 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Transformer-based Cascaded Multimodal Speech Translation
Oct 29, 2019
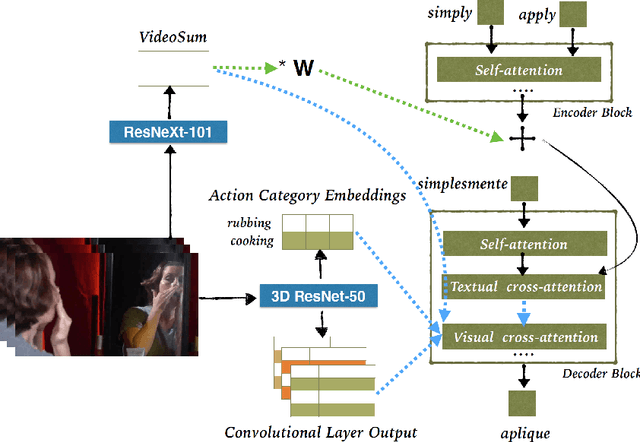
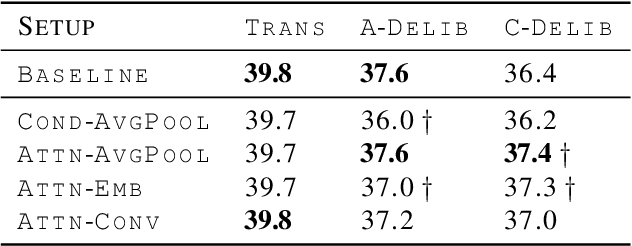
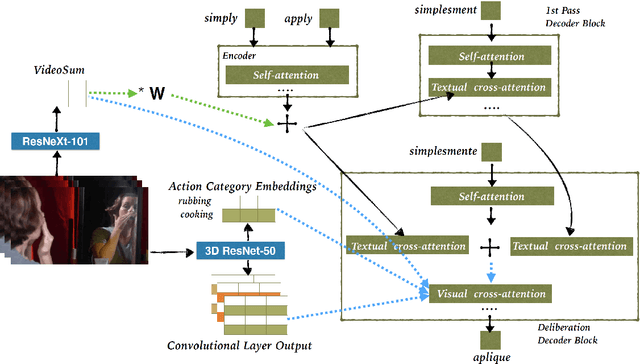
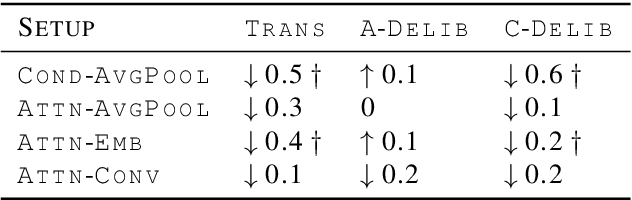
This paper describes the cascaded multimodal speech translation systems developed by Imperial College London for the IWSLT 2019 evaluation campaign. The architecture consists of an automatic speech recognition (ASR) system followed by a Transformer-based multimodal machine translation (MMT) system. While the ASR component is identical across the experiments, the MMT model varies in terms of the way of integrating the visual context (simple conditioning vs. attention), the type of visual features exploited (pooled, convolutional, action categories) and the underlying architecture. For the latter, we explore both the canonical transformer and its deliberation version with additive and cascade variants which differ in how they integrate the textual attention. Upon conducting extensive experiments, we found that (i) the explored visual integration schemes often harm the translation performance for the transformer and additive deliberation, but considerably improve the cascade deliberation; (ii) the transformer and cascade deliberation integrate the visual modality better than the additive deliberation, as shown by the incongruence analysis.
Kurdish (Sorani) Speech to Text: Presenting an Experimental Dataset
Dec 02, 2019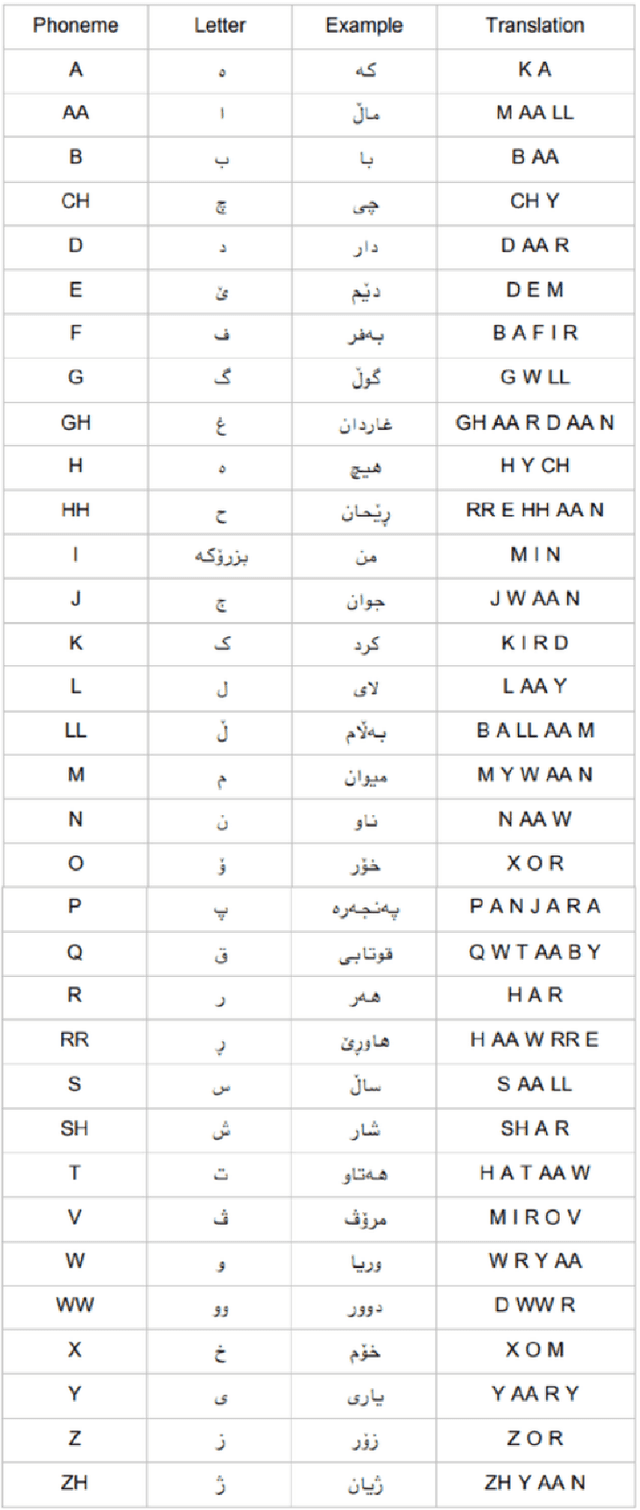
We present an experimental dataset, Basic Dataset for Sorani Kurdish Automatic Speech Recognition (BD-4SK-ASR), which we used in the first attempt in developing an automatic speech recognition for Sorani Kurdish. The objective of the project was to develop a system that automatically could recognize simple sentences based on the vocabulary which is used in grades one to three of the primary schools in the Kurdistan Region of Iraq. We used CMUSphinx as our experimental environment. We developed a dataset to train the system. The dataset is publicly available for non-commercial use under the CC BY-NC-SA 4.0 license.
Unsupervised vs. transfer learning for multimodal one-shot matching of speech and images
Aug 14, 2020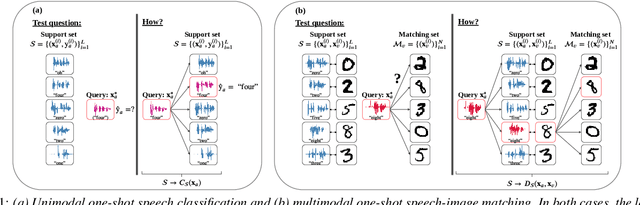
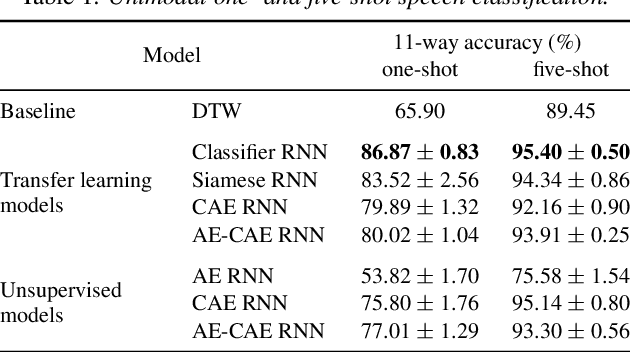
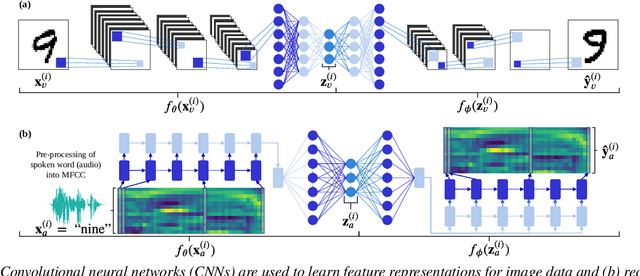
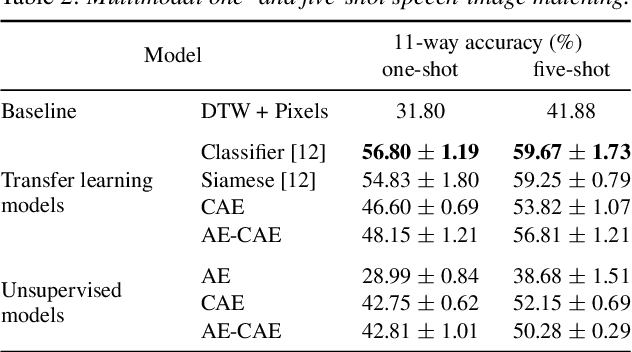
We consider the task of multimodal one-shot speech-image matching. An agent is shown a picture along with a spoken word describing the object in the picture, e.g. cookie, broccoli and ice-cream. After observing one paired speech-image example per class, it is shown a new set of unseen pictures, and asked to pick the "ice-cream". Previous work attempted to tackle this problem using transfer learning: supervised models are trained on labelled background data not containing any of the one-shot classes. Here we compare transfer learning to unsupervised models trained on unlabelled in-domain data. On a dataset of paired isolated spoken and visual digits, we specifically compare unsupervised autoencoder-like models to supervised classifier and Siamese neural networks. In both unimodal and multimodal few-shot matching experiments, we find that transfer learning outperforms unsupervised training. We also present experiments towards combining the two methodologies, but find that transfer learning still performs best (despite idealised experiments showing the benefits of unsupervised learning).
Sequence-To-Sequence Voice Conversion using F0 and Time Conditioning and Adversarial Learning
Oct 07, 2021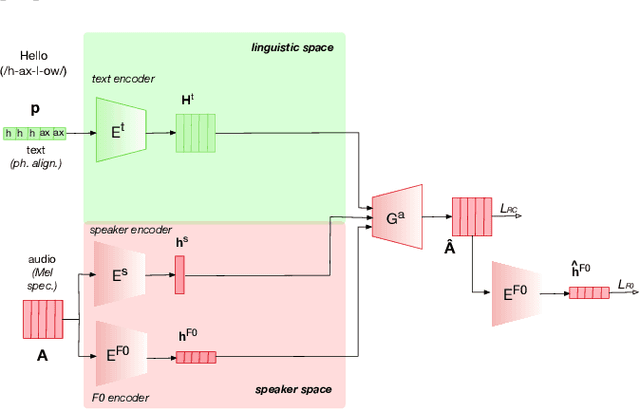
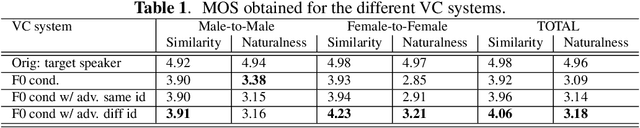
This paper presents a sequence-to-sequence voice conversion (S2S-VC) algorithm which allows to preserve some aspects of the source speaker during conversion, typically its prosody, which is useful in many real-life application of voice conversion. In S2S-VC, the decoder is usually conditioned on linguistic and speaker embeddings only, with the consequence that only the linguistic content is actually preserved during conversion. In the proposed S2S-VC architecture, the decoder is conditioned explicitly on the desired F0 sequence so that the converted speech has the same F0 as the one of the source speaker, or any F0 defined arbitrarily. Moreover, an adversarial module is further employed so that the S2S-VC is not only optimized on the available true speech samples, but can also take efficiently advantage of the converted speech samples that can be produced by using various conditioning such as speaker identity, F0, or timing.
Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders
Oct 25, 2019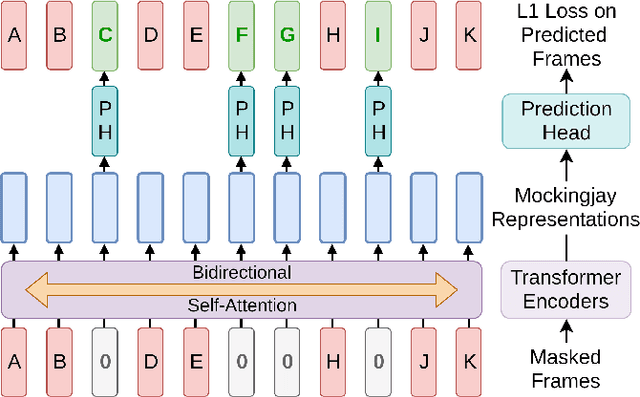
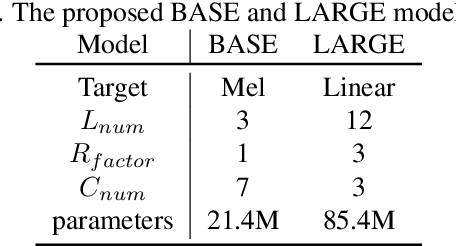
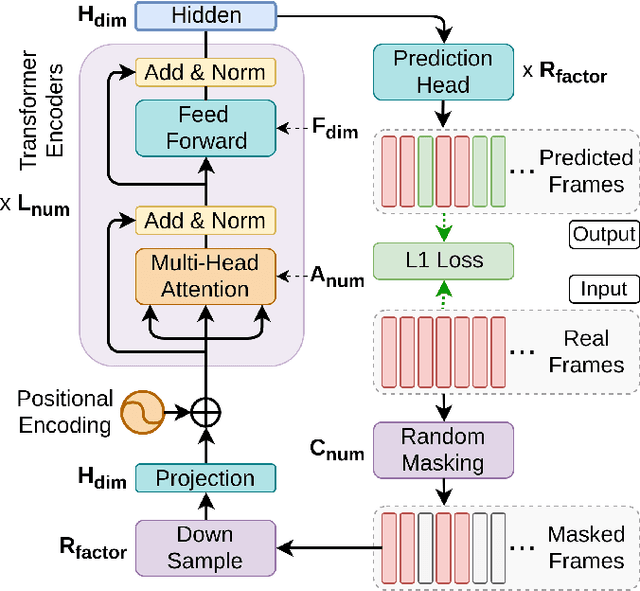
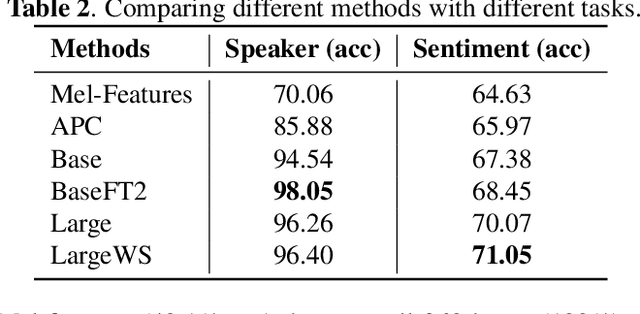
We present Mockingjay as a new speech representation learning approach, where bidirectional Transformer encoders are pre-trained on a large amount of unlabeled speech. Previous speech representation methods learn through conditioning on past frames and predicting information about future frames. Whereas Mockingjay is designed to predict the current frame through jointly conditioning on both past and future contexts. The Mockingjay representation improves performance for a wide range of downstream tasks, including phoneme classification, speaker recognition, and sentiment classification on spoken content, while outperforming other approaches. Mockingjay is empirically powerful and can be fine-tuned with downstream models, with only 2 epochs we further improve performance dramatically. In a low resource setting with only 0.1% of labeled data, we outperform the result of Mel-features that uses all 100% labeled data.
Lite Audio-Visual Speech Enhancement
May 24, 2020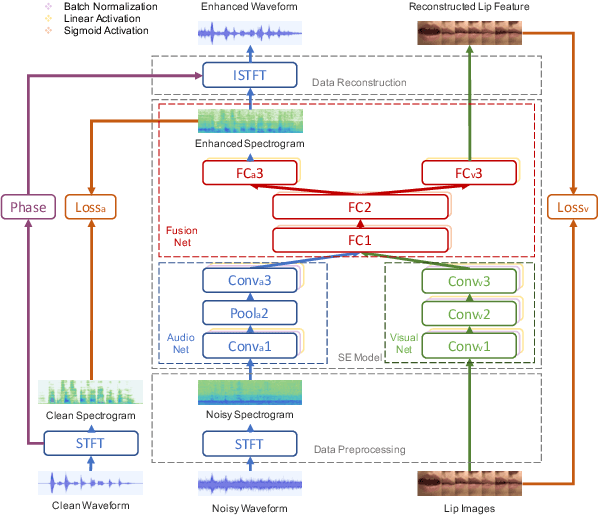
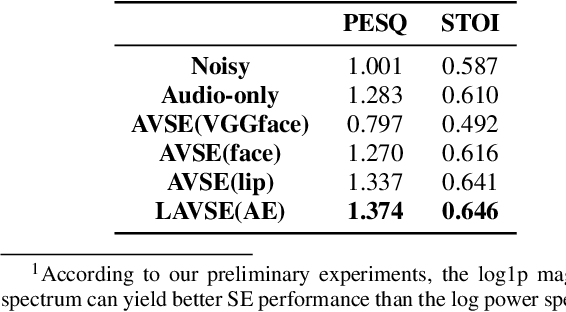
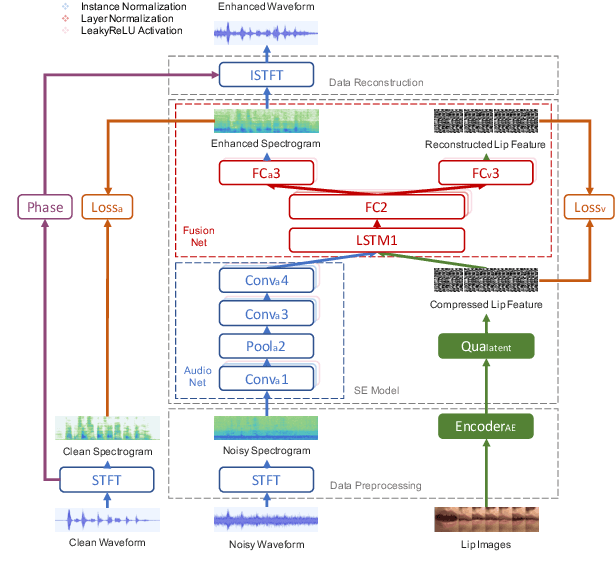
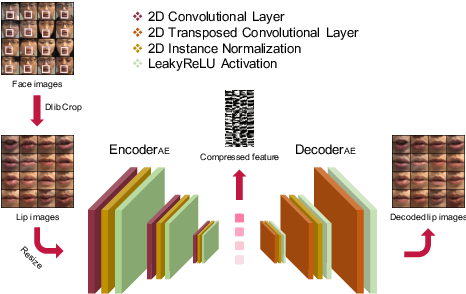
Previous studies have confirmed the effectiveness of incorporating visual information into speech enhancement (SE) systems. Despite improved denoising performance, two problems may be encountered when implementing an audio-visual SE (AVSE) system: (1) additional processing costs are incurred to incorporate visual input and (2) the use of face or lip images may cause privacy problems. In this study, we propose a Lite AVSE (LAVSE) system to address these problems. The system includes two visual data compression techniques and removes the visual feature extraction network from the training model, yielding better online computation efficiency. Our experimental results indicate that the proposed LAVSE system can provide notably better performance than an audio-only SE system with a similar number of model parameters. In addition, the experimental results confirm the effectiveness of the two techniques for visual data compression.
LSTM-LM with Long-Term History for First-Pass Decoding in Conversational Speech Recognition
Oct 21, 2020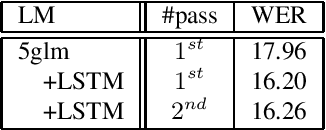
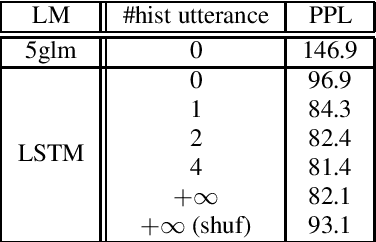

LSTM language models (LSTM-LMs) have been proven to be powerful and yielded significant performance improvements over count based n-gram LMs in modern speech recognition systems. Due to its infinite history states and computational load, most previous studies focus on applying LSTM-LMs in the second-pass for rescoring purpose. Recent work shows that it is feasible and computationally affordable to adopt the LSTM-LMs in the first-pass decoding within a dynamic (or tree based) decoder framework. In this work, the LSTM-LM is composed with a WFST decoder on-the-fly for the first-pass decoding. Furthermore, motivated by the long-term history nature of LSTM-LMs, the use of context beyond the current utterance is explored for the first-pass decoding in conversational speech recognition. The context information is captured by the hidden states of LSTM-LMs across utterance and can be used to guide the first-pass search effectively. The experimental results in our internal meeting transcription system show that significant performance improvements can be obtained by incorporating the contextual information with LSTM-LMs in the first-pass decoding, compared to applying the contextual information in the second-pass rescoring.
Delta Keyword Transformer: Bringing Transformers to the Edge through Dynamically Pruned Multi-Head Self-Attention
Mar 20, 2022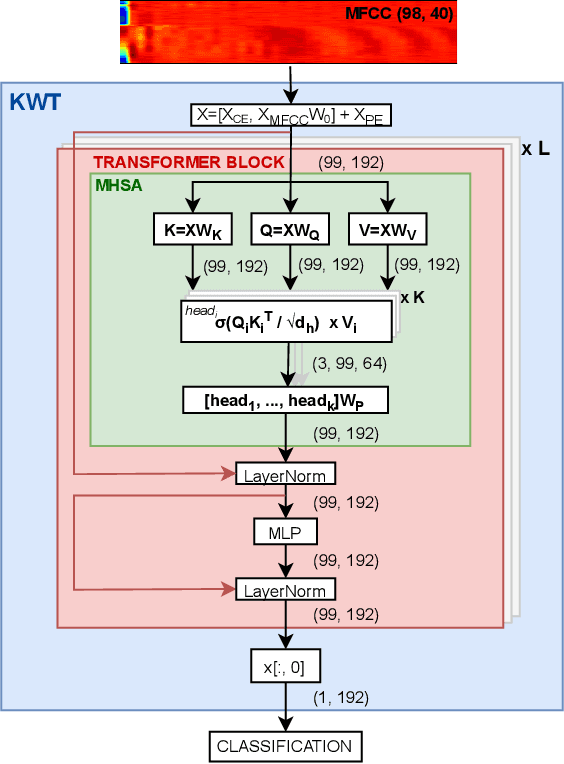
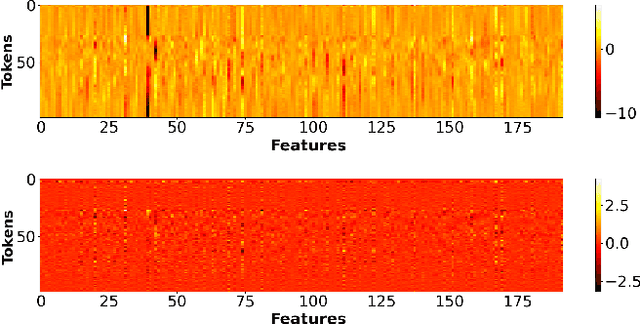
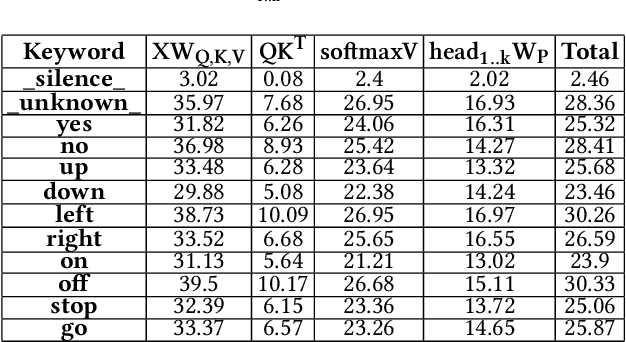
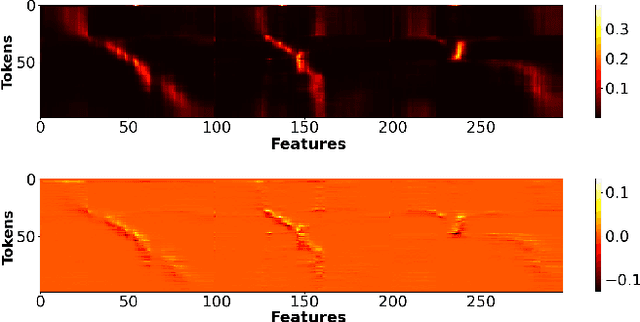
Multi-head self-attention forms the core of Transformer networks. However, their quadratically growing complexity with respect to the input sequence length impedes their deployment on resource-constrained edge devices. We address this challenge by proposing a dynamic pruning method, which exploits the temporal stability of data across tokens to reduce inference cost. The threshold-based method only retains significant differences between the subsequent tokens, effectively reducing the number of multiply-accumulates, as well as the internal tensor data sizes. The approach is evaluated on the Google Speech Commands Dataset for keyword spotting, and the performance is compared against the baseline Keyword Transformer. Our experiments show that we can reduce ~80% of operations while maintaining the original 98.4% accuracy. Moreover, a reduction of ~87-94% operations can be achieved when only degrading the accuracy by 1-4%, speeding up the multi-head self-attention inference by a factor of ~7.5-16.
Self-supervised curriculum learning for speaker verification
Apr 05, 2022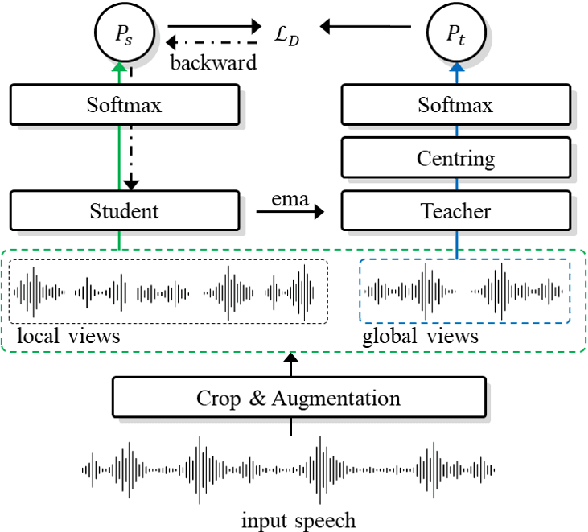
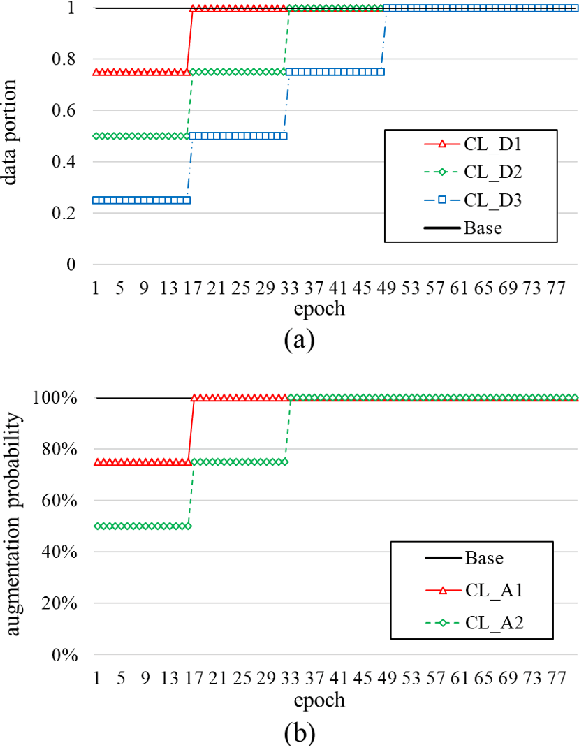
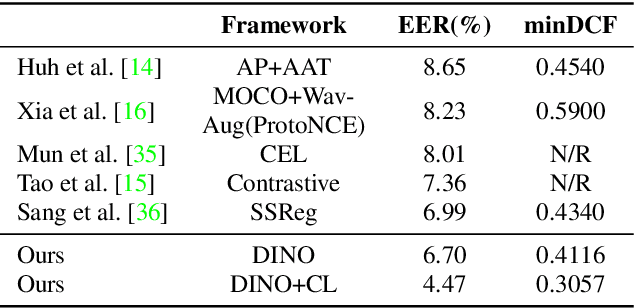
Self-supervised learning is one of the emerging approaches to machine learning today, and has been successfully applied to vision, speech and natural processing tasks. There is a range of frameworks within self-supervised learning literature, but the speaker recognition literature has particularly adopted self-supervision via contrastive loss functions. Our work adapts the DINO framework for speaker recognition, in which the model is trained without exploiting negative utterance pairs. We introduce a curriculum learning strategy to the self-supervised framework, which guides effective training of speaker recognition models. In particular, we propose two curriculum strategies where one gradually increases the number of speakers in training dataset, and the other gradually applies augmentations to more utterances within a mini-batch as the training proceeds. A range of experiments conducted on the VoxCeleb1 evaluation protocol demonstrate the effectiveness of both the DINO framework on speaker verification and our proposed curriculum learning strategies. We report the state-of-the-art equal error rate of 4.47% with a single-phase training.
Is 42 the Answer to Everything in Subtitling-oriented Speech Translation?
Jun 01, 2020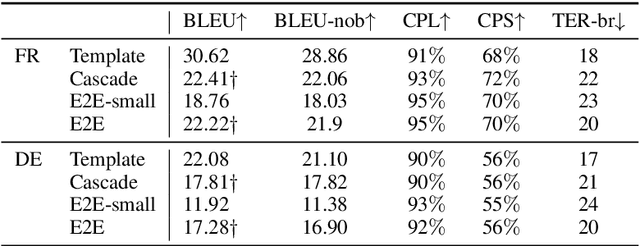
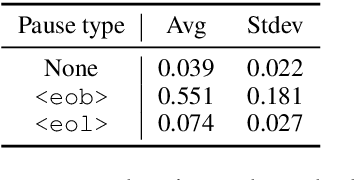

Subtitling is becoming increasingly important for disseminating information, given the enormous amounts of audiovisual content becoming available daily. Although Neural Machine Translation (NMT) can speed up the process of translating audiovisual content, large manual effort is still required for transcribing the source language, and for spotting and segmenting the text into proper subtitles. Creating proper subtitles in terms of timing and segmentation highly depends on information present in the audio (utterance duration, natural pauses). In this work, we explore two methods for applying Speech Translation (ST) to subtitling: a) a direct end-to-end and b) a classical cascade approach. We discuss the benefit of having access to the source language speech for improving the conformity of the generated subtitles to the spatial and temporal subtitling constraints and show that length is not the answer to everything in the case of subtitling-oriented ST.