 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
CSS10: A Collection of Single Speaker Speech Datasets for 10 Languages
Apr 03, 2019
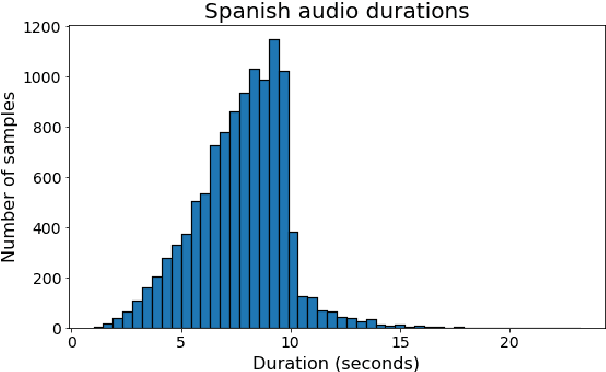


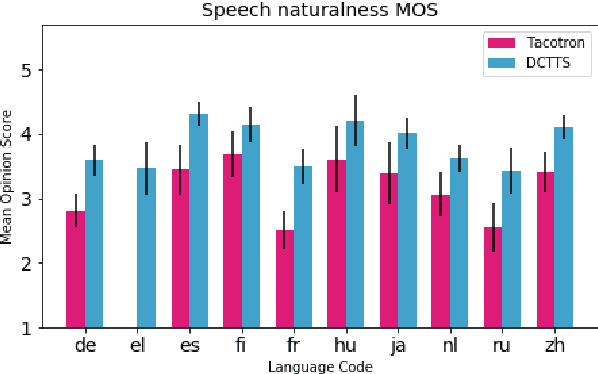
We describe our development of CSS10, a collection of single speaker speech datasets for ten languages. It is composed of short audio clips from LibriVox audiobooks and their aligned texts. To validate its quality we train two neural text-to-speech models on each dataset. Subsequently, we conduct Mean Opinion Score tests on the synthesized speech samples. We make our datasets, pre-trained models, and test resources publicly available. We hope they will be used for future speech tasks.
Universal adversarial examples in speech command classification
Nov 26, 2019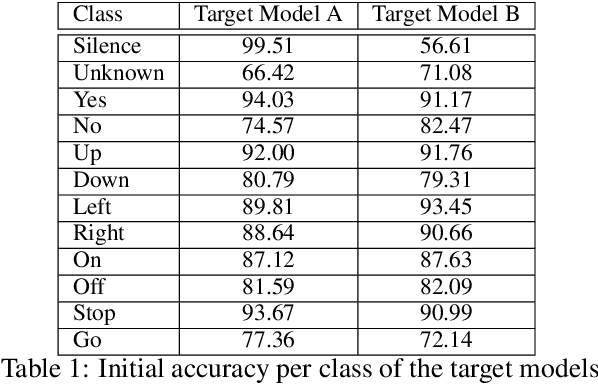
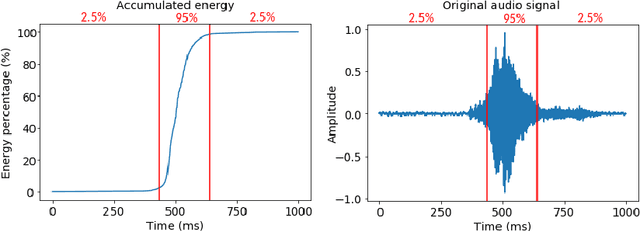
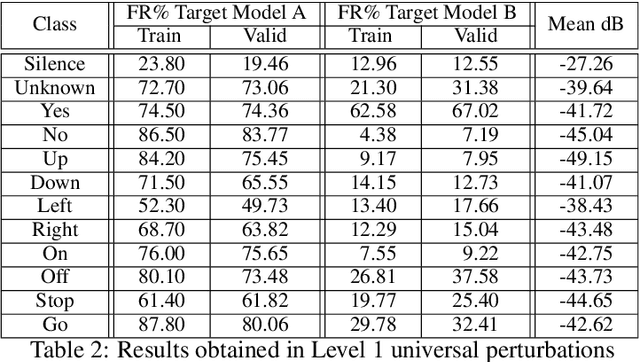
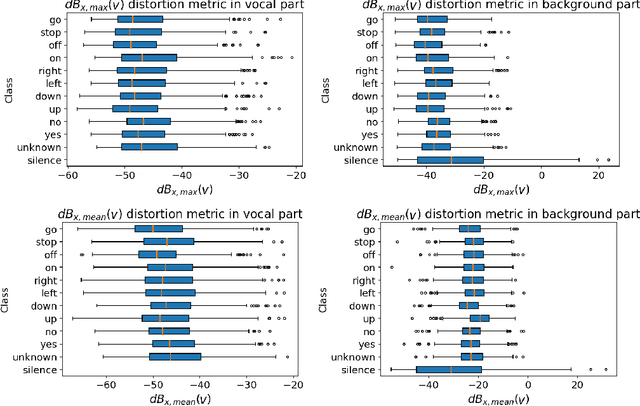
Adversarial examples are inputs intentionally perturbed with the aim of forcing a machine learning model to produce a wrong prediction, while the changes are not easily detectable by a human. Although this topic has been intensively studied in the image domain, classification tasks in the audio domain have received less attention. In this paper we address the existence of universal perturbations for speech command classification. We provide evidence that universal attacks can be generated for speech command classification tasks, which are able to generalize across different models to a significant extent. Additionally, a novel analytical framework is proposed for the evaluation of universal perturbations under different levels of universality, demonstrating that the feasibility of generating effective perturbations decreases as the universality level increases. Finally, we propose a more detailed and rigorous framework to measure the amount of distortion introduced by the perturbations, demonstrating that the methods employed by convention are not realistic in audio-based problems.
Self-training and Pre-training are Complementary for Speech Recognition
Oct 22, 2020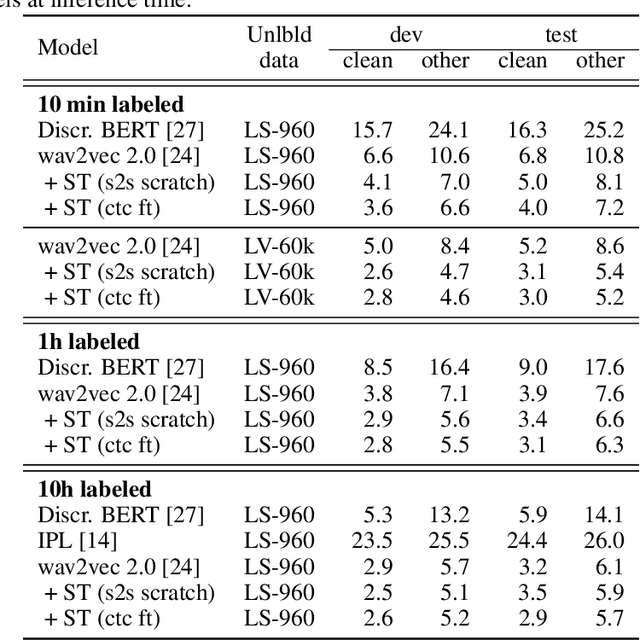
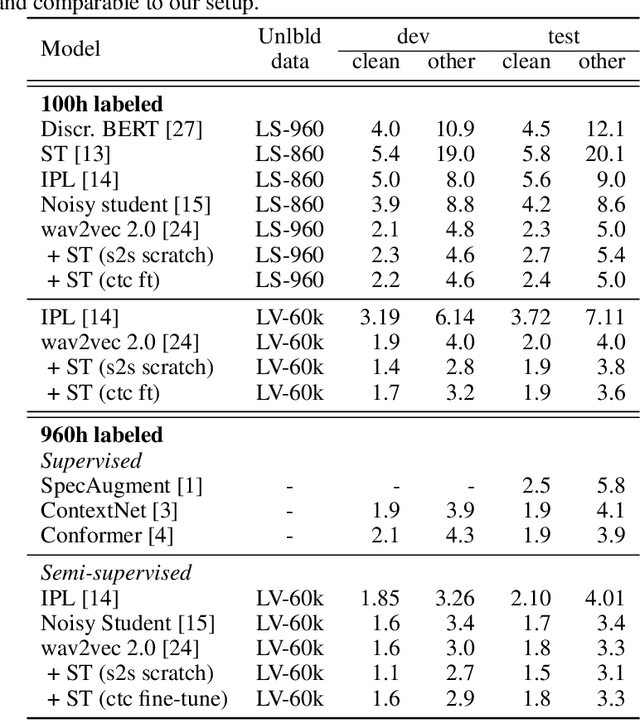
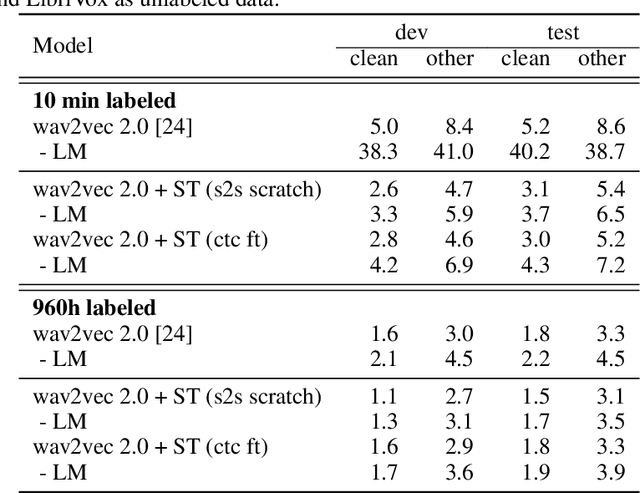
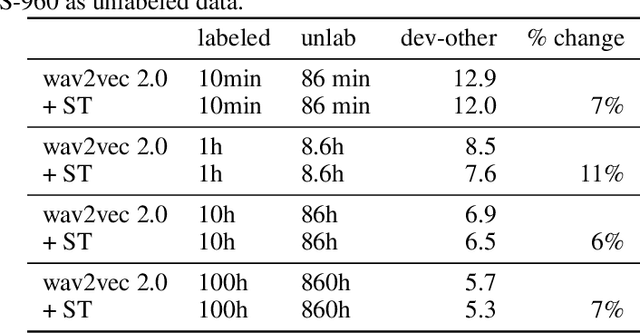
Self-training and unsupervised pre-training have emerged as effective approaches to improve speech recognition systems using unlabeled data. However, it is not clear whether they learn similar patterns or if they can be effectively combined. In this paper, we show that pseudo-labeling and pre-training with wav2vec 2.0 are complementary in a variety of labeled data setups. Using just 10 minutes of labeled data from Libri-light as well as 53k hours of unlabeled data from LibriVox achieves WERs of 3.0%/5.2% on the clean and other test sets of Librispeech - rivaling the best published systems trained on 960 hours of labeled data only a year ago. Training on all labeled data of Librispeech achieves WERs of 1.5%/3.1%.
FDN: Finite Difference Network with Hierachical Convolutional Features for Text-independent Speaker verification
Aug 18, 2021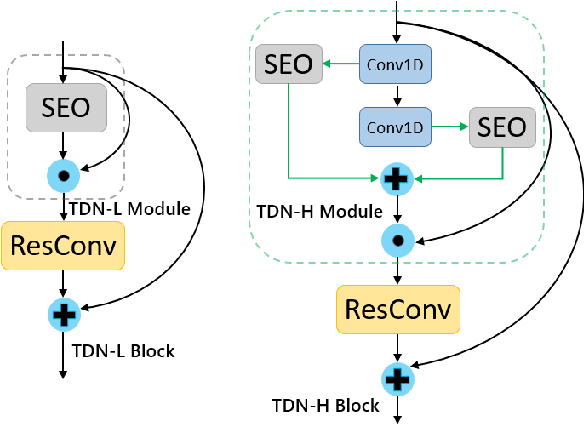
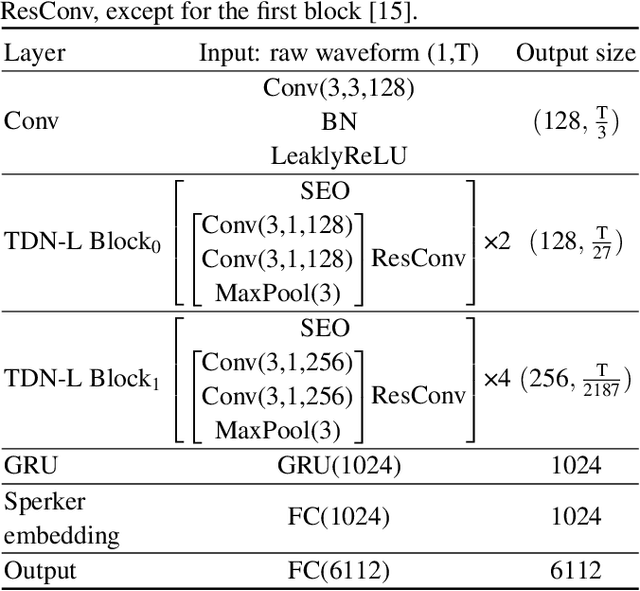
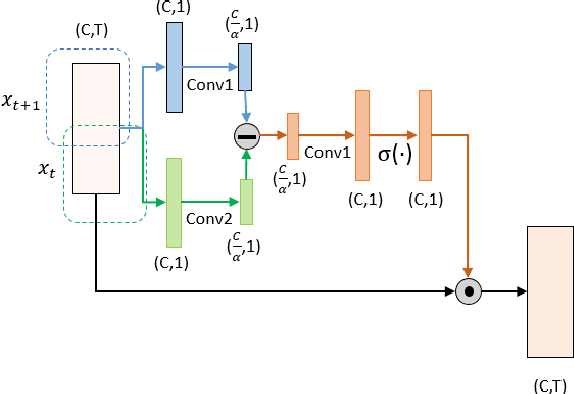
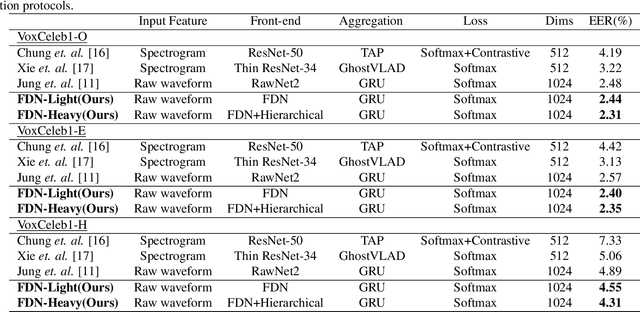
Recently, directly utilize raw waveforms as input is widely explored for the speaker verification system. For example, RawNet [1] and RawNet2 [2] extract feature embeddings from raw waveforms, which largely reduce the front-end computation and achieve state-of-the-art performance. However, they do not consider the speech speed influence which is different from person to person. In this paper, we propose a novel finite-difference network to obtain speaker embeddings. It incorporates speaker speech speed by computing the finite difference between adjacent time speech pieces. Furthermore, we design a hierarchical layer to capture multiscale speech speed features to improve the system accuracy. The speaker embeddings is then input into the GRU to aggregate utterance-level features before the softmax loss. Experiment results on official VoxCeleb1 test data and expanded evaluation on VoxCeleb1-E and VoxCeleb-H protocols show our method outperforms existing state-of-the-art systems. To facilitate further research, code is available at https://github.com/happyjin/FDN
Parameter Tuning of Time-Frequency Masking Algorithms for Reverberant Artifact Removal within the Cochlear Implant Stimulus
Aug 12, 2021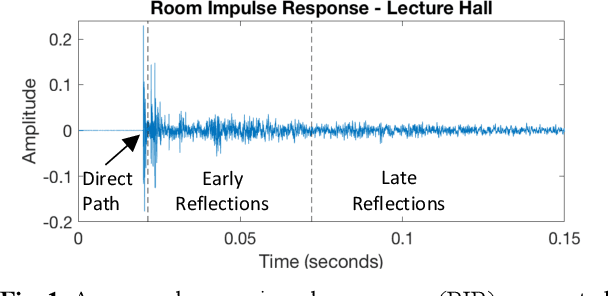
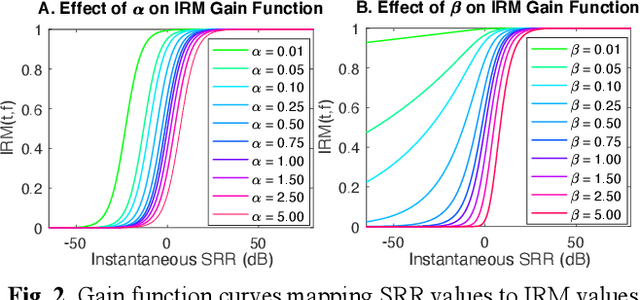
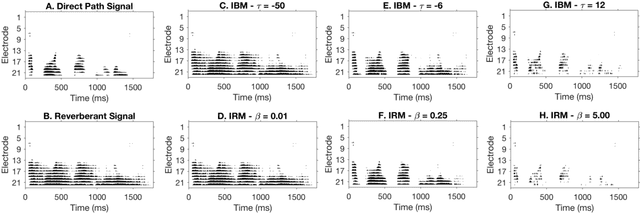
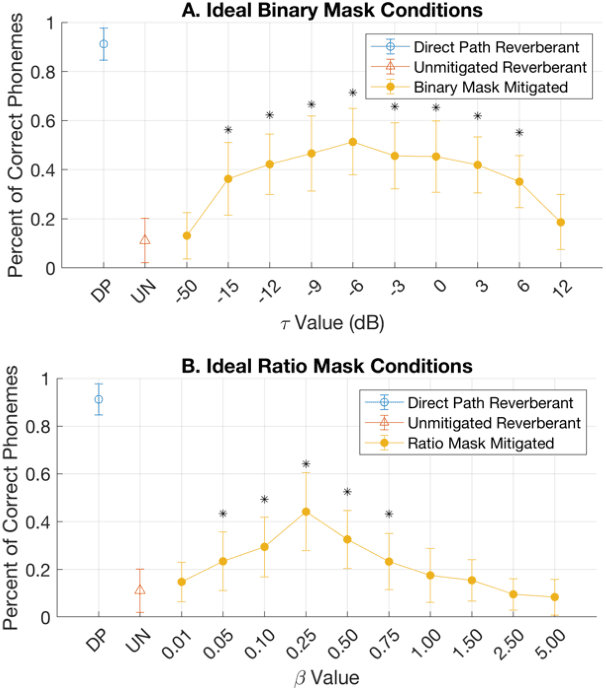
Cochlear implant users struggle to understand speech in reverberant environments. To restore speech perception, artifacts dominated by reverberant reflections can be removed from the cochlear implant stimulus. Artifacts can be identified and removed by applying a matrix of gain values, a technique referred to as time-frequency masking. Gain values are determined by an oracle algorithm that uses knowledge of the undistorted signal to minimize retention of the signal components dominated by reverberant reflections. In practice, gain values are estimated from the distorted signal, with the oracle algorithm providing the estimation objective. Different oracle techniques exist for determining gain values, and each technique must be parameterized to set the amount of signal retention. This work assesses which oracle masking strategies and parameterizations lead to the best improvements in speech intelligibility for cochlear implant users in reverberant conditions using online speech intelligibility testing of normal-hearing individuals with vocoding.
Incremental Text-to-Speech Synthesis with Prefix-to-Prefix Framework
Nov 07, 2019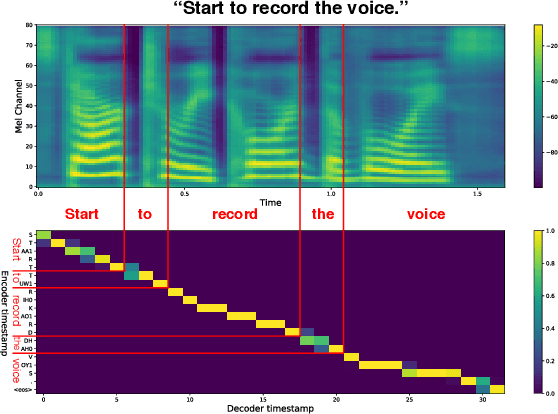
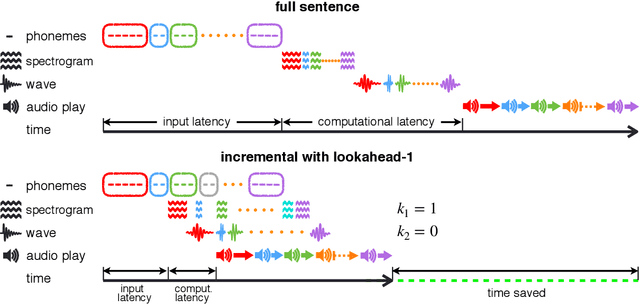
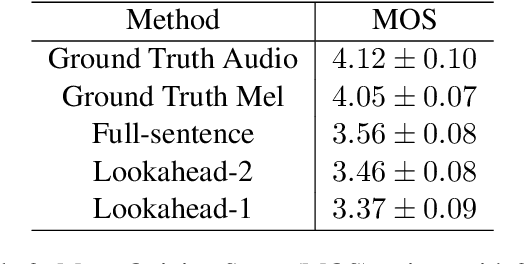
Text-to-speech synthesis (TTS) has witnessed rapid progress in recent years, where neural methods became capable of producing audio with near human-level naturalness. However, these efforts still suffer from two types of latencies: (a) the computational latency (synthesize time), which grows linearly with the sentence length even with parallel approaches, and (b) the input latency in scenarios where the input text is incrementally generated (such as in simultaneous translation, dialog generation, and assistive technologies). To reduce these latencies, we devise the first neural incremental TTS approach based on the recently proposed prefix-to-prefix framework. We synthesize speech in an online fashion, playing a segment of audio while generating the next, resulting in an O(1) rather than O(n) latency. Experiments on English TTS show that our approach achieves similar speech naturalness compared to full sentence methods, but only using a fraction of time and a constant (1 - 2 words) latency.
Deep Learning based Multi-Source Localization with Source Splitting and its Effectiveness in Multi-Talker Speech Recognition
Feb 16, 2021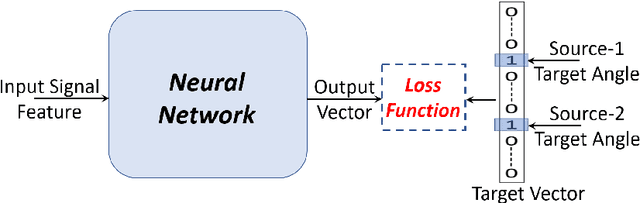
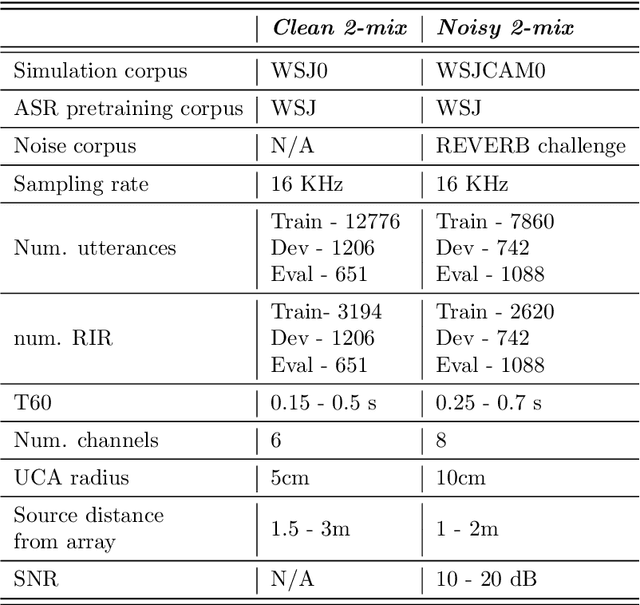
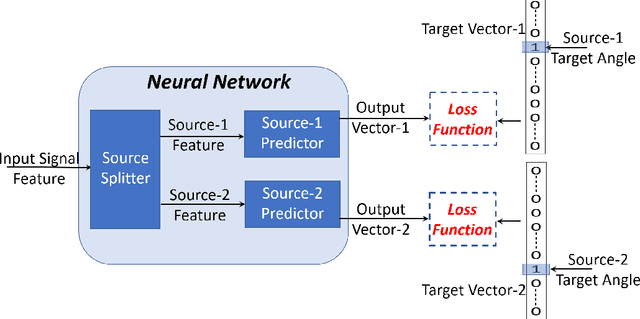
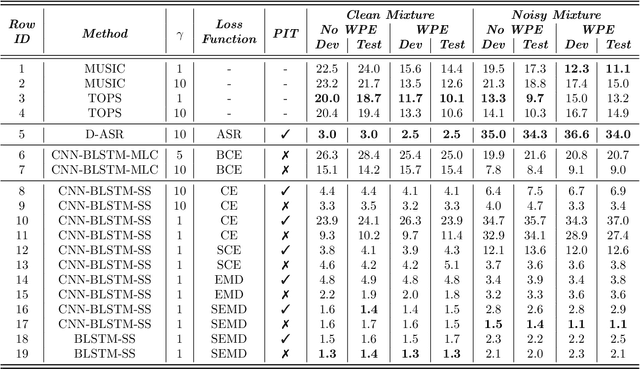
Multi-source localization is an important and challenging technique for multi-talker conversation analysis. This paper proposes a novel supervised learning method using deep neural networks to estimate the direction of arrival (DOA) of all the speakers simultaneously from the audio mixture. At the heart of the proposal is a source splitting mechanism that creates source-specific intermediate representations inside the network. This allows our model to give source-specific posteriors as the output unlike the traditional multi-label classification approach. Existing deep learning methods perform a frame level prediction, whereas our approach performs an utterance level prediction by incorporating temporal selection and averaging inside the network to avoid post-processing. We also experiment with various loss functions and show that a variant of earth mover distance (EMD) is very effective in classifying DOA at a very high resolution by modeling inter-class relationships. In addition to using the prediction error as a metric for evaluating our localization model, we also establish its potency as a frontend with automatic speech recognition (ASR) as the downstream task. We convert the estimated DOAs into a feature suitable for ASR and pass it as an additional input feature to a strong multi-channel and multi-talker speech recognition baseline. This added input feature drastically improves the ASR performance and gives a word error rate (WER) of 6.3% on the evaluation data of our simulated noisy two speaker mixtures, while the baseline which doesn't use explicit localization input has a WER of 11.5%. We also perform ASR evaluation on real recordings with the overlapped set of the MC-WSJ-AV corpus in addition to simulated mixtures.
Data Augmentation for End-to-end Code-switching Speech Recognition
Nov 04, 2020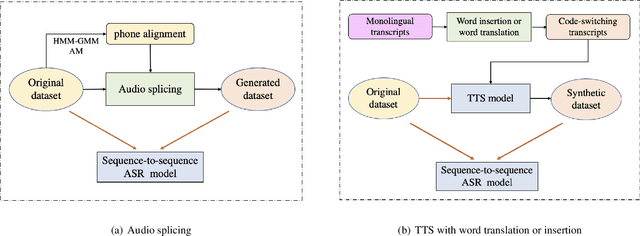
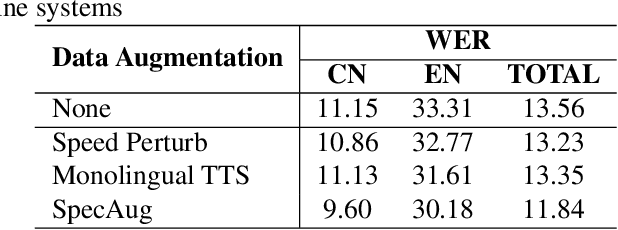
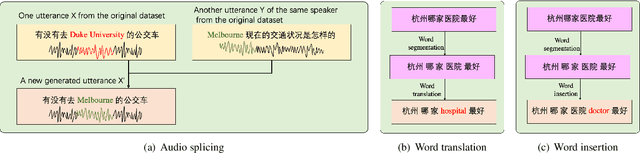
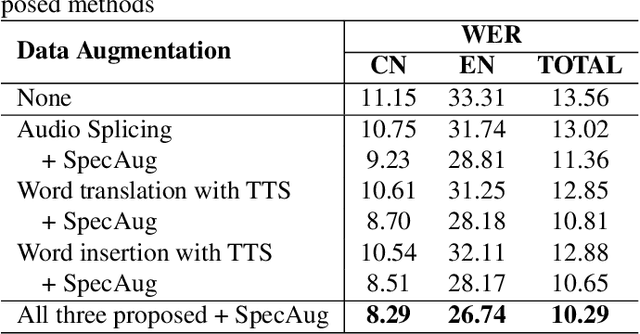
Training a code-switching end-to-end automatic speech recognition (ASR) model normally requires a large amount of data, while code-switching data is often limited. In this paper, three novel approaches are proposed for code-switching data augmentation. Specifically, they are audio splicing with the existing code-switching data, and TTS with new code-switching texts generated by word translation or word insertion. Our experiments on 200 hours Mandarin-English code-switching dataset show that all the three proposed approaches yield significant improvements on code-switching ASR individually. Moreover, all the proposed approaches can be combined with recent popular SpecAugment, and an addition gain can be obtained. WER is significantly reduced by relative 24.0% compared to the system without any data augmentation, and still relative 13.0% gain compared to the system with only SpecAugment
Noisy-to-Noisy Voice Conversion Framework with Denoising Model
Sep 22, 2021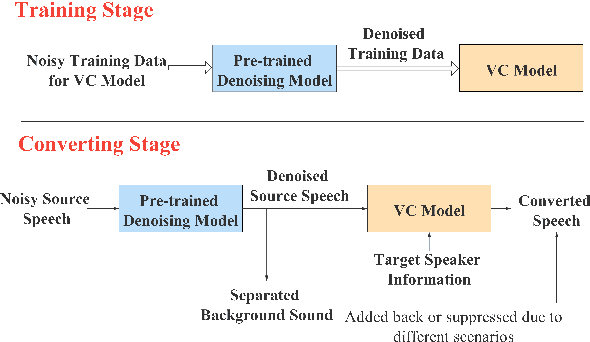
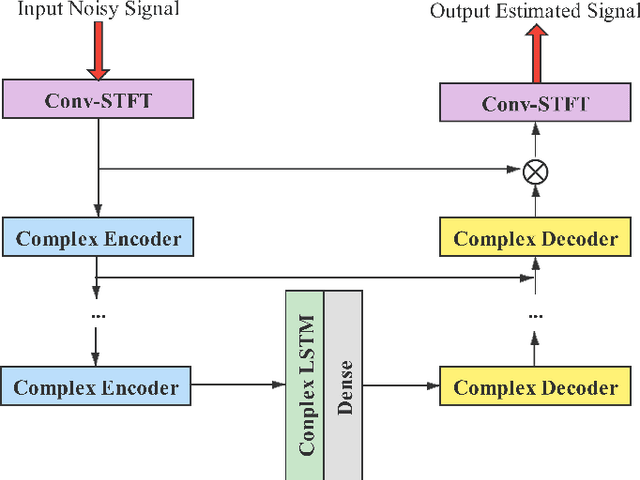
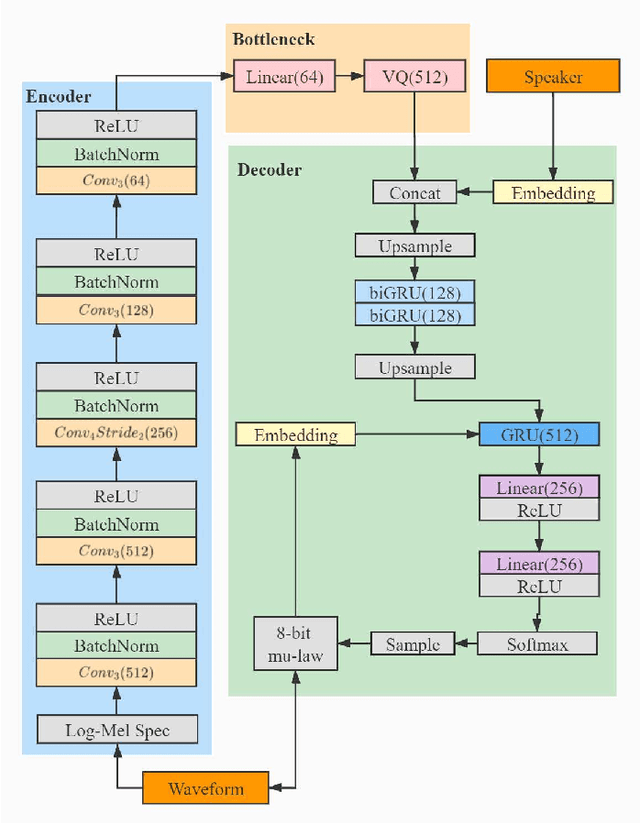
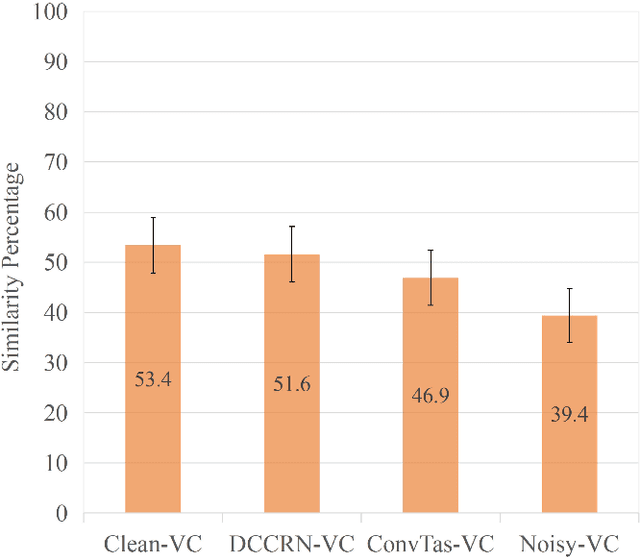
In a conventional voice conversion (VC) framework, a VC model is often trained with a clean dataset consisting of speech data carefully recorded and selected by minimizing background interference. However, collecting such a high-quality dataset is expensive and time-consuming. Leveraging crowd-sourced speech data in training is more economical. Moreover, for some real-world VC scenarios such as VC in video and VC-based data augmentation for speech recognition systems, the background sounds themselves are also informative and need to be maintained. In this paper, to explore VC with the flexibility of handling background sounds, we propose a noisy-to-noisy (N2N) VC framework composed of a denoising module and a VC module. With the proposed framework, we can convert the speaker's identity while preserving the background sounds. Both objective and subjective evaluations are conducted, and the results reveal the effectiveness of the proposed framework.
Towards Learning Universal Audio Representations
Nov 23, 2021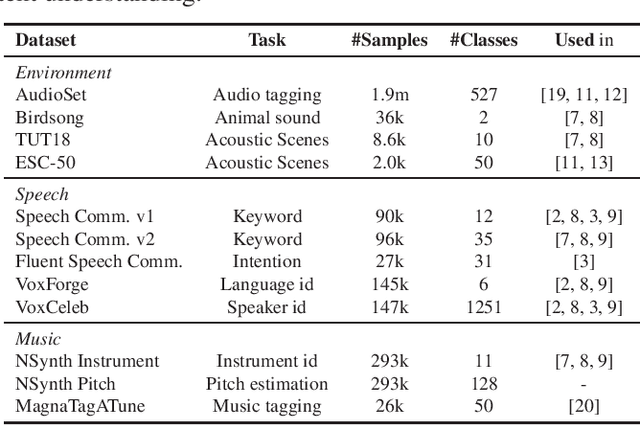
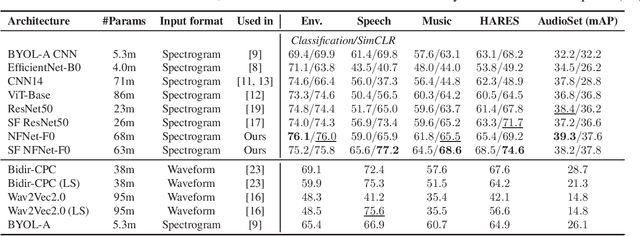
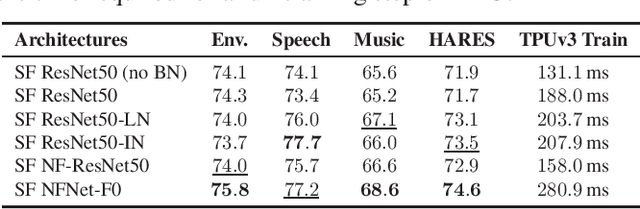
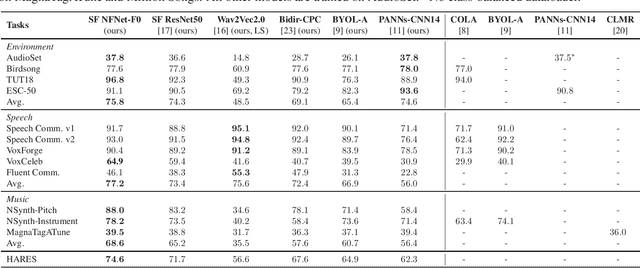
The ability to learn universal audio representations that can solve diverse speech, music, and environment tasks can spur many applications that require general sound content understanding. In this work, we introduce a holistic audio representation evaluation suite (HARES) spanning 12 downstream tasks across audio domains and provide a thorough empirical study of recent sound representation learning systems on that benchmark. We discover that previous sound event classification or speech models do not generalize outside of their domains. We observe that more robust audio representations can be learned with the SimCLR objective; however, the model's transferability depends heavily on the model architecture. We find the Slowfast architecture is good at learning rich representations required by different domains, but its performance is affected by the normalization scheme. Based on these findings, we propose a novel normalizer-free Slowfast NFNet and achieve state-of-the-art performance across all domains.