 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
What does a network layer hear? Analyzing hidden representations of end-to-end ASR through speech synthesis
Nov 04, 2019
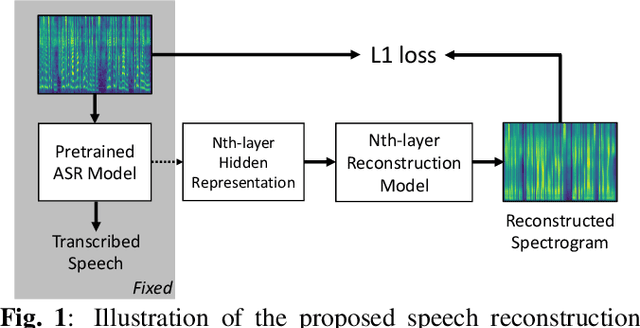
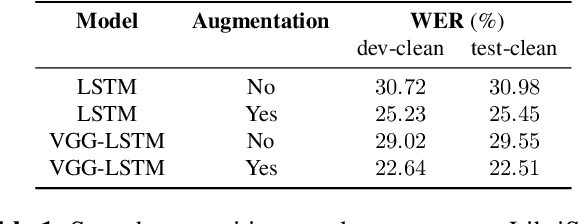
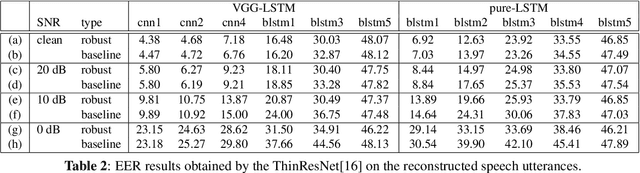
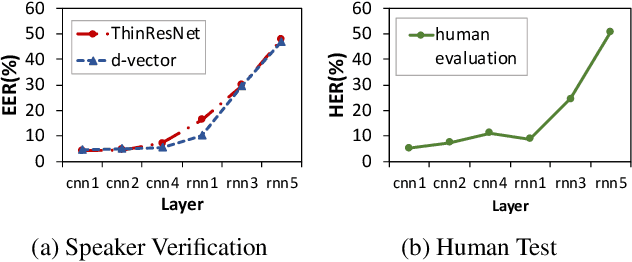
End-to-end speech recognition systems have achieved competitive results compared to traditional systems. However, the complex transformations involved between layers given highly variable acoustic signals are hard to analyze. In this paper, we present our ASR probing model, which synthesizes speech from hidden representations of end-to-end ASR to examine the information maintain after each layer calculation. Listening to the synthesized speech, we observe gradual removal of speaker variability and noise as the layer goes deeper, which aligns with the previous studies on how deep network functions in speech recognition. This paper is the first study analyzing the end-to-end speech recognition model by demonstrating what each layer hears. Speaker verification and speech enhancement measurements on synthesized speech are also conducted to confirm our observation further.
Mask-based Neural Beamforming for Moving Speakers with Self-Attention-based Tracking
May 07, 2022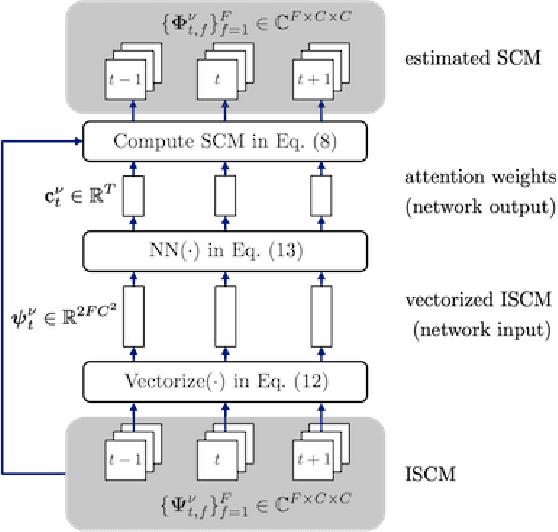
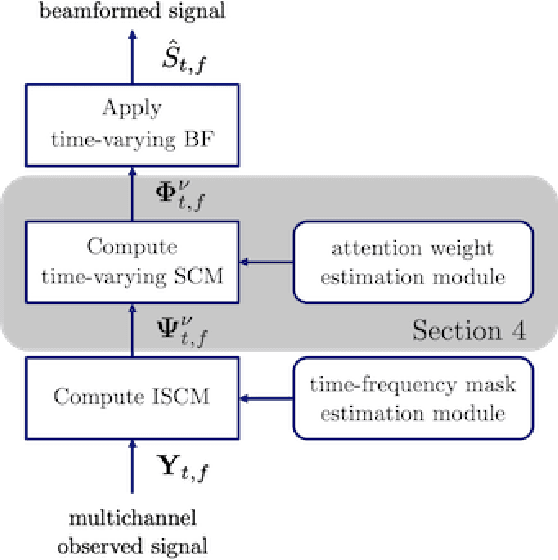
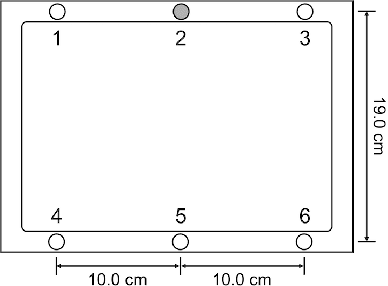
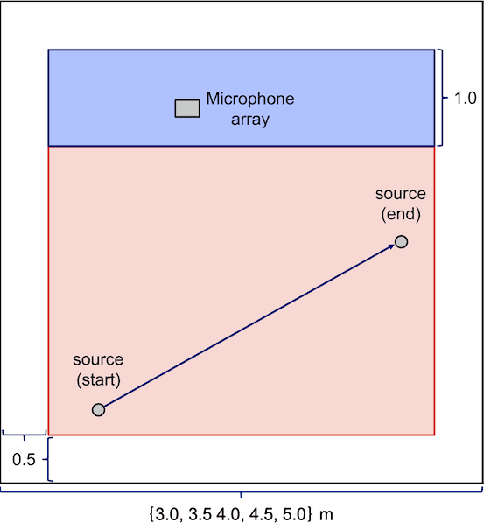
Beamforming is a powerful tool designed to enhance speech signals from the direction of a target source. Computing the beamforming filter requires estimating spatial covariance matrices (SCMs) of the source and noise signals. Time-frequency masks are often used to compute these SCMs. Most studies of mask-based beamforming have assumed that the sources do not move. However, sources often move in practice, which causes performance degradation. In this paper, we address the problem of mask-based beamforming for moving sources. We first review classical approaches to tracking a moving source, which perform online or blockwise computation of the SCMs. We show that these approaches can be interpreted as computing a sum of instantaneous SCMs weighted by attention weights. These weights indicate which time frames of the signal to consider in the SCM computation. Online or blockwise computation assumes a heuristic and deterministic way of computing these attention weights that, although simple, may not result in optimal performance. We thus introduce a learning-based framework that computes optimal attention weights for beamforming. We achieve this using a neural network implemented with self-attention layers. We show experimentally that our proposed framework can greatly improve beamforming performance in moving source situations while maintaining high performance in non-moving situations, thus enabling the development of mask-based beamformers robust to source movements.
On Prosody Modeling for ASR+TTS based Voice Conversion
Jul 20, 2021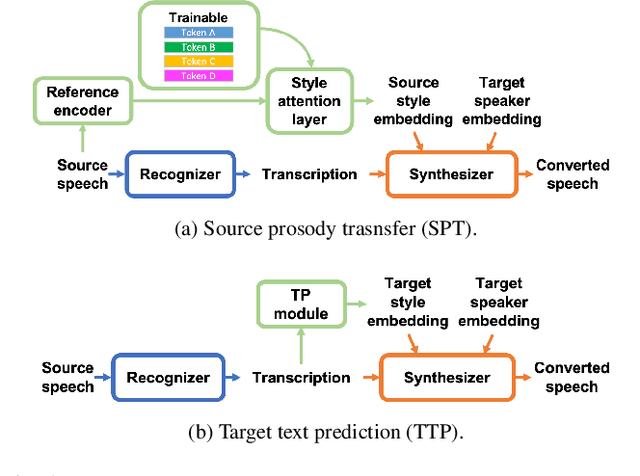

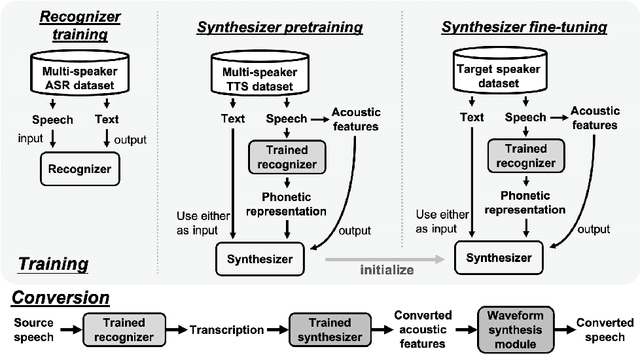

In voice conversion (VC), an approach showing promising results in the latest voice conversion challenge (VCC) 2020 is to first use an automatic speech recognition (ASR) model to transcribe the source speech into the underlying linguistic contents; these are then used as input by a text-to-speech (TTS) system to generate the converted speech. Such a paradigm, referred to as ASR+TTS, overlooks the modeling of prosody, which plays an important role in speech naturalness and conversion similarity. Although some researchers have considered transferring prosodic clues from the source speech, there arises a speaker mismatch during training and conversion. To address this issue, in this work, we propose to directly predict prosody from the linguistic representation in a target-speaker-dependent manner, referred to as target text prediction (TTP). We evaluate both methods on the VCC2020 benchmark and consider different linguistic representations. The results demonstrate the effectiveness of TTP in both objective and subjective evaluations.
Conditional probing: measuring usable information beyond a baseline
Sep 19, 2021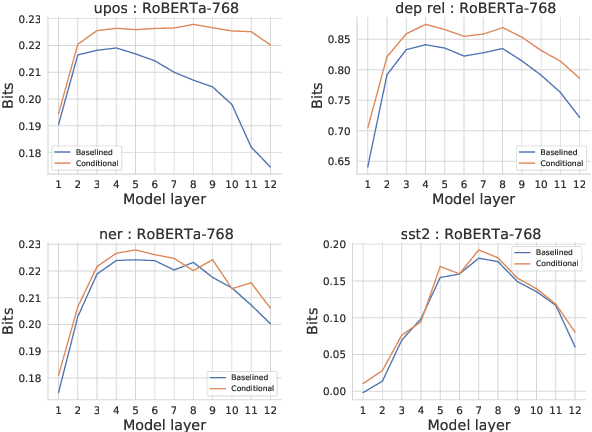
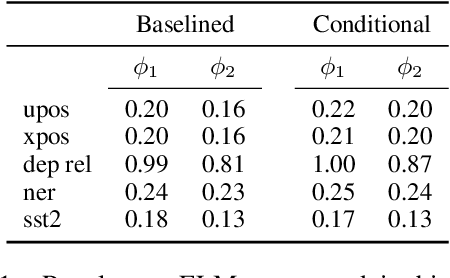
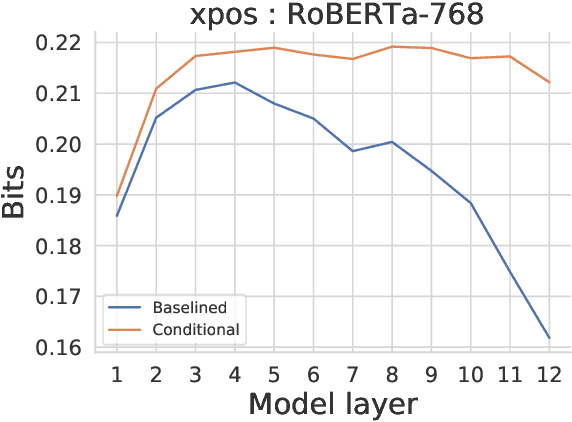
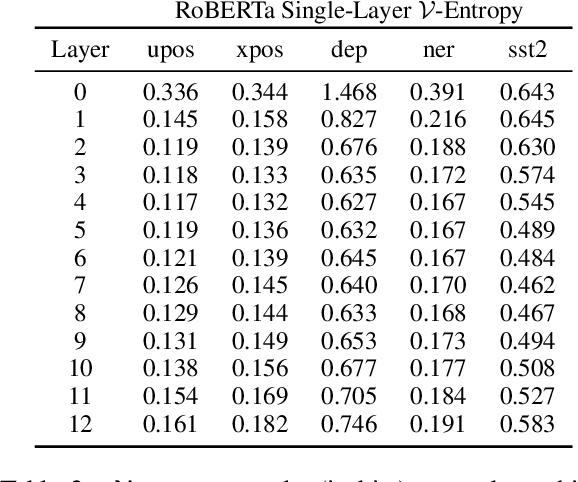
Probing experiments investigate the extent to which neural representations make properties -- like part-of-speech -- predictable. One suggests that a representation encodes a property if probing that representation produces higher accuracy than probing a baseline representation like non-contextual word embeddings. Instead of using baselines as a point of comparison, we're interested in measuring information that is contained in the representation but not in the baseline. For example, current methods can detect when a representation is more useful than the word identity (a baseline) for predicting part-of-speech; however, they cannot detect when the representation is predictive of just the aspects of part-of-speech not explainable by the word identity. In this work, we extend a theory of usable information called $\mathcal{V}$-information and propose conditional probing, which explicitly conditions on the information in the baseline. In a case study, we find that after conditioning on non-contextual word embeddings, properties like part-of-speech are accessible at deeper layers of a network than previously thought.
Transfer Learning from Audio-Visual Grounding to Speech Recognition
Jul 09, 2019
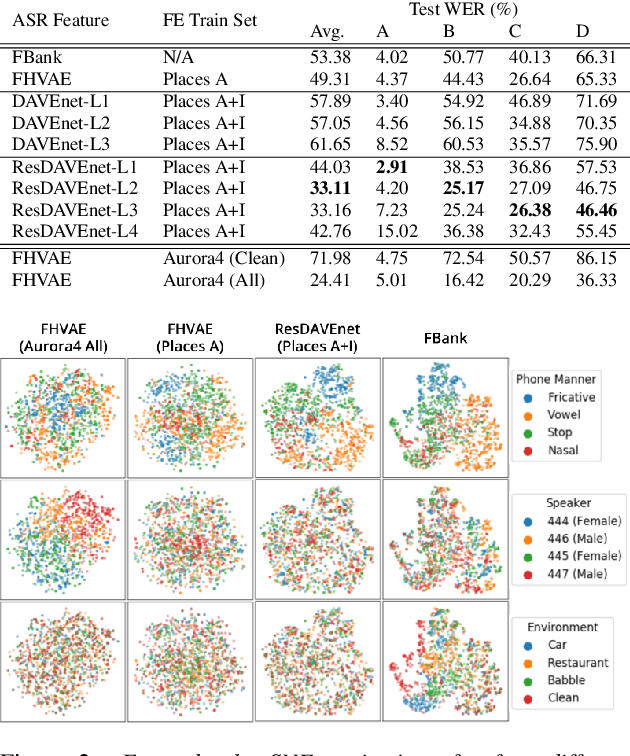
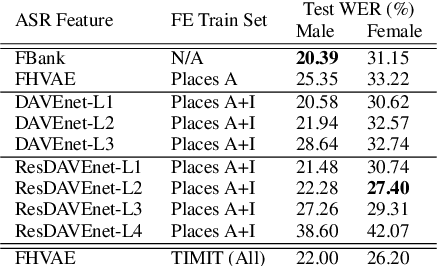
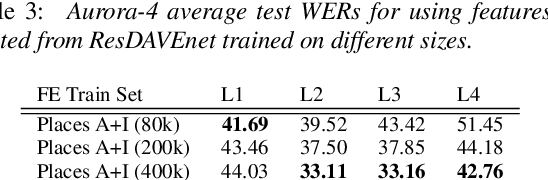
Transfer learning aims to reduce the amount of data required to excel at a new task by re-using the knowledge acquired from learning other related tasks. This paper proposes a novel transfer learning scenario, which distills robust phonetic features from grounding models that are trained to tell whether a pair of image and speech are semantically correlated, without using any textual transcripts. As semantics of speech are largely determined by its lexical content, grounding models learn to preserve phonetic information while disregarding uncorrelated factors, such as speaker and channel. To study the properties of features distilled from different layers, we use them as input separately to train multiple speech recognition models. Empirical results demonstrate that layers closer to input retain more phonetic information, while following layers exhibit greater invariance to domain shift. Moreover, while most previous studies include training data for speech recognition for feature extractor training, our grounding models are not trained on any of those data, indicating more universal applicability to new domains.
Deep Spoken Keyword Spotting: An Overview
Nov 20, 2021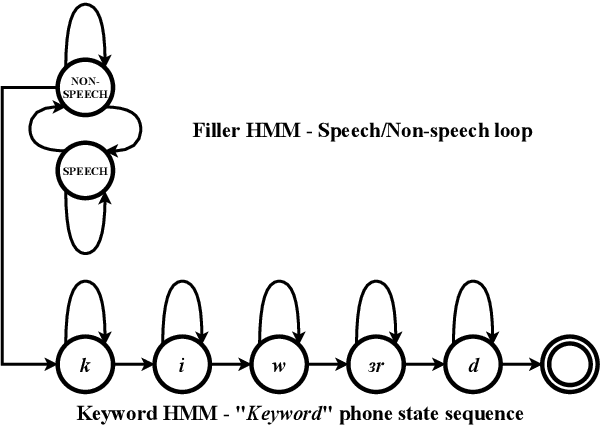
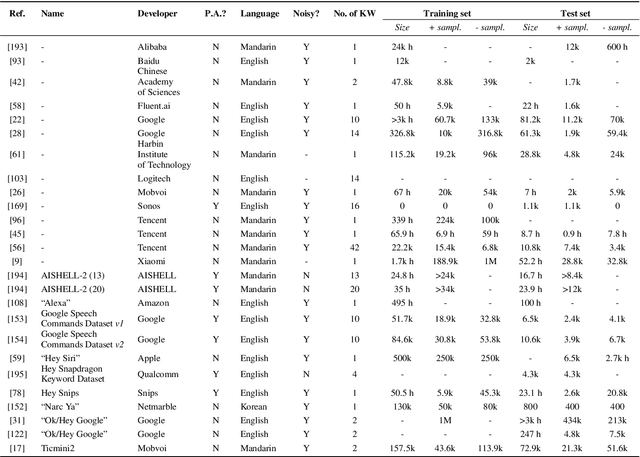
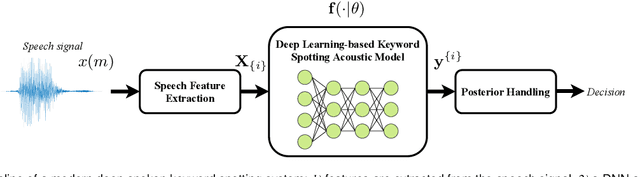

Spoken keyword spotting (KWS) deals with the identification of keywords in audio streams and has become a fast-growing technology thanks to the paradigm shift introduced by deep learning a few years ago. This has allowed the rapid embedding of deep KWS in a myriad of small electronic devices with different purposes like the activation of voice assistants. Prospects suggest a sustained growth in terms of social use of this technology. Thus, it is not surprising that deep KWS has become a hot research topic among speech scientists, who constantly look for KWS performance improvement and computational complexity reduction. This context motivates this paper, in which we conduct a literature review into deep spoken KWS to assist practitioners and researchers who are interested in this technology. Specifically, this overview has a comprehensive nature by covering a thorough analysis of deep KWS systems (which includes speech features, acoustic modeling and posterior handling), robustness methods, applications, datasets, evaluation metrics, performance of deep KWS systems and audio-visual KWS. The analysis performed in this paper allows us to identify a number of directions for future research, including directions adopted from automatic speech recognition research and directions that are unique to the problem of spoken KWS.
Gated Embeddings in End-to-End Speech Recognition for Conversational-Context Fusion
Jun 27, 2019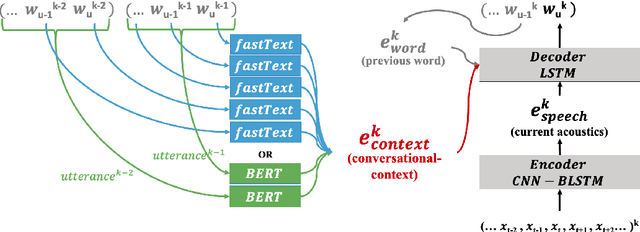
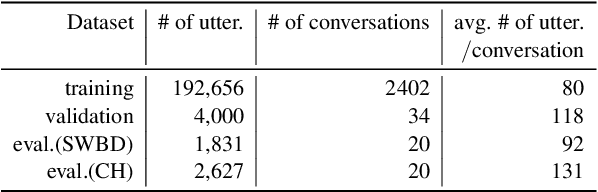
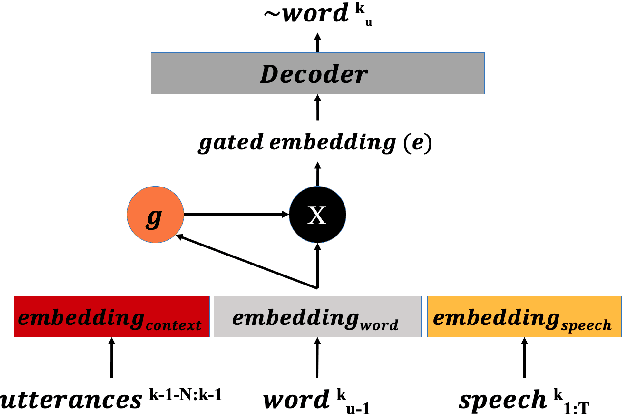
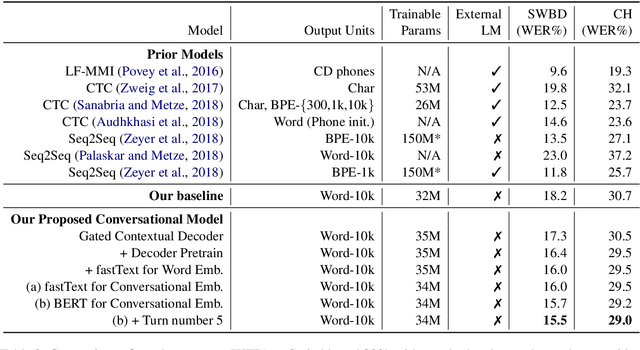
We present a novel conversational-context aware end-to-end speech recognizer based on a gated neural network that incorporates conversational-context/word/speech embeddings. Unlike conventional speech recognition models, our model learns longer conversational-context information that spans across sentences and is consequently better at recognizing long conversations. Specifically, we propose to use the text-based external word and/or sentence embeddings (i.e., fastText, BERT) within an end-to-end framework, yielding a significant improvement in word error rate with better conversational-context representation. We evaluated the models on the Switchboard conversational speech corpus and show that our model outperforms standard end-to-end speech recognition models.
Learning Deep Direct-Path Relative Transfer Function for Binaural Sound Source Localization
Feb 16, 2022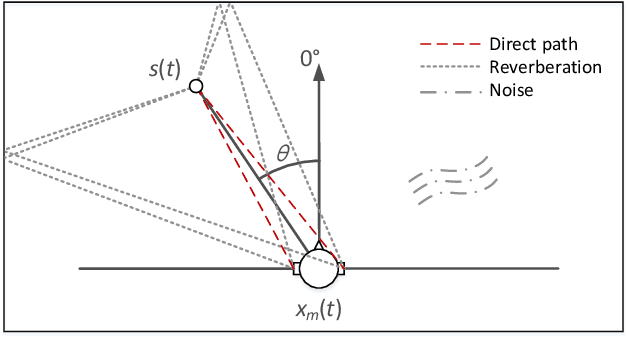
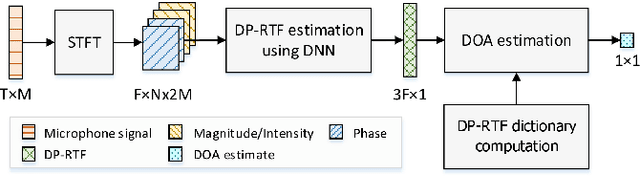
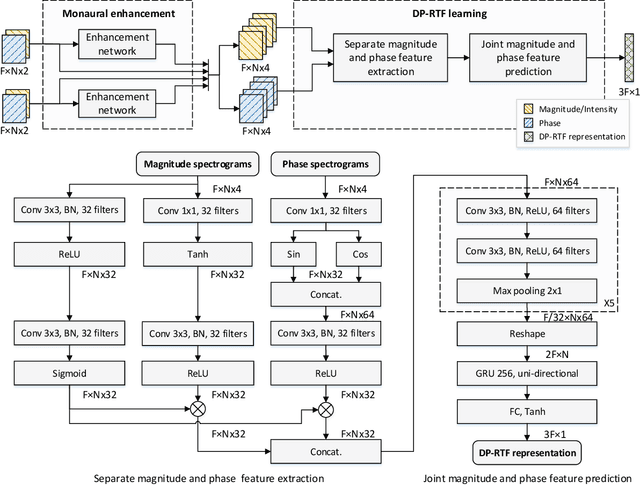
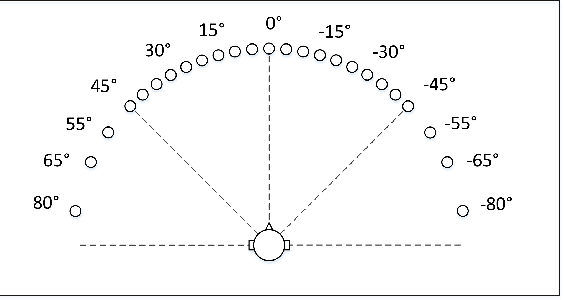
Direct-path relative transfer function (DP-RTF) refers to the ratio between the direct-path acoustic transfer functions of two microphone channels. Though DP-RTF fully encodes the sound spatial cues and serves as a reliable localization feature, it is often erroneously estimated in the presence of noise and reverberation. This paper proposes to learn DP-RTF with deep neural networks for robust binaural sound source localization. A DP-RTF learning network is designed to regress the binaural sensor signals to a real-valued representation of DP-RTF. It consists of a branched convolutional neural network module to separately extract the inter-channel magnitude and phase patterns, and a convolutional recurrent neural network module for joint feature learning. To better explore the speech spectra to aid the DP-RTF estimation, a monaural speech enhancement network is used to recover the direct-path spectrograms from the noisy ones. The enhanced spectrograms are stacked onto the noisy spectrograms to act as the input of the DP-RTF learning network. We train one unique DP-RTF learning network using many different binaural arrays to enable the generalization of DP-RTF learning across arrays. This way avoids time-consuming training data collection and network retraining for a new array, which is very useful in practical application. Experimental results on both simulated and real-world data show the effectiveness of the proposed method for direction of arrival (DOA) estimation in the noisy and reverberant environment, and a good generalization ability to unseen binaural arrays.
Knowledge distillation from language model to acoustic model: a hierarchical multi-task learning approach
Oct 20, 2021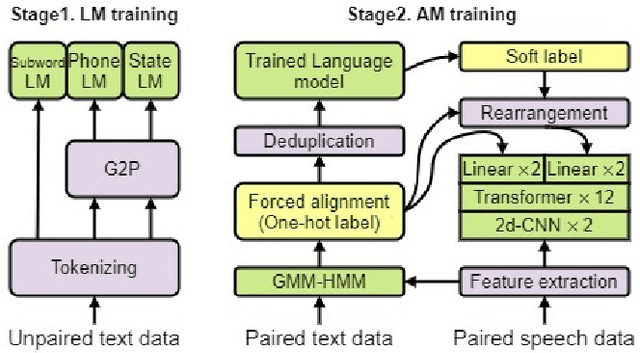
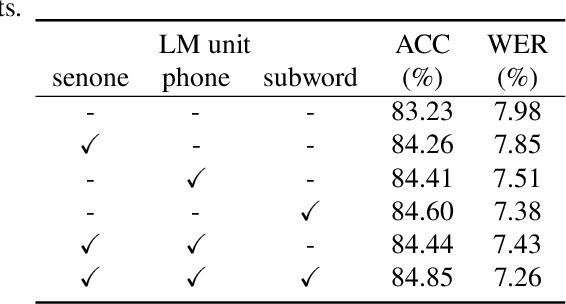
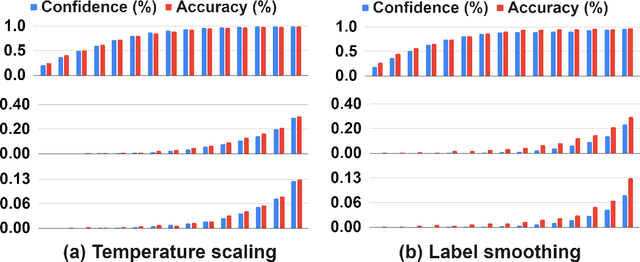

The remarkable performance of the pre-trained language model (LM) using self-supervised learning has led to a major paradigm shift in the study of natural language processing. In line with these changes, leveraging the performance of speech recognition systems with massive deep learning-based LMs is a major topic of speech recognition research. Among the various methods of applying LMs to speech recognition systems, in this paper, we focus on a cross-modal knowledge distillation method that transfers knowledge between two types of deep neural networks with different modalities. We propose an acoustic model structure with multiple auxiliary output layers for cross-modal distillation and demonstrate that the proposed method effectively compensates for the shortcomings of the existing label-interpolation-based distillation method. In addition, we extend the proposed method to a hierarchical distillation method using LMs trained in different units (senones, monophones, and subwords) and reveal the effectiveness of the hierarchical distillation method through an ablation study.
Deep Annotation of Therapeutic Working Alliance in Psychotherapy
Apr 12, 2022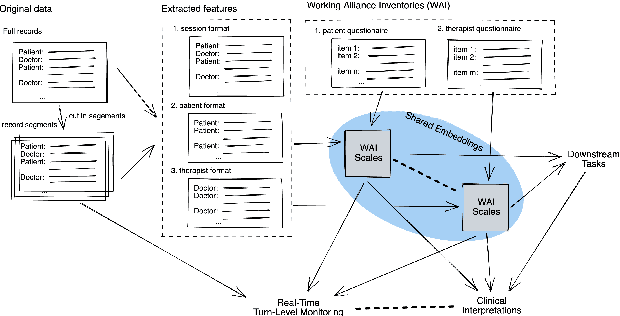



The therapeutic working alliance is an important predictor of the outcome of the psychotherapy treatment. In practice, the working alliance is estimated from a set of scoring questionnaires in an inventory that both the patient and the therapists fill out. In this work, we propose an analytical framework of directly inferring the therapeutic working alliance from the natural language within the psychotherapy sessions in a turn-level resolution with deep embeddings such as the Doc2Vec and SentenceBERT models. The transcript of each psychotherapy session can be transcribed and generated in real-time from the session speech recordings, and these embedded dialogues are compared with the distributed representations of the statements in the working alliance inventory. We demonstrate, in a real-world dataset with over 950 sessions of psychotherapy treatments in anxiety, depression, schizophrenia and suicidal patients, the effectiveness of this method in mapping out trajectories of patient-therapist alignment and the interpretability that can offer insights in clinical psychiatry. We believe such a framework can be provide timely feedback to the therapist regarding the quality of the conversation in interview sessions.