 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Building speech corpus with diverse voice characteristics for its prompt-based representation
Mar 20, 2024


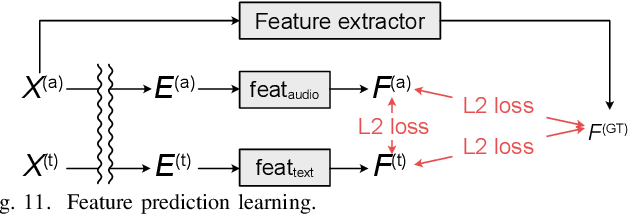
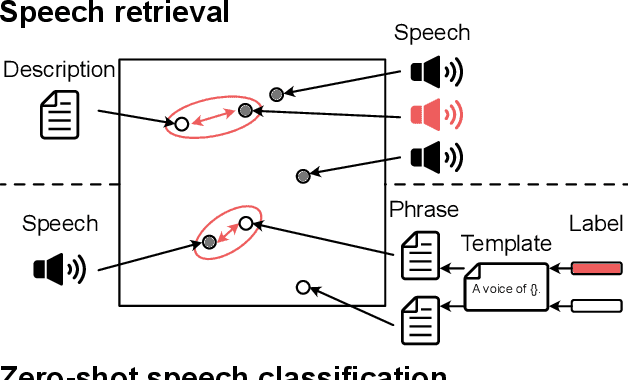
In text-to-speech synthesis, the ability to control voice characteristics is vital for various applications. By leveraging thriving text prompt-based generation techniques, it should be possible to enhance the nuanced control of voice characteristics. While previous research has explored the prompt-based manipulation of voice characteristics, most studies have used pre-recorded speech, which limits the diversity of voice characteristics available. Thus, we aim to address this gap by creating a novel corpus and developing a model for prompt-based manipulation of voice characteristics in text-to-speech synthesis, facilitating a broader range of voice characteristics. Specifically, we propose a method to build a sizable corpus pairing voice characteristics descriptions with corresponding speech samples. This involves automatically gathering voice-related speech data from the Internet, ensuring its quality, and manually annotating it using crowdsourcing. We implement this method with Japanese language data and analyze the results to validate its effectiveness. Subsequently, we propose a construction method of the model to retrieve speech from voice characteristics descriptions based on a contrastive learning method. We train the model using not only conservative contrastive learning but also feature prediction learning to predict quantitative speech features corresponding to voice characteristics. We evaluate the model performance via experiments with the corpus we constructed above.
Multi-Stage Multi-Modal Pre-Training for Automatic Speech Recognition
Mar 28, 2024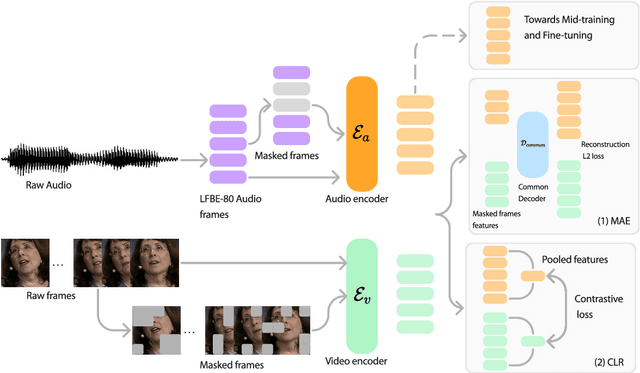
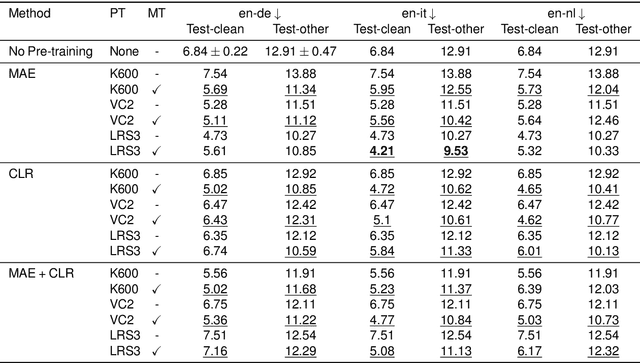
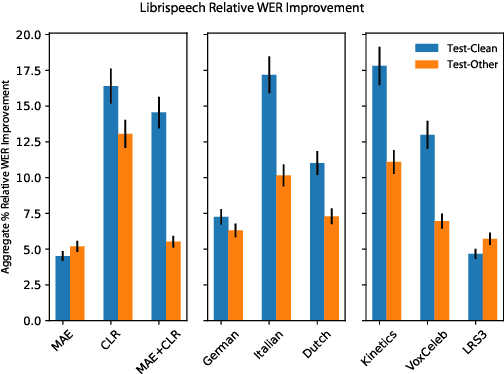
Recent advances in machine learning have demonstrated that multi-modal pre-training can improve automatic speech recognition (ASR) performance compared to randomly initialized models, even when models are fine-tuned on uni-modal tasks. Existing multi-modal pre-training methods for the ASR task have primarily focused on single-stage pre-training where a single unsupervised task is used for pre-training followed by fine-tuning on the downstream task. In this work, we introduce a novel method combining multi-modal and multi-task unsupervised pre-training with a translation-based supervised mid-training approach. We empirically demonstrate that such a multi-stage approach leads to relative word error rate (WER) improvements of up to 38.45% over baselines on both Librispeech and SUPERB. Additionally, we share several important findings for choosing pre-training methods and datasets.
Cross-Domain Audio Deepfake Detection: Dataset and Analysis
Apr 07, 2024Audio deepfake detection (ADD) is essential for preventing the misuse of synthetic voices that may infringe on personal rights and privacy. Recent zero-shot text-to-speech (TTS) models pose higher risks as they can clone voices with a single utterance. However, the existing ADD datasets are outdated, leading to suboptimal generalization of detection models. In this paper, we construct a new cross-domain ADD dataset comprising over 300 hours of speech data that is generated by five advanced zero-shot TTS models. To simulate real-world scenarios, we employ diverse attack methods and audio prompts from different datasets. Experiments show that, through novel attack-augmented training, the Wav2Vec2-large and Whisper-medium models achieve equal error rates of 4.1\% and 6.5\% respectively. Additionally, we demonstrate our models' outstanding few-shot ADD ability by fine-tuning with just one minute of target-domain data. Nonetheless, neural codec compressors greatly affect the detection accuracy, necessitating further research.
Wav2Gloss: Generating Interlinear Glossed Text from Speech
Mar 19, 2024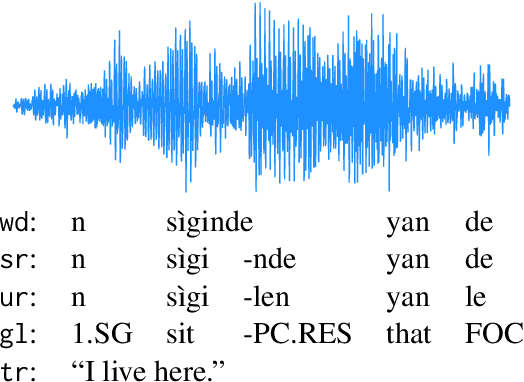
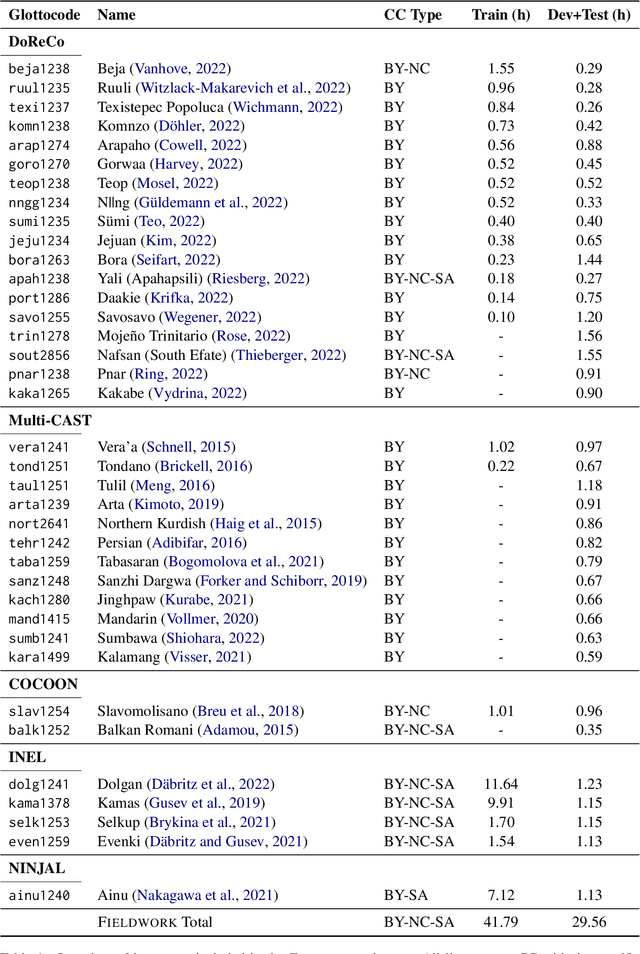
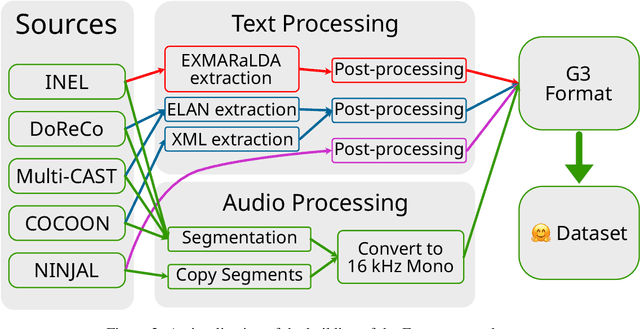
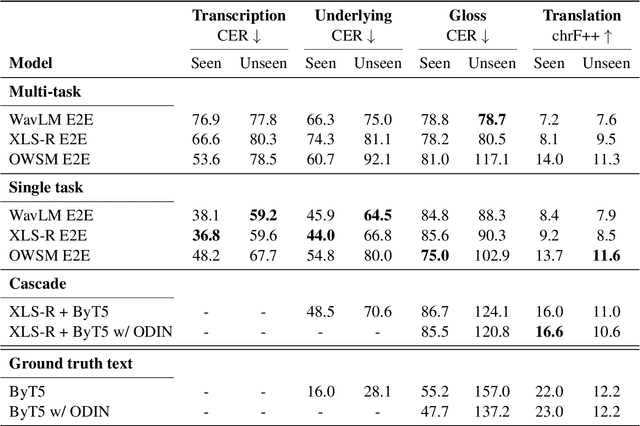
Thousands of the world's languages are in danger of extinction--a tremendous threat to cultural identities and human language diversity. Interlinear Glossed Text (IGT) is a form of linguistic annotation that can support documentation and resource creation for these languages' communities. IGT typically consists of (1) transcriptions, (2) morphological segmentation, (3) glosses, and (4) free translations to a majority language. We propose Wav2Gloss: a task to extract these four annotation components automatically from speech, and introduce the first dataset to this end, Fieldwork: a corpus of speech with all these annotations covering 37 languages with standard formatting and train/dev/test splits. We compare end-to-end and cascaded Wav2Gloss methods, with analysis suggesting that pre-trained decoders assist with translation and glossing, that multi-task and multilingual approaches are underperformant, and that end-to-end systems perform better than cascaded systems, despite the text-only systems' advantages. We provide benchmarks to lay the ground work for future research on IGT generation from speech.
Towards Interpretable Hate Speech Detection using Large Language Model-extracted Rationales
Mar 19, 2024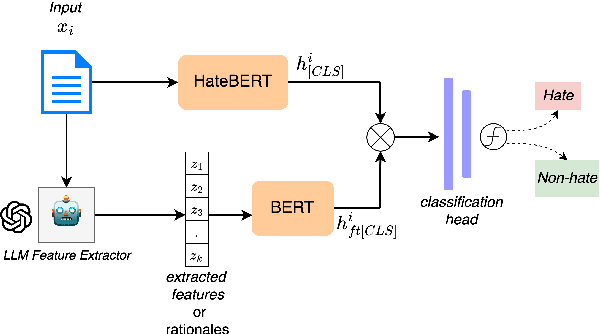
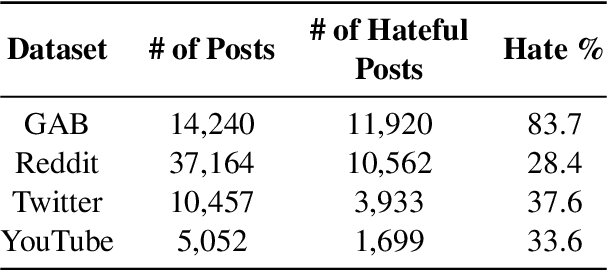

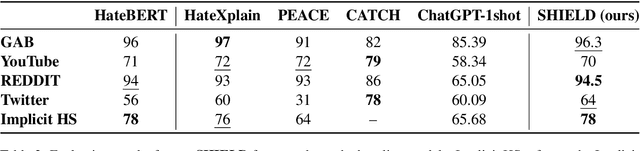
Although social media platforms are a prominent arena for users to engage in interpersonal discussions and express opinions, the facade and anonymity offered by social media may allow users to spew hate speech and offensive content. Given the massive scale of such platforms, there arises a need to automatically identify and flag instances of hate speech. Although several hate speech detection methods exist, most of these black-box methods are not interpretable or explainable by design. To address the lack of interpretability, in this paper, we propose to use state-of-the-art Large Language Models (LLMs) to extract features in the form of rationales from the input text, to train a base hate speech classifier, thereby enabling faithful interpretability by design. Our framework effectively combines the textual understanding capabilities of LLMs and the discriminative power of state-of-the-art hate speech classifiers to make these classifiers faithfully interpretable. Our comprehensive evaluation on a variety of social media hate speech datasets demonstrate: (1) the goodness of the LLM-extracted rationales, and (2) the surprising retention of detector performance even after training to ensure interpretability.
Voice-Assisted Real-Time Traffic Sign Recognition System Using Convolutional Neural Network
Apr 11, 2024Traffic signs are important in communicating information to drivers. Thus, comprehension of traffic signs is essential for road safety and ignorance may result in road accidents. Traffic sign detection has been a research spotlight over the past few decades. Real-time and accurate detections are the preliminaries of robust traffic sign detection system which is yet to be achieved. This study presents a voice-assisted real-time traffic sign recognition system which is capable of assisting drivers. This system functions under two subsystems. Initially, the detection and recognition of the traffic signs are carried out using a trained Convolutional Neural Network (CNN). After recognizing the specific traffic sign, it is narrated to the driver as a voice message using a text-to-speech engine. An efficient CNN model for a benchmark dataset is developed for real-time detection and recognition using Deep Learning techniques. The advantage of this system is that even if the driver misses a traffic sign, or does not look at the traffic sign, or is unable to comprehend the sign, the system detects it and narrates it to the driver. A system of this type is also important in the development of autonomous vehicles.
Visually Grounded Speech Models have a Mutual Exclusivity Bias
Mar 20, 2024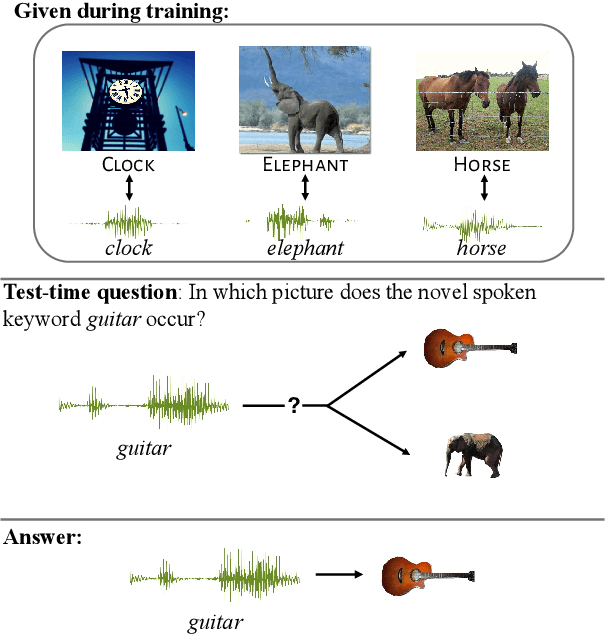

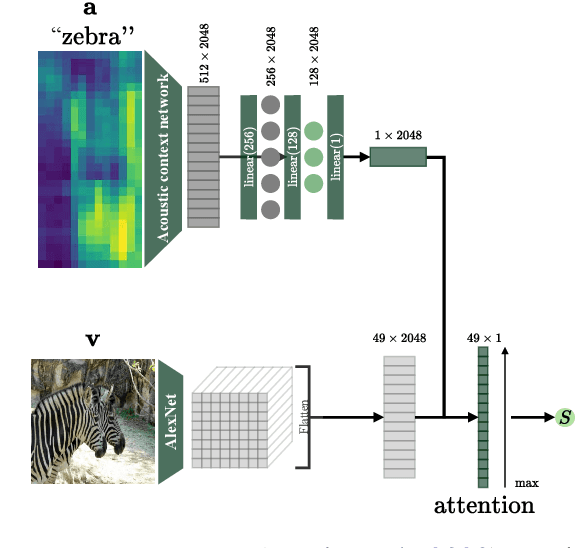
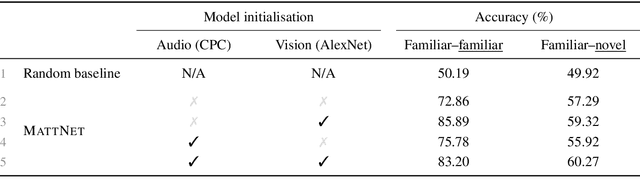
When children learn new words, they employ constraints such as the mutual exclusivity (ME) bias: a novel word is mapped to a novel object rather than a familiar one. This bias has been studied computationally, but only in models that use discrete word representations as input, ignoring the high variability of spoken words. We investigate the ME bias in the context of visually grounded speech models that learn from natural images and continuous speech audio. Concretely, we train a model on familiar words and test its ME bias by asking it to select between a novel and a familiar object when queried with a novel word. To simulate prior acoustic and visual knowledge, we experiment with several initialisation strategies using pretrained speech and vision networks. Our findings reveal the ME bias across the different initialisation approaches, with a stronger bias in models with more prior (in particular, visual) knowledge. Additional tests confirm the robustness of our results, even when different loss functions are considered.
Analyzing Toxicity in Deep Conversations: A Reddit Case Study
Apr 11, 2024Online social media has become increasingly popular in recent years due to its ease of access and ability to connect with others. One of social media's main draws is its anonymity, allowing users to share their thoughts and opinions without fear of judgment or retribution. This anonymity has also made social media prone to harmful content, which requires moderation to ensure responsible and productive use. Several methods using artificial intelligence have been employed to detect harmful content. However, conversation and contextual analysis of hate speech are still understudied. Most promising works only analyze a single text at a time rather than the conversation supporting it. In this work, we employ a tree-based approach to understand how users behave concerning toxicity in public conversation settings. To this end, we collect both the posts and the comment sections of the top 100 posts from 8 Reddit communities that allow profanity, totaling over 1 million responses. We find that toxic comments increase the likelihood of subsequent toxic comments being produced in online conversations. Our analysis also shows that immediate context plays a vital role in shaping a response rather than the original post. We also study the effect of consensual profanity and observe overlapping similarities with non-consensual profanity in terms of user behavior and patterns.
Charles Translator: A Machine Translation System between Ukrainian and Czech
Apr 10, 2024We present Charles Translator, a machine translation system between Ukrainian and Czech, developed as part of a society-wide effort to mitigate the impact of the Russian-Ukrainian war on individuals and society. The system was developed in the spring of 2022 with the help of many language data providers in order to quickly meet the demand for such a service, which was not available at the time in the required quality. The translator was later implemented as an online web interface and as an Android app with speech input, both featuring Cyrillic-Latin script transliteration. The system translates directly, compared to other available systems that use English as a pivot, and thus take advantage of the typological similarity of the two languages. It uses the block back-translation method, which allows for efficient use of monolingual training data. The paper describes the development process, including data collection and implementation, evaluation, mentions several use cases, and outlines possibilities for the further development of the system for educational purposes.
Hatred Stems from Ignorance! Distillation of the Persuasion Modes in Countering Conversational Hate Speech
Mar 18, 2024Examining the factors that the counter-speech uses is at the core of understanding the optimal methods for confronting hate speech online. Various studies assess the emotional base factor used in counter speech, such as emotion-empathy, offensiveness, and level of hostility. To better understand the counter-speech used in conversational interactions, this study distills persuasion modes into reason, emotion, and credibility and then evaluates their use in two types of conversation interactions: closed (multi-turn) and open (single-turn) conversation interactions concerning racism, sexism, and religion. The evaluation covers the distinct behaviors of human versus generated counter-speech. We also assess the interplay between the replies' stance and each mode of persuasion in the counter-speech. Notably, we observe nuanced differences in the counter-speech persuasion modes for open and closed interactions -- especially on the topic level -- with a general tendency to use reason as a persuasion mode to express the counterpoint to hate comments. The generated counter-speech tends to exhibit an emotional persuasion mode, while human counters lean towards using reasoning. Furthermore, our study shows that reason as a persuasion mode tends to obtain more supportive replies than do other persuasion types. The findings highlight the potential of incorporating persuasion modes into studies about countering hate speech, as these modes can serve as an optimal means of explainability and paves the way for the further adoption of the reply's stance and the role it plays in assessing what comprises the optimal counter-speech.