 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
The slurk Interaction Server Framework: Better Data for Better Dialog Models
Feb 02, 2022

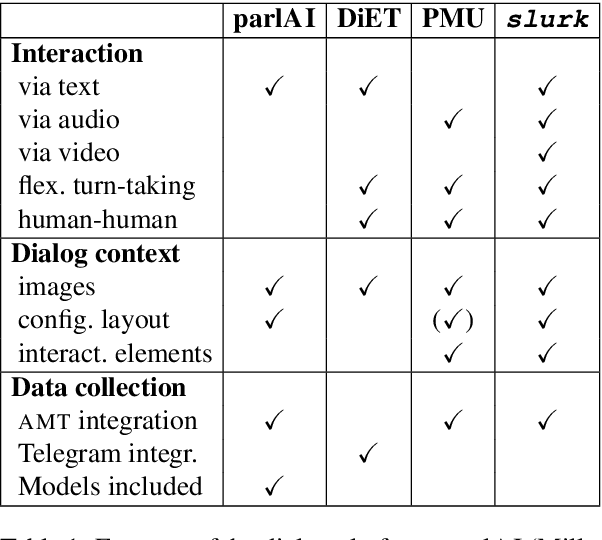
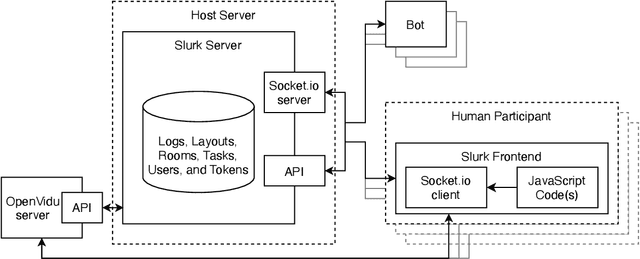
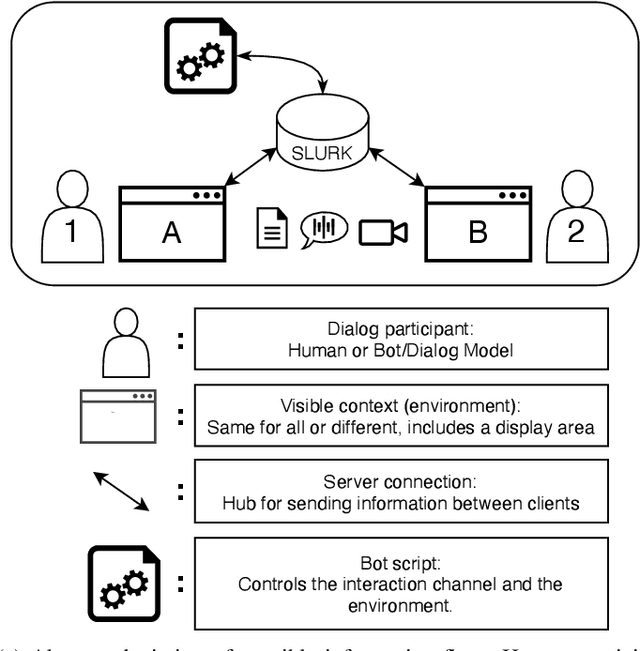
This paper presents the slurk software, a lightweight interaction server for setting up dialog data collections and running experiments. Slurk enables a multitude of settings including text-based, speech and video interaction between two or more humans or humans and bots, and a multimodal display area for presenting shared or private interactive context. The software is implemented in Python with an HTML and JS frontend that can easily be adapted to individual needs. It also provides a setup for pairing participants on common crowdworking platforms such as Amazon Mechanical Turk and some example bot scripts for common interaction scenarios.
Attention-Free Keyword Spotting
Oct 18, 2021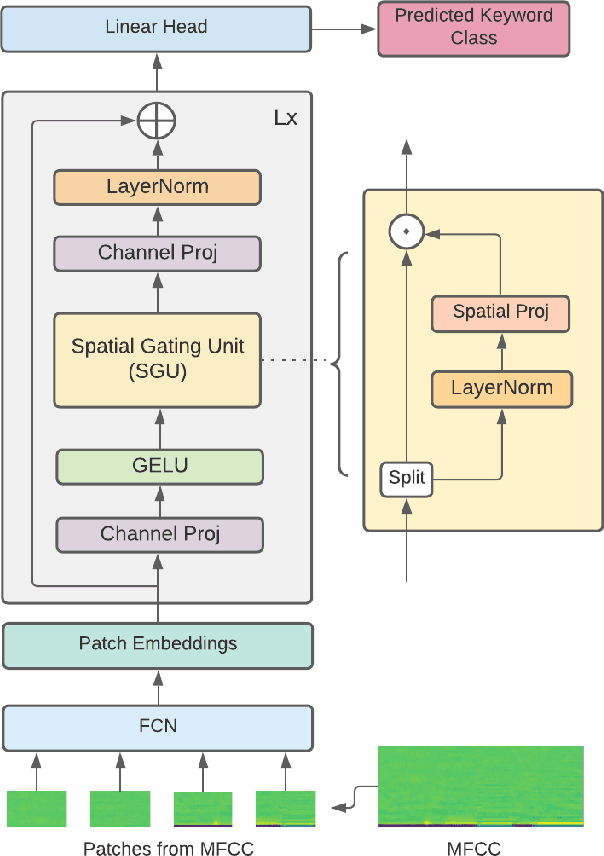
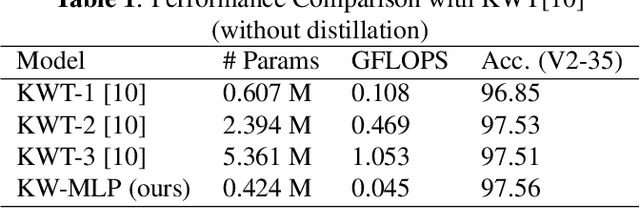
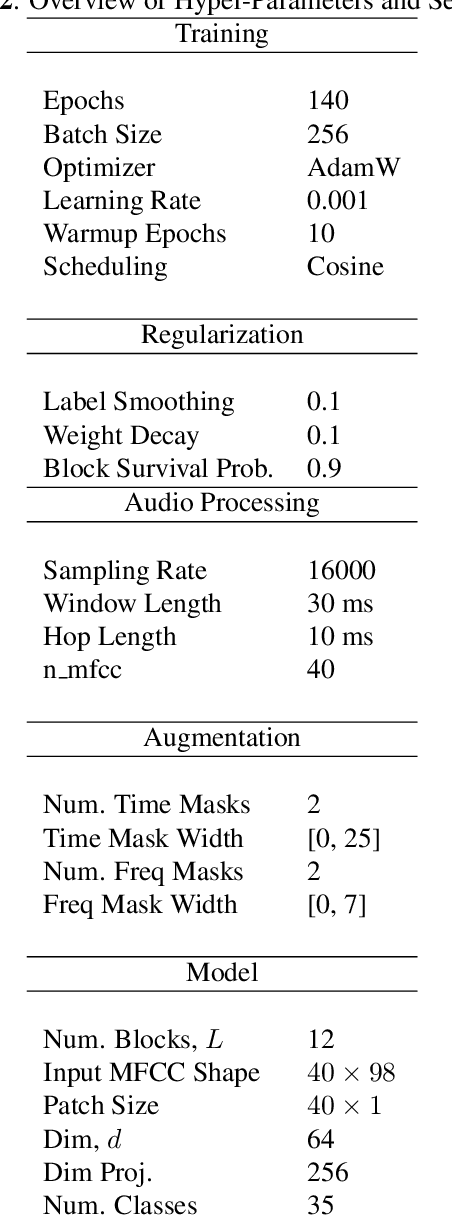
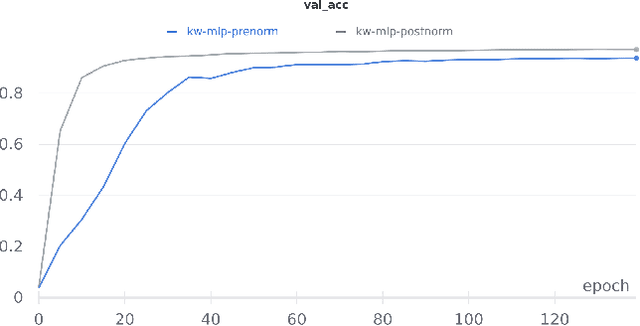
Till now, attention-based models have been used with great success in the keyword spotting problem domain. However, in light of recent advances in deep learning, the question arises whether self-attention is truly irreplaceable for recognizing speech keywords. We thus explore the usage of gated MLPs -- previously shown to be alternatives to transformers in vision tasks -- for the keyword spotting task. We verify our approach on the Google Speech Commands V2-35 dataset and show that it is possible to obtain performance comparable to the state of the art without any apparent usage of self-attention.
Pathological speech detection using x-vector embeddings
Mar 03, 2020



The potential of speech as a non-invasive biomarker to assess a speaker's health has been repeatedly supported by the results of multiple works, for both physical and psychological conditions. Traditional systems for speech-based disease classification have focused on carefully designed knowledge-based features. However, these features may not represent the disease's full symptomatology, and may even overlook its more subtle manifestations. This has prompted researchers to move in the direction of general speaker representations that inherently model symptoms, such as Gaussian Supervectors, i-vectors and, x-vectors. In this work, we focus on the latter, to assess their applicability as a general feature extraction method to the detection of Parkinson's disease (PD) and obstructive sleep apnea (OSA). We test our approach against knowledge-based features and i-vectors, and report results for two European Portuguese corpora, for OSA and PD, as well as for an additional Spanish corpus for PD. Both x-vector and i-vector models were trained with an out-of-domain European Portuguese corpus. Our results show that x-vectors are able to perform better than knowledge-based features in same-language corpora. Moreover, while x-vectors performed similarly to i-vectors in matched conditions, they significantly outperform them when domain-mismatch occurs.
End-to-End Multi-Channel Speech Separation
May 28, 2019
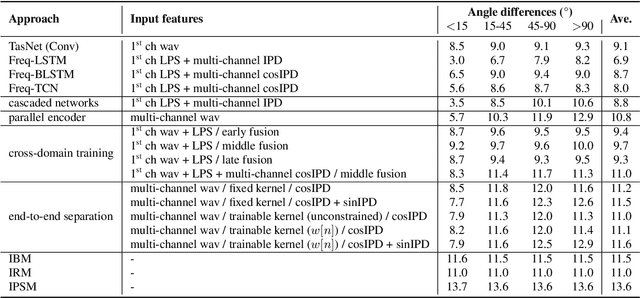
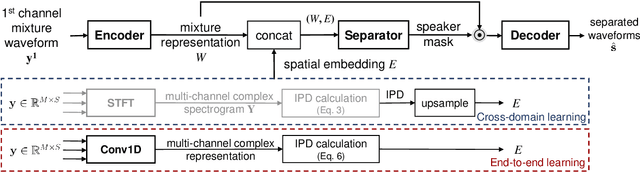

The end-to-end approach for single-channel speech separation has been studied recently and shown promising results. This paper extended the previous approach and proposed a new end-to-end model for multi-channel speech separation. The primary contributions of this work include 1) an integrated waveform-in waveform-out separation system in a single neural network architecture. 2) We reformulate the traditional short time Fourier transform (STFT) and inter-channel phase difference (IPD) as a function of time-domain convolution with a special kernel. 3) We further relaxed those fixed kernels to be learnable, so that the entire architecture becomes purely data-driven and can be trained from end-to-end. We demonstrate on the WSJ0 far-field speech separation task that, with the benefit of learnable spatial features, our proposed end-to-end multi-channel model significantly improved the performance of previous end-to-end single-channel method and traditional multi-channel methods.
Population Based Training for Data Augmentation and Regularization in Speech Recognition
Oct 08, 2020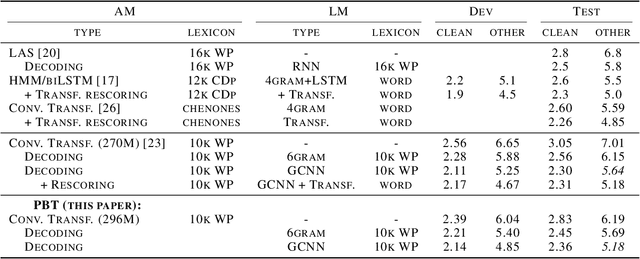
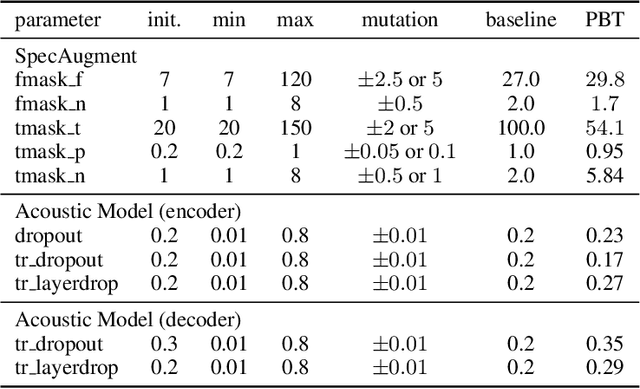
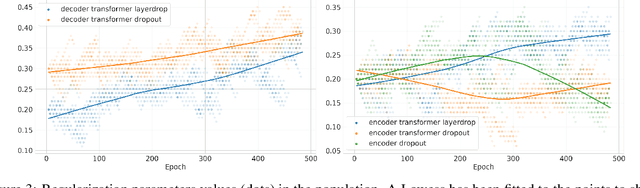
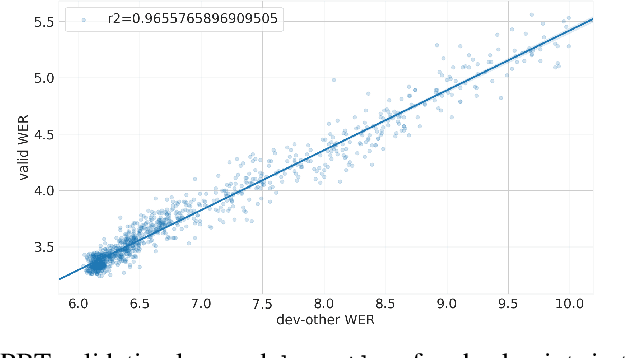
Varying data augmentation policies and regularization over the course of optimization has led to performance improvements over using fixed values. We show that population based training is a useful tool to continuously search those hyperparameters, within a fixed budget. This greatly simplifies the experimental burden and computational cost of finding such optimal schedules. We experiment in speech recognition by optimizing SpecAugment this way, as well as dropout. It compares favorably to a baseline that does not change those hyperparameters over the course of training, with an 8% relative WER improvement. We obtain 5.18% word error rate on LibriSpeech's test-other.
How Familiar Does That Sound? Cross-Lingual Representational Similarity Analysis of Acoustic Word Embeddings
Sep 21, 2021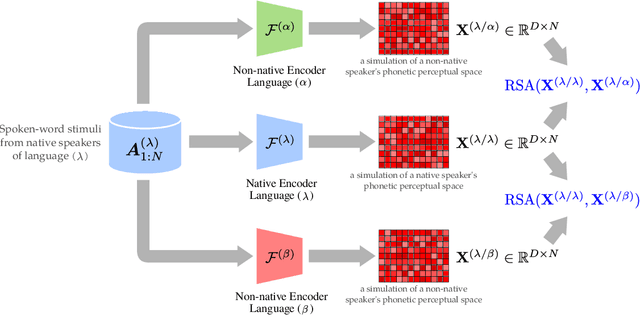
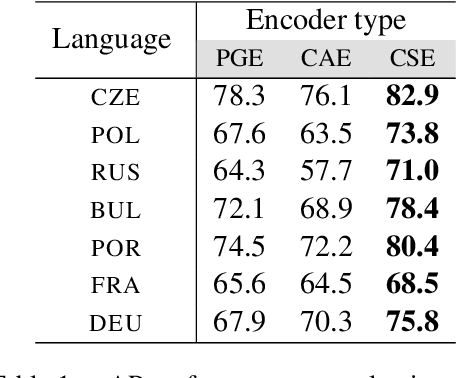
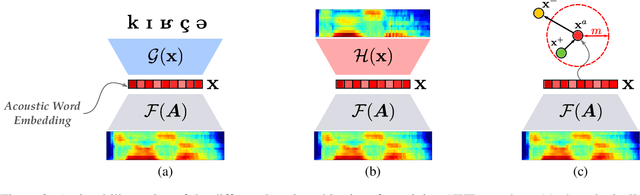
How do neural networks "perceive" speech sounds from unknown languages? Does the typological similarity between the model's training language (L1) and an unknown language (L2) have an impact on the model representations of L2 speech signals? To answer these questions, we present a novel experimental design based on representational similarity analysis (RSA) to analyze acoustic word embeddings (AWEs) -- vector representations of variable-duration spoken-word segments. First, we train monolingual AWE models on seven Indo-European languages with various degrees of typological similarity. We then employ RSA to quantify the cross-lingual similarity by simulating native and non-native spoken-word processing using AWEs. Our experiments show that typological similarity indeed affects the representational similarity of the models in our study. We further discuss the implications of our work on modeling speech processing and language similarity with neural networks.
A scalable noisy speech dataset and online subjective test framework
Sep 17, 2019
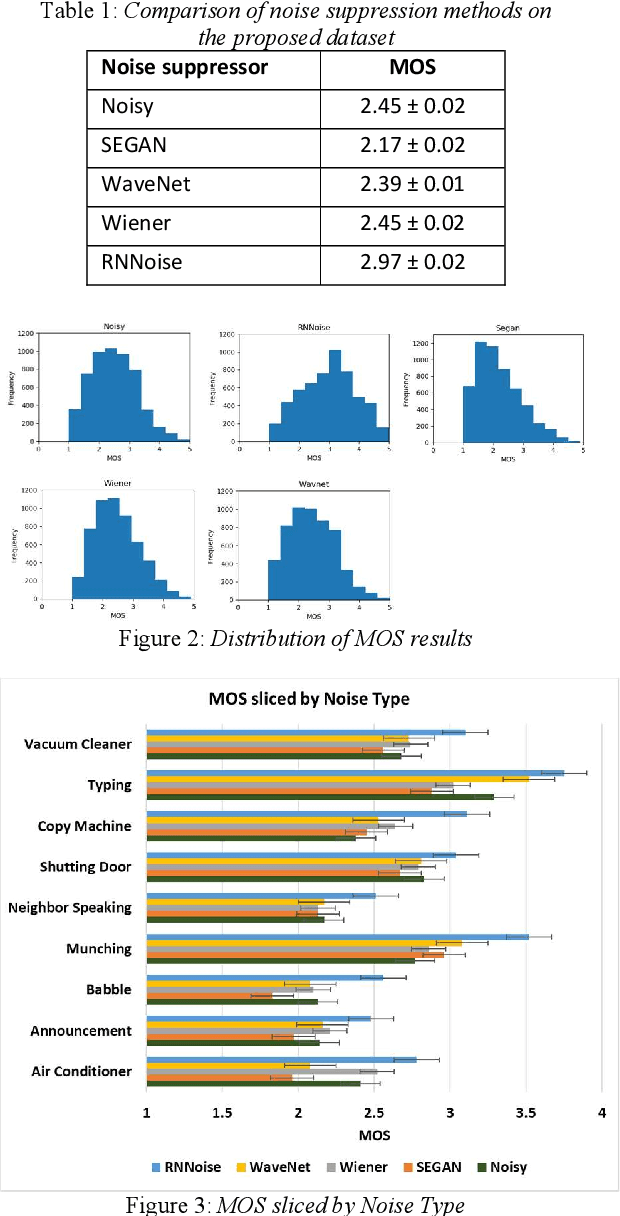
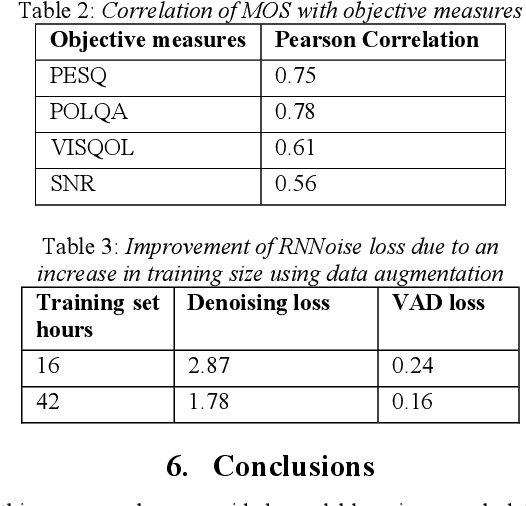
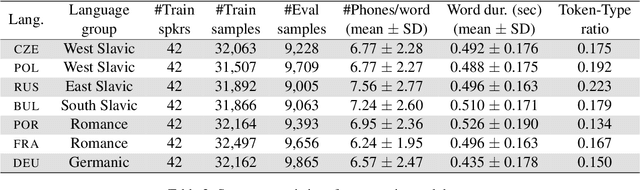
Background noise is a major source of quality impairments in Voice over Internet Protocol (VoIP) and Public Switched Telephone Network (PSTN) calls. Recent work shows the efficacy of deep learning for noise suppression, but the datasets have been relatively small compared to those used in other domains (e.g., ImageNet) and the associated evaluations have been more focused. In order to better facilitate deep learning research in Speech Enhancement, we present a noisy speech dataset (MS-SNSD) that can scale to arbitrary sizes depending on the number of speakers, noise types, and Speech to Noise Ratio (SNR) levels desired. We show that increasing dataset sizes increases noise suppression performance as expected. In addition, we provide an open-source evaluation methodology to evaluate the results subjectively at scale using crowdsourcing, with a reference algorithm to normalize the results. To demonstrate the dataset and evaluation framework we apply it to several noise suppressors and compare the subjective Mean Opinion Score (MOS) with objective quality measures such as SNR, PESQ, POLQA, and VISQOL and show why MOS is still required. Our subjective MOS evaluation is the first large scale evaluation of Speech Enhancement algorithms that we are aware of.
Unraveling Social Perceptions & Behaviors towards Migrants on Twitter
Dec 04, 2021

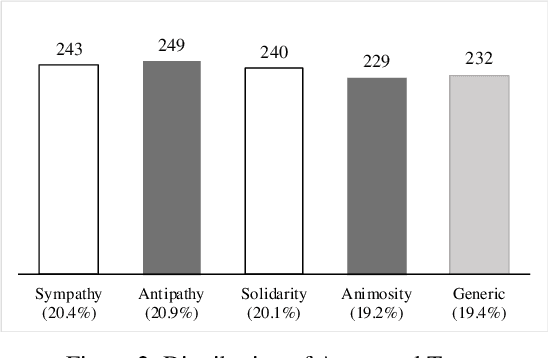
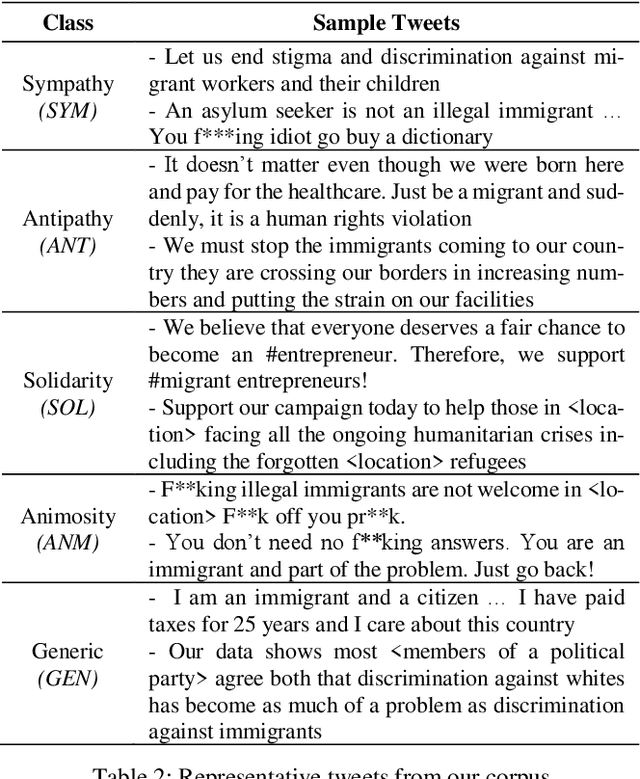
We draw insights from the social psychology literature to identify two facets of Twitter deliberations about migrants, i.e., perceptions about migrants and behaviors towards mi-grants. Our theoretical anchoring helped us in identifying two prevailing perceptions (i.e., sympathy and antipathy) and two dominant behaviors (i.e., solidarity and animosity) of social media users towards migrants. We have employed unsuper-vised and supervised approaches to identify these perceptions and behaviors. In the domain of applied NLP, our study of-fers a nuanced understanding of migrant-related Twitter de-liberations. Our proposed transformer-based model, i.e., BERT + CNN, has reported an F1-score of 0.76 and outper-formed other models. Additionally, we argue that tweets con-veying antipathy or animosity can be broadly considered hate speech towards migrants, but they are not the same. Thus, our approach has fine-tuned the binary hate speech detection task by highlighting the granular differences between perceptual and behavioral aspects of hate speeches.
Align-Refine: Non-Autoregressive Speech Recognition via Iterative Realignment
Oct 24, 2020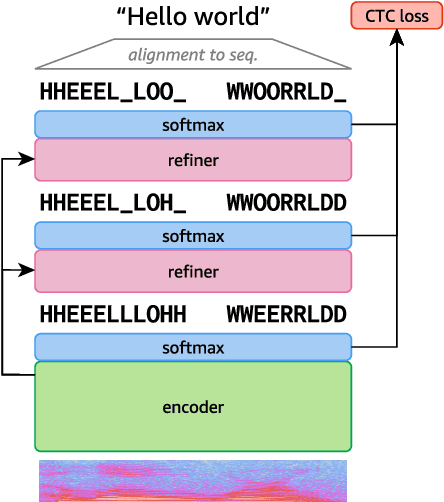
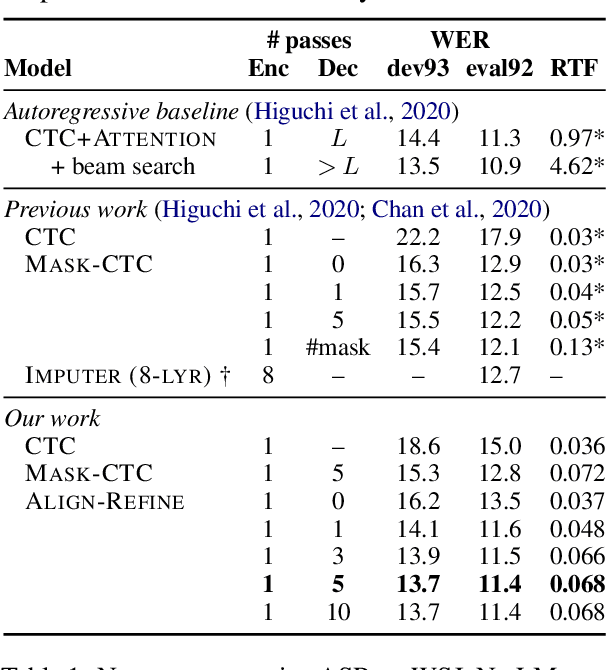
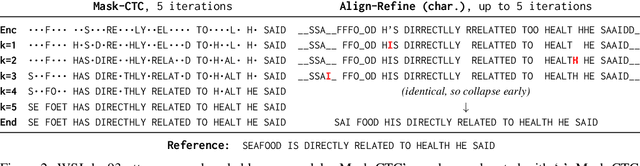
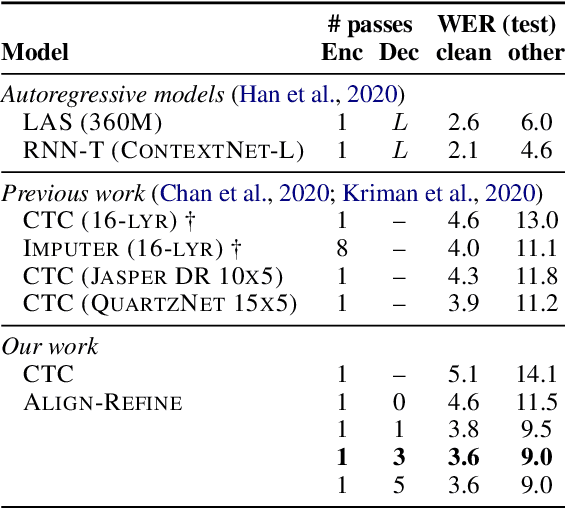
Non-autoregressive models greatly improve decoding speed over typical sequence-to-sequence models, but suffer from degraded performance. Infilling and iterative refinement models make up some of this gap by editing the outputs of a non-autoregressive model, but are constrained in the edits that they can make. We propose iterative realignment, where refinements occur over latent alignments rather than output sequence space. We demonstrate this in speech recognition with Align-Refine, an end-to-end Transformer-based model which refines connectionist temporal classification (CTC) alignments to allow length-changing insertions and deletions. Align-Refine outperforms Imputer and Mask-CTC, matching an autoregressive baseline on WSJ at 1/14th the real-time factor and attaining a LibriSpeech test-other WER of 9.0% without an LM. Our model is strong even in one iteration with a shallower decoder.
How to Teach DNNs to Pay Attention to the Visual Modality in Speech Recognition
Apr 17, 2020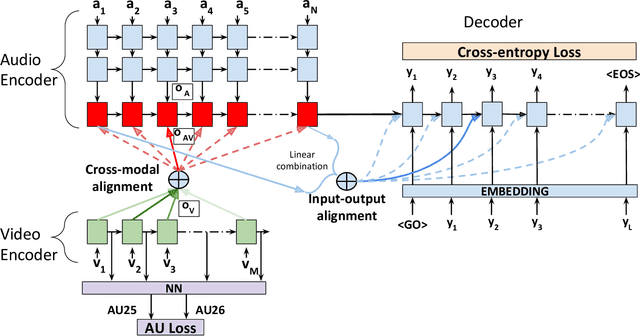
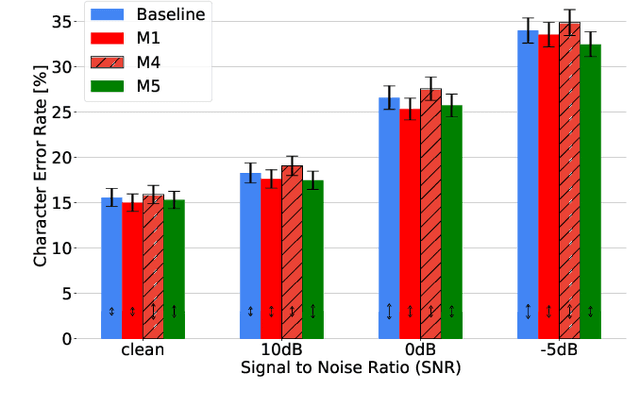
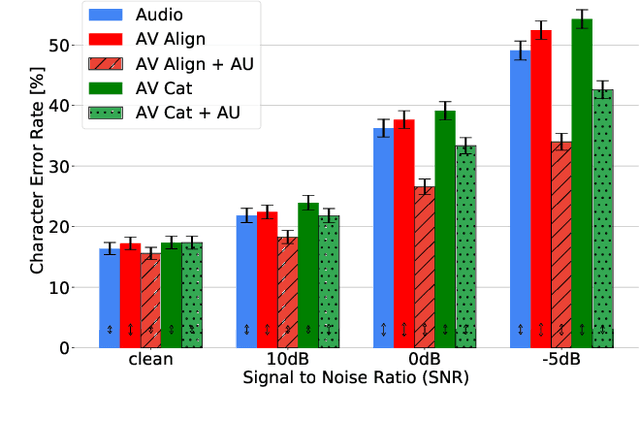
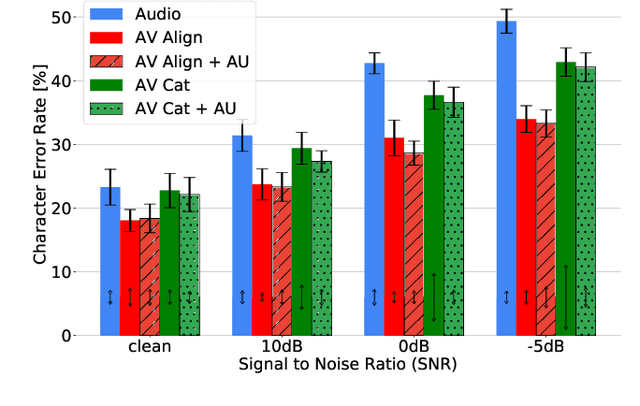
Audio-Visual Speech Recognition (AVSR) seeks to model, and thereby exploit, the dynamic relationship between a human voice and the corresponding mouth movements. A recently proposed multimodal fusion strategy, AV Align, based on state-of-the-art sequence to sequence neural networks, attempts to model this relationship by explicitly aligning the acoustic and visual representations of speech. This study investigates the inner workings of AV Align and visualises the audio-visual alignment patterns. Our experiments are performed on two of the largest publicly available AVSR datasets, TCD-TIMIT and LRS2. We find that AV Align learns to align acoustic and visual representations of speech at the frame level on TCD-TIMIT in a generally monotonic pattern. We also determine the cause of initially seeing no improvement over audio-only speech recognition on the more challenging LRS2. We propose a regularisation method which involves predicting lip-related Action Units from visual representations. Our regularisation method leads to better exploitation of the visual modality, with performance improvements between 7% and 30% depending on the noise level. Furthermore, we show that the alternative Watch, Listen, Attend, and Spell network is affected by the same problem as AV Align, and that our proposed approach can effectively help it learn visual representations. Our findings validate the suitability of the regularisation method to AVSR and encourage researchers to rethink the multimodal convergence problem when having one dominant modality.