 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Understanding Audio Features via Trainable Basis Functions
Apr 25, 2022
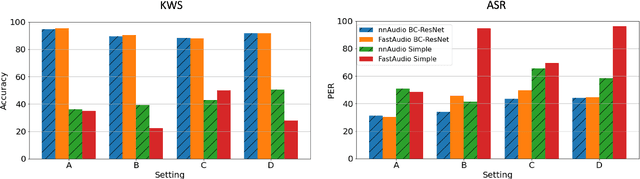

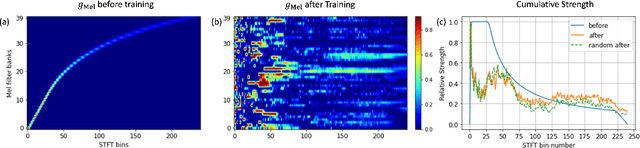
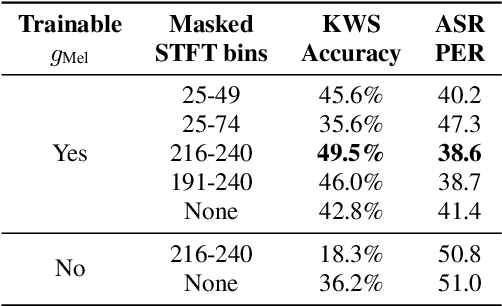
In this paper we explore the possibility of maximizing the information represented in spectrograms by making the spectrogram basis functions trainable. We experiment with two different tasks, namely keyword spotting (KWS) and automatic speech recognition (ASR). For most neural network models, the architecture and hyperparameters are typically fine-tuned and optimized in experiments. Input features, however, are often treated as fixed. In the case of audio, signals can be mainly expressed in two main ways: raw waveforms (time-domain) or spectrograms (time-frequency-domain). In addition, different spectrogram types are often used and tailored to fit different applications. In our experiments, we allow for this tailoring directly as part of the network. Our experimental results show that using trainable basis functions can boost the accuracy of Keyword Spotting (KWS) by 14.2 percentage points, and lower the Phone Error Rate (PER) by 9.5 percentage points. Although models using trainable basis functions become less effective as the model complexity increases, the trained filter shapes could still provide us with insights on which frequency bins are important for that specific task. From our experiments, we can conclude that trainable basis functions are a useful tool to boost the performance when the model complexity is limited.
Probabilistic Spherical Discriminant Analysis: An Alternative to PLDA for length-normalized embeddings
Mar 28, 2022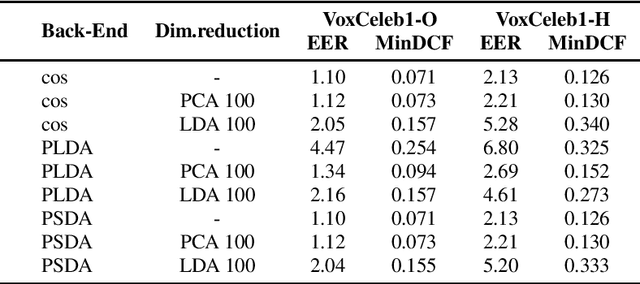
In speaker recognition, where speech segments are mapped to embeddings on the unit hypersphere, two scoring backends are commonly used, namely cosine scoring or PLDA. Both have advantages and disadvantages, depending on the context. Cosine scoring follows naturally from the spherical geometry, but for PLDA the blessing is mixed -- length normalization Gaussianizes the between-speaker distribution, but violates the assumption of a speaker-independent within-speaker distribution. We propose PSDA, an analogue to PLDA that uses Von Mises-Fisher distributions on the hypersphere for both within and between-class distributions. We show how the self-conjugacy of this distribution gives closed-form likelihood-ratio scores, making it a drop-in replacement for PLDA at scoring time. All kinds of trials can be scored, including single-enroll and multi-enroll verification, as well as more complex likelihood-ratios that could be used in clustering and diarization. Learning is done via an EM-algorithm with closed-form updates. We explain the model and present some first experiments.
Assessing Progress of Parkinson s Disease Using Acoustic Analysis of Phonation
Mar 17, 2022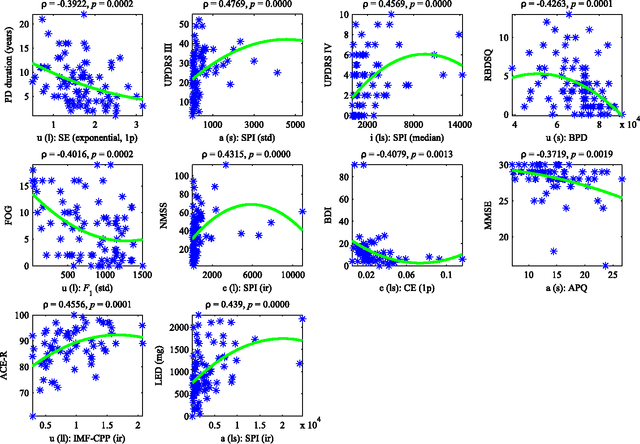
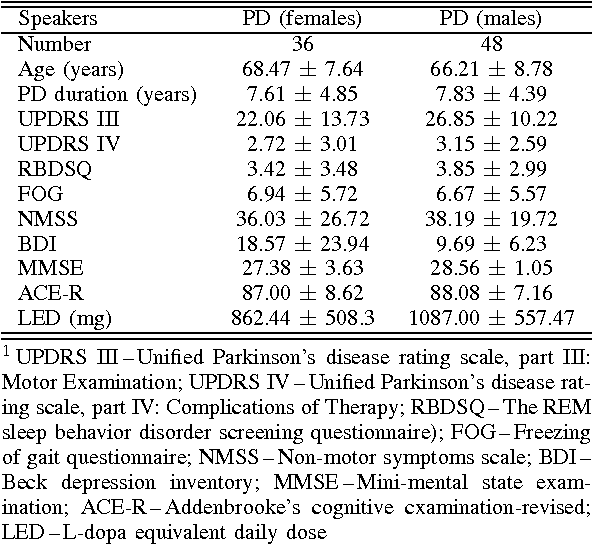
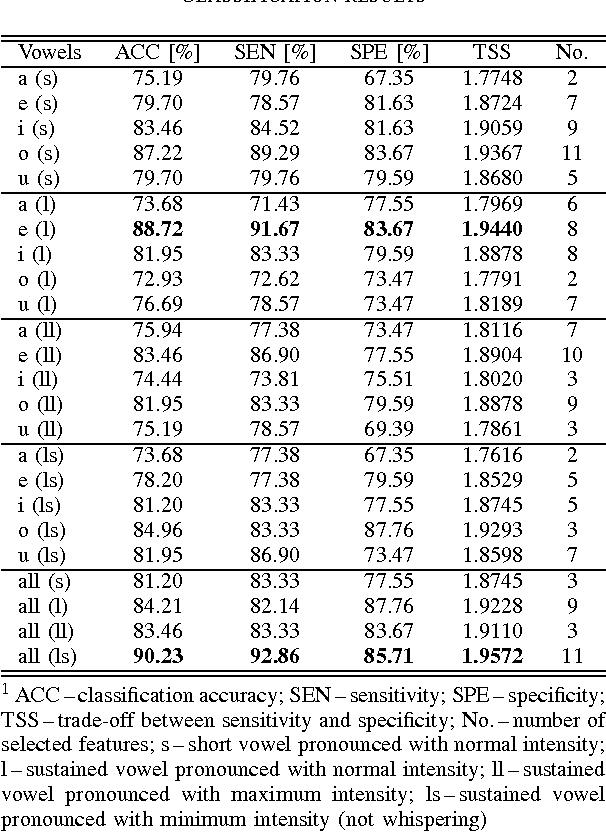
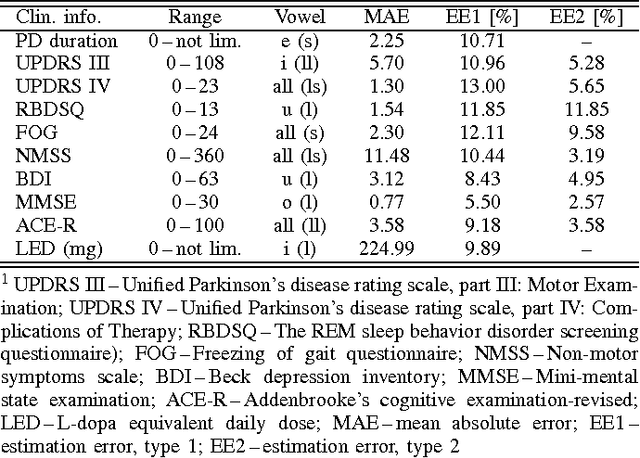
This paper deals with a complex acoustic analysis of phonation in patients with Parkinson's disease (PD) with a special focus on estimation of disease progress that is described by 7 different clinical scales ,e. g. Unified Parkinson's disease rating scale or Beck depression inventory. The analysis is based on parametrization of 5 Czech vowels pronounced by 84 PD patients. Using classification and regression trees we estimated all clinical scores with maximal error lower or equal to 13 %. Best estimation was observed in the case of Mini-mental state examination (MAE = 0.77, estimation error 5.50 %. Finally, we proposed a binary classification based on random forests that is able to identify Parkinson's disease with sensitivity SEN = 92.86 % (SPE = 85.71 %). The parametrization process was based on extraction of 107 speech features quantifying different clinical signs of hypokinetic dysarthria present in PD.
* 8 pages published in the 4th IEEE IWOBI 2015, pp. 115-122, 10-12 June, 2015 Donostia-San Sebastian. ISBN: 978-84-606-8733-7
Robust Unsupervised Audio-visual Speech Enhancement Using a Mixture of Variational Autoencoders
Nov 10, 2019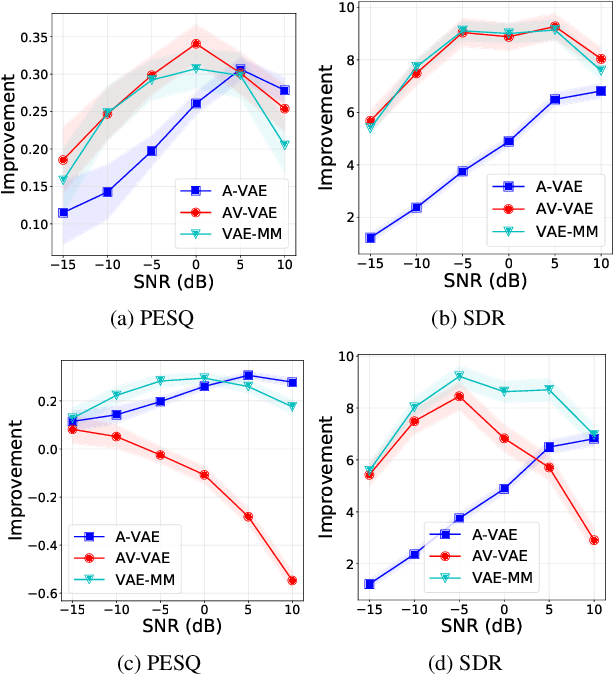
Recently, an audio-visual speech generative model based on variational autoencoder (VAE) has been proposed, which is combined with a nonnegative matrix factorization (NMF) model for noise variance to perform unsupervised speech enhancement. When visual data is clean, speech enhancement with audio-visual VAE shows a better performance than with audio-only VAE, which is trained on audio-only data. However, audio-visual VAE is not robust against noisy visual data, e.g., when for some video frames, speaker face is not frontal or lips region is occluded. In this paper, we propose a robust unsupervised audio-visual speech enhancement method based on a per-frame VAE mixture model. This mixture model consists of a trained audio-only VAE and a trained audio-visual VAE. The motivation is to skip noisy visual frames by switching to the audio-only VAE model. We present a variational expectation-maximization method to estimate the parameters of the model. Experiments show the promising performance of the proposed method.
Learning to detect dysarthria from raw speech
Nov 27, 2018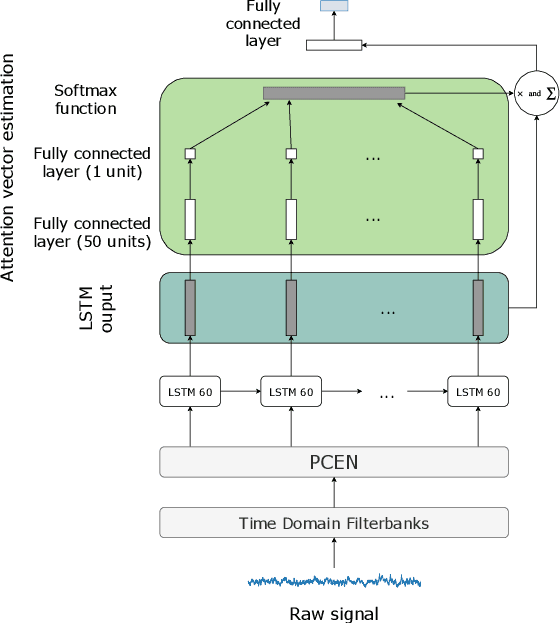
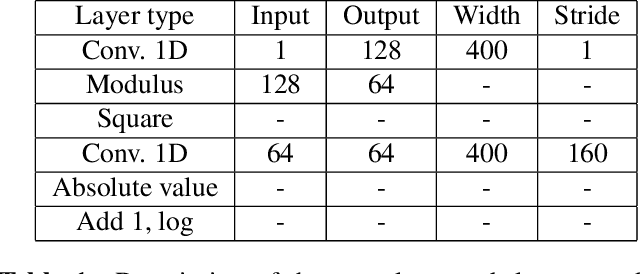

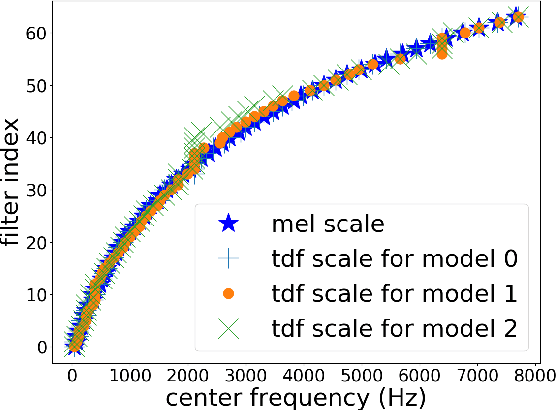
Speech classifiers of paralinguistic traits traditionally learn from diverse hand-crafted low-level features, by selecting the relevant information for the task at hand. We explore an alternative to this selection, by learning jointly the classifier, and the feature extraction. Recent work on speech recognition has shown improved performance over speech features by learning from the waveform. We extend this approach to paralinguistic classification and propose a neural network that can learn a filterbank, a normalization factor and a compression power from the raw speech, jointly with the rest of the architecture. We apply this model to dysarthria detection from sentence-level audio recordings. Starting from a strong attention-based baseline on which mel-filterbanks outperform standard low-level descriptors, we show that learning the filters or the normalization and compression improves over fixed features by 10% absolute accuracy. We also observe a gain over OpenSmile features by learning jointly the feature extraction, the normalization, and the compression factor with the architecture. This constitutes a first attempt at learning jointly all these operations from raw audio for a speech classification task.
Audio-Visual Synchronisation in the wild
Dec 08, 2021

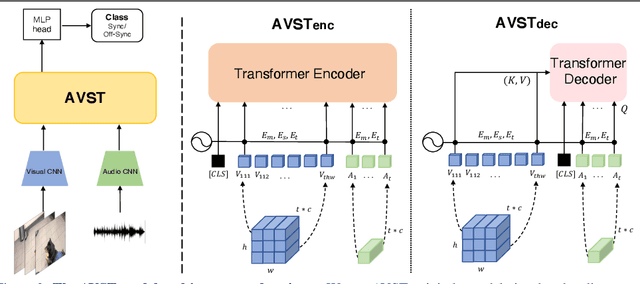
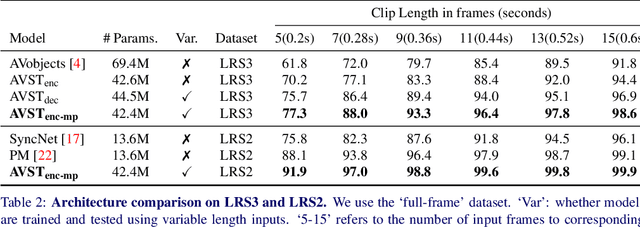
In this paper, we consider the problem of audio-visual synchronisation applied to videos `in-the-wild' (ie of general classes beyond speech). As a new task, we identify and curate a test set with high audio-visual correlation, namely VGG-Sound Sync. We compare a number of transformer-based architectural variants specifically designed to model audio and visual signals of arbitrary length, while significantly reducing memory requirements during training. We further conduct an in-depth analysis on the curated dataset and define an evaluation metric for open domain audio-visual synchronisation. We apply our method on standard lip reading speech benchmarks, LRS2 and LRS3, with ablations on various aspects. Finally, we set the first benchmark for general audio-visual synchronisation with over 160 diverse classes in the new VGG-Sound Sync video dataset. In all cases, our proposed model outperforms the previous state-of-the-art by a significant margin.
Sequence-To-Sequence Voice Conversion using F0 and Time Conditioning and Adversarial Learning
Oct 07, 2021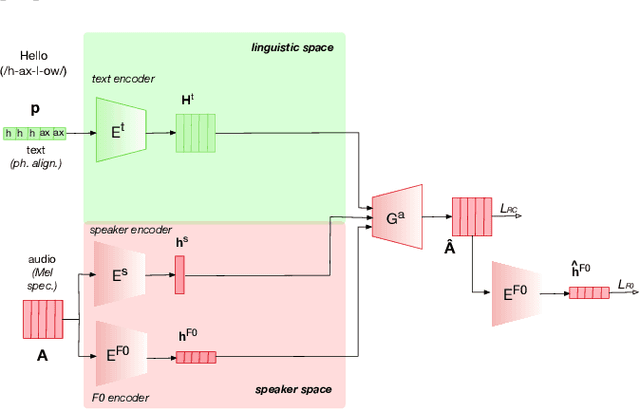
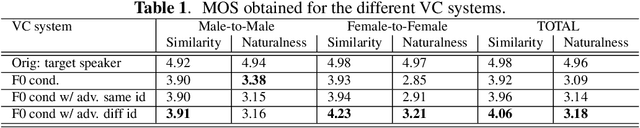
This paper presents a sequence-to-sequence voice conversion (S2S-VC) algorithm which allows to preserve some aspects of the source speaker during conversion, typically its prosody, which is useful in many real-life application of voice conversion. In S2S-VC, the decoder is usually conditioned on linguistic and speaker embeddings only, with the consequence that only the linguistic content is actually preserved during conversion. In the proposed S2S-VC architecture, the decoder is conditioned explicitly on the desired F0 sequence so that the converted speech has the same F0 as the one of the source speaker, or any F0 defined arbitrarily. Moreover, an adversarial module is further employed so that the S2S-VC is not only optimized on the available true speech samples, but can also take efficiently advantage of the converted speech samples that can be produced by using various conditioning such as speaker identity, F0, or timing.
Minimum Word Error Rate Training with Language Model Fusion for End-to-End Speech Recognition
Jun 04, 2021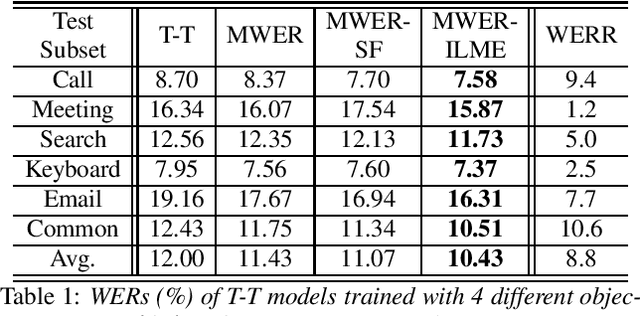
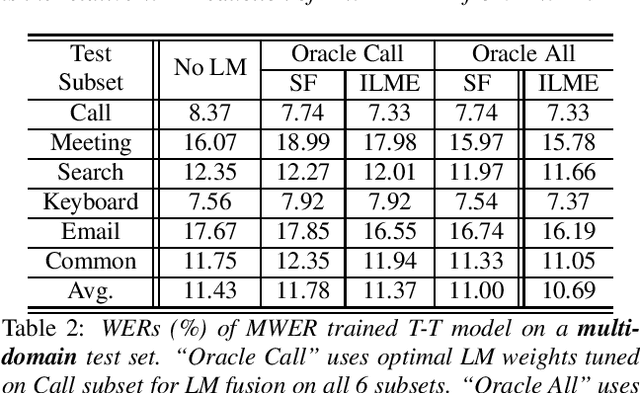
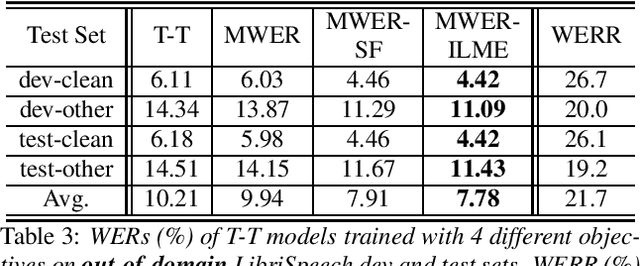
Integrating external language models (LMs) into end-to-end (E2E) models remains a challenging task for domain-adaptive speech recognition. Recently, internal language model estimation (ILME)-based LM fusion has shown significant word error rate (WER) reduction from Shallow Fusion by subtracting a weighted internal LM score from an interpolation of E2E model and external LM scores during beam search. However, on different test sets, the optimal LM interpolation weights vary over a wide range and have to be tuned extensively on well-matched validation sets. In this work, we perform LM fusion in the minimum WER (MWER) training of an E2E model to obviate the need for LM weights tuning during inference. Besides MWER training with Shallow Fusion (MWER-SF), we propose a novel MWER training with ILME (MWER-ILME) where the ILME-based fusion is conducted to generate N-best hypotheses and their posteriors. Additional gradient is induced when internal LM is engaged in MWER-ILME loss computation. During inference, LM weights pre-determined in MWER training enable robust LM integrations on test sets from different domains. Experimented with 30K-hour trained transformer transducers, MWER-ILME achieves on average 8.8% and 5.8% relative WER reductions from MWER and MWER-SF training, respectively, on 6 different test sets
* 5 pages, Interspeech 2021
New Insights on Target Speaker Extraction
Feb 01, 2022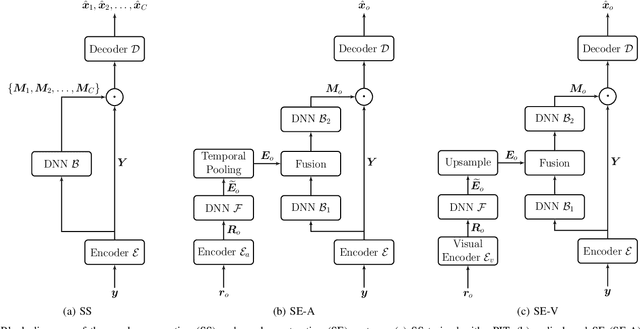
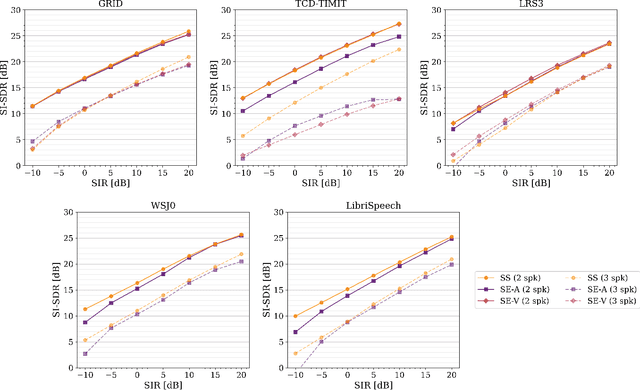
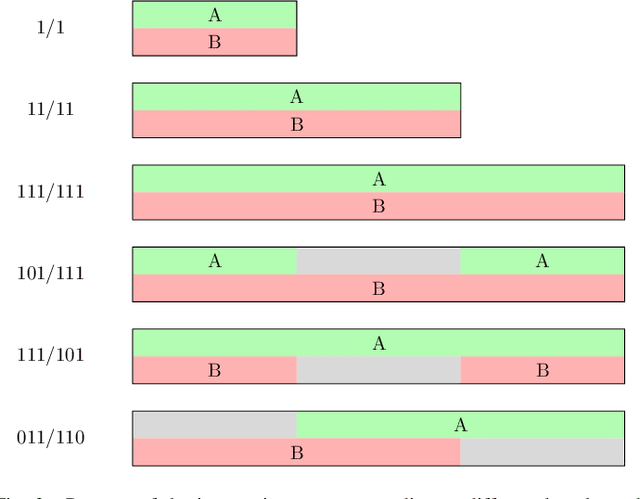
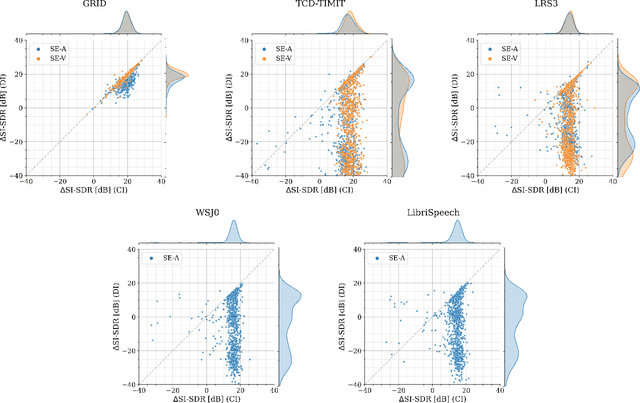
In recent years, researchers have become increasingly interested in speaker extraction (SE), which is the task of extracting the speech of a target speaker from a mixture of interfering speakers with the help of auxiliary information about the target speaker. Several forms of auxiliary information have been employed in single-channel SE, such as a speech snippet enrolled from the target speaker or visual information corresponding to the spoken utterance. Many SE studies have reported performance improvement compared to speaker separation (SS) methods with oracle selection, arguing that this is due to the use of auxiliary information. However, such works have not considered state-of-the-art SS methods that have shown impressive separation performance. In this paper, we revise and examine the role of the auxiliary information in SE. Specifically, we compare the performance of two SE systems (audio-based and video-based) with SS using a common framework that utilizes the state-of-the-art dual-path recurrent neural network as the main learning machine. In addition, we study how much the considered SE systems rely on the auxiliary information by analyzing the systems' output for random auxiliary signals. Experimental evaluation on various datasets suggests that the main purpose of the auxiliary information in the considered SE systems is only to specify the target speaker in the mixture and that it does not provide consistent extraction performance gain when compared to the uninformed SS system.
SoK: The Faults in our ASRs: An Overview of Attacks against Automatic Speech Recognition and Speaker Identification Systems
Jul 21, 2020
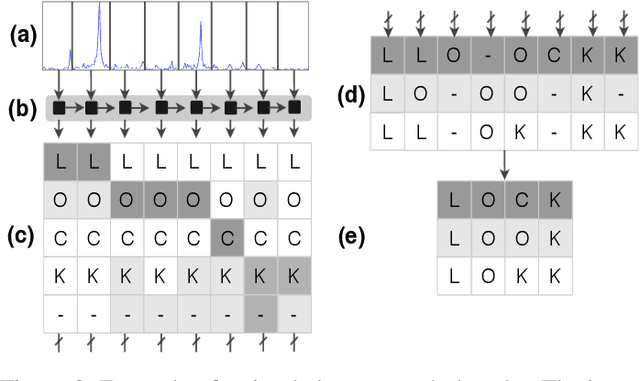
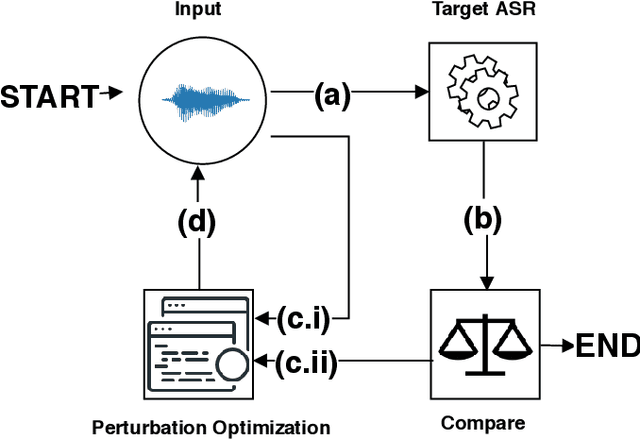
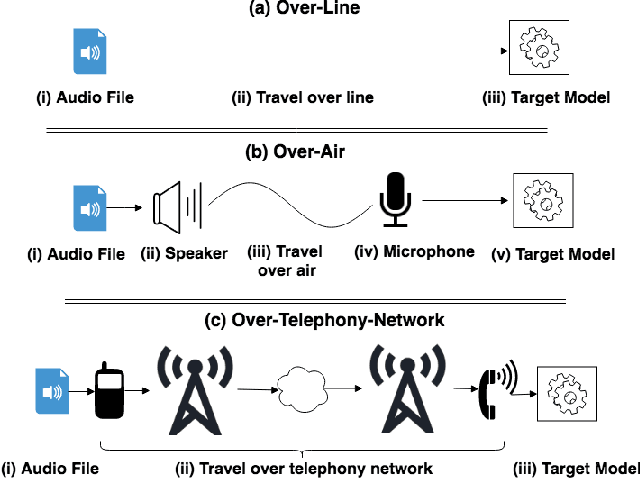
Speech and speaker recognition systems are employed in a variety of applications, from personal assistants to telephony surveillance and biometric authentication. The wide deployment of these systems has been made possible by the improved accuracy in neural networks. Like other systems based on neural networks, recent research has demonstrated that speech and speaker recognition systems are vulnerable to attacks using manipulated inputs. However, as we demonstrate in this paper, the end-to-end architecture of speech and speaker systems and the nature of their inputs make attacks and defenses against them substantially different than those in the image space. We demonstrate this first by systematizing existing research in this space and providing a taxonomy through which the community can evaluate future work. We then demonstrate experimentally that attacks against these models almost universally fail to transfer. In so doing, we argue that substantial additional work is required to provide adequate mitigations in this space.