 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
How to Teach DNNs to Pay Attention to the Visual Modality in Speech Recognition
Apr 17, 2020
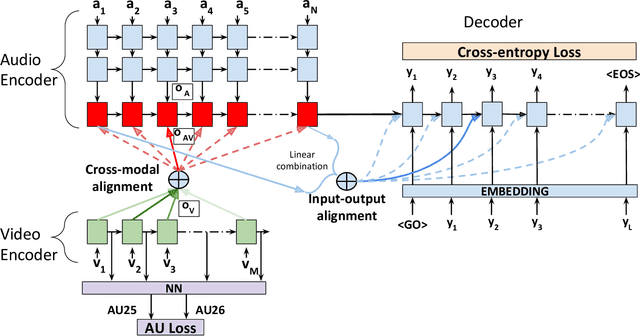
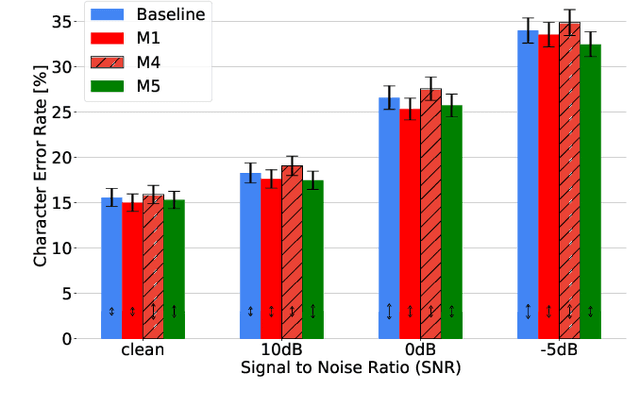
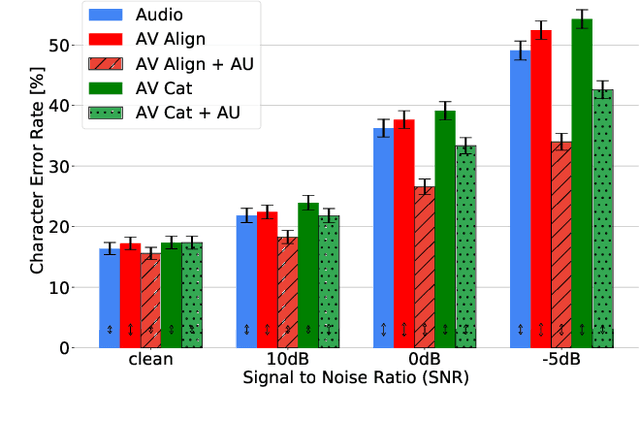
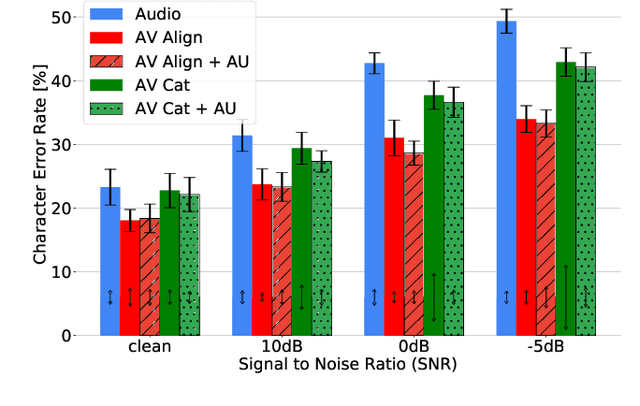
Audio-Visual Speech Recognition (AVSR) seeks to model, and thereby exploit, the dynamic relationship between a human voice and the corresponding mouth movements. A recently proposed multimodal fusion strategy, AV Align, based on state-of-the-art sequence to sequence neural networks, attempts to model this relationship by explicitly aligning the acoustic and visual representations of speech. This study investigates the inner workings of AV Align and visualises the audio-visual alignment patterns. Our experiments are performed on two of the largest publicly available AVSR datasets, TCD-TIMIT and LRS2. We find that AV Align learns to align acoustic and visual representations of speech at the frame level on TCD-TIMIT in a generally monotonic pattern. We also determine the cause of initially seeing no improvement over audio-only speech recognition on the more challenging LRS2. We propose a regularisation method which involves predicting lip-related Action Units from visual representations. Our regularisation method leads to better exploitation of the visual modality, with performance improvements between 7% and 30% depending on the noise level. Furthermore, we show that the alternative Watch, Listen, Attend, and Spell network is affected by the same problem as AV Align, and that our proposed approach can effectively help it learn visual representations. Our findings validate the suitability of the regularisation method to AVSR and encourage researchers to rethink the multimodal convergence problem when having one dominant modality.
Improving Generalizability in Implicitly Abusive Language Detection with Concept Activation Vectors
Apr 05, 2022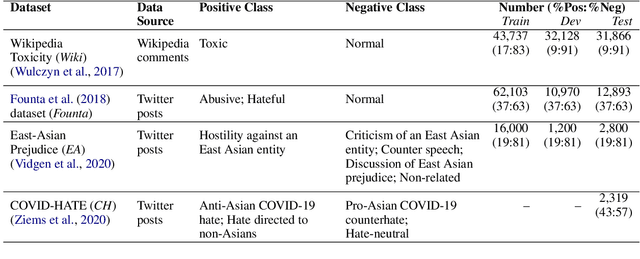
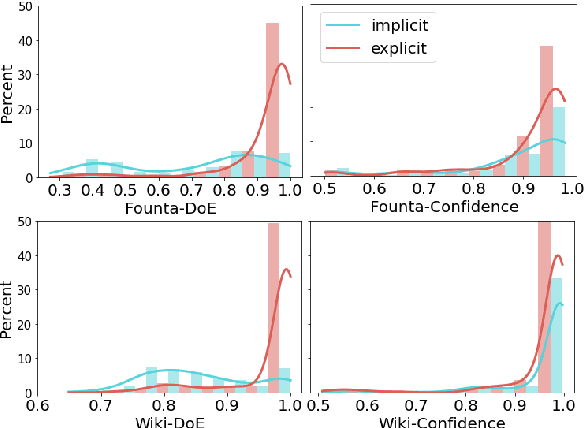
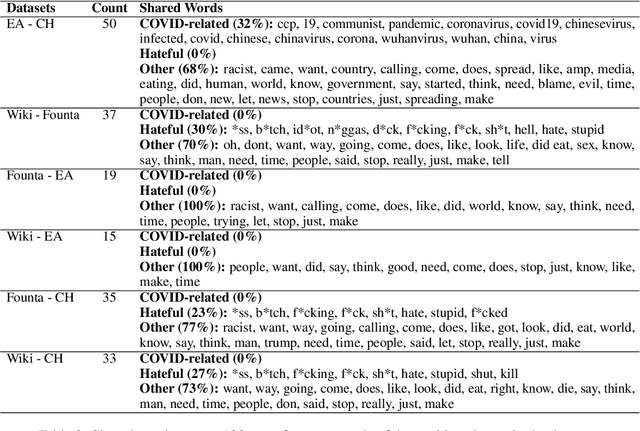
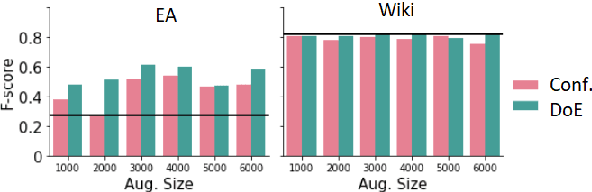
Robustness of machine learning models on ever-changing real-world data is critical, especially for applications affecting human well-being such as content moderation. New kinds of abusive language continually emerge in online discussions in response to current events (e.g., COVID-19), and the deployed abuse detection systems should be updated regularly to remain accurate. In this paper, we show that general abusive language classifiers tend to be fairly reliable in detecting out-of-domain explicitly abusive utterances but fail to detect new types of more subtle, implicit abuse. Next, we propose an interpretability technique, based on the Testing Concept Activation Vector (TCAV) method from computer vision, to quantify the sensitivity of a trained model to the human-defined concepts of explicit and implicit abusive language, and use that to explain the generalizability of the model on new data, in this case, COVID-related anti-Asian hate speech. Extending this technique, we introduce a novel metric, Degree of Explicitness, for a single instance and show that the new metric is beneficial in suggesting out-of-domain unlabeled examples to effectively enrich the training data with informative, implicitly abusive texts.
A scalable noisy speech dataset and online subjective test framework
Sep 17, 2019
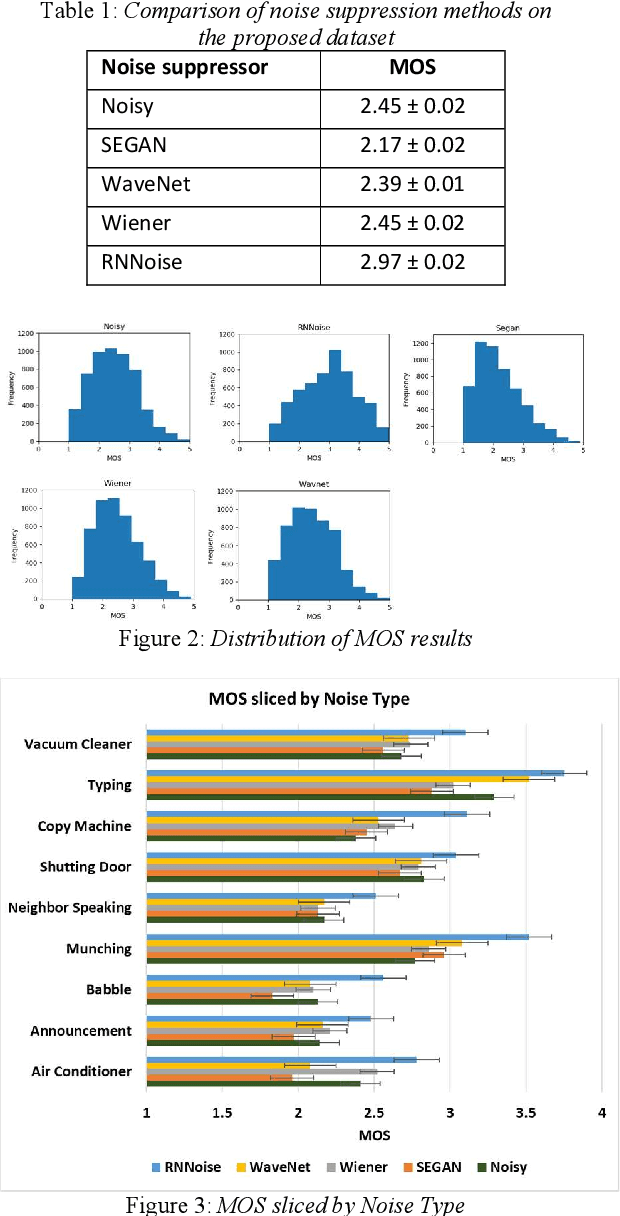
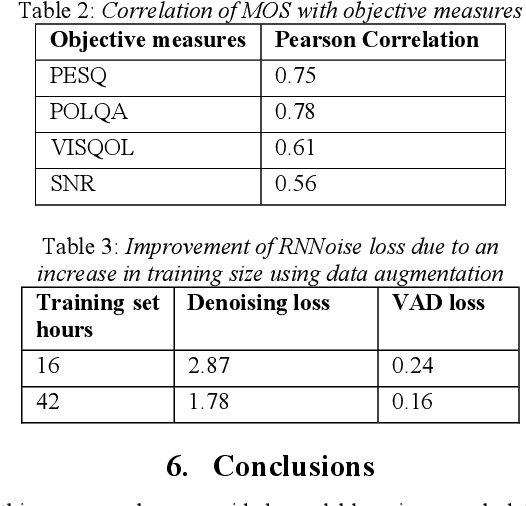
Background noise is a major source of quality impairments in Voice over Internet Protocol (VoIP) and Public Switched Telephone Network (PSTN) calls. Recent work shows the efficacy of deep learning for noise suppression, but the datasets have been relatively small compared to those used in other domains (e.g., ImageNet) and the associated evaluations have been more focused. In order to better facilitate deep learning research in Speech Enhancement, we present a noisy speech dataset (MS-SNSD) that can scale to arbitrary sizes depending on the number of speakers, noise types, and Speech to Noise Ratio (SNR) levels desired. We show that increasing dataset sizes increases noise suppression performance as expected. In addition, we provide an open-source evaluation methodology to evaluate the results subjectively at scale using crowdsourcing, with a reference algorithm to normalize the results. To demonstrate the dataset and evaluation framework we apply it to several noise suppressors and compare the subjective Mean Opinion Score (MOS) with objective quality measures such as SNR, PESQ, POLQA, and VISQOL and show why MOS is still required. Our subjective MOS evaluation is the first large scale evaluation of Speech Enhancement algorithms that we are aware of.
End-to-End Multi-Channel Speech Separation
May 28, 2019
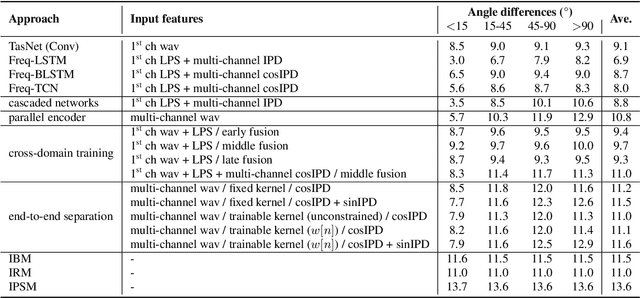
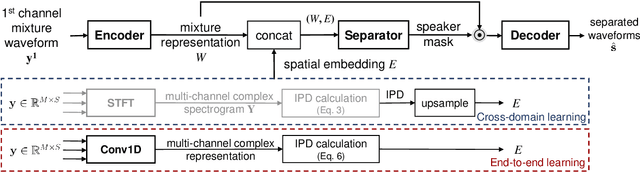

The end-to-end approach for single-channel speech separation has been studied recently and shown promising results. This paper extended the previous approach and proposed a new end-to-end model for multi-channel speech separation. The primary contributions of this work include 1) an integrated waveform-in waveform-out separation system in a single neural network architecture. 2) We reformulate the traditional short time Fourier transform (STFT) and inter-channel phase difference (IPD) as a function of time-domain convolution with a special kernel. 3) We further relaxed those fixed kernels to be learnable, so that the entire architecture becomes purely data-driven and can be trained from end-to-end. We demonstrate on the WSJ0 far-field speech separation task that, with the benefit of learnable spatial features, our proposed end-to-end multi-channel model significantly improved the performance of previous end-to-end single-channel method and traditional multi-channel methods.
Machine Learning: Challenges, Limitations, and Compatibility for Audio Restoration Processes
Sep 06, 2021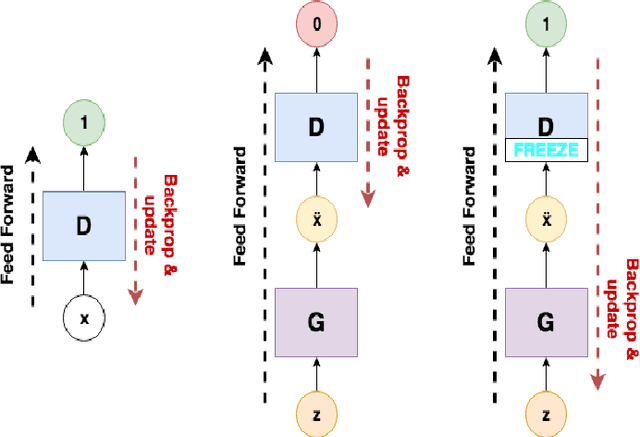
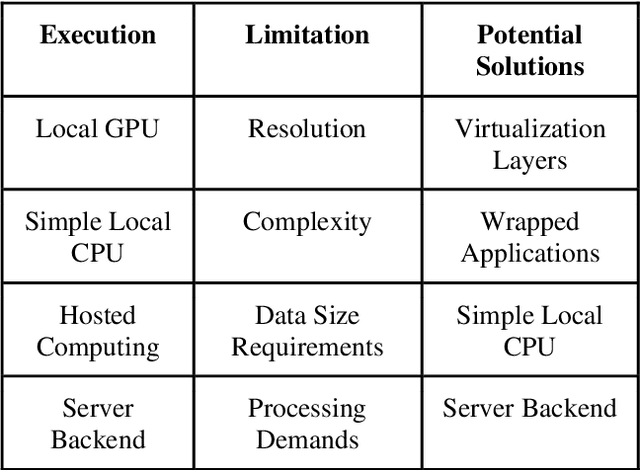
In this paper machine learning networks are explored for their use in restoring degraded and compressed speech audio. The project intent is to build a new trained model from voice data to learn features of compression artifacting distortion introduced by data loss from lossy compression and resolution loss with an existing algorithm presented in SEGAN: Speech Enhancement Generative Adversarial Network. The resulting generator from the model was then to be used to restore degraded speech audio. This paper details an examination of the subsequent compatibility and operational issues presented by working with deprecated code, which obstructed the trained model from successfully being developed. This paper further serves as an examination of the challenges, limitations, and compatibility in the current state of machine learning.
Federated Learning in ASR: Not as Easy as You Think
Sep 30, 2021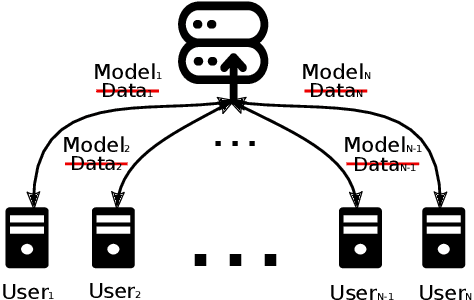
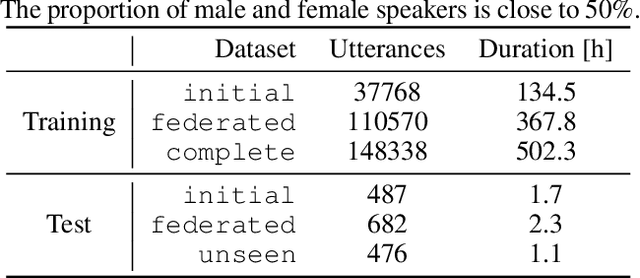
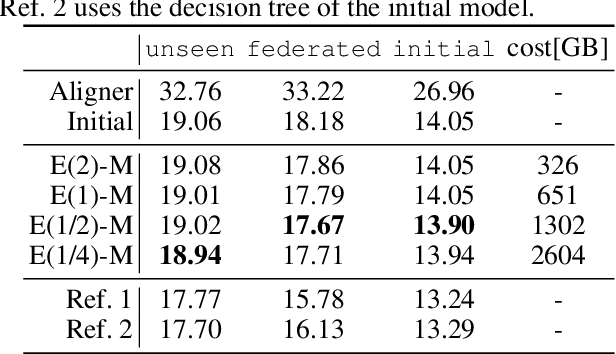
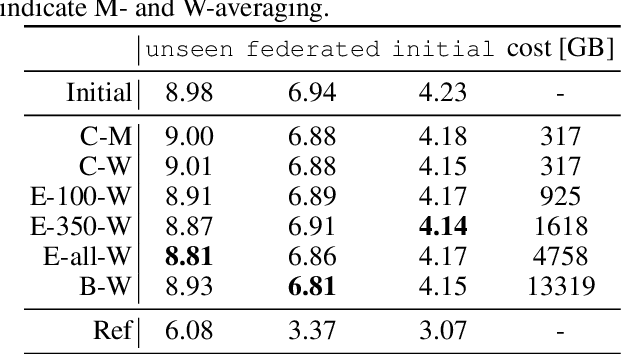
With the growing availability of smart devices and cloud services, personal speech assistance systems are increasingly used on a daily basis. Most devices redirect the voice recordings to a central server, which uses them for upgrading the recognizer model. This leads to major privacy concerns, since private data could be misused by the server or third parties. Federated learning is a decentralized optimization strategy that has been proposed to address such concerns. Utilizing this approach, private data is used for on-device training. Afterwards, updated model parameters are sent to the server to improve the global model, which is redistributed to the clients. In this work, we implement federated learning for speech recognition in a hybrid and an end-to-end model. We discuss the outcomes of these systems, which both show great similarities and only small improvements, pointing to a need for a deeper understanding of federated learning for speech recognition.
Lattention: Lattice-attention in ASR rescoring
Nov 19, 2021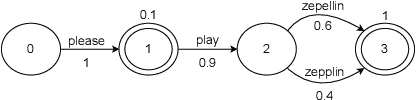
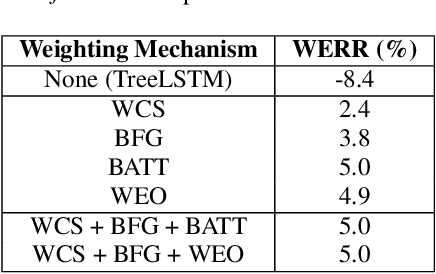
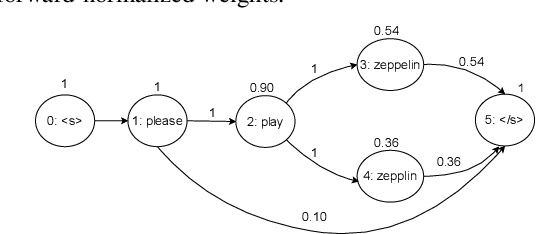
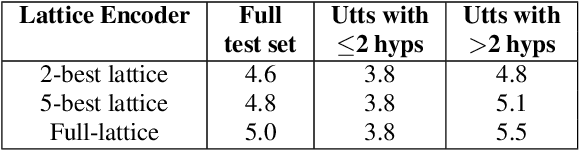
Lattices form a compact representation of multiple hypotheses generated from an automatic speech recognition system and have been shown to improve performance of downstream tasks like spoken language understanding and speech translation, compared to using one-best hypothesis. In this work, we look into the effectiveness of lattice cues for rescoring n-best lists in second-pass. We encode lattices with a recurrent network and train an attention encoder-decoder model for n-best rescoring. The rescoring model with attention to lattices achieves 4-5% relative word error rate reduction over first-pass and 6-8% with attention to both lattices and acoustic features. We show that rescoring models with attention to lattices outperform models with attention to n-best hypotheses. We also study different ways to incorporate lattice weights in the lattice encoder and demonstrate their importance for n-best rescoring.
Speech-driven facial animation using polynomial fusion of features
Dec 12, 2019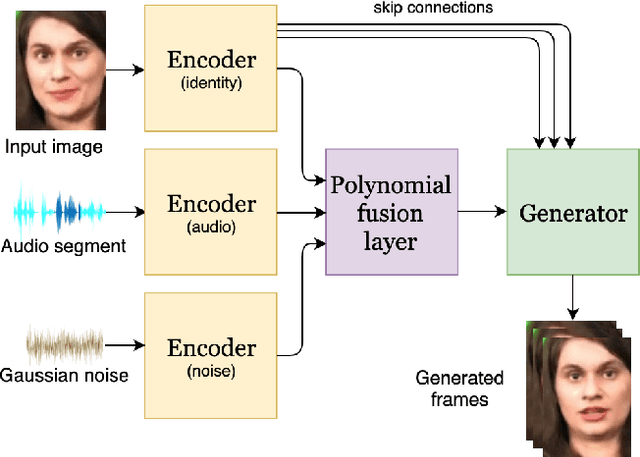
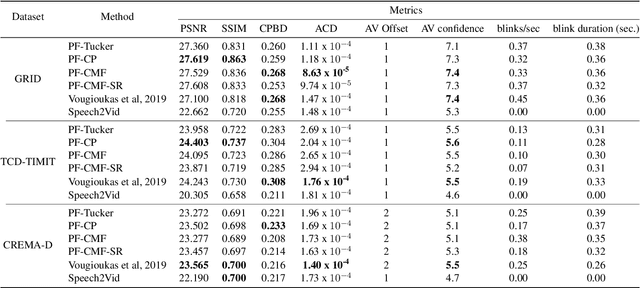
Speech-driven facial animation involves using a speech signal to generate realistic videos of talking faces. Recent deep learning approaches to facial synthesis rely on extracting low-dimensional representations and concatenating them, followed by a decoding step of the concatenated vector. This accounts for only first-order interactions of the features and ignores higher-order interactions. In this paper we propose a polynomial fusion layer that models the joint representation of the encodings by a higher-order polynomial, with the parameters modelled by a tensor decomposition. We demonstrate the the suitability of this approach through experiments on generated videos evaluated on a range of metrics on video quality, audiovisual synchronisation and generation of blinks.
Neural Zero-Inflated Quality Estimation Model For Automatic Speech Recognition System
Oct 03, 2019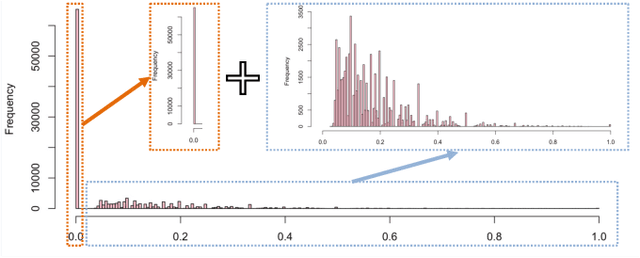

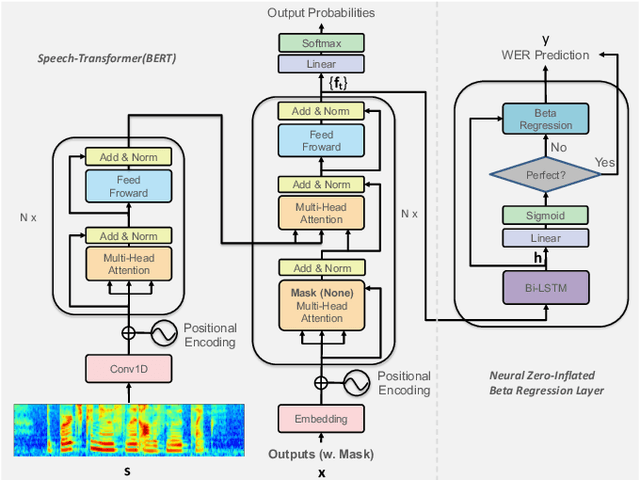

The performances of automatic speech recognition (ASR) systems are usually evaluated by the metric word error rate (WER) when the manually transcribed data are provided, which are, however, expensively available in the real scenario. In addition, the empirical distribution of WER for most ASR systems usually tends to put a significant mass near zero, making it difficult to simulate with a single continuous distribution. In order to address the two issues of ASR quality estimation (QE), we propose a novel neural zero-inflated model to predict the WER of the ASR result without transcripts. We design a neural zero-inflated beta regression on top of a bidirectional transformer language model conditional on speech features (speech-BERT). We adopt the pre-training strategy of token level mask language modeling for speech-BERT as well, and further fine-tune with our zero-inflated layer for the mixture of discrete and continuous outputs. The experimental results show that our approach achieves better performance on WER prediction in the metrics of Pearson and MAE, compared with most existed quality estimation algorithms for ASR or machine translation.
Speech Enhancement with Zero-Shot Model Selection
Dec 17, 2020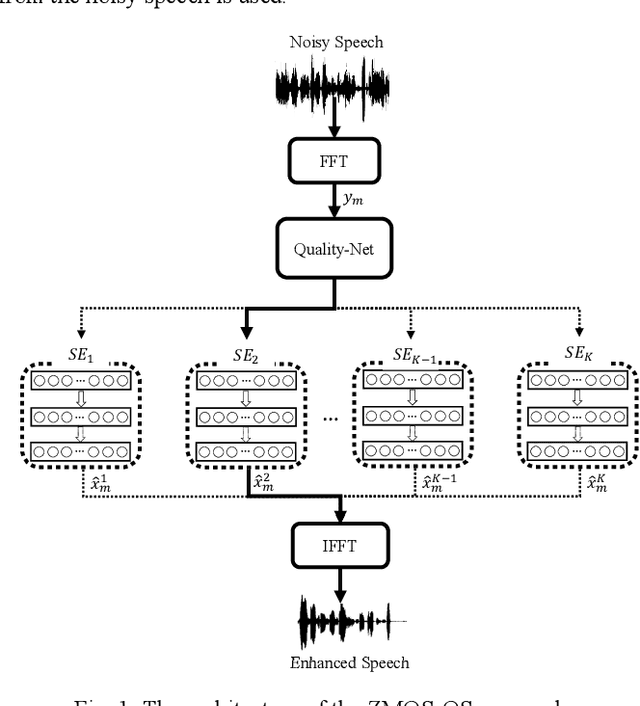
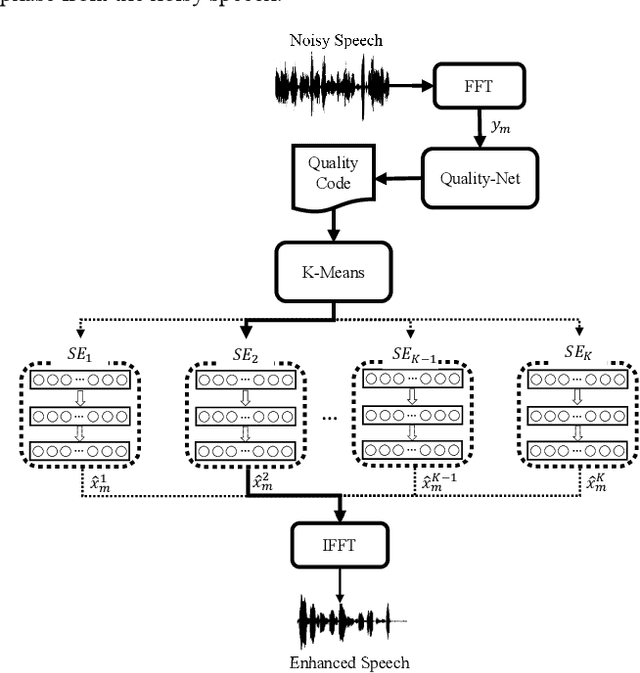
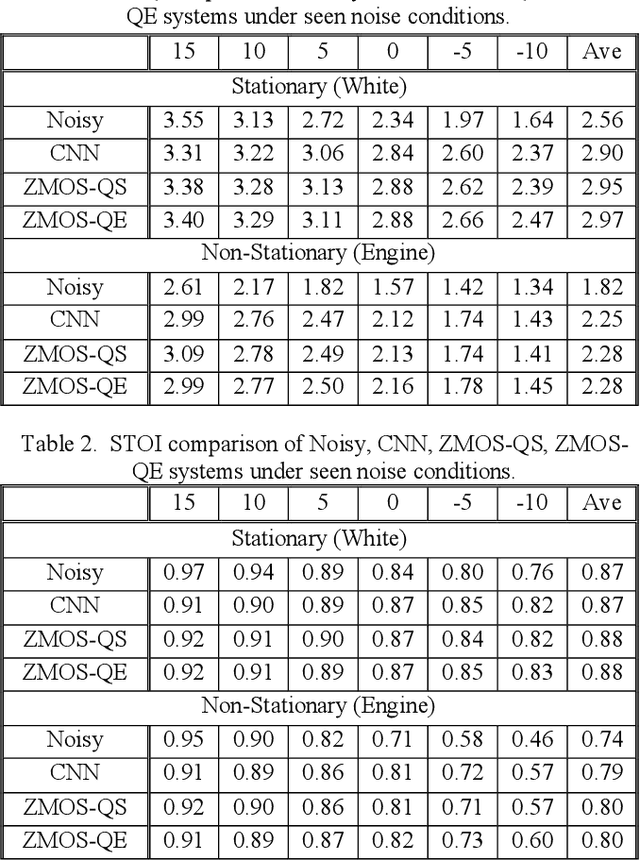
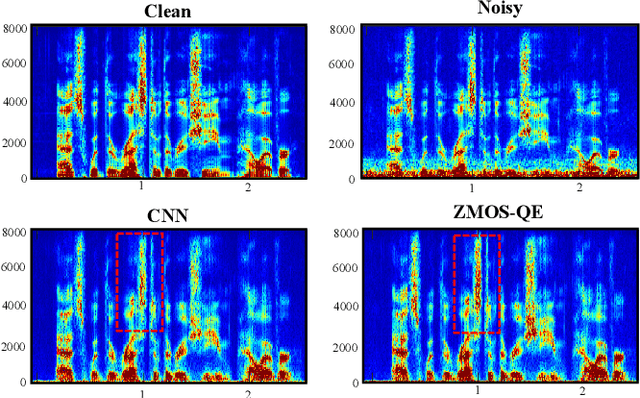
Recent research on speech enhancement (SE) has seen the emergence of deep learning-based methods. It is still a challenging task to determine effective ways to increase the generalizability of SE under diverse test conditions. In this paper, we combine zero-shot learning and ensemble learning to propose a zero-shot model selection (ZMOS) approach to increase the generalization of SE performance. The proposed approach is realized in two phases, namely offline and online phases. The offline phase clusters the entire set of training data into multiple subsets, and trains a specialized SE model (termed component SE model) with each subset. The online phase selects the most suitable component SE model to carry out enhancement. Two selection strategies are developed: selection based on quality score (QS) and selection based on quality embedding (QE). Both QS and QE are obtained by a Quality-Net, a non-intrusive quality assessment network. In the offline phase, the QS or QE of a train-ing utterance is used to group the training data into clusters. In the online phase, the QS or QE of the test utterance is used to identify the appropriate component SE model to perform enhancement on the test utterance. Experimental results have confirmed that the proposed ZMOS approach can achieve better performance in both seen and unseen noise types compared to the baseline systems, which indicates the effectiveness of the proposed approach to provide robust SE performance.