 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
End-to-End Multi-Channel Speech Separation
May 15, 2019

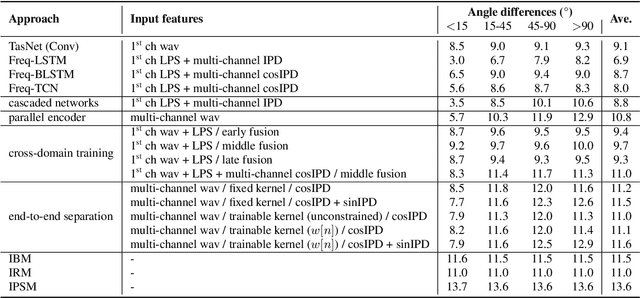
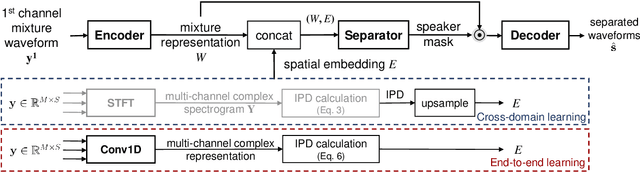

The end-to-end approach for single-channel speech separation has been studied recently and shown promising results. This paper extended the previous approach and proposed a new end-to-end model for multi-channel speech separation. The primary contributions of this work include 1) an integrated waveform-in waveform-out separation system in a single neural network architecture. 2) We reformulate the traditional short time Fourier transform (STFT) and inter-channel phase difference (IPD) as a function of time-domain convolution with a special kernel. 3) We further relaxed those fixed kernels to be learnable, so that the entire architecture becomes purely data-driven and can be trained from end-to-end. We demonstrate on the WSJ0 far-field speech separation task that, with the benefit of learnable spatial features, our proposed end-to-end multi-channel model significantly improved the performance of previous end-to-end single-channel method and traditional multi-channel methods.
Attention-Free Keyword Spotting
Oct 18, 2021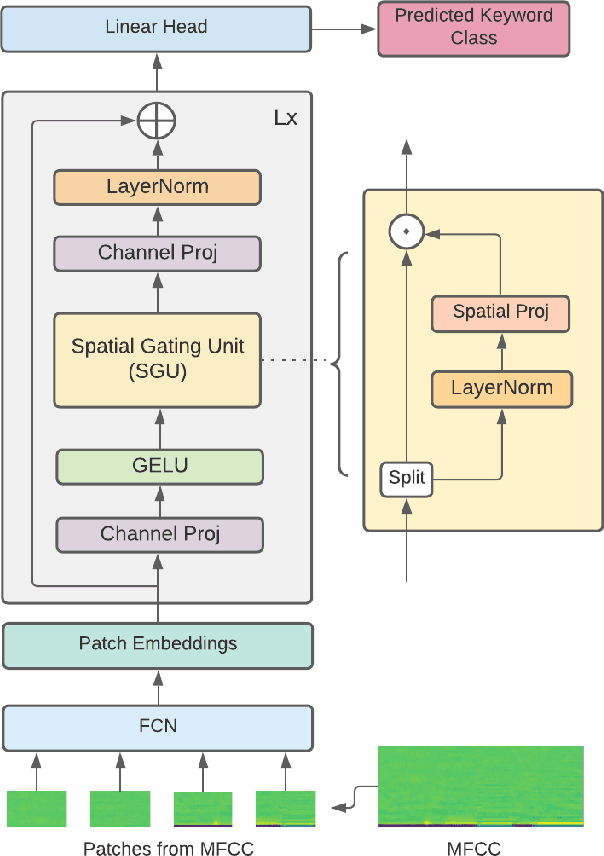
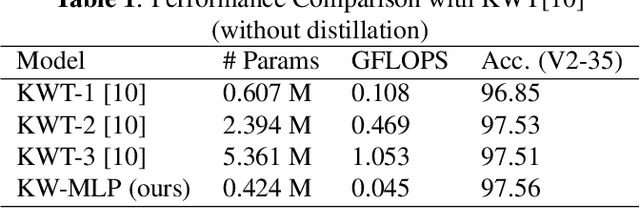
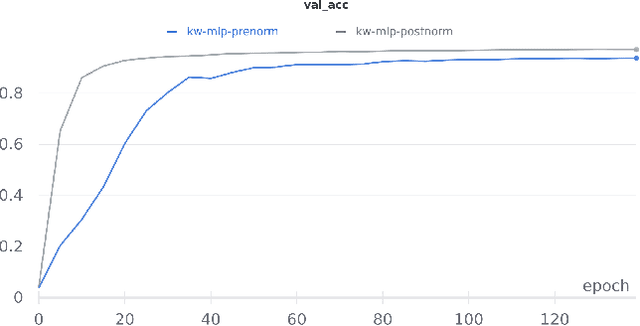
Till now, attention-based models have been used with great success in the keyword spotting problem domain. However, in light of recent advances in deep learning, the question arises whether self-attention is truly irreplaceable for recognizing speech keywords. We thus explore the usage of gated MLPs -- previously shown to be alternatives to transformers in vision tasks -- for the keyword spotting task. We verify our approach on the Google Speech Commands V2-35 dataset and show that it is possible to obtain performance comparable to the state of the art without any apparent usage of self-attention.
ShEMO -- A Large-Scale Validated Database for Persian Speech Emotion Detection
Jun 11, 2019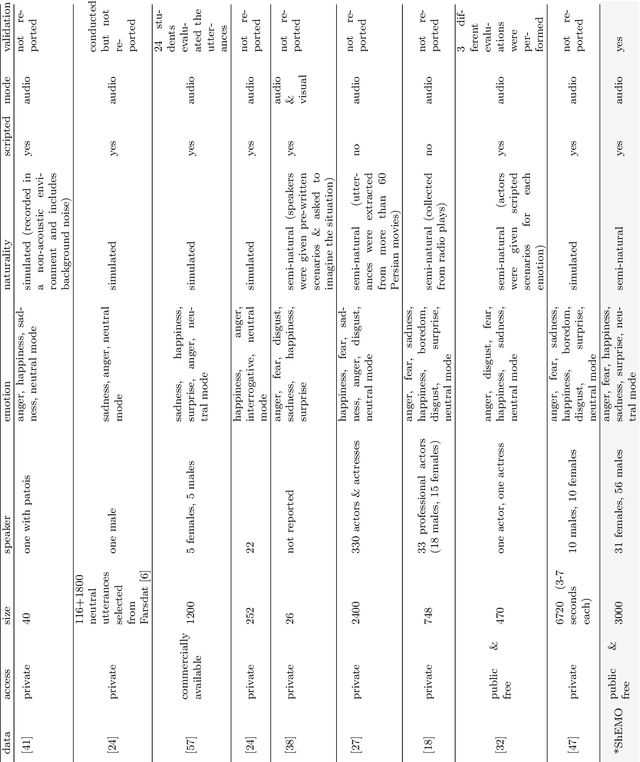
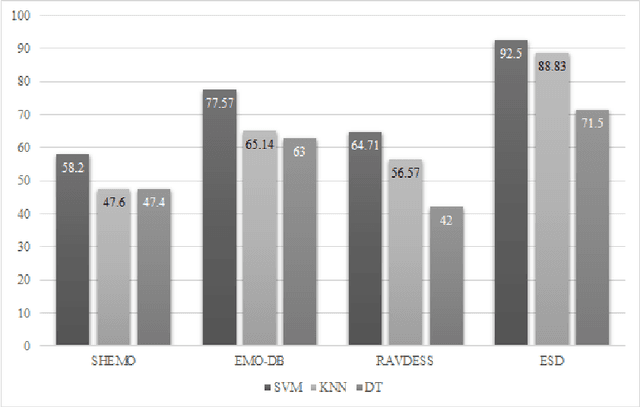

This paper introduces a large-scale, validated database for Persian called Sharif Emotional Speech Database (ShEMO). The database includes 3000 semi-natural utterances, equivalent to 3 hours and 25 minutes of speech data extracted from online radio plays. The ShEMO covers speech samples of 87 native-Persian speakers for five basic emotions including anger, fear, happiness, sadness and surprise, as well as neutral state. Twelve annotators label the underlying emotional state of utterances and majority voting is used to decide on the final labels. According to the kappa measure, the inter-annotator agreement is 64% which is interpreted as "substantial agreement". We also present benchmark results based on common classification methods in speech emotion detection task. According to the experiments, support vector machine achieves the best results for both gender-independent (58.2%) and gender-dependent models (female=59.4%, male=57.6%). The ShEMO is available for academic purposes free of charge to provide a baseline for further research on Persian emotional speech.
Universal adversarial examples in speech command classification
Nov 22, 2019
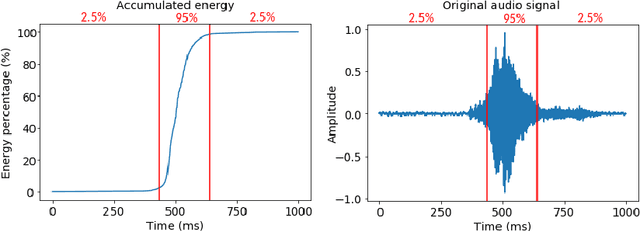
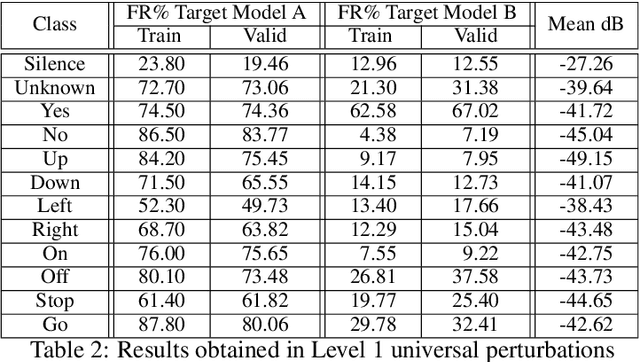
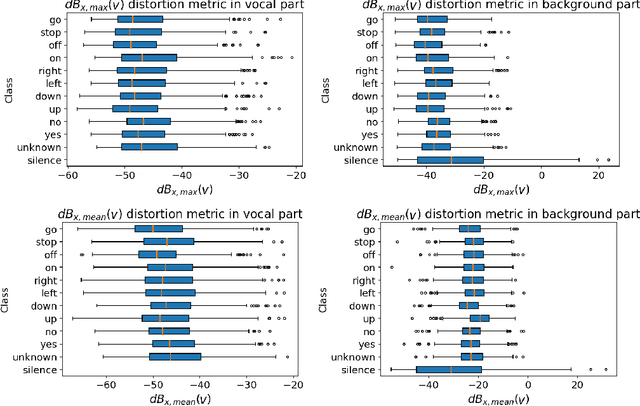
Adversarial examples are inputs intentionally perturbed with the aim of forcing a machine learning model to produce a wrong prediction, while the changes are not easily detectable by a human. Although this topic has been intensively studied in the image domain, classification tasks in the audio domain have received less attention. In this paper we address the existence of universal perturbations for speech command classification. We provide evidence that universal attacks can be generated for speech command classification tasks, which are able to generalize across different models to a significant extent. Additionally, a novel analytical framework is proposed for the evaluation of universal perturbations under different levels of universality, demonstrating that the feasibility of generating effective perturbations decreases as the universality level increases. Finally, we propose a more detailed and rigorous framework to measure the amount of distortion introduced by the perturbations, demonstrating that the methods employed by convention are not realistic in audio-based problems.
Multi-layer Attention Mechanism for Speech Keyword Recognition
Jul 10, 2019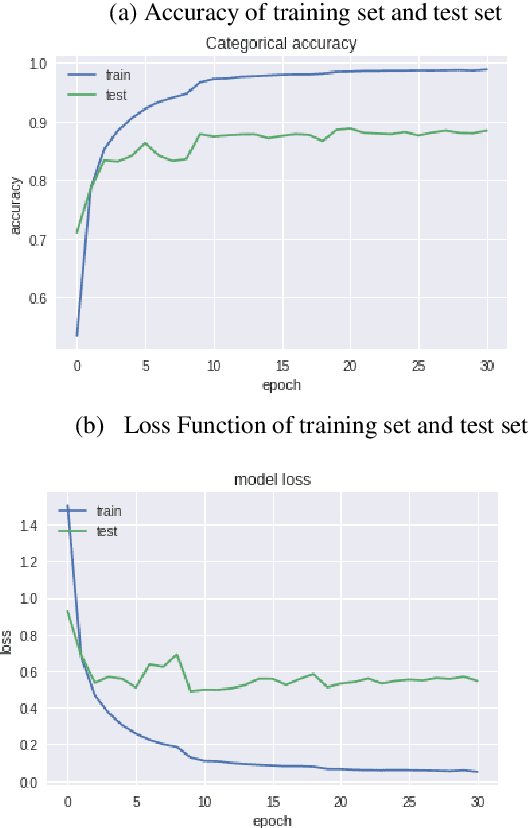
As an important part of speech recognition technology, automatic speech keyword recognition has been intensively studied in recent years. Such technology becomes especially pivotal under situations with limited infrastructures and computational resources, such as voice command recognition in vehicles and robot interaction. At present, the mainstream methods in automatic speech keyword recognition are based on long short-term memory (LSTM) networks with attention mechanism. However, due to inevitable information losses for the LSTM layer caused during feature extraction, the calculated attention weights are biased. In this paper, a novel approach, namely Multi-layer Attention Mechanism, is proposed to handle the inaccurate attention weights problem. The key idea is that, in addition to the conventional attention mechanism, information of layers prior to feature extraction and LSTM are introduced into attention weights calculations. Therefore, the attention weights are more accurate because the overall model can have more precise and focused areas. We conduct a comprehensive comparison and analysis on the keyword spotting performances on convolution neural network, bi-directional LSTM cyclic neural network, and cyclic neural network with the proposed attention mechanism on Google Speech Command datasets V2 datasets. Experimental results indicate favorable results for the proposed method and demonstrate the validity of the proposed method. The proposed multi-layer attention methods can be useful for other researches related to object spotting.
SPEAK YOUR MIND! Towards Imagined Speech Recognition With Hierarchical Deep Learning
Apr 08, 2019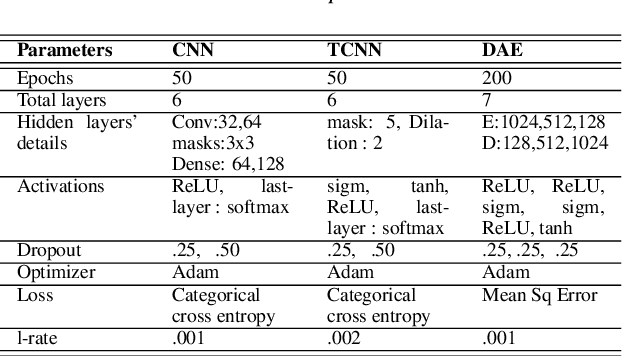
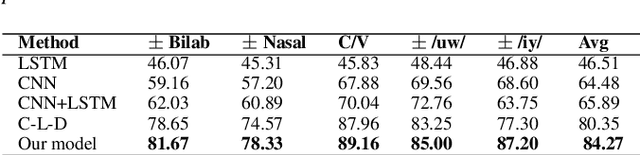
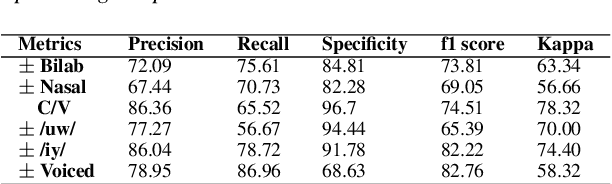
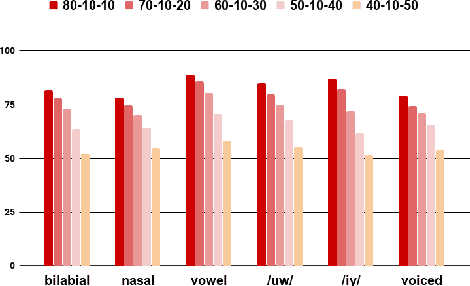
Speech-related Brain Computer Interface (BCI) technologies provide effective vocal communication strategies for controlling devices through speech commands interpreted from brain signals. In order to infer imagined speech from active thoughts, we propose a novel hierarchical deep learning BCI system for subject-independent classification of 11 speech tokens including phonemes and words. Our novel approach exploits predicted articulatory information of six phonological categories (e.g., nasal, bilabial) as an intermediate step for classifying the phonemes and words, thereby finding discriminative signal responsible for natural speech synthesis. The proposed network is composed of hierarchical combination of spatial and temporal CNN cascaded with a deep autoencoder. Our best models on the KARA database achieve an average accuracy of 83.42% across the six different binary phonological classification tasks, and 53.36% for the individual token identification task, significantly outperforming our baselines. Ultimately, our work suggests the possible existence of a brain imagery footprint for the underlying articulatory movement related to different sounds that can be used to aid imagined speech decoding.
How Familiar Does That Sound? Cross-Lingual Representational Similarity Analysis of Acoustic Word Embeddings
Sep 21, 2021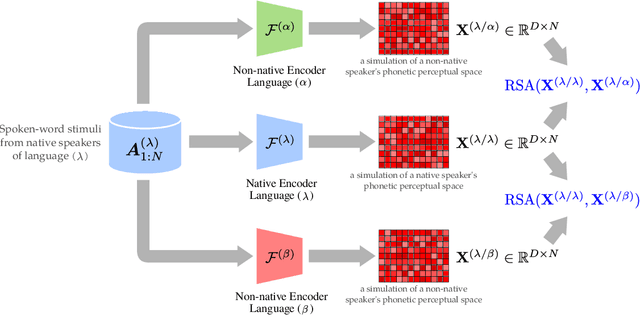
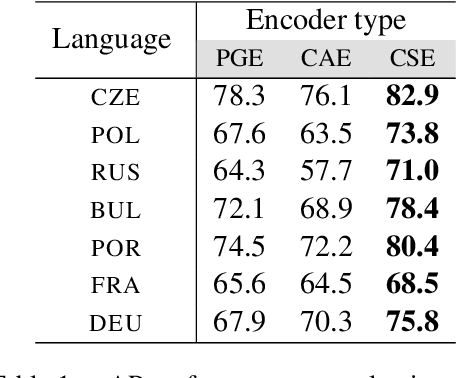
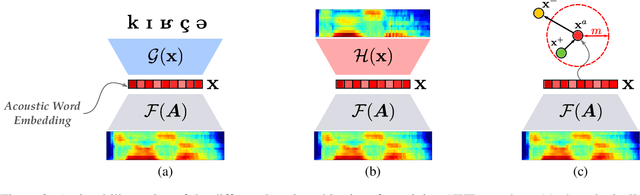
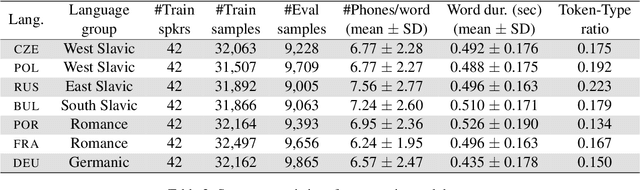
How do neural networks "perceive" speech sounds from unknown languages? Does the typological similarity between the model's training language (L1) and an unknown language (L2) have an impact on the model representations of L2 speech signals? To answer these questions, we present a novel experimental design based on representational similarity analysis (RSA) to analyze acoustic word embeddings (AWEs) -- vector representations of variable-duration spoken-word segments. First, we train monolingual AWE models on seven Indo-European languages with various degrees of typological similarity. We then employ RSA to quantify the cross-lingual similarity by simulating native and non-native spoken-word processing using AWEs. Our experiments show that typological similarity indeed affects the representational similarity of the models in our study. We further discuss the implications of our work on modeling speech processing and language similarity with neural networks.
Enable Deep Learning on Mobile Devices: Methods, Systems, and Applications
Apr 25, 2022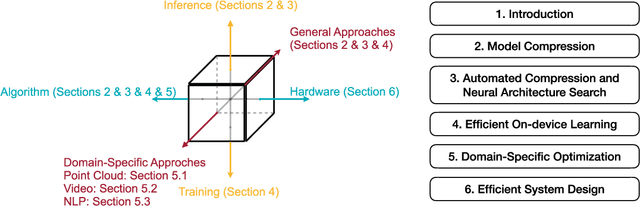
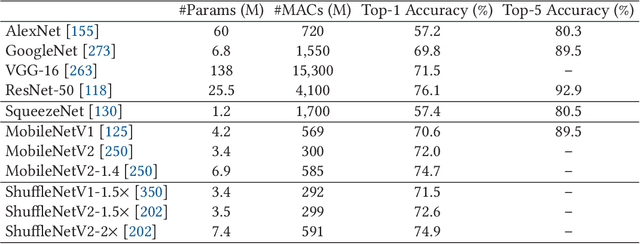
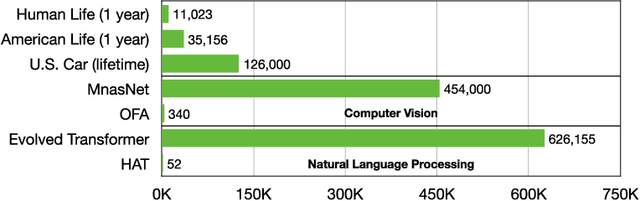
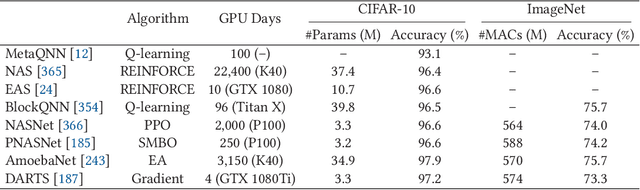
Deep neural networks (DNNs) have achieved unprecedented success in the field of artificial intelligence (AI), including computer vision, natural language processing and speech recognition. However, their superior performance comes at the considerable cost of computational complexity, which greatly hinders their applications in many resource-constrained devices, such as mobile phones and Internet of Things (IoT) devices. Therefore, methods and techniques that are able to lift the efficiency bottleneck while preserving the high accuracy of DNNs are in great demand in order to enable numerous edge AI applications. This paper provides an overview of efficient deep learning methods, systems and applications. We start from introducing popular model compression methods, including pruning, factorization, quantization as well as compact model design. To reduce the large design cost of these manual solutions, we discuss the AutoML framework for each of them, such as neural architecture search (NAS) and automated pruning and quantization. We then cover efficient on-device training to enable user customization based on the local data on mobile devices. Apart from general acceleration techniques, we also showcase several task-specific accelerations for point cloud, video and natural language processing by exploiting their spatial sparsity and temporal/token redundancy. Finally, to support all these algorithmic advancements, we introduce the efficient deep learning system design from both software and hardware perspectives.
* Journal preprint (ACM TODAES, 2021). The first seven authors contributed equally to this work and are listed in the alphabetical order
Personalization of End-to-end Speech Recognition On Mobile Devices For Named Entities
Dec 14, 2019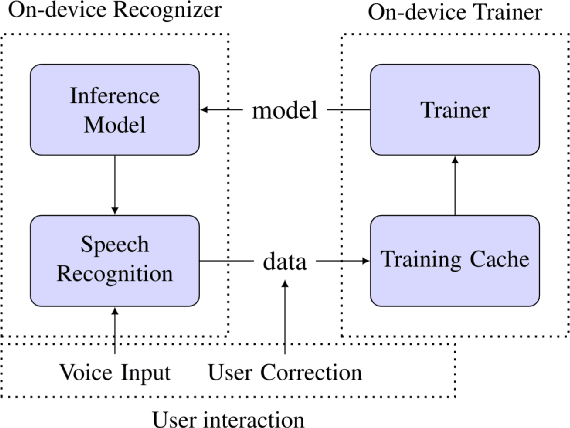
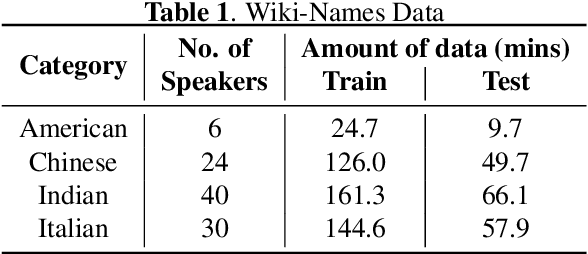
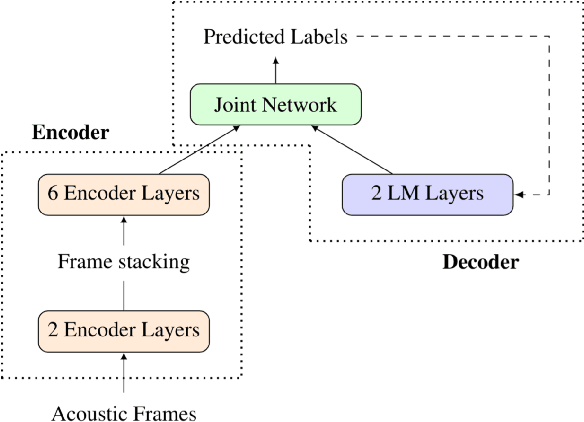
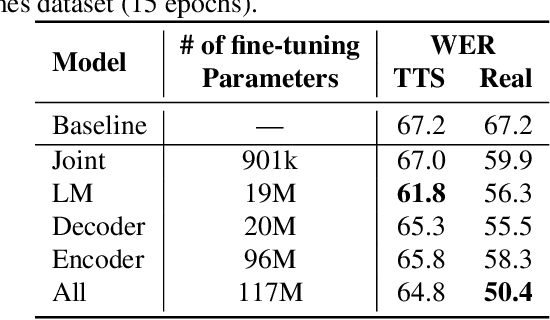
We study the effectiveness of several techniques to personalize end-to-end speech models and improve the recognition of proper names relevant to the user. These techniques differ in the amounts of user effort required to provide supervision, and are evaluated on how they impact speech recognition performance. We propose using keyword-dependent precision and recall metrics to measure vocabulary acquisition performance. We evaluate the algorithms on a dataset that we designed to contain names of persons that are difficult to recognize. Therefore, the baseline recall rate for proper names in this dataset is very low: 2.4%. A data synthesis approach we developed brings it to 48.6%, with no need for speech input from the user. With speech input, if the user corrects only the names, the name recall rate improves to 64.4%. If the user corrects all the recognition errors, we achieve the best recall of 73.5%. To eliminate the need to upload user data and store personalized models on a server, we focus on performing the entire personalization workflow on a mobile device.
Signal in Noise: Exploring Meaning Encoded in Random Character Sequences with Character-Aware Language Models
Mar 15, 2022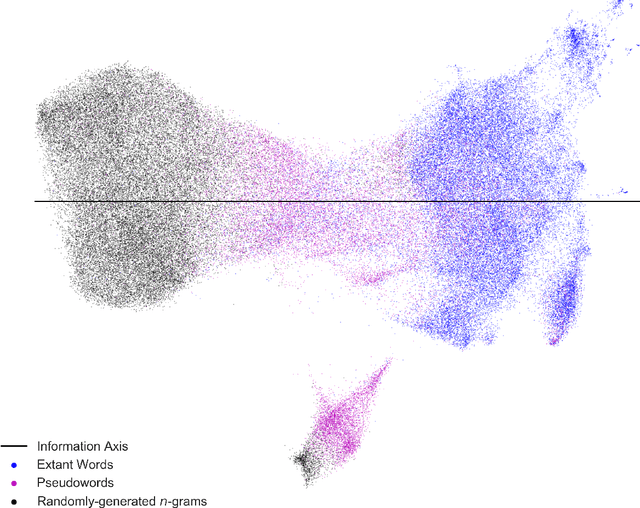

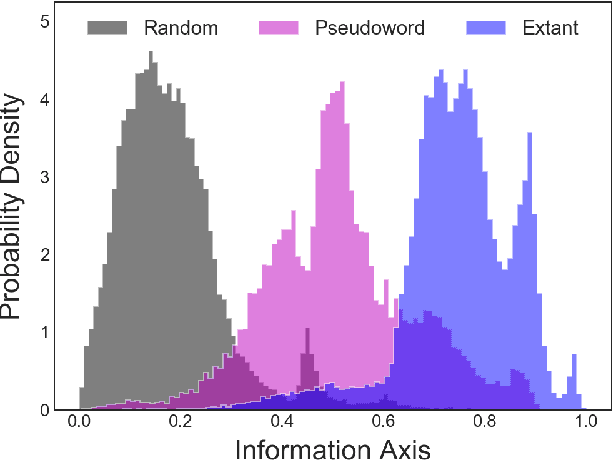
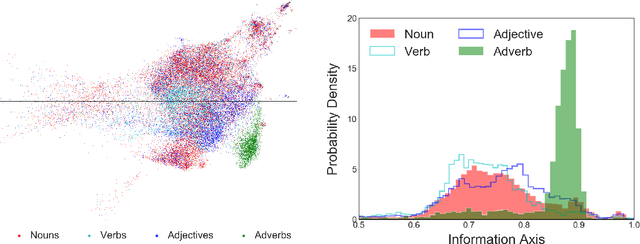
Natural language processing models learn word representations based on the distributional hypothesis, which asserts that word context (e.g., co-occurrence) correlates with meaning. We propose that $n$-grams composed of random character sequences, or $garble$, provide a novel context for studying word meaning both within and beyond extant language. In particular, randomly generated character $n$-grams lack meaning but contain primitive information based on the distribution of characters they contain. By studying the embeddings of a large corpus of garble, extant language, and pseudowords using CharacterBERT, we identify an axis in the model's high-dimensional embedding space that separates these classes of $n$-grams. Furthermore, we show that this axis relates to structure within extant language, including word part-of-speech, morphology, and concept concreteness. Thus, in contrast to studies that are mainly limited to extant language, our work reveals that meaning and primitive information are intrinsically linked.