 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Evaluating Self-supervised Speech Models on a Taiwanese Hokkien Corpus
Dec 06, 2023
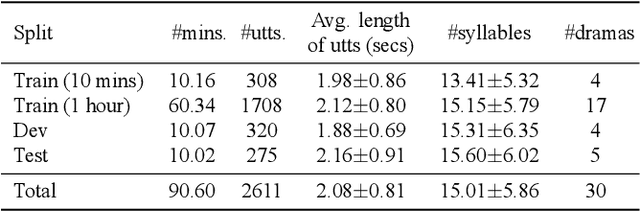
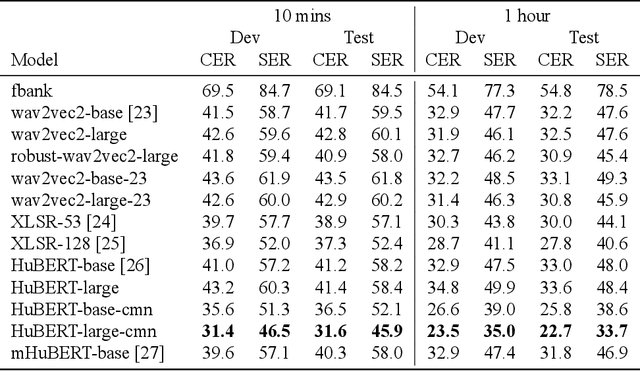
Taiwanese Hokkien is declining in use and status due to a language shift towards Mandarin in Taiwan. This is partly why it is a low resource language in NLP and speech research today. To ensure that the state of the art in speech processing does not leave Taiwanese Hokkien behind, we contribute a 1.5-hour dataset of Taiwanese Hokkien to ML-SUPERB's hidden set. Evaluating ML-SUPERB's suite of self-supervised learning (SSL) speech representations on our dataset, we find that model size does not consistently determine performance. In fact, certain smaller models outperform larger ones. Furthermore, linguistic alignment between pretraining data and the target language plays a crucial role.
Self-supervised Adaptive Pre-training of Multilingual Speech Models for Language and Dialect Identification
Dec 12, 2023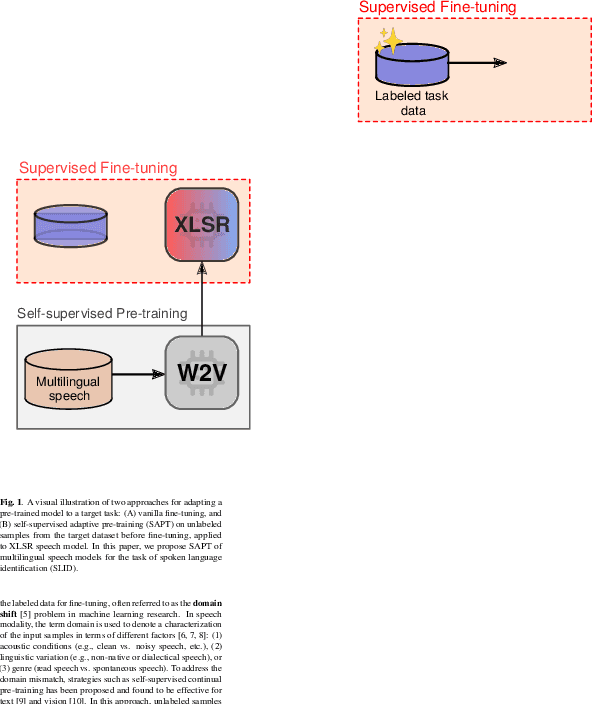
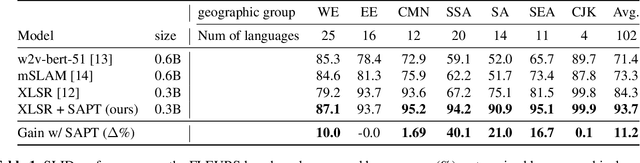
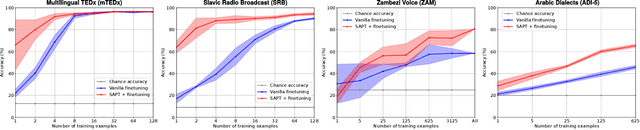
Pre-trained Transformer-based speech models have shown striking performance when fine-tuned on various downstream tasks such as automatic speech recognition and spoken language identification (SLID). However, the problem of domain mismatch remains a challenge in this area, where the domain of the pre-training data might differ from that of the downstream labeled data used for fine-tuning. In multilingual tasks such as SLID, the pre-trained speech model may not support all the languages in the downstream task. To address this challenge, we propose self-supervised adaptive pre-training (SAPT) to adapt the pre-trained model to the target domain and languages of the downstream task. We apply SAPT to the XLSR-128 model and investigate the effectiveness of this approach for the SLID task. First, we demonstrate that SAPT improves XLSR performance on the FLEURS benchmark with substantial gains up to 40.1% for under-represented languages. Second, we apply SAPT on four different datasets in a few-shot learning setting, showing that our approach improves the sample efficiency of XLSR during fine-tuning. Our experiments provide strong empirical evidence that continual adaptation via self-supervision improves downstream performance for multilingual speech models.
Resource-constrained stereo singing voice cancellation
Jan 22, 2024We study the problem of stereo singing voice cancellation, a subtask of music source separation, whose goal is to estimate an instrumental background from a stereo mix. We explore how to achieve performance similar to large state-of-the-art source separation networks starting from a small, efficient model for real-time speech separation. Such a model is useful when memory and compute are limited and singing voice processing has to run with limited look-ahead. In practice, this is realised by adapting an existing mono model to handle stereo input. Improvements in quality are obtained by tuning model parameters and expanding the training set. Moreover, we highlight the benefits a stereo model brings by introducing a new metric which detects attenuation inconsistencies between channels. Our approach is evaluated using objective offline metrics and a large-scale MUSHRA trial, confirming the effectiveness of our techniques in stringent listening tests.
Keyword spotting -- Detecting commands in speech using deep learning
Dec 09, 2023
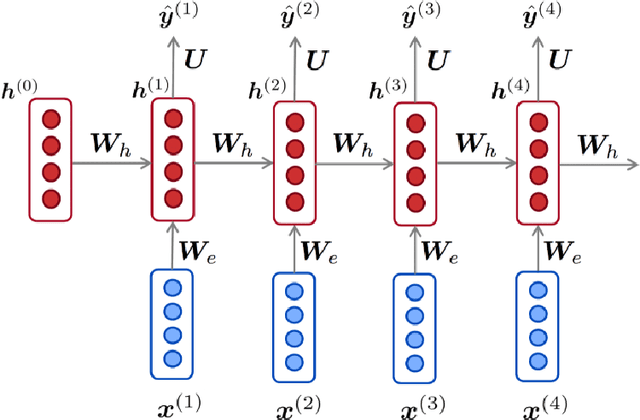
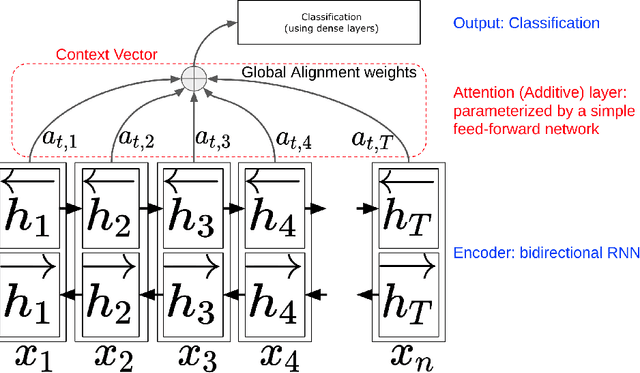
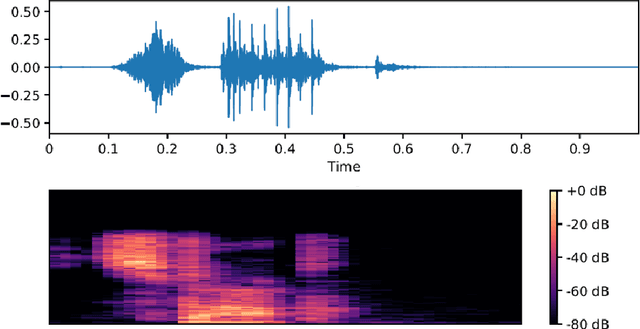
Speech recognition has become an important task in the development of machine learning and artificial intelligence. In this study, we explore the important task of keyword spotting using speech recognition machine learning and deep learning techniques. We implement feature engineering by converting raw waveforms to Mel Frequency Cepstral Coefficients (MFCCs), which we use as inputs to our models. We experiment with several different algorithms such as Hidden Markov Model with Gaussian Mixture, Convolutional Neural Networks and variants of Recurrent Neural Networks including Long Short-Term Memory and the Attention mechanism. In our experiments, RNN with BiLSTM and Attention achieves the best performance with an accuracy of 93.9 %
E-chat: Emotion-sensitive Spoken Dialogue System with Large Language Models
Jan 06, 2024This study focuses on emotion-sensitive spoken dialogue in human-machine speech interaction. With the advancement of Large Language Models (LLMs), dialogue systems can handle multimodal data, including audio. Recent models have enhanced the understanding of complex audio signals through the integration of various audio events. However, they are unable to generate appropriate responses based on emotional speech. To address this, we introduce the Emotional chat Model (E-chat), a novel spoken dialogue system capable of comprehending and responding to emotions conveyed from speech. This model leverages an emotion embedding extracted by a speech encoder, combined with LLMs, enabling it to respond according to different emotional contexts. Additionally, we introduce the E-chat200 dataset, designed explicitly for emotion-sensitive spoken dialogue. In various evaluation metrics, E-chat consistently outperforms baseline LLMs, demonstrating its potential in emotional comprehension and human-machine interaction.
MLAAD: The Multi-Language Audio Anti-Spoofing Dataset
Jan 17, 2024Text-to-Speech (TTS) technology brings significant advantages, such as giving a voice to those with speech impairments, but also enables audio deepfakes and spoofs. The former mislead individuals and may propagate misinformation, while the latter undermine voice biometric security systems. AI-based detection can help to address these challenges by automatically differentiating between genuine and fabricated voice recordings. However, these models are only as good as their training data, which currently is severely limited due to an overwhelming concentration on English and Chinese audio in anti-spoofing databases, thus restricting its worldwide effectiveness. In response, this paper presents the Multi-Language Audio Anti-Spoof Dataset (MLAAD), created using 52 TTS models, comprising 19 different architectures, to generate 160.1 hours of synthetic voice in 23 different languages. We train and evaluate three state-of-the-art deepfake detection models with MLAAD, and observe that MLAAD demonstrates superior performance over comparable datasets like InTheWild or FakeOrReal when used as a training resource. Furthermore, in comparison with the renowned ASVspoof 2019 dataset, MLAAD proves to be a complementary resource. In tests across eight datasets, MLAAD and ASVspoof 2019 alternately outperformed each other, both excelling on four datasets. By publishing MLAAD and making trained models accessible via an interactive webserver , we aim to democratize antispoofing technology, making it accessible beyond the realm of specialists, thus contributing to global efforts against audio spoofing and deepfakes.
ScoreDec: A Phase-preserving High-Fidelity Audio Codec with A Generalized Score-based Diffusion Post-filter
Jan 22, 2024Although recent mainstream waveform-domain end-to-end (E2E) neural audio codecs achieve impressive coded audio quality with a very low bitrate, the quality gap between the coded and natural audio is still significant. A generative adversarial network (GAN) training is usually required for these E2E neural codecs because of the difficulty of direct phase modeling. However, such adversarial learning hinders these codecs from preserving the original phase information. To achieve human-level naturalness with a reasonable bitrate, preserve the original phase, and get rid of the tricky and opaque GAN training, we develop a score-based diffusion post-filter (SPF) in the complex spectral domain and combine our previous AudioDec with the SPF to propose ScoreDec, which can be trained using only spectral and score-matching losses. Both the objective and subjective experimental results show that ScoreDec with a 24~kbps bitrate encodes and decodes full-band 48~kHz speech with human-level naturalness and well-preserved phase information.
StreamVC: Real-Time Low-Latency Voice Conversion
Jan 05, 2024We present StreamVC, a streaming voice conversion solution that preserves the content and prosody of any source speech while matching the voice timbre from any target speech. Unlike previous approaches, StreamVC produces the resulting waveform at low latency from the input signal even on a mobile platform, making it applicable to real-time communication scenarios like calls and video conferencing, and addressing use cases such as voice anonymization in these scenarios. Our design leverages the architecture and training strategy of the SoundStream neural audio codec for lightweight high-quality speech synthesis. We demonstrate the feasibility of learning soft speech units causally, as well as the effectiveness of supplying whitened fundamental frequency information to improve pitch stability without leaking the source timbre information.
NOTSOFAR-1 Challenge: New Datasets, Baseline, and Tasks for Distant Meeting Transcription
Jan 16, 2024We introduce the first Natural Office Talkers in Settings of Far-field Audio Recordings (``NOTSOFAR-1'') Challenge alongside datasets and baseline system. The challenge focuses on distant speaker diarization and automatic speech recognition (DASR) in far-field meeting scenarios, with single-channel and known-geometry multi-channel tracks, and serves as a launch platform for two new datasets: First, a benchmarking dataset of 315 meetings, averaging 6 minutes each, capturing a broad spectrum of real-world acoustic conditions and conversational dynamics. It is recorded across 30 conference rooms, featuring 4-8 attendees and a total of 35 unique speakers. Second, a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. The tasks focus on single-device DASR, where multi-channel devices always share the same known geometry. This is aligned with common setups in actual conference rooms, and avoids technical complexities associated with multi-device tasks. It also allows for the development of geometry-specific solutions. The NOTSOFAR-1 Challenge aims to advance research in the field of distant conversational speech recognition, providing key resources to unlock the potential of data-driven methods, which we believe are currently constrained by the absence of comprehensive high-quality training and benchmarking datasets.
Leveraged Mel spectrograms using Harmonic and Percussive Components in Speech Emotion Recognition
Dec 18, 2023Speech Emotion Recognition (SER) affective technology enables the intelligent embedded devices to interact with sensitivity. Similarly, call centre employees recognise customers' emotions from their pitch, energy, and tone of voice so as to modify their speech for a high-quality interaction with customers. This work explores, for the first time, the effects of the harmonic and percussive components of Mel spectrograms in SER. We attempt to leverage the Mel spectrogram by decomposing distinguishable acoustic features for exploitation in our proposed architecture, which includes a novel feature map generator algorithm, a CNN-based network feature extractor and a multi-layer perceptron (MLP) classifier. This study specifically focuses on effective data augmentation techniques for building an enriched hybrid-based feature map. This process results in a function that outputs a 2D image so that it can be used as input data for a pre-trained CNN-VGG16 feature extractor. Furthermore, we also investigate other acoustic features such as MFCCs, chromagram, spectral contrast, and the tonnetz to assess our proposed framework. A test accuracy of 92.79% on the Berlin EMO-DB database is achieved. Our result is higher than previous works using CNN-VGG16.
* 12 pages