 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Generalization Ability of MOS Prediction Networks
Oct 06, 2021
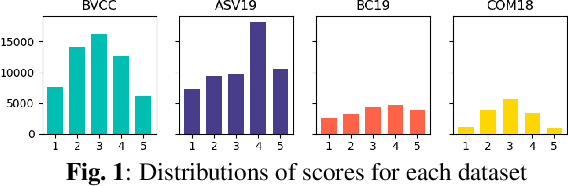
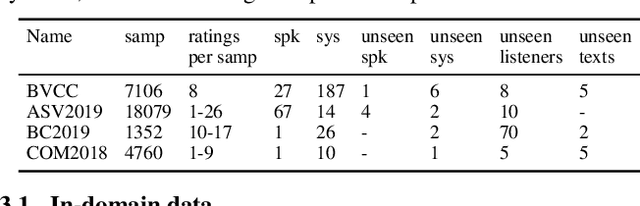
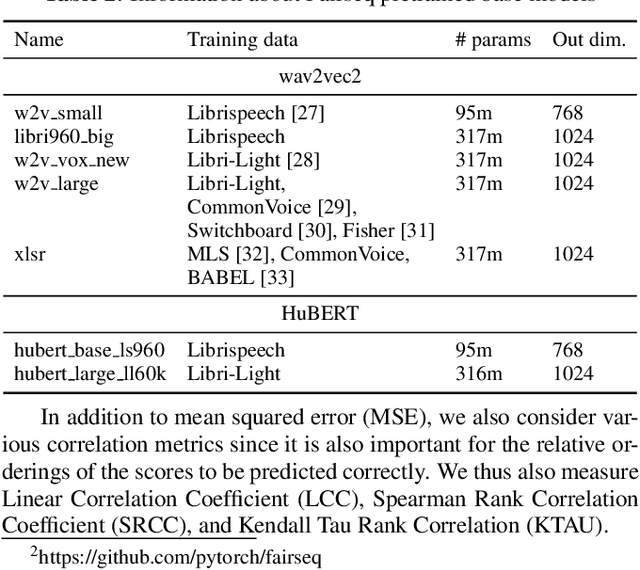
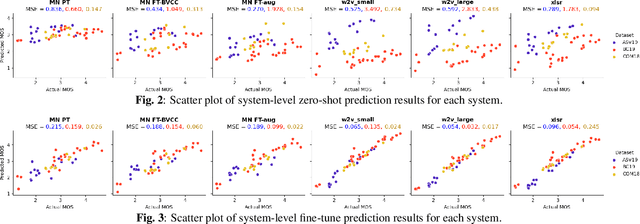
Automatic methods to predict listener opinions of synthesized speech remain elusive since listeners, systems being evaluated, characteristics of the speech, and even the instructions given and the rating scale all vary from test to test. While automatic predictors for metrics such as mean opinion score (MOS) can achieve high prediction accuracy on samples from the same test, they typically fail to generalize well to new listening test contexts. In this paper, using a variety of networks for MOS prediction including MOSNet and self-supervised speech models such as wav2vec2, we investigate their performance on data from different listening tests in both zero-shot and fine-tuned settings. We find that wav2vec2 models fine-tuned for MOS prediction have good generalization capability to out-of-domain data even for the most challenging case of utterance-level predictions in the zero-shot setting, and that fine-tuning to in-domain data can improve predictions. We also observe that unseen systems are especially challenging for MOS prediction models.
A scalable noisy speech dataset and online subjective test framework
Sep 17, 2019
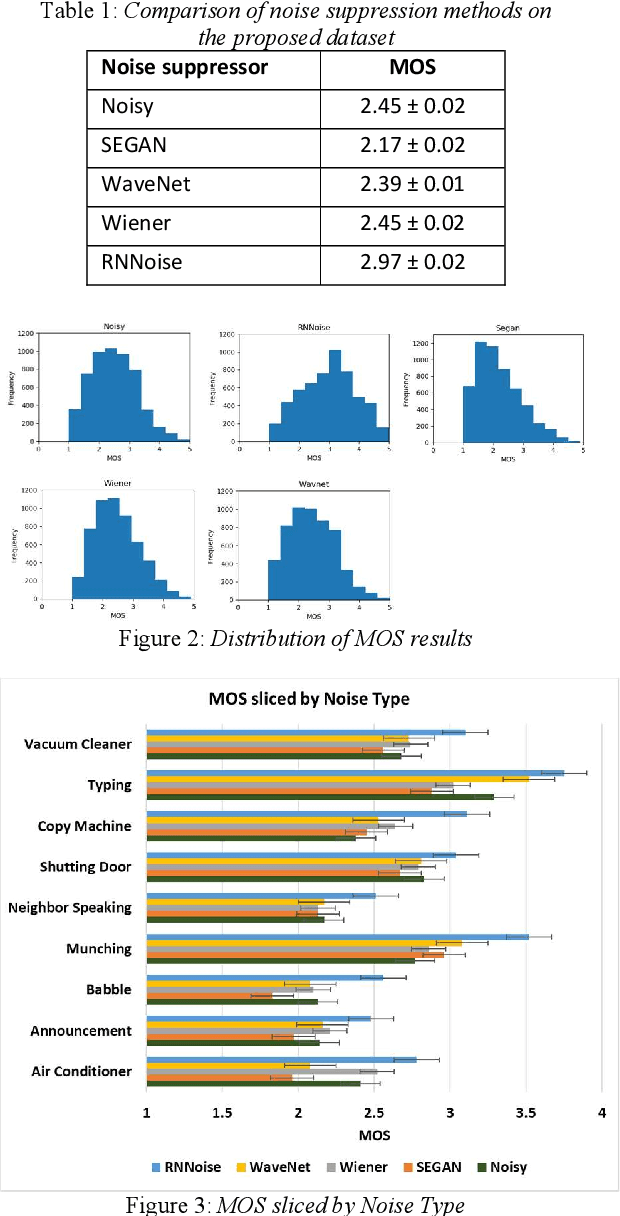
Background noise is a major source of quality impairments in Voice over Internet Protocol (VoIP) and Public Switched Telephone Network (PSTN) calls. Recent work shows the efficacy of deep learning for noise suppression, but the datasets have been relatively small compared to those used in other domains (e.g., ImageNet) and the associated evaluations have been more focused. In order to better facilitate deep learning research in Speech Enhancement, we present a noisy speech dataset (MS-SNSD) that can scale to arbitrary sizes depending on the number of speakers, noise types, and Speech to Noise Ratio (SNR) levels desired. We show that increasing dataset sizes increases noise suppression performance as expected. In addition, we provide an open-source evaluation methodology to evaluate the results subjectively at scale using crowdsourcing, with a reference algorithm to normalize the results. To demonstrate the dataset and evaluation framework we apply it to several noise suppressors and compare the subjective Mean Opinion Score (MOS) with objective quality measures such as SNR, PESQ, POLQA, and VISQOL and show why MOS is still required. Our subjective MOS evaluation is the first large scale evaluation of Speech Enhancement algorithms that we are aware of.
Multilingual Transfer Learning for Code-Switched Language and Speech Neural Modeling
Apr 13, 2021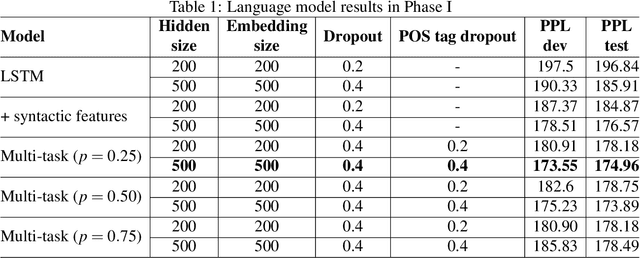
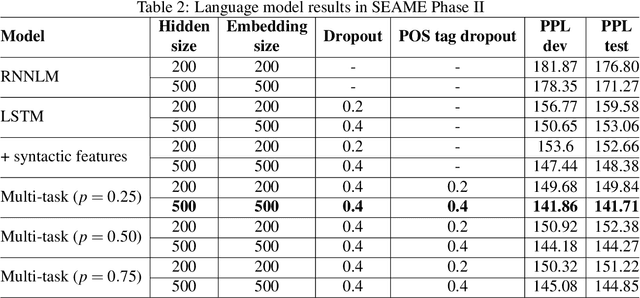
In this thesis, we address the data scarcity and limitations of linguistic theory by proposing language-agnostic multi-task training methods. First, we introduce a meta-learning-based approach, meta-transfer learning, in which information is judiciously extracted from high-resource monolingual speech data to the code-switching domain. The meta-transfer learning quickly adapts the model to the code-switching task from a number of monolingual tasks by learning to learn in a multi-task learning fashion. Second, we propose a novel multilingual meta-embeddings approach to effectively represent code-switching data by acquiring useful knowledge learned in other languages, learning the commonalities of closely related languages and leveraging lexical composition. The method is far more efficient compared to contextualized pre-trained multilingual models. Third, we introduce multi-task learning to integrate syntactic information as a transfer learning strategy to a language model and learn where to code-switch. To further alleviate the aforementioned issues, we propose a data augmentation method using Pointer-Gen, a neural network using a copy mechanism to teach the model the code-switch points from monolingual parallel sentences. We disentangle the need for linguistic theory, and the model captures code-switching points by attending to input words and aligning the parallel words, without requiring any word alignments or constituency parsers. More importantly, the model can be effectively used for languages that are syntactically different, and it outperforms the linguistic theory-based models.
Punctuation Restoration
Feb 19, 2022
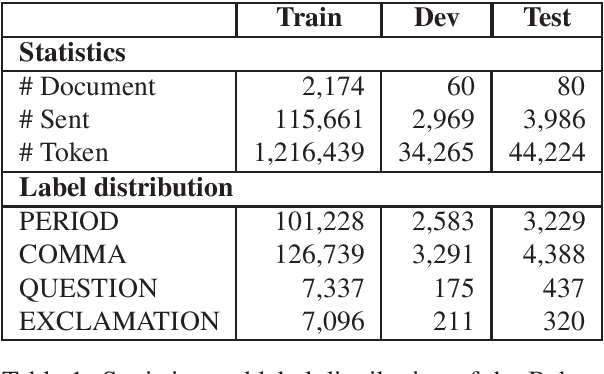


Given the increasing number of livestreaming videos, automatic speech recognition and post-processing for livestreaming video transcripts are crucial for efficient data management as well as knowledge mining. A key step in this process is punctuation restoration which restores fundamental text structures such as phrase and sentence boundaries from the video transcripts. This work presents a new human-annotated corpus, called BehancePR, for punctuation restoration in livestreaming video transcripts. Our experiments on BehancePR demonstrate the challenges of punctuation restoration for this domain. Furthermore, we show that popular natural language processing toolkits are incapable of detecting sentence boundary on non-punctuated transcripts of livestreaming videos, calling for more research effort to develop robust models for this area.
Towards Learning Universal Audio Representations
Dec 01, 2021
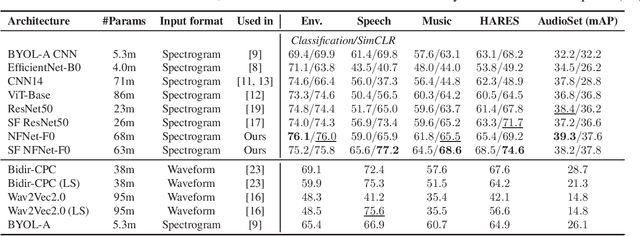
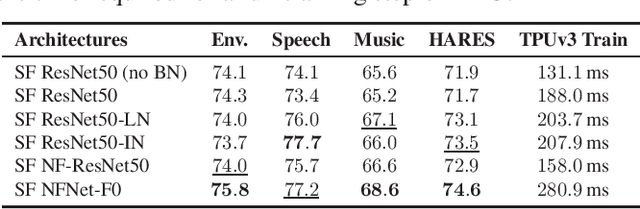
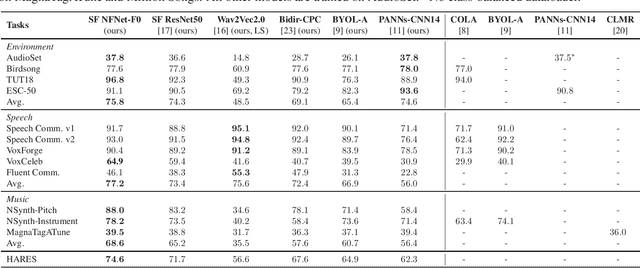
The ability to learn universal audio representations that can solve diverse speech, music, and environment tasks can spur many applications that require general sound content understanding. In this work, we introduce a holistic audio representation evaluation suite (HARES) spanning 12 downstream tasks across audio domains and provide a thorough empirical study of recent sound representation learning systems on that benchmark. We discover that previous sound event classification or speech models do not generalize outside of their domains. We observe that more robust audio representations can be learned with the SimCLR objective; however, the model's transferability depends heavily on the model architecture. We find the Slowfast architecture is good at learning rich representations required by different domains, but its performance is affected by the normalization scheme. Based on these findings, we propose a novel normalizer-free Slowfast NFNet and achieve state-of-the-art performance across all domains.
How to Teach DNNs to Pay Attention to the Visual Modality in Speech Recognition
Apr 17, 2020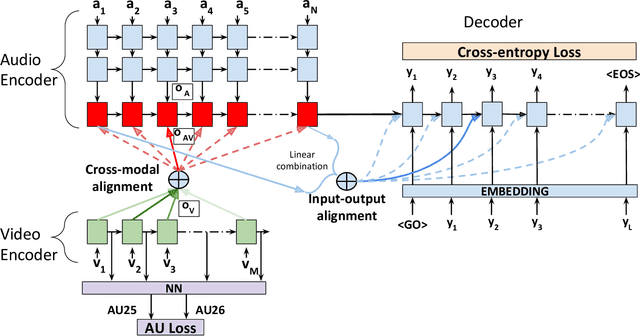
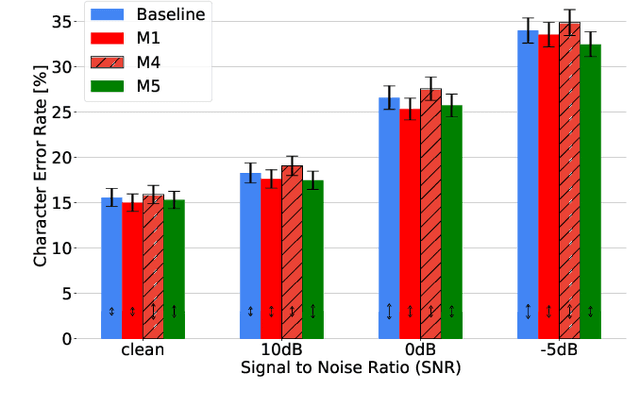
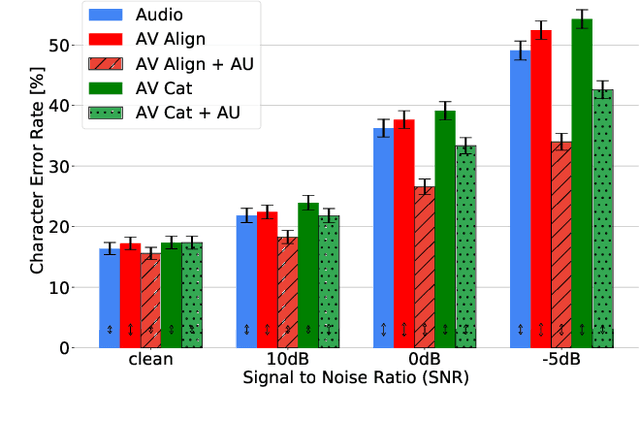
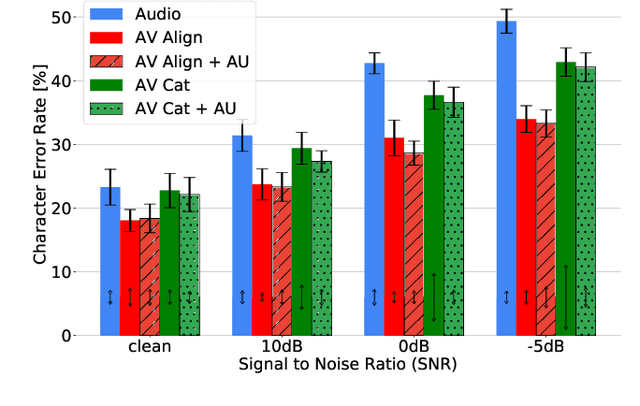
Audio-Visual Speech Recognition (AVSR) seeks to model, and thereby exploit, the dynamic relationship between a human voice and the corresponding mouth movements. A recently proposed multimodal fusion strategy, AV Align, based on state-of-the-art sequence to sequence neural networks, attempts to model this relationship by explicitly aligning the acoustic and visual representations of speech. This study investigates the inner workings of AV Align and visualises the audio-visual alignment patterns. Our experiments are performed on two of the largest publicly available AVSR datasets, TCD-TIMIT and LRS2. We find that AV Align learns to align acoustic and visual representations of speech at the frame level on TCD-TIMIT in a generally monotonic pattern. We also determine the cause of initially seeing no improvement over audio-only speech recognition on the more challenging LRS2. We propose a regularisation method which involves predicting lip-related Action Units from visual representations. Our regularisation method leads to better exploitation of the visual modality, with performance improvements between 7% and 30% depending on the noise level. Furthermore, we show that the alternative Watch, Listen, Attend, and Spell network is affected by the same problem as AV Align, and that our proposed approach can effectively help it learn visual representations. Our findings validate the suitability of the regularisation method to AVSR and encourage researchers to rethink the multimodal convergence problem when having one dominant modality.
Population Based Training for Data Augmentation and Regularization in Speech Recognition
Oct 08, 2020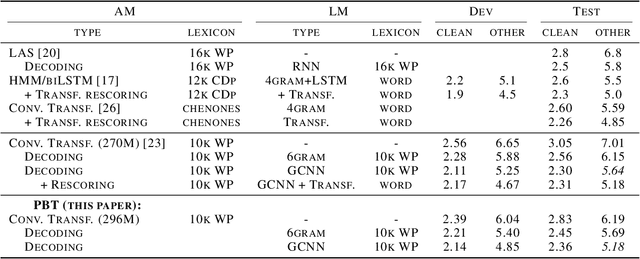
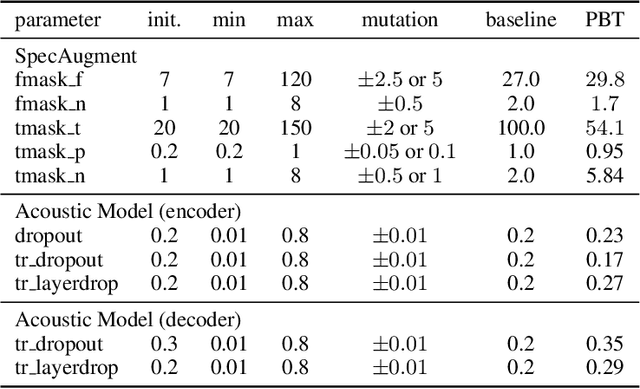
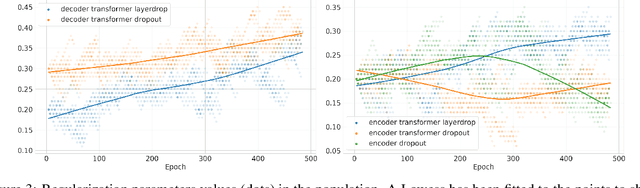
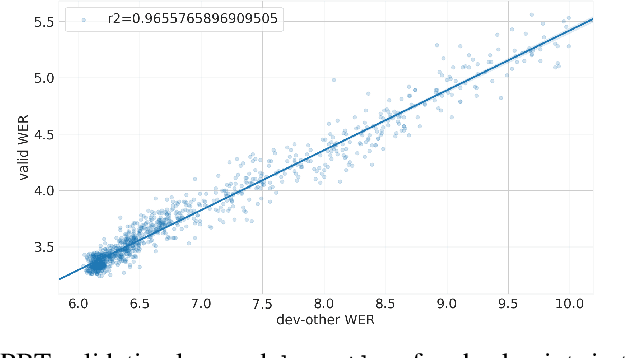
Varying data augmentation policies and regularization over the course of optimization has led to performance improvements over using fixed values. We show that population based training is a useful tool to continuously search those hyperparameters, within a fixed budget. This greatly simplifies the experimental burden and computational cost of finding such optimal schedules. We experiment in speech recognition by optimizing SpecAugment this way, as well as dropout. It compares favorably to a baseline that does not change those hyperparameters over the course of training, with an 8% relative WER improvement. We obtain 5.18% word error rate on LibriSpeech's test-other.
InterAug: Augmenting Noisy Intermediate Predictions for CTC-based ASR
Apr 01, 2022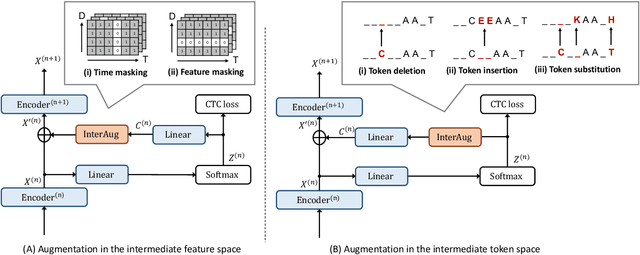
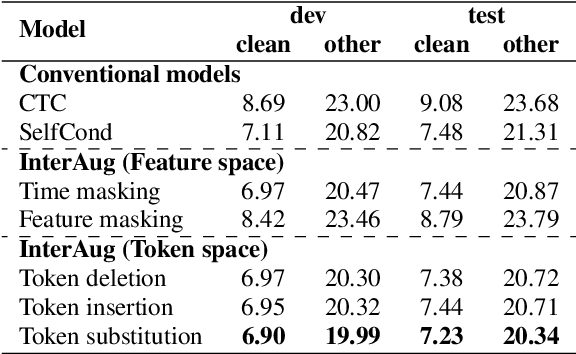
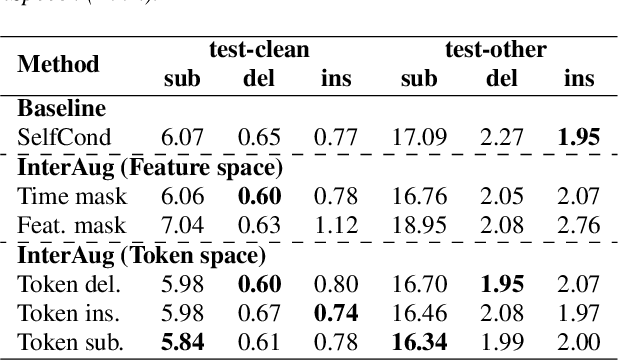
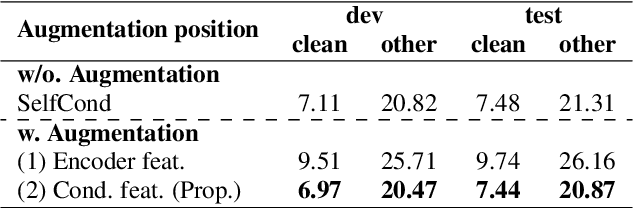
This paper proposes InterAug: a novel training method for CTC-based ASR using augmented intermediate representations for conditioning. The proposed method exploits the conditioning framework of self-conditioned CTC to train robust models by conditioning with "noisy" intermediate predictions. During the training, intermediate predictions are changed to incorrect intermediate predictions, and fed into the next layer for conditioning. The subsequent layers are trained to correct the incorrect intermediate predictions with the intermediate losses. By repeating the augmentation and the correction, iterative refinements, which generally require a special decoder, can be realized only with the audio encoder. To produce noisy intermediate predictions, we also introduce new augmentation: intermediate feature space augmentation and intermediate token space augmentation that are designed to simulate typical errors. The combination of the proposed InterAug framework with new augmentation allows explicit training of the robust audio encoders. In experiments using augmentations simulating deletion, insertion, and substitution error, we confirmed that the trained model acquires robustness to each error, boosting the speech recognition performance of the strong self-conditioned CTC baseline.
CSS10: A Collection of Single Speaker Speech Datasets for 10 Languages
Apr 03, 2019


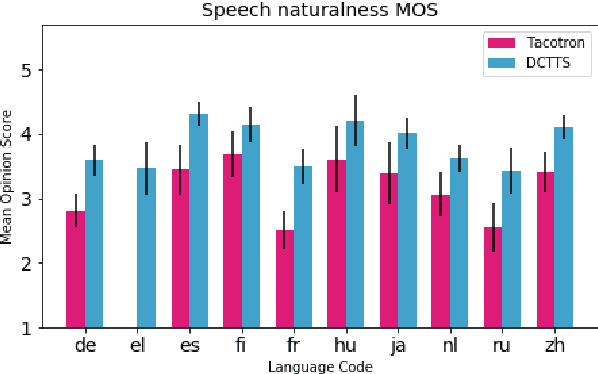
We describe our development of CSS10, a collection of single speaker speech datasets for ten languages. It is composed of short audio clips from LibriVox audiobooks and their aligned texts. To validate its quality we train two neural text-to-speech models on each dataset. Subsequently, we conduct Mean Opinion Score tests on the synthesized speech samples. We make our datasets, pre-trained models, and test resources publicly available. We hope they will be used for future speech tasks.
Align-Refine: Non-Autoregressive Speech Recognition via Iterative Realignment
Oct 24, 2020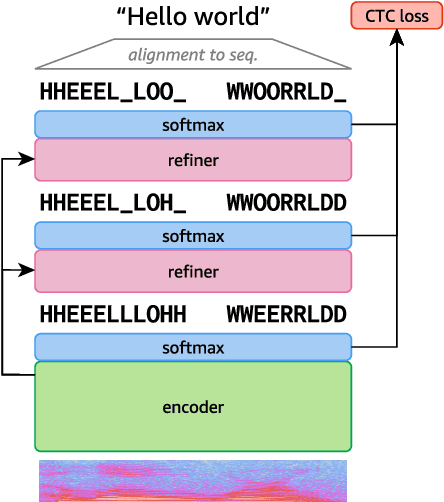
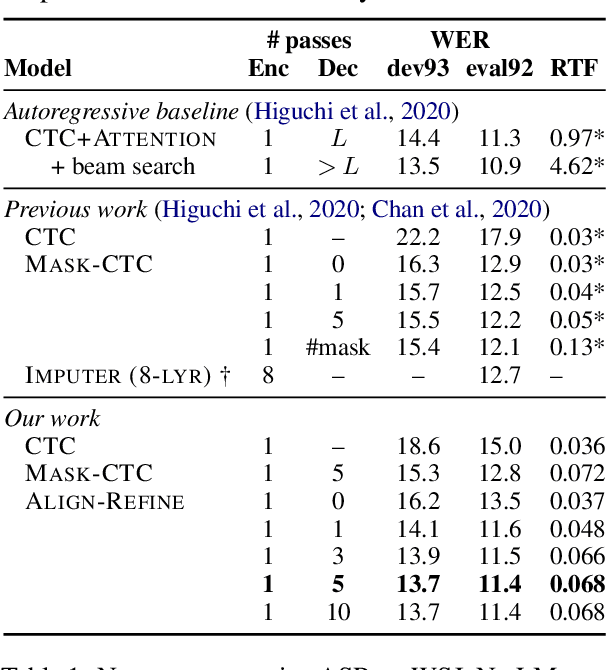
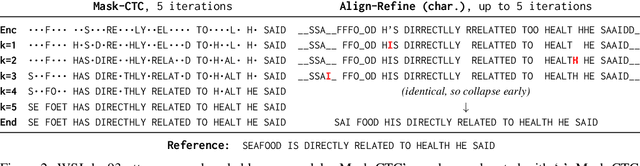
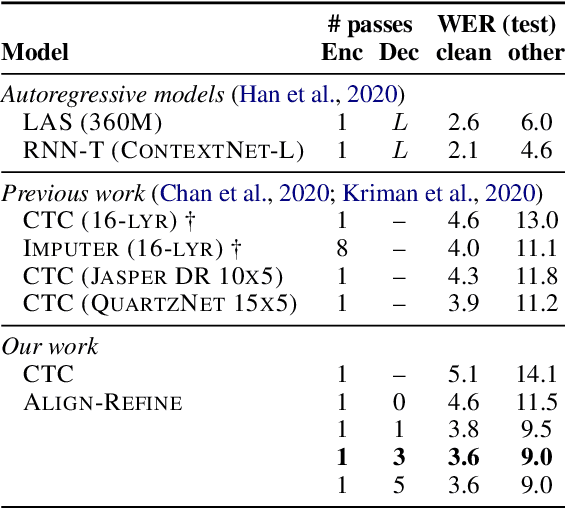
Non-autoregressive models greatly improve decoding speed over typical sequence-to-sequence models, but suffer from degraded performance. Infilling and iterative refinement models make up some of this gap by editing the outputs of a non-autoregressive model, but are constrained in the edits that they can make. We propose iterative realignment, where refinements occur over latent alignments rather than output sequence space. We demonstrate this in speech recognition with Align-Refine, an end-to-end Transformer-based model which refines connectionist temporal classification (CTC) alignments to allow length-changing insertions and deletions. Align-Refine outperforms Imputer and Mask-CTC, matching an autoregressive baseline on WSJ at 1/14th the real-time factor and attaining a LibriSpeech test-other WER of 9.0% without an LM. Our model is strong even in one iteration with a shallower decoder.