 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Pathological voice adaptation with autoencoder-based voice conversion
Jun 15, 2021
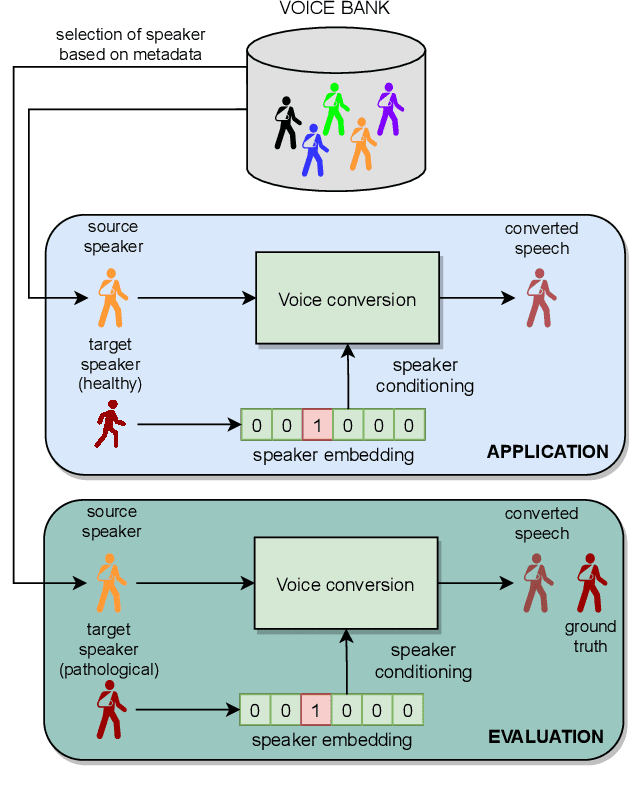

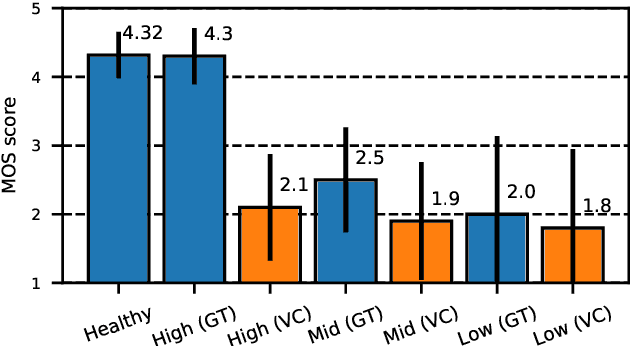
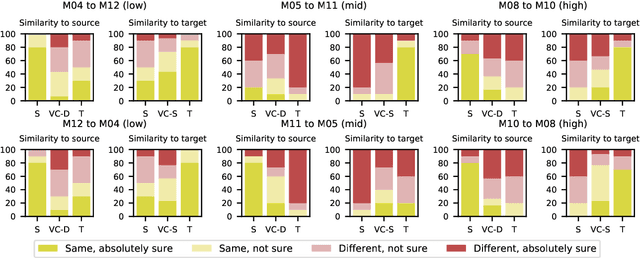
In this paper, we propose a new approach to pathological speech synthesis. Instead of using healthy speech as a source, we customise an existing pathological speech sample to a new speaker's voice characteristics. This approach alleviates the evaluation problem one normally has when converting typical speech to pathological speech, as in our approach, the voice conversion (VC) model does not need to be optimised for speech degradation but only for the speaker change. This change in the optimisation ensures that any degradation found in naturalness is due to the conversion process and not due to the model exaggerating characteristics of a speech pathology. To show a proof of concept of this method, we convert dysarthric speech using the UASpeech database and an autoencoder-based VC technique. Subjective evaluation results show reasonable naturalness for high intelligibility dysarthric speakers, though lower intelligibility seems to introduce a marginal degradation in naturalness scores for mid and low intelligibility speakers compared to ground truth. Conversion of speaker characteristics for low and high intelligibility speakers is successful, but not for mid. Whether the differences in the results for the different intelligibility levels is due to the intelligibility levels or due to the speakers needs to be further investigated.
Training Speech Recognition Models with Federated Learning: A Quality/Cost Framework
Oct 29, 2020
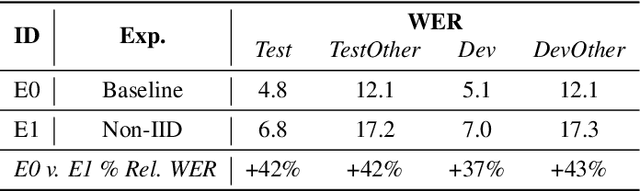
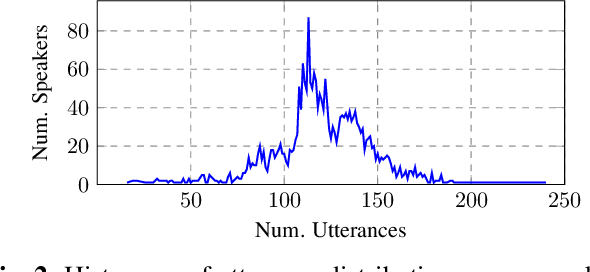
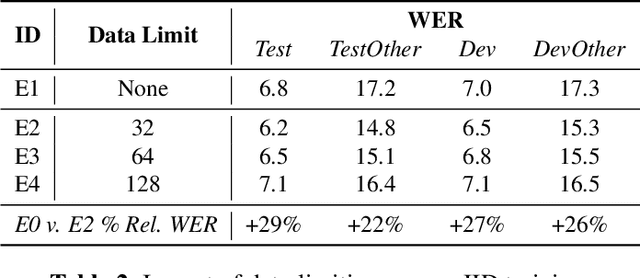
We propose using federated learning, a decentralized on-device learning paradigm, to train speech recognition models. By performing epochs of training on a per-user basis, federated learning must incur the cost of dealing with non-IID data distributions, which are expected to negatively affect the quality of the trained model. We propose a framework by which the degree of non-IID-ness can be varied, consequently illustrating a trade-off between model quality and the computational cost of federated training, which we capture through a novel metric. Finally, we demonstrate that hyper-parameter optimization and appropriate use of variational noise are sufficient to compensate for the quality impact of non-IID distributions, while decreasing the cost.
TasNet: Surpassing Ideal Time-Frequency Masking for Speech Separation
Sep 21, 2018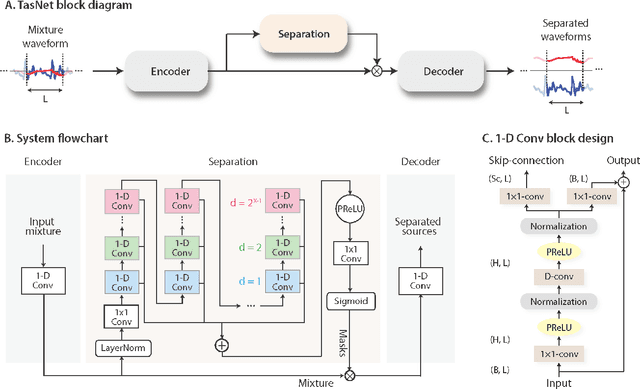
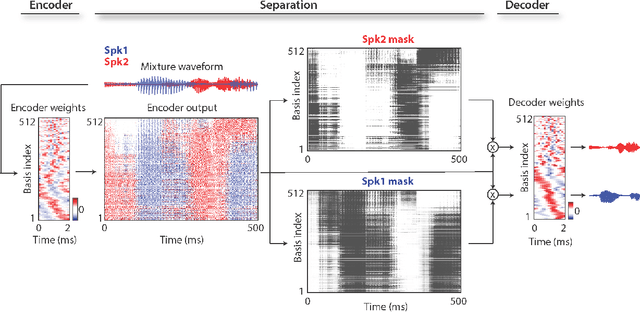
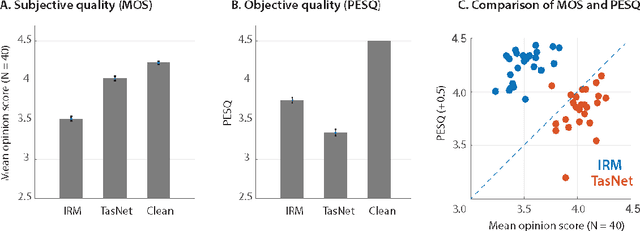
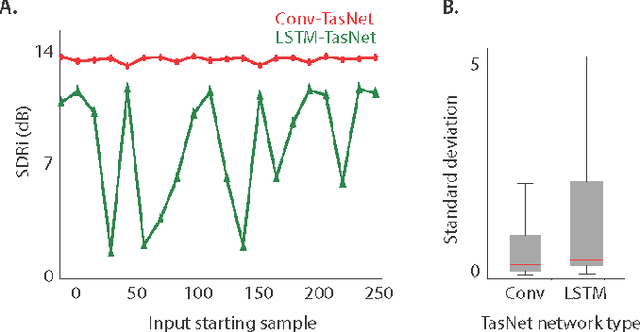
Robust speech processing in multitalker acoustic environments requires automatic speech separation. While single-channel, speaker-independent speech separation methods have recently seen great progress, the accuracy, latency, and computational cost of speech separation remain insufficient. The majority of the previous methods have formulated the separation problem through the time-frequency representation of the mixed signal, which has several drawbacks, including the decoupling of the phase and magnitude of the signal, the suboptimality of spectrogram representations for speech separation, and the long latency in calculating the spectrogram. To address these shortcomings, we propose the time-domain audio separation network (TasNet), which is a deep learning autoencoder framework for time-domain speech separation. TasNet uses a convolutional encoder to create a representation of the signal that is optimized for extracting individual speakers. Speaker extraction is achieved by applying a weighting function (mask) to the encoder output. The modified encoder representation is then inverted to the sound waveform using a linear decoder. The masks are found using a temporal convolutional network consisting of dilated convolutions, which allow the network to model the long-term dependencies of the speech signal. This end-to-end speech separation algorithm significantly outperforms previous time-frequency methods in terms of separating speakers in mixed audio, even when compared to the separation accuracy achieved with the ideal time-frequency mask of the speakers. In addition, TasNet has a smaller model size and a shorter minimum latency, making it a suitable solution for both offline and real-time speech separation applications. This study therefore represents a major step toward actualizing speech separation for real-world speech processing technologies.
Gradient-Adjusted Neuron Activation Profiles for Comprehensive Introspection of Convolutional Speech Recognition Models
Feb 19, 2020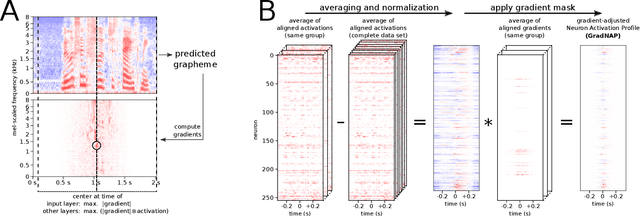
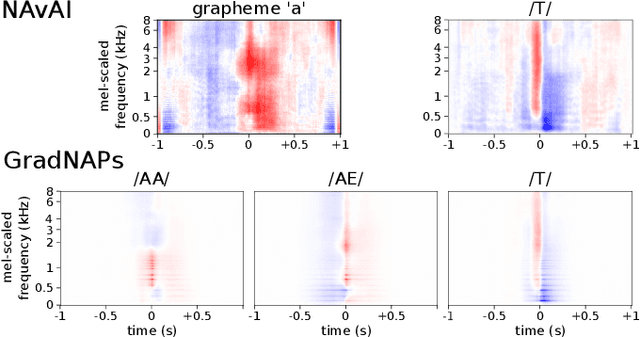
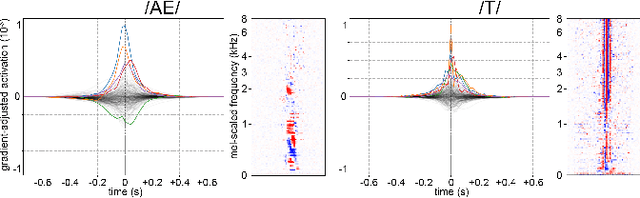
Deep Learning based Automatic Speech Recognition (ASR) models are very successful, but hard to interpret. To gain better understanding of how Artificial Neural Networks (ANNs) accomplish their tasks, introspection methods have been proposed. Adapting such techniques from computer vision to speech recognition is not straight-forward, because speech data is more complex and less interpretable than image data. In this work, we introduce Gradient-adjusted Neuron Activation Profiles (GradNAPs) as means to interpret features and representations in Deep Neural Networks. GradNAPs are characteristic responses of ANNs to particular groups of inputs, which incorporate the relevance of neurons for prediction. We show how to utilize GradNAPs to gain insight about how data is processed in ANNs. This includes different ways of visualizing features and clustering of GradNAPs to compare embeddings of different groups of inputs in any layer of a given network. We demonstrate our proposed techniques using a fully-convolutional ASR model.
Improving Generalizability in Implicitly Abusive Language Detection with Concept Activation Vectors
Apr 05, 2022
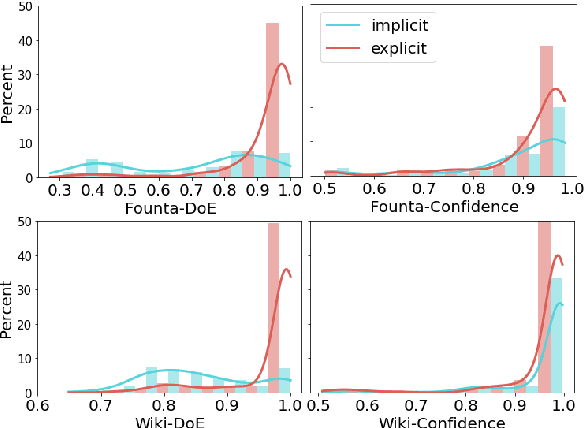
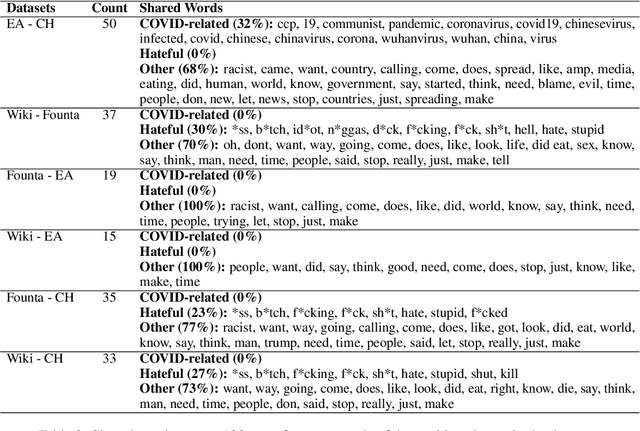
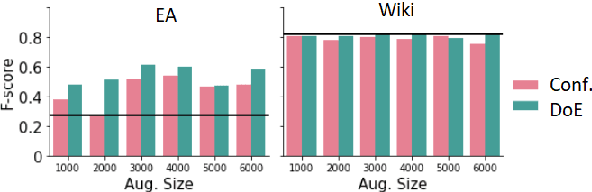
Robustness of machine learning models on ever-changing real-world data is critical, especially for applications affecting human well-being such as content moderation. New kinds of abusive language continually emerge in online discussions in response to current events (e.g., COVID-19), and the deployed abuse detection systems should be updated regularly to remain accurate. In this paper, we show that general abusive language classifiers tend to be fairly reliable in detecting out-of-domain explicitly abusive utterances but fail to detect new types of more subtle, implicit abuse. Next, we propose an interpretability technique, based on the Testing Concept Activation Vector (TCAV) method from computer vision, to quantify the sensitivity of a trained model to the human-defined concepts of explicit and implicit abusive language, and use that to explain the generalizability of the model on new data, in this case, COVID-related anti-Asian hate speech. Extending this technique, we introduce a novel metric, Degree of Explicitness, for a single instance and show that the new metric is beneficial in suggesting out-of-domain unlabeled examples to effectively enrich the training data with informative, implicitly abusive texts.
Phase-aware Speech Enhancement with Deep Complex U-Net
Apr 02, 2019
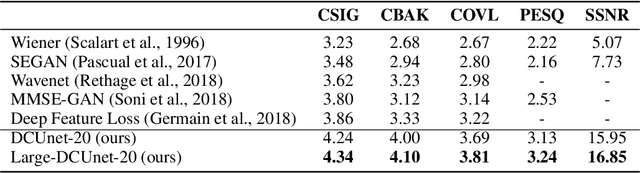

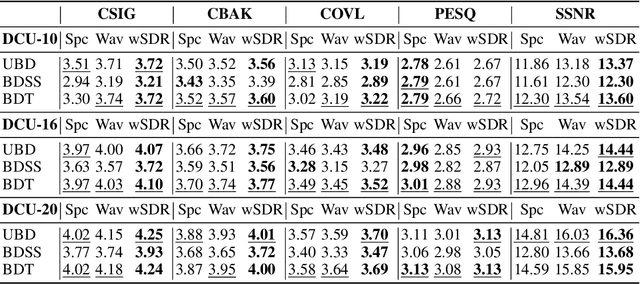
Most deep learning-based models for speech enhancement have mainly focused on estimating the magnitude of spectrogram while reusing the phase from noisy speech for reconstruction. This is due to the difficulty of estimating the phase of clean speech. To improve speech enhancement performance, we tackle the phase estimation problem in three ways. First, we propose Deep Complex U-Net, an advanced U-Net structured model incorporating well-defined complex-valued building blocks to deal with complex-valued spectrograms. Second, we propose a polar coordinate-wise complex-valued masking method to reflect the distribution of complex ideal ratio masks. Third, we define a novel loss function, weighted source-to-distortion ratio (wSDR) loss, which is designed to directly correlate with a quantitative evaluation measure. Our model was evaluated on a mixture of the Voice Bank corpus and DEMAND database, which has been widely used by many deep learning models for speech enhancement. Ablation experiments were conducted on the mixed dataset showing that all three proposed approaches are empirically valid. Experimental results show that the proposed method achieves state-of-the-art performance in all metrics, outperforming previous approaches by a large margin.
GraphTTS: graph-to-sequence modelling in neural text-to-speech
Mar 04, 2020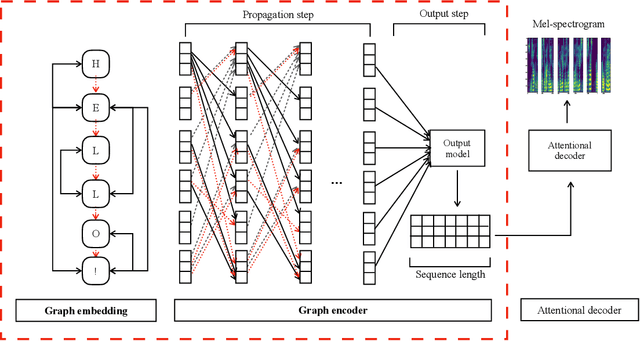

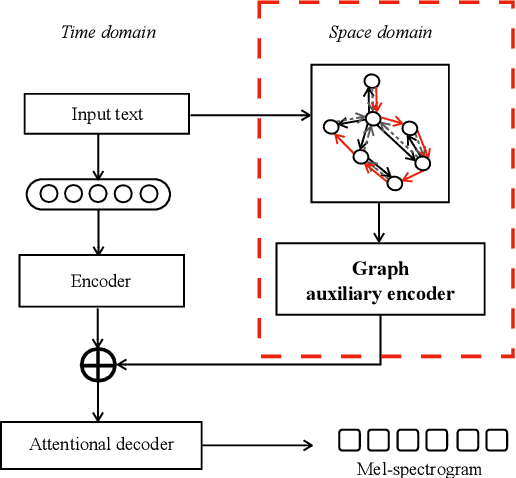
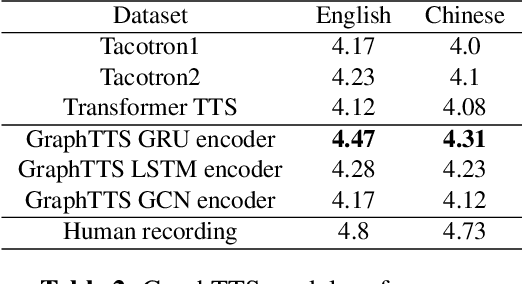
This paper leverages the graph-to-sequence method in neural text-to-speech (GraphTTS), which maps the graph embedding of the input sequence to spectrograms. The graphical inputs consist of node and edge representations constructed from input texts. The encoding of these graphical inputs incorporates syntax information by a GNN encoder module. Besides, applying the encoder of GraphTTS as a graph auxiliary encoder (GAE) can analyse prosody information from the semantic structure of texts. This can remove the manual selection of reference audios process and makes prosody modelling an end-to-end procedure. Experimental analysis shows that GraphTTS outperforms the state-of-the-art sequence-to-sequence models by 0.24 in Mean Opinion Score (MOS). GAE can adjust the pause, ventilation and tones of synthesised audios automatically. This experimental conclusion may give some inspiration to researchers working on improving speech synthesis prosody.
BUT Opensat 2019 Speech Recognition System
Jan 30, 2020


The paper describes the BUT Automatic Speech Recognition (ASR) systems submitted for OpenSAT evaluations under two domain categories such as low resourced languages and public safety communications. The first was challenging due to lack of training data, therefore various architectures and multilingual approaches were employed. The combination led to superior performance. The second domain was challenging due to recording in extreme conditions such as specific channel, speaker under stress and high levels of noise. Data augmentation process was inevitable to get reasonably good performance.
Noisy-to-Noisy Voice Conversion Framework with Denoising Model
Sep 22, 2021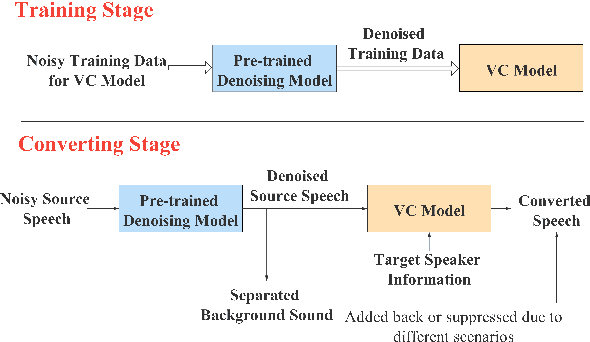
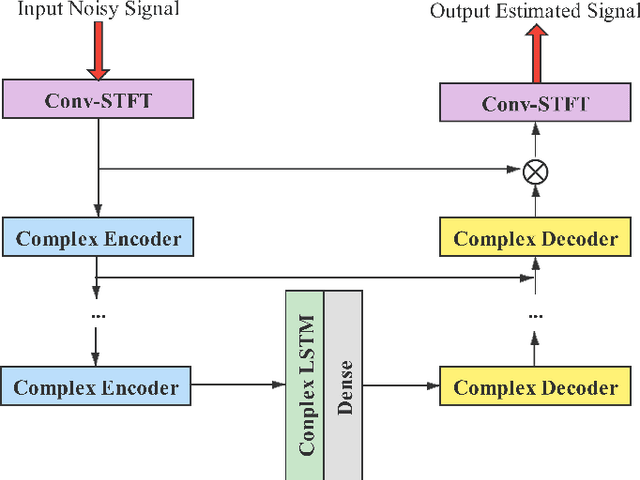
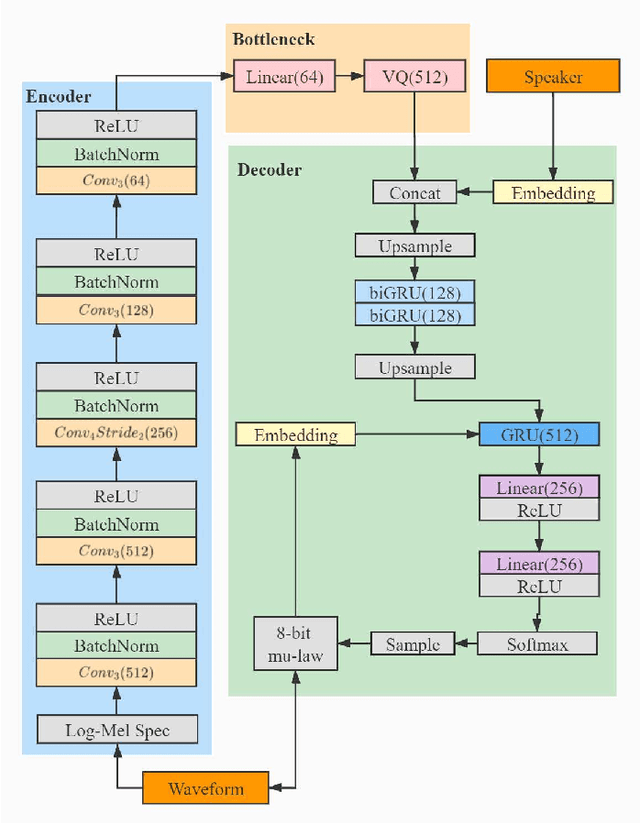
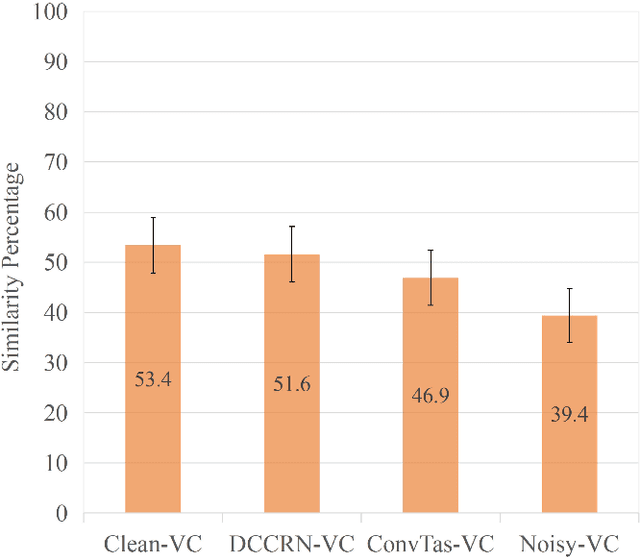
In a conventional voice conversion (VC) framework, a VC model is often trained with a clean dataset consisting of speech data carefully recorded and selected by minimizing background interference. However, collecting such a high-quality dataset is expensive and time-consuming. Leveraging crowd-sourced speech data in training is more economical. Moreover, for some real-world VC scenarios such as VC in video and VC-based data augmentation for speech recognition systems, the background sounds themselves are also informative and need to be maintained. In this paper, to explore VC with the flexibility of handling background sounds, we propose a noisy-to-noisy (N2N) VC framework composed of a denoising module and a VC module. With the proposed framework, we can convert the speaker's identity while preserving the background sounds. Both objective and subjective evaluations are conducted, and the results reveal the effectiveness of the proposed framework.
Investigating the Lombard Effect Influence on End-to-End Audio-Visual Speech Recognition
Jun 05, 2019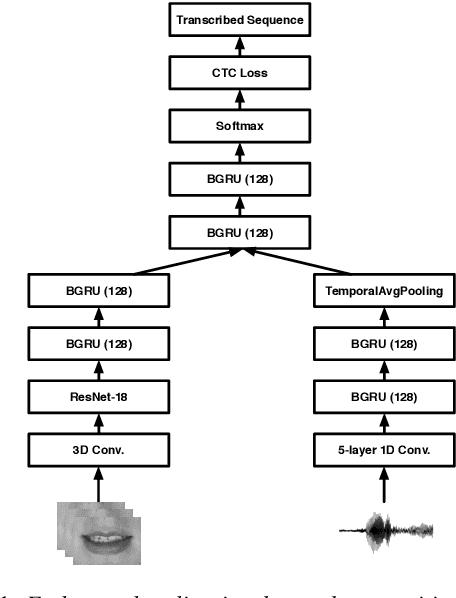

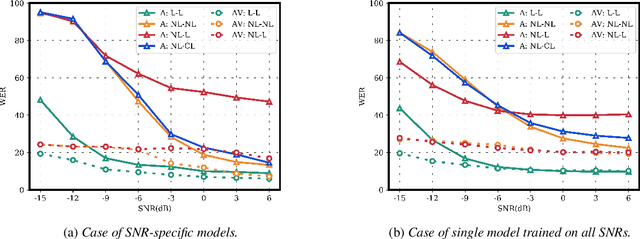
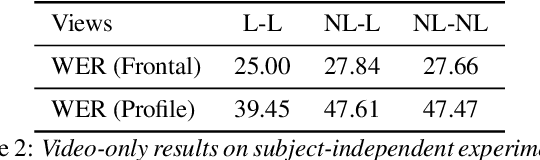
Several audio-visual speech recognition models have been recently proposed which aim to improve the robustness over audio-only models in the present of noise. However, almost all of them ignore the impact of the Lombard effect, i.e., the change in speaking style in noisy environments which aims to make speech more intelligible and affects both the acoustic characteristics of speech and the lip movements. In this paper, we investigate the impact of the Lombard effect in audio-visual speech recognition. To the best of our knowledge, this is the first work which does so using end-to-end deep architectures and presents results on unseen speakers. Our results show that properly modelling Lombard speech is always beneficial. Even if a relatively small amount of Lombard speech is added to the training set then the performance in a real scenario, where noisy Lombard speech is present, can be significantly improved. We also show that the standard approach followed in the literature, where a model is trained and tested on noisy plain speech, provides a correct estimate of the video-only performance and slightly underestimates the audio-visual performance. In case of audio-only approaches, performance is overestimated for SNRs higher than -3dB and underestimated for lower SNRs.