 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Low-Complexity, Real-Time Joint Neural Echo Control and Speech Enhancement Based On PercepNet
Feb 10, 2021
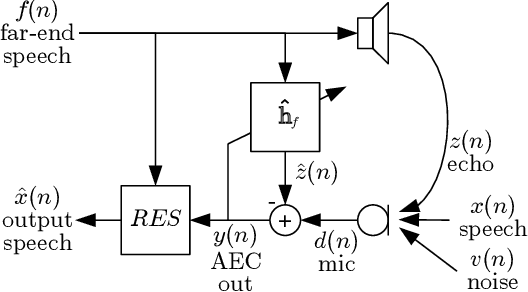
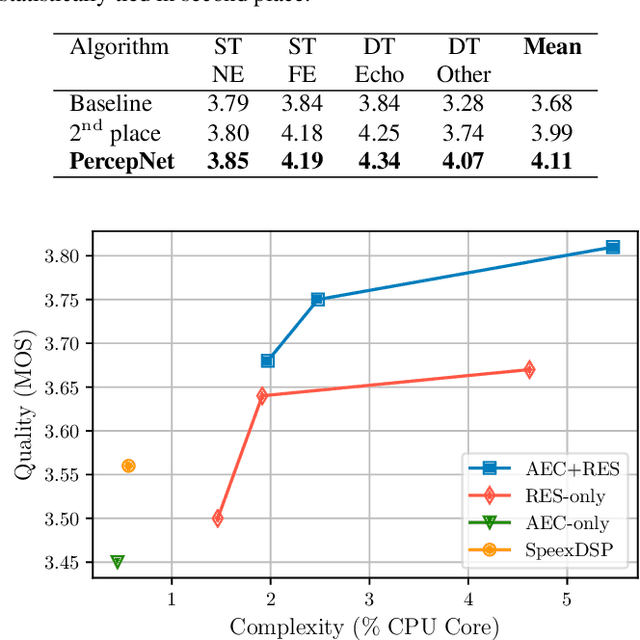
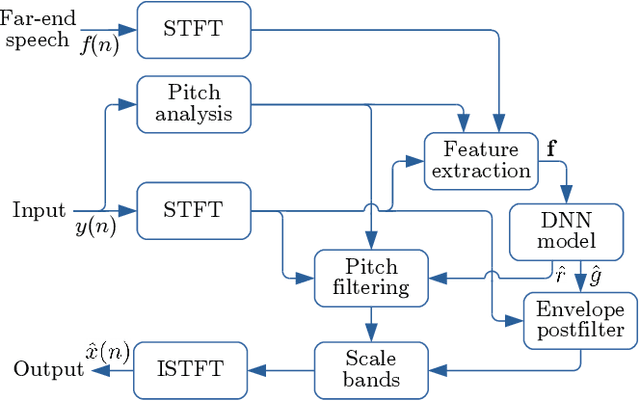
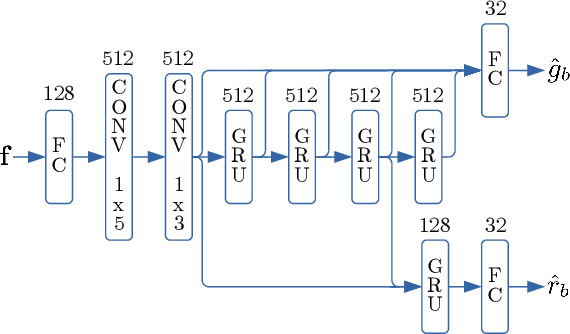
Speech enhancement algorithms based on deep learning have greatly surpassed their traditional counterparts and are now being considered for the task of removing acoustic echo from hands-free communication systems. This is a challenging problem due to both real-world constraints like loudspeaker non-linearities, and to limited compute capabilities in some communication systems. In this work, we propose a system combining a traditional acoustic echo canceller, and a low-complexity joint residual echo and noise suppressor based on a hybrid signal processing/deep neural network (DSP/DNN) approach. We show that the proposed system outperforms both traditional and other neural approaches, while requiring only 5.5% CPU for real-time operation. We further show that the system can scale to even lower complexity levels.
Rhythm Zone Theory: Speech Rhythms are Physical after all
Mar 12, 2019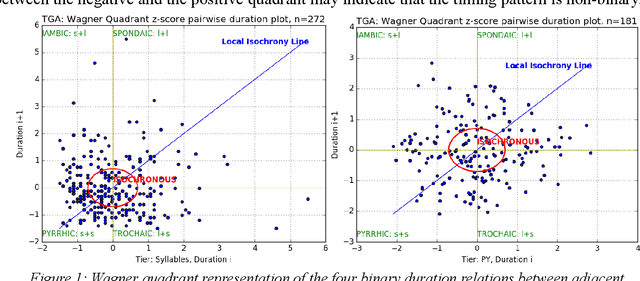
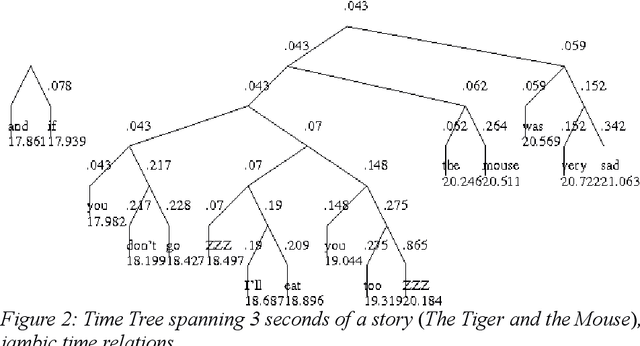
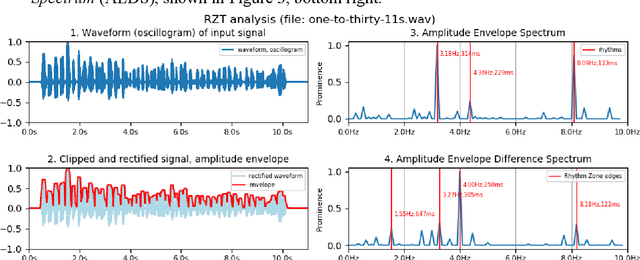
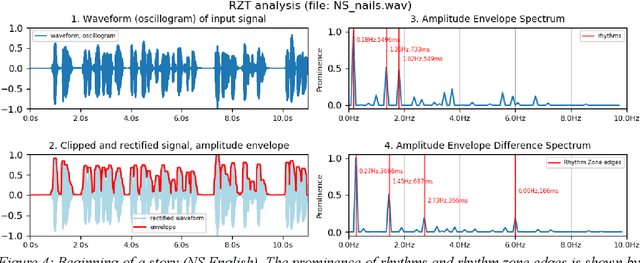
Speech rhythms have been dealt with in three main ways: from the introspective analyses of rhythm as a correlate of syllable and foot timing in linguistics and applied linguistics, through analyses of durations of segments of utterances associated with consonantal and vocalic properties, syllables, feet and words, to models of rhythms in speech production and perception as physical oscillations. The present study avoids introspection and human-filtered annotation methods and extends the signal processing paradigm of amplitude envelope spectrum analysis by adding an additional analytic step of edge detection, and postulating the co-existence of multiple speech rhythms in rhythm zones marked by identifiable edges (Rhythm Zone Theory, RZT). An exploratory investigation of the utility of RZT is conducted, suggesting that native and non-native readings of the same text are distinct sub-genres of read speech: a reading by a US native speaker and non-native readings by relatively low-performing Cantonese adult learners of English. The study concludes by noting that with the methods used, RZT can distinguish between the speech rhythms of well-defined sub-genres of native speaker reading vs. non-native learner reading, but needs further refinement in order to be applied to the paradoxically more complex speech of low-performing language learners, whose speech rhythms are co-determined by non-fluency and disfluency factors in addition to well-known linguistic factors of grammar, vocabulary and discourse constraints.
Gender in Danger? Evaluating Speech Translation Technology on the MuST-SHE Corpus
Jun 10, 2020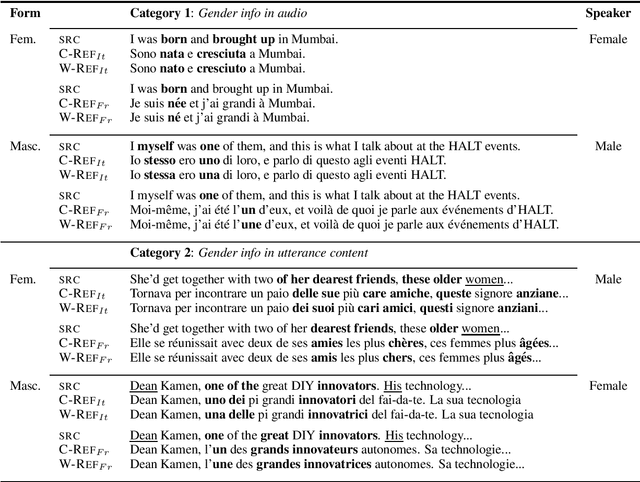
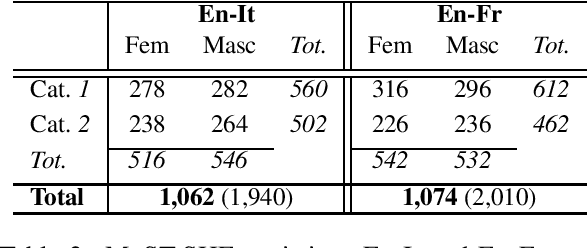
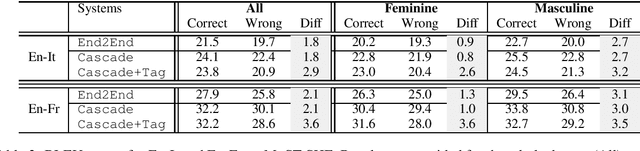
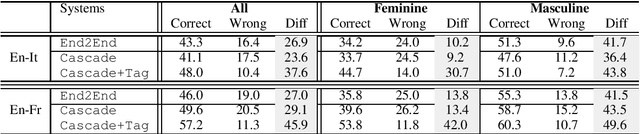
Translating from languages without productive grammatical gender like English into gender-marked languages is a well-known difficulty for machines. This difficulty is also due to the fact that the training data on which models are built typically reflect the asymmetries of natural languages, gender bias included. Exclusively fed with textual data, machine translation is intrinsically constrained by the fact that the input sentence does not always contain clues about the gender identity of the referred human entities. But what happens with speech translation, where the input is an audio signal? Can audio provide additional information to reduce gender bias? We present the first thorough investigation of gender bias in speech translation, contributing with: i) the release of a benchmark useful for future studies, and ii) the comparison of different technologies (cascade and end-to-end) on two language directions (English-Italian/French).
On The Robustness of Offensive Language Classifiers
Mar 21, 2022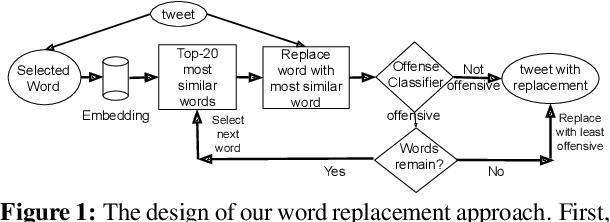
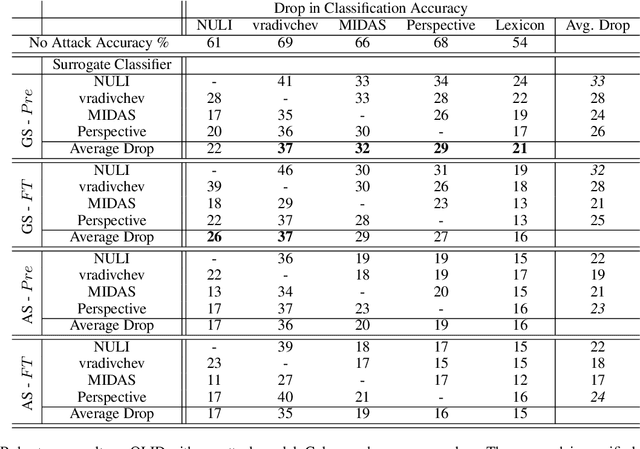
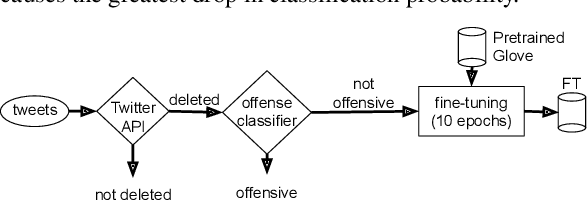
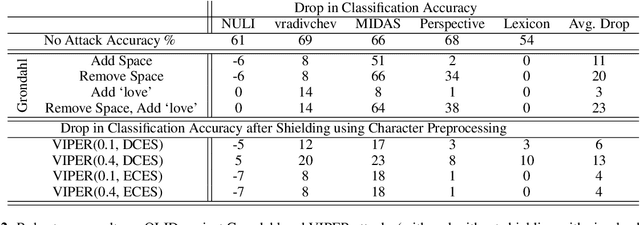
Social media platforms are deploying machine learning based offensive language classification systems to combat hateful, racist, and other forms of offensive speech at scale. However, despite their real-world deployment, we do not yet comprehensively understand the extent to which offensive language classifiers are robust against adversarial attacks. Prior work in this space is limited to studying robustness of offensive language classifiers against primitive attacks such as misspellings and extraneous spaces. To address this gap, we systematically analyze the robustness of state-of-the-art offensive language classifiers against more crafty adversarial attacks that leverage greedy- and attention-based word selection and context-aware embeddings for word replacement. Our results on multiple datasets show that these crafty adversarial attacks can degrade the accuracy of offensive language classifiers by more than 50% while also being able to preserve the readability and meaning of the modified text.
Data Efficient Direct Speech-to-Text Translation with Modality Agnostic Meta-Learning
Nov 11, 2019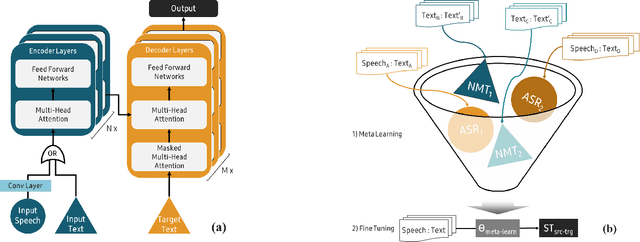

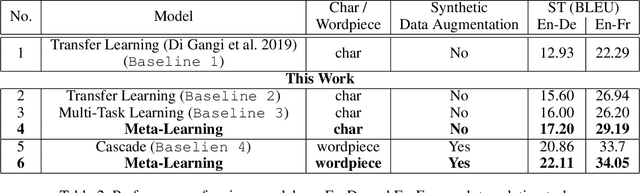
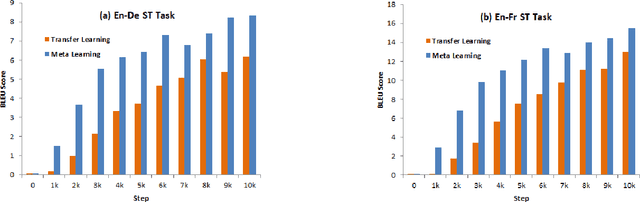
End-to-end Speech Translation (ST) models have several advantages such as lower latency, smaller model size, and less error compounding over conventional pipelines that combine Automatic Speech Recognition (ASR) and text Machine Translation (MT) models. However, collecting large amounts of parallel data for ST task is more difficult compared to the ASR and MT tasks. Previous studies have proposed the use of transfer learning approaches to overcome the above difficulty. These approaches benefit from weakly supervised training data, such as ASR speech-to-transcript or MT text-to-text translation pairs. However, the parameters in these models are updated independently of each task, which may lead to sub-optimal solutions. In this work, we adopt a meta-learning algorithm to train a modality agnostic multi-task model that transfers knowledge from source tasks=ASR+MT to target task=ST where ST task severely lacks data. In the meta-learning phase, the parameters of the model are exposed to vast amounts of speech transcripts (e.g., English ASR) and text translations (e.g., English-German MT). During this phase, parameters are updated in such a way to understand speech, text representations, the relation between them, as well as act as a good initialization point for the target ST task. We evaluate the proposed meta-learning approach for ST tasks on English-German (En-De) and English-French (En-Fr) language pairs from the Multilingual Speech Translation Corpus (MuST-C). Our method outperforms the previous transfer learning approaches and sets new state-of-the-art results for En-De and En-Fr ST tasks by obtaining 9.18, and 11.76 BLEU point improvements, respectively.
Neural Pitch-Shifting and Time-Stretching with Controllable LPCNet
Oct 05, 2021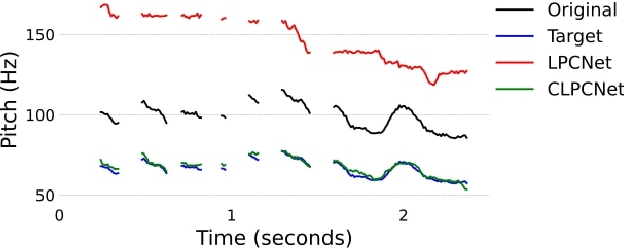
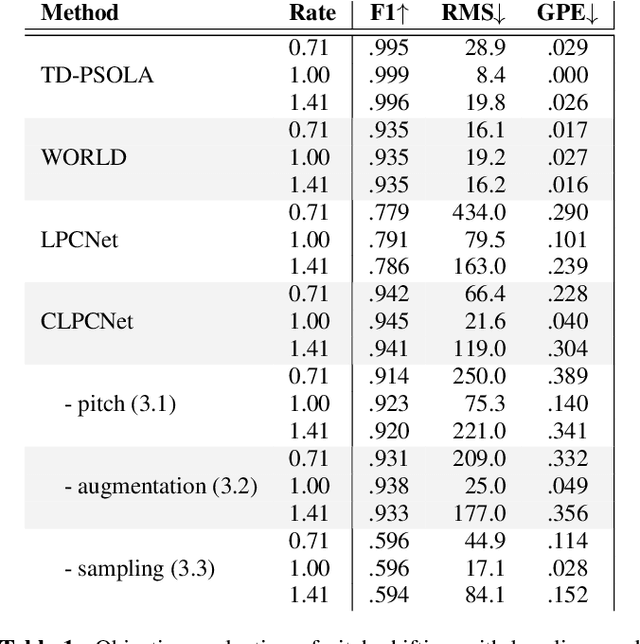
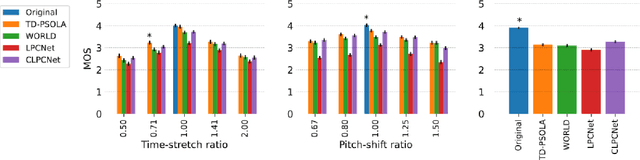
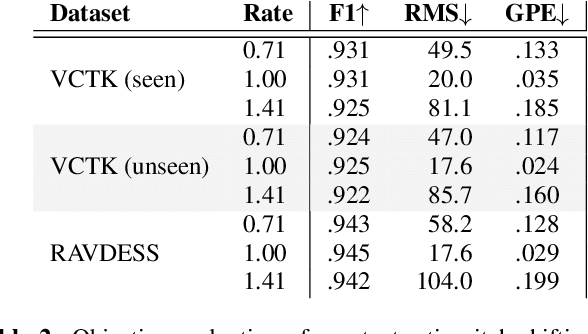
Modifying the pitch and timing of an audio signal are fundamental audio editing operations with applications in speech manipulation, audio-visual synchronization, and singing voice editing and synthesis. Thus far, methods for pitch-shifting and time-stretching that use digital signal processing (DSP) have been favored over deep learning approaches due to their speed and relatively higher quality. However, even existing DSP-based methods for pitch-shifting and time-stretching induce artifacts that degrade audio quality. In this paper, we propose Controllable LPCNet (CLPCNet), an improved LPCNet vocoder capable of pitch-shifting and time-stretching of speech. For objective evaluation, we show that CLPCNet performs pitch-shifting of speech on unseen datasets with high accuracy relative to prior neural methods. For subjective evaluation, we demonstrate that the quality and naturalness of pitch-shifting and time-stretching with CLPCNet on unseen datasets meets or exceeds competitive neural- or DSP-based approaches.
PhyAAt: Physiology of Auditory Attention to Speech Dataset
May 23, 2020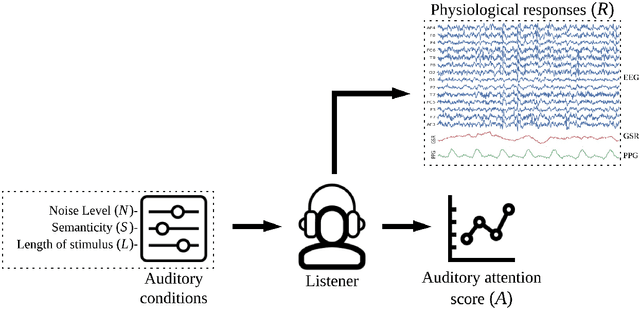
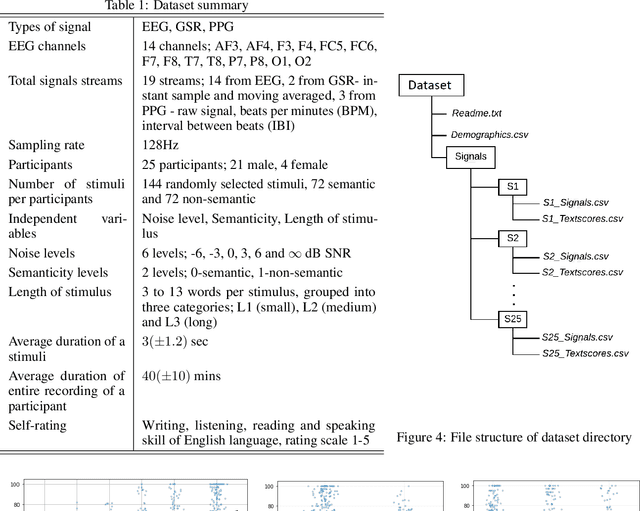
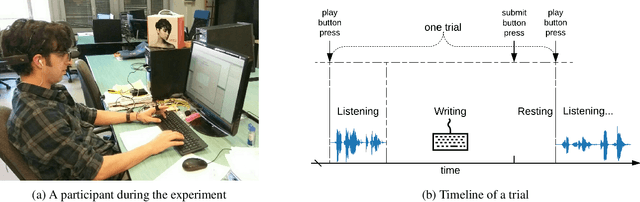
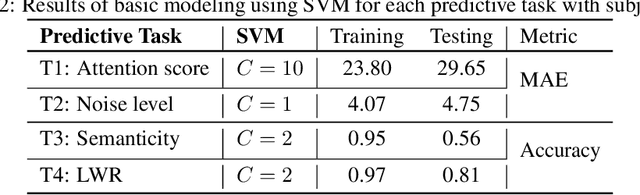
Auditory attention to natural speech is a complex brain process. Its quantification from physiological signals can be valuable to improving and widening the range of applications of current brain-computer-interface systems, however it remains a challenging task. In this article, we present a dataset of physiological signals collected from an experiment on auditory attention to natural speech. In this experiment, auditory stimuli consisting of reproductions of English sentences in different auditory conditions were presented to 25 non-native participants, who were asked to transcribe the sentences. During the experiment, 14 channel electroencephalogram, galvanic skin response, and photoplethysmogram signals were collected from each participant. Based on the number of correctly transcribed words, an attention score was obtained for each auditory stimulus presented to subjects. A strong correlation ($p<<0.0001$) between the attention score and the auditory conditions was found. We also formulate four different predictive tasks involving the collected dataset and develop a feature extraction framework. The results for each predictive task are obtained using a Support Vector Machine with spectral features, and are better than chance level. The dataset has been made publicly available for further research, along with a python library - phyaat to facilitate the preprocessing, modeling, and reproduction of the results presented in this paper. The dataset and other resources are shared on webpage - https://phyaat.github.io.
LPCNet: Improving Neural Speech Synthesis Through Linear Prediction
Oct 28, 2018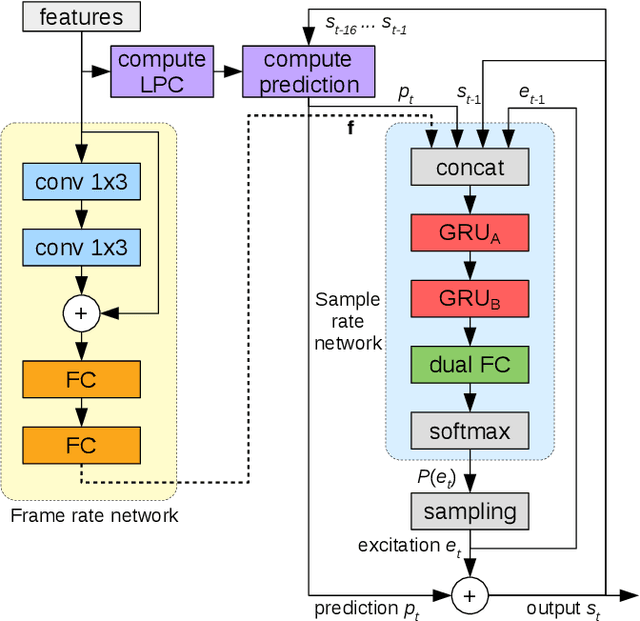
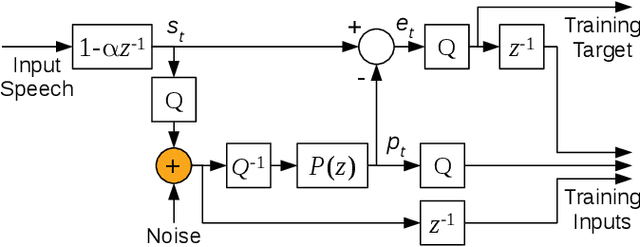
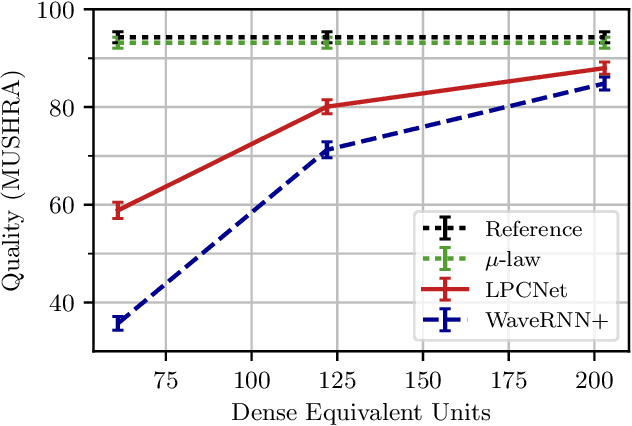
Neural speech synthesis models have recently demonstrated the ability to synthesize high quality speech for text-to-speech and compression applications. These new models often require powerful GPUs to achieve real-time operation, so being able to reduce their complexity would open the way for many new applications. We propose LPCNet, a WaveRNN variant that combines linear prediction with recurrent neural networks to significantly improve the efficiency of speech synthesis. We demonstrate that LPCNet can achieve significantly higher quality than WaveRNN for the same network size and that high quality LPCNet speech synthesis is achievable with a complexity under 3 GFLOPS. This makes it easier to deploy neural synthesis applications on lower-power devices, such as embedded systems and mobile phones.
Automatic Fake News Detection: Are current models "fact-checking" or "gut-checking"?
Apr 14, 2022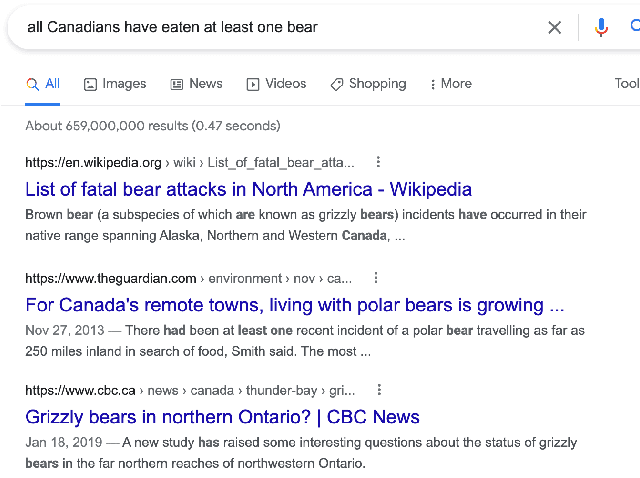
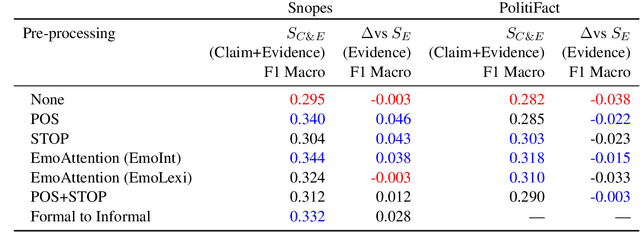
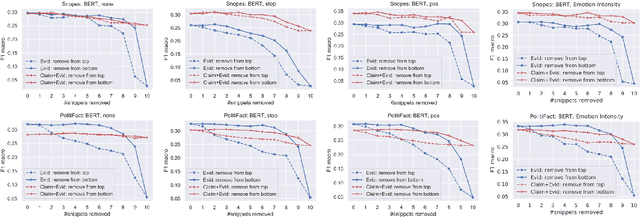
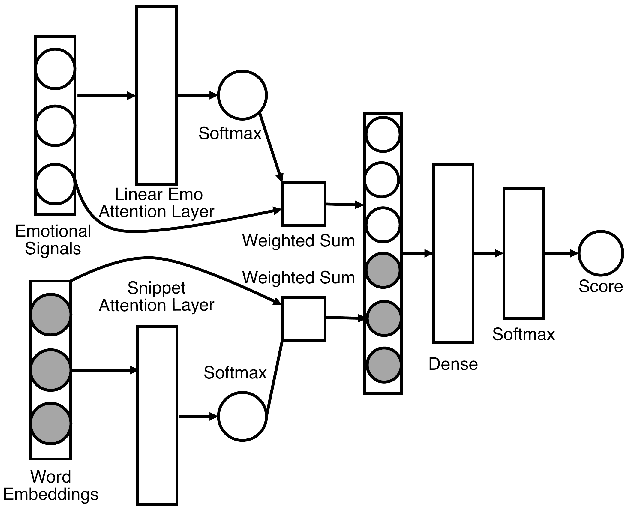
Automatic fake news detection models are ostensibly based on logic, where the truth of a claim made in a headline can be determined by supporting or refuting evidence found in a resulting web query. These models are believed to be reasoning in some way; however, it has been shown that these same results, or better, can be achieved without considering the claim at all -- only the evidence. This implies that other signals are contained within the examined evidence, and could be based on manipulable factors such as emotion, sentiment, or part-of-speech (POS) frequencies, which are vulnerable to adversarial inputs. We neutralize some of these signals through multiple forms of both neural and non-neural pre-processing and style transfer, and find that this flattening of extraneous indicators can induce the models to actually require both claims and evidence to perform well. We conclude with the construction of a model using emotion vectors built off a lexicon and passed through an "emotional attention" mechanism to appropriately weight certain emotions. We provide quantifiable results that prove our hypothesis that manipulable features are being used for fact-checking.
Investigating the Lombard Effect Influence on End-to-End Audio-Visual Speech Recognition
Jul 09, 2019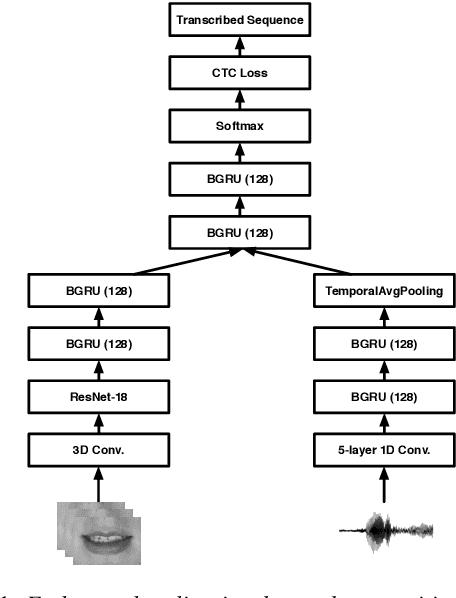

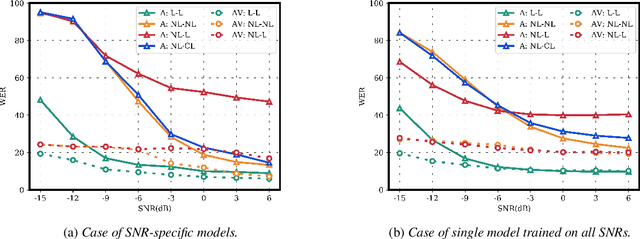
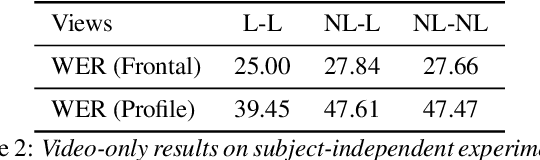
Several audio-visual speech recognition models have been recently proposed which aim to improve the robustness over audio-only models in the presence of noise. However, almost all of them ignore the impact of the Lombard effect, i.e., the change in speaking style in noisy environments which aims to make speech more intelligible and affects both the acoustic characteristics of speech and the lip movements. In this paper, we investigate the impact of the Lombard effect in audio-visual speech recognition. To the best of our knowledge, this is the first work which does so using end-to-end deep architectures and presents results on unseen speakers. Our results show that properly modelling Lombard speech is always beneficial. Even if a relatively small amount of Lombard speech is added to the training set then the performance in a real scenario, where noisy Lombard speech is present, can be significantly improved. We also show that the standard approach followed in the literature, where a model is trained and tested on noisy plain speech, provides a correct estimate of the video-only performance and slightly underestimates the audio-visual performance. In case of audio-only approaches, performance is overestimated for SNRs higher than -3dB and underestimated for lower SNRs.