adversarial detection methods, especially in the multi-modal domain, is very limited. In this work, we propose an efficient and straightforward detection method based on the temporal correlation between audio and video streams. The main idea is that the correlation between audio and video in adversarial examples will be lower than benign examples due to added adversarial noise. We use the synchronisation confidence score as a proxy for audio-visual correlation and based on it we can detect adversarial attacks. To the best of our knowledge, this is the first work on detection of adversarial attacks on audio-visual speech recognition models. We apply recent adversarial attacks on two audio-visual speech recognition models trained on the GRID and LRW datasets. The experimental results demonstrated that the proposed approach is an effective way for detecting such attacks.
Hate Speech Detection and Racial Bias Mitigation in Social Media based on BERT model
Aug 28, 2020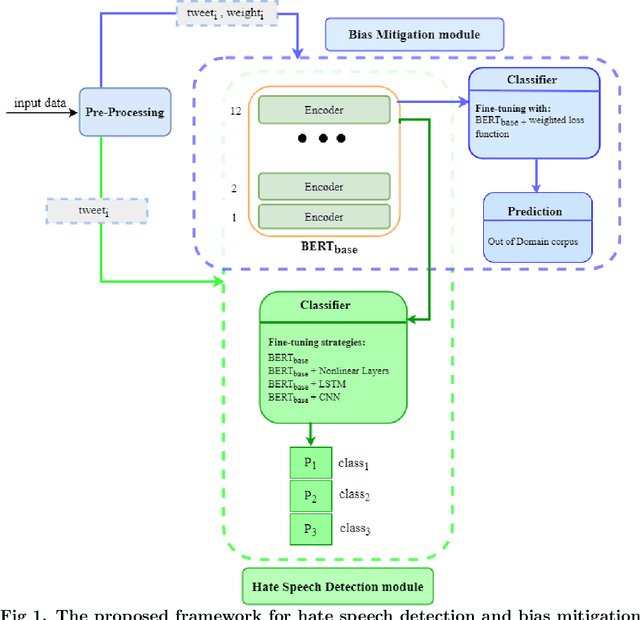
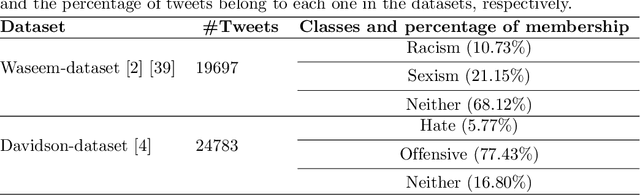
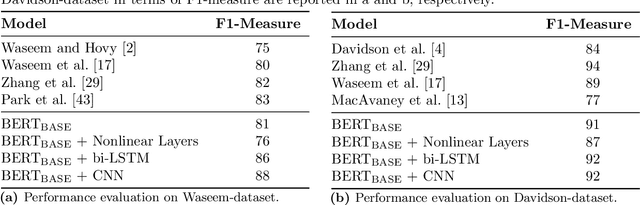
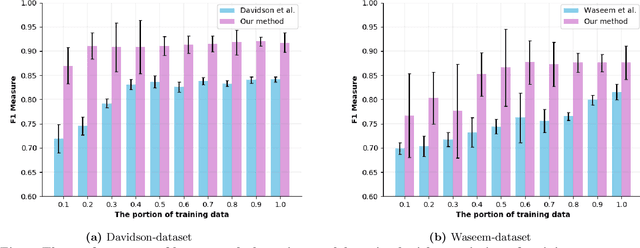
Disparate biases associated with datasets and trained classifiers in hateful and abusive content identification tasks have raised many concerns recently. Although the problem of biased datasets on abusive language detection has been addressed more frequently, biases arising from trained classifiers have not yet been a matter of concern. Here, we first introduce a transfer learning approach for hate speech detection based on an existing pre-trained language model called BERT and evaluate the proposed model on two publicly available datasets annotated for racism, sexism, hate or offensive content on Twitter. Next, we introduce a bias alleviation mechanism in hate speech detection task to mitigate the effect of bias in training set during the fine-tuning of our pre-trained BERT-based model. Toward that end, we use an existing regularization method to reweight input samples, thereby decreasing the effects of high correlated training set' s n-grams with class labels, and then fine-tune our pre-trained BERT-based model with the new re-weighted samples. To evaluate our bias alleviation mechanism, we employ a cross-domain approach in which we use the trained classifiers on the aforementioned datasets to predict the labels of two new datasets from Twitter, AAE-aligned and White-aligned groups, which indicate tweets written in African-American English (AAE) and Standard American English (SAE) respectively. The results show the existence of systematic racial bias in trained classifiers as they tend to assign tweets written in AAE from AAE-aligned group to negative classes such as racism, sexism, hate, and offensive more often than tweets written in SAE from White-aligned. However, the racial bias in our classifiers reduces significantly after our bias alleviation mechanism is incorporated. This work could institute the first step towards debiasing hate speech and abusive language detection systems.
Towards Learning Universal Audio Representations
Nov 23, 2021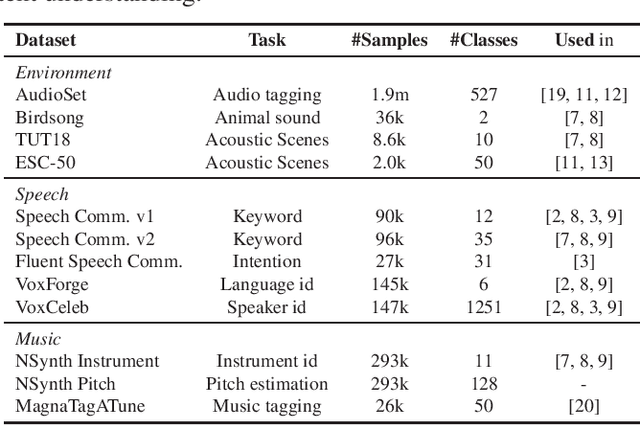
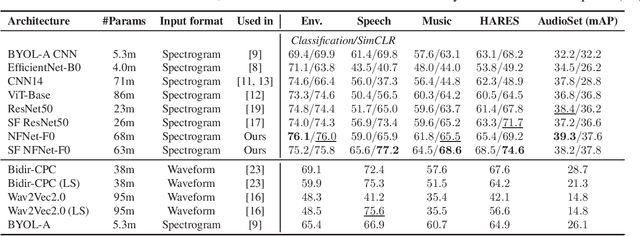
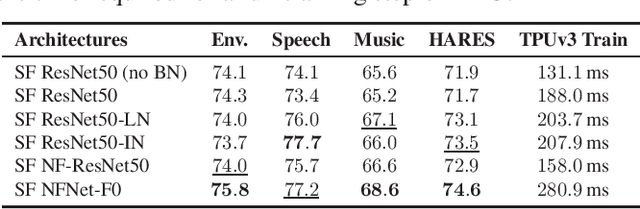
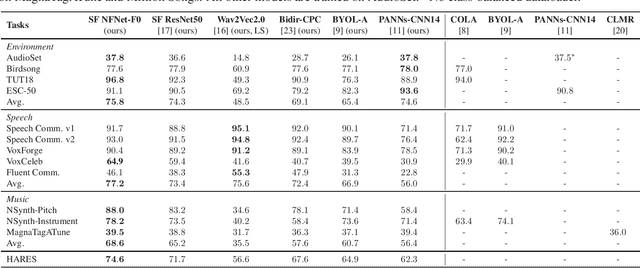
The ability to learn universal audio representations that can solve diverse speech, music, and environment tasks can spur many applications that require general sound content understanding. In this work, we introduce a holistic audio representation evaluation suite (HARES) spanning 12 downstream tasks across audio domains and provide a thorough empirical study of recent sound representation learning systems on that benchmark. We discover that previous sound event classification or speech models do not generalize outside of their domains. We observe that more robust audio representations can be learned with the SimCLR objective; however, the model's transferability depends heavily on the model architecture. We find the Slowfast architecture is good at learning rich representations required by different domains, but its performance is affected by the normalization scheme. Based on these findings, we propose a novel normalizer-free Slowfast NFNet and achieve state-of-the-art performance across all domains.
The USTC-NEL Speech Translation system at IWSLT 2018
Dec 06, 2018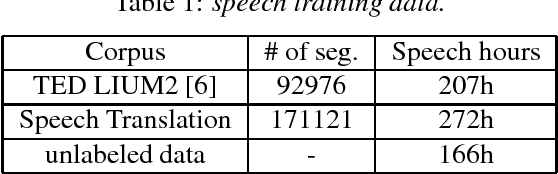
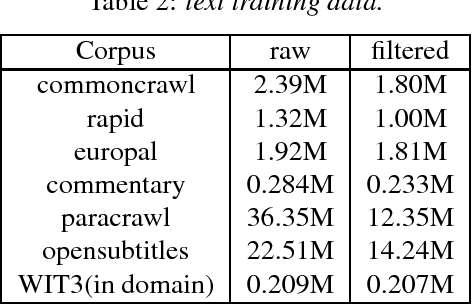
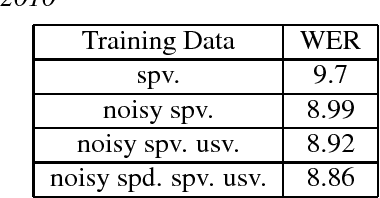

This paper describes the USTC-NEL system to the speech translation task of the IWSLT Evaluation 2018. The system is a conventional pipeline system which contains 3 modules: speech recognition, post-processing and machine translation. We train a group of hybrid-HMM models for our speech recognition, and for machine translation we train transformer based neural machine translation models with speech recognition output style text as input. Experiments conducted on the IWSLT 2018 task indicate that, compared to baseline system from KIT, our system achieved 14.9 BLEU improvement.